📔설명
정규화, 관계 및 조인, 트랜잭션, NULL속성, 본질식별자와 인조식별자의 차이에 대해 알아보자
🧂정규화
1. 제1정규형 : 모든 속성은 반드시 하나의 값을 가져야 한다
제1정규형 : 하나의 속성에는 하나의 값
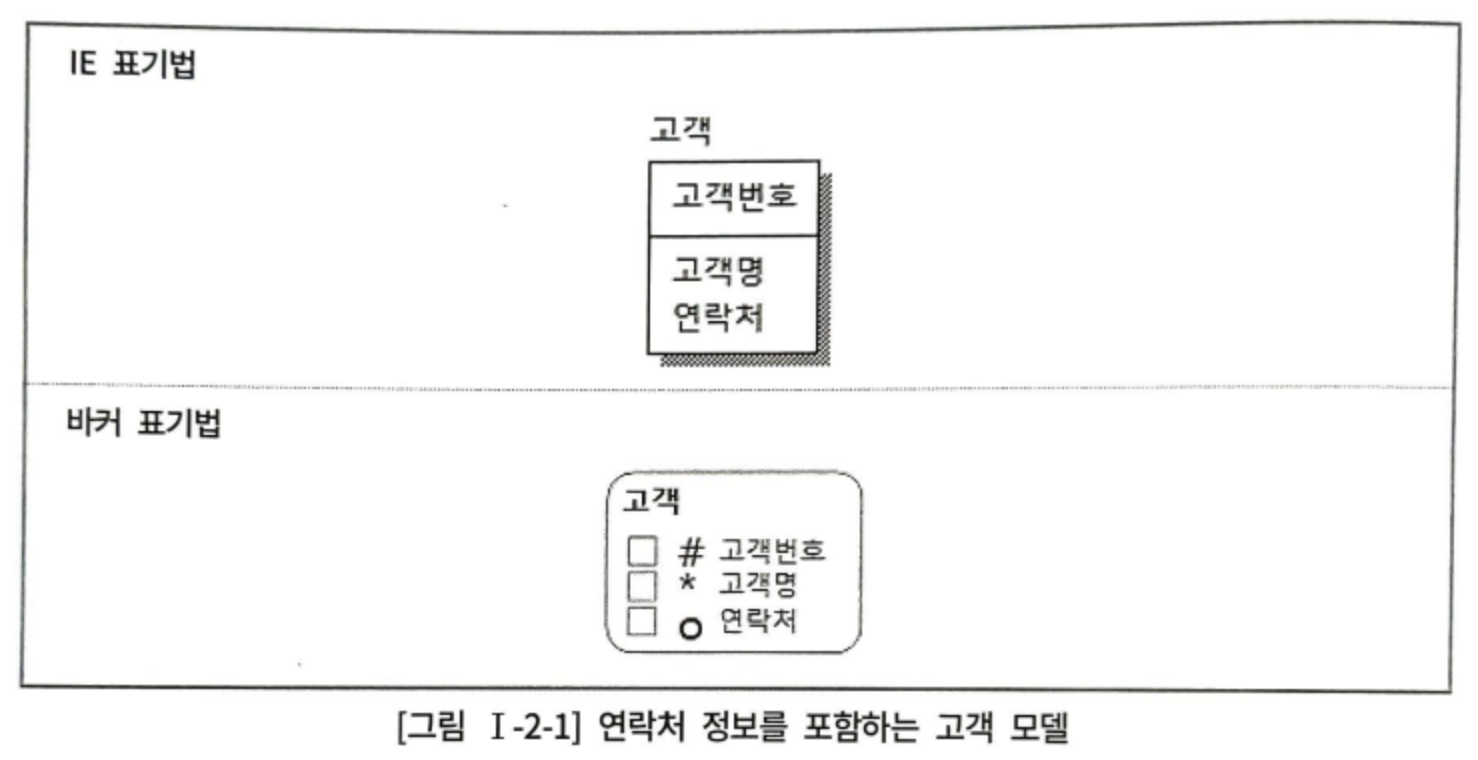
위의 모델에서 연락처 속성에 다중값이 들어가는 경우
| 고객번호 | 고객명 | 연락처 |
|---|---|---|
| 10000 | 정우진 | 02-123-4567, 010-1234-5678 |
| 10001 | 한형식 | 010-5678-2345 |
연락처에서 집전화 번호와 휴대폰 번호를 구별하기 어려움
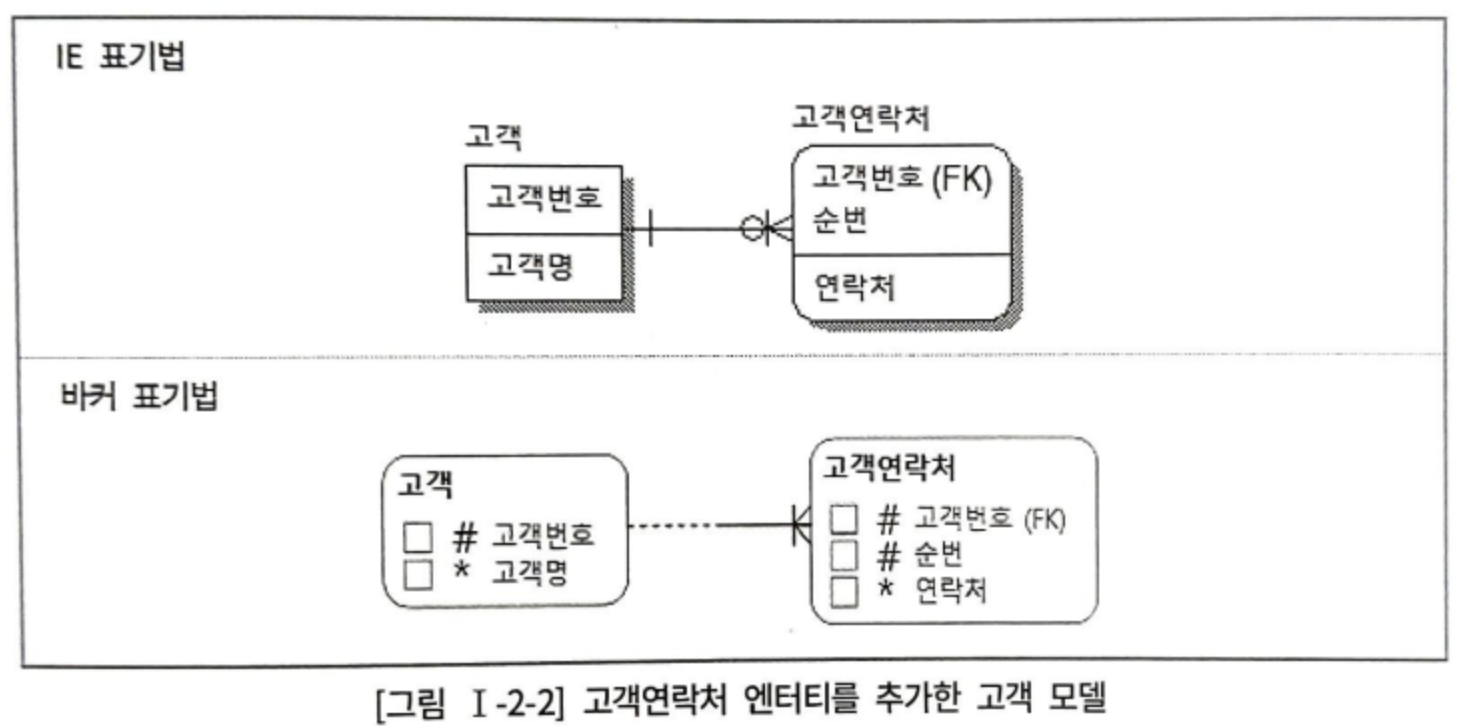
고객연락처라는 엔터티를 추가하여 다중값에 대한 문제점 해결
고객
| 고객번호 | 고객명 |
|---|---|
| 10000 | 정우진 |
| 10001 | 한형식 |
고객연락처
| 고객번호 | 순번 | 연락처 |
|---|---|---|
| 10000 | 1 | 02-123-4567 |
| 10000 | 2 | 010-1234-5678 |
| 100001 | 1 | 010-5678-2345 |
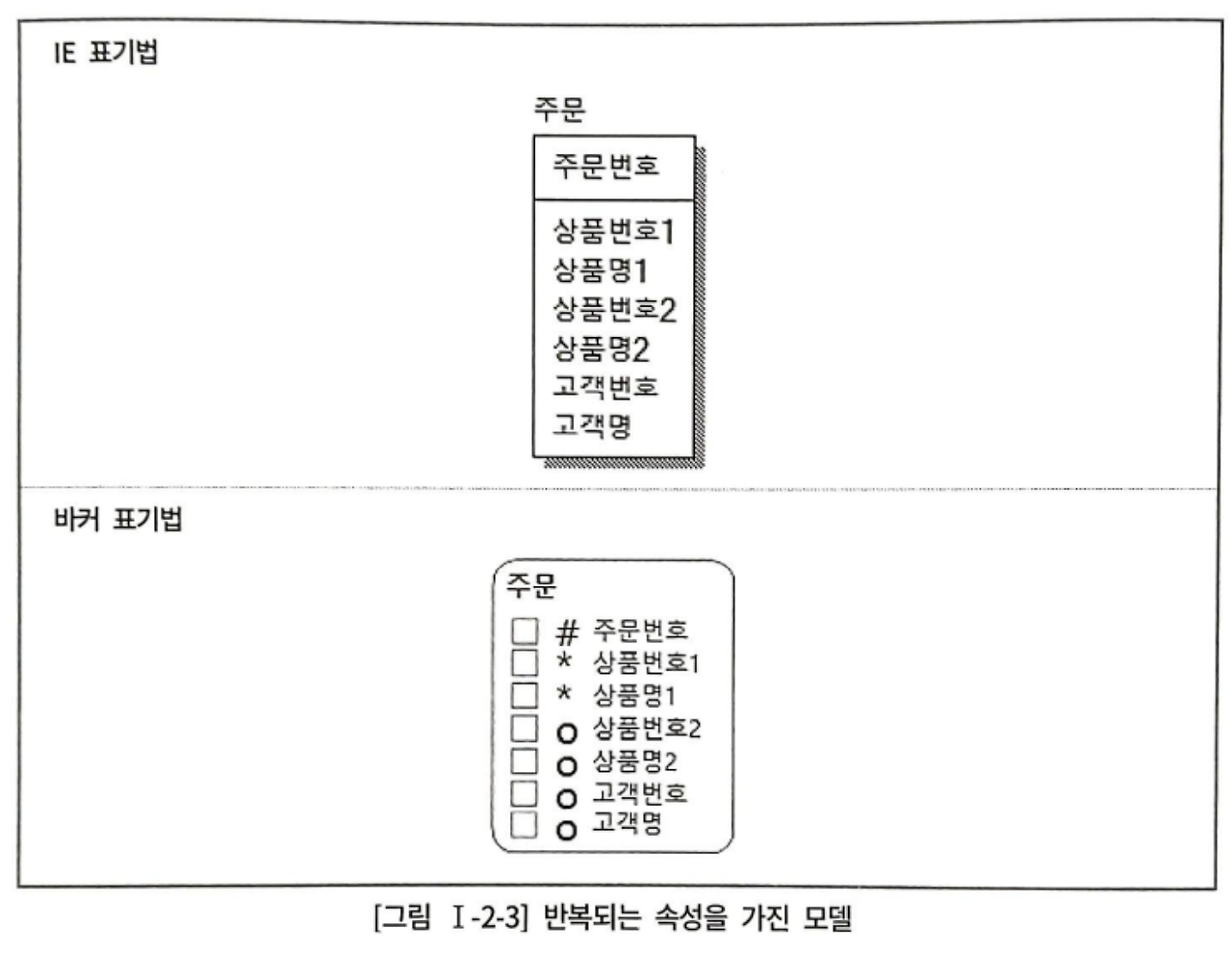
위 모델에서 다른 유형의 중복 데이터도 제1정규형을 위배한다.
위의 모델에서는 상품을 3개이상 주문할 수 없다.
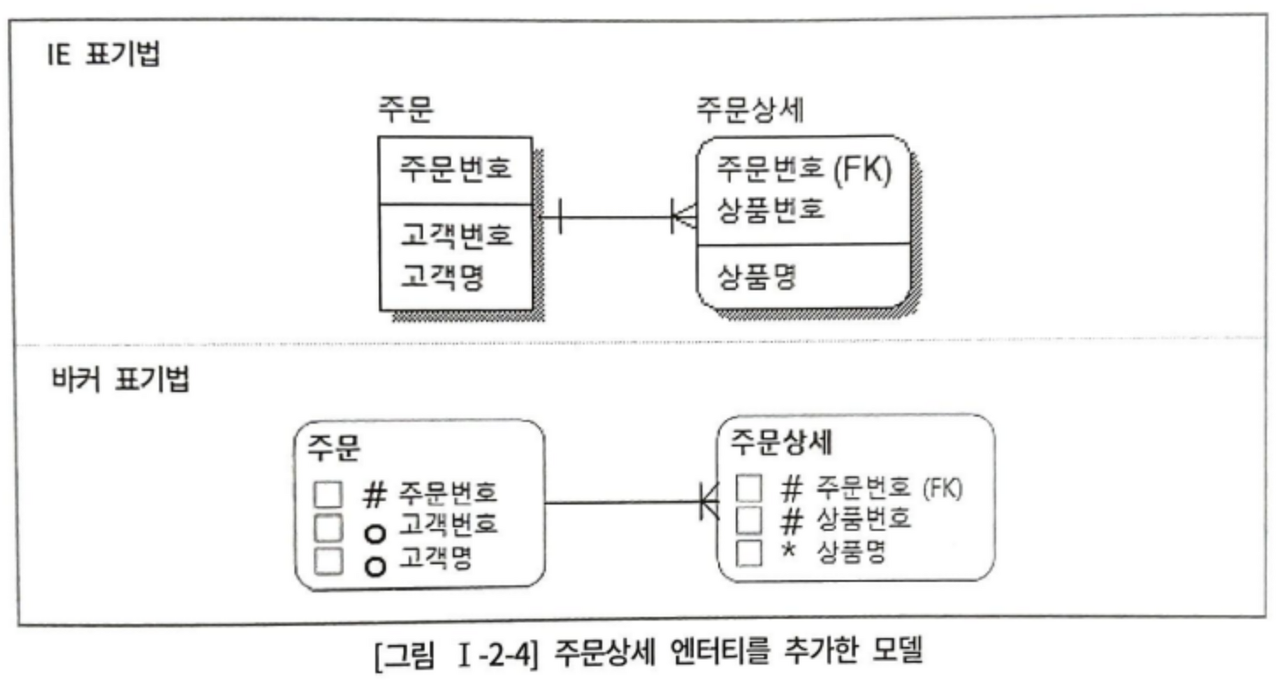
주문상세 엔터티를 추가하면 상품을 몇 개 주문하던 제약을 받지 않는다.
2. 제2정규형 : 엔터티의 일반속성은 주식별자 전체에 종속적이어야 한다
주문상세 엔터티를 추가한 모델에서 상품명 속성이 상품번호에 대해서만 반복되어 쌓이는 구조가 된다.
주문상세
| 주문번호 | 상품번호 | 상품명 |
|---|---|---|
| 1100001 | 256 | SQL 전문가 가이드 |
| 1100002 | 257 | 친절한 SQL 튜닝 |
| 1100003 | 256 | SQL 전문가 가이드 |
상품명 SQL 전문가 가이드 데이터가 반복되고 있다.
상품명은 주문번호와 관계없이 오로지 상품번호에 의해서만 결정 =>종속적
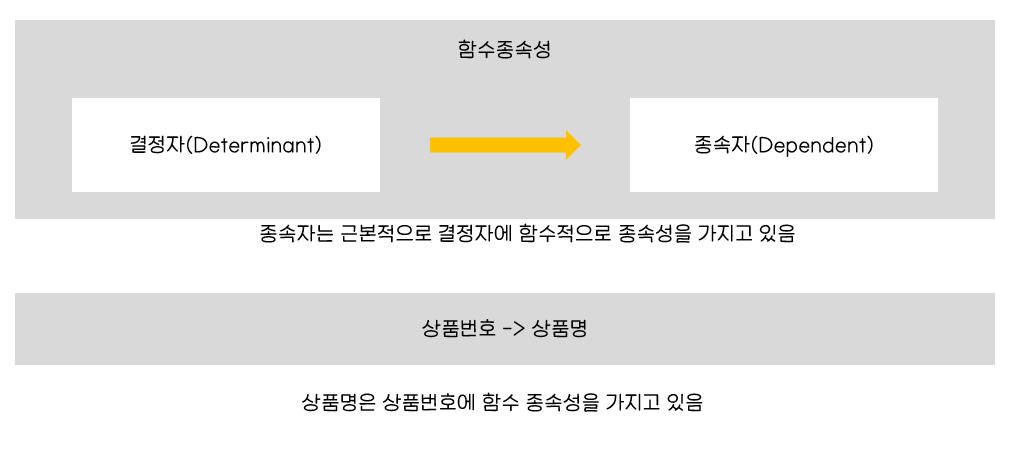
함수종속성 : 데이터들이 어떤 기준값에 의해 종속되는 현상
결정자 : 기준값
종속자 : 종속되는 값
부분 종속 : 주문상세 엔터티에서 상품명이 식별자 전체가 아닌 일부에만 종속적
=> 엔터티의 일반속성은 주식별자 전체에 종속적이어야 한다는 제2정규형 위배
=> 상품명이 변경된다면 중복된 상품명을 모두 변경해야하며, 변경 중 특정 시점에는 아직 변경되지 않은 상품명이 존재하고 트랜잭션이 들어온다면 일관되지 않은 데이터 조회
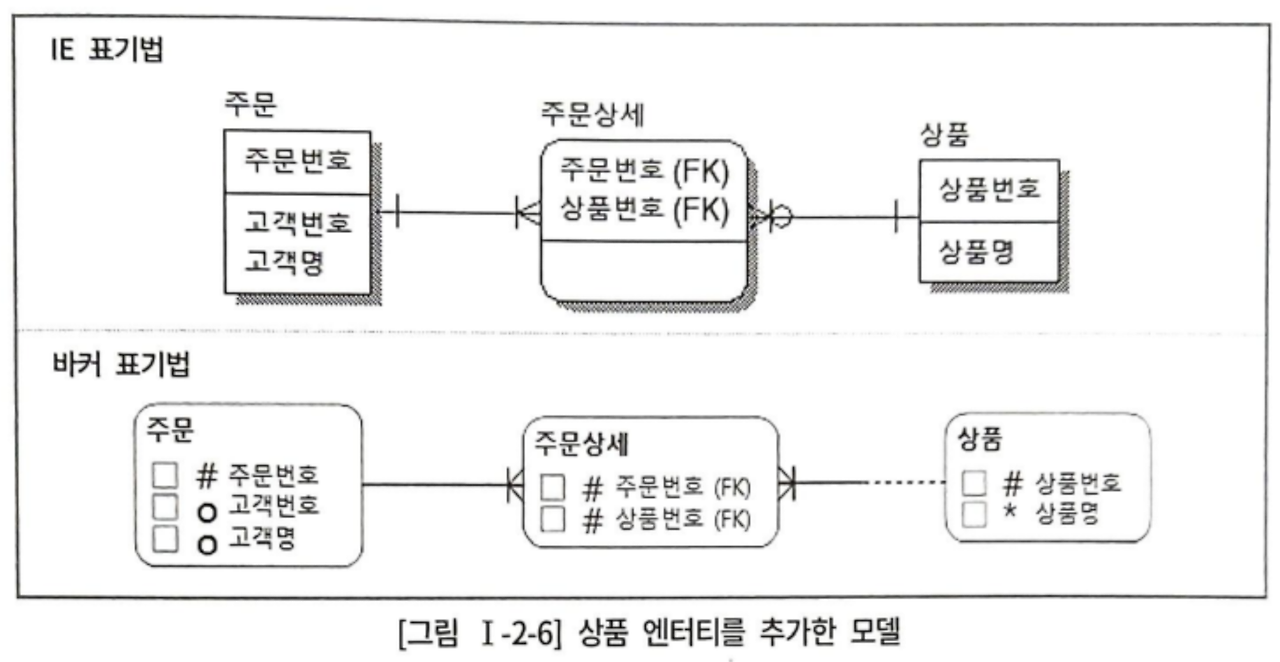
상품 엔터티를 추가해 주문상세 엔터티의 부분 종속성 제거 가능
주문상세
| 주문번호 | 상품번호 |
|---|---|
| 1100001 | 256 |
| 1100002 | 257 |
| 1100003 | 256 |
상품
| 상품번호 | 상품명 |
|---|---|
| 256 | SQL 전문가 가이드 |
| 257 | 친절한 SQL 튜닝 |
3. 제3정규형 : 엔터티의 일반속성 간에는 서로 종속적이지 않는다
제3정규형 : 이행적 종속을 배제
위의 모델에서 주문 엔터티를 보면, 고객번호는 주문번호에 종속적이고, 고객명은 고객번호에 종속적이다. 이는 고객명이 주문번호에 종속적이며 이행적 종속(Transitive Depencdency)이라 함
만일 고객명이 변경된다면, 주문엔터티의 고객명을 전부 갱신해야 하며, 데이터 중복으로 발생하는 문제는 성능 부하 및 정합성 오류를 유발함
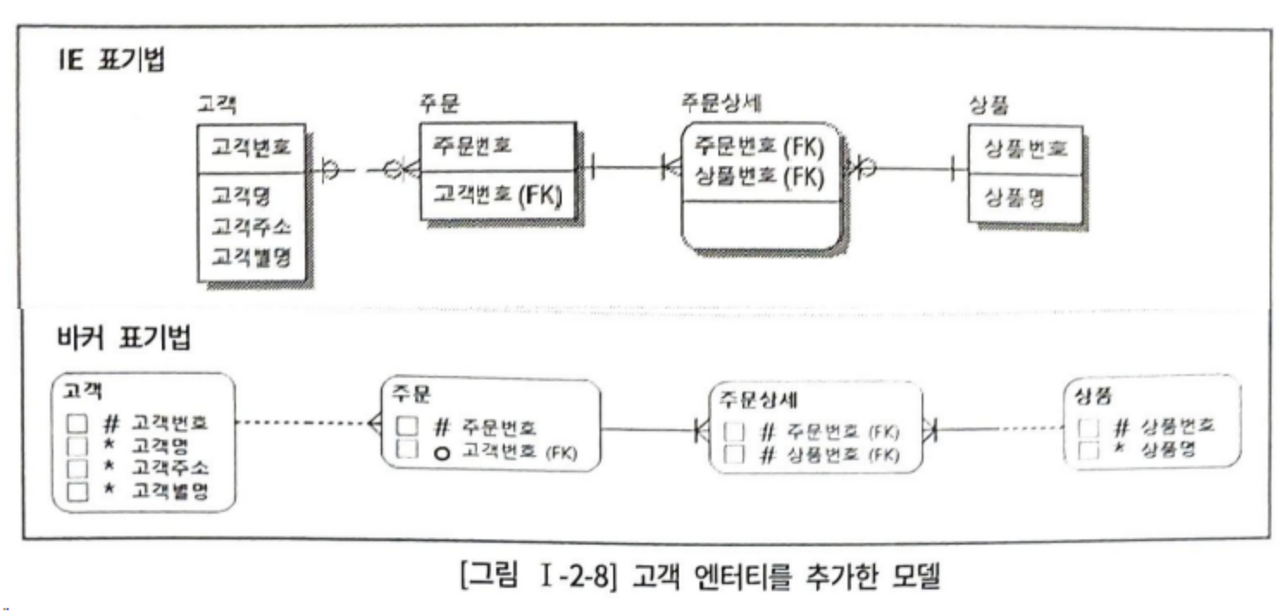
고객 엔터티를 추가해 고객 속성에 대한 변경이 주문 엔터티에 이제 영향을 주지 않는다.
4. 반정규화와 성능
반정규화 : 정규화를 반대로 하는 것, 성능을 위해 데이터 중복을 허용
정규화 : 데이터 중복을 최소화
반정규화를 적용한 모델에서 성능이 향상될 수 있는 경우
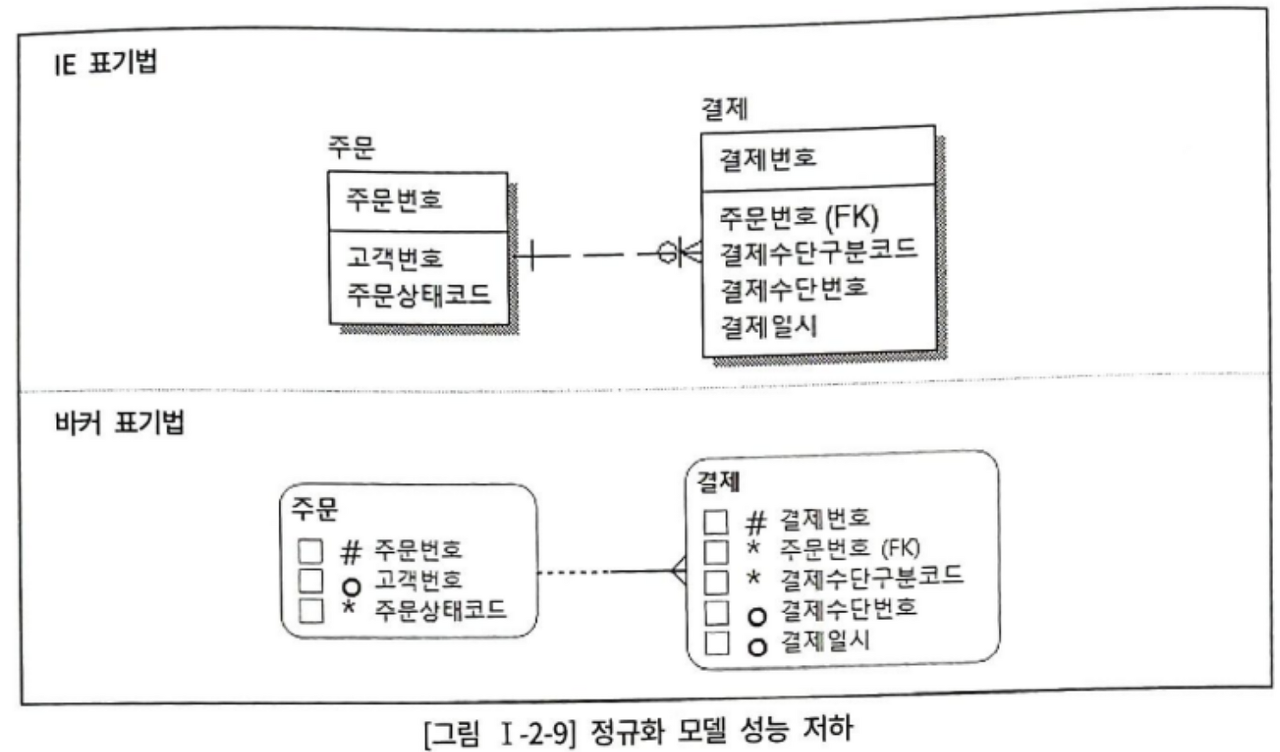
-- 최근 결제정보를 미리 셋팅하여 고객에게 보여주고자 할 때
SELECT A.결제수단번호
FROM (SELECT B. 결제수단번호
FROM 주문 A, 결제 B
WHERE A.주문번호 = B.주문번호
AND A.고객번호 = 1234
AND B.결제수단구분코드 = '신용카드'
ORDER BY B.결제일시 DESC
) A
WHERE ROWNUM = 1;위 쿼리는 1234 고객의 주문내역이 많을 수록 성능이 나빠진다.
조인된 결제정보를 모두 읽고 내림차순 정렬 후 최근 1건의 데이터를 가져오기 때문에 조인 부하가 증가
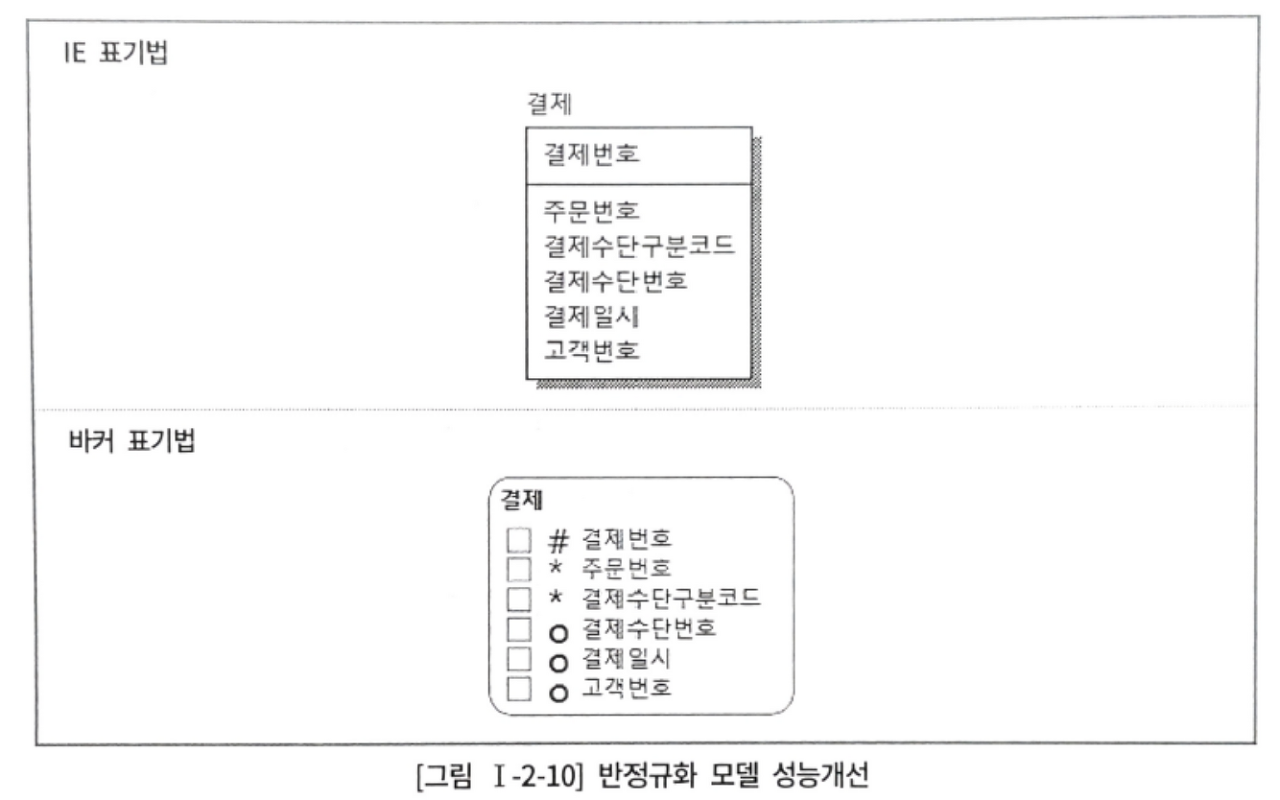
--결제 엔터티에 고객번호를 반정규화
SELECT A.결제수단번호
FROM (SELECT A.결제수단번호
FROM 결제 A
WHERE A.고객번호 = 1234
AND A.결제수단구분코드 = '신용카드'
ORDER BY A.결제일시 DESC
) A
WHERE ROWNUM = 1;고객번호+결제수단구분코드+결제일시 인덱스를 통해 index_desc로 최종 1건을 읽어 결제수단번호를 가져올 수 있다.
반정규화를 적용한 모델에서 성능이 저하될 수 있는 경우
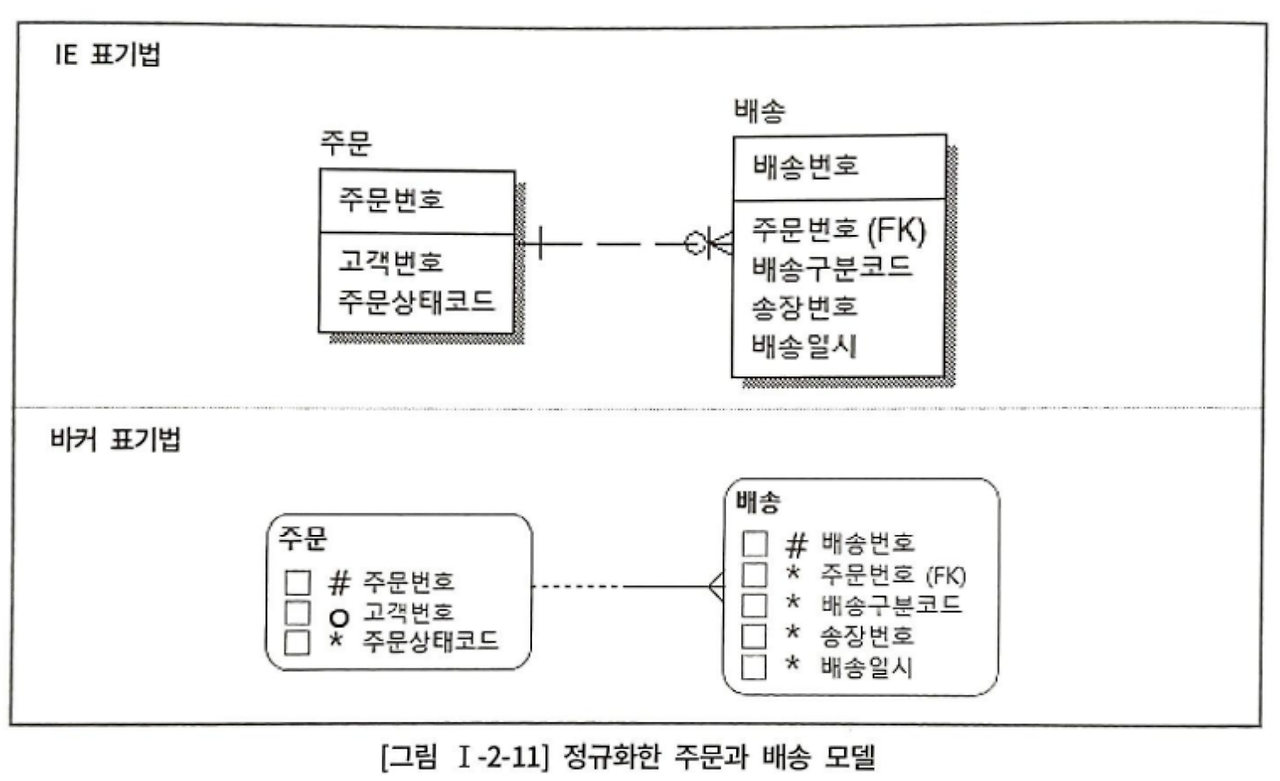
업무적으로 보면 고객이 주문한 후, 판매자가 배송을 한다.
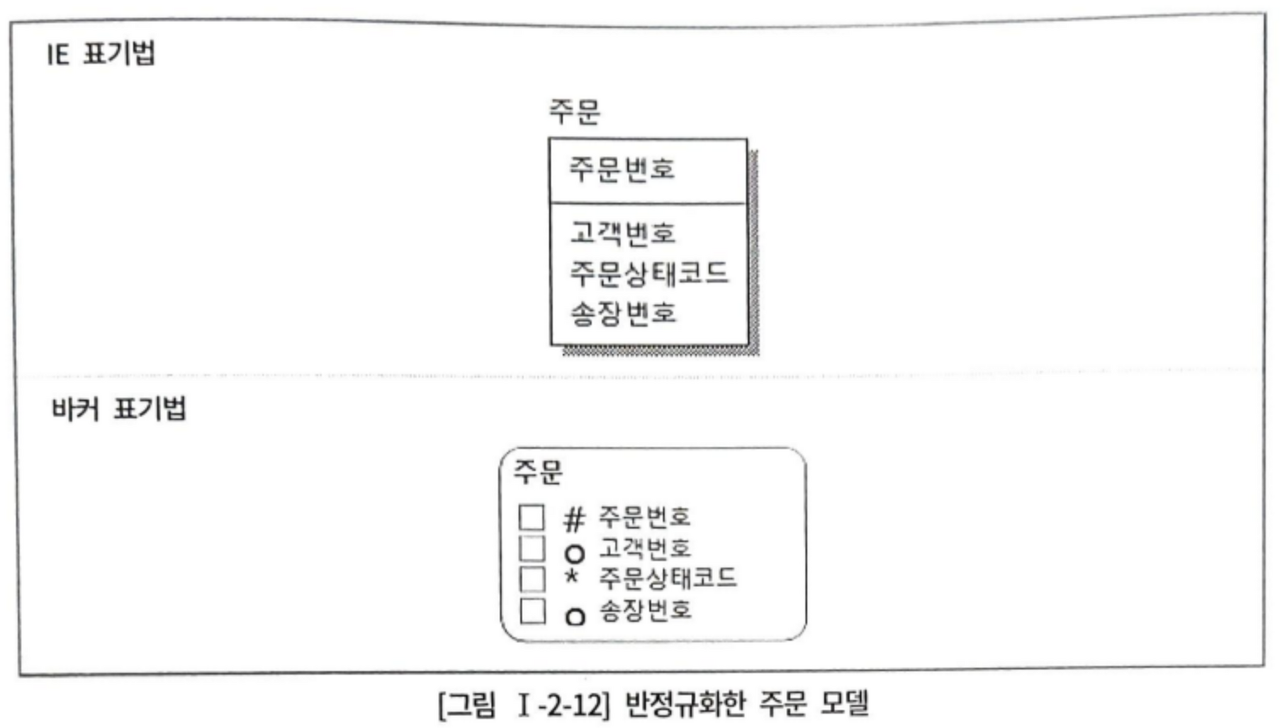
송장번호를 반정규화하게 되면 배송 엔터티와 조인하지 않아도 되지만 고객이 주문하는 시점에선 송장번호를 알 수 없다. 그러므로 주문 시점에는 NULL이 들어가며, 배송 준비가 되면 update해야 한다. => 불필요한 갱신
반정규화는 데이터 불일치로 인한 정합성 문제 뿐만 아니라, 불필요한 트랜잭션으로 성능 문제를 만들 수 있다.
🥓관계와 조인의 이해
조인(Join) : 식별자를 상속하고, 상속된 속성을 매핑키로 활용하여 데이터를 결합하는 것
1. 조인
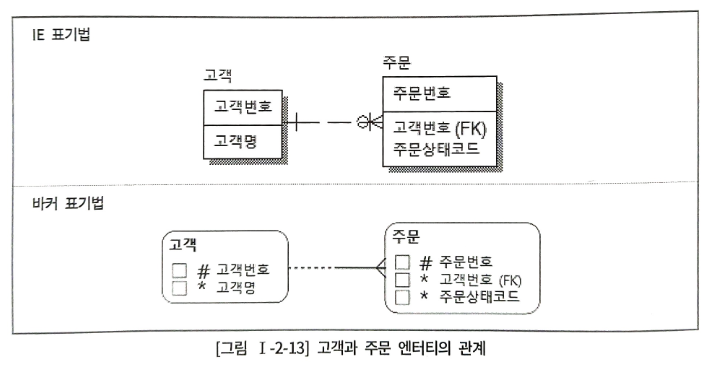
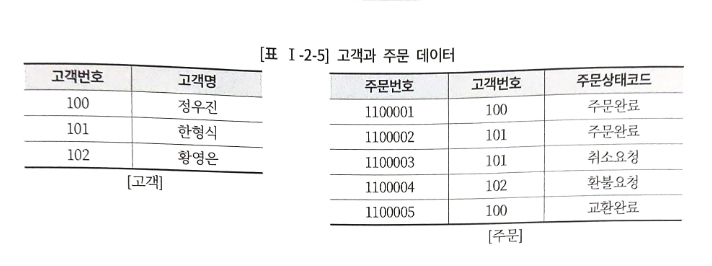
주문 엔터티에 고객 데이터의 고객번호를 상속시킨 것을 볼 수 있다.
SELECT B.고객명
FROM 주문 A, 고객 B
WHERE A.주문번호 = '1100001'
AND A.고객번호 = B.고객번호; -- 조인키2. 계층형 데이터 모델
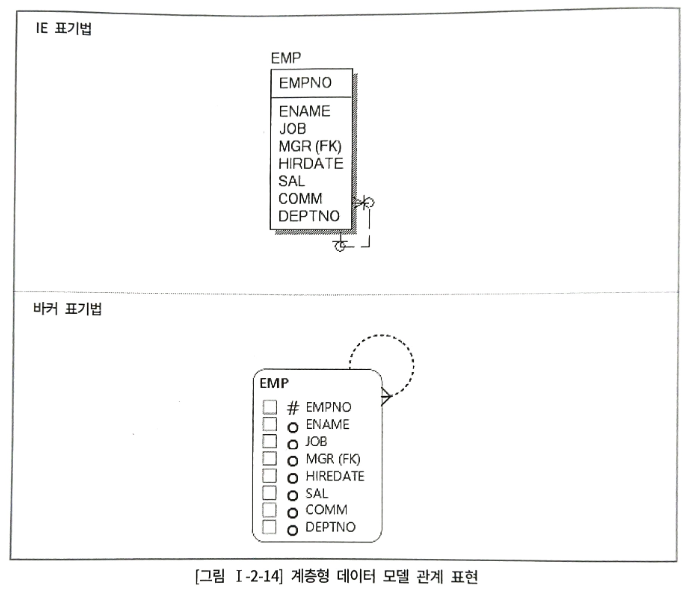
계층형 데이터 모델 : 계층 구조를 가진 데이터, 데이터 간 계층이 존재할 때 발생
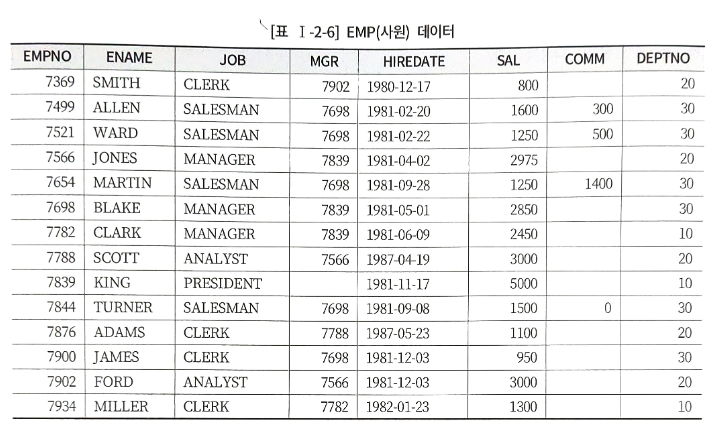
MGR 속성은 각 사원 관리자의 사원번호를 의미한다.
ex. SMITH의 관리자는 7902인 FORD가 된다.
SELECT B.ENAME -- empno가 7902인 FORD를 확인한다.
FROM EMP A, EMP B
WHERE A.ENAME = 'SMITH' -- emp a에서 ename이 smith인 데이터를 찾는다.
AND A.MGR = B.EMPNO -- smith의 mgr이 7902인 것을 확인하고, empno가 7902인 데이터를 찾는다셀프조인(SELF-JOIN) : 자기 자신을 조인
위 모델에서 상속된 식별자가 바로 mgr 속성이기 때문에 셀프 조인 가능
3. 상호배타적 관계
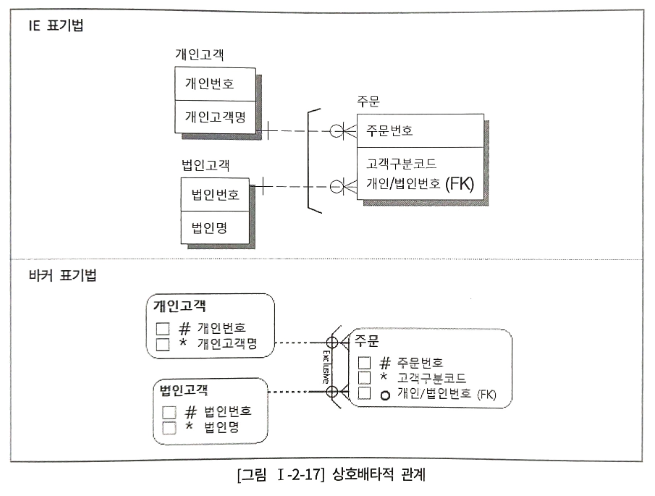
IE 표기법에서는 괄호와 유사한 선을 그려 상호배타적(Exclusive-OR) 관계 표현
위 모델에서 주문 엔터티는 개인 또는 법인번호 둘 중 하나만 상속될 수 있다.
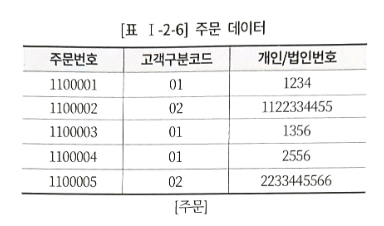
-- 주문번호가 1100001인 주문의 주문자명
SELECT B.개인고객명
FROM 주문 A, 개인고객 B
WHERE A.주문번호 = 1100001
AND A.고객구분코드 = '01'
AND A.개인/법인번호 = B.개인번호
UNION ALL
SELECT B.법인명
FROM 주문 A, 법인고객 B
WHERE A.주문번호 = 1100001
AND A.고객구분코드 = '02'
AND A.개인/법인번호 = B.법인번호;
--조인되는 결과 없을 경우 공집합 출력-- 개인번호와 법인번호가 중복되지 않을 경우
SELECT COALESCE(B.개인고객명, C.법인명) 고객명
FROM 주문 A
LEFT OUTER JOIN 개인고객 B ON (A.개인/법인번호 = B.개인번호)
LEFT OUTER JOIN 법인고객 C ON (A.개인/법인번호 = C.법인번호)
WHERE A.주문번호 = 1100001;
--조인되는 결과 없을 경우 NULL 출력🥚모델이 표현하는 트랜잭션의 이해
트랜잭션 : 데이터베이스의 논리적 연산단위, 하나의 업무단위로 묶여서 처리되어야 하는 것
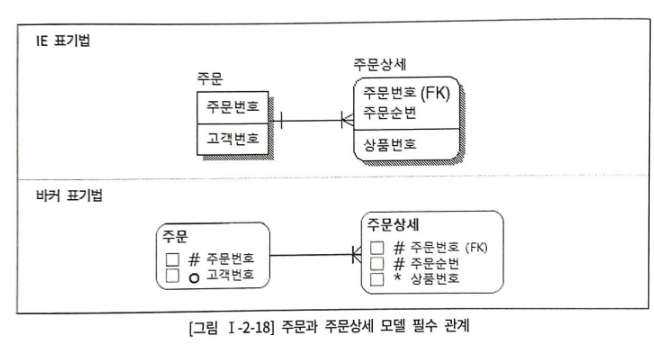
고객이 상품을 구매하면 주문이 발생한다. 그렇다면, 위의 모델에서 주문은 주문상세 데이터와 함께 발생한다. => 필수적인 관계
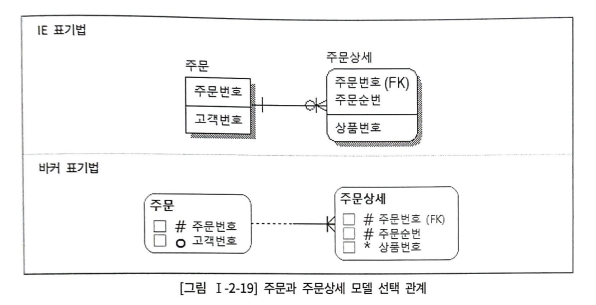
위의 모델은 주문과 주문상세 관계가 선택적이다.
주문은 고객이 상품을 구매해야 생기므로 올바르지 않은 모델이라고 할 수 있다.
주문과 주문상세는 동시에 발생하기 때문에, 하나의 트랜잭션으로 묶어서 처리해야 한다.
=> All or Nothing인 원자성이 보장되도록, 즉 커밋 단위를 하나로 묶어야 함
// A->B 계좌이체
Step1. 계좌이체API{ 잔고수정(고객번호=>A, 수정값=>현재잔고-이체금액);
잔고수정(ㅒ고객번호=>B, 수정값=>현재잔고+이체금액);
commit();}위 처럼 모두 완료 된 후에 커밋을 수행해야 한다.
// 고객 주문 발생
Step1. 주문API{ 주문입력(주문번호=>110001, 고객명=>A, ...);
commit();}
Step2. 주문상세API{ 주문상세입력(주문번호=>110001, 상품번호=>1234, ...);
commit();} 함께 수행해야 할 주문과 주문상세의 INSERT를 각각 호출하면, 만약 오류나 장애로 인해 함께 수행되지 못하고 하나만 수행된다면, 주문과 주문상세에 잘못된 데이터가 발생할 수 있다.
// 고객 주문 발생
Step1. 주문API{ 주문입력(주문번호=>110001, 고객명=>A, ...);
주문상세입력(주문번호=>110001, 상품번호=>1234, ...);
commit();} 태생자체가 함께 발생하는 데이터는 재사용성의 이점도 없으므로 반드시 하나의 트랜잭션으로 처리
잘못된 트랜잭션 처리는 데이터 정합성의 문제를 야기하고, 데이터 품질에도 큰 영향을 끼침
🍳Null 속성의 이해
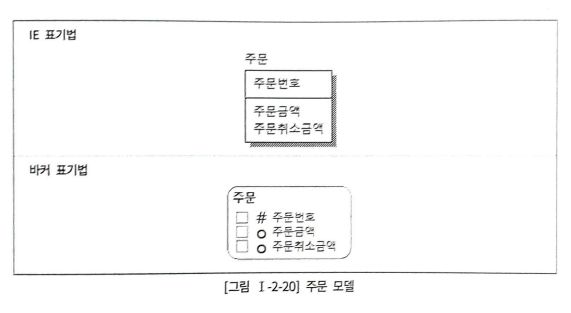
IE 표기법에선 알 수 없지만, 바커 표기법에선 속성 앞 동그라미가 Null 허용 속성
1. Null 값의 연산은 언제나 Null이다
Null : 값이 존재하지 않음
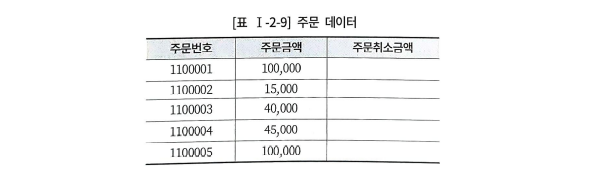
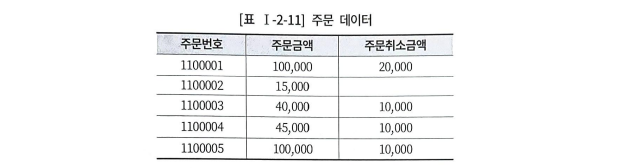
주문

--최종 주문금액
select 주문금액-주문취소금액 col1,
nvl(주문금액-주문취소금액,0) col2,
nvl(주문금액,0)-nvl(주문취소금액,0) col3
from 주문;
col1은 null값을 전혀 고려하지 않고 계산했다. 그러므로, 15000-null=null이 나왔다.
col2는 주문금액에서 주문취소금액을 뺀 후에 nvl을 처리하였다. 두번째 결과는 15000-null=null에 nvl을 사용해 0이 되었다.
col3은 각 속성별로 nvl을 처리한 후, 빼기를 했다. 15000-0=15000이라는 금액이 나온다.
2. 집계함수는 Null 값을 제외하고 처리한다
집계함수는 Null 값의 경우 제외하고 연산
--최종주문금액 총합
select sum(주문금액)-sum(주문취소금액) col1,
nvl(sum(주문금액-주문취소금액),0) col2,
nvl(sum(주문금액),0)-nvl(sum(주문취소금액),0) col3
from 주문;
col1은 주문취소금액이 한 건도 존재하지 않아 합산 결과가 Null이 된다. 그러므로, 300,000-Null=Null이 된다.
col2는 주문별로 주문금액-주문취소금액을 한 결과를 합치는 것인데, 100,000-Null로 Null이 되며, 모든 결과가 Null값을 반환해, nvl함수로 인해 값이 0이 된다.
col3는 각 속성별로 sum함수를 실행한다. nvl(sum(주문취소금액),0)이 0이 되어 300,000-0으로 300,000을 출력했다.
-- 주문취소금액 평균값 구하기
select sum(주문취소금액)/count(*) col1,
avg(주문취소금액) col2
from 주문;
col1은 주문취소금액의 합계를 총건수로 나누었다. 50000/5로 10000 반환
col2는 avg를 사용했다. 50000/4로 null값을 제외한 개수로 나누었다.
🧇본질식별자 vs. 인조식별자
본질식별자 : 업무에 의해 만들어진 식별자
인조식별자 : 인위적으로 만든 식별자
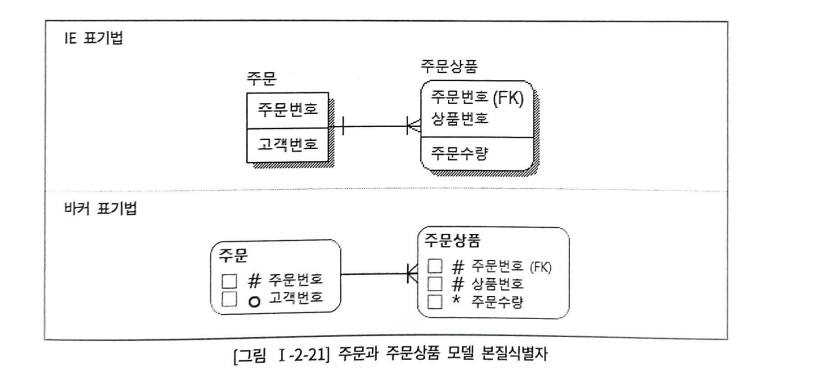
주문상품의 식별자가 본질식별자

주문상품에 INSERT할 경우
insert into 주문상품 values(11001, 1234, 1);
insert into 주문상품 values(11001, 1566, 5);
insert into 주문상품 values(11001, 234, 2);주문에 구매한 상품에 대한 정보를 INSERT 하기만 하면 됨
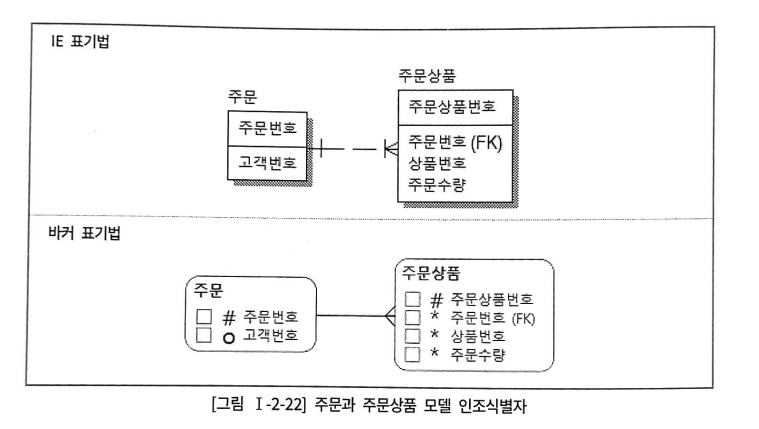
주문상품번호라는 인조식별자를 생성
주문상품에 INSERT할 경우
insert into 주문상품 values(주문상품번호SEQ.NEXTVAL, 11001, 1234, 1);
insert into 주문상품 values(주문상품번호SEQ.NEXTVAL, 11001, 1566, 5);
insert into 주문상품 values(주문상품번호SEQ.NEXTVAL, 11001, 234, 2);오히려 불필요한 시퀀스를 사용할 뿐이다.
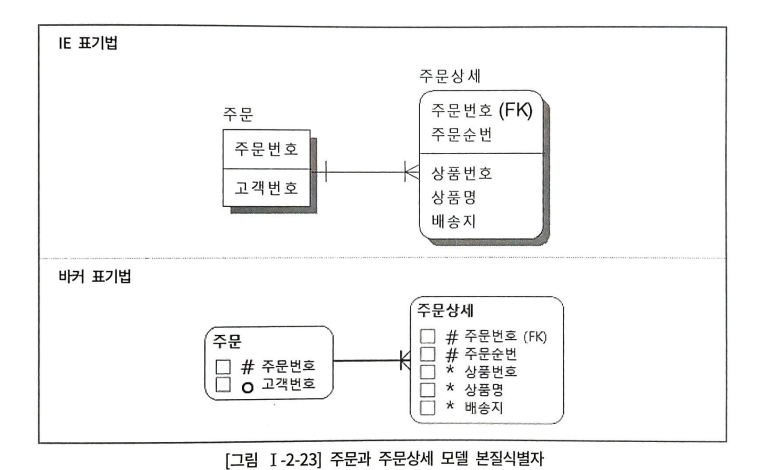
하나의 주문에 동일상품을 중복으로 구매하고 싶다면, 2-21 모델에서는 불가능하다. 상품번호가 중복되기 때문이다. 2-23 모델은 상품번호를 식별자로 구성하지 않고, 하나의 주문에 발생하는 주문순번이라는 상품의 count 식별자를 구성하였다.

현재 하고 싶은 것은, 동일한 상품을 각기 다른 배송지에 보내고 싶은 것이다.
insert into 주문상품 values(11001, 1, 1234, '제주감귤 1box', '우리집');
insert into 주문상품 values(11001, 2, 1234, '제주감귤 1box', '부모님집');
insert into 주문상품 values(11001, 3, 1234, '제주감귤 1box', '친구집');위의 모델은 하나의 주문에 구매하는 상품의 count를 계산해 입력해야 한다.
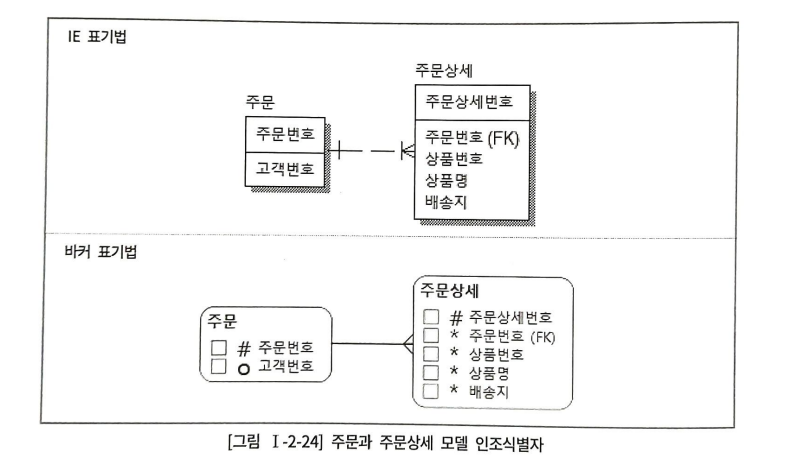
번거로움을 없애기 위해 주문상세번호를 인조식별자로 구성하였다.

주문순번은 하나의 주문번호에 대해 구매가 일어나는 상품의 count를 계산하였기 때문에, 시퀀스를 사용할 수 없었다.
하지만, 주문상세번호는 단일식별자로 구성된 키이므로, 시퀀스 사용이 가능하다.
insert into 주문상품 values(주문상세번호SEQ.NEXTVAL, 11001, 1234, '제주감귤 1box', '우리집');
insert into 주문상품 values(주문상세번호SEQ.NEXTVAL, 11001, 1234, '제주감귤 1box', '부모님집');
insert into 주문상품 values(주문상세번호SEQ.NEXTVAL, 11001, 1234, '제주감귤 1box', '친구집');실제 작업량이 줄어들지만, 문제점이 있다.
1. 중복 데이터로 인한 품질 문제
인조식별자를 사용하면 중복 데이터를 막을 수 없다.
insert into 주문상품 values(주문상세번호SEQ.NEXTVAL, 11001, 1234, '제주감귤 1box', '우리집');
insert into 주문상품 values(주문상세번호SEQ.NEXTVAL, 11001, 1234, '제주감귤 1box', '우리집');기본키를 인조식별자로 구성했기 때문에 주문상세번호에 대해 기본키 제약이 걸려있어 중복으로 데이터가 들어가게 된다.

주문상세번호는 시퀀스를 사용하므로 제약에 위배된 사항이 없기 때문이다.
그러므로 최대한 본질식별자를 사용하도록 해야한다.
인조식별자를 사용했다면, 애플리케이션에서 방어해주어야 한다.
2. 불필요한 인덱스 생성
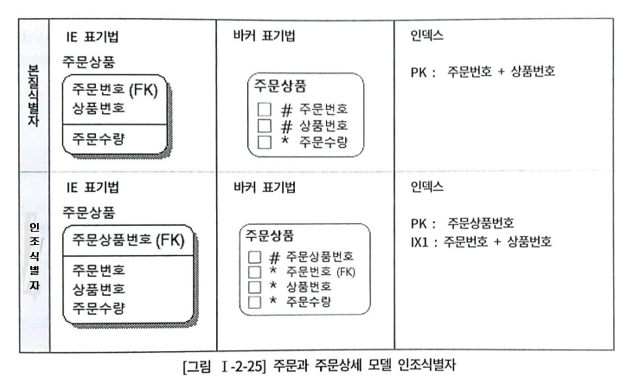
주문상품 모델 데이터에 액세스한다고 가정하자.
select *
from 주문상품
where 주문번호=:B1;또는
select *
from 주문상품
where 주문번호=:B1
and 상품번호=:B2;본질식별자로 구성한다면, PK인덱스를 활용할 수 있지만, 인조식별자로 구성한다면 추가 인덱스가 필요하다. 즉, 인조식별자를 이용하면 불필요한 인덱스를 추가로 생성해야 한다.
