📔설명
쿼리 작성과 연관된 시스템 변수, MySQL 연산자 및 내장 함수, SELECT, INSERT, DELETE, UPDATE, DDL, 쿼리 성능 테스트에 대해 알아보자
🥑쿼리 작성과 연관된 시스템 변수
대소문자 구분, 문자열 표기 방법 등 SQL 작성 규칙은 MySQL 서버 설정에 따라 달라짐
1. SQL 모드
sql_mode : 여러 개의 값 동시에 설정, SQL 문장 작성 규칙과 데이터 타입 변환 및 기본값 제어 등
STRICT_ALL_TABLES & STRICT_TRANS_TABLES:INSERT나UPDATE로데이터 변경시 칼럼 타입과 저장되는 값 타입이 다를 때자동으로타입 변경수행하는데,적절히 변환이 어렵거나 칼럼에 저장될 값이없거나값의 길이가 최대 길이보다큰 경우이때 문장을 계속 실행할지 아니면 에러를 발생시킬지 결정 =>엄격한 모드ANSI_QUOTES:홑따옴표만 문자열 값 표기,쌍따옴표는 칼럼명이나 테이블명 표기ONLY_FULL_GROUP_BY:SELECT절에GROUP BY절에 명시된 칼럼과집계 함수만 사용 가능PIPE_AS_CONCACT:||를OR이 아닌문자열 연결 연산자로 사용PAD_CHAR_TO_FULL_LENGTH:CHAR칼럼값을 가져올 때뒤쪽 공백 제거 XNO_BACKSLASH_ESCAPES:역슬래시를이스케이프 용도로 사용 XIGNORE_SPACE:스토어드 프로시저나함수명과괄호 사이에 있는공백도이름으로 간주하는데, 해당 옵션 사용시공백 무시REAL_AS_FLOAT:REAL타입은DOUBLE타입의 동의어로 사용되나, 해당 옵션 사용시FLOAT의 동의어로 변경NO_ZERO_IN_DATE & NO_ZERO_DATE:잘못된 날짜저장 불가능ANSI:SQL 표준에 맞게 동작하게 만들어줌TRADITIONAL:STRICT보다조금 더 엄격한 방법으로,여러 모드 조합으로 만들어진 모드
2. 영문 대소문자 구분
lower_case_table_names
=> 1로 설정 : 모두 소문자로만 저장, 대소문자 구분 X
=> 2로 설정 : 저장은 대소문자 구분, 쿼리에선 구분 X
=> 0 (기본값) : DB나 테이블명에 대해 대소문자 구분
3. MySQL 예약어
예약어와 같은 키워드로 테이블이나 칼럼 생성시 역따옴표나 쌍따옴표로 감싸야 함
🥒매뉴얼의 SQL 문법 표기 읽는 방법

SQL의 각 키워드는 표기된 순서로만 사용
대문자로 표기된 단어는 모두 키워드
=> 키워드는 대소문자 구분X로 사용 가능
이탤릭체로 표현한 단어는 사용자가 선택해서 작성하는 토큰
=> 테이블명이나 칼럼명 등
대괄호는 선택 사항
파이프는 앞과 뒤 키워드나 표현식 중 단 하나만 선택해서 사용 가능
중괄호는 괄호 내 아이템 중 반드시 하나 사용해야 함
...는 앞에 명시된 키워드나 표현식 조합이 반복될 수 있음을 나타냄
🥬MySQL 연산자와 내장 함수
1. 리터럴 표기법 문자열
문자열
SQL 표준 : 문자열은 홑따옴표(')
select * from departments where dept_no='d001';
select * from departments where dept_no="d001"; -- MySQL홑따옴표 포함시 홑따옴표 두 번 연속해서 입력하면 됨
쌍따옴표 포함시 쌍따옴표 두 번 연속해서 입력하면 됨
select * from departments where dept_no='d''001';
select * from departments where dept_no='d""001';
select * from departments where dept_no="d'001"; -- MySQL
select * from departments where dept_no="d""001"; -- MySQL예약어 충돌 피하기 위해 역따옴표(``) 사용
select `column` from tab_test;
-- 다른 DBMS는 쌍따옴표나 대괄호로 감쌈숫자
비교 대상이 문자열이면 문자열 값을 숫자 값으로 자동 변환
날짜
정해진 형태의 날짜 포맷으로 표기하면 자동으로 DATE나 DATETIME 값으로 변환
select * from dept_emp where from_date='2011-04-29'; -- 문자열을 DATE로 변환
select * from dept_emp where from_date=str_to_date('2011-04-29','%Y-%m-%d'); --위랑 같음불리언
BOOL 이나 BOOLEAN은 TINYINT 타입에 대한 동의어
=> FALSE 또는 TRUE 형태로 비교하거나 값 저장 가능
=> FALSE : 0
=> TRUE : 1
create table tb_bool (bool_value boolean);
insert into tb_bool values (false), (true), (1), (2), (3) ;
select * from tb_bool;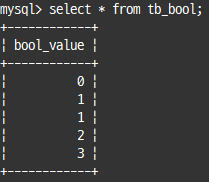
select * from tb_bool where bool_value in (false, true);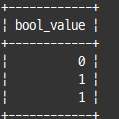
2. MySQL 연산자
동등(Equal) 비교(=, <=>)
<=> : =와 같으며 부가적으로 null값에 대한 비교 수행
select 1=1, null=null, 1=null;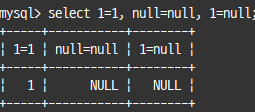
select 1<=>1, null<=>null, 1<=>null;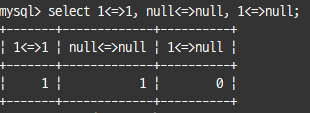
한 쪽만 Null이라면 FALSE 반환
부정(Not-Equal) 비교(<>, !=)
같지 않다
NOT 연산자(!)
TRUE 또는 FALSE 연산의 결과를 반대로 만드는 연산자
select !1;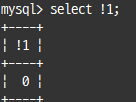
select not (1=1);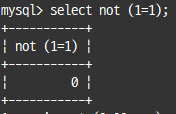
AND(&&)와 OR(||) 연산자
AND는 &&, OR은 ||와 같으나, 다른 용도로 사용될 수 있는 &&와 ||는 사용 자제
=> 우선순위는 AND가 더 높음
나누기(/, DIV)와 나머지(%, MOD) 연산자
일반적으론 / 사용, 정수 부분만 가져오려면 DIV, 나머지를 가져오려면 % 또는 MOD 사용
select 29/9;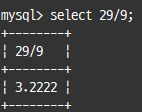
select 29 div 9;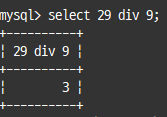
select mod(29,9); -- 또는 29 mod 9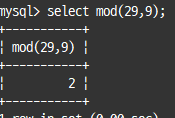
REGEXP 연산자
문자열 값이 어떤 패턴을 만족하는지 확인하는 연산자
RLIKE는 REGEXP와 똑같음
REGEXP 좌측에 비교 대상 문자열 값 또는 문자열 칼럼, 우측에 정규 표현식 사용
select 'abc' regexp '^[x-z]'; -- x, y, z로 시작하는지 검증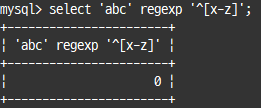
^: 문자열의시작표시$: 문자열의끝표시[]:문자그룹표시, 안에 표시된문자 중 하나인지 확인():문자열그룹 표시, 안에 표시된문자열모두 있는지 확인|:|로 연결된문자열중 하나인지 확인.: 어떠한 문자든지1개의 문자표시*: 앞에 표시된 정규 표현식이0또는1번 이상반복+:1번 이상반복?:0또는1번만
[0-9]* : 0~9까지 숫자만 0 또는 1번 이상 반복
^Tear : Tear 문자열로 시작하는 정규 표현
Tear$ : Tear 문자열로 끝나는 정규 표현
^Tear$ : Tear와 같은 문자열REGEXP 조건 비교는 인덱스 레인지 스캔 불가
LIKE 연산자
어떤 상수 문자열이 있는지 없는지 정도 판단
select 'abcdef' like '%abc';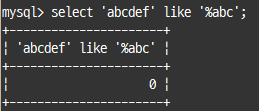
와일드카드 문자
%:0또는1개 이상의 모든 문자에 일치_: 정확히1개의 문자에 일치
% 또는 _ 문자 자체 비교시 escape 절 설정
select 'a%' like 'a/%' escape '/';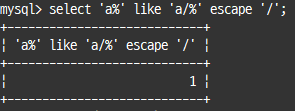
와일드카드 문자가 뒤쪽에 있다면 인덱스 레인지 스캔 가능
BETWEEN 연산자
select * from dept_emp
where dept_no='d003' and emp_no=10001;
select * from dept_emp
where dept_no between 'd003' and 'd005' and emp_no=10001;between은 범위 비교이고, IN은 동등 비교 연산자와 비슷하다.
between으로 범위 검색시 emp_no 조건은 범위를 줄이지 못함
select * from dept_emp
where dept_no in ('d003', 'd004', 'd005')
and emp_no=10001;
-- emp_no도 작업 범위 줄이는 용도로 사용 가능여러 칼럼으로 인덱스가 만들어져 있는데, 인덱스 앞쪽에 있는 칼럼 선택도가 떨어질 때 IN으로 변경하면, 쿼리 성능 개선
-- 세미 조인 최적화를 통해 더 빠른 쿼리로 알아서 변환
select *
from dept_emp
where dept_no in(
select dept_no
from departments
where dept_no between 'd003' and 'd005')
and emp_no=10001;IN 연산자
여러 개의 값에 대해 동등 비교 연산 수행
=> 여러 번의 동등 비교로 실행해 빠르게 처리됨
explain
select *
from dept_emp
where (dept_no, emp_no) in (('d001', 10017), ('d002', 10144), ('d003', 10054));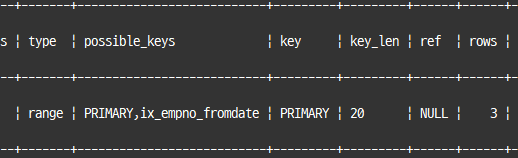
NOT IN은 인덱스 풀 스캔으로 표시되는데, 부정형 비교여서 인덱스를 이용해 처리 범위를 줄이는 조건으로 사용할 수 없기 때문
3. MySQL 내장 함수
사용자 정의 함수 : C/C++ API를 이용해 사용자가 원하는 기능을 직접 함수로 만들어 추가
=> 스토어드 프로그램으로 작성되는 함수랑은 다름
NULL 값 비교 및 대체(IFNULL, ISNULL)
IFNULL() : 칼럼이나 표현식 값이 NULL인지 비교하고, NULL이면 다른 값으로 대체
ifnull(비교하려는 칼럼, 대체할 값);
-- 첫 번째가 null이 아니면 첫 번째 인자 값 반환ISNULL() : 칼럼 값이 NULL인지 아닌지 비교, null이면 true(1), null이 아니면 false(0) 반환
isnull(칼럼);select ifnull(null, 1);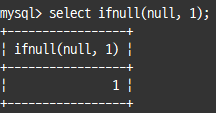
select isnull(1/0);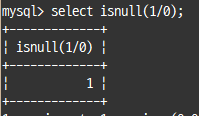
현재 시각 조회(NOW, SYSDATE)
현재의 시간을 반환
NOW() : 하나의 SQL에서 같은 값 가짐
SYSDATE() : 하나의 SQL에서도 호출되는 시점에 따라 결과값 달라짐
select now(), sleep(2), now();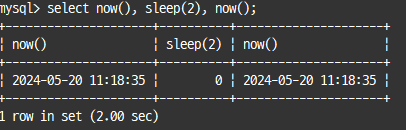
select sysdate(), sleep(2), sysdate();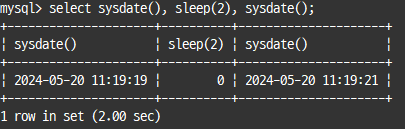
SYSDATE() 함수는 문제가 있다
- 해당 함수 사용 SQL은
레플리카 서버에서 안정적으로 복제X - 해당 함수와
비교되는 칼럼은인덱스 효율적으로 사용X
explain
select emp_no, salary, from_date, to_date
from salaries
where emp_no=10001 and from_date>sysdate();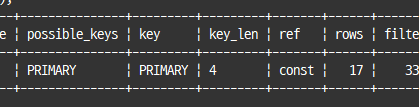
emp_no 칼럼만 인덱스를 사용할 수 있어 key_len이 4바이트가 됨
SYSDATE() 함수는 함수가 호출될 때마다 다른 값을 반환하므로 인덱스 스캔시에도 매번 비교되는 레코드마다 함수 실행해야 함
sysdate-is-now를 설정해 SYSDATE()가 NOW()와 동일하게 작동하도록 설정 권장
날짜와 시간의 포맷(DATE_FORMAT, STR_TO_DATE)
DATE_FORMAT() : DATETIME 타입의 칼럼이나 값을 원하는 형태의 문자열로 변환할 때
| 지정문자 | 내용 |
|---|---|
| %Y | 4자리 연도 |
| %m | 2자리 숫자 표시 월 |
| %d | 일자 |
| %H | 두자리 숫자 표시 시 (00~23) |
| %i | 분 |
| %s | 초 |
select date_format(now(), '%Y-%m-%d') as current_dt;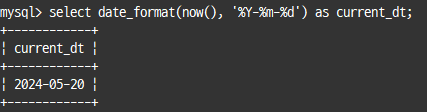
STR_TO_DATE() : 문자열을 DATETIME 타입으로 변환
select str_to_date('2024-05-10', '%Y-%m-%d') as current_dt;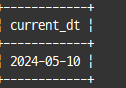
날짜와 시간의 연산(DATE_ADD, DATE_SUB)
DATE_ADD(), DATE_SUB() : 특정 날짜에서 연도나 월일 또는 시간 등을 더하거나 뺄 때
date_add(연산 수행 날짜, interval n [YEAR, MONTH, ...]);select date_add(now(), interval 1 day) as tomorrow;
| 단위 | 의미 |
|---|---|
| MICROSECOND | 마이크로 초 |
| QUARTER | 분기 |
| WEEK | 주 |
타임스탬프 연산(UNIX_TIMESTAMP, FROM_UNIXTIME)
UNIX_TIMESTAMP() : '1970-01-01 00:00:00'으로부터 경과된 초의 수 반환
FROM_UNIXTIME() : 타임스탬프 값을 DATETIME 타입으로 변환하는 함수
select unix_timestamp();
select from_unixtime(unix_timestamp());
문자열 처리(RPAD, LPAD / RTRIM, LTRIM, TRIM)
RPAD(), LPAD() : 문자열의 좌측 또는 우측에 문자를 덧붙여서 지정된 길이의 문자열로 만듦
RPAD(문자열, 적용 후 문자열 길이, 패딩할 문자);
LPAD ..;RTRIM(), LTRIM(), TRIM() : 연속된 공백 문자 제거
select rpad('Close', 10,'_');
select ltrim(' Close') as name;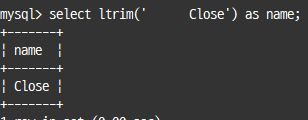
문자열 결합(CONCAT)
여러 개의 문자열을 연결해서 하나의 문자열로 반환
select concat('Georgi', 'Christian', CAST(2 as char)) as name;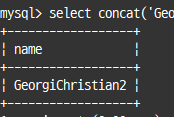
CONCAT_WS() : 문자열 연결시 구분자 넣어줌
select concat_ws(',','Georgi', 'hi') as name;
-- 첫 번째 인자 : 구분자로 사용할 문자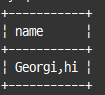
GROUP BY 문자열 결합(GROUP_CONCAT)
그룹 함수 중 하나로, 값들을 먼저 정렬한 후 연결 하거나 구분자 설정 가능
select group_concat(dept_no) from departments;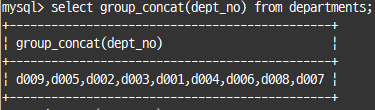
select group_concat(dept_no separator '|') from departments;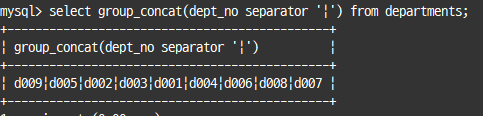
select group_concat(dept_no order by emp_no desc)
from dept_emp
where emp_no between 100001 and 100003;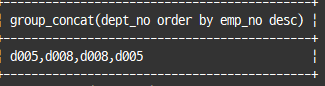
select group_concat(distinct dept_no order by emp_no desc)
from dept_emp
where emp_no between 100001 and 100003;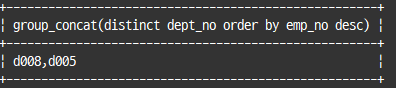
연결을 위해 제한적인 메모리 버퍼 공간 사용
값의 비교와 대체(CASE WHEN ... THEN ... END)
select emp_no, first_name,
case gender when 'M' then 'Man'
when 'F' then 'Woman'
else 'Unkonw' end as gender
from employees
limit 10;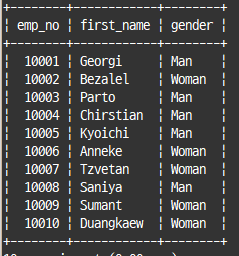
select emp_no, first_name,
case when hire_date<'1995-01-01' then 'Old'
else 'New' end as employee_type
from employees
limit 10;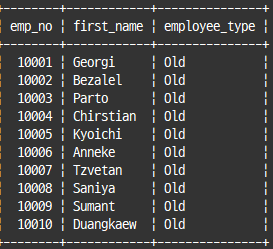
case when절이 일치하는 경우에만 then 이하 표현식 실행됨
타입의 변환(CAST, CONVERT)
명시적으로 타입 변환
cast(변환할 값 as 데이터 타입)select cast('1234' as signed integer) as converted_integer;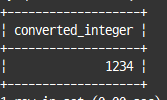
convert() 함수는 cast()함수와 같이 타입 변환 하는 용도와, 문자열의 문자 집합 변환 용도로 사용
select convert(1-2, unsigned);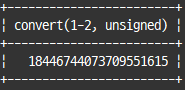
select convert('ABC' using 'utf8mb4');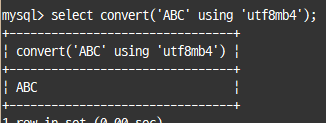
이진값과 16진수 문자열(Hex String) 변환(HEX, UNHEX)
HEX() : 이진값을 16진수 문자열로 변환
UNHEX() : 16진수 문자열을 이진값으로 변환
암호화 및 해시 함수(MD5, SHA, SHA2)
MD5와 SHA 모두 비대칭형 암호화 알고리즘으로, 해시 값을 만들어내는 함수
SHA()는 SHA-1 암호화 알고리즘 사용, MD5는 메시지 다이제스트 알고리즘 사용
MD5는 입력된 문자열의 길이를 줄이는 용도로 사용
select sha2('abc',256);
처리 대기(SLEEP)
디버깅 용도로 잠깐 대기하거나 일부러 쿼리 실행을 오랜 시간 유지하고자 할 때 사용
select sleep(1.5)
from employees
where emp_no between 10001 and 10010;
sleep() 함수는 레코드 건수만큼 sleep 함수를 호출하기 때문에 10*1.5초로 15초동안 쿼리 실행
벤치마크(BENCHMARK)
BENCHMARK() : 디버깅이나 간단한 함수의 성능 테스트용으로 유용
benchmark(반복 수행 횟수, 표현식(스칼라값))스칼라값 : 하나의 칼럼을 가진 하나의 레코드
select benchmark(10000000,md5('abcdefghijk'));
IP 주소 변환(INET_ATON, INET_NTOA)
IPv4 주소를 문자열이 아닌 부호 없는 정수 타입에 저장할 수 있도록 함
INET_ATON() : 문자열로 구성된 주소를 정수형으로 변환
INET_NTOA() : 정수형의 주소를 .으로 구분된 문자열로 변환
INET6_ATON() : IP주소를 binary 타입으로 변환
INET6_NTOA() : binary타입의 주소를 문자열로 변환
select hex(inet6_aton('10.0.5.9'));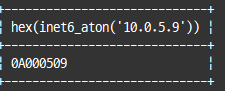
JSON 포맷(JSON_PRETTY)
기본적으로 JSON 데이터 표시 방법이 단순 텍스트 포맷이라 가독성이 떨어지는 것을 변환
select doc from employee_docs where emp_no=10005;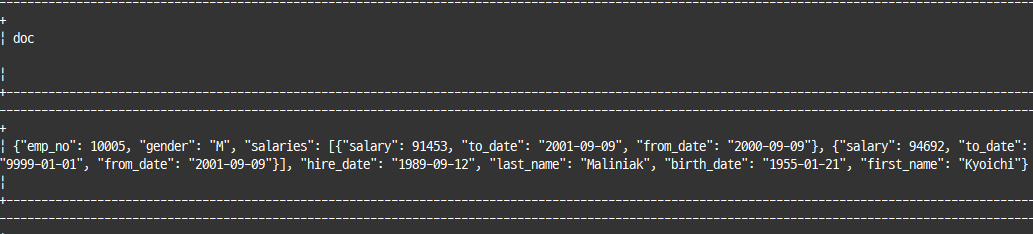
select json_pretty(doc) from employee_docs where emp_no=10005;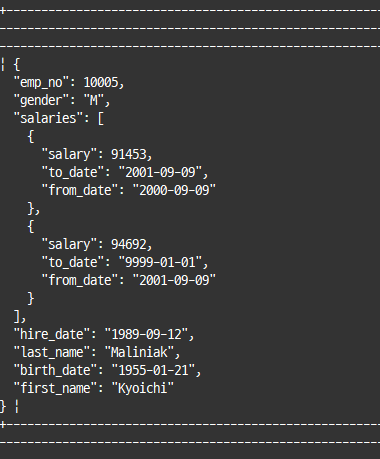
JSON 필드 크기(JSON_STORAGE_SIZE)
JSON은 텍스트 기반이라 실제 디스크에 저장할 때 BSON(Binary JSON) 포맷을 사용한다.
=> 저장 공간 크기 예측을 위한 함수
select emp_no, json_storage_size(doc) from employee_docs limit 2;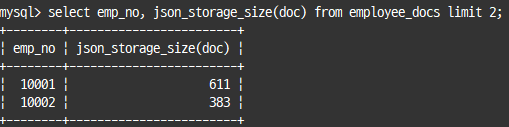
JSON 필드 추출(JSON_EXTRACT)
특정 필드의 값을 가져오는 함수
json_extract(칼럼 또는 json 도큐먼트 자체, 필드 json 경로);select emp_no, json_extract(doc, "$.first_name") from employee_docs;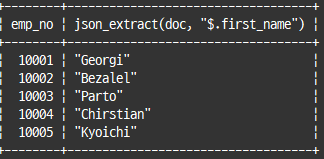
JSON_UNQUOTE() : 따옴표 없이 값만 가져옴
-> : JSON_EXTRACT()와 동일한 기능
->> : JSON_UNQUOTE()와 JSON_EXTRACT() 조합
JSON 오브젝트 포함 여부 확인(JSON_CONTAINS)
JSON 도큐먼트 또는 지정된 JSON 경로에 JSON 필드를 가지고 있는지를 확인
select emp_no
from employee_docs
where JSON_CONTAINS(doc, '{"first_name":"Christian"}');첫번째 인자로 주어진 도큐먼트에서 두 번째 인자의 json 오브젝트가 존재하는지 검사
세번째 인자는 선택으로, json 경로 명시시 해당 경로에 오브젝트 존재하는지 여부 체크
JSON 오브젝트 생성(JSON_OBJECT)
칼럼 값을 이용해 json 오브젝트 생성
select json_object("empNo", emp_no,
"salary", salary,
"fromDate",from_date,
"toDate",to_date) as as_json
from salaries limit 3;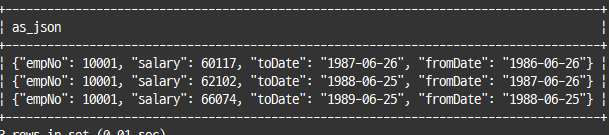
JSON 칼럼으로 집계(JSON_OBJECTAGG & JSON_ARRAYAGG)
group by절과 함께 사용되는 집계 함수로서, json 배열 또는 도큐먼트 생성 함수
select dept_no, json_objectagg(emp_no, from_date) as agg
from dept_manager
where dept_no in ('d001', 'd002', 'd003')
group by dept_no;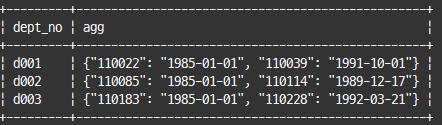
select dept_no, json_arrayagg(emp_no) as agg
from dept_manager
where dept_no in ('d001', 'd002', 'd003')
group by dept_no;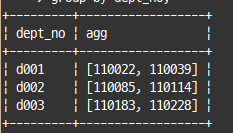
json_objectagg() 함수는 2개의 인자가 필요하며, 첫 번째 인자는 키, 두 번째 인자는 값으로 사용해 키-밸류 쌍으로 반환
JSON 데이터를 테이블로 변환(JSON_TABLE)
json 데이터 값들을 모아서 rdbms 테이블을 만들어 반환
=> 반환 레코드 건수는 원본 테이블과 동일
select e2.emp_no, e2.first_name, e2.gender
from employee_docs e1,
JSON_TABLE(doc, "$" COLUMNS (emp_no int PATH "$.emp_no",
gender char(1) PATH "$.gender",
first_name varchar(20) PATH "$.first_name") as e2
where e1.emp_no in (10001, 10002);| emp_no | first_name | gender |
|---|---|---|
| 10001 | Georgi | M |
| 10002 | Bezalel | F |
🥦SELECT
1. SELECT 절의 처리 순서
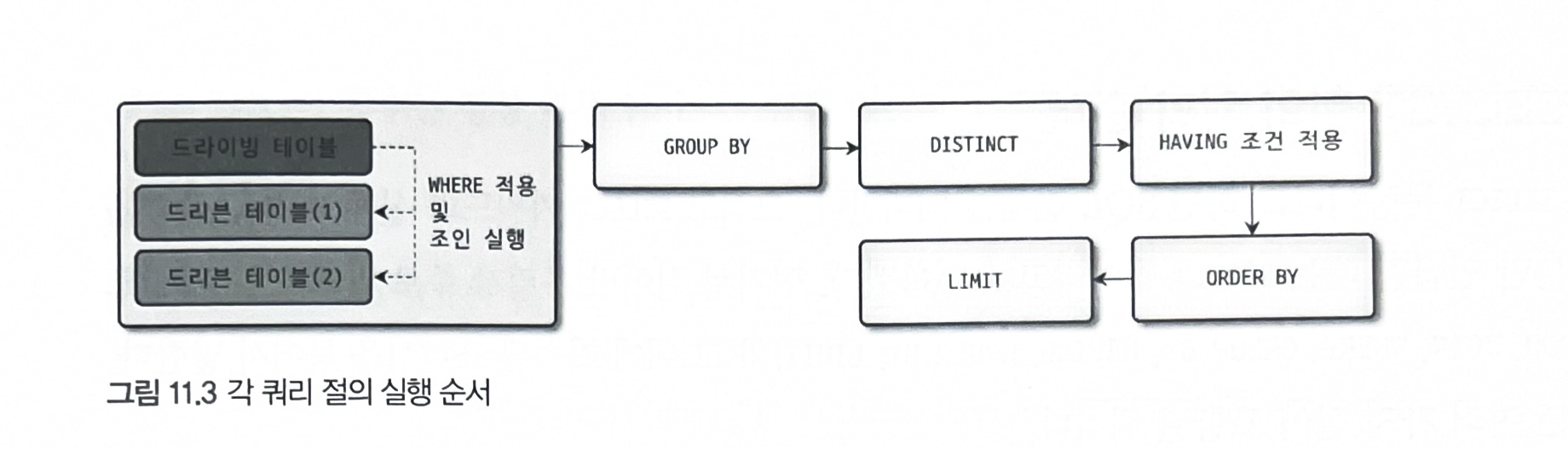
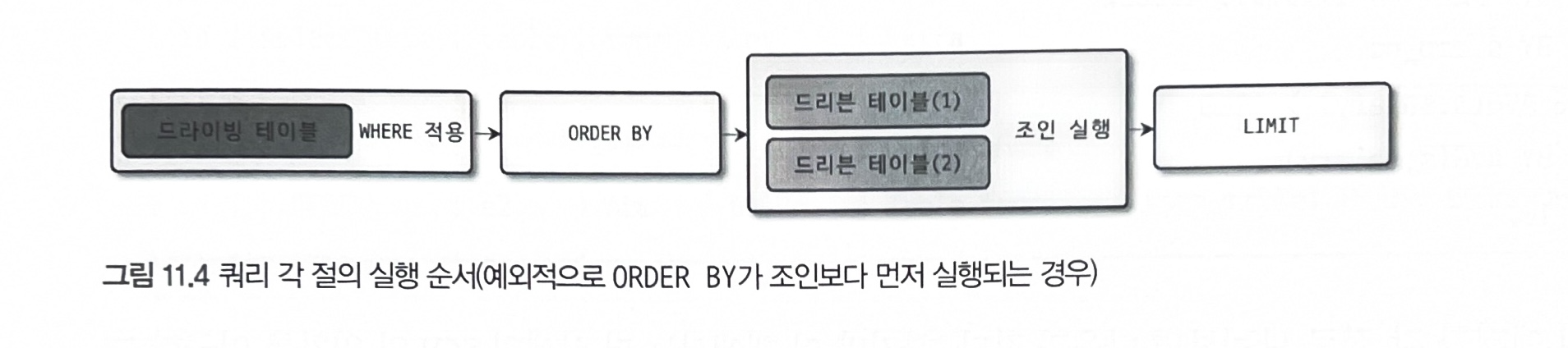
order by가 사용됐을 때 첫 번째 테이블만 읽어서 정렬 수행 후, 나머지 테이블을 읽을 때 나타남
2. WHERE 절과 GROUP BY 절, ORDER BY 절의 인덱스 사용
인덱스 사용을 위한 기본 규칙
인덱스된 칼럼의 값 자체를 변환하지 않고 그대로 사용
WHERE 절의 인덱스 사용
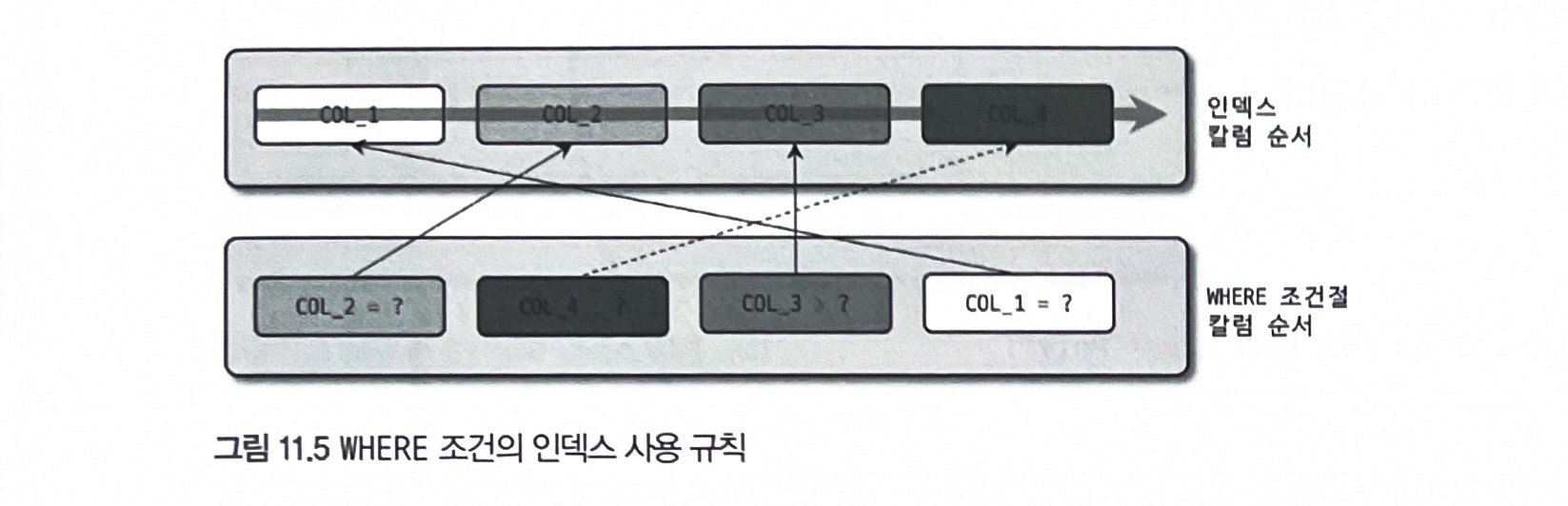
범위 비교 조건이 있다면, 그 다음 조건은 체크 조건으로 사용됨
or 조건으로 연결된 SQL문은 풀 테이블 스캔을 진행
=> 풀 테이블 스캔+인덱스 레인지 스캔보다는 풀 테이블 스캔 한 번이 더 빠르기 때문
GROUP BY 절의 인덱스 사용
group by절에 명시된 칼럼의순서가인덱스구성 칼럼순서와 같으면 인덱스 이용 가능인덱스구성 칼럼 중뒤쪽에 있는 칼럼은 명시되지 않아도 인덱스 사용 가능하나,앞쪽칼럼은 꼭 있어야 함group by절에 명시된 칼럼이하나라도 인덱스에 없으면전혀 인덱스 사용 불가
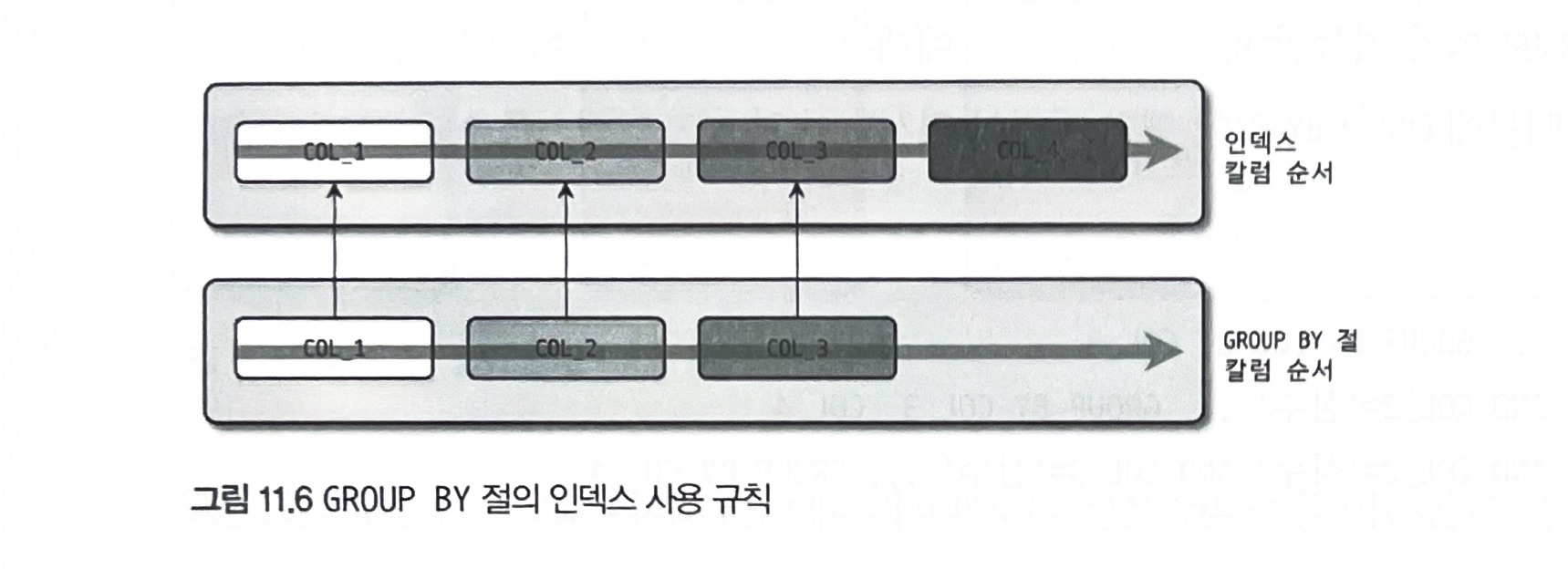
조건절에 col_1이나 col_2가 동등 비교 조건으로 사용된다면 group by절에 col_1이나 col_2 빠져도 인덱스 사용 가능할 때 있음
(col_2가 빠지려면 col_1도 where절에 있어야 함)
ORDER BY 절의 인덱스 사용
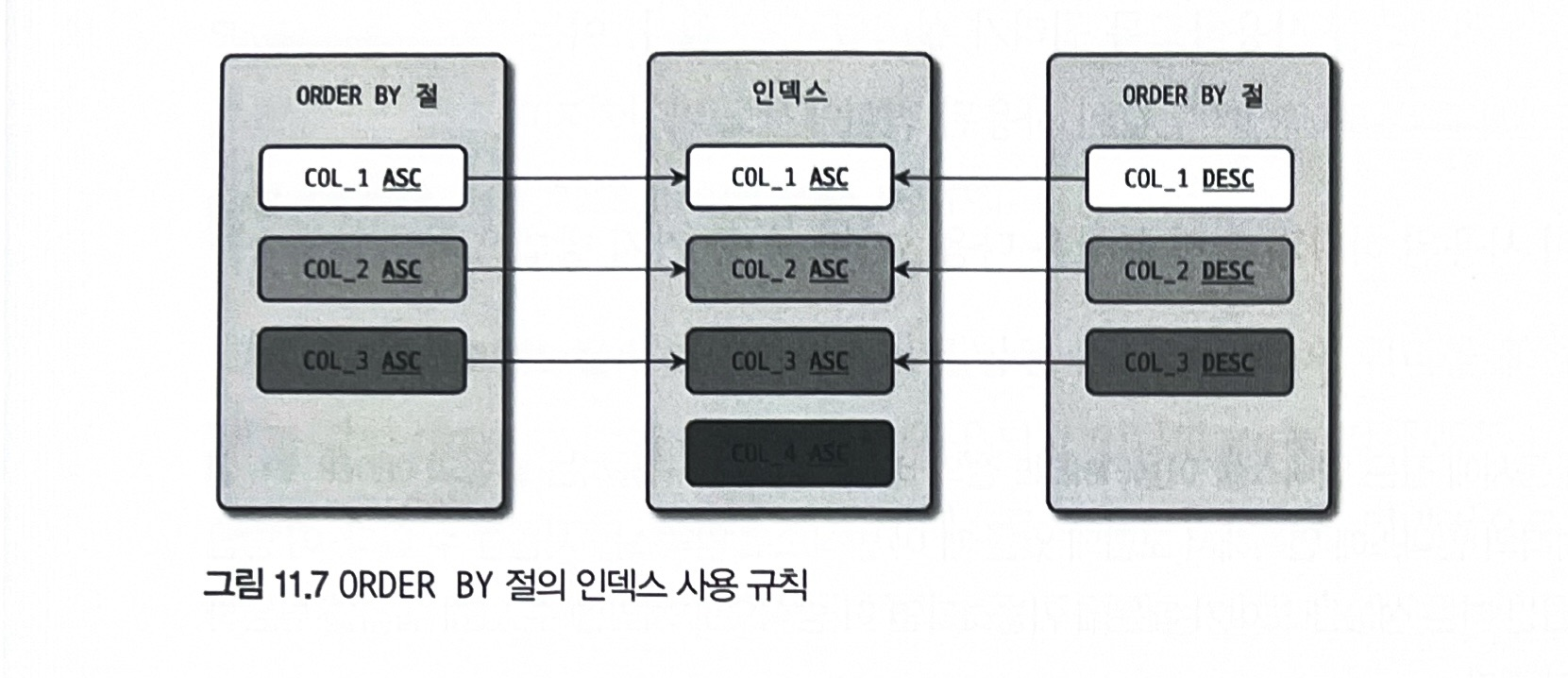
order by절의 모든 칼럼이 오름차순이거나 내림차순일 때만 인덱스 사용 가능
order by절의 칼럼들이 인덱스에 정의된 칼럼의 왼쪽부터 일치해야 함
WHERE 조건과 ORDER BY(또는 GROUP BY) 절의 인덱스 사용
where절과order by절이동시에 같은 인덱스이용 : 가장 빠른 성능where절만 인덱스사용 :where절의 조건에 일치하는레코드 건수가 많지 않을 때order by절만 인덱스사용 : 아주 많은 레코드를 조회해서 정렬할 경우
where절에서 동등 비교 조건으로 비교된 칼럼과 order by 절에 명시된 칼럼이 순서대로 왼쪽 부터 일치해야 함
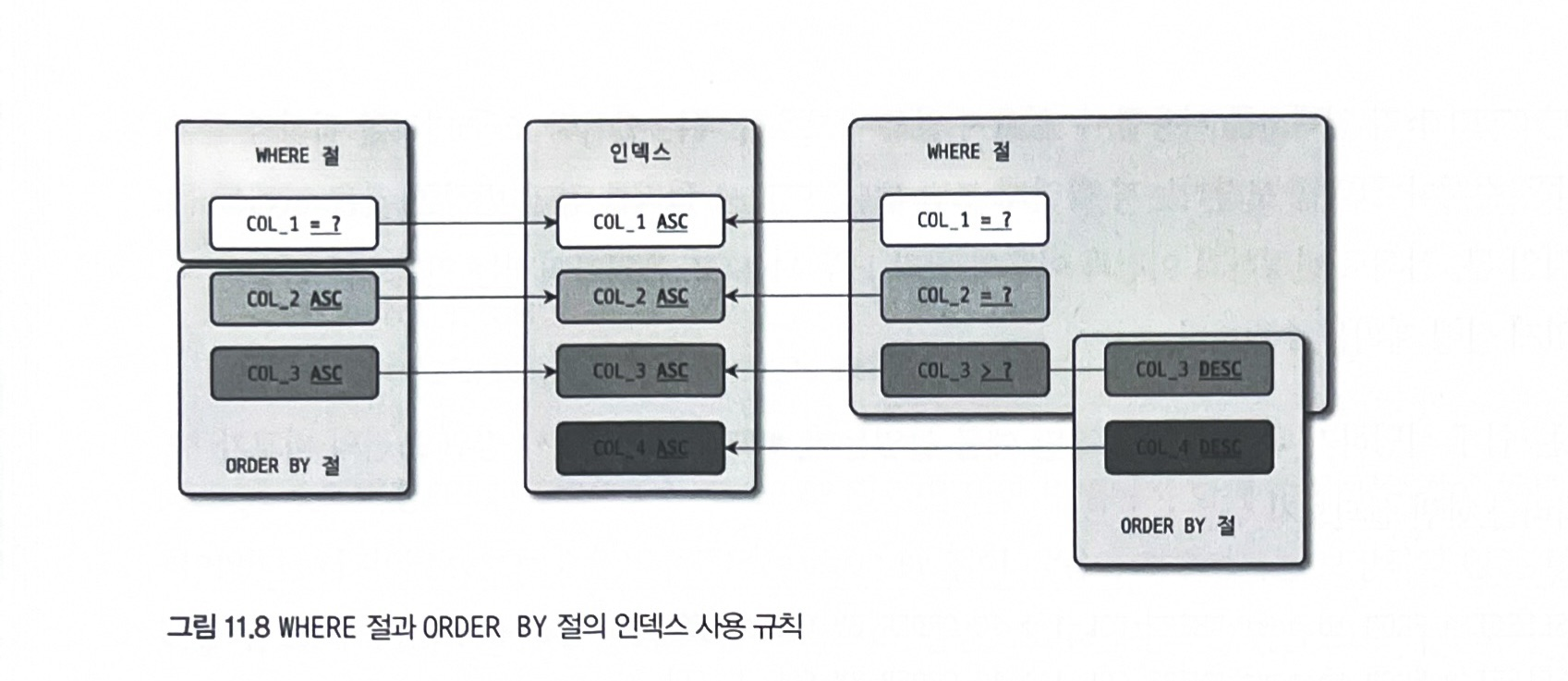
GROUP BY 절과 ORDER BY 절의 인덱스 사용
모두 하나의 인덱스를 사용하려면 group by절에 명시된 칼럼과 order by절에 명시된 칼럼의 순서와 내용이 모두 같아야 함
둘 중 하나라도 인덱스를 이용할 수 없을 땐 둘 다 인덱스 이용 불가
WHERE 조건과 ORDER BY 절, GROUP BY 절의 인덱스 사용
3. WHERE 절의 비교 조건 사용 시 주의사항
NULL 비교
null 값이 포함된 레코드도 인덱스로 관리
null 비교하려면 is null(또는 <=>) 연산자 사용
explain
select * from titles
where to_date is null;
ix_todate 인덱스를 ref 방식으로 이용
문자열이나 숫자 비교
문자열 칼럼이나 숫자 칼럼을 비교할 땐 반드시 그 타입에 맞는 상숫값 사용 권장
날짜 비교
DATE 타입 : 날짜만 저장
DATETIME 과 TIMESTAMP : 날짜와 시간 저장
TIME : 시간만 저장
DATE 또는 DATETIME과 문자열 비교
문자열 값을 자동으로 datetime 타입의 값으로 변환해서 비교 수행
select count(*)
from employees
where hire_date>'2011-07-23';DATE와 DATETIME의 비교
date() : datetime 타입의 값에서 시간 부분은 버리고 날짜 부분만 반환
select count(*)
from employees
where hire_date>DATE(NOW());만약 datetime을 date로 만들지 않는다면 date 타입의 값을 서버가 datetime으로 변환해서 같은 타입으로 만든 다음 비교 수행
인덱스 사용 여부에 영향 X
DATETIME과 TIMESTAMP의 비교
칼럼이 datetime 타입이라면 from_unixtime() 함수를 이용해 timestamp 값을 datetime 으로 바꿔야 함
timestamp 타입 칼럼이라면 unix_timestamp() 함수를 이용해 datetime을 timestamp로 변환해서 비교해야 함
Short-Circuit Evaluation
boolean in_trainsaction;
if(in_transaction && has_modified()){
commit();
}Short-circuit Evaluation : 여러개의 표현식이 and 또는 or 논리 연산자로 연결된 경우 선행 표현식의 결과에 따라 후행 표현식을 평가할지 말지 결정하는 최적화
select count(*) from salaries;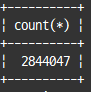
select count(*) from salaries
where convert_tz(from_date,'+00:00','+09:00')>'1991-01-01';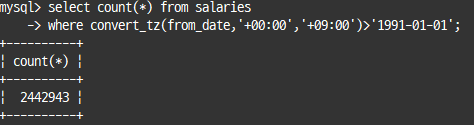
select count(*) from salaries
where to_date<'1985-01-01';
select count(*) from salaries
where convert_tz(from_date,'+00:00','+09:00')>'1991-01-01'
and to_date<'1985-01-01';
select count(*) from salaries
where to_date<'1985-01-01'
and convert_tz(from_date,'+00:00','+09:00')>'1991-01-01';
4. DISTINCT
유니크한 값의 조회를 위해 사용
5. LIMIT n
LIMIT : 쿼리 결과에서 지정된 순서에 위치한 레코드만 가져오고자 할 때 사용
select * from employees
where emp_no between 10001 and 10010
order by first_name
limit 0, 5;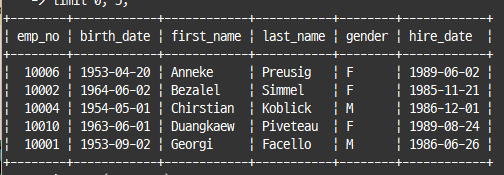
LIMIT은 where 조건이 아니기 때문에 항상 쿼리 마지막에 실행
LIMIT에 필요한 레코드 건수만 준비되면 즉시 쿼리 종료
group by와 함께 limit 사용시 group by가 끝난 후 limit 수행 가능하므로 실질적으로 작업 내용을 크게 줄여주진 못함
select distinct first_name
from employees
limit 0,10;풀 테이블 스캔과 동시에 중복 제거 작업(임시 테이블 사용)을 진행
limit n; --상위 n개
limit n, m; -- n부터 m개limit 10, 10;
--- 11번째 부터 10개limit 제한사항
- 인자로
표현식이나서브쿼리사용 불가
6. COUNT()
결과 레코드의 건수 반환
count() 함수에 칼럼명이나 표현식이 인자로 사용되면 null이 아닌 레코드 건수만 반환
7. JOIN
JOIN의 순서와 인덱스
드라이빙 테이블을 읽을 땐 인덱스 탐색 작업을 단 한번만 수행하고, 그 이후부턴 스캔
드리븐 테이블에선 인덱스 탐색 작업과 스캔 작업을 드라이빙 테이블에서 읽은 레코드 건수만큼 반복
select *
from employees e, dept_emp de
where e.emp_no=de.emp_no;옵티마이저는 조인 칼럼에 인덱스가 있는 것을 드리븐 테이블로 선택하며, 둘 다 있을 경우 레코드 건수에 따라 최적으로 선택
두 칼럼 모두 인덱스가 없는 경우는 해시 조인으로 처리되며, 레코드 건수가 적은 테이블을 드라이빙 테이블로 선택
JOIN 칼럼의 데이터 타입
조인 칼럼 간의 비교에 각 칼럼의 데이터 타입이 일치하지 않으면 인덱스 효율적으로 이용 불가
조인 시 문제가 되는 경우
char 타입과int 타입의 비교처럼 데이터 타입의종류가 완전히 다른 경우- 같은 char 타입이라도
문자 집합이나콜레이션이 다른 경우 - 같은 int 타입이라도
부호 존재 여부가 다른 경우
OUTER JOIN의 성능과 주의사항
테이블의 데이터가 일관되지 않은 경우에만 아우터 조인이 필요
MySQL은 where절에 안티 조인 효과를 기대하는 경우를 제외하곤 left join을 inner join으로 자동변환
JOIN과 외래키(FOREIGN KEY)
데이터 무결성을 보장하기 위해 외래키를 생성
지연된 조인(Delayed Join)
지연된 조인 : 조인이 실행되기 이전에 group by나 order by를 처리하는 방식
=> limit이 함께 사용돼야 더 큰 효과
explain
select e.*
from (select s.emp_no
from salaries s
where s.emp_no between 10001 and 13000
group by s.emp_no
order by sum(s.salary) desc
limit 10) x,
employees e
where e.emp_no=x.emp_no;
래터럴 조인(Lateral Join)
특정 그룹별로 서브쿼리를 실행해 그 결과와 조인하는 것이 가능
=> 서브쿼리에서 외부 쿼리의 테이블 칼럼 참조 가능
LATERAL 키워드를 가진 서브쿼리는 조인 순서상 후순위로 밀림
실행 계획으로 인한 정렬 흐트러짐
NL 조인 대신 해시 조인이 사용되면 쿼리 결과의 레코드 정렬 순서가 달라짐
8. GROUP BY
WITH ROLLUP
rollup : group by와 함께 사용하며 그룹별로 소계
select dept_no, count(*)
from dept_emp
group by dept_no with rollup;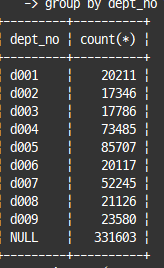
select first_name, last_name, count(*)
from employees
group by first_name, last_name with rollup;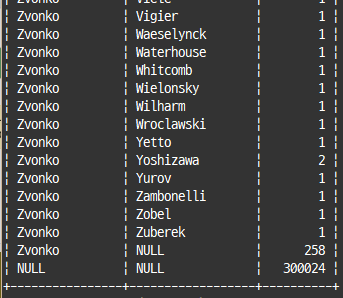
GROUPING() 함수 : 그룹 레코드에 표시되는 null을 사용자가 변경할 수 있도록 함
select if(grouping(first_name), 'All first_name', first_name) as first_name,
if(grouping(last_name), 'All last_name', last_name) as last_name,
count(*)
from employees
group by first_name, last_name with rollup;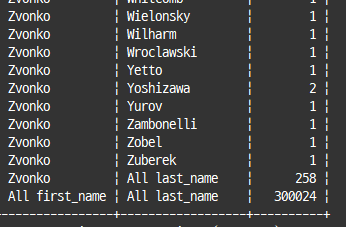
레코드를 칼럼으로 변환해서 조회
피봇(Pivot) 은 sum()이나 count()와 case when..end를 이용해 구현
레코드를 칼럼으로 변환
-- 부서별 사원 수 확인
select dept_no, count(*)
from dept_emp
group by dept_no;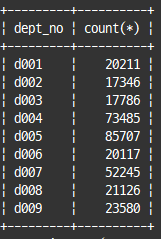
-- 레코드를 칼럼으로 변환
select
sum(case when dept_no='d001' then emp_count else 0 end) as count_d001,
sum(case when dept_no='d002' then emp_count else 0 end) as count_d002,
sum(case when dept_no='d003' then emp_count else 0 end) as count_d003,
sum(case when dept_no='d004' then emp_count else 0 end) as count_d004,
sum(case when dept_no='d005' then emp_count else 0 end) as count_d005,
sum(case when dept_no='d006' then emp_count else 0 end) as count_d006,
sum(case when dept_no='d007' then emp_count else 0 end) as count_d007,
sum(case when dept_no='d008' then emp_count else 0 end) as count_d008,
sum(case when dept_no='d009' then emp_count else 0 end) as count_d009,
sum(emp_count) as count_total
from (
select dept_no, count(*) as emp_count from dept_emp group by dept_no
) tb_derived;
하나의 칼럼을 여러 칼럼으로 분리
-- 전체 사원수와 입사 연도별 사원 수 구함
select de.dept_no,
sum(case when e.hire_date between '1980-01-01' and '1989-12-31' then 1 else 0 end) as cnt_1980,
sum(case when e.hire_date between '1990-01-01' and '1999-12-31' then 1 else 0 end) as cnt_1990,
sum(case when e.hire_date between '2000-01-01' and '2009-12-31' then 1 else 0 end) as cnt_2000,
count(*) as cnt_total
from dept_emp de, employees e
where e.emp_no=de.emp_no
group by de.dept_no;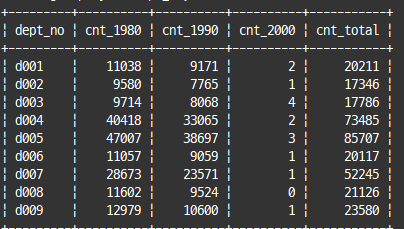
9. ORDER BY
어떤 순서로 정렬할지 결정
ORDER BY 사용법 및 주의사항
1개 또는 그 이상 여러 개 칼럼으로 정렬 수행 가능
여러 방향으로 동시 정렬
각 칼럼의 정렬 순서가 오름차순과 내림차순이 혼용되면 인덱스 사용 불가
=> 인덱스 생성 자체를 혼용해서 생성
함수나 표현식을 이용한 정렬
함수 기반 인덱스를 이용해 정렬 가능
10. 서브쿼리
SELECT 절에 사용된 서브쿼리
인덱스를 사용할 수 있다면 크게 주의할 사항 없음
레코드는 무조건 1건 존재
서브쿼리 결과가 0건이면, 서브쿼리 결과는 null로 채워져서 반환
select emp_no, (select dept_name from departments where dept_name='Sales1')
from dept_emp limit 10;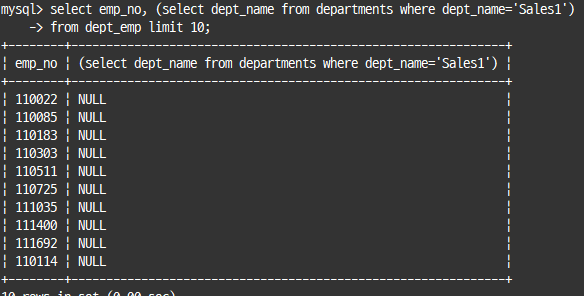
래터럴 조인을 사용하면, 인덱스를 통해 정렬된 결과를 가져올 수 있음에도, Using filesort가 실행되는 버그 있음
FROM 절에 사용된 서브쿼리
서브쿼리 결과를 임시 테이블로 저장하고, 필요할 때 다시 임시 테이블을 읽음
=> from 절의 서브쿼리를 외부 쿼리로 병합하는 최적화
explain
select *
from (select * from employees) y;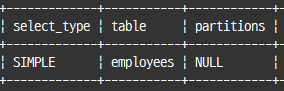
show warnings \g
from 절의 서브쿼리가 외부 쿼리로 병합되지 못하는 경우
- 집합 함수 사용
- distinct
- group by 또는 having
- limit
- union 또는 union all
- select 절에 서브쿼리가 사용된 경우
- 사용자 변수 사용
order by 절을 가진 경우, 외부 쿼리가 group by나 distinct를 사용하지 않는다면, 서브쿼리 정렬 조건을 외부 쿼리로 병합
WHERE 절에 사용된 서브쿼리
동등 또는 크다 작다 비교(= (subquery))
이전까진 서브쿼리 외부 조건으로 쿼리 실행을 하고, 최종적으로 서브쿼리를 체크 조건으로 사용
=> 성능 저하 심각
explain
select * from dept_emp de
where de.emp_no=(select e.emp_no
from employees e
where e.first_name='Georgi' and e.last_name='Facello' limit 1);5.5 이전까진 dept_emp 테이블을 풀 스캔하면서 서브쿼리 조건에 일치하는지 여부를 체크
5.5 부터는 서브쿼리를 먼저 실행한 후 상수로 변환해, 상숫값을 서브쿼리로 대체해서 처리
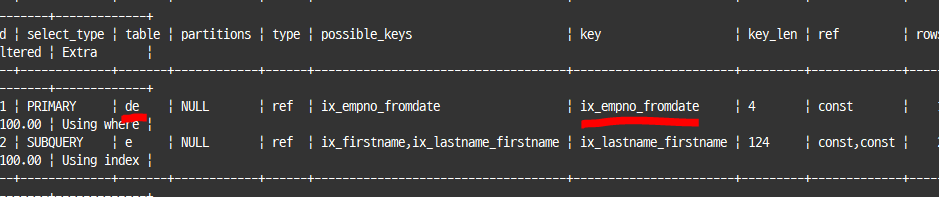
단일 값 비교가 아닌 튜플 비교 방식을 사용하면, 서브쿼리가 먼저 처리되어 상수화되긴 하지만 외부 쿼리는 인덱스 사용 불가
=> ex. ~~where (emp_no, from_date)= (select emp_no, from_date ~~);
IN 비교( IN (subquery))
세미 조인 : where 절에 사용된 in (subquery) 형태의 조건
NOT IN 비교( NOT IN (subquery))
안티 세미 조인 : not in 형태의 조건
=> 인덱스 제대로 활용 불가
11. CTE(Common Table Expression)
이름을 가지는 임시 테이블로, SQL 문장 종료시 자동으로 CTE 임시 테이블은 삭제
비 재귀적 CTE(Non-Recursive CTE)
with cte1 as (select * from departments)
select * from cte1;cte 쿼리는 with절로 정의
cte로 생성된 임시 테이블은 다른 cte 쿼리에서 참조 가능
재귀적 CTE(Recursive CTE)
with recursive cte(no) as (
select 1 -- 비 재귀적 파트
union all
select (no+1) from cte where no<5 --재귀적 파트
)
select * from cte;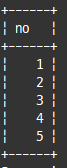
비 재귀적 쿼리 파트와 재귀적 쿼리 파트로 구분
=> 이 둘을 union 또는 union all로 연결하는 형태로 반드시 작성
cte 테이블의 모든 레코드를 조회하는 것이 아니라, 직전 단계에서 만들어진 결과만을 참조
재귀 쿼리가 반복을 멈추는 조건은 재귀 파트 쿼리의 결과가 0건일 때까지
-- CTE 임시 테이블의 칼럼명 변경
with cte1(fd1, fd2, fd3) as (select * from departments)
select * from cte1;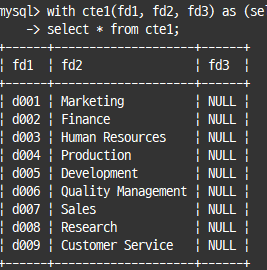
재귀적 CTE(Recursive CTE) 활용
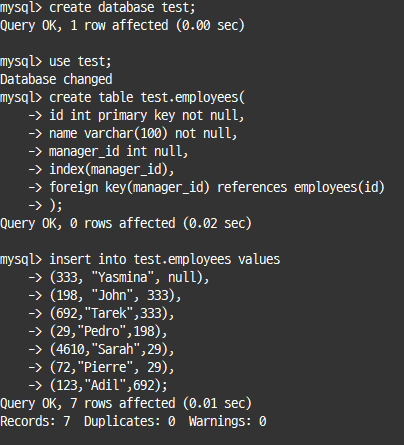
# Adil(id=123)의 상위 조직장 찾는 쿼리
with recursive managers as
(select *, 1 as lv from employees where id=123
union all
select e.*, lv+1 from managers m
inner join employees e on e.id=m.manager_id and m.manager_id is not null
)
select * from managers
order by lv desc;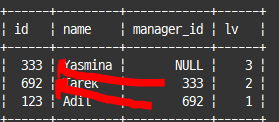
12. 윈도우 함수(Window Function)
조회하는 현재 레코드를 기준으로 연관된 레코드 집합의 연산 수행
=> 레코드 건수는 변하지 않음
쿼리 각 절의 실행 순서
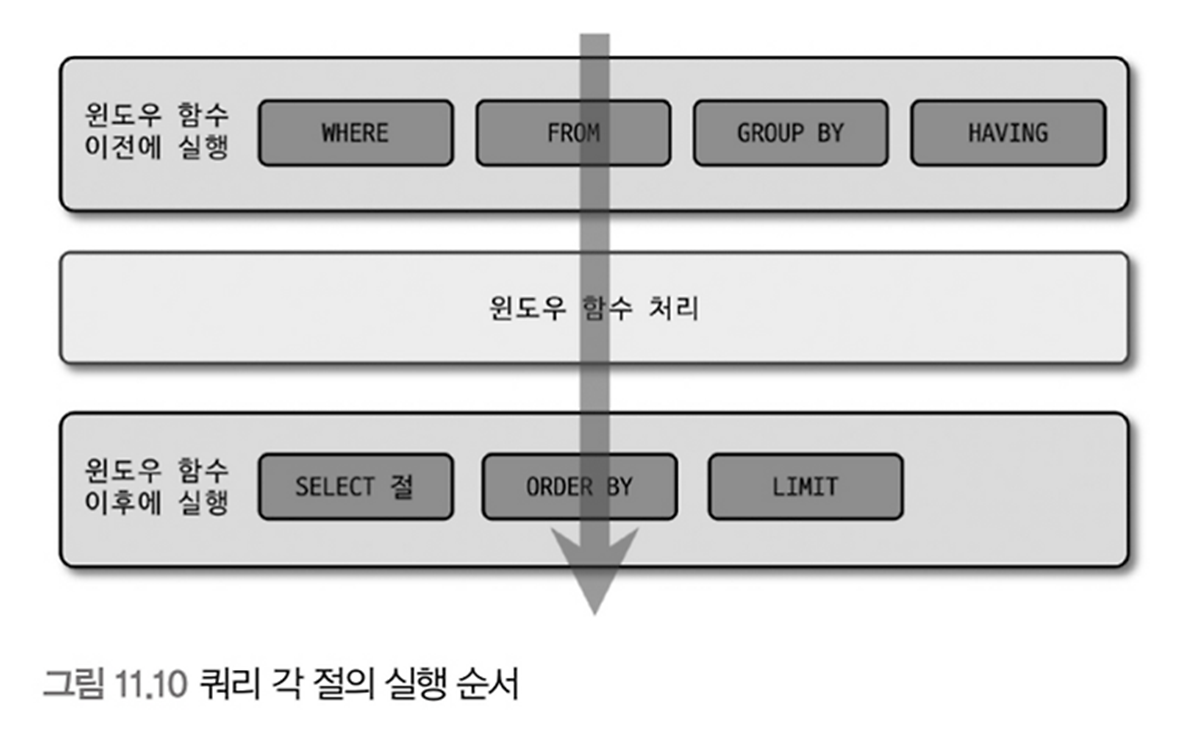
이 순서를 벗어나는 쿼리 작성하고자 한다면 from 절의 서브쿼리 사용해야 함
윈도우 함수 기본 사용법
aggregate_func() over (<partition> <order>) as window_func_column-- 부서별 입사 순위
select de.dept_no, e.emp_no, e.first_name, e.hire_date,
rank() over(partition by de.dept_no order by e.hire_date) as hire_date_rank
from employees e inner join dept_emp de on de.emp_no=e.emp_no
order by de.dept_no, e.hire_date;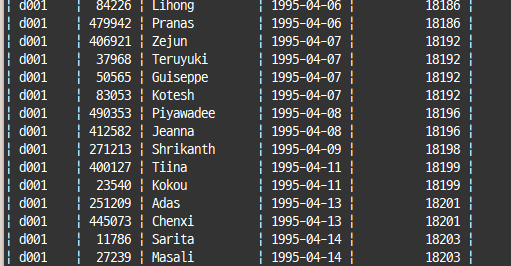
aggregate_func() over(<partition> <order> <frame>) as window_func_column
-- 프레임 : 연산 범위 제한하는 역할
frame:
{ ROWS|RANGE } {frame_start|frame_between}
#ROWS : 레코드의 위치를 기준으로 프레임을 생성
#RANGE : ORDER BY 절에 명시된 칼럼을 기준으로 값의 범위로 프레임 생성current row: 현재 레코드unbounded preceding: 파티션의첫번째 레코드unbounded following: 파티션의마지막레코드expr preceding: 현재 레코드로부터n번째 이전레코드expr following: 현재 레코드로부터n번째 이후레코드
rows로 구분되면 expr에는 레코드 위치 명시
range로 구분되면 expr에는 칼럼과 비교할 값이 설정돼야 함
=> 10 preceding : 현재 레코드로부터 10건 이전부터
=> interval 5 day preceding : 현재 레코드의 칼럼값보다 5일 이전 레코드부터
select emp_no, from_date, salary,
min(salary) over(order by from_date range interval 1 year preceding) as min_1
from salaries
where emp_no=10001;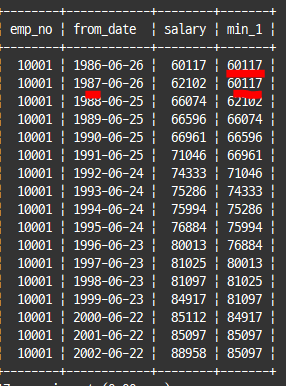
order by 사용 시 : range between unbounded preceding and current row
order by 미 사용 시 : range between unbounded preceding and unbounded following
자동으로 프레임이 파티션의 전체 레코드로 설정
cume_dist()dense_rank()lag()lead()ntile()percent_rank()rank()row_number()
윈도우 함수
집계 함수는 over() 절 없이 단독으로 사용 가능
비 집계 함수는 반드시 over() 절을 가지고 있어야 함
| 집계 함수 | 설명 |
|---|---|
| avg() | 평균 값 반환 |
| bit_and() | and 비트 연산 결과 반환 |
| bit_or() | or 비트 연산 결과 반환 |
| bit_xor() | xor 비트 연산 결과 반환 |
| count() | 건수 반환 |
| json_arrayagg() | 결과를 json 배열로 반환 |
| json_objectagg() | 결과를 json object 배열로 반환 |
| 비 집계 함수 | 설명 |
|---|---|
| cume_dist() | 누적 분포 값 반환 |
| dense_rank() | 랭킹 값 반환(동일값 동일 순위) |
| first_value() | 파티션의 첫 번째 레코드 값 |
| lag() | n번째 이전 레코드 값 |
| last_value() | 파티션의 마지막 레코드 값 |
| lead() | n번째 이후 레코드 값 |
| nth_value() | n번째 값 |
| ntile() | 전체 건수를 n 등분 |
| percent_rank() | 퍼센트 랭킹 값 |
| rank() | 랭킹 값 |
| row_number() | 레코드 순번 |
DENSE_RANK()와 RANK(), ROW_NUMBER()
rank() : 동점인 레코드가 두 건 이상인 경우, 그 다음 레코드를 동점 레코드 수만큼 증가시킨 순위 반환
dense_rank() : 동점인 레코드를 1건으로 가정
row_number() : 정렬된 순서대로 레코드 번호 부여
LAG()와 LEAD()
lag() : n번째 이전 레코드 반환
lead() : n번째 이후 레코드 반환
select from_date, salary,
lag(salary,5) over (order by from_date) as prior,
lead(salary,5,-1) over (order by from_date) as next
from salaries
where emp_no=10001;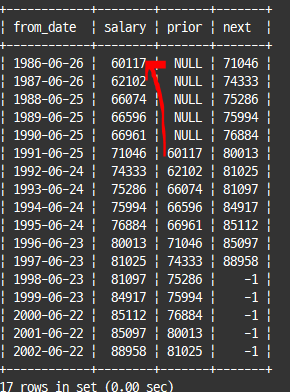
윈도우 함수와 성능
윈도우 함수는 인덱스를 전혀 활용하지 못해 테이블 풀 스캔
13. 잠금을 사용하는 SELECT
for share : select 쿼리로 읽은 레코드에 대해 읽기 잠금
=> 다른 세션에서 해당 레코드 변경 불가(읽기 가능)
for update : select 쿼리로 읽은 레코드에 대해 쓰기 잠금
=> 다른 세션에서 해당 레코드 변경 및 읽기 불가(for share절 사용하는 select)
select * from employees where emp_no=10001 for share;
select * from employees where emp_no=10001 for update;두 옵션 모두 자동 커밋이 비활성화된 상태 또는 begin 명령이나 start transaction 명령으로 트랜잭션이 시작된 상태에서만 잠금 유지
for share이나 for update가 없는 단순한 select는 대기 없이 실행
잠금 테이블 선택
select *
from employees e
inner join dept_emp de on de.emp_no=e.emp_no
inner join departments d on d.dept_no=de.dept_no
for update;innodb는 3개 테이블에서 읽은 레코드에 대해 모두 쓰기 잠금을 건다
of 테이블 절을 추가해 해당 테이블에 대해서만 잠금 걸 수 있음
select *
from employees e
inner join dept_emp de on de.emp_no=e.emp_no
inner join departments d on d.dept_no=de.dept_no
for update of e;NOWAIT & SKIP LOCKED
nowait : 이미 레코드가 잠겨진 상태라면 무시하고 즉시 에러 반환
skip locked : 다른 트랜잭션에 의해 잠겨진 상태라면, 잠긴 레코드는 무시하고 잠금이 걸리지 않은 레코드만 가져옴
🥔INSERT
1. 고급 옵션
insert ignore 옵션과 insert ... on duplicate key update 옵션 모두 유니크 인덱스나 프라이머리 키에 대해 중복 레코드를 어떻게 처리할지 결정
=> ignore 옵션은 추가로 에러 핸들링 기능도 포함
INSERT IGNORE
저장하는 레코드의 프라이머리 키나 유니크 인덱스 칼럼 값이 이미 테이블에 존재하는 레코드와 중복되는 경우, 저장하는 레코드의 칼럼이 테이블의 칼럼과 호환되지 않는 경우 모두 무시하고 다음 레코드 처리
insert ignore into salaries
select emp_no, (salary+100), '2020-01-01','2022-01-01'
from salaries where to_date>='2020-01-01';데이터 타입이 일치하지 않을 경우, 칼럼의 기본 값으로 insert
=> 만약 null 입력시, 숫자 칼럼 기본 값인 0을 대신 insert
INSERT ... ON DUPLICATE KEY UPDATE
프라이머리 키나 유니크 인덱스의 중복 발생시 update 문장 역할 수행
=> 중복된 레코드 존재시, 기존 레코드 삭제하지 않고 update하는 방식
=> replace 문장 : delete와 insert의 조합
insert into daily_statistics (target_date, stat_name, stat_value)
values (date(now()), 'visit', 1)
on duplicate key update stat_value=stat_value+1;count(*)와 같은 group by 결과 참조 불가능
=> values() 함수 사용
values() 함수 : 실제 저장하려고 했던 값이 무엇인진 몰라도, 칼럼에 insert하고자 했던 값 가져옴
on duplicate key update stat_value=stat_value+values(stat_value);
-- stat_value 칼럼에 insert 하려고 했던 값 다시 가져옴
# 8.0.20 이후 지원X 예정#인라인 뷰 사용 또는
insert ...
from ()
on duplicate~~
#별칭 부여
insert ~~ as new
on duplicate~~ +new.stat_value;2. LOAD DATA 명령 주의 사항
데이터를 빠르게 적재
=> insert 명령과 비교했을 때 매우 빠름
단점
단일 스레드로 실행단일 트랜잭션으로 실행
데이터 파일을 여러 개로 준비해서 load data 문장을 실행하거나, insert .. select 문장으로 적재하는 것이 좋음
LOAD DATA
[LOW_PRIORITY | CONCURRENT] [LOCAL]
INFILE 'file_name'
[REPLACE | IGNORE]
INTO TABLE tbl_name
[PARTITION (partition_name [, partition_name] ...)]
[CHARACTER SET charset_name]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
[IGNORE number {LINES | ROWS}]
[(col_name_or_user_var
[, col_name_or_user_var] ...)]
[SET col_name={expr | DEFAULT}
[, col_name={expr | DEFAULT}] ...]3. 성능을 위한 테이블 구조
insert 문장 성능은 쿼리 문장 자체보다 테이블 구조에 의해 많이 결정
대량 INSERT 성능
하나의 insert 문장으로 여러 레코드를 insert한다면, insert될 레코드들을 프라이머리 키 값 기준으로 미리 정렬해서 insert 문장 구성
프라이머리 키 선정
프라이머리 키 선정은 select 성능과 insert 성능의 대립되는 두 가지 요소 중에 하나를 선택
Auto-Increment 칼럼
select보다는 insert에 최적화된 테이블 생성
단조 증가또는단조 감소되는 값으로프라이머리 키선정세컨더리 인덱스 최소화
자동 증가(Auto Increment) 칼럼을 이용하면 클러스터링되지 않는 테이블의 효과 얻음
create table(
id bigint not null auto_increment,
...
primary key(id)
);자동 증가 값을 프라이머리 키로 해서 테이블 생성하면, 가장 빠른 Insert 보장
자동 증가 값의 채번을 위해 잠금 필요
=> auto-inc 잠금
last_insert_id() : 현재 커넥션에서 가장 마지막에 증가된 auto_increment 값
🧄UPDATE와 DELETE
MySQL에는 여러 테이블을 조인해서 한 개 이상 테이블의 레코드를 변경하거나 삭제 가능
1. UPDATE ... ORDER BY ... LIMIT n
MySQL에서는 order by 절과 limit 절을 동시에 사용해 특정 칼럼으로 정렬해서, 상위 몇 건만 변경 및 삭제 가능
delete from employees order by last_name limit 10;2. JOIN UPDATE
두 개 이상의 테이블을 조인해 조인된 결과 레코드를 변경 및 삭제하는 쿼리
=> 조인된 테이블 중 특정 테이블의 칼럼 값을 다른 테이블의 칼럼에 업데이트 시
update tb_test1 t1, employees e
set t1.first_name=e.first_name #employees 테이블의 칼럼 값을 t1 테이블에 복사
where e.emp_no=t1.emp_no;join update 문에서는 group by나 order by 사용 불가
=> 서브쿼리로 그룹핑 후 조인하기
straight_join 키워드 : 조인 키워드로 사용되기도 함
3. 여러 레코드 UPDATE
# 레코드 별로 서로 다른 값 업데이트
update user_lvel ul
inner join (values row(1,1), row(2,4))
new_user_level(user_id, user_lv) #두 건의 레코드를 가지는 임시 테이블 생성
on new_user_level.user_id=ul.user_id
set ul.user_lv=ul.user_lv+new_user_level.user_lv;4. JOIN DELETE
join delete 문장에는 삭제할 테이블 명시해야 함
delete e #employees 테이블 레코드만 삭제
from employees e, dept_emp de, departments d
where e.emp_no=de.emp_no and de.dept_no=d.dept_no and d.dept_no='d001';🧅스키마 조작(DDL)
DBMS 서버의 모든 오브젝트를 생성하거나 변경하는 쿼리
1. 온라인 DDL
이전까진 테이블 구조 변경하는 동안 다른 커넥션에서 DML 실행 불가
=> 8.0 이후 MySQL 서버에 내장된 온라인 DDL 기능으로 처리 가능
온라인 DDL 알고리즘
온라인 DDL : 스키마를 변경하는 작업 도중에도 다른 커넥션에서 해당 테이블의 데이터를 변경하거나 조회하는 작업 가능하게 해줌
=> algorithm과 lock 옵션을 이용
스키마 변경에 적합한 알고리즘 찾는 순서
algorithm=instant로 스키마 변경 가능한지 확인 후, 가능하면 선택algorithm=inplace로 스키마 변경 가능한지 확인 후, 가능하면 선택algorithm=copy알고리즘 선택
스키마 변경 알고리즘의 우선순위가 낮을수록, 스키마 변경을 위해 더 큰 잠금과 많은 작업을 필요로 함
instant: 테이블의 데이터는 전혀 변경하지 않고,메타데이터만 변경하고 작업 완료inplace: 임시 테이블로 데이터를복사하지 않고스키마 변경 실행copy: 변경된 스키마를 적용한임시 테이블을 생성하고, 테이블의 레코드를 모두임시 테이블로복사한 후 임시 테이블rename해서 스키마 변경 완료
Lock 옵션
none: 아무런 잠금을 걸지 않음shared:읽기 잠금을 걸고 스키마 변경 실행
=> 읽기는 가능하지만쓰기는 불가함exclusive:쓰기 잠금을 걸고 스키마 변경
inplace 알고리즘을 사용하면, 내부적으로 테이블 리빌드가 필요할 수 있음
=> 프라이머리 키를 추가하는 경우, 데이터 파일에서 레코드의 저장 위치가 바뀌어야 하기 때문
=> Data Reorganizing 또는 Table Rebuild
온라인 처리 가능한 스키마 변경
모든 스키마 변경 작업이 온라인으로 가능한 것이 아니므로, 온라인으로 처리될 수 있는지 아니면 테이블의 읽고 쓰기가 대기하게 되는지 확인
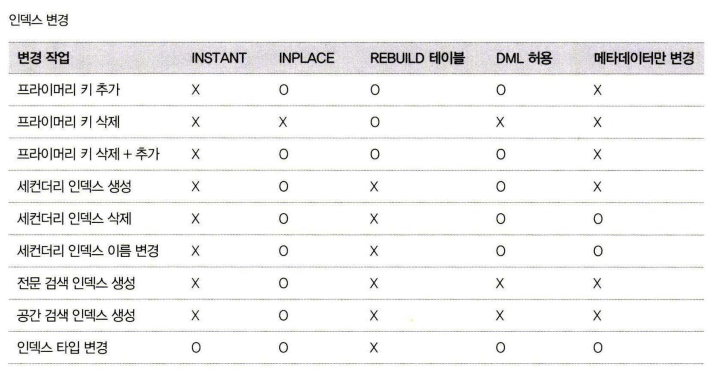
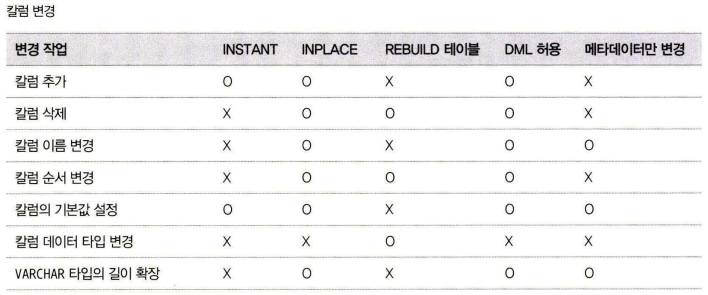
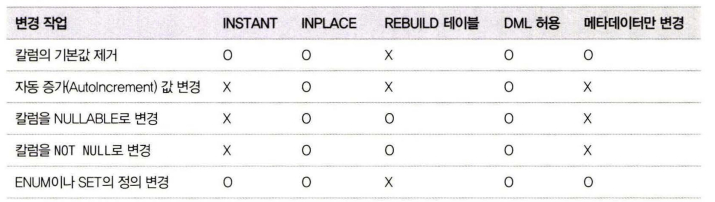
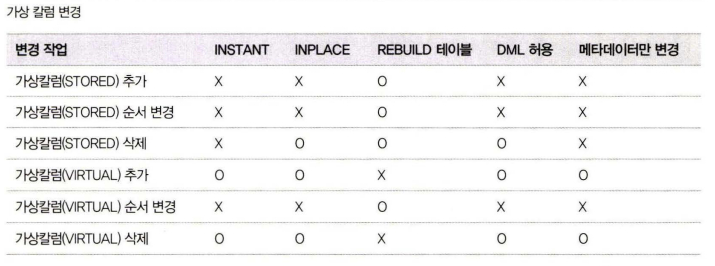

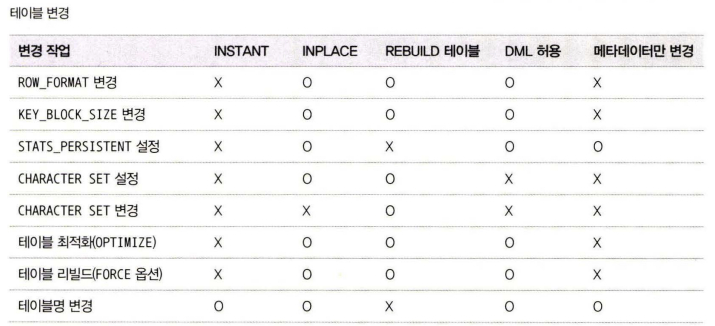
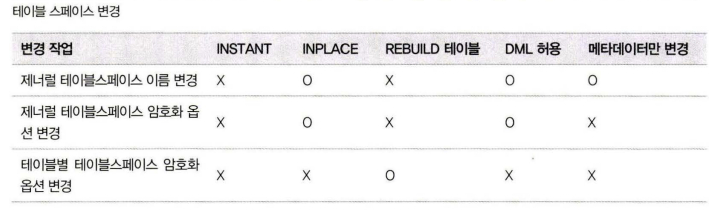
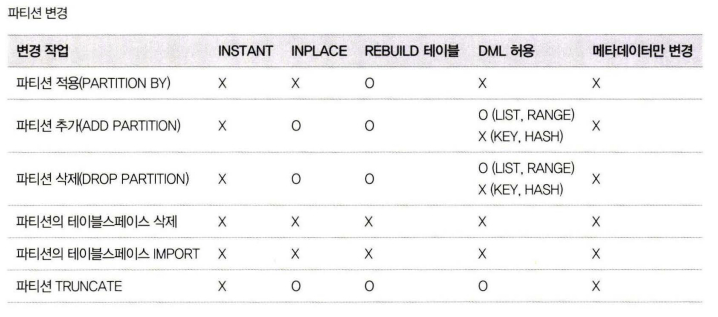
https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html
INPLACE 알고리즘
임시 테이블로 레코드를 복사하진 않더라도 내부적으로 테이블의 모든 레코드를 리빌드해야 하는 경우 많음
inplace 스키마 변경이 지원되는 스토리지 엔진의 테이블인지 확인inplace 스키마 변경준비- 테이블 스키마
변경및 새로운 DML로깅
=> 다른 스레드에서 사용자에 의해 발생한 DML들에 대해 로그 기록 로그 적용( DML 로그를 테이블에 적용)- 스키마 변경 완료(
commit)
inplace 알고리즘으로 온라인 스키마 변경이 진행되는 동안 새로 유입된 DML 쿼리들에 의해 변경되는 데이터를 온라인 변경 로그에 쌓아두었다가 실제 테이블로 일괄 적용
온라인 DDL의 실패 케이스
- alter table 명령이 장시간 실행되고 동시에 다른 커넥션에서
DML이 많이 실행되는 경우, 또는
온라인 변경 로그공간이 부족한 경우 - alter table 이전 버전
테이블 구조에서는 아무런 문제가 안되지만alter table이후테이블 구조에는 적합하지 않은 레코드가insert또는update시 - 스키마 변경을 위해 필요한 잠금 수준보다
낮은 잠금 옵션이 사용된 경우 - 온라인 스키마 변경은
lock=none으로 실행되더라도,변경 작업의처음과마지막에잠금필요한데 획득하지 못하고타임 아웃발생시 - 온라인으로
인덱스 생성시 정렬을 위해tmpdir에 설정된 디스크 임시 디렉터리 사용하는데, 이공간이 부족한 경우
온라인 DDL 진행 상황 모니터링
performance_schema를 통해 진행 상황 모니터링
set global performance_schema=on; # 서버 재시작 필요#Instrument 활성화
update performance_schema.setup_instruments
set enabled='YES', timed='YES'
where name like 'stage/innodb/alter%';#Consumer 활성화
update performance_schema.setup_consumers
set enabled='YES'
where name like '%stages%';스키마 변경 작업의 진행 상황은 performance_schema.events_stages_current 테이블을 통해 확인
select event_name, work_completed, work_estimated
from performance_schema.events_stages_current;온라인 DDL은 단계 별로 event_name 칼럼 값이 달라져 여러개 보임
| EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED |
|---|---|---|
| ~~~(read PK and internal sort) | 9776 | 25281 |
work_estimated는 예측치
work_completed는 현재까지 완료된 정도
2. 데이터베이스 변경
MySQL 서버는 스키마와 데이터베이스가 동격의 개념이며, 하나의 인스턴스는 1개 이상의 데이터베이스를 가질 수 있음
데이터베이스 생성
create database [if not exists] employees
character set utf8mb4 collate utf8mb4_general_ci;데이터베이스 목록
show databases;
데이터베이스 선택
use employees;데이터베이스 속성 변경
#데이터베이스 생성 시 지정한 문자 집합 또는 콜레이션 변경
alter database employees character set=euckr;데이터베이스 삭제
drop database [if exists] employees;3. 테이블 스페이스 변경
InnoDB 스토리지 엔진의 시스템 테이블 스페이스(ibdata1)만 제너럴 테이블스페이스 사용
=> 제너럴 테이블스페이스 : 여러 테이블의 데이터를 한꺼번에 저장하는 테이블스페이스
제너럴 테이블스페이스 제약사항
파티션 테이블은 제너럴 테이블스페이스 사용 불가복제 소스와레플리카 서버가동일 호스트에서 실행되는 경우add datafile 문장사용 불가테이블 암호화는 테이블스페이스 단위로 설정테이블 압축 가능 여부는 테이블스페이스 블록 사이즈와 InnoDB 페이지 사이즈에 의해 결정- 특정 테이블을
삭제해도디스크 공간이 운영체제로 반납 X
제너럴 테이블스페이스 장점
파일 핸들러최소화테이블스페이스 관리에 필요한메모리 공간최소화
=> 테이블 개수가 많은 경우 유용
기본 설정은 자동으로 개별 테이블스페이스 사용
4. 테이블 변경
테이블 생성
create [temporary] table t (
칼럼명 칼럼타입 [타입별 옵션] [NULL 여부] [기본값]
#ex. member_point int [not null] [default 0]
)engine=INNODB;temporary 키워드 : 해당 데이터베이스 커넥션(세션)에서만 사용 가능한 임시 테이블 생성
테이블 구조 조회
# 테이블의 create table 문장 표시
show create table 테이블명 \G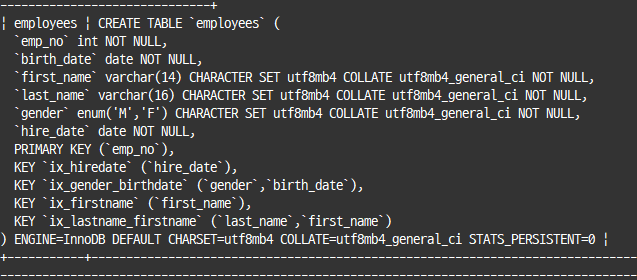
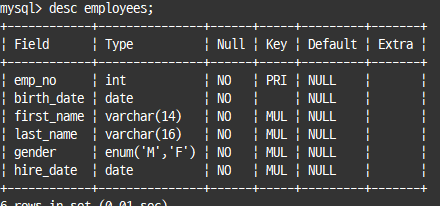
desc 테이블명;desc 명령은 인덱스 칼럼 순서나 외래키, 테이블 자체의 속성을 보여주진 않음
테이블 구조 변경
alter table 명령 사용
=> 테이블 자체 속성 변경 및 인덱스 추가, 삭제 등
테이블 자체에 대한 속성 변경
=> 테이블의 문자 집합이나 스토리지 엔진, 파티션 구조 등 변경
alter table employees
convert to cahracter set utf8mb4 ~~;
#기본 문자 집합 및 콜레이션 변경
alter table employees engine=innodb,
algorithm=inplace, lock=none;
# 테이블의 데이터를 복사하는 작업 실행
# 테이블 리빌드 작업을 위해 사용하기도 함
# 테이블 리빌드 : 레코드 삭제가 발생하는 테이블에서 빈 공간 제거하는 역할테이블 명 변경
rename table 명령
rename table table1 to table2;
rename table db1.table1 to db2.table2;
# 다른 데이터베이스로 테이블 이동 가능테이블 상태 조회
show table status like 테이블명 \G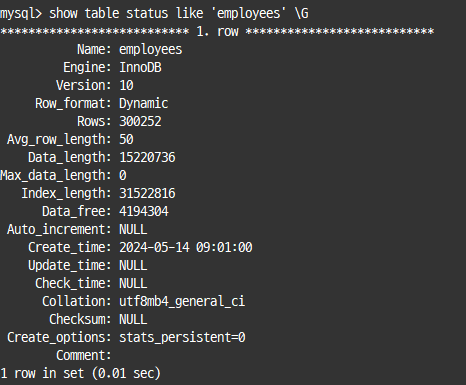
information_schema 데이터베이스에는 데이터베이스와 테이블에 대한 메타 정보를 모아서 메모리에 모아두고 참조
테이블 구조 복사
create table .. as select .. limit 0은 인덱스가 생성되지 않는다는 단점 존재
create table 테이블명 like 테이블명;모든 칼럼과 인덱스가 같은 테이블 생성
테이블 삭제
drop table [if exists] table1;5. 칼럼 변경
칼럼 추가
칼럼 추가 작업은 대부분 inplace 알고리즘을 사용하는 온라인 DDL로 처리 가능
테이블의 제일 마지막 칼럼으로 추가하는 경우 instant 알고리즘으로 즉시 추가
alter table 테이블명 add column 컬럼명 컬럼타입;
#테이블 중간에 칼럼 추가
alter table employees add column emp_telno varchar(20) after emp_no,
algorithm=inplace, lock=none;칼럼 삭제
칼럼 삭제는 항상 테이블 리빌드를 필요로 하므로 instant 알고리즘 사용 불가
=> inplace 알고리즘으로만 칼럼 삭제 가능
#column 키워드 삭제 가능
alter table employees drop column emp_telno,
algorithm=inplace, lock=none;칼럼 이름 및 칼럼 타입 변경
#이름 변경
alter table salaries change to_date end_date date not null;
#타입 변경
alter table salaries modify salary varchar(20);
# 타입 변경 시 copy 알고리즘 필요6. 인덱스 변경
인덱스 추가
alter table 테이블명 add primary key (칼럼명), ...
alter table 테이블명 add unique index 인덱스명 (칼럼명)..인덱스 조회
show index from 테이블명;
인덱스 이름 변경
alter table 테이블명 rename index 인덱스명 to 바꿀인덱스명,
algorithm=inplace, lock=none;인덱스 가시성 변경
alter table drop index : 인덱스 삭제
인덱스 가시성 : MySQL 서버가 쿼리 실행을 할 때 해당 인덱스를 사용할 수 있게 할지 말지를 결정
#특정 인덱스 사용 못하게 함
alter table employees alter index ix_firstname invisible;인덱스 삭제
alter table 테이블명 drop index 인덱스명
alter table 테이블명 drop primary key, algorithm=copy, lock=shared;프라이머리 키 삭제 작업은 모든 세컨더리 인덱스의 리프 노드에 저장된 프라이머리 키 값을 삭제해야 하므로, 임시 테이블로 레코드 복사해서 테이블 재구축
7. 테이블 변경 묶음 실행
온라인 DDL이 가능하다면, 개별로 실행하고 그렇지 않다면 모아서 실행하는 것이 효율적
alter table 테이블명
add index ~~
add index ~~
algorithm=inplace, lock=none;8. 프로세스 조회 및 강제 종료
사용자 목록이나 각 클라이언트 사용자가 어떤 쿼리를 실행하고 있는지 확인
show processlist;
#커넥션 또는 쿼리 강제 종료
kill query id번호; #쿼리 종료
kill id번호; #커넥션 종료9. 활성 트랜잭션 조회
트랜잭션 목록은 information_schema.innodb_trx 테이블을 통해 확인
select * from infromation_schema.innodb_trx where trx_id=트랜잭션아이디 \G
#어떤 레코드 잠그고 있는지
select * from data_locks \G🥕쿼리 성능 테스트
1. 쿼리의 성능에 영향을 미치는 요소
MySQL 서버가 가지고 있는 여러 종류의 버퍼나 캐시
운영체제의 캐시
MySQL 서버는 운영체제의 파일 시스템 관련 기능(시스템 콜)을 이용해 데이터 파일을 읽어옴
=> 대부분 운영체제는 한 번 읽은 데이터를 운영체제가 관리하는 별도의 캐시 영역에 보관
$ sync #캐시나 버퍼 내용을 디스크와 동기화
$ echo 3>/proc/sys/vm/drop_cahces # 캐시 초기화MySQL 서버의 버퍼 풀(InnoDB 버퍼 풀과 MyISAM의 키 캐시)
MySQL 서버에서도 데이터 파일의 내용을 페이지 단위로 캐시하는 기능 제공
=> InnoDB의 캐시를 버퍼 풀
=> MyISAM의 캐시를 키 캐시
독립된 MySQL 서버
MySQL 서버가 기동 중인 장비에 웹 서버나 다른 배치용 프로그램이 실행된다면, 테스트하려는 쿼리의 성능이 영향을 받게 됨
쿼리 테스트 횟수
테스트하려는 쿼리를 번갈아 가면서 6~7번 실행한 후, 처음 한두번 결과를 버리고 나머지 결과의 평균값을 기준으로 비교
