Python 멀티스레딩으로 실시간 데이터 파이프라인 구현하기
배경
여러 디바이스가 개별 토픽으로 데이터를 발행하고 있었다. 각 디바이스는 devices/{device_id}/metrics 형식의 토픽을 사용했는데, 클라이언트가 모든 디바이스의 데이터를 받으려면 수십 개의 토픽을 일일이 구독해야 하는 상황이었다. (MQTT republish라는 걸 쓰면 분산된 토픽을 통합하지 않고, 그대로 다시 뿌려준다고 한다.)
현재 상황
devices/device_001/metrics → Client A, B, C 모두 구독
devices/device_002/metrics → Client A, B, C 모두 구독
devices/device_003/metrics → Client A, B, C 모두 구독
...이건 명백히 비효율적이다. 클라이언트마다 수십 개의 구독을 관리해야 하고, 네트워크 오버헤드도 크다.
목표
- 분산된 토픽들을 하나의 통합 토픽으로 재발행
- 실시간성 유지 (1초 주기)
devices/device_001/metrics ┐
devices/device_002/metrics ├→ [통합 모듈] → devices/all/metrics
devices/device_003/metrics ┘전체 아키텍처
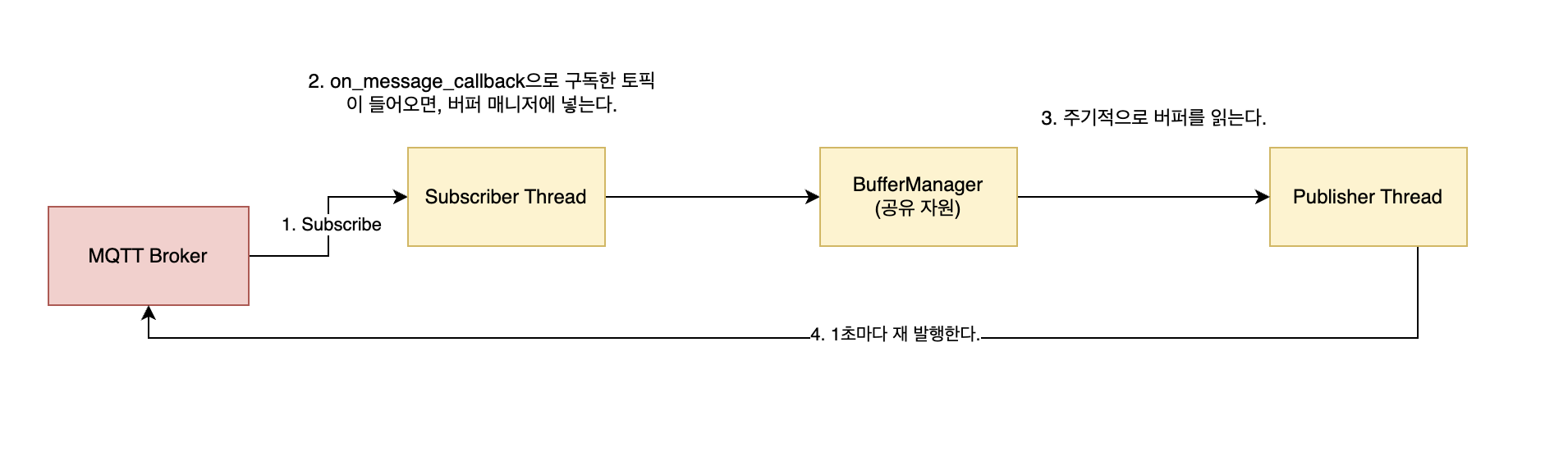
핵심 모듈
- BufferManager: device_id별 최신 데이터를 HashMap으로 관리
- PeriodicPublisher: 1초마다 버퍼 데이터를 통합 발행
- AggregatorService: 전체 흐름 조율
구현
1. BufferManager (자료 구조)
요구사항
- device_id를 키로하는 HashMap 구조
- 새 데이터가 오면 기존 데이터를 덮어쓰는, 최신 상태만 관리함
import threading
from typing import Dict, List, Any
class BufferManager:
def __init__(self):
self._buffer : Dict[str,Any] = {}
self._lock=threading.Lock()
def update(self,device_id:str, data:Any) -> None:
with self._lock:
self._buffer[device_id] = data
def get_snapshot(self)->List[Dict[str,Any]]:
with self._lock:
return [
{"device_id" : device_id, "data": data}
for device_id,data in self._buffer.items()
]사실 락을 도입할 지 말지 고민했다. 왜냐하면 이 데이터들은 금융 데이터처럼 정합성이 중요하기보다는,
단순히 실시간적으로 데이터를 빠르게 보여주기만 하면 되기 때문이다.
그래도 락의 오버헤드는 마이크로 초 단위라 매우 오버헤드가 적고, 1초에 1번 발행이므로 경합이 적기 때문에 락을 도입해도 문제 없다고 판단해서 락을 넣었다.
2. PeriodicPublisher (주기적으로 발행하는 스레드)
요구 사항
- 정확히 1초마다 발행
- 데이터 없으면 빈 배열로 발행
import threading
import json
class PeriodicPublisher:
def __init__(self,
publisher,
buffer_manager,
target_topic:str,
interval:float=1.0,
):
self.publisher = publisher
self.buffer_manager = buffer_manager
self.target_topic = target_topic
self.interval = interval
self._thread=None
self._stop_event=threading.Event()
def _publish_loop(self):
while not self._stop_event.is_set():
try:
data=self.buffer_manager.get_snapshot()
payload=json.dumps(data,ensure_ascii=False).encode('utf-8')
self.publisher.publish(self.target_topic,payload)
except Exception as e:
print(e)
self._stop_event.wait(self.interval) # Event.wait()은 set()되면 즉시 깨어남.
def start(self):
if self._thread and self._thread.is_alive():
return
self._stop_event.clear()
self._thread=threading.Thread(target=self._publish_loop,daemon=True)
self._thread.start()
def stop(self):
if not self._thread:
return
self._stop_event.set() # 즉시 깨어난다.
self._thread.join(timeout=5) # 스레드가 다 작업을 끝날 때까지 대기한다.
self._thread=None
Event.wait(timeout)는 timeout 동안 대기 하되, set()이 호출되면 즉시 반환환다.
3. AggregatorSerivce
역할
- subscriber , publisher 초기화
- 메시지 콜백 등록
- 모든 컴포넌트의 생명 주기 관리
import json
class MessageAggregatorService:
def __init__(self,
subscriber,
publisher,
target_topic:str,
publish_interval:float=1.0,
):
self.subscriber = subscriber
self.publisher = publisher
self.target_topic = target_topic
self.buffer_manager=BufferMangager()
self.periodic_publisher=None
def _on_message_received(self, topic:str, payload:bytes)->None:
"""
MQTT 메시지 수신 콜백.
비동기적으로 호출되며, 버퍼를 즉시 업데이트.
"""
try :
# 1. 전처리
device_id=pre_process(payload)
# 2. 데이터 파싱
data=json.loads(payload.decode("utf-8"))
# 3. 버퍼 업데이트
self.buffer_manager.update(device_id,data)
except Exception as e:
print(e)
def strat(self):
# 1. subscriber 연결 및 콜백 등록
self.subscriber.set_callback(self._on_message_received)
self.subscriber.connect()
self.subscriber.subscribe("some_topic")
# 2. publisher 연결
self.publisher.connect()
# 3. 주기적 발행 스레드 시작
self.periodic_publisher = PeriodicPublisher(
publisher=self.publisher,
buffer_manager=self.buffer_manager,
target_topic=self.target_topic,
interval=1.0,
use_clear=False,
)
self.periodic_publisher.start()
def stop(self):
if self.periodic_publisher:
self.periodic_publisher.stop()
self.subscriber.disconnect()
self.publisher.disconnect()일반적인 함수는 내 코드가 직접 호출한다.
반면, 콜백 함수는 내가 해당 함수를 등록하면 라이브러리가 알아서 호출한다. 이 코드에서는 메시지가 올 경우 라이브러리가 알아서 내 콜백을 호출하고, 버퍼에 넣는다.
왜 콜백을 쓰는가?
- 메시지가 언제 올지 모름
- 메시지가 오면 즉시 콜백 호출
- 내 코드는 대기하지 않고 다른 일 수행
배운점
- 실시간 데이터 파이프라인의 전형적인 설계
- 데이터 소스 → 버퍼 → 변환 → 발행
- 이 구조는 kafka, redis pub sub, rabbitmq에도 많이 쓰인다.
- 이벤트 기반 아키텍처
- threading.lock과 threading.event
- 콜백 넣어서 함수 등록하기

아키텍쳐 설계에 관심이 많은 백엔드 개발자입니다.