데이터 엔진이어링
데이터의 종류가 많다.
프로그램 데이터 : 프로그램을 실행 중에만 불러온다.(휘발성)
파일 : 크기가 큰 데이터는 컴퓨터의 성능을 저하시키고 모두 불러오기 때문에 시간이 오래 걸린다.
데이터베이스 : 필요한 정보만 불러올 수 있으며 데이터 간의 관계를 설정하고 구조화 시켜 효율적으로 workflow를 만들 수 있으며 비용을 절감할 수 있다.
git - 다른 사람과 협업할 때 사용하는 데이터 쉐어링 구조이다.
local 컴퓨터에서 작업을 하고 다시 이를 공유할 수 있다.
git init // git 경로를 초기화 한다.
git remote add [이름][repository 경로] //레포지토리를 연결한다.
git add README.md // 올리고 싶음 파일을 add 로 stage 영역에 놓는다.
git status // 지금 git 의 상태를 확인한다.
git commit -m "initial commit" // add 된 파일을 commit 한다. 저장은 아니다.
git branch "new branch name" // 새로운 브런치를 만든다.
git checkout "new branch name" // publish 한다.
git push origin "new branch name" // origin 이라는 repository에 있는 commited 된 파일을 새로운 브런치로 push 한다.
ACID
Transaction
Atomicity : 모든 단계는 실패이거나 성공이여야 한다. 작은 단위
Consistency : 일관성이 있어야 한다.
Isolation : 각 request 들을 따로 수행해야 한다. ex) 수강신청
지속성 : 과거의 데이터를 잊고 최신 데이터를 계속 유지 한다.
이 모든 과정은 정규화를 위해 필요한 속성들이다.
정규화 normalisation
제1정규화 : PK로 구분하여 데이터를 중복 없이 나눈다.
제2정규화 : 2개의 PK로 구분할 때는 테이블을 나눌 수 있다. 테이블을 나눠 더 작은 단위의 데이터를 만들 때 사용하는 정규화 방법이다.
제3정규화 : 기본 키를 제외한 Features 의 속성을 확인한다.
Feature 의 종속성. y와 x가 고정이 되어있다. 예를 들어 모델명. 24GN600은 모델명이기 때문에 이는 항상 LG울트라기어게이밍 모니터 24 인치 모델을 가르킨다. 하지만 제품고유번호는 항상 저 모니터 모델명을 가르키지 않고 모니터 자체에 유일성을 부여한다.
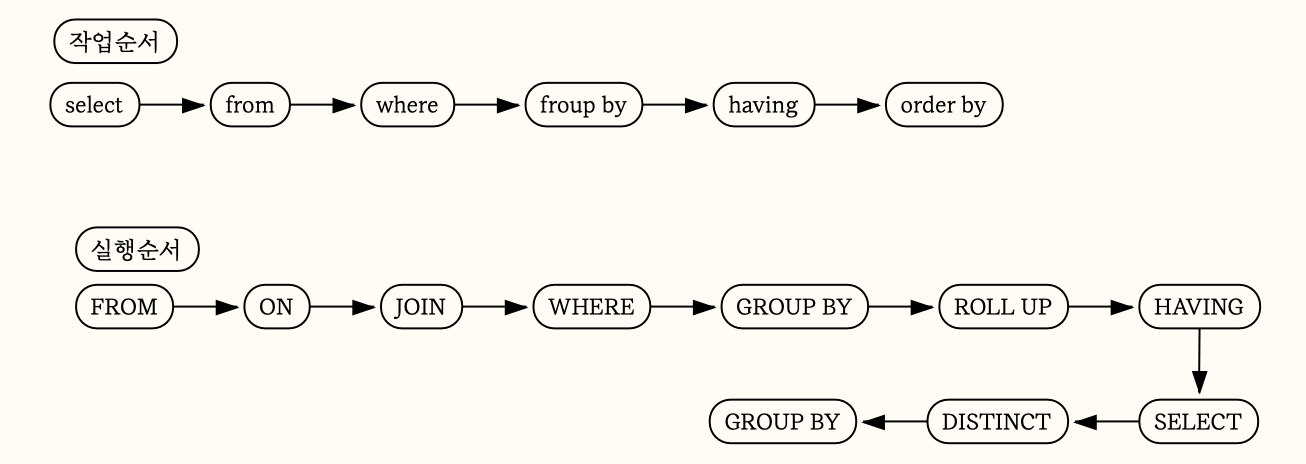
SQL 언어는 엄격한 문법이 존재한다. 이를 잘 따라야 한다.
