📔설명
디스크 읽기 방식, 인덱스 종류들, 외래키에 대해 알아보자
🍈디스크 읽기 방식
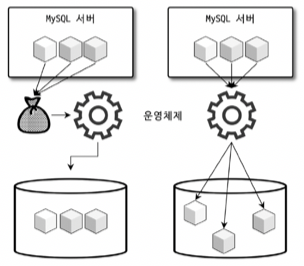
순차 I/O는 3개의 페이지를 읽기 위해 1번 시스템 콜 요청 (왼)
랜덤 I/O는 3개의 페이지를 읽기 위해 3번 시스템 콜 요청 (오)
🍉인덱스란?
인덱스 : 칼럼 값과 해당 레코드가 저장된 주소를 키와 값의 쌍(Key-Value Pair)으로 만듦
=> 칼럼의 값을 미리 정렬
=> 데이터의 저장(Insert, Update, Delete) 성능을 희생하고 대신 읽기 속도를 높이는 기능
프라이머리 키 : 레코드를 대표하는 칼럼의 값으로 만들어진 인덱스
=> Null 허용 X
=> 중복 허용X
세컨더리 인덱스 : 프라이머리 키 제외한 모든 인덱스
B-Tree 알고리즘 : 칼럼의 값을 변형하지 않고 원래의 값을 이용해 인덱싱
Hash 인덱스 알고리즘 : 칼럼의 값으로 해시값을 계산해서 인덱싱
=> 값을 변형해서 인덱싱하므로 값 일부만 검색하거나 범위 검색할 때는 해시 인덱스 사용 불가
🍊B-Tree 인덱스
B-Tree : 칼럼의 원래 값을 변형시키지 않고 인덱스 구조체 내에서 항상 정렬된 상태로 유지
1. 구조 및 특성

인덱스는 테이블의 키 칼럼만 가지고 있어 나머지 칼럼을 읽으려면 데이터 파일에서 해당 레코드를 찾아야 함
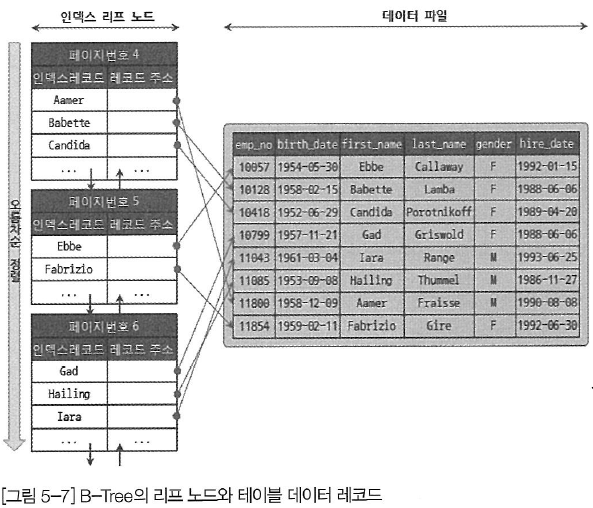
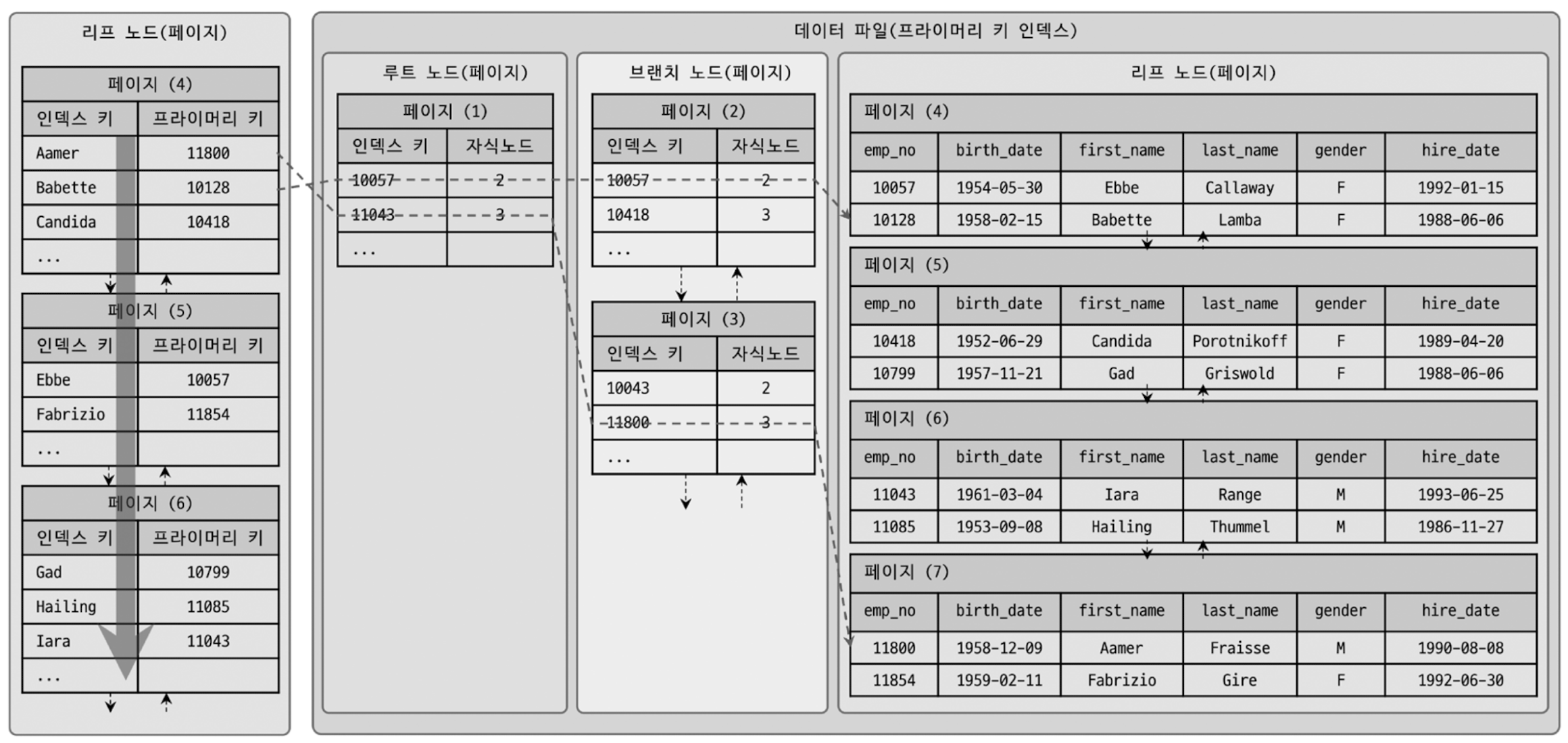
InnoDB 테이블에서 인덱스를 통해 레코드 읽을 경우 프라이머리 키를 저장하고 있는 B-Tree를 다시 한번 검색해야 함
2. B-Tree 인덱스 키 추가 및 삭제
인덱스 키 추가
저장될 키 값을 이용해 B-Tree 상의 적절한 위치를 검색- 저장될 위치 결정시
레코드 키 값과 대상 레코드주소 정보를 B-Tree리프 노드에 저장 리프 노드가 꽉 차서 더는 저장 불가시리프 노드 분리(Split)
인덱스 키 삭제
- 해당 키 값이 저장된 B-Tree의
리프 노드를 찾아서삭제 마크만 하면 작업 완료
인덱스 키 변경
- 키 값을
삭제한 후, 다시 새로운 키 값을추가하는 형태로 처리
인덱스 키 검색
- 인덱스의 키 값에
변형 가해진 경우이용 불가 100% 일치또는값의 앞부분만 일치하는 경우 사용 가능
3. B-Tree 인덱스 사용에 영향을 미치는 요소
인덱스 키 값의 크기
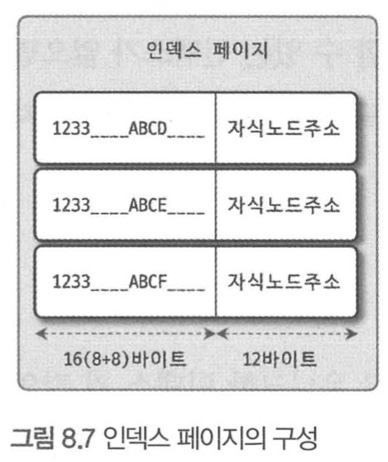
하나의 인덱스 페이지(16KB)에 몇 개의 키를 저장할 수 있을까?
=> 16*1024/(16+12)=585개
=> 자식 노드를 585개
만약 키 값이 커지면 어떻게 될까?
=> 32바이트로 늘어났다면, 16*1024/(32+12) = 372
B-Tree 깊이
인덱스 키 값의 평균 크기가 늘어나면, 추가로 인덱스 깊이가 깊어져서 디스크 읽기가 더 많이 필요해진다
선택도(기수성)
모든 인덱스 키 값 가운데 유니크한 값의 수
=> 선택도가 높을수록 검색 대상이 줄어듦 (유니크한 값이 많아지니까)
읽어야 하는 레코드의 건수
인덱스를 통해 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않고 테이블을 모두 직접 읽어서 필요한 레코드만 가려내는 방식으로 처리하는 것이 효율적
4. B-Tree 인덱스를 통한 데이터 읽기
인덱스 레인지 스캔
인덱스 레인지 스캔 : 검색해야 할 인덱스의 범위가 결정됐을 때 사용
select *
from employees
where first_name between 'Ebbe' and 'Gad';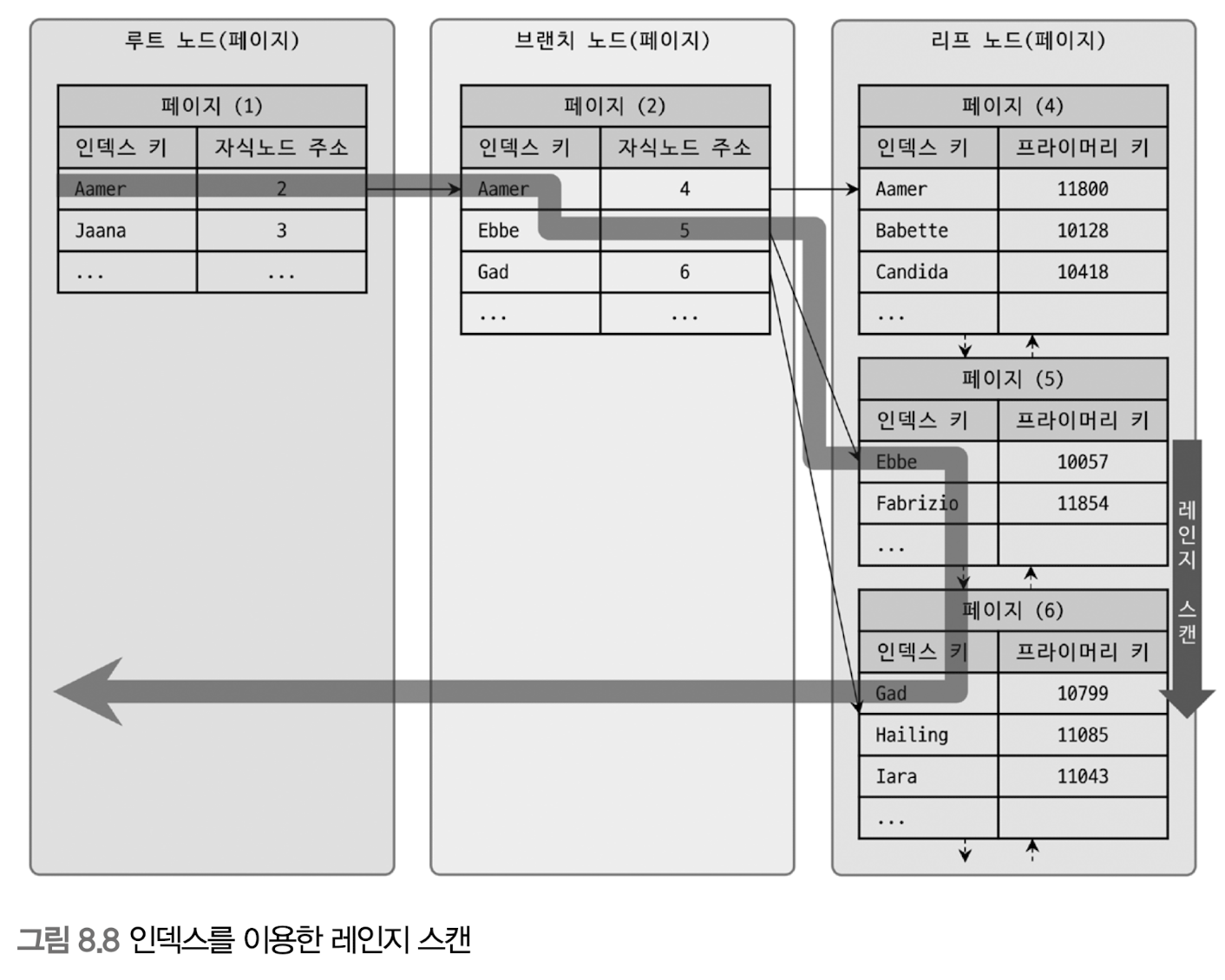
인덱스 레인지 스캔 단계
- 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾음 -
인덱스 탐색 - 탐색된 위치부터 필요한 만큼 인덱스를 차례대로 쭉 읽음 -
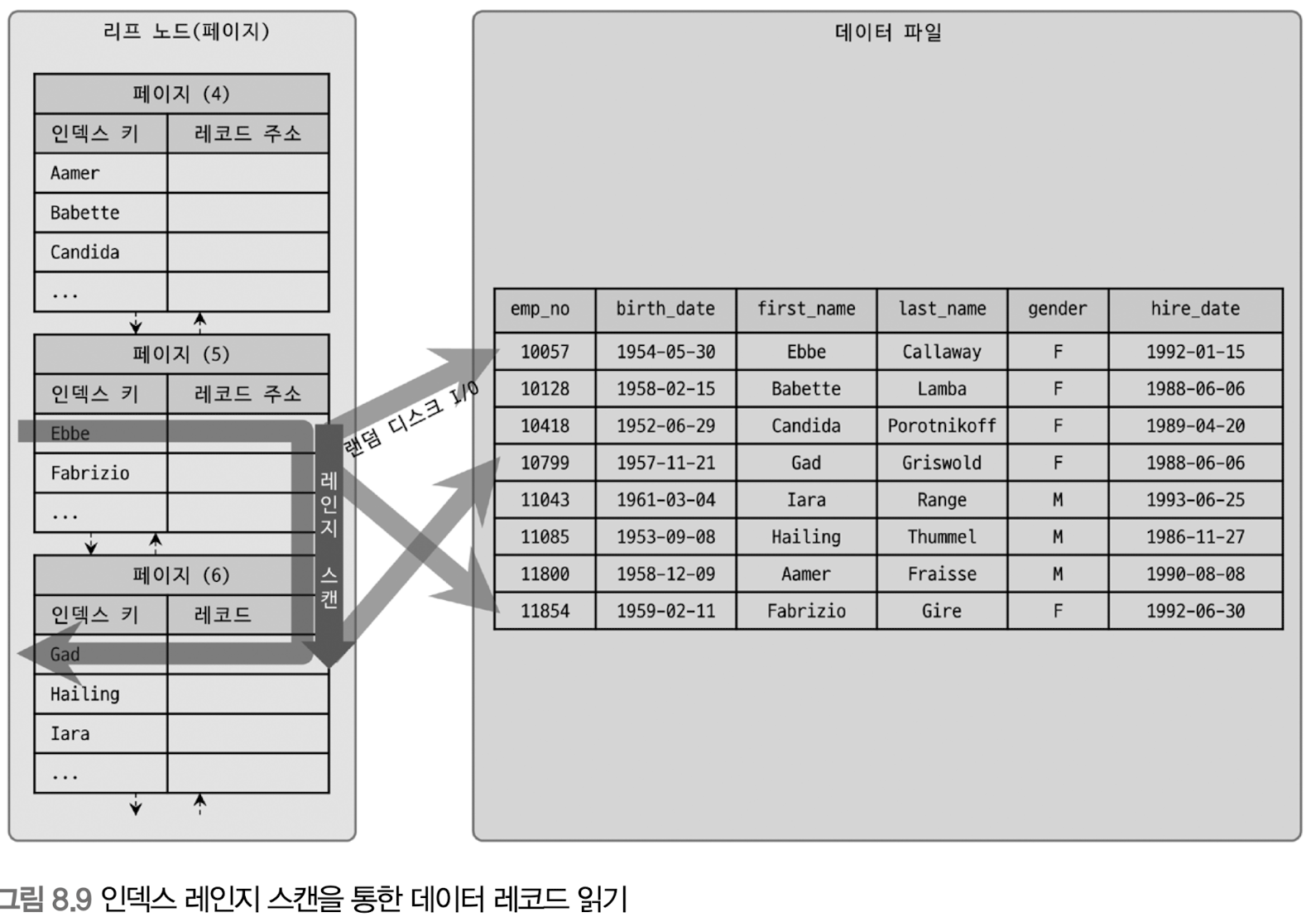
인덱스 스캔 인덱스 키와레코드 주소를 이용해 레코드가 저장된 페이지를 가져와, 최종 레코드 읽음
커버링 인덱스 : 디스크의 레코드를 읽지 않아도 되며, 위 과정 중 세번째 과정 제외한 것
-- 위 단계중 1번, 2번 단계 작업을 얼마나 수행했는지
show status like 'Handler_%';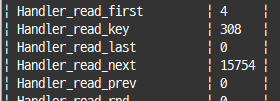
Handler_read_key: 위에서 1번 단계가 실행된 횟수Handler_read_next와Handler_read_prev: 2번 단계로 읽은 레코드 건수
=> 전자는정순, 후자는역순Handler_read_first와Handler_read_last:min()또는max()와 같이 제일 큰 값 또는 제일 작은 값만 읽는 경우 증가
인덱스 풀 스캔
인덱스 풀 스캔 : 인덱스의 처음부터 끝까지 모두 읽는 방식
=> 쿼리의 조건절에 사용된 칼럼이 인덱스의 첫 번째 칼럼이 아닌 경우 사용
=> 인덱스에 포함된 칼럼만으로 쿼리를 처리할 수 있는 경우 효율적

루스 인덱스 스캔
루스 인덱스 스캔 : 인덱스 스캔을 느슨하게 또는 듬성듬성하게 읽는 것
=> Oracle의 인덱스 스킵 스캔
=> group by 또는 max() 또는 min()에 대해 최적화하는 경우
-- 인덱스 : dept_no+emp_no
select dept_no, min(emp_no)
from dept_emp
where dept_no betwwen 'd002' and 'd004'
group by dept_no;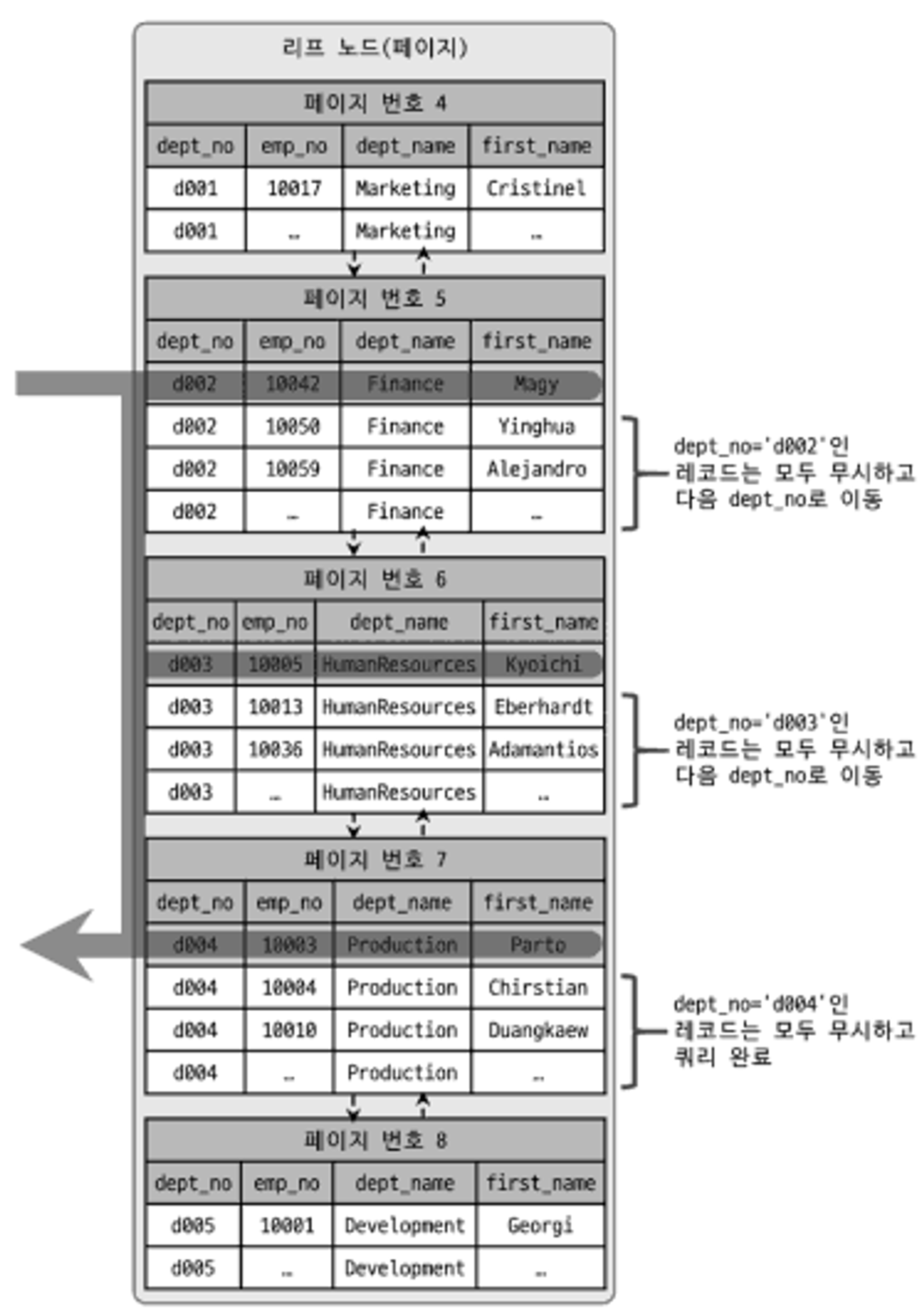
인덱스 스킵 스캔
alter table employees add index ix_gender_birthdate(gender,birth_date);위 인덱스를 사용하려면 gender 칼럼에 대한 비교 조건이 필수였으나, 인덱스 스킵 스캔을 이용해 gender 컬럼을 건너뛰어서 birth_date 칼럼만으로 인덱스 검색 가능하게 해줌
루스 인덱스 스캔은 group by 작업을 처리하기 위해 인덱스 사용하는 경우에만 적용 가능
--인덱스 스킵 스캔 비활성화
set optimizer_switch='skip_scan=off';
explain
select gender, birth_date
from employees
where birth_date>='1965-02-01';
type 칼럼이 index라고 표시된 것은 인덱스 풀 스캔을 의미한다.
--인덱스 스킵 스캔 활성화
set optimizer_switch='skip_scan=on';
explain
select gender, birth_date
from employees
where birth_date>='1965-02-01';
type 칼럼이 range로 표시된 것은 인덱스에서 꼭 필요한 부분만 읽었다는 것 의미
Using index for skip scan으로 표시된 것은 인덱스 스킵 스캔을 활용했다는 것을 의미
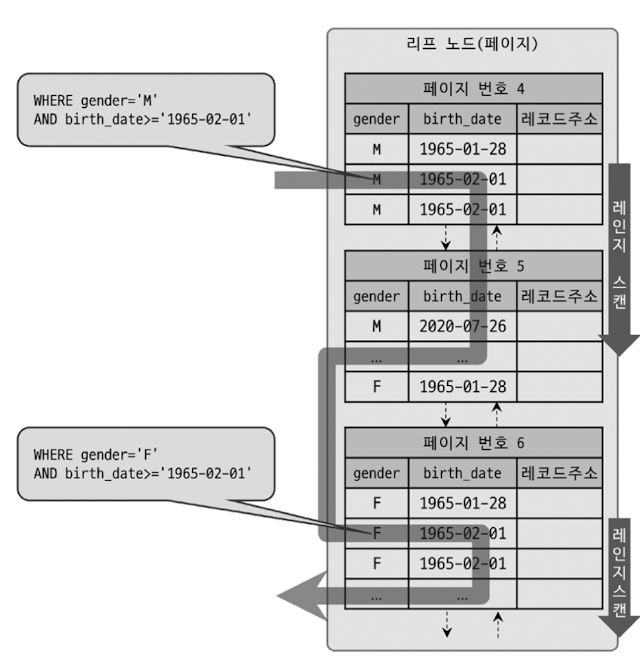
MySQL 옵티마이저는 gender 칼럼에서 유니크한 값을 모두 조회해 주어진 쿼리에 gender 칼럼 조건을 추가해서 쿼리를 다시 실행
select gender, birth_date
from employees
where gender='M'
and birth_date>='1965-02-01';
select gender, birth_date
from employees
where gender='F'
and birth_date>='1965-02-01';인덱스 스킵 스캔 단점
- 조건이 없는 인덱스의
선행 칼럼의 유니크한값의 개수가 적어야 함 - 쿼리가
인덱스에 존재하는 칼럼만으로 처리 가능해야 함 -커버링 인덱스
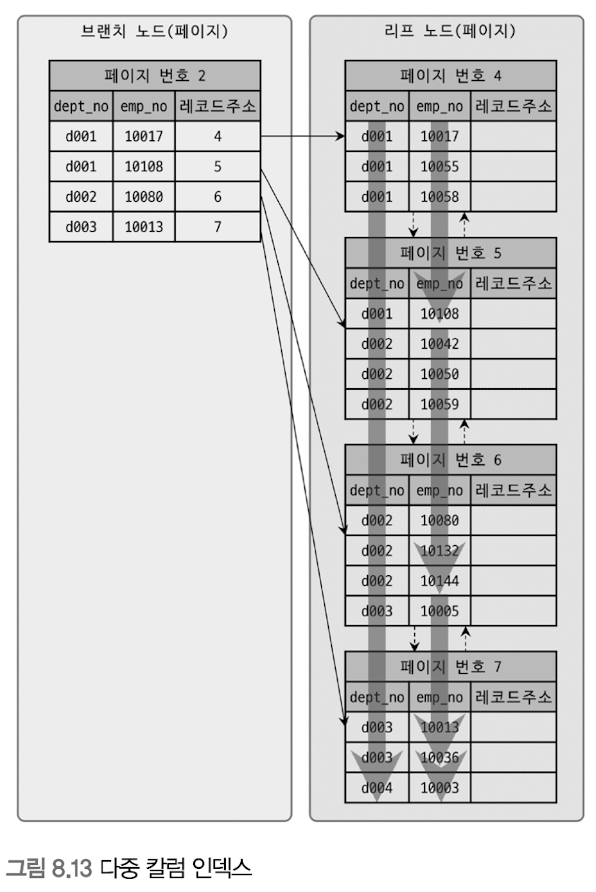
5. 다중 칼럼(Multi-column) 인덱스
다중 칼럼 인덱스 : 2개 이상의 칼럼을 포함하는 인덱스
6. B-Tree 인덱스의 정렬 및 스캔 방향
인덱스의 정렬
--인덱스 정렬 순서 혼합 가능 (8.0 이상)
create index ix_teamname_userscore on employees (team_name asc, user_score desc);인덱스 스캔 방향
select * from employees
order by first_name desc
limit 1;위 쿼리의 경우 인덱스를 최댓값부터 거꾸로 읽으면 내림차순으로 값을 가져올 수 있음
내림차순 인덱스
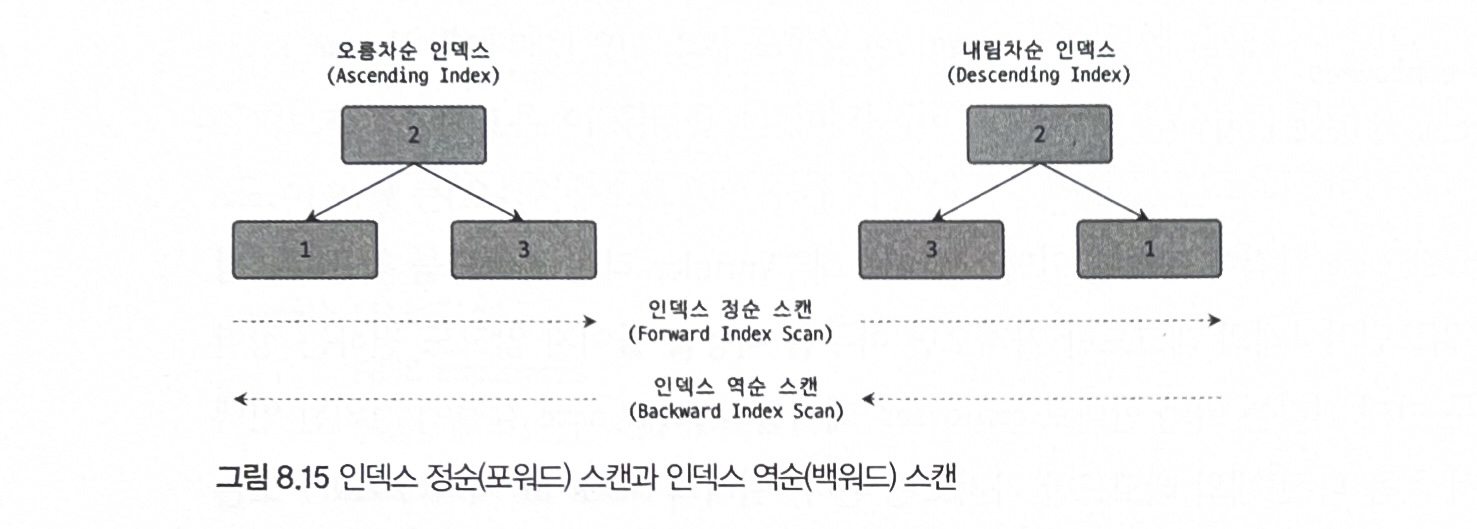
오름차순 인덱스:작은 값의 인덱스 키가왼쪽으로 정렬된 인덱스내림차순 인덱스:큰 값의 인덱스 키가왼쪽으로 정렬된 인덱스인덱스 정순 스캔: 리프 노드의왼쪽페이지 부터 오른쪽으로 스캔인덱스 역순 스캔: 리프 노드의오른쪽페이지 부터 왼쪽으로 스캔
인덱스 역순 스캔이 인덱스 정순 스캔에 비해 느릴 수 밖에 없는 이유
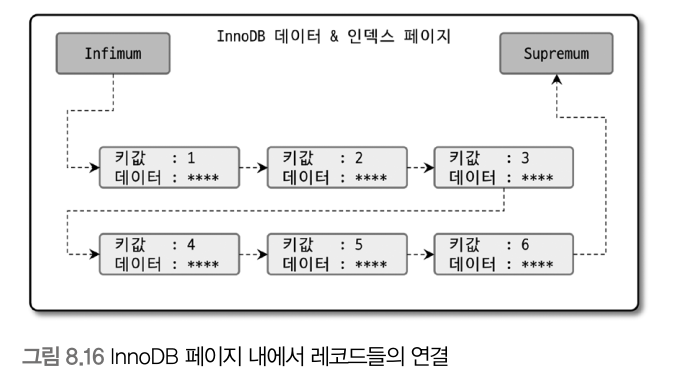
- 페이지 잠금이
인덱스 정순 스캔에 적합한 구조 - 페이지 내에서 인덱스 레코드가
단방향으로만 연결된 구조
7. B-Tree 인덱스의 가용성과 효율성
비교 조건의 종류와 효율성
각 칼럼 순서와 그 칼럼에 사용된 조건이 동등 비교인지 아니면 범위 조건인지에 따라 활용 형태 달라짐
select * from dept_emp
where dept_no='d002' and emp_no>=10114;
--인덱스 dept_no+emp_no : 케이스 A
--인덱스 emp_no+dept_no : 케이스 B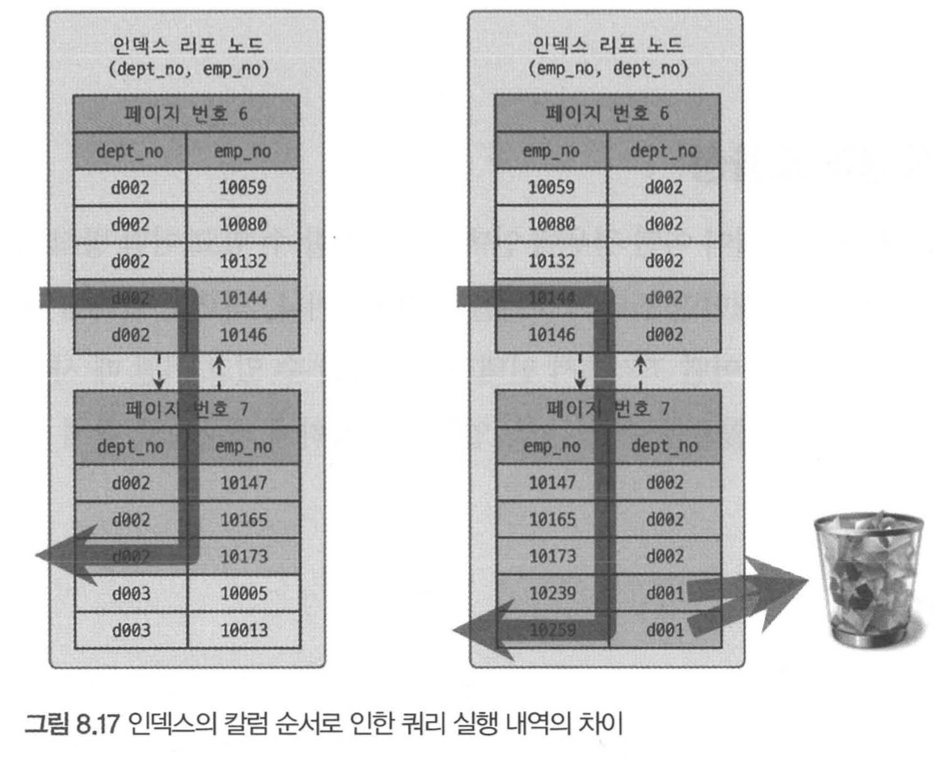
필터링 : 인덱스를 통해 읽은 레코드가 나머지 조건에 맞는지 비교하면서 취사선택하는 작업
작업 범위 결정 조건 : 케이스 A에서 처럼 작업의 범위를 결정하는 조건
필터링 조건 : 케이스 B의 dept_no 처럼 비교 작업 범위를 줄이지 못하고 단순히 거름종이 역할만 하는 조건
인덱스의 가용성
인덱스 레인지 스캔을 위해선 왼쪽 부분이 꼭 있어야 함
--인덱스 : first_name
select * from employees where first_name like '%mer';위 쿼리는 왼쪽 부분이 고정X(%mer)이므로 인덱스 레인지 스캔 불가능
가용성과 효율성 판단
아래와 같은 경우 범위 조건으로 사용할 수 없음
Not-Equal로 비교된 경우Like %??형태로 문자열 비교스토어드 함수나 다른 연산자로 인덱스 칼럼이변형된 경우Not-Deterministic 속성의스토어드 함수가 비교 조건에 사용된 경우- 데이터 타입이
서로 다른비교 문자열 데이터 타입의콜레이션이 다른 경우
=>where utf8_bin_char_column=euckr_bin_char_column
Null값도 인덱스에 저장됨
다중 칼럼의 인덱스가 사용되는 조건과 사용할 수 없는 조건
-- index : column_1+column2+...+column_n)-
범위 조건으로 인덱스를 사용하지 못하는 경우
=>column_1에 대한 조건이 없는 경우
=>column_1의 비교 조건이 위의 인덱스 사용 불가 조건 중 하나인 경우 -
범위 조건으로 인덱스 사용하는 경우
=>column_1~column_(i-1)칼럼까지 동등 비교 형태로 비교
=>column_i 칼럼에 대해 다음 연산자 중 하나로 비교- 동등 비교
- 크다 작다 형태
- Like로
좌측 일치패턴
위 두가지 조건을 모두 만족하는 쿼리는 column_1부터 column_i까지는 범위 조건, 그 이후는 필터링 조건으로 사용
🍋R-Tree 인덱스
공간 인덱스(Spatial Index) : R-Tree 인덱스 알고리즘을 이용해 2차원의 데이터를 인덱싱하고 검색하는 인덱스
=> 위치 기반 서비스를 구현하기 위함
B-Tree는 칼럼의 값이 1차원 스칼라 값인 반면, R-Tree는 2차원의 공간 개념 값
MySQL의 공간 확장
- 공간 데이터를 저장할 수 있는
데이터 타입 - 공간 데이터의 검색을 위한
공간 인덱스(R-Tree 알고리즘) - 공간 데이터의
연산 함수
1. 구조 및 특성
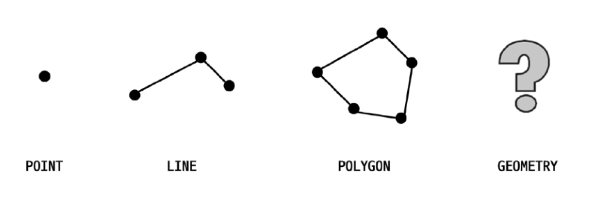
공간 정보의 저장 및 검색을 위해 여러 가지 기하학적 도형(Geometry) 정보 관리할 수 있는 데이터 타입 제공
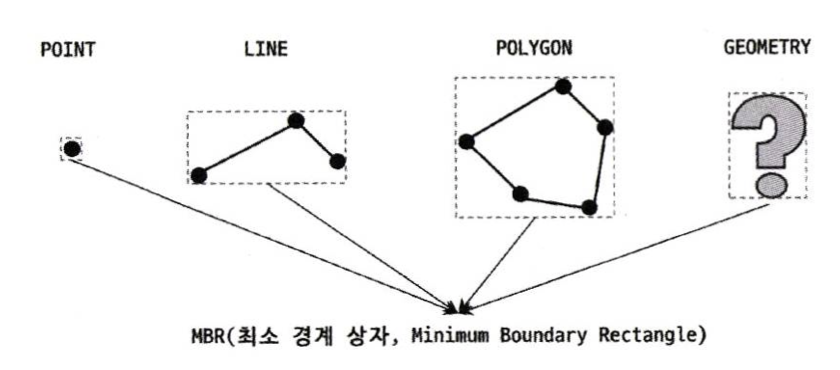
MBR(Minimum Bounding Rectangle) : 해당 도형을 감싸는 최소 크기의 사각형
위의 공간 데이터의 MBR을 그려보면 아래와 같다.
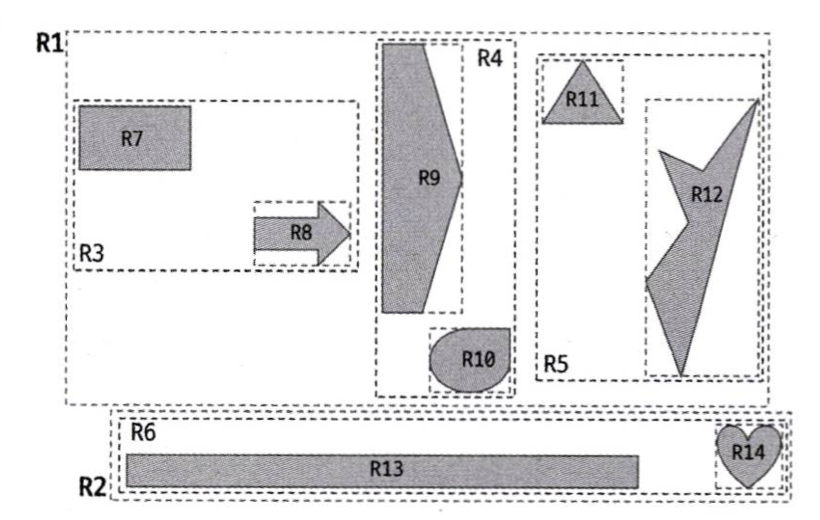
- 최상위 레벨 : R1, R2 =>
루트 노드 - 차상위 레벨 : R3~R6 =>
브랜치 노드 - 최하위 레벨 : R7~R14 =>
리프 노드
2. R-Tree 인덱스의 용도
R-Tree는 Rectangle의 R과 B-Tree의 Tree를 섞어서 만들었으며, 공간 인덱스라고도 함
=> 경도, 위도 뿐만 아니라 좌표 시스템에 기반을 둔 정보에 대해선 모두 적용 가능
=> ST_Contains() 또는 ST_Within() 처럼 포함 관계를 비교하는 함수로 검색하는 경우만 인덱스 사용 가능
ex. 현재 사용자 위치로부터 반경 5km 이내
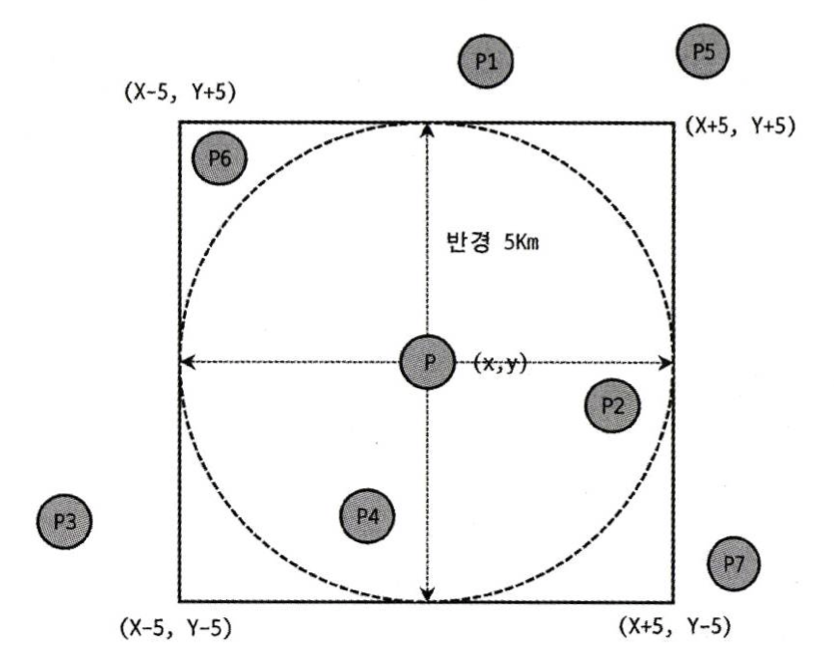
ST_Contains() 또는 ST_Within()는 사각형 박스와 같은 다각형으로만 연산이 가능해 원을 포함하는 MBR로 포함 관계 비교 수행
-- p6 음식점 제거 안해도 될 경우
-- 사각 상자에 포함된 좌표 Px만 검색
-- 사각 상자 : 포함 경계를 가진 도형 명시
-- px : 포함되는 도형(또는 점 좌표) 명시
select * from tb_location where ST_Contains(사각 상자, px);
select * from tb_location where ST_Within(px, 사각 상자);-- p6 반드시 제거해야 할 경우
-- ST_Distance_Sphere() 함수로 필터링 필요
select * from tb_location
where ST_Contains(사각 상자, px) -- 공간 좌표 px가 시각 상자에 포함되는지 비교
and ST_Distance_Sphere(p,px)<=5*1000 -- 5km;🍌전문 검색 인덱스
전문(Full Text) 검색 : 문서의 내용 전체를 인덱스화해서 특정 키워드가 포함된 문서를 검색
1. 인덱스 알고리즘
문서 본문의 내용에서 사용자가 검색하게 될 키워드를 분석해 내고, 빠른 검색용으로 사용할 수 있게 이러한 키워드로 인덱스 구축
=> 어근 분석
=> n-gram 분석
어근 분석 알고리즘
아래 과정을 거쳐 색인 작업 수행
불용어(Stop Word) 처리: 검색에서 별 가치가 없는 단어를 필터링해서제거어근 분석(Stemming): 검색어로 선정된 단어의 뿌리인원형을 찾는 작업
n-gram 알고리즘
본문을 무조건 몇 글자씩 잘라서 인덱싱
=> n-gram의 n은 인덱싱할 키워드의 최소 글자 수
ex. To be or not to be. That is the question
띄어쓰기와 마침표를 기준으로 10개 단어로 구분
2글자씩 중첩해서 토큰으로 분리
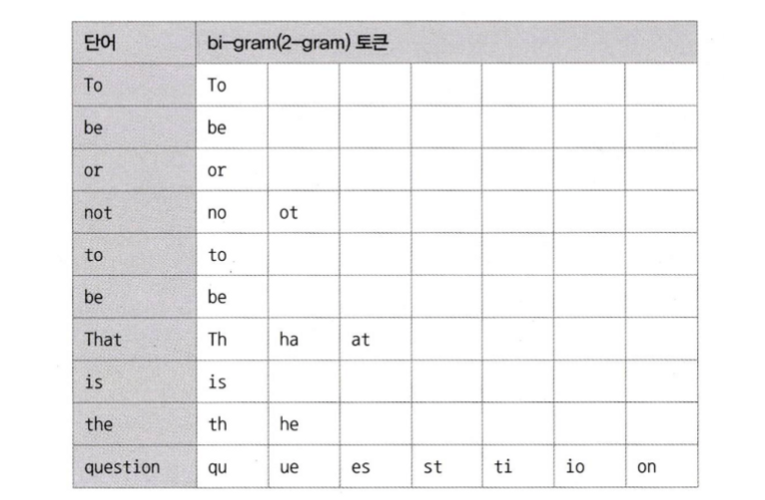
-- 내장된 불용어 확인
select *
from information_schema.INNODB_FT_DEFAULT_STOPWORD;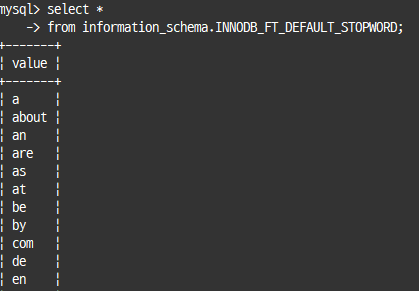
위 표에서 불용어를 제외한 것들만 인덱스에 등록
불용어 변경 및 삭제
ti와 at같은 단어는 a와 i가 불용어로 등록되어 있어 모두 걸러져 버려짐
=> 불용어 처리를 무시하거나 사용자가 직접 불용어를 등록 권장
전문 검색 인덱스의 불용어 처리 무시
=>my.cnf의ft_stopword_file에빈 문자열설정
=> (InnoDB)innodb_ft_enable_stopword시스템 변수를OFF로 설정사용자 정의 불용어 사용
=>my.cnf의ft_stopword_file에불용어 목록 파일설정
=> (InnoDB) 불용어 목록을테이블로 저장 --inno_ft_server_stopword_table
create table my_stopword(
value varchar(30)
) engine=innodb;
insert into my_stopword(value) values ('MySQL');
set global innodb_ft_server_stopword_table='mydb/my_stopword';
alter table tb_bi_gram add fulltext index fx_title_body (title, body) with parser ngram;
-- 여러 전문 검색 인덱스가 다른 불용어 사용해야할 경우 innodb_ft_user_stopword_table 변수 사용2. 전문 검색 인덱스의 가용성
전문 검색 인덱스 사용 조건
- 쿼리 문장이 전문 검색을 위한 문법(
match ... against...) 사용 - 테이블이 전문 검색 대상 칼럼에 대해서
전문 인덱스보유
-- 전문 검색 인덱스 구성 칼럼은 match절 괄호 안에 모두 명시돼야 함
select * from tb_test
where match(doc_body) against('애플' in boolean mode);***
🍍함수 기반 인덱스
함수 기반 인덱스 : 칼럼의 값을 변형해서 만들어진 값에 대해 인덱스 구축
함수 기반 인덱스 구현 방법
가상 칼럼을 이용한 인덱스함수를 이용한 인덱스
1. 가상 칼럼을 이용한 인덱스
create table user (
user_id bigint,
first_name varchar(10),
last_name varchar(10),
primary key(user_id)
);위 테이블에서 first_name과 last_name을 합쳐서 검색해야 하는 요건이 있다면, 가상 칼럼을 추가하고 그 가상 칼럼에 인덱스를 생성
alter table user add full_name varchar(30) as (concat(first_name,' ',last_name)) virtual,
add index ix_fullname(full_name);가상 칼럼은 테이블에 새로운 칼럼을 추가하는 것과 같은 효과를 내어 실제 테이블 구조가 변경됨
2. 함수를 이용한 인덱스
create table user (
user_id bigint,
first_name varchar(10),
last_name varchar(10),
primary key(user_id),
index ix_fullname ((concat(first_name,' ',last_name)))
);🥭멀티 밸류 인덱스
멀티 밸류(Multi-Value) 인덱스 : 하나의 데이터 레코드가 여러 개의 키 값을 가지는 형태의 인덱스
=> JSON의 배열 타입의 필드에 저장된 원소들에 대한 인덱스 요건
create table user (
user_id bigint auto_increment primary key,
first_name varchar(10),
last_name varchar(10),
credit_info json,
index mx_creditscores ((cast(credit_info->'$.credit_scores' as unsigned array)) )
);
insert into user values (1,'Matt','Lee','{"credit_scores":[360,353,351]}');멀티 밸류 인덱스 활용을 위해 아래 함수들을 이용해서 검색해야 인덱스 활용 가능
MEMBER OF()JSON_CONTAINS()JSON_OVERLAPS()
select * from user
where 360 member of (credit_info->'$.credit_scores');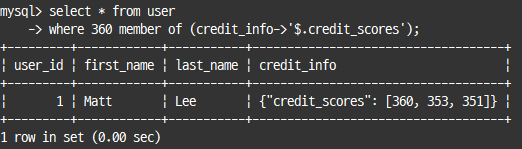
explain
select * from user
where 360 member of (credit_info->'$.credit_scores');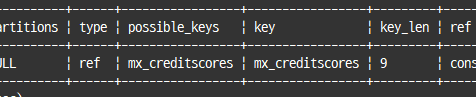
🍎클러스터링 인덱스
클러스터링 : 테이블의 레코드를 비슷한 것(프라이머리 키 기준)들 끼리 묶어서 저장
1. 클러스터링 인덱스
클러스터링 인덱스 : 프라이머리 키 값이 비슷한 레코드끼리 묶어서 저장하는 것
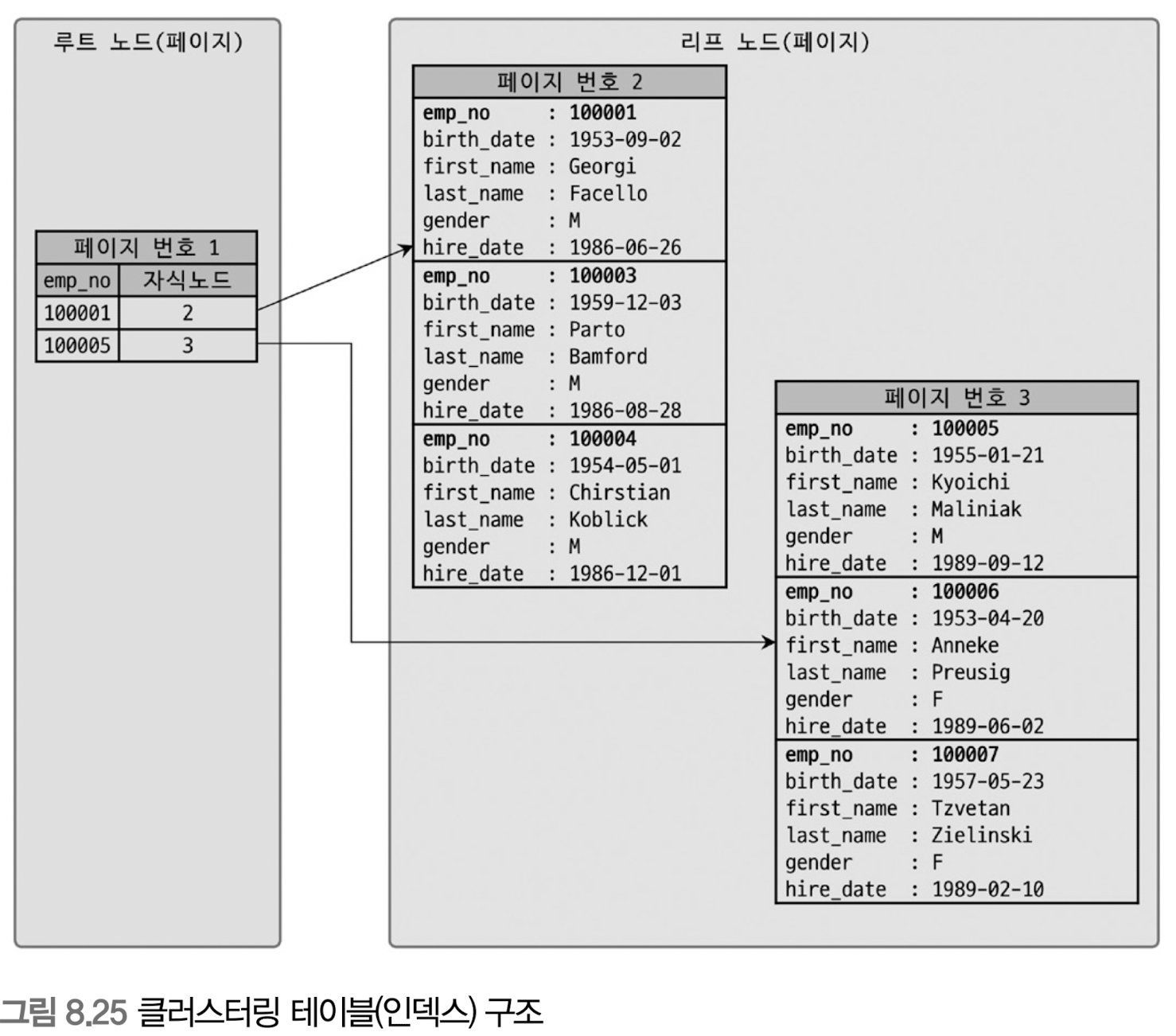
클러스터링 인덱스의 리프 노드에는 레코드의 모든 칼럼이 같이 저장돼 있음
프라이머리 키가 없는 InnoDB 테이블의 경우 아래 우선순위로 대체 칼럼 선택
- 프라이머리 키가 있다면, 기본적으로 프라이머리 키가
클러스터링 키 not null옵션의유니크 인덱스중 첫 번째 인덱스- 자동으로 유니크한 값을 가지도록
증가되는 칼럼을 내부적으로 추가한 후 선택
2. 세컨더리 인덱스에 미치는 영향
InnoDB의 모든 세컨더리 인덱스는 해당 레코드가 저장된 주소가 아니라 프라이머리 키 값을 저장하도록 구현
3. 클러스터링 인덱스의 장점과 단점
| 구분 | 내용 |
|---|---|
| 장점 | - 프라이머리 키로 검색시 성능 매우 빠름 - 테이블의 모든 세컨더리 인덱스가 프라이머리 키를 가지고 있어 인덱스만으로 처리될 수 있음 |
| 단점 | - 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 가져 키 값의 크기가 클 경우 전체적으로 인덱스 크기 커짐 - 세컨더리 인덱스로 검색시 프라이머리 키로 다시 한번 검색해야 하므로 처리 성능 느림 - insert할 때 프라이머리 키에 의해 레코드 저장 위치 결정돼 처리 성능 느림 -프라이머리 키 변경시 레코드 delete 하고 insert하는 작업 필요해 처리 성능 느림 |
4. 클러스터링 테이블 사용 시 주의사항
클러스터링 인덱스 키 크기
클러스터링 테이블의 경우 모든 세컨더리 인덱스가 프라이머리 키를 포함하므로 프라이머리 키의 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커짐
프라이머리 키는 AUTO-INCREMENT 보다는 업무적인 칼럼으로 생성
프라이머리 키는 대부분 검색에서 빈번하게 사용되므로 크기가 크더라도 업무적으로 해당 레코드를 대표할 수 있다면 그 칼럼을 프라이머리 키로 설정
프라이머리 키는 반드시 명시할 것
프라이머리 키를 생성하지 않으면 내부적으로 일련번호 칼럼을 추가하는데, 이는 사용자가 사용불가하므로 똑같은 auto_increment 칼럼을 생성하고 프라이머리 키로 사용하는 것이 더 낫다.
AUTO-INCREMENT 칼럼을 인조 식별자로 사용할 경우
세컨더리 인덱스도 필요하고 프라이머리 키의 크기도 길다면 auto_increment칼럼을 추가하고 이를 프라이머리 키로 설정
=> 인조 식별자 : 프라이머리 키를 대체하기 위해 인위적으로 추가된 프라이머리 키
🍏유니크 인덱스
유니크 인덱스 : Null 저장 가능
1. 유니크 인덱스와 일반 세컨더리 인덱스의 비교
인덱스 읽기
읽어야 할 레코드 건수가 같다면 성능상의 차이는 미미
인덱스 쓰기
일반 인덱스는 체인지 버퍼를 이용해 버퍼링이 가능하지만 유니크 인덱스는 반드시 중복 체크를 해야 하므로 버퍼링 하지 못해, 세컨더리 인덱스보다 변경 작업이 더 느림
2. 유니크 인덱스 사용 시 주의사항
유니크 인덱스도 일반 세컨더리 인덱스와 같은 역할을 동일하게 수행하므로 중복으로 생성X
🍐외래키
외래키 제약이 설정되면 자동으로 연관되는 테이블의 칼럼에 인덱스 생성
외래키 관리의 중요한 특징
- 테이블의
변경이 발생하는 경우에만잠금 대기발생 - 외래키와 연관되지 않은 칼럼의 변경은
최대한 잠금 대기 발생X
ex. child 테이블이 parent 테이블의 id를 참조하는 pid 칼럼 가지고 있음
1. 자식 테이블의 변경이 대기하는 경우

자식 테이블의 외래 키 칼럼의 변경은 부모 테이블의 확인이 필요한데, 이 상태에서 부모 테이블의 해당 레코드가 쓰기 잠금이 걸려있으면 해당 쓰기 잠금이 해제될 때까지 대기
자식 테이블의 외래키(pid)가 아닌 칼럼의 변경은 외래키로 인한 잠금 확장 발생X
2. 부모 테이블의 변경 작업이 대기하는 경우

on delete cascade 때문에 child 테이블의 레코드에 대한 쓰기 잠금이 해제될 때까지 parent 테이블은 대기해야 함
