Sequence Modeling
딥러닝에는 크게 두 분야가 있다. 바로 이미지를 다루는 Computer Vision과 자연어를 다루는 NLP(Natural language processing)이다.
그 동안 이미지 처리를 다루는 computer vision에 관해 학습했고, 앞으로는 자연어를 다루는 NLP에 관해 학습할 예정이다. 이미지 데이터와 자연어 데이터의 가장 큰 차이는 무엇일까? 여러 차이점이 있을 수 있겠지만, 그 중 하나를 꼽자면 이미지의 경우 input size가 고정되는 반면 자연어의 경우 input size가 변할 수 있다는 것이다. 그렇다면 이러한 자연어를 어떻게 처리하는지 이제부터 살펴보자!
Exsample of Sequence Modeling
자연어 처리에는 어떠한 세분야가 있을까? 다음과 같은 것들이 있다.

Named Entity Recognition (NER)
NER(Named Entity Recognition), 개체명 인식은 말 그대로 Named Entity(이름을 가진 개체)를 Recognition(인식)하는 것을 말한다. NER은 자연어 처리를 이용한 정보 검색과 요약, 질문 답변, 지식 베이스 구축 등 다방면에 사용되고 있다. 특히 기계 번역의 품질을 높이고, 사용자 맞춤형 번역을 제공하는데 큰 도움을 줄 수 있다.
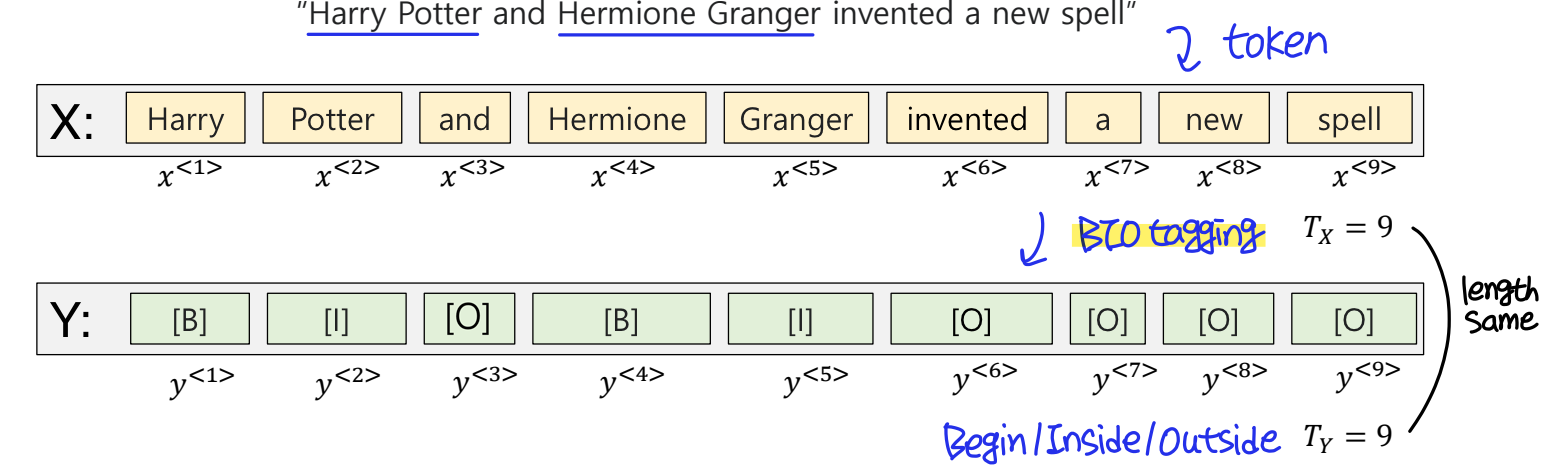
NER은 문장을 토큰 단위로 나누고, 이 토큰들을 각각 태깅(tagging)해서 개체명인지 아닌지를 분간한다. 이때 여러 개의 토큰을 하나의 개체명으로 묶기 위해 도입된 것이 바로 태깅 시스템이다. 예를 들어 Harry Potter는 하나의 개체이다.
주로 BIO 시스템을 사용하는데, BIO 시스템에서는 개체명의 시작에는 B를, 토큰이 개체명 중간에 있을 때는 I를, 토큰이 개체명이 아닐 경우에는 O를 붙인다.
Word Representation
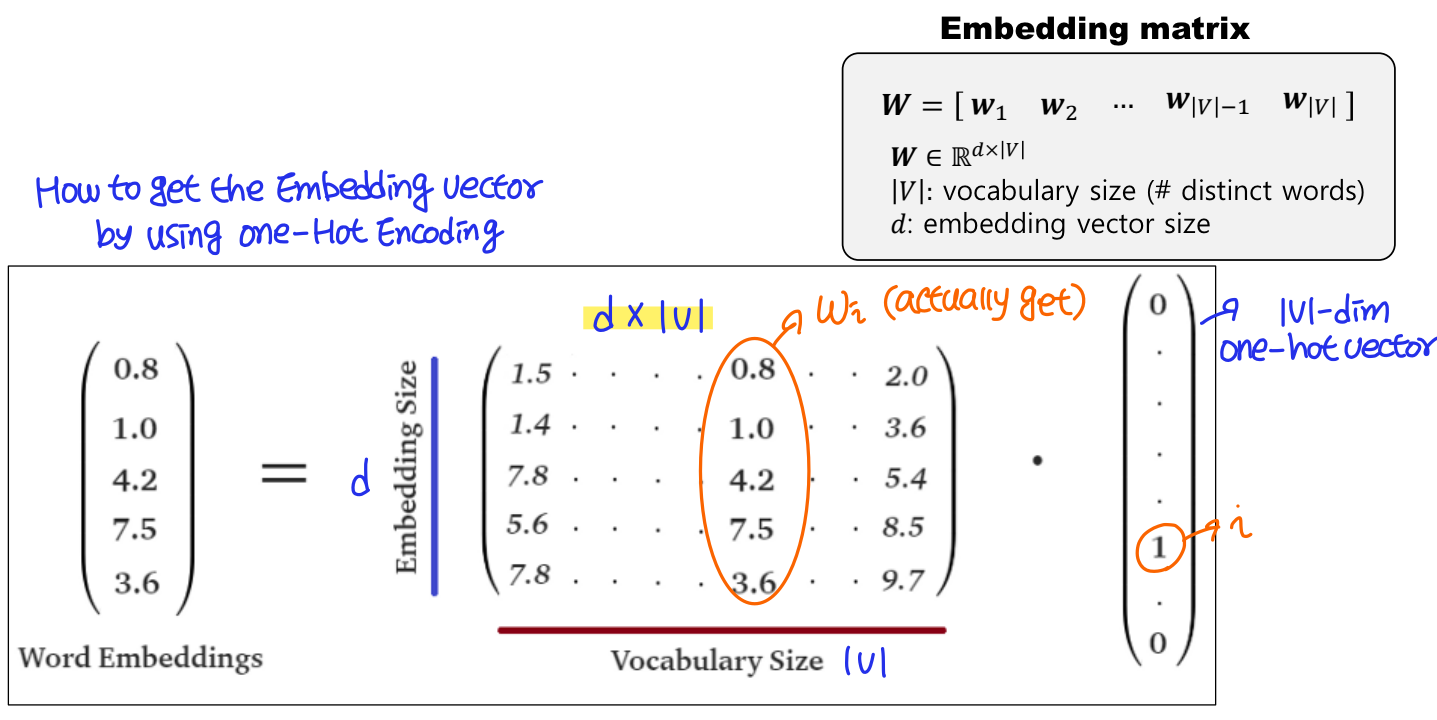
단어를 표현하기 위한 방법에는 One-hot encoding과 Word embedding이 있다. One-hot encoding은 단어 집합의 개수 만큼의 차원을 가지고 해당 단어의 ID만 1이고 나머지는 모두 0인 벡터로 매우 sparse하다. 이 경우 메모리를 많이 사용하는 문제도 있지만, 가장 큰 문제 중 하나는 비슷하거나 정반대 의미를 가진 단어들의 distance(similarity)가 항상 같게 나온다는 것이다. 즉 단어의 의미를 담기 어렵다. 따라서 Word embedding을 통해 dense한 representation을 사용해야한다.
Recurrent Neural Networks (RNNs)
왜 NLP Task에서 RNN을 사용해야할까?
- 데이터의 길이가 고정적이지않아도 학습이 가능하다.
- 순서가 있는 데이터를 모델링할 때 강점을 보인다.
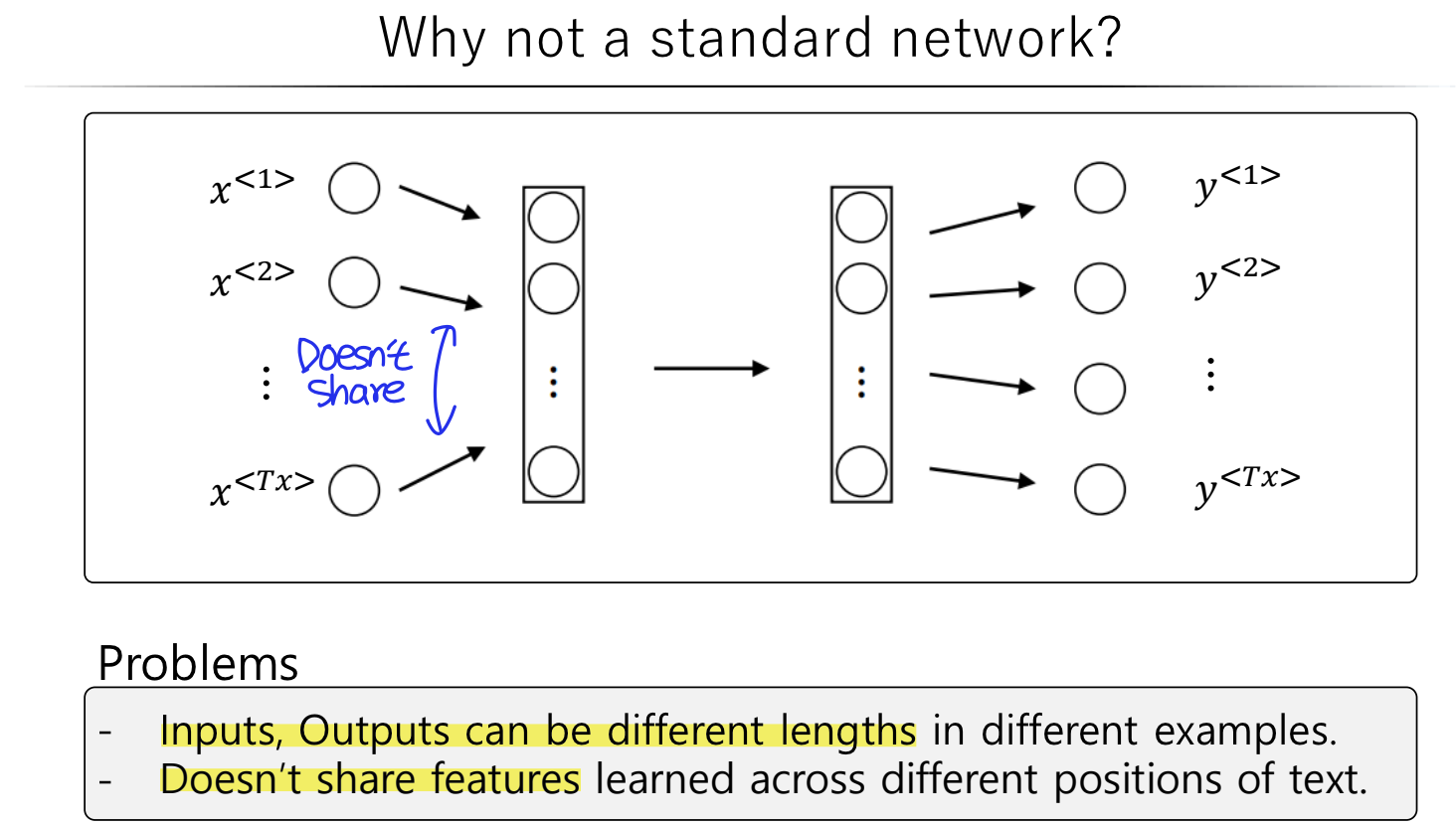

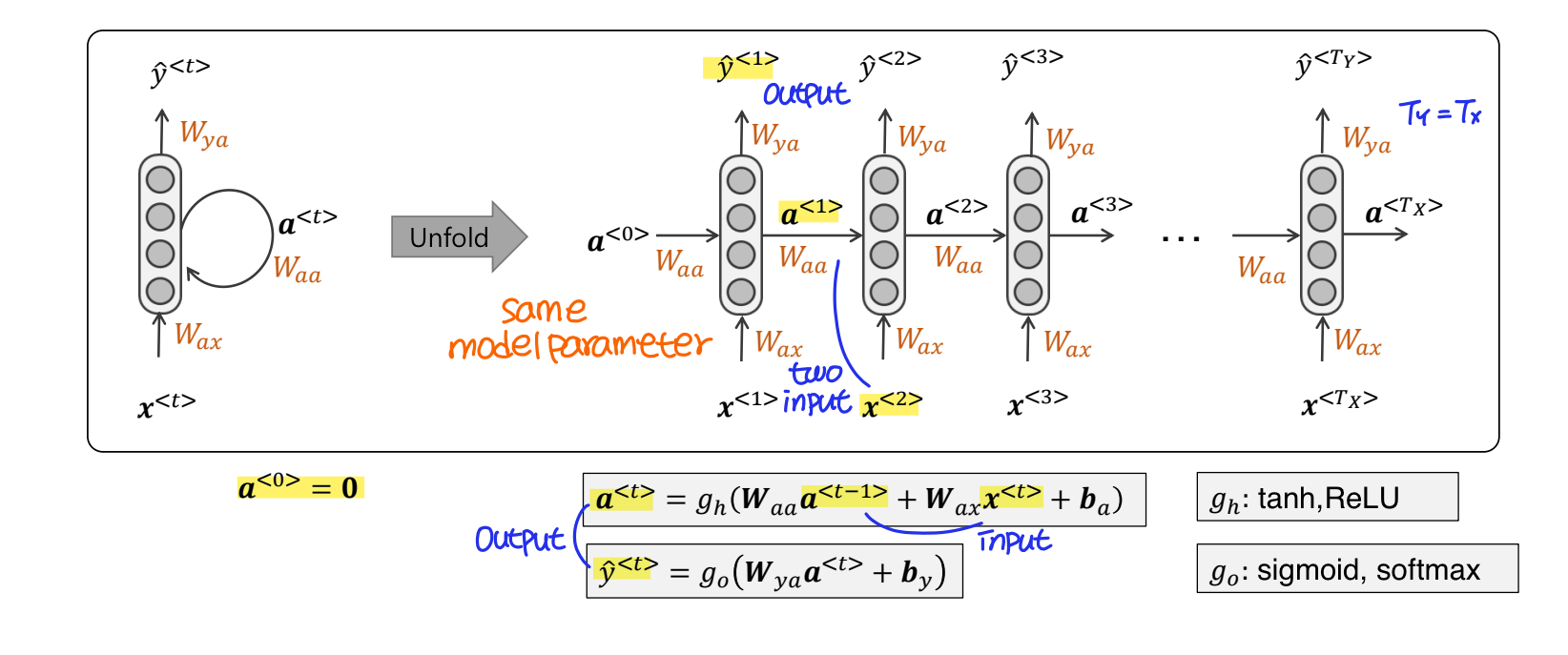
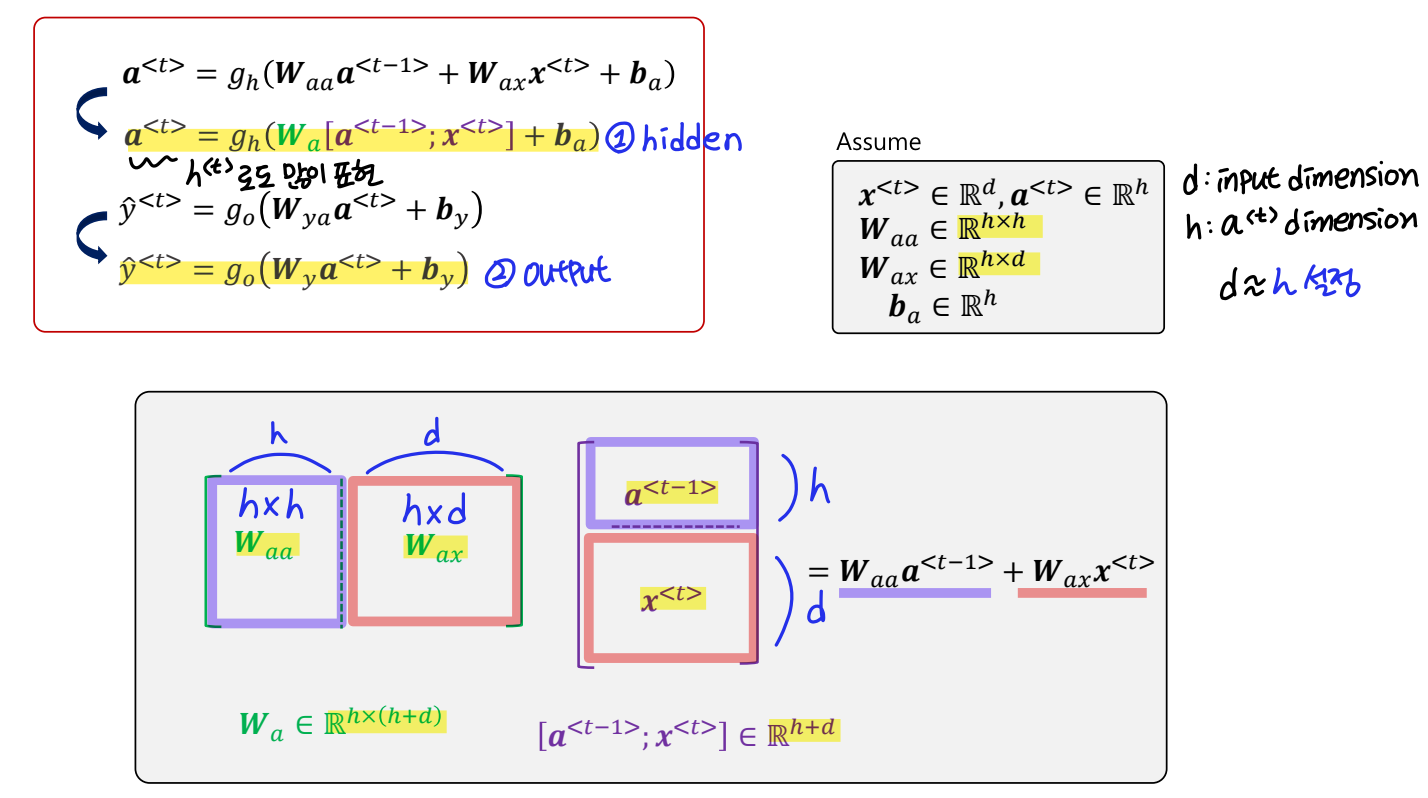
그럼 이제 RNN의 구조를 살펴보자. RNN은 Feed Forward Neural Network(은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향하는 신경망)와 달리 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서, 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징을 가지고 있다.
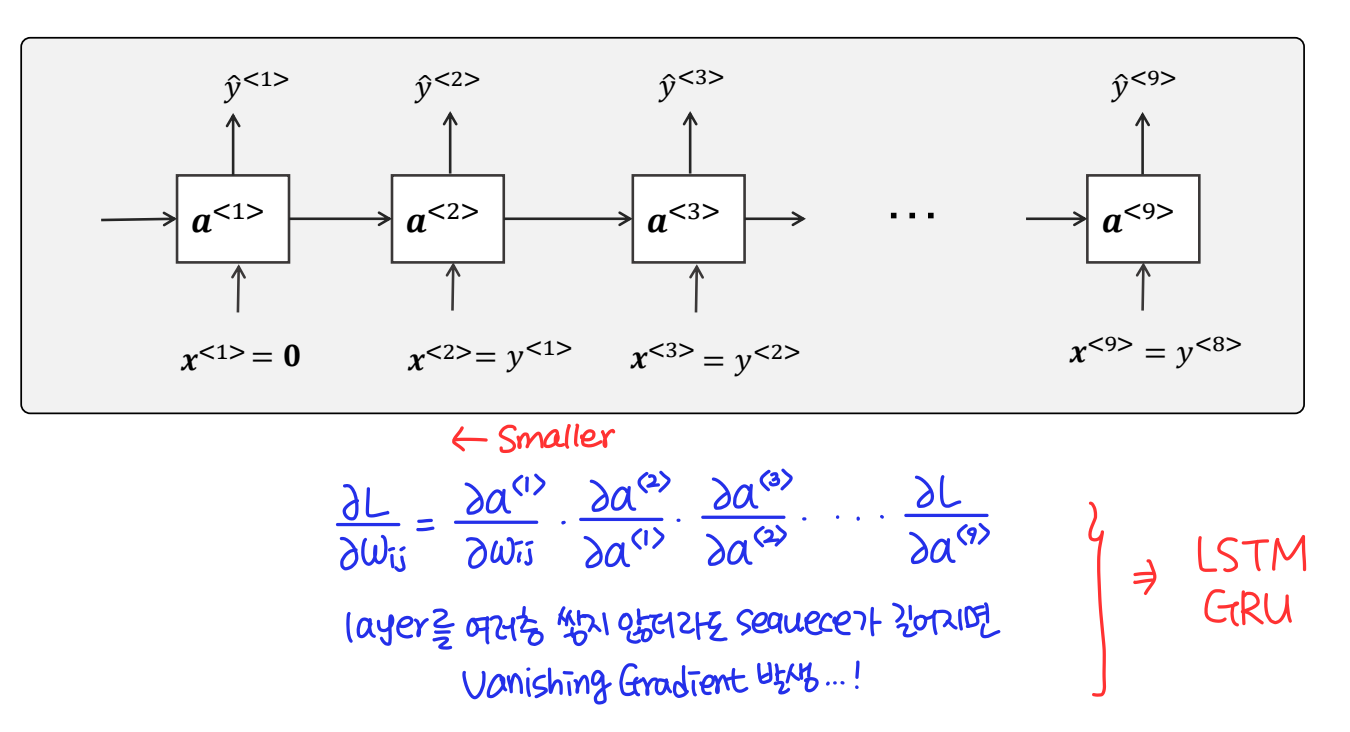
RNN에서는 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생한다. layer를 깊게 쌓지 않아도 sequence가 길어지게되면 해당 문제가 발생하는 것이다. 따라서 이러한 문제를 극복하기위해 RNN의 변형인 LSTM과 GRU를 이용할 수 있다.
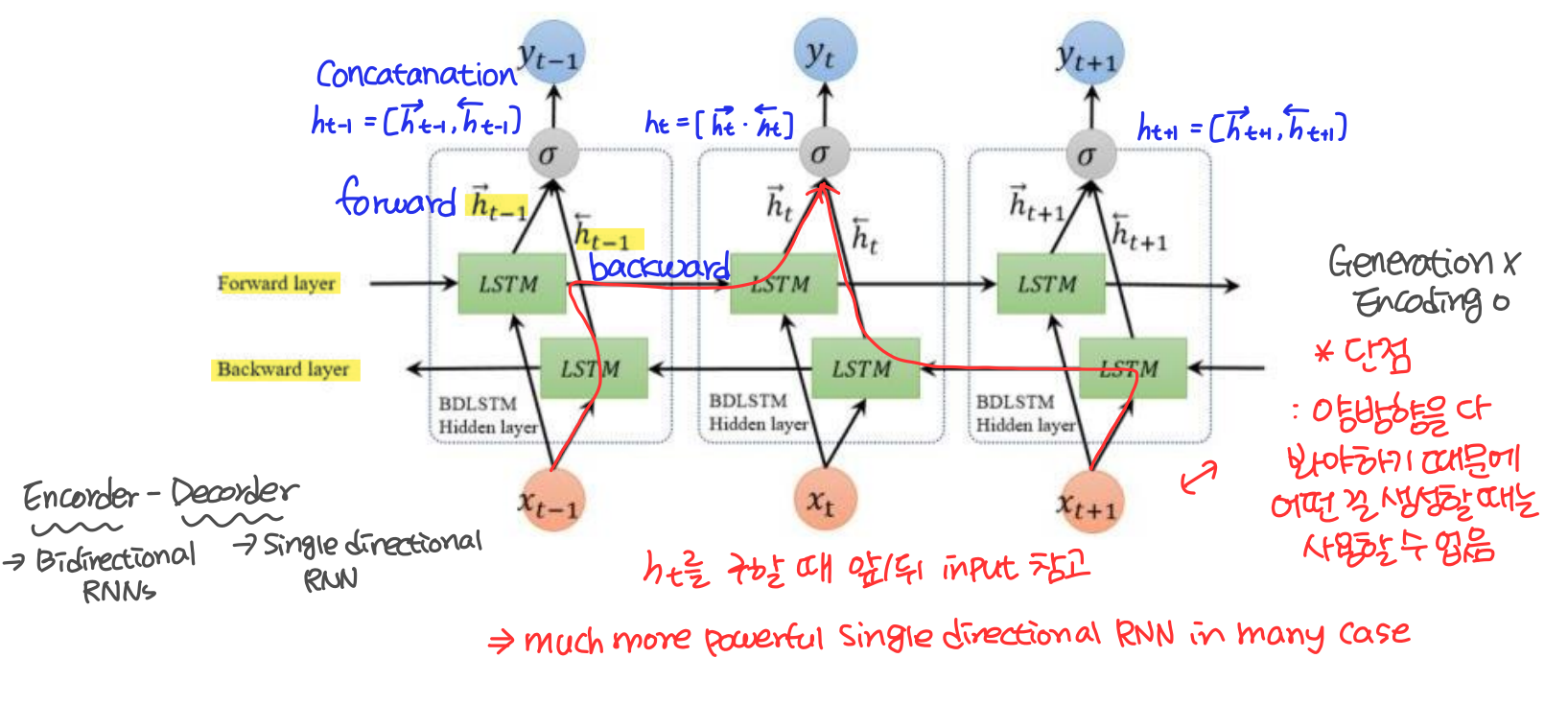
Bidirectional RNNs
Bidirectional RNNs은 ht를 구할 때 앞/뒤 input을 모두 참조한다. 이는 앞뒤 문맥을 모두 참조하기 때문에 대부분의 경우에서 single directional RNN 보다 더 powerful하다. 단 양방향을 다 봐야하기 때문에 무언가를 생성할 때는 사용할 수 없다는 단점이 있다.
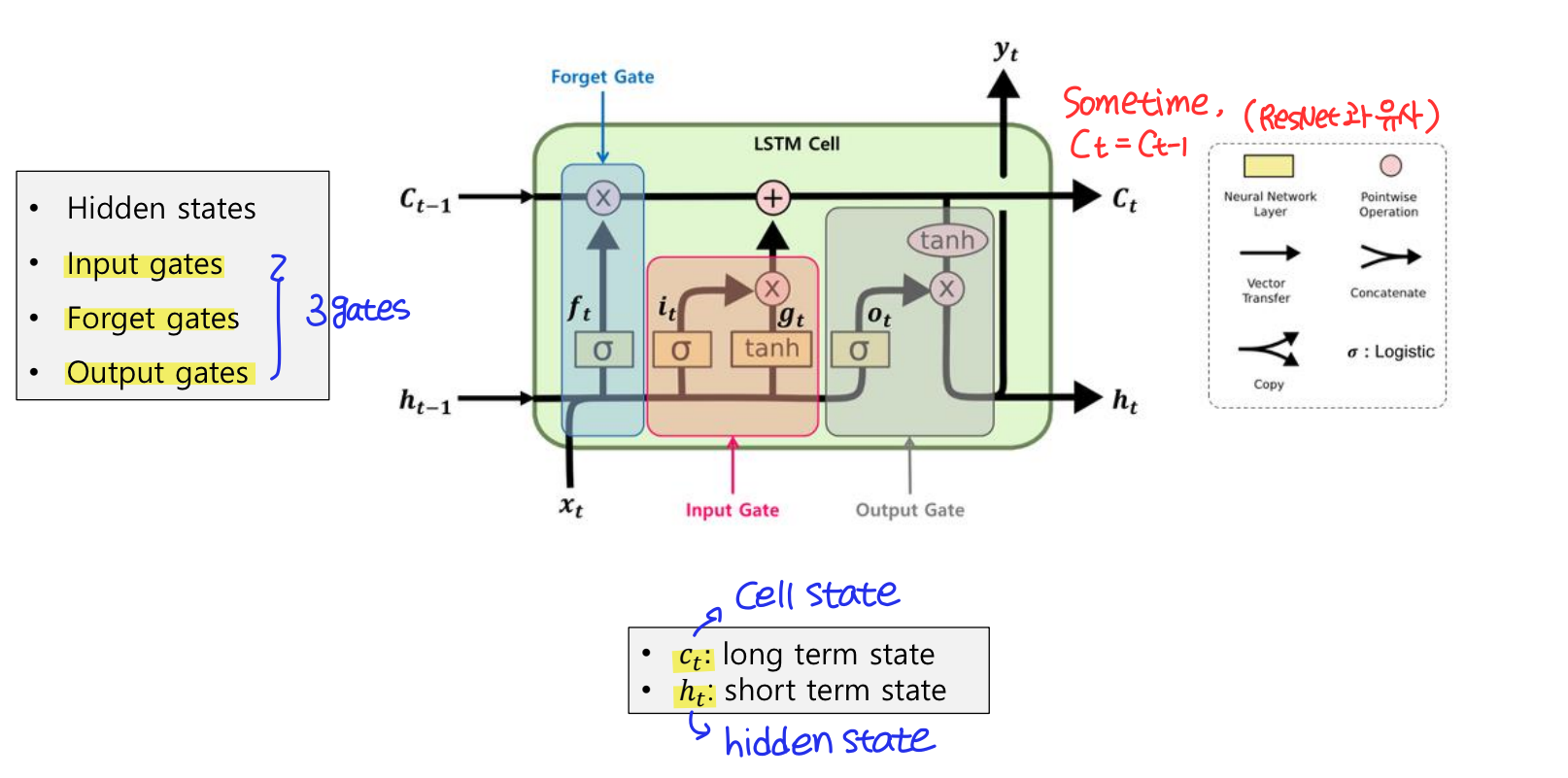
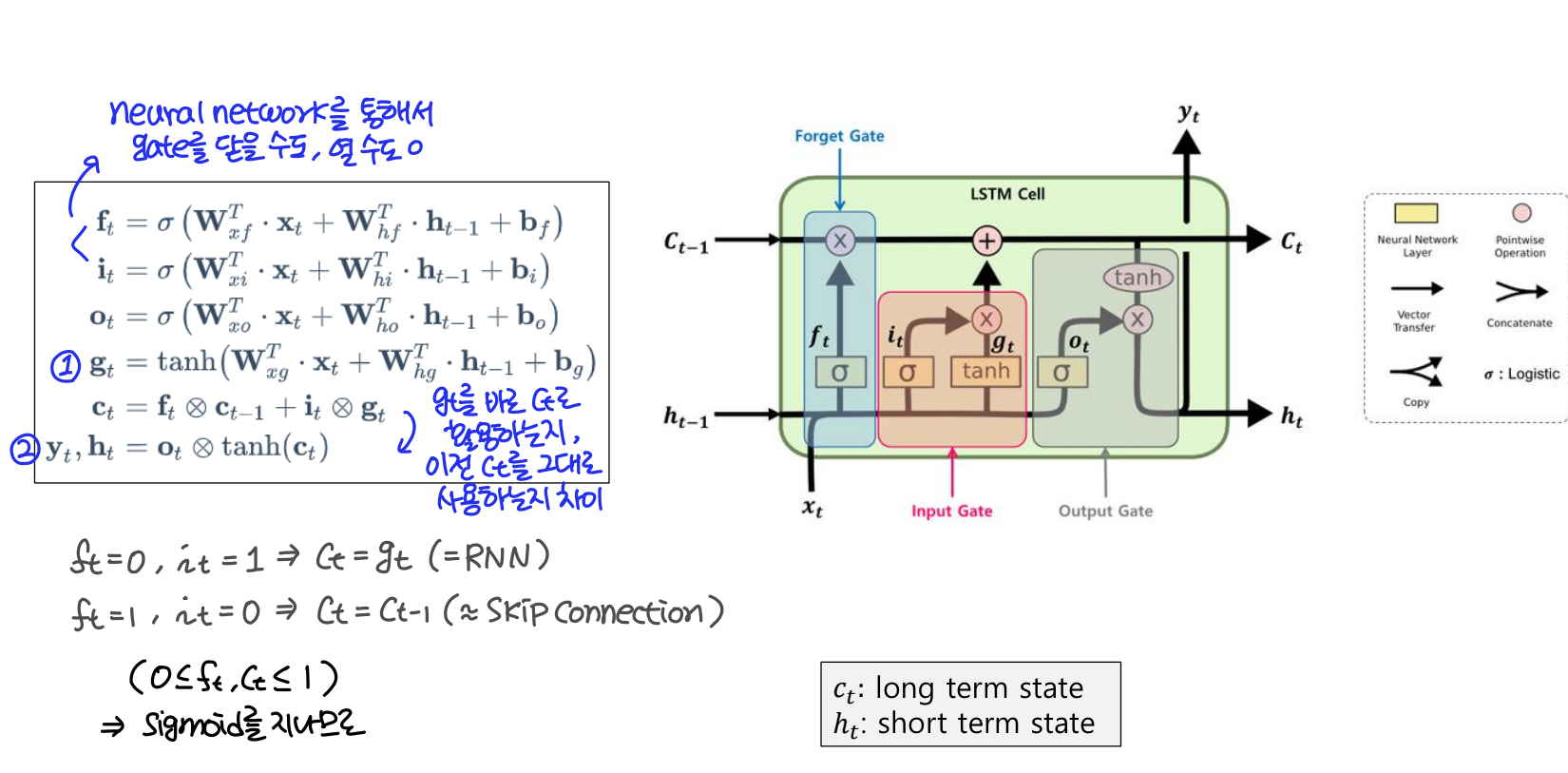
LSTM (Long Short Term Memory)
LSTM은 은닉층의 메모리 셀에 Input gates, Forget gates, Output gates를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.
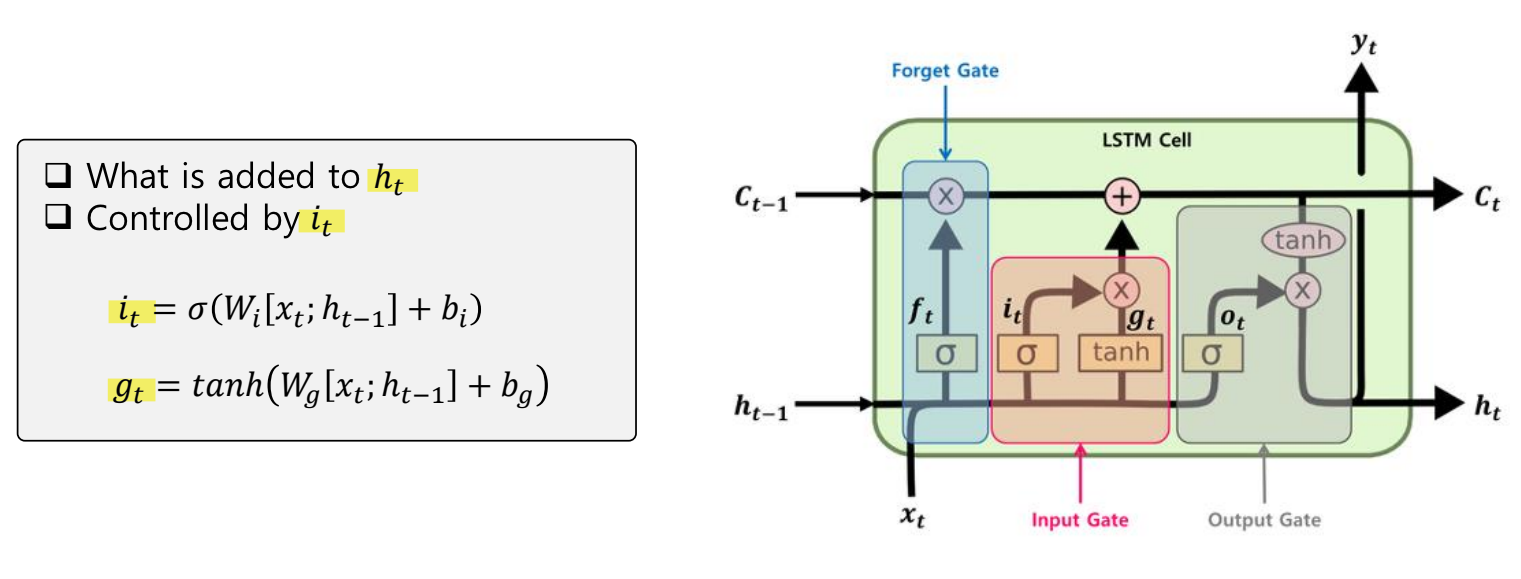
Input gate
입력 게이트는 현재 정보를 기억하기 위한 게이트이다.
Forget gate
삭제 게이트는 기억을 삭제하기 위한 게이트이다.

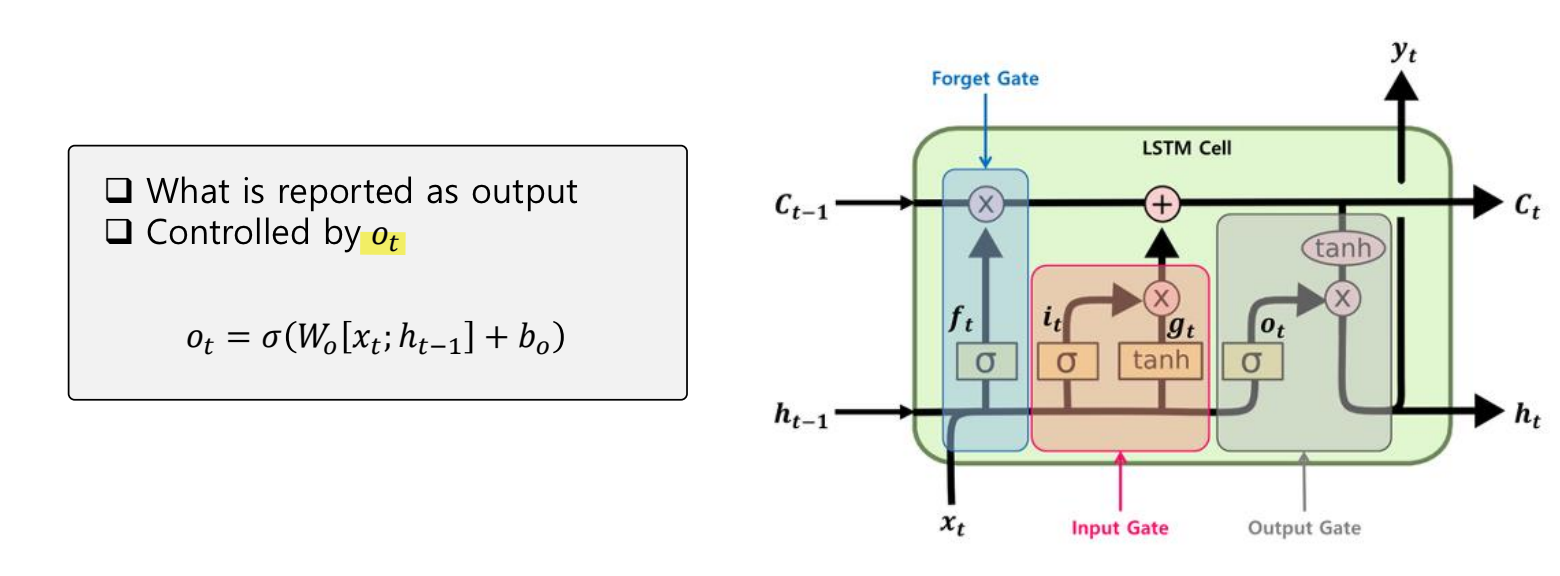
Output gate
출력 게이트는 현재 시점 t의 값과 이전 시점 t-1의 은닉 상태가 시그모이드 함수를 지난 값이다.
LSTM에 관해 정리해보면 다음과 같다. 삭제 gate와 입력 gate를 통해 다음과 같이 잊어버릴 정보의 양과 기억할 정보의 양을 조절한다.
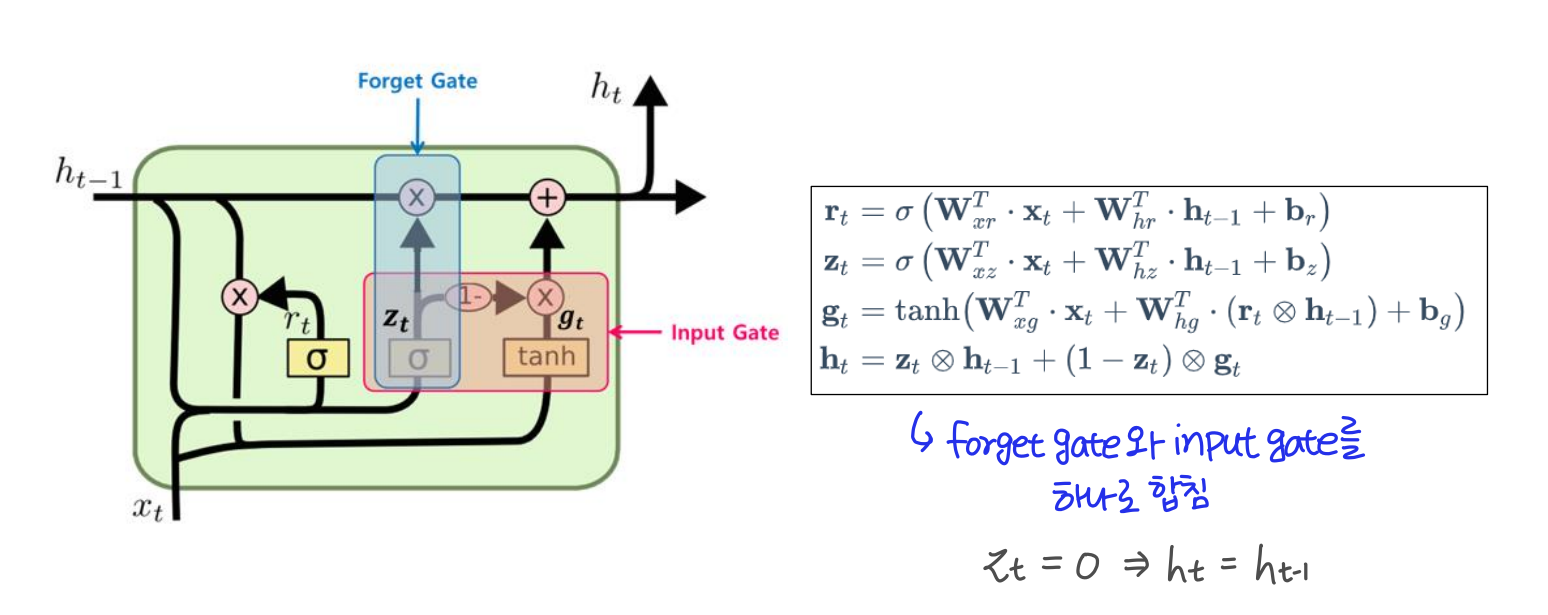
GRU
GRU는 LSTM과 매우 유사하다. 다른 점은 forget gate와 input gate를 하나로 합쳐서 gate 수가 총 2개라는 것이다. 따라서 LSTM보다 조금 더 가볍다고 할 수 있다. 하지만 언제부턴가 주로 LSTM을 사용하는 추세라고 한다.