블로그에 포스팅하는 내용들은 강의 전체 내용이 아닌 내 기준, 나한테 필요한 내용들 기억하고 싶은 내용들 위주입니다
해당 내용의 출처는 LG Aimers(https://www.lgaimers.ai)에 있습니다
Part 2. 합성곱 신경망 기반의 시계열 회귀
Convolutional Neural Network(CNN)
합성곱 신경망 : Convolutoin 연산을 통해 이미지로부터 필요한 feature를 스스로 학습할 수 있는 능력을 갖춘 심층 신경망
CNN Basics
Image Representaion
이미지를 어떻게 컴퓨터한테 숫자로 인식시킬 것인가
컴퓨터는 이미지를 3차원의 Tensor로 표현함
Width X Height X 3(RGB)
각 pixel들을 입력 노드로 간주하고 서로 다른 가중치로 연결하게 되면 input layer와 hidden layer 사이 너무 많은 가중치가 생김(width X height X 3 X hidden layer node 수) => 따라서 Convolution 연산을 사용
Image convolution : 특정 속성을 탐지하는데 사용되는 matrix

여기서 3X3 matrix를 filter라고 표현, 이 filter를 image에 건다고 표현
filter를 통해 이미지의 feature를 추출
CNN 이전에는 이 filter들을 직접 고안함
CNN은 이러한 filter를 데이터를 통해 스스로 학습함
합성곱 신경망 : 합성곱 연산을 통해 이미지로부터 필요한 feature를 스스로 학습한다
이미지의 특성
- 인접 픽셀간 높은 상관관계(spatially-local correlation)
- 이미지의 부분적 특성(눈, 귀 등)은 고정된 위치에 등장하지 않음(feature invariance)
Convoultion
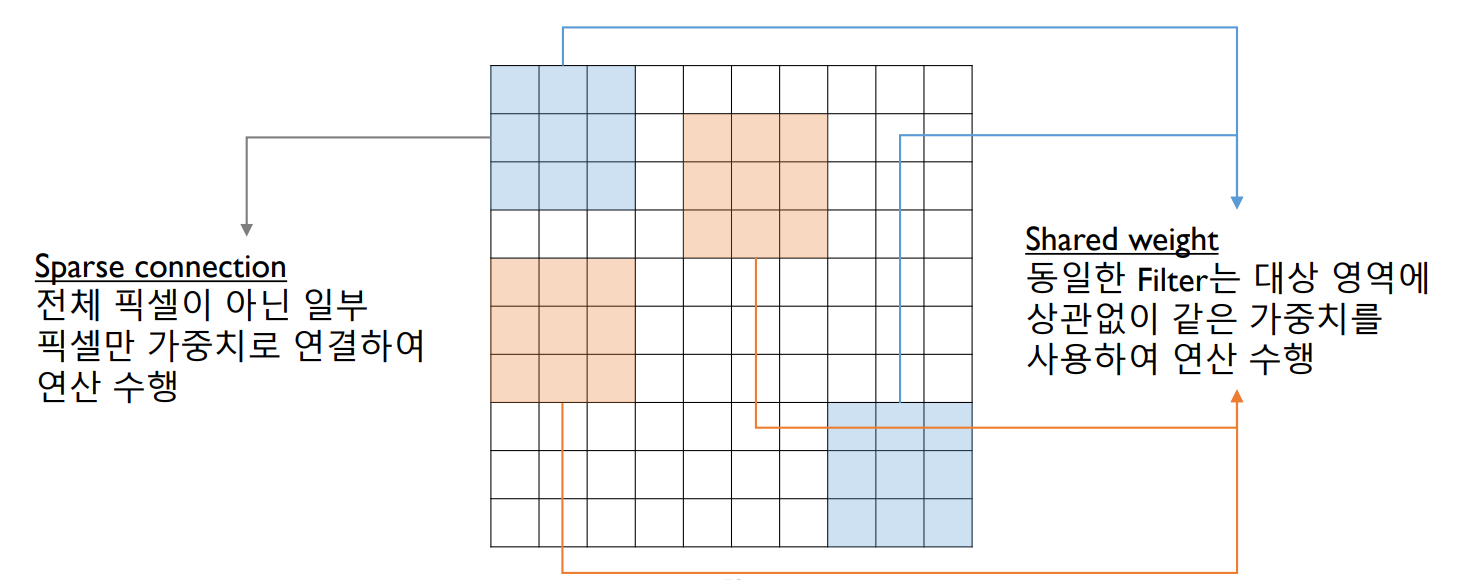
Sparse connection
- spatialy-local correlation 고려
- 인접 변수만을 이용해 새 feature 생성
Shared weight
- invariant feature 추출
- 같은 대상 크기에는 위치가 다르더라도 동일한 weight를 적용
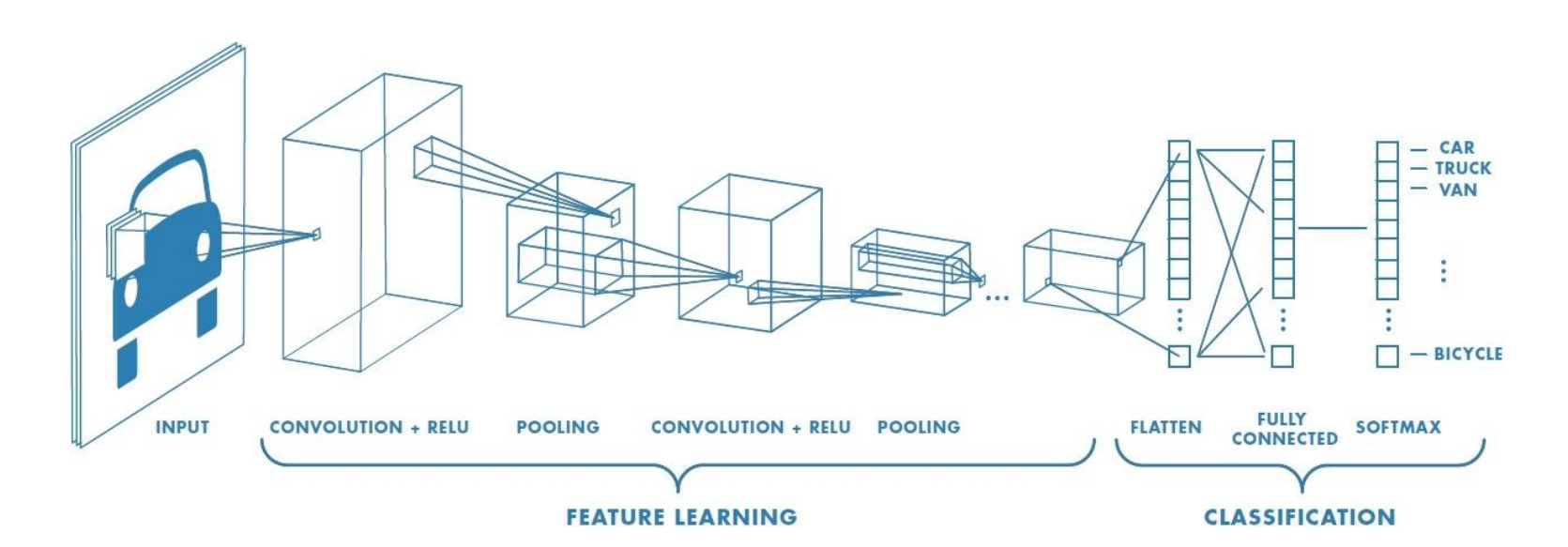
세 가지의 연산 반복
Convolution 연산
Activation 연산 : 비선형 활성화
Pooling 연산 : 차원을 줄임
=> 이걸 반복하며 데이터의 feature를 학습
Flatten : tensore 형태의 data를 1차원으로 펼침
Convolution
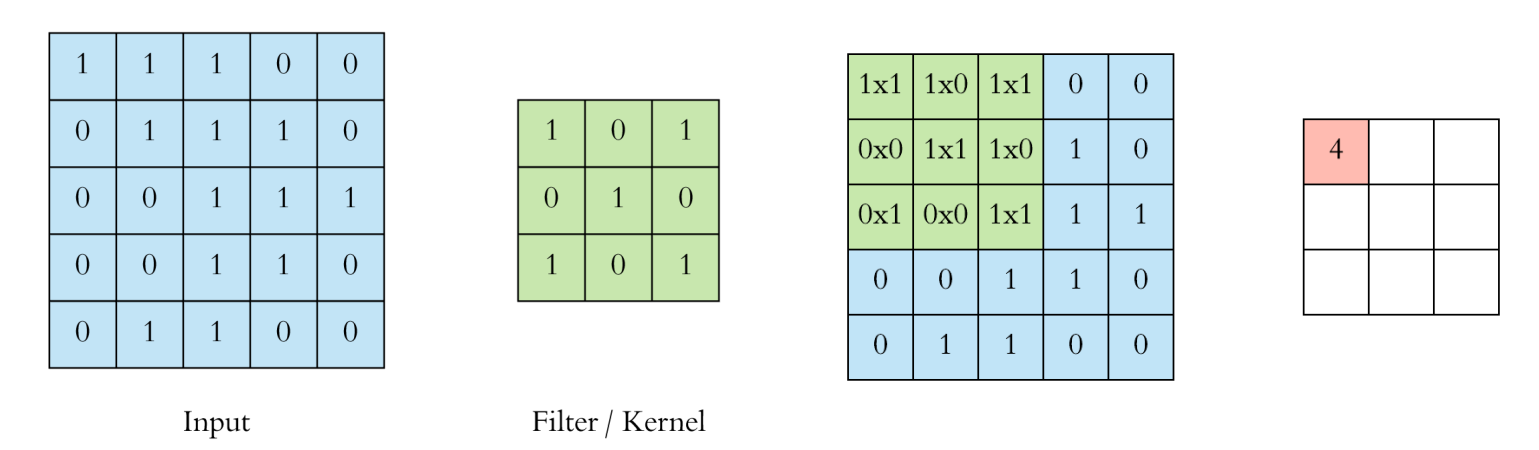
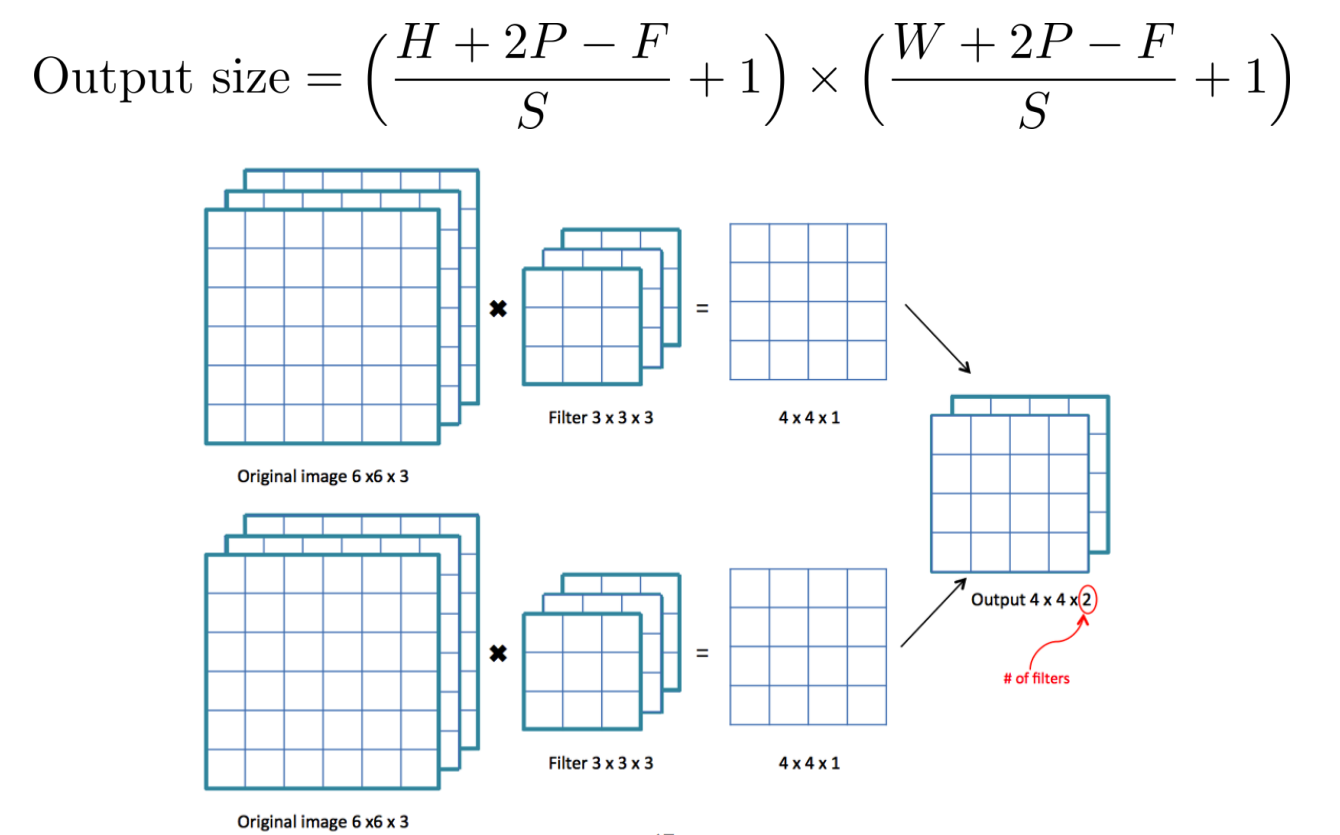
input data에 filter/kernel을 씌움(=요소별로 곱 연산)
이미지가 3차원 Tensor이므로 filter 역시 3차원
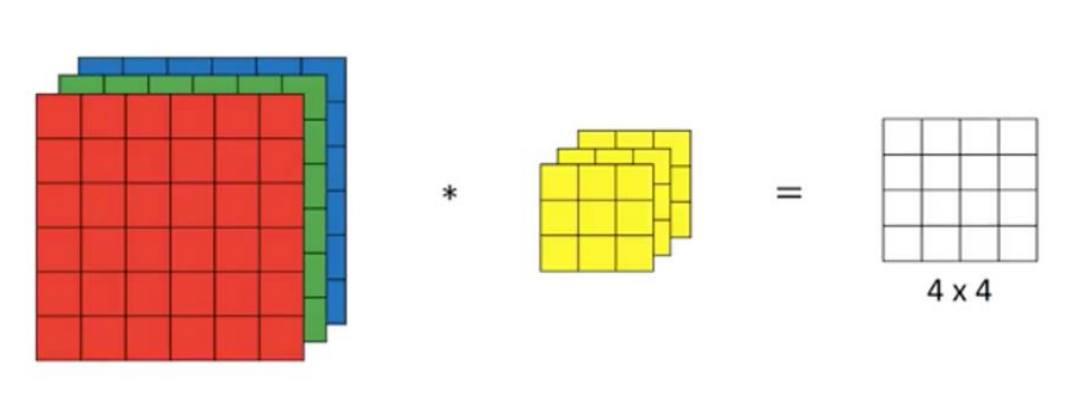
각 rgb 채널별로 결과가 나오면 그걸 합쳐줘서 첫 번째 cell의 값을 만듬
즉 이미지와 filter는 동일한 depth를 가짐
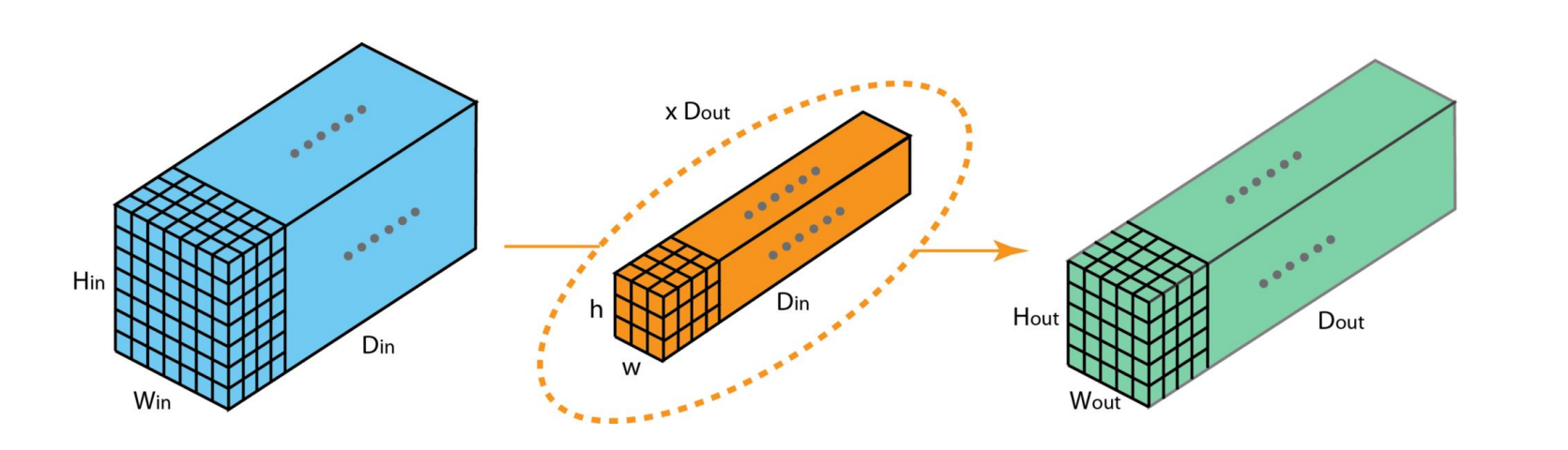
이미지 : Hi X Wi X Di
filter : Hf X Wf X Di, 그리고 Dout(filter 수)
output : Ho X Wo X Dout
filter가 한번에 한 칸씩 이동하면 너무 오래 걸린다
- Stride : filter가 한번에 여러 칸 이동
가장자리 pixel은 중앙부보다 conv 연산이 적게 수행됨
- Padding : 테두리에 0 값인 pad 추가
Output size 계산
Activation
convolution을 통해 학습된 값들을 비선형 변환 수행
- 선형 조합만 사용하면 결국 결과는 선형조합임
- 복잡한 관계식을 찾기 위함
ReLU(GLU.. 등) 사용
- 0보다 작은 값은 0으로 변환
- 0보다 크면 자기 자신
Pooling
고차원의 Tensor를 Compact하게 축약
Max Pooling, Average Pooling
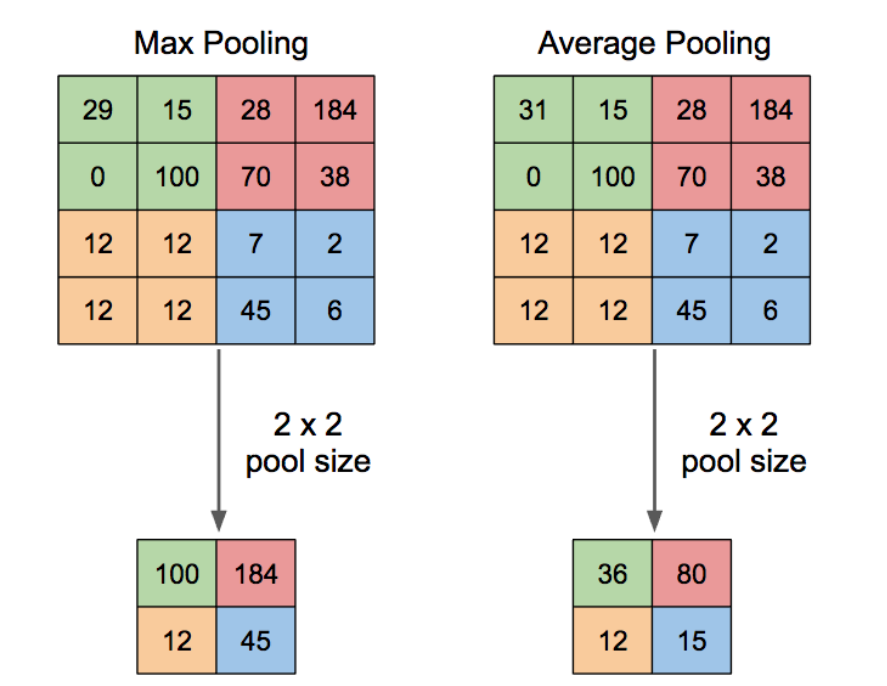
이미지의 경우, 도드라지는 특징을 보존하는게 더 효과있음(max pooling)
시계열 경우 상황 따라서(특정 시점이 중요한지, 전체 흐름이 중요한지)
Strided Convolution
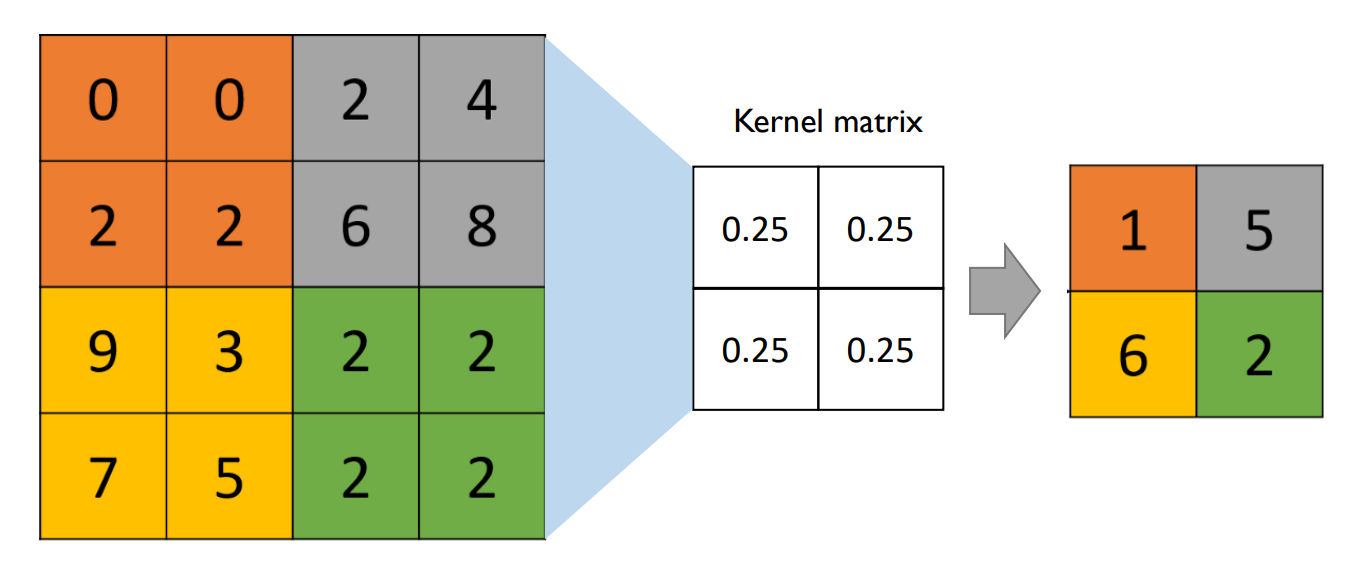
average pooling은 strided convolution의 특수 케이스이다
Flatten
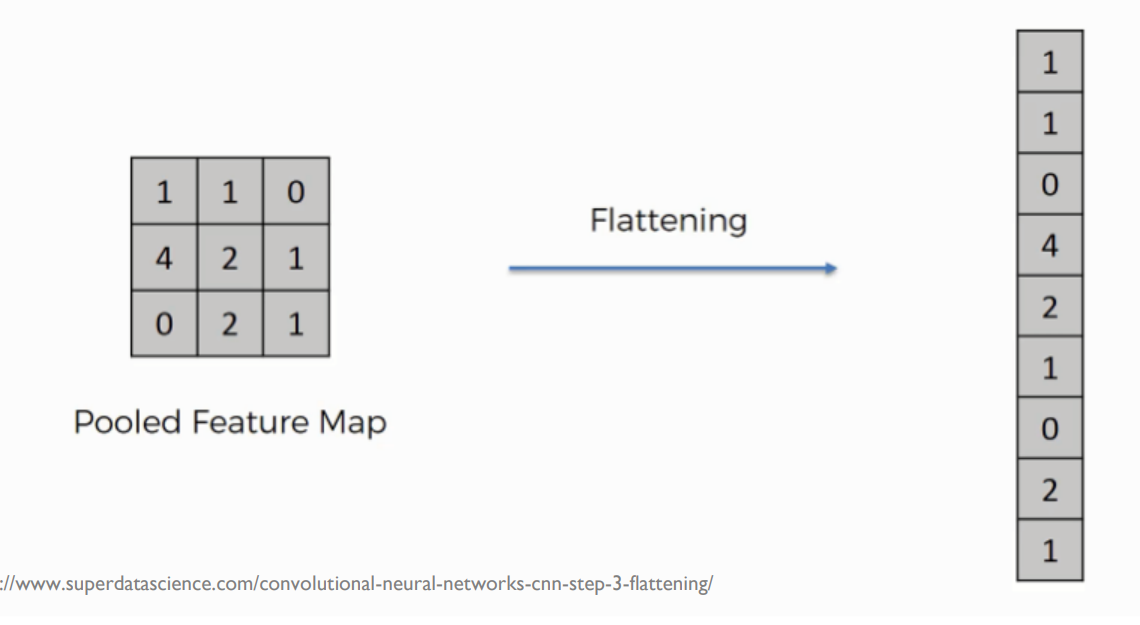
3차원 Tensor를 1차원의 vector로 변환
마지막 분류 문제를 해결하기 위함
하이퍼파라미터
convolution filter 크기, 수
stride, padding 크기
CNN Architecture
AlexNet
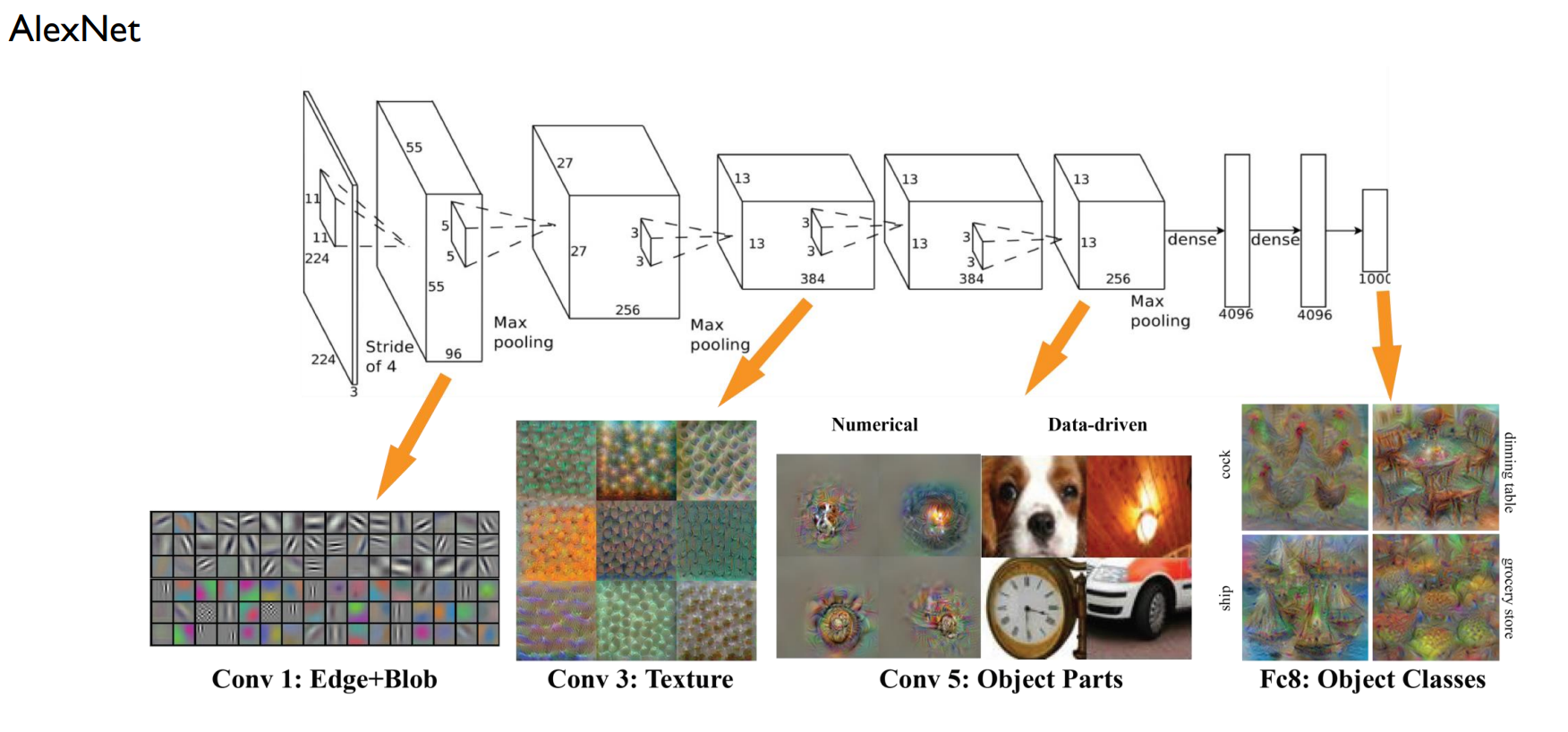
원본 image를 224X224로 resize => 224X224X3 tensor
11X11은 filter(11X11X3) 96개, stride 4 => 초반에는 넓게 듬성듬성 보고 후반에는 좁고 세밀하게
output은 55X55(55X55X96)
max pooling
5X5 filter(55X5X256) 256개
output 27X27X256
3X3 filter(3X3X384) 384개
output 13X13X384
3X3 filter(3X3X384) 384개
output 13X13X384
3X3 filter(3X3X256) 256개
output 13X13X256
(즉 convolution 5번)
flatten해서 4095 차원 dense layer
최종적으로 classification

fully connected layer는 마지막 flatten했던 dense layer 2개
VGGNet
backbone, 즉 이미지 데이터 처리의 기본 구조로 많이 사용됌
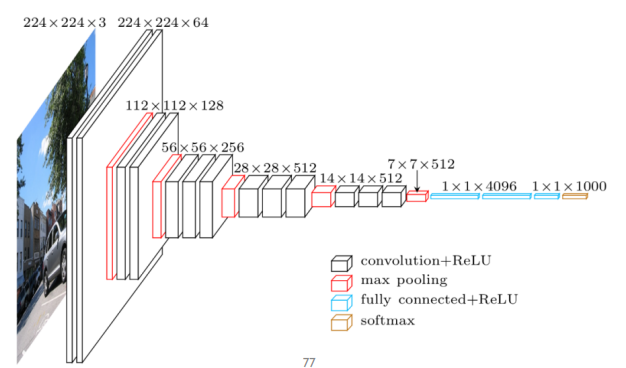
3X3 convolutoin with stride 1을 기본 연산으로, 중간 중간에 2X2 max pooling 섞음
CNN for Time-Series Data
time series data 가정 : 모든 변수는 동일한 주기로 수집
- classification
- regression
- anomaly detection
시계열 데이터는 spatial correlation이 존재하지 않음
시간축으로 움직이는 convolution만이 의미있음 (변수축은 의미X)
1-D Convolution
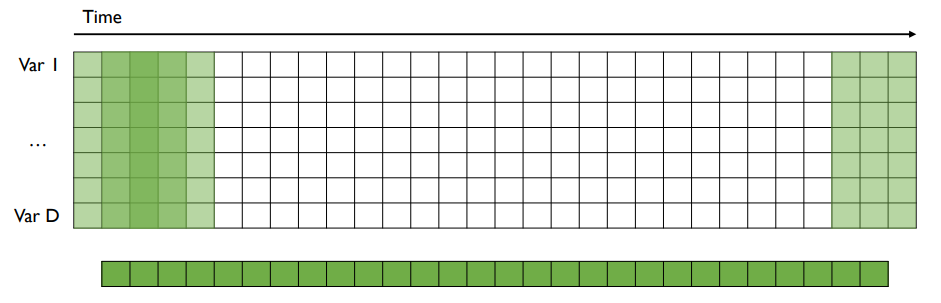
...
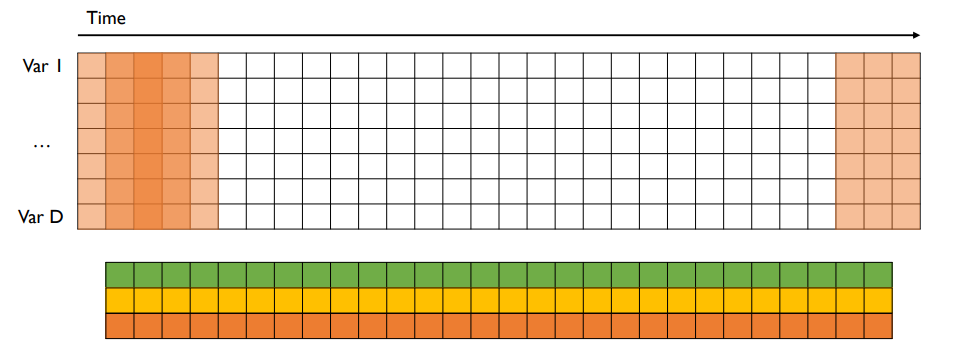
모든 변수를 한 번에 고려하여 시간 축으로만 convolution 연산을 수행 (즉 filter 크기가 정사각형이 아닐 수 있으며 height는 변수 개수)
결과는 1개의 vector
vector 개수는 filter 개수와 동일
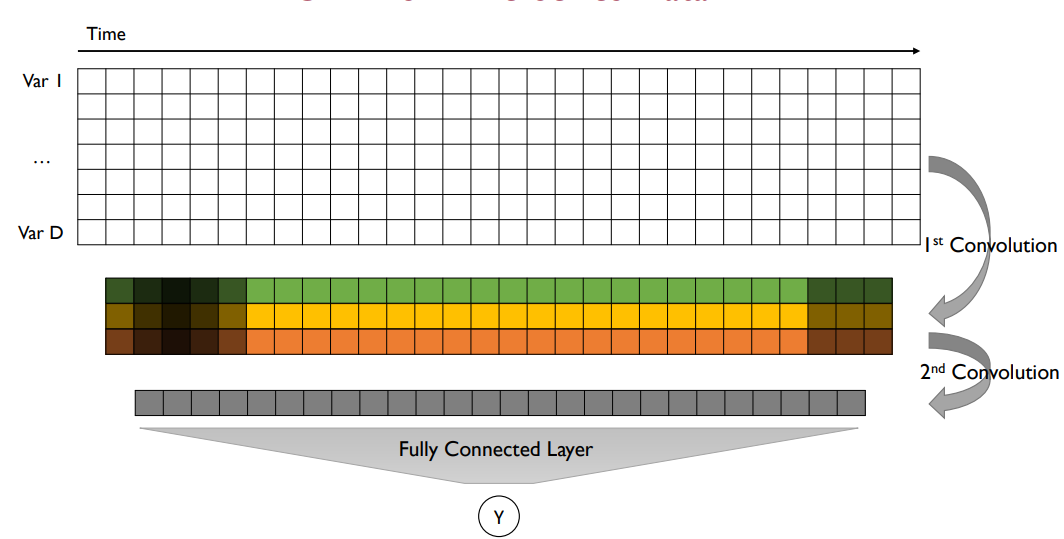
반복적으로 가능
Dilated Convolution
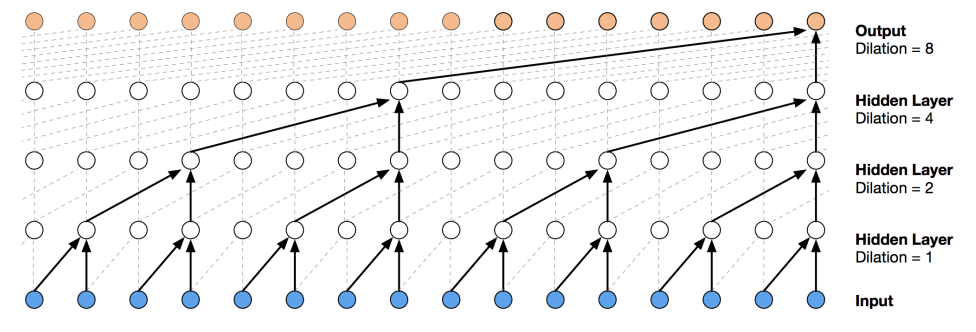
standard convolution은 항상 인접한 연속된 시점의 데이터에 대한 합성곱 연산을 수행
따라서 합성곱 연산을 띄엄띄엄하는게 dilated conv
긴 길이의 시계열 데이터를 효과적으로 처리함(더 과거의 시점을 고려함)
Summary

