1. 문제
[본 문제는 정확성과 효율성 테스트 각각 점수가 있는 문제입니다.]
카카오는 하반기 경력 개발자 공개채용을 진행 중에 있으며 현재 지원서 접수와 코딩테스트가 종료되었습니다. 이번 채용에서 지원자는 지원서 작성 시 아래와 같이 4가지 항목을 반드시 선택하도록 하였습니다.
- 코딩테스트 참여 개발언어 항목에 cpp, java, python 중 하나를 선택해야 합니다.
- 지원 직군 항목에 backend와 frontend 중 하나를 선택해야 합니다.
- 지원 경력구분 항목에 junior와 senior 중 하나를 선택해야 합니다.
- 선호하는 소울푸드로 chicken과 pizza 중 하나를 선택해야 합니다.
인재영입팀에 근무하고 있는 니니즈는 코딩테스트 결과를 분석하여 채용에 참여한 개발팀들에 제공하기 위해 지원자들의 지원 조건을 선택하면 해당 조건에 맞는 지원자가 몇 명인 지 쉽게 알 수 있는 도구를 만들고 있습니다.
예를 들어, 개발팀에서 궁금해하는 문의사항은 다음과 같은 형태가 될 수 있습니다.
코딩테스트에 java로 참여했으며, backend 직군을 선택했고, junior 경력이면서, 소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 50점 이상 받은 지원자는 몇 명인가?
물론 이 외에도 각 개발팀의 상황에 따라 아래와 같이 다양한 형태의 문의가 있을 수 있습니다.
- 코딩테스트에 python으로 참여했으며, frontend 직군을 선택했고, senior 경력이면서, 소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
- 코딩테스트에 cpp로 참여했으며, senior 경력이면서, 소울푸드로 pizza를 선택한 사람 중 코딩테스트 점수를 100점 이상 받은 사람은 모두 몇 명인가?
- backend 직군을 선택했고, senior 경력이면서 코딩테스트 점수를 200점 이상 받은 사람은 모두 몇 명인가?
- 소울푸드로 chicken을 선택한 사람 중 코딩테스트 점수를 250점 이상 받은 사람은 모두 몇 명인가?
- 코딩테스트 점수를 150점 이상 받은 사람은 모두 몇 명인가?
즉, 개발팀에서 궁금해하는 내용은 다음과 같은 형태를 갖습니다.
- [조건]을 만족하는 사람 중 코딩테스트 점수를 X점 이상 받은 사람은 모두 몇 명인가?
[문제]
지원자가 지원서에 입력한 4가지의 정보와 획득한 코딩테스트 점수를 하나의 문자열로 구성한 값의 배열 info, 개발팀이 궁금해하는 문의조건이 문자열 형태로 담긴 배열 query가 매개변수로 주어질 때,
각 문의조건에 해당하는 사람들의 숫자를 순서대로 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
제한 사항
- info 배열의 크기는 1 이상 50,000 이하입니다.
- info 배열 각 원소의 값은 지원자가 지원서에 입력한 4가지 값과 코딩테스트 점수를 합친 "개발언어 직군 경력 소울푸드 점수" 형식입니다.
- 개발언어는 cpp, java, python 중 하나입니다.
- 직군은 backend, frontend 중 하나입니다.
- 경력은 junior, senior 중 하나입니다.
- 소울푸드는 chicken, pizza 중 하나입니다.
- 점수는 코딩테스트 점수를 의미하며, 1 이상 100,000 이하인 자연수입니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- query 배열의 크기는 1 이상 100,000 이하입니다.
- query의 각 문자열은 "[조건] X" 형식입니다.
- [조건]은 "개발언어 and 직군 and 경력 and 소울푸드" 형식의 문자열입니다.
- 언어는 cpp, java, python, - 중 하나입니다.
- 직군은 backend, frontend, - 중 하나입니다.
- 경력은 junior, senior, - 중 하나입니다.
- 소울푸드는 chicken, pizza, - 중 하나입니다.
- '-' 표시는 해당 조건을 고려하지 않겠다는 의미입니다.
- X는 코딩테스트 점수를 의미하며 조건을 만족하는 사람 중 X점 이상 받은 사람은 모두 몇 명인 지를 의미합니다.
- 각 단어는 공백문자(스페이스 바) 하나로 구분되어 있습니다.
- 예를 들면, "cpp and - and senior and pizza 500"은 "cpp로 코딩테스트를 봤으며, 경력은 senior 이면서 소울푸드로 pizza를 선택한 지원자 중 코딩테스트 점수를 500점 이상 받은 사람은 모두 몇 명인가?"를 의미합니다.
- 키워드
- 저장 -> 정렬 -> 탐색 과정을 거치도록 로직을 짜보자.
2. 풀이
처음에 이 문제를 딱 봤을 때는 dictionary를 써야겠다는 생각이 들었고,
역시 다들 그렇게 푸는 거 같았다.
문제는 그렇게 풀었더니 효율성 부분에서 시간초과가 일어났다.
어떤 부분이 잘못 된건지 생각하고 있었는데
아무래도 탐색 부분에서 시간을 많이 잡아 먹는 경우인 거 같다.
탐색을 그냥 순차가 아닌 이진탐색을 바꿔줬더니 통과가 되었다.
로직은 총 3단계이다.
1. 저장
dict 혹은 Map에 저장할 key값으로 언어+분야+경력+음식 문자열을 만든다.
ex) "java" + "backend" + "senior" + "pizza" -> javabackendseniorpizza
이것이 하나의 key값이고, 한 가지의 정보에서 총 16가지의 key값이 나온다.
'-' 역시 포함이 되어야 하기 때문에
javabackendseniorpizza
javabackendsenior-
javabackend-pizza
javabackend--
java-seniorpizza
java-senior-
java--pizza
java---
-backendseniorpizza
-backendsenior-
-backend-pizza
-backend--
--seniorpizza
--senior-
---pizza
----
총 16가지의 경우의 수에 key값을 만들어주고 점수를 저장한다.
이 때 dfs를 활용하면 된다.
2. 정렬
우리는 탐색에서 시간을 줄여야 한다.
최악의 경우에 50,000*100,000을 하게 될 수도 있기때문이다.
그렇기에 탐색에서 이진탐색을 활용하기 위해 각 저장된 리스트를 정렬하도록 하자.
3. 탐색
모든 지원자의 정보가 dict 혹은 Map에 저장되었다.
query에서 split을 통해 각 조건을 선택해 key값을 만들고
기준 점수를 이용해 이진탐색을 하도록 한다.
만약 key값이 존재하지 않는다면 0을 return하고
그게 아니라면 값을 찾으면 된다.
3. 소스코드
# python
dic = dict()
def saveInfo(info, depth, data):
if depth == 4:
if data not in dic:
dic[data] = []
dic[data].append(int(info[4]))
else:
saveInfo(info,depth+1,data+info[depth])
saveInfo(info,depth+1,data+"-")
def sortInfo():
for value in dic.values():
value.sort()
def getResult(query):
getKey = query[0] + query[2] + query[4] + query[6]
score = int(query[7])
if getKey not in dic:
return 0
left,right = 0,len(dic[getKey])-1
mid = (left+right) // 2
while left<=right:
mid = (left+right) // 2
if dic[getKey][mid] < score:
left = mid+1
else:
right = mid-1
return len(dic[getKey])-left
def solution(info,query):
answer = []
for i in info:
saveInfo(i.split(" "),0,"")
sortInfo()
for q in query:
answer.append(getResult(q.split(" ")))
return answer// java
import java.util.*;
class Solution {
private static Map<String,ArrayList<Integer>> dic;
private static ArrayList<Integer> value;
public void saveInfo(String[] info, int depth, String key){
if(depth == 4){
if(!dic.containsKey(key)) {
value = new ArrayList<>();
value.add(Integer.parseInt(info[4]));
dic.put(key,value);
}else{
dic.get(key).add(Integer.parseInt(info[4]));
}
return;
}else{
saveInfo(info,depth+1,key+"-");
saveInfo(info,depth+1,key+info[depth]);
}
}
public void sortScore(){
List<String> keys = new ArrayList<>(dic.keySet());
for(String key : keys)
Collections.sort(dic.get(key));
}
public int getQueryResult(String[] query){
String getKey = query[0] + query[2] + query[4] + query[6];
if(!dic.containsKey(getKey)) return 0;
List<Integer> scores = dic.get(getKey);
int score = Integer.parseInt(query[7]);
int left=0,right= dic.get(getKey).size()-1;
int mid = (left+right) / 2;
while(left <= right){
mid = (left+right) / 2;
if(scores.get(mid) < score) left = mid+1;
else right = mid-1;
}
return scores.size()-left;
}
public int[] solution(String[] info, String[] query) {
int[] answer = new int[query.length];
dic = new HashMap<>();
for(String s : info) saveInfo(s.split(" "),0,"");
sortScore();
for(int i=0;i<query.length;i++){
String[] q = query[i].split(" ");
answer[i] = getQueryResult(q);
}
return answer;
}
}4. 후기
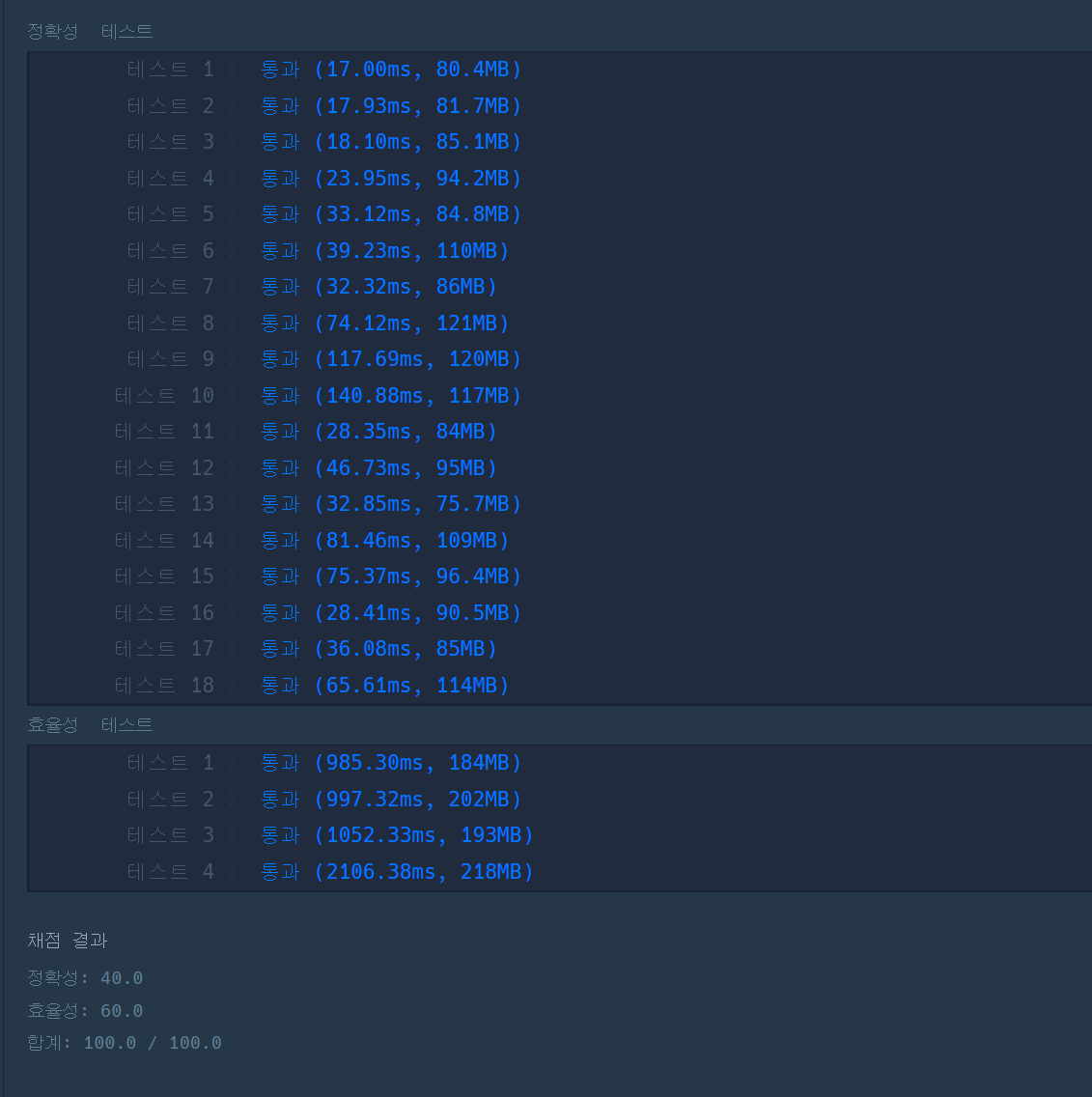
java
python
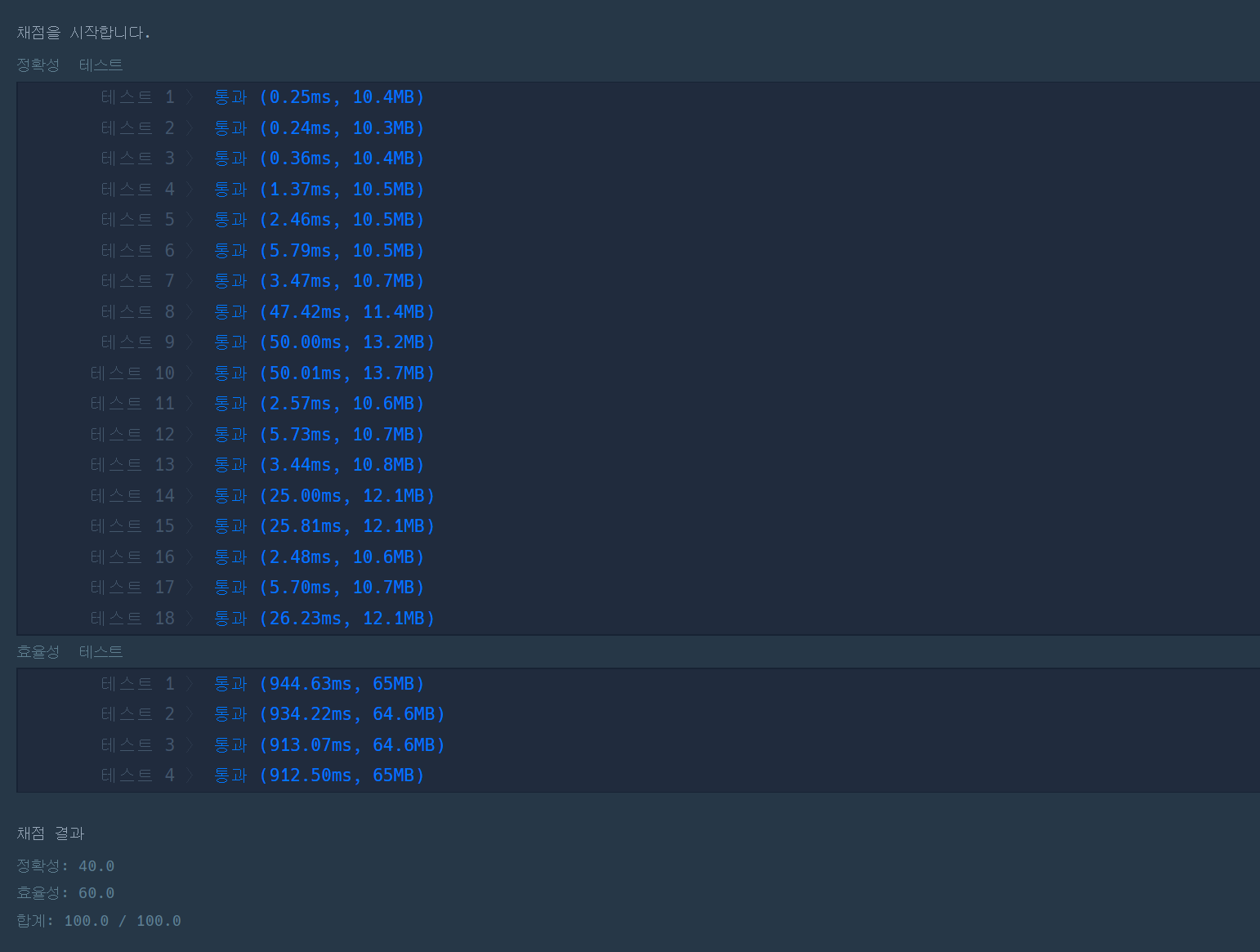
이번 문제는 java로 먼저 풀어보았다.
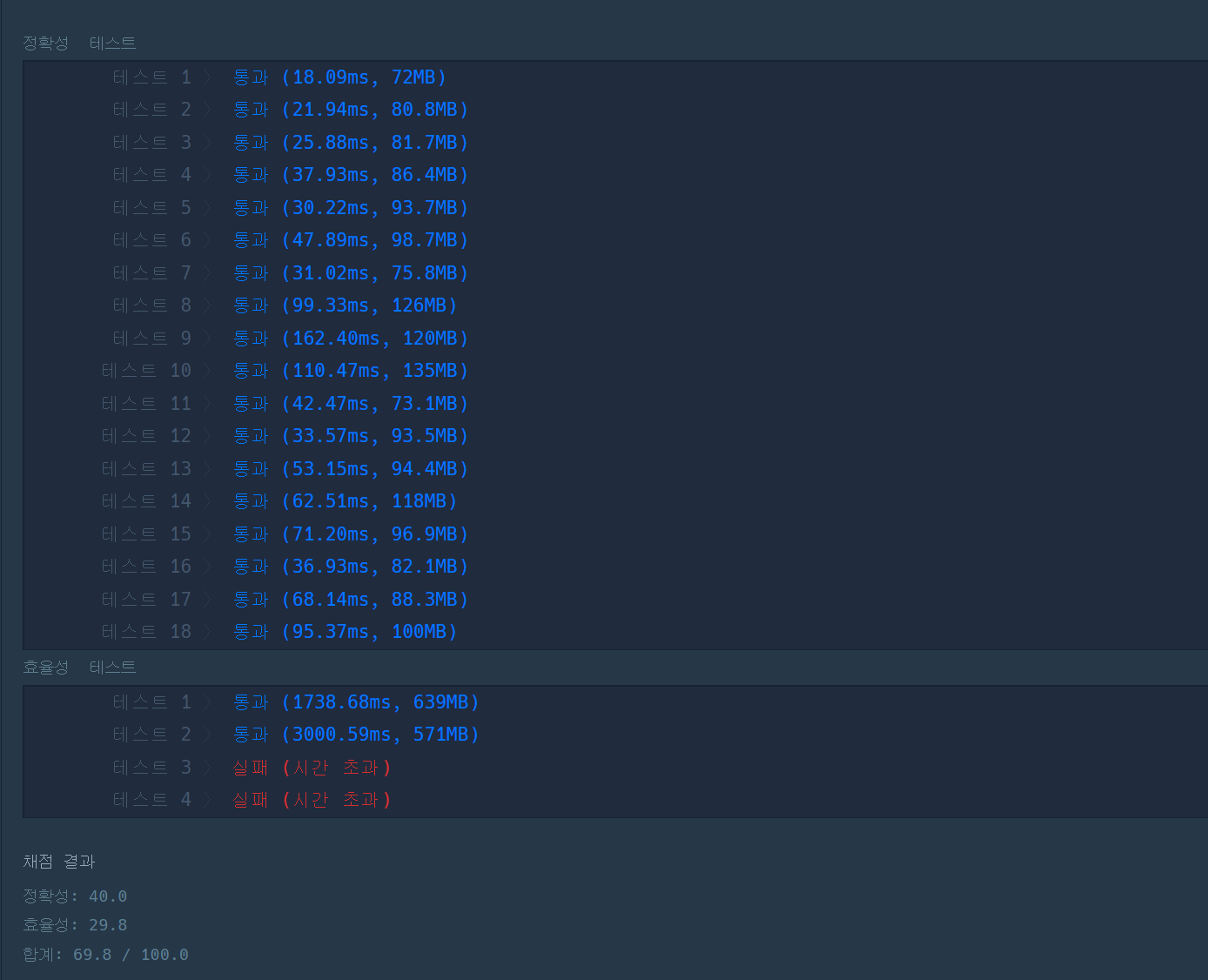
문제는 java로 문제를 푸는데 효율성에서 반정도 오버가 났었다.
이유는 코드의 31번째 줄이다.
public int getQueryResult(String[] query){
String getKey = query[0] + query[2] + query[4] + query[6];
if(!dic.containsKey(getKey)) return 0;
List<Integer> scores = dic.get(getKey); // <<
int score = Integer.parseInt(query[7]);
int left=0,right= dic.get(getKey).size()-1;
int mid = (left+right) / 2;
while(left <= right){
mid = (left+right) / 2;
if(scores.get(mid) < score) left = mid+1;
else right = mid-1;
}
return scores.size()-left;
}정답 코드에는 저렇게 제출했지만, 처음에는 다음과 같이 제출했었다.
public int getQueryResult(String[] query){
String getKey = query[0] + query[2] + query[4] + query[6];
if(!dic.containsKey(getKey)) return 0;
ArrayList<Integer> scores = new ArrayList<>(dic.get(getKey)); // <<
int score = Integer.parseInt(query[7]);
int left=0,right= dic.get(getKey).size()-1;
int mid = (left+right) / 2;
while(left <= right){
mid = (left+right) / 2;
if(scores.get(mid) < score) left = mid+1;
else right = mid-1;
}
return scores.size()-left;
}이 답안을 제출했더니 시간초과가 발생했다.
아무래도 인터페이스에 주입하는데 걸리는 시간과
새로 생성하는 시간차가 무시못할 수준인 것으로 보인다.
이 외에도 List와 ArrayList, LinkedList의 차이점도 찾아보았다.
생성/삭제에는 LinkedList가 빠르고
탐색에는 ArrayList가 빠르다고 한다.
List는 ArrayList로 구현한 인터페이스라고 한다. 기존 Vector를 개선한 것이라고 하며,
Vector보단 이것을 권장한다고 한다.
이외에도 Arrays.sort와 Collections.sort의 차이도 있었다.
처음에는 Arrays.sort로 정렬을 하려고 했지만, 에러가 발생하였다.
이유는 Arrays.sort의 경우
int[], char[], Object[], ... 등등 배열에만 사용이 가능하며,
List<>의 경우 Collections.sort를 이용해야 한다고 한다.
기본형의 경우 Arrays.sort는 퀵정렬을 이용하지만,
참조형의 경우 둘 다 TimSort를 이용한다고 한다.
최근 코딩테스트에서는 아직 Python으로 보고있지만, Java로 바꾸려면 시간이 꽤 많이 필요해 보인다.
사소한 부분에서도 시간차가 많이 나게 되다보니 여러 문제를 경험해 볼 필요가 있어보인다.
Reference
- https://velog.io/@roro/Java-List-ArrayList-LinkedList ( List VS ArrayList VS LinkedList )
- https://codingnojam.tistory.com/38 ( Arrays.sort() VS Collections.sort() )
