
😅 이 글을 쓰게 된 계기
postgis 인강을 듣고있는데, 순간적으로 이해하지 못할 현상이 발생했습니다.
지금부터 이 현상이 왜 일어났는지를 알아가는 글입니다.
일단 해당 강의에서는 아래와 같은 테이블을 생성하도록 지시했습니다.
create table wetlands (
wl_id serial primary key,
wl_name varchar(10) unique not null,
wl_system varchar(15) default 'Palustrine'
check (wl_system in ('Riverine', 'Lacustrine', 'Palustrine')) not null,
wl_subsys varchar(15) default '' not null,
wl_class varchar(15),
wl_width double precision,
wl_depth double precision
);이렇게 하면 postgresql 내부적으로 serial 컬럼에서 사용할 sequence 을 생성합니다.
생성된 시퀀스의 현재값이 궁금해서 저는 아래와 같이 쿼리를 실행했습니다.
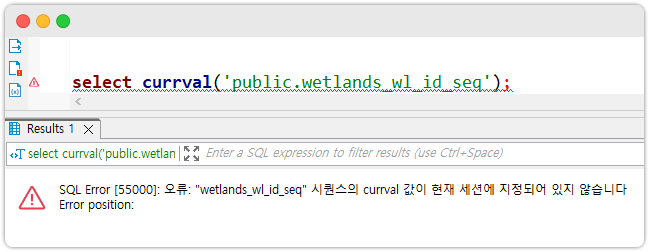
🙄 왜 이럴까요...?
왜 이런건지 이유를 알기 위해서 구글링을 시작했고 이 StackOverflow 게시물에 있는 무수한 답변들을 보고 원인을 짐작할 수 있었습니다. 이 글에 나오는 답변들을 요약하면 아래와 같습니다.
📌 각 메소드의 기능
nextval의 기능- 시퀀스의 값을
+1합니다. - 새롭게 생성된 이 값을 현재 세션에 반환한다.
- 시퀀스의 값을
currval의 기능- 현재 세션이 가장 최근에 nextval 를 통해 받은 번호를 재반환한다.
- 만약 단 한번이라도 현재 세션에서 시퀀스를 생성한 적이 없다면 에러가 발생한다.
📌 결론
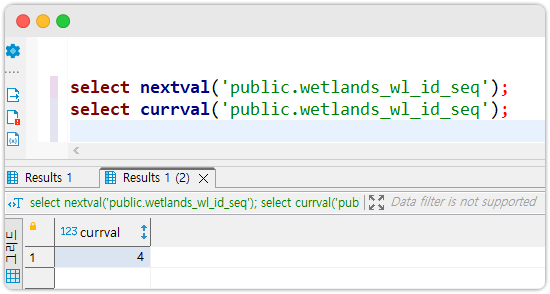
즉 nextval 을 먼저 호출하고 나서, currval 을 호출해야 정상적으로 동작한다는 의미입니다. 실제로 아래처럼 쿼리를 실행하면 문제가 없는 걸 알 수 있습니다.
💡 왜 이렇게 만들었을까요?
왜 굳이 이렇게 만들었을까요?
그냥 currval 을 호출하면 어느 세션에서 만들었던 간에,
가장 최신값을 받아오면 장땡 아닌가요?
이렇게 만든 이유를 이해하기 위해서 step by step 으로 알아봅시다.
🡆 Thread-Safe 하게 동작하는 Sequence
시퀀스는 자동으로 넘버링을 매겨주는 DB Object 라는 건 다들 아시죠?
중요한 건 이 번호를 매겨줄 때 시퀀스는 항상 Thread-Safe 하게 동작되도록
설계되어 있다는 점입니다.
그래서 서로 다른 DB Session 에서 시퀀스가 생성하는 번호를 부여 받으면,
그 번호가 반드시 유니크한 값임을 보장 받습니다.
그 덕분에 DBMS 를 사용하는 Client(= Session)들은 마음 편하게 insert 할 때,
PK 컬럼에 해당 Sequence 값을 사용할 수 있는 것입니다.
🡆 왜 굳이 2단계로 나눌까?
왜 굳이 2단계로 나눌까요? 귀찮게 말이죠?
그냥 max(pk) + 1 을 사용해서 대체할 수도 있지 않을까요?
하지만 시퀀스와 같이 유니크한 값을 보장받지 못합니다.
만약에 currval 이 어떤 세션이 만들었던 간에 가장 최신값을 받는 것이였다면,
그러니까 max(pk_id) + 1 같은 느낌의 연산자였다면
Sequence 의 가장 중요한 특징인 각 세션이 유니크한 값을 사용한다는 보장이 깨져버립니다.
더 이해하기 쉽도록 아래와 같은 시나리오가 발생한다고 생각해봅시다.
세션1이테이블 A에 insert 를 하기 전에 nextval 을 호출한다.- nextval 을 사용해서 받은 값으로 insert 를 무사히 수행한다.
세션1은 이어서테이블 A가 사용했던 시퀀스 값을 다른 테이블의 외래키로
사용하기 위해서 currval 을 호출한다.- 그런데 currval이 호출되기 바로 직전에
세션2도 위의1~2번 과정을 거쳤다. 세션1이 currval 이 호출되는 시점에는세션2의해서 새롭게 생성된 시퀀스값을 가진다.세션1은 1번에서 생성된 시퀀스 값이 아닌 엉뚱한 값을 받고 이것을 사용한다.- (결말은... 좋지 않겠죠? 😨)
이래서 currval 은 현재 세션이 생성했던 가장 최근의 시퀀스 값을 return 하도록 하는 것입니다. 각 세션에 이미 할당된 시퀀스 값만을 currval 로 계속 가져와서 사용하면, 중간에 다른 세션이 nextval 로 새로운 시퀀스 값을 생성해도 현재의 세션은 이미 생선한 것을 계속 사용하므로 아무런 영향을 받지 않는 겁니다.
Tip: 이미 알겠지만, create table 할 때 column 타입을
serial로 하면
자동으로 serial 과 매칭되는sequence가 생성됩니다.그렇다면 이런 시퀀스는 어떻게 조회할까요? 방법은 아래와 같습니다.
select nextval(pg_get_serial_sequence('schema.table_name','id')); select currval(pg_get_serial_sequence('schema.table_name','id'));
🎯 결론
최소 한번의 nextval 을 호출하여, 해당 세션이 가질 수 있는 고유한 값을 미리 갖게 하고,
이렇게 생성된 값만 currval 로 받게 함으로써, 다른 세션에 의한 영향을 받지 않는 것입니다.
이 개념은
max(pk) + 1같은 쿼리 시퀀스 대용으로 쓰지 말아야하는 이유이기도 하다.
읽어두면 좋은 관련글
sequence 대신 select max(pk)+1 을 사용하는 방식이 왜 위험한지를 잘 설명해주는
글이 있어서 퍼왔다. Quora 에서 퍼왔다. (출처: https://qr.ae/pyTBa3)
Question :
why shouldn't one select max (primary key column) instead of using an id column or sequence?
Answer :
The most important reason is that two clients could both select
max(primary_key)+1 at almost the same exact instant,
both get the same result, and both try to use the same value in
their subsequent insert statement. One will execute their insert first,
and then the other will fail, because they're trying to insert a primary key
value that now exists in the table. This is called a race condition.
To avoid this, you would have to do the following steps for every insert:
Lock the entire table
Select max(primary_key)+1
Insert new row
Release your table lock (maybe not until the end of your transaction)
In an environment where you want multiple concurrent clients inserting
rows rapidly, this keeps the table locked for too long.
Clients queue up against each other, waiting for the table lock.
You end up having a bottleneck in your application.
Auto-increment mechanisms work differently:
Lock the auto-increment generation object
Get the next id
Release the auto-increment lock
Insert new row using the id your thread just generated
The auto-increment generator is also a single resource that the threads are
contending for, but the usage of it is extremely brief, and is released
immediately after the id is generated, instead of persisting
until the end of the transaction.
Using auto-increment features allows for greater scalability -- i.e.
more concurrent clients inserting rows to the same table without queueing unnecessarily.
You said your superior doesn't think there will be a lot of users inserting rows.
But it doesn't take a lot of users, it only takes two -- if they're close together.
There's an old saying about the likelihood of rare occurrences: one in a million is next Tuesday.
Besides, you haven't described any legitimate reason not to use an auto-increment.