
문제 상황
현재 기존 프로젝트에는 저번 1편에 이은 동시성 문제를 고려하지 않은 조회 업데이트와 조회 업데이트만을 위해서 @Transactional 이 readOnly = false 로 지정되어있다.
한번 개편해보자.
그리고 현재는 DTO 조회로 되어있는데 Entity 조회를 하고 애플리케이션에서 조립을하여서 원하는 포맷으로 보내는 것과 차이가 얼마나 나는지 알아보자(성능이 개선되면 좋은거고 아니면 이유를 찾으면 되는거니깐)
리팩토링이 늘 성공적이라고는 볼 수 없다.
하지만 왜 차이가 나고 어떤 부분에서 나중에 개선을 할 수 있는지 알면 그것이 성공적인 개발자 리팩토링 아닐까
성능 툴은 저번 1편에 이어 Jmeter를 사용하려고한다.
기존 프로젝트 코드
// ItemService
@Transactional
public PreItemInfoViewDto preFindItemInfo(Long itemId, Member member) {
increaseViews(itemId);
List<PreItemInfoResponseDto> itemResponses = itemRepository.preItemResponse(itemId, member);
PreItemInfoResponseDto itemInfoResponseDto = itemResponses.get(0);
Set<String> platforms = new LinkedHashSet<>();
Set<String> urls = new LinkedHashSet<>();
for (PreItemInfoResponseDto itemResponse : itemResponses) {
if (itemResponse.getPlatform() != null && itemResponse.getUrl() != null) {
platforms.add(itemResponse.getPlatform());
urls.add(itemResponse.getUrl());
}
}
itemInfoResponseDto.setUrl(String.join(", ", urls));
itemInfoResponseDto.setPlatform(String.join(", ", platforms));
List<String> filterTags = itemResponses.stream()
.map(PreItemInfoResponseDto::getFilterTag)
.distinct()
.limit(2)
.toList();
itemInfoResponseDto.setFilterTag(filterTags.toString());
PreItemInfoViewDto itemInfoViewDto = new PreItemInfoViewDto(itemInfoResponseDto);
return itemInfoViewDto;
}
// PreItemInfoViewDto
public PreItemInfoViewDto(PreItemInfoResponseDto itemInfoResponseDto) {
this.itemId = itemInfoResponseDto.getItemId();
this.name = itemInfoResponseDto.getName();
this.brand = itemInfoResponseDto.getBrand();
this.description = itemInfoResponseDto.getDescription();
this.price = itemInfoResponseDto.getPrice();
this.imgUrl = itemInfoResponseDto.getImgUrl();
this.views = itemInfoResponseDto.getViews();
this.platforms = new ArrayList<>(Arrays.asList(itemInfoResponseDto.getPlatform().split(", ")));
this.urls = getUrls(itemInfoResponseDto);
this.filterTags = Arrays.asList(itemInfoResponseDto.getFilterTag().split(", "));
this.categoryTag = itemInfoResponseDto.getCategoryTag();
this.isLiked = itemInfoResponseDto.isLiked();
}
public List<String> getFilterTags() {
return filterTags.stream()
.map(tag -> tag.replaceAll("\\[|\\]", "").trim())
.toList();
}
public Map<String, String> getUrls(PreItemInfoResponseDto itemInfoResponseDto) {
Map<String, String> urls = new HashMap<>();
String[] platforms = itemInfoResponseDto.getPlatform().split(", ");
String[] urlsArr = itemInfoResponseDto.getUrl().split(", ");
// 문제부분************
for (int i = 0; i < platforms.length; i++) {
urls.put(platforms[i], urlsArr[i]);
}
return urls;
}
기존 프로젝트는 DTO로 조회를 한뒤 서비스단에서 우리가 최종적으로 원하는 상세페이지 정보를 주게 되어있다.
여기서 일반 보이는 문제점을 찾아보았다.
기존 문제점
- ", " 로 문자를 조립한뒤 다시 Dto에서 분해작업을 한다.
조회 이후 바로 사용을 하게되면 ", " 문자열 들의 사이에만 생기기 때문에 마지막 인덱스 같은 경우 split() 가 되지 않아 인덱스 불일치 문제가 발생하게 된다. => 해당 자료형을 Map 자료형으로 바꾸면 될 것 같다. 만약 중복이 걱정된다면 스트림으로 한번 제거해준다.
또한 현재처럼하면 set의 순서에 따라 섞여 들어갈 수 있다.
-
앞서 말한 @Transactional 문제.
-
repository에서 Dto 조회 시 약간 중복되는 형태가 있다.
- 동일하지만 다르게 조작할 수 있는 방법이 없는 지 찾아보자
외전 문제점은 아니지만 엔티티 조회로 변경하고 싶은 욕구를 알아요???
ㅋㅋㅋㅋㅋㅋㅋㅋ
엔티티로 변환하고 성능 테스트 해볼래요
일단 테스트 데이터는
아이템 1건 -연관되어있는 아이템 필터 5건(중간테이블)-필터 5건
- 연관되어있는 아이템 카테고리 5건(중간테이블) - 카테고리 5건
해당 SQL은 문자열 생성 사이트에서 잘 조작해서 만들었다
http://www.generatedata.com/
나름 괜찮은 사이트인것 같지만 수작업은 어쩔수없다.(유료임)
INSERT INTO item (id,brand,name,description,price,views,img_url,min_age,max_age)
VALUES
(1,'Cassandra Dillard','Jena Guthrie','XPY85CIT2YF',911,0,'Sed nulla ante, iaculis nec,',3,9),
(2,'Violet Robinson','Cairo Meadows','NKR67DLV4RN',205,0,'eu dui. Cum sociis natoque',4,2),
(3,'Jolene Lowe','Herman Marsh','DWT21WBQ8KX',583,0,'vulputate, nisi sem semper erat,',3,7),
(4,'Hyacinth Vaughan','Elliott Sandoval','ZRD15CCL8EN',17,0,'at, nisi. Cum sociis natoque',5,0),
(5,'Miriam Bernard','Molly Aguirre','BVG01RJC9UR',871,0,'Nulla tempor augue ac ipsum.',7,1);
INSERT INTO filter (id,name)
VALUES
(1,'posuere cubilia Curae'),
(2,'sagittis augue, eu'),
(3,'conubia nostra, per'),
(4,'non lorem vitae'),
(5,'cursus et, eros.');
INSERT INTO category (id,name)
VALUES
(1,'sapien. Cras dolor'),
(2,'ligula. Nullam feugiat'),
(3,'Nam nulla magna,'),
(4,'quis, tristique ac,'),
(5,'egestas a, scelerisque');
INSERT INTO item_url (id,item_id,url,platform)
VALUES
(1,1,'In faucibus. Morbi vehicula. Pellentesque','nascetur ridiculus mus.'),
(2,1,'Donec at arcu. Vestibulum ante','fringilla cursus purus.'),
(3,1,'fermentum arcu. Vestibulum ante ipsum','dapibus rutrum, justo.'),
(4,1,'erat volutpat. Nulla dignissim. Maecenas','Aliquam gravida mauris'),
(5,1,'erat. Etiam vestibulum massa rutrum','eget magna. Suspendisse');
INSERT INTO item_category (id,item_id,category_id)
VALUES
(1,1,1),
(2,1,2),
(3,1,3),
(4,1,4),
(5,1,5);
INSERT INTO item_filter (id,item_id,filter_id,name )
VALUES
(1,1,1,'happy'),
(2,1,2,'sad'),
(3,1,3,'soso'),
(4,1,4,'angry'),
(5,1,5,'disgust');그래도 테스트 데이터는 한번 만들어놓으면 해당 연관 엔티티를 사용할때 자주 사용하니깐 하나 만들어 놓는것이 아주 편한것 같다.
그럼 문제점 수정부터 시작
1번
url 과 platform은 모두 ItemUrl 엔티티에 일대다 형태로 붙어있다.

그렇다면 ItemUrl을 굳이 분해야할까...?
set을 사용한 의도인 일단 중복을 제거하면서 한번 해보자

중복된 요소를 가지고 오고 싶지 않으면 조회시에 distinct 옵션을 활용하여 제거하는 것이 나을 듯하다.
이것에 대한 추가 리팩토링은 뒤에서 더 자세하게 적을려고한다. 조회 쿼리 자체를 다르게 접근 할 예정이라.
그래서 한번 리팩토링을 해보자면...
현재 join으로 뻥튀기된 A와 관련된 여러 url를 함께 들고와서 정보는 0번째 인덱스로 써주고
차이가 나는 url, platform 관련 해서 set을 사용한 것 이다.List<PreItemInfoResponseDto> content = queryDslConfig.jpaQueryFactory() .select(Projections.constructor(PreItemInfoResponseDto.class, qItem.id.as("itemId"), qItem.name.as("name"), qItem.brand.as("brand"), qItem.description.as("description"), qItem.price.as("price"), qItem.imgUrl.as("imgUrl"), qItem.views.as("views"), qItemUrl.platform.as("platform"), qItemUrl.url.as("url"), qItemFilter.name.as("filterTag"), qCategory.name.as("categoryTag"), isLiked.as("isLiked"))) .from(qItem) .innerJoin(qItemUrl).on(qItem.id.eq(qItemUrl.item.id)) .innerJoin(qItemCategory).on(qItem.id.eq(qItemCategory.item.id)) .innerJoin(qCategory).on(qItemCategory.category.id.eq(qCategory.id)) .innerJoin(qItemFilter).on(qItem.id.eq(qItemFilter.item.id)) .leftJoin(qItemLike).on(qItem.id.eq(qItemLike.item.id) .and(member != null ? qItemLike.member.id.eq(member.getId()) : null)) .leftJoin(qItemLike.member, qMember) .where(qItem.id.eq(itemId).and(qItemFilter.filter.id.eq(5L)) .and(qItem.id.stringValue().substring(0, 1).eq(qCategory.id.stringValue()))) .fetch();
외전) 내가 만든 Entity로만 조회해서 만든 쿼리들
default_batch_fetch_size를 사용하여 일대다인 컬렉션을 조회했고
또한 그에 연결된 다대일 인 요소들을 직접 fetch join으로 새로 조회했다.
이에 대해서 인터넷을 찾아보니
A(1) <-> B(다) <-> C(1) 로 N:N을 풀어내면 A가 C의 필드를 사용해야한다고하면 적은 필드를 사용하게 될 것이다. name, age 등
그렇게 되면 join 과 Dto로 원하는 항목을 가져오는 방식이 fetch join으로 엔티티 전부를 들고오는 것보단 적은 부하를 일으킬 것이다. 라고 한다.
그렇다 우리는 필드의 하나의 값이 필요한거라 현재처럼 join과 Dto로 우리가 원하는 항목을 핏하게 가져오는 것이다.혹은
- 전략을 hibernate.default_batch_fetch_size를 글로벌 설정으로 사용해 N+1 문제를 최대한 in 쿼리로 기본적인 성능을 보장하게 한다.
- @OneToOne, @ManyToOne과 같이 1 관계의 자식 엔티티에 대해서는 모두 Fetch Join을 적용하여 한방 쿼리를 수행한다.
- @OneToMany, @ManyToMany와 같이 N 관계의 자식 엔티티에 관해서는 가장 데이터가 많은 자식쪽에 Fetch Join을 사용한다.
한번만 사용이 가능한 만큼 제일 큰쪽에 붙여버리는 것이다.
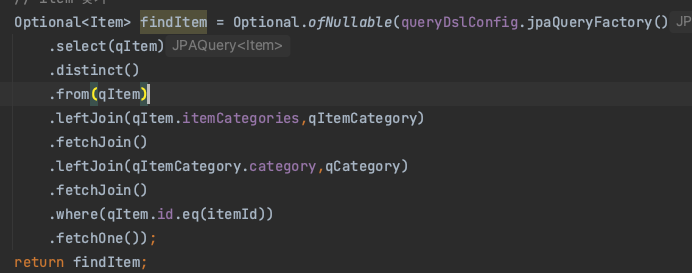
그래서 가장 큰 itemCategory에 붙이고 그 이후는 다대일이니깐 이어주었다.
그리고 나머지 일대다 다대일은 다시 한번 fetchJoin으로 IN절과 함께 조회해주었다.
총 쿼리수는 15개에서 4개까지 줄였다.
하지만 기존의 프로젝트 쿼리는 한방 쿼리
과연 성능 차이는 얼마나 존재할까? 일단 p6spy에서는


크게 차이가 없긴하다... 한번 Jmeter로 확인해보자
1000번 1번 반복
내가 리팩토링한 엔티티 위주의 쿼리의 TPS이다.
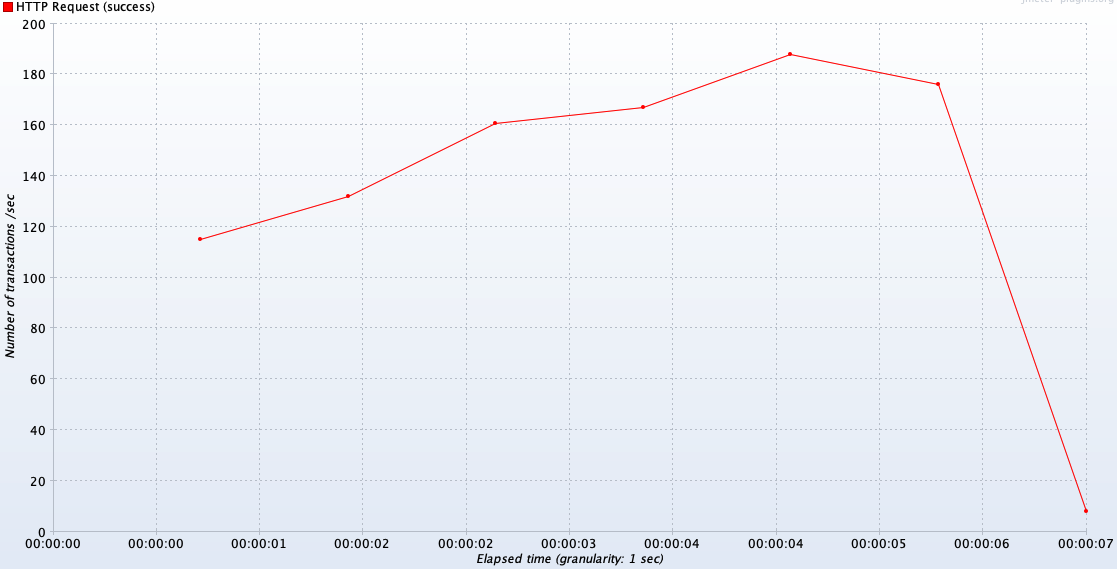
원래 기존의 TPS이다.
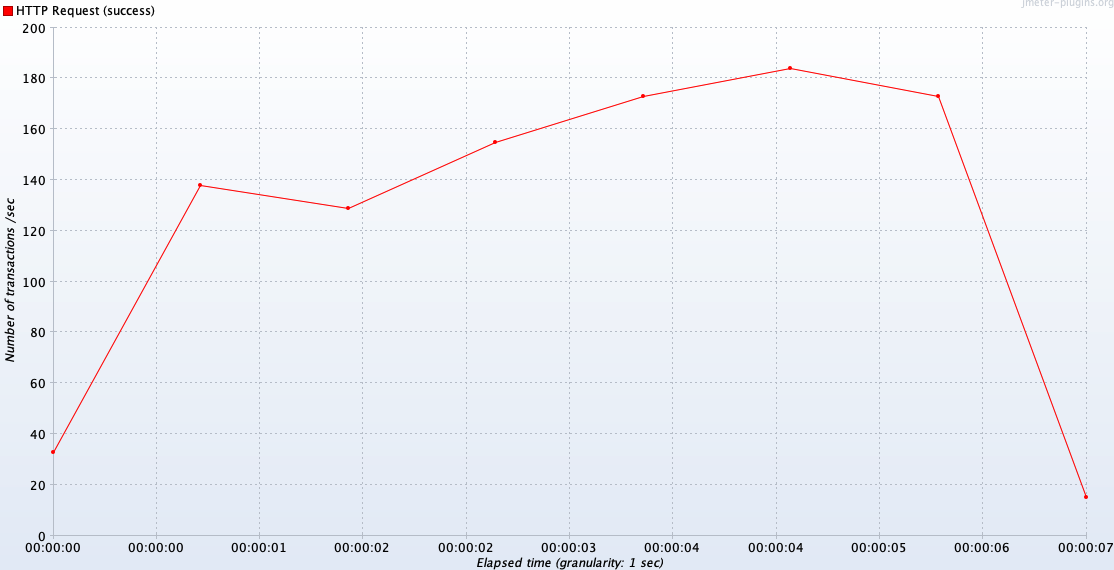
비슷한 양상이다.
TPS는 비슷하지만 리팩토링한 엔티티는 쿼리가 총 4개 , 기존 쿼리는 1개로 쿼리의 네트워크 타는 횟수가 다르다.
하지만 기존 쿼리와 다르게 리팩토링한 엔티티는 조회하는 엔티티와 항목이 명확하게 보여서 여러명이 함께 유지보수하기에 가독성이 좋다.

더 많은 테스트 케이스로 다음에 추후 한번 더 테스트 해봐야겠다.
2번 Transactional
제일 먼저@Transactional(readOnly =true) 작성 후 최상단에 int itemView = this.itemRepository.increaseView(itemId);
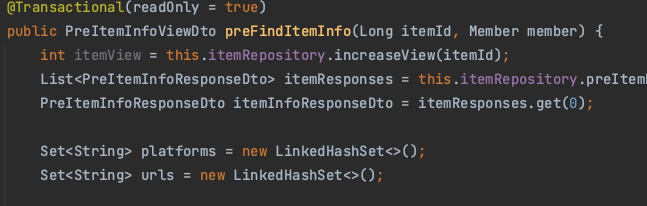
반환은 안받아도되고 미리 업데이트를 해야 해당 받은 유저가 올라간 조회수를 볼 수 있다.
예외처리해야할듯하다.
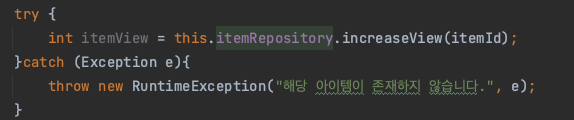
라고 했더니 에러가 나온다.
너 지금 트랜잭션 "readOnly인데 어떻게 업데이트하게?"
미안...

그러면 트랜잭션 전파에 있는 새로운 커넥션을 받아오는
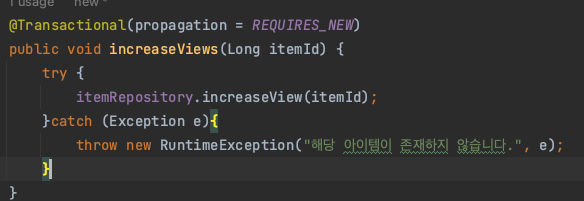
propagation을 REQUIRES_NEW 로 만들어버린다면...?
호호.... 근데 이 방법은 사실 쓰느니만 못하다.
1개의 master 커넥션만으로 처리할 수 있는 작업을 여러개의 커넥션을 이용하게 되기 때문이다.
트래픽이 몰리면 안그래도 커넥션 고갈이 발생할텐데 굳이 이렇게 커넥션을 낭비할 필요는 없다.
순수하게 읽기 기능만 하는 그런 메소드에만 readOnly를 붙여주자.

최종 코드는 itemRepository.increaseView(itemId);만 붙여서 쿼리 하나를 줄였고 동시성 처리도 만족했다.
3번 Dto 조회 다시 작성해보기
비슷한 양상이 나올지도 모르지만 한방쿼리로 작성한 해당 Dto 조회에서 최적화 요소가 없을까보다가 생각났다.
BooleanExpression isLiked = member != null ? new CaseBuilder().when(qItemLike.member.eq(member)).then(true).otherwise(false)
: Expressions.asBoolean(false);해당 문법을
private BooleanExpression memberEq(Member member) {
if (member == null)
return Expressions.asBoolean(false);
else
return qItemLike.member.eq(member);
}로 수정했다. CaseBuilder보단 멤버가 익명이면 바로 False를 반환하는 것이 좋을 듯하여 변경
나머지는 on절을 지운 것 밖에 없어서 각 팀의 컨벤션에 맞게 하면 될 듯하다.
@Override
public List<PreItemInfoResponseDto> preItemResponse(Long itemId, Member member) {
return queryDslConfig.jpaQueryFactory()
.select(Projections.constructor(PreItemInfoResponseDto.class,
qItem.id.as("itemId"), qItem.name.as("name"), qItem.brand.as("brand"),
qItem.description.as("description"), qItem.price.as("price"),
qItem.imgUrl.as("imgUrl"), qItem.views.as("views"),
qItemUrl.platform.as("platform"), qItemUrl.url.as("url"),
qItemFilter.name.as("filterTag"), qCategory.name.as("categoryTag"), memberEq(member).as("itemLike")))
.from(qItem)
.innerJoin(qItem.itemUrls,qItemUrl)
.innerJoin(qItem.itemCategories,qItemCategory )
.innerJoin(qItemCategory.category,qCategory)
.innerJoin(qItem.itemFilters,qItemFilter)
.where(qItem.id.eq(itemId))
.fetch();
}이것도 한방 쿼리 확인했다.
결론
과거의 프로젝트의 보완점을 찾아보고 당시에는 해보지 않았던 성능 테스트와 궁금했던 점을 해소하면서 발전이 생긴것 같다. 또한 동시성 문제는 직접 경험해보지못하면 우리가 클릭하는 것으로는 정상 작동하기때문에 한번씩 동시성 문제에 대해서 깊이 생각하고 코드를 짜야할듯한다.
이렇게 추가로 학습을 하고 여러 자료를 찾아보면서 좋은 인사이트를 얻었는데 그 중 하나를 언급하고 이 글을 마치려고 한다.
null 반환에 대해 안전하게 짜는 다중 쿼리문에 대한 고민을 자바의 특성에 맞게 잘 표현한 식이다.
역시 갓영한

