데이터베이스 개념
공유 / 저장 / 통합 / 운영 : 공장통운
1. 데이터와 정보
- 공유데이터(Shared Data) : 여러 응용 프로그램들이 공통으로 사용
- 저장데이터(Stored Data) : 저장된
- 통합데이터(Integrated Data) : 중복 최소된 데이터
- 운영데이터(Operational Data) : 조직의 목적을 위해 필요한
2. 데이터베이스의 특징 읽고 넘김
- 실시간 접근성(Real Time Accessibility) : 가용성
- 계속적 변화(Continuous Evolution)
- 동시 공유(Concurrent Sharing)
- 내용에 대한 참조(Content Reference)
- 데이터의 독립성(Independence)
3. 데이터 언어 : DMC
- DDL(Data Definition Language) : 정의
- DML(Data Manipulation Language) : 조작
- DCL(Data Control Language) : 제어
4. 스키마(Schema) : 데이터베이스의 구조/제약조건에 관해 전반적인 명세를 기술한 것 **
4-1. 3계층 스키마
-
외부(External Schema) : 사용자 뷰: 여러화면
- 논리적 스키마
-
개념(Conceptual Schema) : 전체적인 구조와 제약 조건
- 물리적 스키마
-
내부(Internal Schema) : 저장 스키마
4.2 데이터 독립성
-
외부 ~ 논리 ~ 개념 :논리적 독립성:개념스키마가 바뀌어도 외부 스키마에는 영향 없다.
-
개념 ~ 물리 ~ 내부 :물리적 독립성:내부 스키마가 바뀌어도 외부/개념 스키마에는 영향 없다.
데이터베이스 관리 시스템 (Data Base Management System : DBMS)
1. DBMS 정의
- DBMS를 통해서 데이터베이스를 관리하며 응용프로그램들이 데이터베이스를 공유하고 사용할 수 있는 환경 제공
2. DBMS 기능
- 데이터 정의 / 조작 / 제어 (Definition / Manipulation / Control : DMC)
- 데이터 공유 / 보호 / 구축
- 유지보수
3. DMBS 종류
- 계층형(Hierachical Database) : 트리 구조
- 네트워크형(Network Database) : N:N / CODASYL DBTG모델
- 관계형(Relational Database) : 테이블 구조로 단순화 시킨 모델
- 객체지향형(Object-oriented Database) : 객체지향 프로그래밍 개념을 기반으로 만듬
- 객체관계형(Object-relational Database)
- NoSQL(Not Only SQL): SQL뿐만 아니라 다양한 특성을 지원
- NewSQL : RDBMS의 SQL과 NoSQL의 장점을 결합한 관계형 모델
데이터베이스 설계
1. 요구조건 분석
- 개념적 설계 : DBMS에 독립적으로 설계 / 데이터베이스의 개념적 스키마 구성(E-R Diagram)
- 논리적 설계 : 목표 DBMS에 맞춰 / 정규화 실행 / Transaction, Interface 설계
- 물리적 설계 : 성능고려 특정DBMS 맞춰서 설계 / Transaction 세부 설계
반정규화(join 횟수 줄이기 위함) ** : 파티션 / 클러스터링 / 인덱스(힌트) / 뷰 해보고 성능 향상 안될경우 진행
데이터 모델링
1. 데이터모델 개념 중요도 하
- 데이터모델 개념 : 현실세계의 요소를 인간과 컴퓨터가 이해할 수 있는 정보로 표현
2. 데이터모델에 표시해야 할 요소
- 구조 : 개체타입과 개체타입들 간의 관계
- 연산 : 저장될 데이터를 처리하는 방법
- 제약조건 : 데이터의 논리적인 제약조건
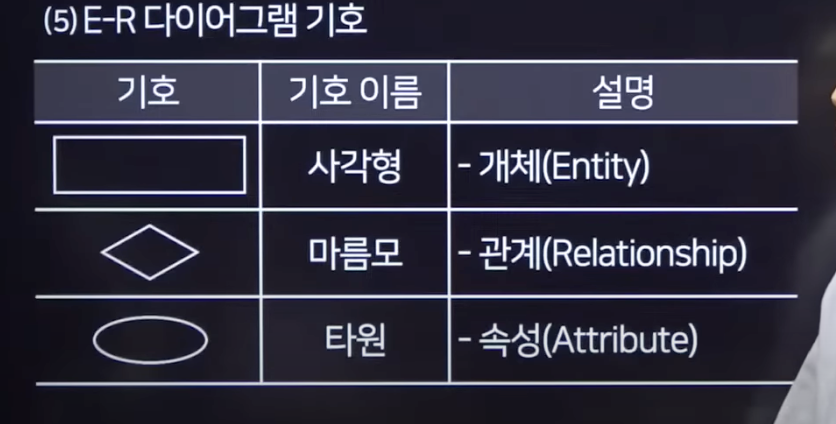
데이터 모델링 : 개체-관계 모델(Entity Relation Model)
- 개체-관계 모델 개념 : 데이터베이스에 대한 요구사항을 그래픽적으로 표현하는 방법
- 개체(Entity) : 현실 세계에서 꼭 필요한 사람이나 사물과 같이 구별되는 모든 것
- 애트리뷰트, 속성(Attribute) : 개체나 관계가 가지고 있는 고유의 특성
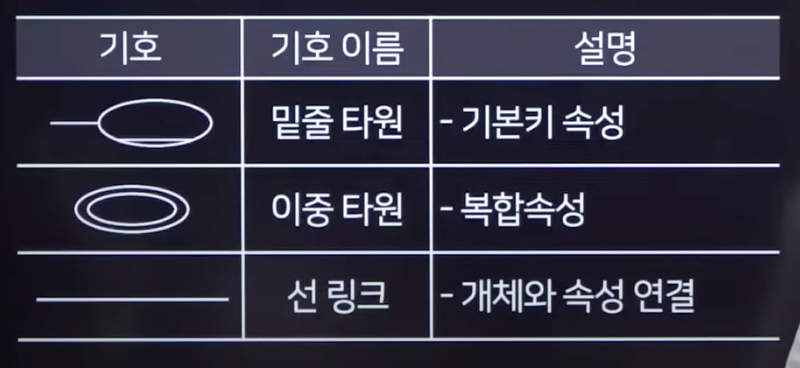
속성 유형:- 단일값 속성 : 값을 하나만 가질 수 있는
- 다중값 속성 : 값을 여러개 가질 수 있는
- 단순 속성 : 의미를 더는 분해할 수 없는
- 복합 속성 : 의미를 분해 할 수 있는
- 유도 속성 : 다른 속성의 값에서 유도되어 나온
- 널(Null) 속성 : 아직 결정되지 않은 존재하지 않는
- 키 속성 : 개체를 식별하는데 사용하는
- 관계(Relationship) : 서로 다른 개체가 맺고 있는 의미 있는 연관성
데이터 모델링 : 품질 기준 : 요구사항에 기준
정확성 / 안정성 / 준거성 / 최신성 / 일관성 / 활용성
논리 데이터베이스 설계 : 정규화
-
논리적 모델링 : 개념적 설계에서 추출된 실체와 속성들의 관계를 주고적으로 설계하는 단계
-
정규화(Nomalization) : 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화 / 이상현상을 최소화(삽입/삭제/갱신)
완전함수(Full Functional Dependency) 종속관계: 주민번호(1개에 완전 속함)
부분함수(Partial Functional Dependency) 종속관계: 학번/과목을 알아야 학생의 점수를 조회 가능: 학생의 이름은 학번에만 속함
이행함수(Transitive functional Dependency) 종속관계: X->Y->Z 이면 X->Z ?제1정규화 : 도메인이 원자값만으로 구성
제2정규화 : 부분함수 종속 제거 -> 완전함수 Full Functional Dependency
제3정규화 : 이행함수 종속 제거 -> 완전함수 Full Functional Dependency
BCNF : 모든 결정자가 후보키 집합에 속해야 한다.
제4정규화 : 다치종속 제거
제5정규화 : 조인종속 제거-반정규화() : 시스템의 성능향상과 개발 편의성 등을 위해 정규화에 위배되는 중복을 허용하는 기법
적용순서 : 반정규화 대상 조사 -> 다른방법으로 유도(파티셔닝/ 클러스터링 / 인덱스(힌트) / 뷰) -> 반정규화 수행 (테이블/속성/관계)다른방법
-
지나치게 많은 조인이 걸려 데이터 조회하는 작업이 기술적으로 어려운 경우
뷰(성능향상시키지 않음) -
대량의 데이터처리나 부분처리에 의해 성능저하되는 경우
인덱스 조정 : 인덱스를 통해 성능을 충분히 확보할 수 있다면 인덱스를 조정하여 반정규화를 회피
클러스터링(조회에 적합) : 인덱스를 통해 성능향상이 불가능할 경우 대량의 데이터를 특정 클러스터링 팩터에 의해 저장방식을 다르게 함.데이터를 입력/수정/삭제하는 경우 성능이 많이 저하 -
대량의 데이터는 Primary Key의 성격에 따라 부분적인 테이블로 분리 가능
파티셔닝 : 성능저하 방지 / 인위적인 테이블의 통합/분리하지 않고 물리적인 저장기법에 따라 성능을 향상 : 데이터가 특정 기준(파티셔닝 키)에 의해 다르게 저장되고 파티셔닝 키에 따른 조회가 될 때 성능이 좋아지는 특성 => 특정기준에 의해 물리적 저장공간이 구분되고 트랙잭션이 일정한 기준에 의해 들어온다면 파티셔닝 테이블을 적용하여 조회 성능향상 가능 -
응용 어플리케이션에서 로직을 구사하는 방법을 변경함으로써 성능 향상
응용메모리 영역에 데이터 처리를 위한 캐쉬 / 중간 클래스 영역에 데이터 캐쉬 하여 공유하게 하여 성능 향상
데이터베이스 이중화
1. 이중화 구성
- 장애 발생시 데이터베이스를 보호하기 위해 동일한 데이터베이스를 중복시켜 동시에 갱신하여 관리
fireWall - L4 - WAS 2 - DB A(Active) / DB B(Standby)- WAS 1
- WAS 3 정보보안 3요소 : 기밀성 / 무결성 / 가용성
2.이중화의 분류
- Eager 기법: 변경 발생 즉시 반영
- Lazy 기법: 트랜잭션 완료 후 반영
3.이중화의 종류
- Active-Active
- Active-StandBy(hot, warm, cold)
데이터베이스 백업
1. 개념
- 중단 사태에 대비 / 복구 진행할 수 있게 데이터를 주기적으로 복사
2.방식
- 전체백업 : Data 모두
- 증분백업 : 변경/추가된 Data만 백업
- 차등백업 : 변경/추가된 Data를 모두 포함하여 백업
- 실시간백업 : 즉시 백업
- 트랜잭션 로그 백업: 모든 SQL문을 기록한 로그
- 합성백업 : 전체 백업본과 여러개의 증분 백업
3.복구 시간/시점 목표
- 복구 시간 목표 RTC : 서비스 중단 시점과 서비스 복원 시점 간에 허용되는 최대 지연 시간
- 복구 시점 목표 RPO : 마지막 복구 시점과 서비스 중단 시점 간에 허용되는 데이터 손실량
4.데이터베이스 암호화
- API : 어플리케이션에서 암/복호화 수행
- Plug-in : 제품을 설치하여 암/복호화 수행(고가) :DBMS에 설치
- TDE(Transparent Data Encryption) : DBMS 내장 모듈을 이용하여 암/복호화
데이터베이스 물리속성 설계 :: 파티셔닝 :성능고려
1.개념 : (하나의 Disk)
- 데이터베이스를 여러부분으로 분할하는 것
2.샤딩(Sharding) : (여러개 Disk 분산저장)
- 하나의 거대한 데이터베이스나 네트워크 시스템을 여러 개의 작은 조각으로 나누어 분산 저장/관리
3.분할기준
- 범위 분할(Range Partitioning)
- 목록 분할(List)
- 해시 분할(Hash) : 단방향
역상 저항성 : 복호화X (레인보우 테이블 이용하여 가능)
제2역상 저항성 : X를 암호화해서 값 Z가 만들어짐 => X는 Y를 암호화 했을때 Z가 나오는것을 알면 안된다. => x->z는 알고있지만 Y->z를 알면안된다. 어떤 값을 암호화 했을때 같은값이 나온다를 알면 안된다.
충돌 저항성 : X,Y를 각각 암호화 했을때 같은 값 Z가 나온다를 알면 안된다. - 라운드 로빈 분할(Round Robin)
- 합성 분할(Composite)
데이터베이스 물리속성 설계 :: 클러스터링 :성능고려
1.개념
- 디스크로부터 데이터를 읽어오는 시간을 줄이기 위해 데이터를 디스크의 같은위치에 저장하는 방법
데이터베이스 물리속성 설계 :: 인덱스 :성능고려
1.개념
- 추가적인 저장 공간을 활용하여 데이터베이스 테이블의 검색속도를 향상시키기 위한 자료구조
2.종류
-
클러스터 인덱스: 테이블당 1개 : 해당컬럼 기준으로 테이블일 물리적으로 정렬
클러스터 인덱스 테이블 --- 주문테이블
-
넌클러스터 인덱스: 레코드 원본은 정렬되지 않음 인덱스 페이지/테이블만 정렬 / 테이블당 약 240개 만들수 있음.
넌클러스터 인덱스 테이블 1
넌클러스터 인덱스 테이블 2 --- 주문테이블
넌클러스터 인덱스 테이블 3힌트를 줘서 넌클러스터 인덱스 테이블 2가 가장 효율적으로 조회가능함을 알려준다. -
밀집 인덱스: 데이터 레코드 각각에 대해 하나의 인덱스 생성
-
희소 인덱스: 레코드 그룹 또는 데이터 블록에 대해 하나의 인덱스
3.구조
- 트리기반 : B+트리 인덱스를 주로 사용
- 비트맵 기반 : 비트를 이용하여 컬럼값을 저장하고 이용
- 함수 기반 : 함수나 수식 결과 이용
- 비트맵 조인 : 물리적인 구조는 비트맵 인덱스와 동일
- 도메인 인덱스 : 개발자가 자신이 원하는 인덱스 타입을 생성
데이터베이스 물리속성 설계 :: 뷰 :성능고려
1.개념
- 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블
- 외부스키마
2.특징
- 외부 스키마
외부스키마
논리적 독립성 : 테이블로 부터
개념스키마
물리적 독립성 : 테이블 속성/컬럼으로 부터
내부스키마 - 논리적 데이터 독립성 제공
- ALTER VIEW문을 사용할 수 없음
- 뷰로 구성된 내용에 대한 삽입,삭제,갱신 연산에 제약
데이터베이스 : 시스템 카탈로그: 시스템에의해 생성 / 유지 / 관리
-
시스템 테이블 :
-
데이터베이스에 저장되어 있는 모든 개체들에 대한 정의에 대한 정보가 수록
-
데이터 사전(Data Dictionary)
-
사용자가 SQL문을 이용하여 내용을 검색할 수 있음, 수정 안됨
File Descriptor : 운영체제가 파일 관리위한 정보를 가짐
PCB(Process Control Block) : 운영체제가 프로세스 관리를 위함 => PCB를 사용하여 문맥교환(Context Swtitching) 실행
관계 데이터베이스 모델 : 논리적 구조 => 물리적 구조(릴레이션/테이블)
1.개념
- 데이터의 논리적 구조가 릴레이션/테이블 형태의 평면파일로 표현되는 데이터모델
2.구조
- 속성: Attribute / 컬럼
- 디그리: Degree / 차수 / 속성의 개수 = 컬럼의 개수
- 튜플 : Tuple / 로우 / 레코드
- 커디널리티: Cardinality / 튜플의 개수 = 로우의 개수
- 도메인 : 컬럼의 제약조건 e.g. 성별 : '남' or '여' 만 저장
3.릴레이션
- 구성
- 릴레이션 스키마 : 릴레이션 이름과 모든 속성의 이름으로 정의하는 논리적인 구조
- 릴레이션 인스턴스 : 릴레이션 스키마에 실제로 저장된 데이터의 집합
- 특징
- 튜플의 유일성 : 릴레이션 안에는 똑같은 튜플이 존재할 수 없음
- 튜플의 무순서성 : 튜플 사이에는 순서가 없음
- 속성의 무순서성 : 속성 사이에는 순서가 없음
- 속성의 원자성 : 속성은 더이상 분해할 수 없는 원자값을 가진다.
- 튜플의 삽입,갱신,삭제 작업이 실시간 반영 => 릴레이션 수시 변경
관계 데이터베이스 모델 :: 관계데이터 언어 : 관계대수
관계대수 : 절차적
관계해석 : 비절차적
1.개념
- 원하는 데이터를 얻기 위해 데이터를 어떻게 찾는지에 대한 처리과정을 명시하는 절차적 언어
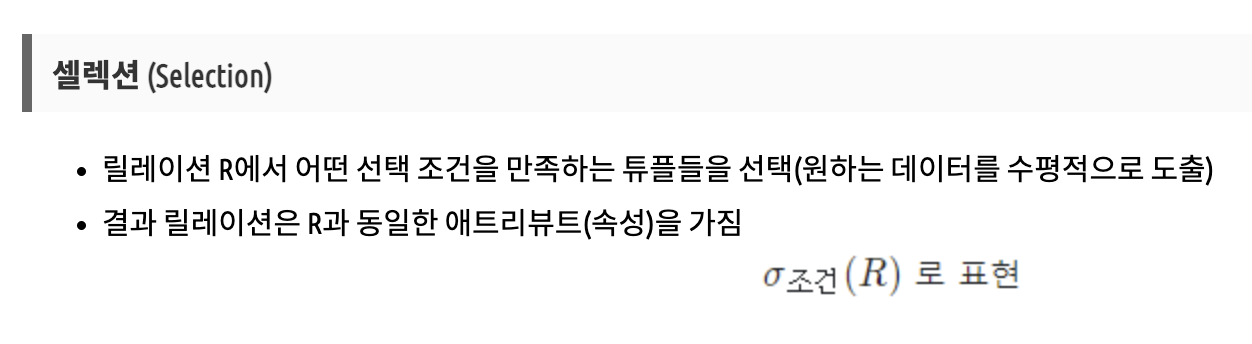
2.순수관계 연산자


실렉트 Select
시그마<조건=>(테이블명)
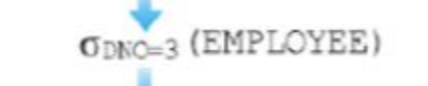
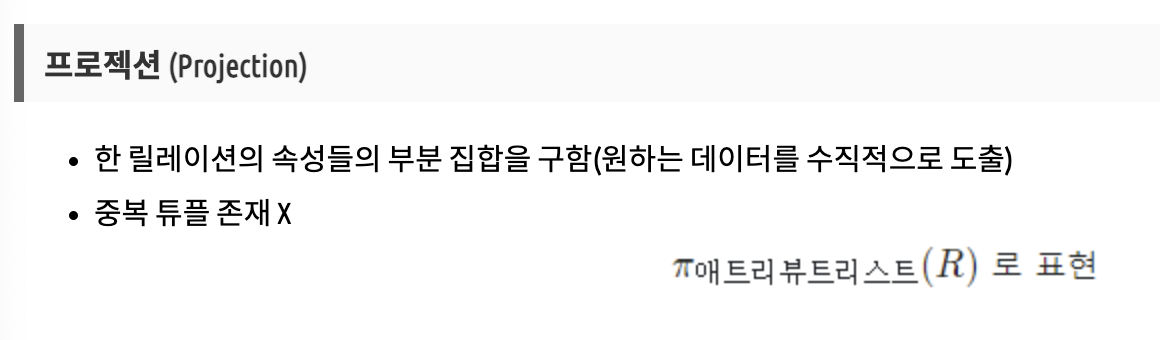
프로젝트 Project
파이<컬럼명>(테이블명)
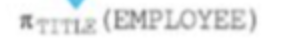
조인 Join
(테이블명)보타이<조건>(조인할 테이블명)
디비젼 Division
(테이블명)나누기표(테이블명)
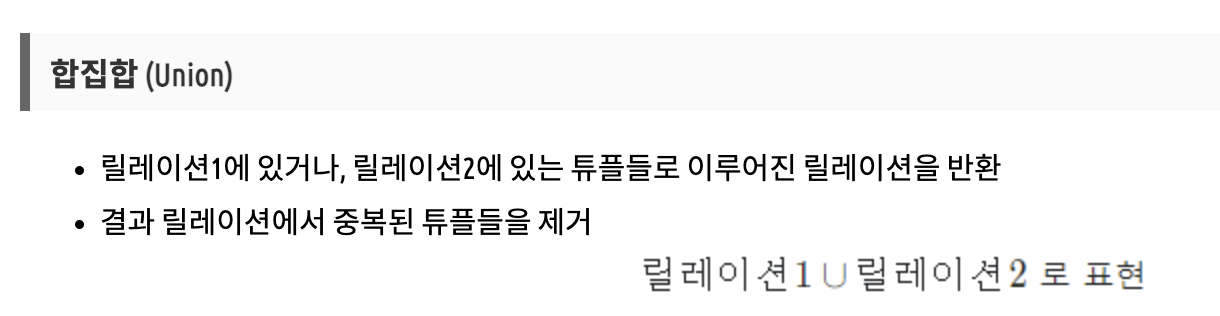
합집합 Union U
교집합 Intersection n

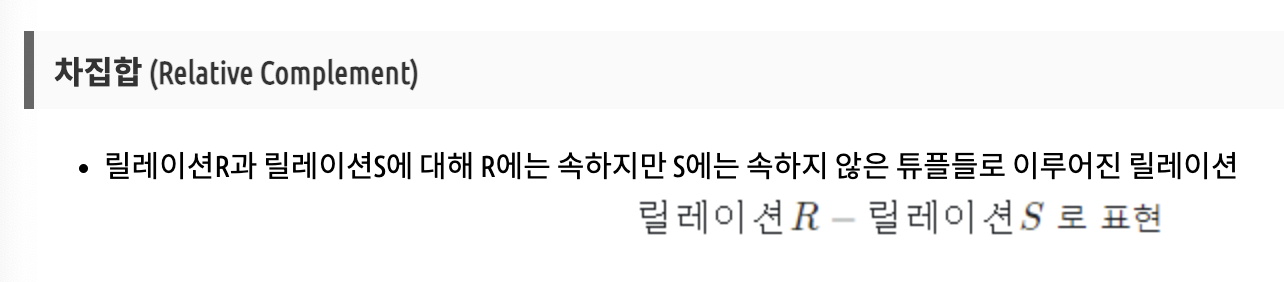
차집합 Relative Complement -
카티션 프로덕트 Cartesian Product X

관계 데이터베이스 모델 :: 관계데이터 언어 : 관계해석
1.개념
- 비절차적 언어
- 관계 데이터 모델의 제안자인 코드가 수학의 Predicate Calculus에 기반을 두고 관계데이터베이스를 위해 제안
- 관계해석은 원하는 정보가 무엇이라는 것만 정의
- 튜플 관계해석과 도메인 관계해석이 있다.
2.연산자
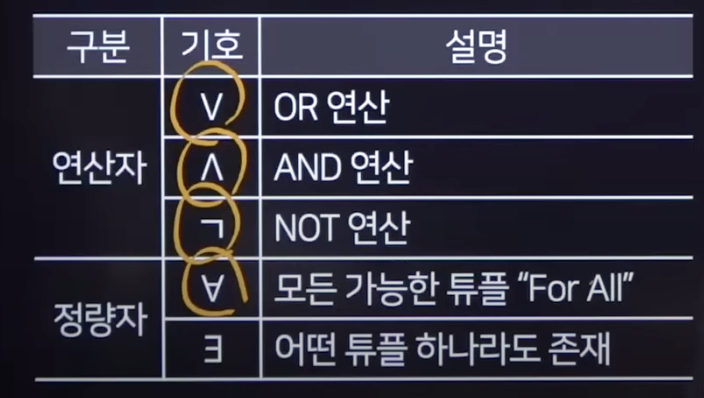
키와 무결성 제약조건 :: Key 키 : 무언가를 식별하는 고유한 식별자 (Identifier)
1.개념
- 릴레이션에서 다른 튜플들과 구별될 수 있는 유일한 기준이 되는 컬럼(속성)
2.키 종류
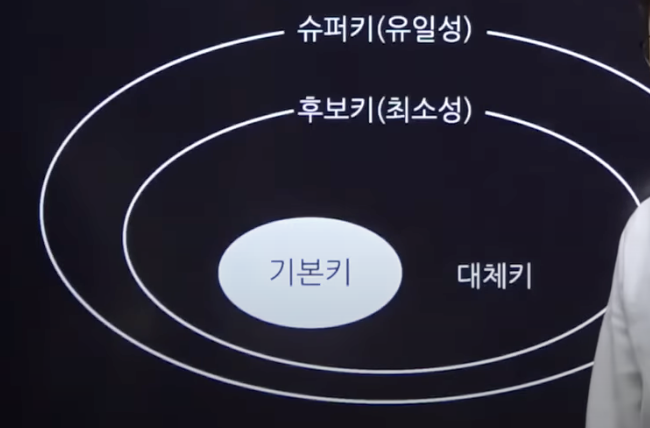
- 슈퍼키 : 유일성 > 후보키를 포함 : 하나를 특정 가능
- 후보키 : 유일성 + 최소성 > 대체키를 포함 : 하나를 특정가능 + 최소한의 속성을 포함
주민등록번호로 충분이 1인을 지목 가능 => 주민등록번호 + 성별 키가 불필요 - 대체키 : 유일성 + 최소성을 가지며 후보키에 속함 > 기본키를 포함
- 기본키 : 유일성 _ 최소성을 가지며 대체키에 속함
유일성 : 하나의 키로 특정 행을 바로 찾아낼 수 있는 고유한 데이터 속성 (주민번호)
키와 무결성 제약조건 :: 무결성
1.개념
- 데이터의 정확성, 일관성, 유효성이 유지되는것
2.종류
무결성을 지키기 위한 개체/참조/도메인
- 개체 무결성(Entity Integrity) : 모든 릴레이션은 기본키(Primary키를 가짐 / 기본키는 중복되지 않는 고유한 값 가짐 / 릴레이션의 기본키는 Null값을 불허
- 참조 무결성(Referential Integrity) : 외래키 값은 Null이거나 참조하는 릴레이션의 기본키값과 동일해야 함 / 각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없음.
제한 Restrict : 참조되는 튜플의 삭제를 제한
연쇄 Cascade : 부모 튜플 삭제시 참조하는 자식의 튜플도 함께 일괄 처리
널값 Nullify : 부모 튜플 삭제시 참조하는 자식의 튜플은 Null로 등록
기본값 Default : 부모 튜플 삭제시 참조하는 자식의 튜플은 DEFAULT값으로 등록 - 도메일 무결성(Domain Integrity) : 속성들의 값은 정의된 도메인에 속한 값이어야 한다.
- 고유 무결성(Unique Integrity) : 릴레이션의 특정 속성에 대해 각 튜플이 갖는 속성값들이 서로 달라야 함 : 핸드폰 번호 등의 중복 값을 불허하는
- 키 무결성(Key Integrity) : 하나의 릴레이션에는 적어도 하나의 키값이 존재
- 릴레이션 무결성(Relation Integrity) : 삽입,삭제,갱신과 같은 연산을 수행하기 전과 후에 대한 상태의 제약
물리데이터 모델 품질 검토 :: SQL : CRUD
스킵
물리데이터 모델 품질 검토 :: SQL : 옵티마이저(Optimizer)
1.개념
- 사용자가 질의한 SQL문에 대해 최적의 실행방법을 결정하는 역할을 수행
2.SQL 처리 흐름
- 구문 분석 단계 : SQL문이 문법에 따라 정상적으로 작성되었는지 분석 / 테이블 유무 체크
- 실행 단계 : 정의된 테이블의 해당데이터 파일로부터 테이블을 읽어서 데이터버퍼 캐시영역에 저장
- 추출 단계 : 데이터버퍼 캐시영역에서 관련 테이블 데이터를 읽어서 사용자가 요청한 클라이언트로 전송
3.옵티마이저 구분
- 규칙 기반(Rule Based Optimizer): 규칙(우선순위)를 가지고 실행 계획 생성(인덱스_힌트 등을 참조)
- 비용 기반(Cost Based Optimizer): 이전 실행결과의 통계정보를 활용하여 실행 계획 생성
물리데이터 모델 품질 검토 :: SQL : 튜닝
1.개념
- SQL문을 최적화하여 빠른시간내에 원하는 결과값을 얻기 위한 작업
2.튜닝 영역
- 데이터베이스 설계 튜닝: 정규화 및 반정규화하여 재설계
- 데이터베이스 환경 튜닝: 메모리나 블록 크기 지정
- SQL 문장 튜닝: 성능 고려하여 SQL문장 작성
3.Row Migration / Row Chainning
- Row Migration: 다른 블록에 데이터를 넣어두고 링크를 남긴다.
- Row Chainning: 두개의 블록에 작성
분산 데이터베이스 : CDN Contents Delivery/Distribution Network
1.정의
- 여러곳으로 분산되어있는 데이터베이스를 하나의 가상 시스템으로 사용할 수 있도록한 데이터베이스
2.구성요소
- 분산 처리기
- 분산 데이터베이스
- 통시 네트워크
3.적용기법
- 테이블 위치 분산
- 테이블 분할 분산
- 테이블 복제 분산
- 테이블 요약 분산
4.분산의 투명성 조건
- 위치 투명성(Location): 실제 위치를 알 필요없이 논리적인 명칭으로 엑세스
- 분할 투명성(Division): 각 단편의 사본이 여러 위치에 저장
- 지역사상 투명성(Local Mapping): 각 지역시스템의 이름과 무관한 이름 사용 가능
- 중복 투명성(Replication): 동일 데이터가 여러곳에 중복되어 있어도 하나처럼 사용가능
- 병행 투명성(Concurrency): 다수의 트랜잭션들이 동시에 실현되더라도 결과는 영향을받지 않음
- 장애 투명성(Failure): 장애에도 불구하고 트랜잭션을 정확하게 처리
분산 데이터베이스 : CAP이론
1.개념
어떤 분산환경에서도 아래 3가지 중 2개만 가질수 있다는 이론
- 일관성(Consistency)
- 가용성(Availability)
- 분단허용성(Partition Tolerance)
분산 데이터베이스 : 트랜잭션
1.개념
- 데이터베이스의 상태를 변환시키는 하나의 논리적인 기능을 수행하는 작업단위
2.트랜잭션의 성질
- 원자성(Atomicity) : 모두 반영되거나 전혀 반영되지 않아야 함.(Commit / Rollback)
- 일관성(Consistency) : 실행을 완료하면 언제나 일관성있는 데이터베이스 상태로 변환
- 독립성/격리성(Isolation) : 하나의 트랜잭션 실행 중에 다른 트랜잭션의 연산이 끼어들 수 없음.
- 영속성(Durability) : 트랜잭션의 결과는 시스템이 고장이 나더라도 영구적으로 반영되어야 함.
3.트랜잭션의 상태
- 활동(Active) : 실행 중인 상태
- 실패(Failed) : 오류가 발생되어 중단상태
- 철회(Aborted) : Rollback 연산을 수행한 상태
- 부분완료(Partially Commited) : Commit 연산이 실행되기 직전의 상태
- 완료(Commited) : Commit 연산을 실행한 후의 상태
SQL (Structured Query Language)
1. 종류
- DDL(Data Definition Language) : CREATE / ALTER / DROP / RENAME / TRUNCATE
- DML(Data Manipulation Language) : SELECT / INSERT / UPDATE /DELETE
- DCL(Data Control Language) : GRANT / REVOKE
- TCL(Transaction Control Language) : COMMIT / ROLLBACK / SAVEPOINT
SQL : 저장 프로시저(Stored Procedure)
1.개념
- 일련의 쿼리를 하나의 함수처럼 실행하기 위한 쿼리의 집합
2.구조
CREATE OR REPLACE PROCEDURE 프로시저명
(변수 1 IN 변수타입, 변수2 IN 변수타입, 변수3 IN OUT 변수타입...)
IS
변수 처리부
BEGIN
처리내용
EXCEPTION
예외처리
END;
SQL : 트리거(Trigger)
1.개념
- 테이블에 대한 이벤트에 반응해서 자동으로 실행되는 작업
2.유형
- 행트리거 : FOR EACH ROW 옵션 사용
- 문장트리거 : INSERT, UPDATE, DELETE문에 대해 단 한번만 실행
3.실행시기
- BEFORE : 테이블 이벤트 전
- AFTER : 테이블 이벤트 후
SQL : 사용자 정의 함수 (프로시져와 비슷)
1.개념
-
파라미터는 입력 파라미터만 가능하고 리턴값이 하나이다.
CREATE OR REPLACE FUNCTION 함수명
(변수 1 IN 변수타입, 변수2 IN 변수타입, 변수3 IN OUT 변수타입...)
RETURN 데이터타입
IS
변수 처리부
BEGIN
처리내용
RETURN 반환값;
EXCEPTION
예외처리
END;
병행제어와 회복 :: 병행제어
1.병행제어를 하지 않았을때
- 갱신 분실(Lost Update): 두개 이상의 트랜잭션이 같은 자료를 공유하여 갱신할 때 갱신 결과의 일부가 없어지는 현상
- 비완료 의존성(Uncommited Dependency): 하나의 트랜잭션 수행이 실패한 후 회복되기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상
- 모순성(Inconsistency): 두개의 트랜잭션이 병행수행될때 원치않는 자료를 이용함으로써 발생되는 문제 / 갱신분실과 보이지만 여러 데이터를 가져올 때 발생하는 문제
- 연쇄 복귀(Cascading Rollback):
2.병행제어 기법
- 로킹 기법(Locking): 트랜잭션이 어떤 데이터에 접근하고자 할때 로킹 수행
로킹단위 크면(범위가 큼) -> 로크수 적음 -> 병행성 낮아짐 -> 오버헤드 감소
로킹단위 작으면(범위가 작음) -> 로크수 많음 -> 병행성 높음 -> 오버헤드 증가 - 2단계 로킹 규약(Two-Phase Locking Protocol)
확장단계 : 새로운 Lock은 가능하고 Unlock은 불가능
축소단계 : Unlock은 가능하고 새로운 Lock은 불가능 - 타임스탬프(Time Stamp): 데이터에 접근하는 시간을 미리 정해서 정해진 시간(Time Stamp)의 순서대로 데이터에 접근하여 수행
- 낙관적 병행제어(Optimistic Concurrency Control): 트랜잭션 수행중에는 어떠한 검사도 하지 않고, 트랜잭션 종료시에 일괄적으로 검사
- 다중 버전 병행제어(Multi-version,Concurrency Control): 여러버전의 타임스탬프를 비교하여 스케쥴상 직렬 가능성이 보장되는 타임스탬프를 선택
병행제어와 회복 :: 회복
1.회복 기법
-
로그기반 회복 기법
지연갱신 회복 기법(Deferred Update): 커밋이 발생하기 전까진 데이터베이스에 기록하지 않음 / 중간에 장애가 생기더라도 데이터베이스에 기록되지 않았으므로 UNDORK 필요없음.(미실행된 로그 폐기)즉시갱신 회복 기법(Immediate Update): 트랜잭션 수행 도중에도 변경내용을 즉시 데이터베이스에 기록 / 커밋 발생 이전의 갱신은 원자성이 보장되지 않는 미완료 갱신이므로 장애발생시 UNDO필요
-
검사점 회복 기법(Checkpoint Recovery): 장애발생 시 검사점(Checkpoint)이전에 처리된 트랜잭션은 회복에서 제외하고 검사점 이후에 처리된 트랜잭션은 회복 작업 수행
-
그림자 회복 기법(Shodow Paging Recovery): 트랜잭션이 실행되는 메모리상의 Current Page Table과 하드디스크의 Shadow Page Table이용
-
미디어 회복 기법(Media Recovery): 디스크와 같은 비휘발성 저장 장치가 손상되는 장애 발생을 대비한 회복기법
-
ARIES 회복 기법(Algorithms for Recovery and Isolatio Exploit Semantics): 분석단계 -> REDO단계 -> UNDO단계
데이터 전환 : ETL(Extraction, Transformation, Loading) :마이그래이션이라 불림
1.개념
- 기존의 원천 시스템에서 데이터를 추출(Extraction)하여 목적 시스템의 데이터베이스에 적합한 형식과 내용으로 변환(Transformation)한 후, 목적 시스템에 적재(Loading)하는 일련의 과정
2.ETL 기능
- 추출(Extraction): 하나 또는 그 이상의 데이터 소스로부터 데이터 획득
- 변환(Transformation): 데이터 클렌징, 형식 변환 및 표준화, 데이터 통합
- 적재(Load): 변형 단계의 처리가 완료된 데이터를 목표 시스템에 적재
