모던 자바 인 액션 - 2장
4장 스트림 소개
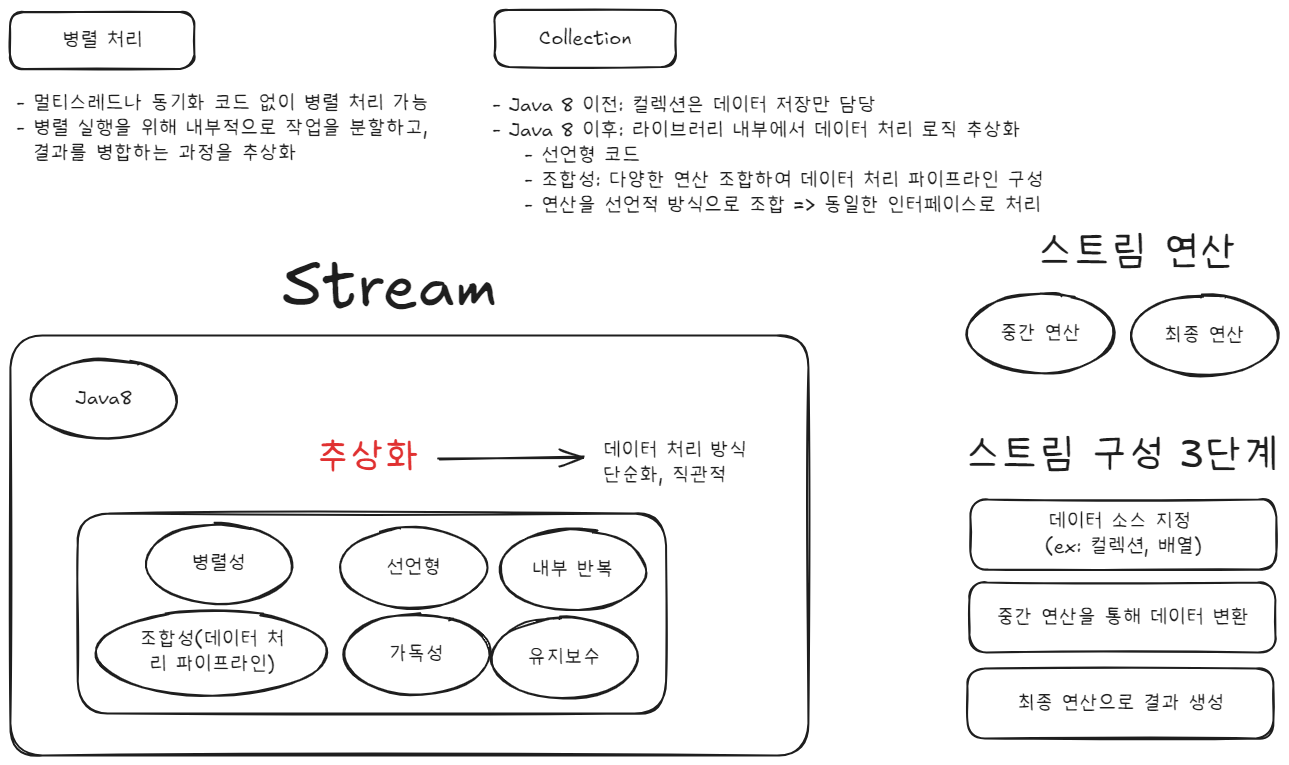
개발자는 "무엇을 할 것인가"에 집중하고, "어떻게 처리할 것인가"는 Stream API 내부에 맡긴다.
왜 스트림이 필요한가?
- Java는 기존에 루프 기반 처리 위주였기 때문에, 함수형 프로그래밍 트렌드에 맞춰 Lambda와 함께 Stream API가 도입됨
- 많은 요소를 담는 컬렉션 데이터를 처리할 때 기존 방식은 코드가 복잡하고 가독성이 떨어질수도
- 멀티코어 CPU를 효과적으로 활용하기 위해 병렬 처리 필요
- 복잡한 루프 기반 코드는 유지보수와 디버깅이 어려움
👉 Java 8의 스트림 API는 이러한 문제를 선언형 방식으로 간결하고 효율적으로 해결 가능
주의할 점과 한계
- 스트림은 1회용: 재사용 불가. 다시 사용하려면 다시 생성해야 함.
- 디버깅 어려움: 스트림 파이프라인 내부는 디버깅이 쉽지 않음 → 로그나 peek()을 활용
- 무한 스트림 주의: generate, iterate는 제한 (limit) 없이 사용 시 무한 루프 발생 가능
- 병렬 스트림 주의: 모든 상황에서 병렬이 빠르지는 않음. 오히려 성능 저하될 수도 있음 ex) I/O 작업
스트림이란?
- Java 8에 새롭게 도입된 기능
- 선언형(declarative) 방식으로 컬렉션 데이터를 처리
- 데이터 처리 로직을 명시적 구현 없이 질의(query) 형태로 표현
- 멀티스레드나 동기화 코드 없이 병렬 처리 가능
stream()→parallelStream()으로 쉽게 병렬화
- 라이브러리 내부에서 데이터 처리 로직 추상화
- 복잡한 로직 없이 간결한 선언형 코드로 표현 가능
- 다양한 빌딩 블록 연산 (
filter,map,sorted,collect)을 조합해 데이터 처리 파이프라인 구성
선언형 vs 명령형
- 선언형: 무엇을 할 것인지만 기술 (SQL처럼)
- 명령형: 어떻게 할 것인지를 명확히 기술
- 예: “삼겹살 사와” (선언형) vs “집 나가서 CU 가서 삼겹살 사” (명령형)
- 스트림 API는 선언형 코드 작성이 가능하도록 명령형 로직을 추상화함
// 명령형 방식
List<Dish> lowCaloricDishes = new ArrayList<>();
for (Dish d : menu) {
if (d.getCalories() < 400) {
lowCaloricDishes.add(d);
}
}
Collections.sort(lowCaloricDishes, Comparator.comparing(Dish::getCalories));
List<String> names = new ArrayList<>();
for (Dish d : lowCaloricDishes) {
names.add(d.getName());
}
// 선언형 방식 (Java 8 스트림)
List<String> names = menu.stream()
.filter(d -> d.getCalories() < 400)
.sorted(comparing(Dish::getCalories))
.map(Dish::getName)
.collect(toList());
스트림 API의 특징
- 선언형: 코드가 간결하고 가독성이 뛰어남
- 조합성: 연산들을 파이프라인 형태로 조합 가능
- 병렬성: 병렬 스트림으로 성능 향상 가능
스트림의 정의와 동작 원리
- 스트림은 "데이터 처리 연산을 지원하는, 소스로부터 추출된 연속된 요소"
- 연속된 요소: 순차적 데이터 접근
- 소스: 컬렉션, 배열, I/O 리소스 등
- 지연 연산(lazy evaluation): 최종 연산 전까지 실제 처리되지 않음 (게으른 계산)
파이프라이닝
- 대부분의 중간 연산(
filter,map,sorted)은 새로운 스트림을 반환 → 파이프라인 구성 가능 - 지연 연산 + 쇼트서킷(short-circuiting) 최적화 지원
내부 반복과 외부 반복
- 외부 반복: for-each, iterator 등 명시적 반복
- 내부 반복: 스트림에서 사용하는 추상화된 반복
// 외부 반복
for (Dish dish : menu) {
names.add(dish.getName());
}
// 내부 반복
List<String> names = menu.stream()
.map(Dish::getName)
.collect(toList());
👉 내부 반복은 병렬 처리 최적화와 선언형 코드 작성을 가능하게 함
스트림 vs 컬렉션
| 비교 항목 | 컬렉션(Collection) | 스트림(Stream) |
|---|---|---|
| 목적 | 데이터 저장 및 조작 | 데이터 처리(변환, 필터링, 매핑 등) |
| 데이터 저장 | 가능 | 불가능 |
| 재사용성 | 가능 | 불가능 (1회 사용 후 폐기) |
| 동시 사용 | 여러 소비자 가능 | 단일 소비자 전용 |
| 처리 방식 | 내부 저장 후 전처리 | 필요 시 처리 (지연 계산) |
| 병렬 처리 | 직접 구현 필요 | parallelStream()으로 병렬 처리 지원 |
| 무한 데이터 | 불가능 | 가능 (Stream.generate, Stream.iterate) |
스트림 연산
중간 연산
- 스트림을 변형하거나 필터링
- 예:
filter,map,limit,distinct,sorted - 지연 처리 → 최종 연산이 수행될 때 실행
최종 연산
- 스트림을 닫고 결과를 반환
- 예:
collect,forEach,count,reduce
List<String> names = menu.stream()
.filter(d -> d.getCalories() > 300)
.map(Dish::getName)
.limit(3)
.collect(toList());👉 최종 연산 전까지는 아무 연산도 수행하지 않음
5장 스트림 활용
필터링, 슬라이싱, 매핑
1. 필터링 (Filtering)
- Predicate를 이용한 필터링 :
filter는Predicate<T>를 받아 해당 조건을 만족하는 요소들만으로 구성된 새로운 스트림을 반환 - 중복 제거 distinct :
distinct는 요소의equals와hashCode를 기반으로 중복 제거를 수행
Predicate 대신 람다 함수를 넣으면 투명하게 관리할 수 있다.
2. 슬라이싱 (Slicing)
- 요소 제한 (
limit)과 건너뛰기 (skip) - 조건 기반 슬라이싱 : taskWhile(조건이 참인 동안), dropWhile(조건이 거짓이 될 때까지)
3. 매핑 (Mapping)
- 속성 추출 (map) : 각 요소에 함수를 적용하여 새로운 값을 생성
- 중첩 map(중복해서) : 연속적인 변환이 가능
- 평면화 (flatMap) : 여러 개의 스트림을 하나로 병합
검색, 매칭, 리듀싱
1. 검색 및 매칭
- anyMatch, allMatch, noneMatch : 조건에 따라 불리언 반환 (쇼트서킷 처리 = 불필요한 연산을 생략함으로써 성능을 개선하는 연산 방식)
- findAny, findFirst : 조건을 만족하는 요소를 Optional로 반환
2. 리듀싱 (Reducing)
- 모든 요소를 하나의 결과로 결합(합산, 최댓값 등)한다.
- 합계 구하기, 최댓값 구하기
- 장점
- 공유 상태 없이 병렬 처리에 유리
- 내부적으로 fold(접기) 연산처럼 작동
3. 상태 여부에 따른 스트림 연산 분류
| 연산 유형 | 상태 없음 (Stateless) | 상태 있음 (Stateful) |
|---|---|---|
| 예시 | map, filter, flatMap | sorted, distinct, limit |
| 특징 | 각 요소만으로 결과 결정 가능 | 이전 요소 또는 전체 필요 |
| 병렬처리 유리성 | 매우 유리 | 비효율 가능성 있음 |
숫자 스트림 사용하기
IntStream,DoubleStream등은 박싱/언박싱 오버헤드를 줄이고 성능을 높인다.- 박싱/언박싱 비용 피하고 성능 향상
mapToInt,summaryStatistics,boxed등 사용
int totalCalories = menu.stream()
.mapToInt(Dish::getCalories)
.sum();다중 소스로부터 스트림 만들기
여러 방식으로 스트림 생성 가능:
Stream.of(...),Arrays.stream(...)- 파일, 컬렉션, 함수로 생성
- 두 스트림 합치기:
Stream.concat - 다중 소스 평면화:
flatMap
Stream<String> stream1 = Stream.of("A", "B");
Stream<String> stream2 = Stream.of("C", "D");
Stream<String> merged = Stream.concat(stream1, stream2);무한 스트림
- 반드시
limit()과 함께 사용하지 않으면 무한 실행
Stream<Integer> evenNumbers = Stream.iterate(0, n -> n + 2);
Stream<Double> randoms = Stream.generate(Math::random);6장 스트림으로 데이터 수집
요약
- 스트림으로 수집할 데이터를 어떻게 반환할 것인가?
- 스트림을 사용하면 복잡한 데이터 가공도 간결하고 선언적으로 표현할 수 있는데, 결과를 만들어내는 최종 연산의 핵심은 바로
collect()이고, 이를 유연하게 만들어주는 게 바로 Collector이다.
- Java 스트림과 컬렉터를 활용하면 반복문과 조건문으로 가득했던 데이터 처리 코드를 간결하고 선언적으로 바꿀 수 있다. - collector 인터페이스에 정의된 메서드를 구현해서
커스텀 컬렉터를 개발가능. - 범위
- 스트림의 데이터 수집을 책임지는 컬렉터의 개념과 활용법, 그리고 커스텀 컬렉터 구현
컬렉터란 무엇인가?
- 컬렉터(Collector)는 스트림의 요소를 리스트, 맵, 문자열, 통계 등으로 어떻게 수집할지 정의하는 객체 => 전략 객체
- 스트림에서collect메서드는 스트림의 요소들을 원하는 형태로 모아주는 최종 연산. 이때 "어떻게 모을지"를 결정하는 것이 바로 컬렉터(Collector) - 스트림의
collect메서드에 컬렉터를 전달하면,collect메서드는 내부적으로 리듀싱 연산을 수행하며, 최종 결과를 List, Array, Map, 문자열, 통계 등 다양한 형태로 뽑아낼 수 있다.
- 명령형 코드에서 반복문과 조건문으로 직접 구현하던 데이터 가공 과정을 컬렉터로 간단하게 대체 가능
리듀싱
- 스트림 요소를 반복적으로 처리해 하나의 결과로 축소하는 과정
컬렉터는 이 리듀싱 과정을 유연하게 설계할 수 있게 해준다. 즉, 개발자는 "무엇을 원하는지"만 명확히 명시하면, 스트림은 내부적으로 알아서 각 요소를 누적(축소)해서 최종 결과를 만든다.
자주 쓰는 미리 정의된 컬렉터
- Collectors에서 제공하는 메서드의 기능은 크게 세 가지로 구분할 수 있다.
- 스트림의 요소를 하나의 값으로 리듀스 하고 요약
- 최대-최솟값 검색, 요약 연산, 문자열 연결
- 범용 리듀싱 요약 연산
-reducing()은reduce()를 Collector로 확장한 고급 기능
- 요소 그룹화
- 그룹화된 요소 조작
- 다수준 그룹화
- 서브 그룹으로 데이터 수집
-groupingBy()+toSet()같은 조합으로 그룹 내 결과 형태도 조절 가능
- 요소 분할
- 조건 기반의 true/false 분류
- 필터링과 다르게 true/false 양쪽 데이터를 동시에 수집
Collector 인터페이스
이걸로 나만의 Collector 가능. 이를 통해 성능 최적화도 가능하다.
Collector 인터페이스 메서드
supplier(): 결과 컨테이너 생성accumulator(): 각 요소를 결과에 누적combiner(): 병렬 처리 시 부분 결과 병합finisher(): 최종 결과 변환characteristics(): 병렬 가능 여부, 병합 방식 등 힌트 제공
예시
public Supplier<List<String>> supplier() {
return ArrayList::new; // 빈 ArrayList 생성
}
public BiConsumer<List<String>, String> accumulator() {
return List::add; // 요소를 리스트에 추가
}
public BinaryOperator<List<String>> combiner() {
return (list1, list2) -> {
list1.addAll(list2); // 두 리스트 합치기
return list1;
};
}
public Function<List<String>, List<String>> finisher() {
return Function.identity(); // IDENTITY_FINISH인 경우
}
public Set<Characteristics> characteristics() {
return Set.of(Characteristics.IDENTITY_FINISH); // 변환 없음을 명시
}
reduce, collect, Collectors.reducing
reduce()는 스트림 요소를 하나의 결과로 축소하는 가장 단순한 방식이고, Collectors.reducing()은 이를 Collector 형태로 확장한 고급 전략. 그리고 collect()는 다양한 Collector 전략 객체를 활용해 결과를 원하는 구조로 만들어내는 스트림의 핵심 최종 연산
1️⃣ reduce() – 스트림 요소를 하나의 결과로 축소
- 가장 기본적인 리듀싱 연산
- 누산자(accumulator) 함수와 초기값을 명시
- 단순한 합계, 곱, 최대값/최솟값 계산 등에 적합
- 불변성(Immutable) 기반: 매번 새로운 값을 반환
- 병렬 처리 시 적절한 연산자를 사용해야 안전하게 작동
int sum = numbers.stream().reduce(0, Integer::sum);2️⃣ Collectors.reducing() – 고급 리듀싱 Collector
- reduce()의 기능을 Collector 형태로 추상화한 것
- collect()에서 사용 가능 → 조합성과 가독성 향상
// collect(reducing(...))은 reduce(...)와 동일한 동작이지만, Collector 문맥 안에서 사용할 수 있는 확장형
int totalCalories = menu.stream()
.collect(Collectors.reducing(0, Dish::getCalories, Integer::sum));3️⃣ collect() – Collector 전략을 통해 다양한 결과물 생성
- 스트림 결과를 List, Map, 통계, 문자열 등 복합 구조로 수집 가능
- 가변(Mutable) 구조를 이용해 중간 상태를 유지하며 데이터 누적
- 병렬 스트림에서Collector가CONCURRENT설정되어 있다면 병렬성 확보 가능 - reducing() 외에도 groupingBy(), partitioningBy(), summarizingInt() 등과 함께 조합 가능
List<String> names = menu.stream()
.map(Dish::getName)
.collect(Collectors.toList());
Map<Type, List<Dish>> dishesByType =
menu.stream().collect(Collectors.groupingBy(Dish::getType));7장 병렬 데이터 처리와 성능
- 병렬 스트림으로 데이터를 병렬 처리하기
- 병렬 스트림의 성능 분석
- 포크/조인 프레임워크
- Spliterator로 스트림 데이터 쪼개기
병렬 스트림은 선언적으로 병렬 처리를 가능하게 해주며, Fork/Join 프레임워크와 Spliterator와 같은 기반 기술을 통해 동작한다. 하지만, 무조건 빠르지 않으며 적절한 상황, 자료구조, 작업 종류에 따라 현명하게 사용하는 것이 중요! 성능을 높이기 위해 병렬화를 쓰는 것이지, 단순히 코드를 짧게 하기 위해 사용하는 것은 아니다.
병렬 스트림
정리
1. 적절한 경우에만 사용: 100만 개 이상 데이터, CPU 집약적 작업
2. 자료구조 신중 선택: ArrayList > LinkedList
3. 상태 공유 금지: 순수 함수형 프로그래밍 원칙 준수
4. 성능 측정 필수: 실제 환경에서 벤치마크 진행
5. 병렬 처리 친화적 연산: range(), filter(), map()
1. 병렬 스트림이란?
- 기존의 순차 스트림에
.parallel()메서드를 호출하면 간단히 변환할 수 있다. - 내부적으로 데이터를 여러 조각(청크)으로 나눈 후, 멀티코어 CPU에서 병렬로 처리한다.
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 순차 처리
long sumSequential = numbers.stream().mapToInt(i -> i).sum();
// 병렬 처리
long sumParallel = numbers.parallelStream().mapToInt(i -> i).sum();2. 병렬 스트림의 작동 원리
- 분할: 전체 데이터를 여러 청크(조각)로 분할
2. 처리: 각 청크를 별도 스레드에서 처리
3. 결합: 부분 결과를 최종 결과로 합침
병렬 스트림의 작동 원리는 SI 프로젝트의 업무 분할·병렬 진행·통합 과정에 비유 가능.
데이터 = 작업, 스레드 = 사람
3. 성능 벤치마크: 순차 vs 병렬
잘못된 사용 사례
Stream.iterate()처럼 순차적으로 생성되는 스트림은 병렬 처리에 부적합
// 병렬 처리가 비효율적인 예 (Stream.iterate 사용)
long badParallelSum = Stream.iterate(1L, i -> i + 1)
.limit(10_000_000)
.parallel()
.reduce(0L, Long::sum);
- 문제점:
iterate는 순차적 생성 → 청크 분할 어려움 => 순차 처리보다 몇 배는 느리다.
올바른 사용 사례
- 대용량 데이터 (예: 100만 건 이상) 처리
- 연산이 CPU 집약적이고 각 작업이 서로 독립적일 때
- 예: 이미지 필터 처리, 수치 계산, 웹 크롤링 등
// 병렬 처리에 적합한 예 (LongStream.rangeClosed 사용)
long goodParallelSum = LongStream.rangeClosed(1, 10_000_000)
.parallel()
.sum();- 장점: 쉽게 분할 가능한 범위 생성
- 결과: 순차 처리보다 빠름!
실제로는 JMH와 같은 도구로 벤치마크 후 사용하는 것이 가장 정확
4. 병렬 스트림 사용 시 주의사항
공유 상태 수정 금지
- 공유 상태(전역 변수 등)를 변경하는 연산은 병렬 처리 시 오류 발생 가능 (ex. race condition)
// 위험한 예: 공유 변수 사용
class Accumulator {
public long total = 0;
public void add(long value) { total += value; }
}
Accumulator acc = new Accumulator();
LongStream.rangeClosed(1, 10_000).parallel().forEach(acc::add);- 문제:
total에 대한 데이터 레이스 발생 - 해결: 상태 없는(stateless) 연산 사용
적절한 자료구조 선택
| 자료구조 | 병렬 적합성 | 이유 |
|---|---|---|
ArrayList | ⭐️⭐️⭐️⭐️⭐️ | 랜덤 액세스, 쉬운 분할 |
LinkedList | ⭐️ | 순차 접근 필요 |
IntStream.range | ⭐️⭐️⭐️⭐️⭐️ | 고정 크기, 예측 가능한 분할 |
5. 병렬 스트림 최적화 전략
1. 기본형 스트림 사용
`// 박싱/언박싱 오버헤드 제거
LongStream.rangeClosed(1, 1_000_000) // 기본형
.parallel()
.sum();`2. 순서 의존성 피하기
`// 비효율적
list.parallelStream()
.sorted() // 전체 데이터 수집 필요
.forEach(System.out::println);
// 효율적
list.parallelStream()
.unordered() // 순서 무시
.forEach(System.out::println);`
3. 적절한 작업 크기 설정
- 소규모 데이터(1,000개 미만): 순차 처리 권장
- 대규모 데이터(100만개 이상): 병렬 처리 유리
6. 병렬 처리에 적합한 연산 예시
CPU 집약적 작업
// 이미지 처리
images.parallelStream()
.map(img -> applyFilter(img)) // 고비용 연산
.collect(Collectors.toList());독립적인 작업
// 웹 페이지 크롤링
urls.parallelStream()
.map(url -> downloadContent(url)) // I/O 작업
.collect(Collectors.toList());7. 성능 측정 팁
JMH를 이용한 정확한 측정
`@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class MyBenchmark {
@Benchmark
public void testMethod() { // 성능 측정할 코드
}
}`- 주의: JVM 웜업 시간 고려, 여러 번 실행 후 평균값 사용
Fork/Join Framework
- 자바 7부터 도입된 ForkJoinPool을 이용해 작업을 분할(Fork) 하고, 결과를 합침(Join) 으로써 병렬 실행을 가능하게 한다.
- 병렬 스트림도 내부적으로 이 프레임워크를 사용한다.
예시: 1GB 넘는 JSON 로그 파일이 있음 (배열 형태로 수천 개 객체가 들어 있음). 이걸 한 번에 파싱하면 메모리도 터지고, 시간도 오래 걸림.
- 이 리스트가 너무 길면 → 작게 나누고 (Fork) → 각각 파싱한 뒤 → 합친다 (Join).
- 결과적으로 파싱 속도 향상
병렬 처리의 작업 분할 및 실행을 담당하는 클래스
// RecursiveTask<T>는 결과를 반환하는 병렬 작업 클래스
class JsonParseTask extends RecursiveTask<List<MyData>> {
private List<String> lines; // 파싱 대상인 JSON 문자열 목록
protected List<MyData> compute() {
// 작업 크기가 작다면 그냥 순차적 처리
// Fork/Join은 너무 잘게 쪼개면 오히려 오버헤드가 크다.
// 작업 분할과 병합, 스레드 관리 등 병렬 처리 자체에 드는 부가 비용
if (lines.size() <= 1000) {
return lines.stream().map(JsonUtils::parseLine).toList();
}
// 리스트를 절반으로 나눠서 왼쪽/오른쪽 나눈다.
int mid = lines.size() / 2;
JsonParseTask left = new JsonParseTask(lines.subList(0, mid));
JsonParseTask right = new JsonParseTask(lines.subList(mid, lines.size()));
// 모든 작업을 fork 하면 스레드가 과하게 생성될 수 있음
left.fork(); // 왼쪽 작업 비동기 시작!
List<MyData> rightResult = right.compute(); // 오른쪽은 지금 이 스레드에서 처리
List<MyData> leftResult = left.join(); // 왼쪽 작업이 끝날 때까지 기다림
leftResult.addAll(rightResult);
return leftResult;
}
}
이를 실행하는 스레드 풀(ForkJoinPool) 을 제공
// 1. ForkJoinPool을 명시적으로 설정
public static void main(String[] args) {
List<String> lines = ... // JSON 라인 데이터 준비
// ForkJoinPool을 명시적으로 설정 (예: 4개의 스레드 사용)
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
// JsonParseTask 실행
JsonParseTask task = new JsonParseTask(lines);
List<MyData> result = forkJoinPool.invoke(task); // ForkJoinPool에서 병렬 실행
// 결과 처리
result.forEach(System.out::println);
}
// 2. parallelStream() 사용하기
// - parallelStream() 활용하면 ForkJoinPool을 내부적으로 사용하여 병렬 처리를 쉽게 구현
public static void main(String[] args) {
List<String> lines = ... // JSON 라인 데이터 준비
// parallelStream()을 사용해서 스트림을 병렬 처리
List<MyData> result = lines.parallelStream()
.map(JsonUtils::parseLine)
.collect(Collectors.toList());
// 결과 처리
result.forEach(System.out::println);
}
Spliterator 인터페이스
Spliterator란?
- "Split + Iterator"의 합성어
Spliterator는 Java Stream이 데이터를 병렬로 쪼갤 수 있도록 지원하는 인터페이스- 커스텀 분할, 스트림 병렬 처리 최적화
예시: 아주 큰 log 파일 한 줄씩 병렬 처리
// `Spliterator`를 커스터마이징해서 병렬 처리에 필요한 제어를 직접 수행
public class LogFileSpliterator implements Spliterator<String> {
private final BufferedReader reader;
public LogFileSpliterator(BufferedReader reader) {
this.reader = reader;
}
// `Stream`이 데이터를 처리할 때 `BufferedReader`로 한 줄씩 읽어서 `Stream`에 넘긴다.
// 이 메서드는 Stream 내부에서 계속 호출된다.
@Override
public boolean tryAdvance(Consumer<? super String> action) {
try {
String line = reader.readLine();
if (line == null) return false; // 다음 줄이 없다면
action.accept(line);
return true;
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
// 병렬 처리를 위해 일을 나눠주는 메서드
// 예시: 현재 reader 상태에서 일정 줄 수(1000줄)만큼 분할해서 새로운 Spliterator 생성
// => 이 덩어리를 Java가 병렬로 처리할 수 있도록 Spliterator로 반환
@Override
public Spliterator<String> trySplit() {
List<String> chunk = new ArrayList<>();
try {
for (int i = 0; i < 1000; i++) {
String line = reader.readLine();
if (line == null) break;
chunk.add(line);
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
if (chunk.isEmpty()) return null;
return chunk.spliterator(); // chunk는 Stream에서 병렬 분할 가능
}
// 대충. `Stream`이 내부적으로 "데이터가 얼마나 있지?"를 예측할 수 있도록 힌트
// => Stream이 적절히 분할(split) 하려면 대략적인 데이터 양을 알아야 효율적으로 스레드를 배분할 수 있다.
@Override
public long estimateSize() {
return Long.MAX_VALUE;
}
@Override
public int characteristics() {
return ORDERED | NONNULL;
}
}
// 호출
BufferedReader reader = Files.newBufferedReader(Paths.get("large-log.txt"));
Stream<String> lines = StreamSupport.stream(new LogFileSpliterator(reader), true); // 병렬 처리
lines.filter(line -> line.contains("ERROR"))
.forEach(System.out::println);
