모던 자바 인 액션 - 5장
CHAPTER 15 CompletableFuture와 리액티브 프로그래밍 컨셉의 기초
여러 웹서비스에 접근해야하는데, 응답을 기다리는 동안 연산이 블록되거나 CPU 자원을 낭비하지 않고, 비동기적으로 작업을 처리하고 싶다.
CompletableFuture: 비동기 작업 조합의 핵심 도구 → thenCombine, thenCompose 활용
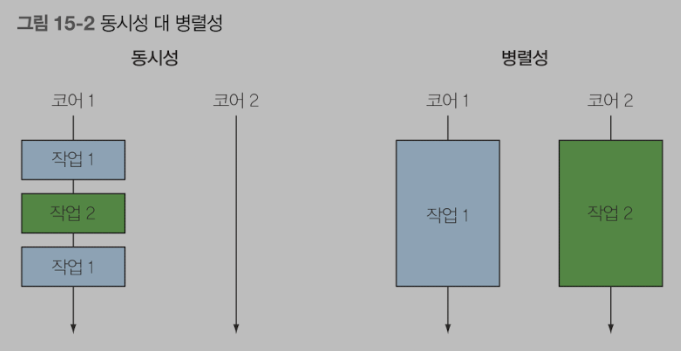
왜 동시성이 중요한가?
- MSA 시대: 서비스는 작아졌지만, 그만큼 네트워크 호출은 많아짐 → 외부 자원을 기다리는 시간이 많아짐.
- 현대 앱 구조: 하나의 독립 앱보다는 여러 소스를 조합하는 Mash-up 형태가 많음.
- 단순히 CPU 병렬성(parallelism)이 아니라, 동시성(concurrency) — 즉, 외부 자원을 기다리며 CPU를 놀리지 않는 구조가 중요함.
앞 장들에서는 포크/조인 프레임워크와 병렬 스트림으로 간단하게 병렬 실행 가능
동시성 기술의 필요성
병렬성이 아니라 동시성을 필요로 하는 상황 = 조금씩 연관된 작업을 같은 CPU에서 동작하는 것 또는 애플리케이션을 생산성을 극대화할 수 있도록 코어를 바쁘게 유지하는 것이 목표라면, 원격 서비스나 데이터베이스 결과를 기다리는 스레드를 볼록함으로 연산 자원을 낭비하는 일은 피해야 한다.
=> Future 인터페이스로 CompletableFuture 구현, 플로 API
- 동시성은 단일 코어 머신에서 발생할 수 있는 프로그래밍 속성으로 실행이 서로 겹칠 수 있는 반면
- 병렬성은 병렬 실행을 하드웨어 수준에 지원한다.
동시성 제어 기법들은 단일 스레드가 여러 작업을 번갈아 처리하는 상황뿐 아니라, 실제로 여러 스레드가 동시에 작업을 처리하는 멀티스레드 환경(즉, 병렬 처리)에서도 똑같이 적용되어 데이터의 일관성과 프로그램의 안정성을 보장
ex) 데이터 불일치, 경쟁 조건(race 컨디션), 데드락 같은 문제를 해결하는 기법
동시성을 구현하는 자바 지원의 진화
- 스레드, 고수준 추상화, 스레드 풀, Futures
자바 동시성 지원의 진화 과정
자바의 동시성 프로그래밍 지원은 하드웨어 발전(멀티코어 CPU 등)과 프로그래밍 패러다임 변화에 맞춰 단계적으로 발전해왔습니다. 주요 단계를 시대별로 정리하면 다음과 같습니다:
1. 초기 : Thread & Runnable (JDK 1.x)
new Thread(() -> System.out.println("실행")).start();- 기본적인 스레드 생성/관리 기능 제공
- 한계: 직접 스레드 생성/관리 필요 → 복잡성 증가, 자원 낭비
- 직접 스레드를 만들고, 직접 실행
2. ExecutorService + Future (Java 5)
ExecutorService executor = Executors.newFixedThreadPool(4);
Future<Integer> future = executor.submit(() -> 42);
Integer result = future.get(); // 블로킹 호출- ExecutorService 도입
- 스레드 풀 도입 → 태스크 제출과 실행을 분리:
executor.submit(task)
- 작업(태스크)을 실행하는 '방법'과 '시점'을 개발자가 직접 관리하지 않고, 작업을 단순히 제출만 하면 실제 실행은 ExecutorService(즉, 스레드 풀)가 알아서 처리하도록 맡기는 구조 - 스레드 풀 관리 자동화
- 스레드 풀 도입 → 태스크 제출과 실행을 분리:
- Callable & Future
- 결과 반환 가능한 비동기 작업 처리
- Future로 비동기 결과 조회 가능하지만 여전히
get()호출 시 블로킹
3. Fork/Join 프레임워크 (Java 7)
class SumTask extends RecursiveTask<Long> {
protected Long compute() {
// 작업 분할 및 병합 로직
}
}- RecursiveTask : 분할-정복 알고리즘 지원
- 장점: 작업 도둑질(work-stealing) 알고리즘으로 멀티코어 활용 최적화
- vs ExecutorService : 모든 스레드가 중앙 큐에서 작업 가져옴
- Fork/Join 프레임워크 : 각 스레드가 전용 Deque(덱) 보유
- 불규칙한 작업 크기 분포의 경우 더 낫다.
- Fork/Join 프레임워크 : 각 스레드가 전용 Deque(덱) 보유
4. CompletableFuture & 병렬 스트림 (Java 8, 2014)
- 병렬 스트림
list.parallelStream().map(...).collect(...); // 간단한 병렬 처리 - CompletableFuture : 비동기 작업 체이닝 및 조합 가능
CompletableFuture.supplyAsync(() -> "데이터") .thenApplyAsync(s -> s + " 처리") .thenAccept(System.out::println); // 논블로킹[3]
5.Flow API (Java 9, 2017) - 리액티브 스트림 지원
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
publisher.subscribe(new Subscriber<>() { ... });- Flow API : 발행-구독 모델 구현(Pub/Sub)
- 의의: 역압력(백프레셔(backpressure)) 지원으로 과부하 방지
✅ 1. 추상화 수준
| 도구 | 추상화 수준 | 관리 방식 |
|---|---|---|
| Thread/Runnable | Low-Level | 직접 스레드 생성/관리 |
| ExecutorService | Mid-Level | 스레드 풀 자동 관리 |
| Fork/Join | High-Level | 작업 분할 자동화 |
| CompletableFuture | High-Level | 스레드 풀 + 비동기 파이프라인 |
| Flow API (Reactive Streams) | Very High-Level | 비동기 데이터 흐름 자동 관리 (Backpressure 포함) |
✅ 2. 주요 사용 사례
| 도구 | 적합한 작업 유형 | 최적화 포인트 |
|---|---|---|
| Thread/Runnable | 간단한 단일 작업 | - |
| ExecutorService | 독립적이고 균일한 다수 작업 | 스레드 재사용 |
| Fork/Join | 재귀적 분할 가능한 대규모 작업 | 작업 도둑질 (Work-Stealing) |
| CompletableFuture | 의존 관계가 있는 비동기 작업 | 체이닝(thenX), 예외 처리 |
| Flow API (Reactive Streams) | 데이터 스트림 처리 (무한/이벤트 기반) | Backpressure, 연산자 기반 조합 |
✅ 3. 선택 가이드
| 상황 | 추천 도구 | 이유 |
|---|---|---|
| 간단한 비동기 작업 | ExecutorService | 사용 편의성 |
| 균등한 작업 + 성능 중요 | ThreadPoolExecutor | 객체 생성 오버헤드 최소화 |
| 재귀적 분할 작업 | Fork/Join | Work-Stealing 최적화 |
| I/O 집중 작업 | ExecutorService | 블로킹 대응에 유리 |
| 의존 관계 있는 비동기 연쇄 작업 | CompletableFuture | 직관적 체이닝 + 예외 처리 지원 |
| 데이터 스트림 + 반응형 UI/서버 | Flow API (Reactor, RxJava 등) | 이벤트 기반 설계 최적화, backpressure 대응 |
진화의 핵심 방향
- 추상화 수준 향상 (스레드 사용 패턴을 추상화)
저수준 스레드 관리 → 고수준 API(ExecutorService, Stream 등) - 하드웨어 활용 최적화
멀티코어 CPU 효율적 사용(Fork/Join, 병렬 스트림) - 비동기 프로그래밍 강화
Future → CompletableFuture → Flow로 점진적 개선 - 함수형 패러다임 통합
람다/스트림과의 시너지 효과
"동시성 처리는 이제 라이브러리 수준에서 추상화되어, 개발자는 비즈니스 로직에 집중할 수 있게 되었습니다."
이러한 변화들은 클라우드 환경과 대규모 분산 시스템 요구사항에 대응하기 위한 자바의 지속적인 진화를 보여준다.
스레드풀
1. 스레드의 문제점
- 비용 문제:
- 자바 스레드는 직접 운영체제 스레드에 접근한다
- 운영체제 스레드 생성/종료는 고비용 (메모리, CPU 자원 소모).
→ 과도한 스레드 생성 시 시스템 자원 고갈 가능성.
- 하드웨어 제약:
- CPU 코어 수에 따라 최적 스레드 수 결정 (예: 8코어 → 8~16스레드).
→ 코어 수를 초과하는 스레드는 컨텍스트 스위칭 오버헤드 발생.
- CPU 코어 수에 따라 최적 스레드 수 결정 (예: 8코어 → 8~16스레드).
2. 스레드 풀의 장점
- 자원 재사용:
- 미리 생성된 스레드 재활용 → 생성/종료 오버헤드 감소. - 작업 큐 관리:
- 대기 작업을 큐에 저장 → 작업 처리 순서 제어 가능. - 설정 유연성: 큐 크기, 거부 정책, 우선순위 등 세밀한 제어 가능.
3. 스레드 풀의 단점
- 블로킹 작업 시 효율 저하
- 데드락 위험 : 상호 의존적 작업 시 교착 상태 발생 가능
- 종료 누락 : 종료하지 않으면 애플리케이션 무한 대기
스레드 풀 동작 원리
// 이 구조 덕분에, 과도한 스레드 생성 없이 효율적인 작업 처리가 가능
1. 작업 제출
2. 코어 스레드가 비어 있다면 → 즉시 실행
3. 코어 스레드가 모두 사용 중이라면
→ 작업 큐에 저장 (큐가 안 찼다면)
→ 큐가 가득 찼다면
→ 최대 스레드 수 초과 여부 판단
→ 초과 안 했으면 스레드 추가 생성
→ 초과했다면 거부 정책 발동 (예: 예외 발생)스레드의 다른 추상화 : 중첩되지 않은 메서드 호출
- 7장(병렬 스트림 처리와 포크/조인 프레임워크)에서 사용한 동시성과의 비교
- 포크/조인
- 엄격한 포크/조인 : 스레드 생성과 join()이 한 쌍처럼 충첩된 메서드 호출. 순서가 있다.
- 여유로운 포크/조인: 시작된 태스크를 내부 호출이 아니라 외부 호출에서 종료하도록. 순서 상관 x
- 비동기 메서드
- 메서드가 반환된 후에도 만들어진 태스크 실행이 계속되는 메서드를 비동기 메서드
- 주의사항
- 스레드 실행은 메서드를 호출한 다음의 코드와 동시에 실행되므로 데이터 경쟁 문제를 일으키지 않도록해야 한다.
- 기존 실행 중이던 스레드가 종료되지 않은 상황에서 자바의 main() 메서드가 반환되면 문제가 발생할 수 있다.
- 포크/조인
비동기 API 기법
- Runnable 사용
- 복잡한 코드
- ExecutorService + Future (자바 5~)
- 스레드 재사용으로 성능 향상,
Future.get()으로 결과를 구조화된 방식으로 수신 - But 여전히 명시적인 submit 메서드 호출 같은 불필요한 코드로 오염
- 스레드 재사용으로 성능 향상,
- Future 형식 API : (Future 반환 메서드)
- 메서드 자체가
Future를 반환하도록 설계
- API 수준에서의 비동기 지원 시작 => 추상화함으로써, 호출자가 실행 메커니즘을 알 필요 없이 결과만 기다리게 하는 것이 목표 - 호출 즉시 자신의 원래 바디를 평가하는 task를 포함하는 Future 반환
- 실제로 작업이 끝났는지(완료됐는지) 여부를 get()을 호출하는 시점에서야 알 수 있다.
- 메서드 자체가
- 리액티브 형식 API
- 메서드들의 시그니처를 바꿔 콜백 형식의 프로그래밍을 이용하는 것
- 메서드에 추가 인수로 콜백(람다)을 전달해서 메서드의 바디에서는
return 문으로 결과를 반환하는 것이 아니라 결과가 준비되면 이를 람다로 호출하는 태스크를 만드는 것 - 보완 사항
- if-then-else를 이용해 적절한 락을 이용해 두 콜백이 모두 호출되었는지 확인 후 수행
- 리액티브 형식의 API는 보통 한 결과가 아니라 일련의 이벤트에 반응하도록 설계되었으므로 Future를 이용하는 것이 더 적절
- 리액티브 프로그래밍 (자바 9+)
CompletableFuture조합 →java.util.concurrent.Flow(발행-구독 모델)- 완전한 비동기 체인 구성 가능
실제 개발 시 마주칠 주요 문제(블로킹, 예외 처리)와 해결 전략
잠자기(그리고 기타 블로킹 동작)는 해로운 것으로 간주 = 블로킹 동작의 위험성
- 스레드 풀에서 sleep중인 태스크는 다른 태스크가 시작되지 못하게 막으므로 자원을 소비한다.
- 이상적으로는 절대 태스크에서 기다리는 일을 만들지 말거나 코드에서 예외를 일으키는 방법으로 이를 처리할 수 있다.
=> 비효율적 자원 사용 방지 해야한다.
현실성 확인
- 현실적으로 '모든 것은 비동기'라는 설계 원칙을 지킬 수는 없으니, 고려하자. 대체 방안으로 네트워크 서버의 블록/비블록 API를 일관적으로 제공하는 Netty 같은 새로운 라이브러리를 사용하는 것도 추천
비동기 API에서 예외는 어떻게 처리할까?
- 비동기 API에서 호출된 메서드의 실제 바디는 별도의 스레드에서 호출되며 이때 발생하는 어떤 에러는 이미 호출자의 실행 범위와는 관계가 없는 상황이 된다.
- Future를 구현한 CompletableFuture에서는 런타임 get() 메서드에 예외를 처리할 수 있는 기능을 제공하며 예외에서 회복할 수 있도록 exceptionally() 같은 메서드도 제공한다.
박스와 채널 모델
- 프로그램의 일부를 채널을 이용해 소통하는 박스로 표시하는 다이어그램 방식 설명
= 박스와 채널 모델은 동시성을 설계하고 계념화하기 위한 모델
=> 이를 통해 생각, 코드 구조화로 대규모 시스템 구현의 추상화 수준을 높일 수 있다. - 박스(또는 프로그램의 콤비네티어) : 원하는 연산 표현
고려사항
-
병렬성을 극대화하기 위해 모든 함수를 Future 로 감싸려고 한다면, 시스템이 커지고 각자의 박스, 채널이 등장한다면 많은 task가 get() 호출해서 Future 끝나기를 기다리는 상황 => 하드웨어의 병렬성 저조 혹은 데드락 가능성
=> CompletableFuture와 콤비네이터로 문제 해결 -
목적: 동시성 프로그램을 추상화하여 구조화
-
핵심 요소
- 박스: 연산 단위 (예: CompletableFuture)
- 채널: 박스 간 데이터 흐름 (예: 비동기 스트림)
-
위험: 많은 task의 과도한 Future.get() 사용 → 병렬성 저하/데드락
-
해결책: CompletableFuture와 콤비네이터로 문제 해결
CompletableFuture와 콤비네이터를 이용한 동시성
- 일반적으로 Future는 실행해서 get()으로 결과를 얻을 수 있는 Callable로 만들어진다
- CompletableFuture는 실행할 코드 없이 Future를 조합할 수 있는 기능이 있다.
- complete() 메서드를 이용해 다른 스레드가 완료한 후에 get()으로 값을 얻을 수 있도록 허용한다.
CompletableFuture와 thenCombine을 이용한 비동기 작업 조합
기본 개념
- CompletableFuture: Java 8에서 도입된 비동기 작업 처리 클래스
Future의 확장판으로, 작업 체이닝과 조합 기능을 제공- Non-blocking 방식으로 여러 작업을 병렬 처리 가능
문제 상황
CompletableFuture<Integer> a = new CompletableFuture<>();
executorService.submit(() -> a.complete(f(x)));
int b = g(x); System.out.println(a.get() + b); // ❌ a.get()에서 블로킹 발생g(x)는 동기 실행 →f(x)와 병렬 처리되지 않음
해결책: thenCombine 사용
CompletableFuture<Integer> a = CompletableFuture.supplyAsync(() -> f(x), executor);
CompletableFuture<Integer> b = CompletableFuture.supplyAsync(() -> g(x), executor);
// 결과를 추가하는 세 번째 연산c는 다른 두 작업이 끝날 때까지 실행되지 않는다.
CompletableFuture<Integer> c = a.thenCombine(b, (y, z) -> y + z);
System.out.println(c.get()); // ✅ 최종 결과만 블로킹
발행-구독 그리고 리액티브 프로그래밍
Future vs 리액티브 프로그래밍
Java에서 Future는 한 번 실행해서 결과를 한 번 반환하는 비동기 방식, 하지만 리액티브 프로그래밍은 시간이 지나면서 계속해서 데이터를 발행하고, 그 결과에 반응하는 프로그래밍이다.
즉, Future는 "한 방에 끝", 리액티브는 "계속 반응하면서 처리"
Java 9부터는 java.util.concurrent.Flow API를 통해 이 개념을 지원하며, 발행-구독(Publisher-Subscriber) 모델을 기반
📈 발행-구독(Pub-Sub) 모델의 데이터 흐름 방향:
Publisher → Subscription → Subscriber
데이터 흐름 방향: 업스트림과 다운스트림
- 업스트림 (Upstream): 데이터가 위쪽에서 내려옴 → 예:
onNext(newValue) - 다운스트림 (Downstream): 아래쪽으로 흐름 → 예:
notifyAllSubscribers()
예제
// 이를 통해 SimpleCell은 구독자 혹은 발행자가 될 수 있다.
public class SimpleCell implements Publisher<Integer>, Subscriber<Integer> {}
subscribe : 구독자 추가
onNext : 구독자들에게 전파
역압력
- 압력 상황
- 매 초마다 수천개의 메시지가 onNext로 전달된다면 빠르게 전달되는 이벤트를 아무 문제 없이 처리할 수 있을까? => 이럴때는 정보의 흐름 속도를 제어하는 역압력 기법이 필요
- 역압력 : Subscriber가 Publisher에게 "하나씩만 줘!" 라고 요청하는 방식
// Flow.Subscriber의 주요 메서드
void onSubscribe(Subscription subscription); // Subscription은 Publisher와 Subscriber 사이의 커넥션을 나타냅니다
@Override
public void onNext(Integer item) {
// 처리...
subscription.request(1); // request(n)을 호출해 몇 개를 받을지 명시
}
역압력 설계 시 고민할 점 ex) 실시간 처리 vs 중요한 로그 저장 등
- 느린 Subscriber 때문에 전체 속도를 늦출 것인가?
- 각 Subscriber에게 별도 큐를 둘 것인가?
- 큐가 넘치면 데이터를 버릴 것인가?
- 중요한 데이터라면 버리면 안 되는데?
리액티브 시스템 vs 리액티브 프로그래밍
리액티브 시스템이란?
리액티브 시스템은 애플리케이션 전체 구조나 아키텍처 차원의 개념
시스템이 외부 환경의 변화, 오류, 부하 증가에 잘 반응하고 견디도록 설계되어야 한다.
- 속성은 반응성(responsive), 회복성(resilient), 탄력성(elastic)
- 반응성: 사용자 요청에 빠르게 응답하는 시스템. 오류나 부하 상황에서도 응답성이 유지됨
- 회복성: 일부 컴포넌트가 실패해도 전체 시스템이 무너지지 않고 복구 가능
- 탄력성: 부하가 커져도 유연하게 확장하거나 축소해 처리 가능 (예: 수평 확장)
- 이러한 속성을 구현하는 방법 중 하나로 리액티브 프로그래밍을 이용할 수 있다.
리액티브 프로그래밍이란?
리액티브 프로그래밍은 데이터의 변화나 이벤트 흐름에 따라 자동으로 반응하는 코딩 방식
예를 들어, 버튼을 클릭하면 자동으로 이벤트 핸들러가 실행되거나, 실시간 데이터가 들어오면 UI가 즉시 업데이트되는 경우
✅ 코드 단위에서 비동기 흐름과 이벤트 기반 반응을 구현하는 기술입니다.
- 예:
RxJava,Project Reactor,Flow API (Java 9+)- 기술 관점:
onNext,subscribe,stream,event등으로 표현됨- 역할: 데이터 흐름에 대한 반응형 처리
즉, 리액티브 프로그래밍은 구현 기술이고, 리액티브 시스템은 전체 시스템의 설계 철학이다.
하지만 단지 리액티브 프로그래밍을 썼다고 해서 전체 시스템이 리액티브 시스템이 되는 것은 아니다. 장애 대응, 부하 분산, 서비스 간 독립성, 모니터링까지 포함돼야 리액티브 시스템
CHAPTER 16 CompletableFuture : 안정적 비동기 프로그래밍
Future의 단순 활용 (java 8 이전)
Future란?
- 비동기 작업의 결과를 나타내는 객체입니다. = 비동기 작업의 결과를 나중에 제공받는 약속(Promise)
- 예: 오래 걸리는 계산을 별도의 스레드에서 실행하고 결과를 Future로 받음.
ExecutorService executor = Executors.newCachedThreadPool();
// 1. 비동기 작업 제출 (오래 걸리는 계산)
Future<Double> future = executor.submit(() -> doSomeLongComputation());
// 2. 다른 작업 수행
doSomethingElse();
try {
// 3. 최대 1초 동안 결과 기다림
Double result = future.get(1, TimeUnit.SECONDS);
} catch (TimeoutException e) {
// 타임아웃 처리
} catch (InterruptedException | ExecutionException e) {
// 예외 처리
}
💡 get() 메서드는 결과가 나올 때까지 현재 스레드를 블록시킴. 오래 걸리는 작업이 영원히 끝나지 않을 수 있는 문제가 있으므로 get 메서드를 오버로드해서 스레드가 대기할 최대 타임아웃 시간을 설정하는 것이 좋다.
Future의 한계
- 두 비동기 작업의 결과 조합이나, 가장 빠른 작업 선택 등 고급 비동기 흐름을 구성하기 어렵다.
- 예외 처리나 수동 완료 기능이 제한적
→ 이를 보완하기 위해 Java 8에서 CompletableFuture가 도입됨.
CompletableFuture로 비동기 API 구현하기
- 동기 메서드 -> 비동기 메서드로 변환
- 비동기 계산과 완료 결과를 포함하는 CompletableFuture 인스턴스 활용
- 결과가 준비되기 전에도
Future를 반환해 다른 작업을 병행할 수 있게 한다
기본 패턴
public Future<Double> getPriceAsync(String product) {
CompletableFuture<Double> futurePrice = new CompletableFuture<>();
new Thread(() -> {
double price = calculatePrice(product);
futurePrice.complete(price); // 계산 완료 시 결과 전달
}).start();
return futurePrice;
}사용 예시
// 비동기로 처리되므로 즉시 Future 반환하고, 그 사이에 다른 작업 처리
Shop shop = new Shop("BestShop");
long start = System.nanoTime();
Future<Double> futurePrice = shop.getPriceAsync("my favorite product"); //제품 가격 요청
long invocationTime = ((System.nanoTime() - start) / 1_000_000);
//제품의 가격을 계산하는 동안
doSomethingElse();
//다른 상점 검색 등 작업 수행
try {
double price = futurePrice.get(); //가격정보를 받을때까지 블록
} catch (Exception e) {
throw new RuntimeException(e);
}
long retrievalTime = ((System.nanoTime() - start) / 1_000_000);- 에러 처리 방법
CompletableFuture에서는completeExceptionally()로 비동기 내부 예외를 외부에 전달 가능- 비동기 로직에서 에러가 발생한다면?
- 예외가 발생하면 해당 스레드에만 영향을 미치기 때문에 클라이언트는 get 반환때까지 영원히 기다릴 수 있다.
- 따라서 타임아웃을 활용해 예외처리를 하고, completeExceptionally 메서드를 이용해 CompletableFuture 내부에서 발생한 에외를 클라이언트로 전달해야 한다
public Future<Double> getPriceAsync(String product) {
CompletableFuture<Double> futurePrice = new CompletableFuture<>();
new Thread(() -> {
try {
double price = calculatePrice(product);
futurePrice.complete(price);
} catch {
futurePrice.completeExceptionally(ex); //에러를 포함시켜 Future를 종료
}
}).start();
return futurePrice;
}- 팩토리 메서드 supplyAsync 로 간단히 CompletableFuture 만들 수도 있다.
CompletableFuture<Double> future = CompletableFuture.supplyAsync(() -> calculatePrice("product"));
비블록 방식으로 동작 개선하기
Stream의 게으름 + CompletableFuture의 병렬성
- Stream은 "게으른(lazy)" 연산이다
stream.map(...)을 쓴다고 바로 실행되지 않고, 최종 연산(collect,forEach)이 있어야 실행됨.- 중간 연산(
map,filter등)은 데이터를 바로 처리하지 않고, 파이프라인만 만든다.
CompletableFuture.join()은 결과를 기다리는 동기 메서드이다.- 이걸 호출하면 해당
CompletableFuture의 작업이 완료될 때까지 기다림.
- 이걸 호출하면 해당
예제
- Stream 사용해서 List에서 각 객체를 돌면서 블록되는 시간 발생
shops.stream() .map(shop -> shop.getPrice(product)) .map(Discount::applyDiscount) .collect(toList()); // 동기, 순차 처리
해결
-
병렬 스트림으로 요청 병렬화하기 : parallelStream()
-
CompletableFuture로 비동기 호출 구현하기 : CompletableFuture.supplyAsync
- 추가로, List<CompletableFuture< String>> -> List< String>
-
개선 : CompletableFuture를 사용한 결과는 순차 방식보단 빠르지만 병렬 스트림보단 느림
- 커스텀 Executor 사용
- 병렬스트림 버전에 비해 작업에 이용할 수 있는 다양한 Executor를 지정할 수 있다는 장점이 있다. Executor로 스레드 풀 크기를 조정할수도 있고 애플리케이션에 맞는 최적화 설정이 가능(스레드 수, 큐 정책 등 제어 가능 → 성능 향상)
- 커스텀 Executor 사용
List<CompletableFuture<String>> priceFutures = shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product), executor))
.map(future -> future.thenApply(Quote::parse))
.map(future -> future.thenCompose(
quote -> CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote), executor)))
.collect(toList());
return priceFutures.stream()
.map(CompletableFuture::join)
.collect(toList());중요
- 두 map 연산을 하나의 스트림 처리 파이프라인이 아닌, 두 개의 파이프라인으로 처리함!
- 스트림 연산은 게으른 특성이 있으므로 하나의 파이프라인으로 처리했다면 모든 가격 정보 요청 동작이 동기적, 순차적으로 이루어지게 된다.
=>map(...).map(join)형태로 사용하면 순차 처리됨 - 파이프라인 2단계 : 먼저
CompletableFuture로 비동기 작업 생성 → 나중에join()으로 결과 모음
- 스트림 연산은 게으른 특성이 있으므로 하나의 파이프라인으로 처리했다면 모든 가격 정보 요청 동작이 동기적, 순차적으로 이루어지게 된다.
// 잘못된 접근
shop1.getPrice() → 기다림(join)
shop2.getPrice() → 기다림(join)
shop3.getPrice() → 기다림(join)
// 올바른(병렬) 처리
shop1.getPrice()
shop2.getPrice()
shop3.getPrice()
↓
기다림(join)
↓
결과 모음
비동기 작업 파이프라인 만들기
CompletableFuture을 이용한 예제
하나의 주제(가격 정보 조회 및 처리) 안에서 점점 복잡한 기능을 단계적으로 확장
1단계: 기본적인 가격 조회 (동기, 순차적 처리)
- 모든 작업이 순차적이고 동기적으로 처리됨 → 느림
- 상점 수가 늘어나면 처리 시간도 늘어남 (
n * (가격 + 할인)시간)
2단계: CompletableFuture를 이용한 비동기 처리 (병렬화)
- ① 가격 정보 비동기로 요청
- ② 응답 문자열을
Quote로 파싱 - ③ 비동기로 할인 서비스 호출
- 결과를
join()으로 한꺼번에 모음
✅ 훨씬 빠르고 효율적인 병렬 처리
3단계: 독립적인 두 작업 합치기 (thenCombine)
getPrice와getRate는 서로 독립적이므로 동시에 실행 가능thenCombine으로 서로 독립적인 비동기 작업을 동시에 실행한 두 결과를 결합하여 새로운 결과 생성- 비동기 API를 효과적으로 조합하는 방식
4단계: 타임아웃 처리 (orTimeout, completeOnTimeout)
orTimeout: 지정 시간 초과 시 예외 발생completeOnTimeout: 시간 초과 시 기본값으로 자동 완료
✅ 안정적인 비동기 처리를 위한 실전 전략
// # 1단계
shops.stream()
.map(shop -> shop.getPrice(product))
.map(Quote::parse)
.map(Discount::applyDiscount)
.collect(toList());
// # 2단계
List<CompletableFuture<String>> priceFutures =
shops.stream()
.map(shop -> CompletableFuture.supplyAsync(() -> shop.getPrice(product), executor)) // ①
.map(future -> future.thenApply(Quote::parse)) // ②
.map(future -> future.thenCompose(quote ->
CompletableFuture.supplyAsync(() -> Discount.applyDiscount(quote), executor))) // ③
.collect(toList());
return priceFutures.stream()
.map(CompletableFuture::join) // 결과 모으기
.collect(toList());
// # 3단계
Future<Double> futurePriceInUSD =
CompletableFuture.supplyAsync(() -> shop.getPrice(product)) // 가격 요청
.thenCombine(
CompletableFuture.supplyAsync(() -> exchangeService.getRate(EUR, USD)), // 환율 요청
(price, rate) -> price * rate); // 결과 조합
// # 4단계
// 실패할 수 있는 네트워크 호출에 타임아웃 설정
CompletableFuture.supplyAsync(() -> shop.getPrice(product))
.thenCombine(CompletableFuture.supplyAsync(() -> exchangeService.getRate(EUR, USD))
.completeOnTimeout(DEFAULT_RATE, 1, TimeUnit.SECONDS), // 환율 기본값 사용
(price, rate) -> price * rate)
.orTimeout(3, TimeUnit.SECONDS); // 전체 작업 제한 시간
CompletableFuture의 종료에 대응하는 방법
- 16.4 예제는
CompletableFuture로 비동기 파이프라인을 구성하여 병렬 처리 성능을 향상.
=> 이 흐름을 스트림으로 리팩터링하여 결과가 준비되자마자 즉시 처리하는 방식으로 발전 가능 - 주요 초점: "모든 결과 기다리기 vs 하나라도 처리하기" 전략을 유연하게 다룰 수 있도록 개선.
모든 결과 vs 하나의 결과
CompletableFuture.allOf(): 모든 작업 완료 후 실행CompletableFuture.anyOf(): 하나라도 완료되면 즉시 실행 → 반응형 UX, 알림 처리 등- 실시간 반응형 UI 또는 알림 서비스 등에 유용.
CompletableFuture.anyOf(futures).thenAccept(System.out::println);
- 실시간 반응형 UI 또는 알림 서비스 등에 유용.
CHAPTER 17 리액티브 프로그래밍
- 애플리케이션 수준, 시스템 수준의 리액티브 프로그래밍
- 리액티브 스트림, 자바 9 플로 API를 사용한 예제 코드
- 널리 사용되는 리액티브 라이브러리 RxJava 소개
요약
| 구성요소 | 설명 |
|---|---|
Publisher | 데이터를 발행하는 주체 (뉴스 발행사) |
Subscriber | 데이터를 소비하는 주체 (뉴스 구독자) |
Subscription | 데이터 흐름 조절 (얼마나 받을지 설정) |
Processor | 데이터 가공 (중간 필터 역할) |
리액티브 프로그래밍 패러다임의 중요성: 왜 필요할까?
변화한 환경
- 빅데이터 시대: 데이터는 페타바이트(PB) 단위로 폭증하고 있으며, 계속해서 쏟아지고 있음.
- 다양한 장치: 모바일, IoT, 클라우드 서버 등 다양한 환경에서 데이터가 생성되고 수신됨.
- 사용자 기대치: 사용자는 24시간 언제든지 밀리초 단위의 빠른 응답을 원함.
➡️ 이처럼 빠르고 안정적인 처리를 위해 비동기적으로 데이터 스트림을 다루는 리액티브 프로그래밍이 중요해짐.
리액티브 매니패스토
- 소프트웨어 아키텍쳐에 대한 선언문으로 Reactive System의 특성을 강조한 가이드라인
리액티브 시스템의 핵심 원칙 4가지
| 원칙 | 설명 |
|---|---|
| 반응성 (Responsive) | 항상 일정하고 예측 가능한 속도로 반응 |
| 회복성 (Resilient) | 장애가 발생해도 반응성을 유지하며 복구 가능 |
| 탄력성 (Elastic) | 트래픽이 몰리면 시스템을 자동으로 확장 |
| 메시지 주도 (Message-driven) | 비동기 메시지를 사용하여 컴포넌트 간의 느슨한 결합 유지 |
애플리케이션 vs 시스템 수준 리액티브
| 구분 | 애플리케이션 수준 | 시스템 수준 |
|---|---|---|
| 초점 | 단일 앱의 비동기 처리 | 분산 시스템 전체 아키텍처 |
| 주요 기술 | Reactor, RxJava | 카프카, Akka, 쿠버네티스 |
| 예시 | 웹 서버의 논블로킹 IO | 마이크로서비스 간 이벤트 드리븐 통신 |
애플리케이션 수준의 리액티브
- 이벤트 기반 처리: 이벤트 루프가 데이터를 감지하고 이벤트를 비동기로 처리
- 멀티코어 활용 극대화: 스레드를 효율적으로 공유하여 처리량 증가
- 전제조건 - 블로킹 금지: 데이터베이스, 네트워크 등 모든 I/O는 비동기 처리 필수
- 콜백, 퓨처, 액터 등으로 구성된 이벤트 시스템을 활용
시스템 수준의 리액티브
- 애플리케이션 조합: 여러 리액티브 앱이 하나의 안정적인 플랫폼으로 통합
- 고립성 유지: 한 컴포넌트 장애가 전체 시스템에 영향을 미치지 않음
- 위치 투명성: 서비스 간 통신은 위치에 구애받지 않음
- 수평 확장 가능: 시스템 복제 및 확장이 용이함
리액티브 스트림과 플로 API
리액티브 프로그래밍은 리액티브 스트림을 사용하는 프로그래밍이다. 리액티브 스트림은 잠재적으로 무한의 비동기 데이터를 순서대로 그리고 블록하지 않는 역압력을 전제해 처리하는 표준 기술이다.
📌 리액티브 스트림의 특징
- 비동기 데이터 처리
- 무한 스트림 가능
- 역압력 (Backpressure): 소비자가 감당할 수 없는 속도로 데이터를 받지 않도록 조절
🧩 java.util.concurrent.Flow API 구성
| 인터페이스 | 설명 |
|---|---|
Publisher<T> | 구독자에게 데이터를 발행 |
Subscriber<T> | 발행자로부터 데이터를 수신 |
Subscription | 데이터 요청/취소를 관리 |
Processor<T, R> | 데이터 변환 중개자 (Publisher + Subscriber 역할 모두 수행) |
흐름 요약
Subscriber는Publisher에 구독(subscribe)을 요청함Publisher는onSubscribe()로Subscription을 전달함Subscriber는request(n)으로 몇 개의 데이터를 받을지 요청함Publisher는 최대n개의 데이터를onNext()로 전달- 완료되면
onComplete(), 에러 나면onError()
//Publisher가 발행한 리스너로 Subscriber에 등록할 수 있다.
@FunctionalInterface
public interface Publisher<T> {
void subscribe(Subscriber<? super T> s);
}
//Publisher가 관련 이벤트를 발행할 때 호출할 수 있도록 콜백 메서드 네 개를 정의
public interface Subscriber<T> {
void onSubscribe(Subscription s);
void onNext(T t);
void onError(Throwable t);
void onComplete();
}
// Subscription은 Publisher와 Subscriber 사이의 제어 흐름, 역압력을 관리
public interface Subscription {
void request(long n); //publisher에게 이벤트를 처리할 준비가 되었음을 알림
void cancel(); //publisher에게 이벤트를 받지 않음을 통지
}
//리액티브 스트림에서 처리하는 이벤트의 변환단계를 나타냄
//에러나 Subscription 취소 신호 등을 전파
public interface Processor<T, R> extends Subscriber<T>, Publisher<R> { }
Processor는 중간 처리자로써, 예를 들어 온도를 섭씨로 바꾸는 등의 변환 작업 수행Subscriber이자Publisher이므로 중간에서 가공 가능
public class SimpleReactiveExample {
public static void main(String[] args) throws InterruptedException {
// 1. Publisher 생성
SubmissionPublisher<String> publisher = new SubmissionPublisher<>();
// 2. Subscriber 생성
Flow.Subscriber<String> subscriber = new Flow.Subscriber<>() {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
this.subscription = subscription;
System.out.println("✔ 구독 시작!");
subscription.request(1); // 먼저 1개 요청
}
@Override
public void onNext(String item) {
System.out.println("📦 받은 데이터: " + item);
subscription.request(1); // 처리 후 다음 1개 요청
}
@Override
public void onError(Throwable throwable) {
System.err.println("❌ 에러 발생: " + throwable.getMessage());
}
@Override
public void onComplete() {
System.out.println("✅ 모든 데이터 수신 완료!");
}
};
// 3. Subscriber를 Publisher에 등록
publisher.subscribe(subscriber);
// 4. 데이터 발행
publisher.submit("Hello");
publisher.submit("Reactive");
publisher.submit("Streams");
// 5. 마무리
publisher.close(); // onComplete() 호출됨
Thread.sleep(1000); // 비동기이므로 대기
}
}
// result
✔ 구독 시작!
📦 받은 데이터: Hello
📦 받은 데이터: Reactive
📦 받은 데이터: Streams
✅ 모든 데이터 수신 완료!
- `onSubscribe()`에서 구독을 시작하고 첫 데이터를 요청
- `onNext()`에서 데이터 수신 후 다시 1개 요청 → 역압력(backpressure)
- `close()`를 호출했기 때문에 모든 데이터 전송 후 `onComplete()` 호출됨
자바는 왜 Flow API 구현체를 직접 제공하지 않을까?
- 여러 라이브러리의 표준화를 위한 인터페이스로 활용
- 실제 구현은 외부 리액티브 라이브러리에 맡김 → 유연성 확보
리액티브 라이브러리 RxJava
RxJava의 두 가지 핵심 클래스
| 클래스 | 설명 |
|---|---|
Flowable | 역압력 지원 |
Observable | 역압력 미지원 (GUI 이벤트 등 가벼운 스트림에 적합) |
권장 사용 가이드
Flowable: 데이터가 많고(대량 데이터 처리), 처리 속도가 불균형할 때Flowable.range(1, 1000000) .onBackpressureDrop() .subscribe(System.out::println);Observable: 클릭, 마우스 이동 등 빠른 응답이 필요한 GUI 이벤트 처리Observable.just("Hello", "World") .subscribe(System.out::println);
추가: 그럼에도 리액티브 프로그래밍이 널리 사용되지 않는 이유
- 학습 곡선이 높고, 코드 가독성이 떨어짐
- 리액티브 프로그래밍은 전통적인 명령형 방식에 익숙한 개발자에게 익숙하지 않은 추상화를 요구함
map(),flatMap(),subscribe()등의 체이닝 구조는 코드를 추적하고 디버깅하기 어려움- 특히
onError,onComplete등 다양한 상태 처리를 명확히 이해해야 함
Flowable.fromPublisher(publisher)
.map(data -> transform(data))
.flatMap(result -> process(result))
.subscribe(System.out::println);
// → 이런 코드는 처음 접하는 사람에게는 “무슨 일이 일어나는지” 직관적이지 않음.- 디버깅과 에러 추적이 어려움
- 콜 스택이 비동기적으로 분리되기 때문에, 예외 발생 시 어디서 문제가 생겼는지 추적이 어려움
NullPointerException,TimeoutException등이 체이닝 중간에서 발생하면 로그만 봐서는 원인 파악이 힘듦
💡 해결하려면.doOnError(),.onErrorResume()등을 잘 다뤄야 함
- 블로킹 I/O와의 궁합 문제
- 기존 레거시 시스템(예: JDBC, JPA, 외부 REST API 등)은 대부분 블로킹 API
- 리액티브 시스템은 블로킹을 허용하지 않음, 따라서 중간에 하나라도 블로킹 호출이 있으면 전체 리액티브 체인이 무의미
- 완전한 리액티브 시스템을 만들려면 DB, WebClient, 메시지 큐 등 모든 요소가 비동기 API여야 함 → 도입 장벽이 큼
- 개발 속도 저하 및 생산성 감소 가능성
- 작은 비즈니스 로직을 구현하는 데도 체이닝과 콜백 지옥에 빠질 수 있음
- 팀 전체가 리액티브에 익숙하지 않다면, 프로젝트의 생산성과 유지보수성이 떨어질 수 있음
- 코드 리뷰/테스트 시에도 진입장벽이 생김
- 운영 및 모니터링 도구 부족
- 전통적인 APM 툴이나 로그 분석 도구는 리액티브 컨텍스트 추적에 한계가 있음
- 예: 스레드 기반 트랜잭션 추적이 불가능 → Context Propagation을 위한 추가 설정이 필요함
그럼에도 불구하고 리액티브가 유리한 상황
| 상황 | 리액티브 유리 |
|---|---|
| 실시간 데이터 스트리밍 | 예: IoT 센서, 주식 데이터 |
| 수천 개의 동시 연결 | 예: 채팅 앱, SSE, WebSocket |
| 외부 API 호출이 많고 비동기 처리 가능 | 예: API 게이트웨이, API 집계 서버 |
| 마이크로서비스 간 호출 | 메시지 기반 처리와 궁합이 좋음 |
리액티브의 미래 = 현대 소프트웨어 아키텍처의 필수 사고방식 중 하나
- 클라우드 네이티브: 쿠버네티스 + 서비스 메시 조합
- 실시간 데이터 파이프라인: 플링크, 스파크 스트리밍
- IoT: 수백만 디바이스의 실시간 데이터 처리
가상 스레드가 어떻게 리액티브 프로그래밍을 대체하는가
리액티브 프로그래밍의 복잡성을 줄이면서도 높은 처리량(throughput)을 달성할 수 있는 대안
예전 자바 스레드는 "실제 운영체제 스레드"와 1:1로 매칭됬으나, 가상 스레드는 JVM이 직접 관리하는 초경량 스레드로서 1만 개의 가상 스레드를 만들어도 실제 운영체제는 10~20개 정도의 진짜 스레드만 관리
-
기존 리액티브 프로그래밍의 문제점
- 복잡한 코드 구조(콜백 지옥(callback hell)과 체인형 API)
- 디버깅 어려움
- 스레드 공유 모델(스레드 로컬 변수 사용이 제한)
-
가상 스레드의 동작 원리
가상 스레드는 경량 스레드로, JVM이 직접 관리하며 OS 스레드(캐리어 스레드)에 매핑된다.- 블로킹의 경량화: I/O 작업 중 블로킹이 발생하면 가상 스레드가 자동으로 일시 중단되고, 캐리어 스레드는 다른 가상 스레드를 실행. 이를 통해 OS 스레드 수십 개로 수만 개의 가상 스레드를 효율적으로 처리 가능.
- 스레드-per-request 모델 복원: 기존처럼 각 요청마다 전용 스레드를 할당하되, 블로킹 비용이 극히 낮아져 동시성 문제 없이 확장 가능
-
리액티브 프로그래밍 대체 가능성
- 가상 스레드는 리액티브 프로그래밍의 핵심 목표인 높은 처리량을 더 간단한 방식으로 달성한다.
- 동기식 코드 작성 가능: 블로킹 코드를 그대로 사용해도 내부적으로 논블로킹으로 동작. 예를 들어, synchronized 블록이나 Thread.sleep()을 사용해도 캐리어 스레드는 다른 작업을 처리합니다.
- Structured Concurrency: ExecutorService 대신 StructuredTaskScope를 사용해 관련 작업을 하나의 단위로 묶어 예외 처리 및 취소를 단순화
- Scoped Values: 가상 스레드 간 안전한 데이터 공유를 위해 ThreadLocal 대신 ScopedValue를 사용한다.
-
성능 비교
- I/O 집약적 작업: 가상 스레드는 리액티브 프로그래밍과 유사한 처리량을 제공하지만, 코드 복잡성은 크게 낮습니다. 실제 벤치마크에서 리액티브가 10~20% 더 높은 성능을 보이지만, 대부분의 애플리케이션에서는 차이가 미미하다.
- CPU 집약적 작업: 가상 스레드는 성능 향상을 목표로 하지 않으며, 이 경우 여전히 플랫폼 스레드 사용이 권장된다
-
남은 리액티브 프로그래밍의 활용처
- 극한의 성능 요구: 초고속 트래픽 처리나 역압력 관리가 필요한 시스템(예: 실시간 스트리밍)에서는 리액티브가 유리할 수 있다.
- 기존 리액티브 코드베이스: Spring WebFlux나 RxJava로 구축된 시스템은 당분간 유지될 것
