글을 쓰게 된 계기
최근에 일을 계속하면서 개발의 Core 한 부분에 대한 이해가
떨어진다는 생각이 들었고, 이에 대한 갈증을 해소하기 위해 공부를 하고 있습니다.
그중에서도 가장 공부하고 싶었던 주제가 객체지향 프로그래밍(OOP) 입니다.
그래서 최근에 2권의 OOP 관련 서적을 읽었습니다.
개인적으로는...
조영호 님의 책은 객체지향 개념에 대한 튼튼한 기준 잡아주는 역할을 해주었고,
최범균 님의 책은 모호할 수도 있는 개념들을 실제 코드를 통해서 이해의 깊이를 더해 줬습니다.
2책 모두 저에게는 너무나도 좋은 책이였습니다.
모두 읽은 후에는 욕심이 생겨서 또 다른 관련 서적을 찾아볼 예정입니다.
그런데 더 좋은 책들을 보기 전에 여태 알아낸 지식을 정리할 필요성을 느껴서,
제 나름대로 여태 배운 것에 대한 요약/정리글을 쓰게 되었습니다.
"제 나름대로 정리한 글"이기 때문에 제 주관이 좀 들어간 것들도 많습니다.
혹시 애매하거나, 반박하고 싶은 부분이 있다면 댓글을 달아주세요!
추후에 안 맞거나 생각이 바뀐 부분이 있으면 수정할 예정입니다.
저 스스로가 서적들을 읽다보면 계속 생각이 바뀔거라 생각되서 말이죠.
객체지향이란?
객체지향을 설명하기 앞서 객체부터 정의하자면 아래와 같습니다.
하나의 소프트웨어에서 제공해야될 다양한 기능들 중에서 관련된 것들 끼리 묶는데,
이 묶는 단위를 "객체" 라고 합니다. 그리고 이런 객체들이 서로 협력, 즉 서로의
기능을 요청(= 메시지)하는 구조로 프로그래밍하는 방식을 객체지향 (프로그래밍)이라고 합니다.
인터페이스
객체지향에서 많이 표현하는 단어가 인터페이스입니다.
앞서 "관련된 기능의 묶음" 이라는 장황한 표현을 사용했는데,
객체지향에 세계에서는 이런 기능의 묶음을 다른 말로 "인터페이스"라고 합니다.
다시 말해 객체는 기능의 묶음, 즉 인터페이스를 제공하는 것이라고도 말할 수 있죠.
책임과 역할
관련된 기능들의 묶음(인터페이스)을 객체라는 단위로 묶는다고 말씀드렸죠?
이 말은 다르게 말하자면 객체가 관련된 기능을 제공하는 "책임"을 갖는다고 할 수 있습니다.
그리고 이 책임이라는 표현은 곧 해당 객체가 해당 기능을 제공해야 되는 "역할"을
수행한다는 말과 완전히 똑같아 보입니다. 실제로 그렇게 표현하는 곳도 많고요.
하지만 어떤 서적들에서는 역할을 조금 더 넓은 의미로 사용합니다.
객체가 어떤 특정한 협력 안에서 수행하는 책임의 집합을 역할이라고도 합니다.
단순히 응집력있는 기능의 집합인 책임 하나만 갖는게 아니라,
이러한 기능 집합을 여러개 갖는 것을 역할이라고 확장해서 생각하면 됩니다.
객체는 응집력있는 기능의 집합을 제공하는, 즉 "책임"을 갖으며
그 책임을 수행하기 위한 하나의 "역할"을 갖는다고 표현할 수 있습니다.
타입 그리고 인스턴스
타입이란?
객체지향을 통해 구현된 애플리케이션은 내부적으로 메모리에 올라와 있는
여러 객체들이 서로 협력을 하게 됩니다.
그리고 이 협력은 객체간에 서로 요청을 보낸고,
그 요청에 대한 결과를 반환하면서 이루어집니다.
이때 요청을 처리해주는 것은 해당 요청을 처리해줄 수 있는 "역할(또는 책임)"을
갖는 객체가 수행하게 됩니다.
그리고 이러한 하나의 역할을 수행할 수 있는 객체는 하나 이상일 수 있는데,
이때 이 객체들을 하나로 Grouping 하는 단위를 타입(Type)이라고 표현할 수 있습니다.
그리고 Type 이라는 Boundary 내에 소속된 객체들을 우리는 인스터스라고도 표현합니다.
Java, C#, C++ 개발자라면, OOP 하면 무조건 Class 를 생각할 수도 있다.
하지만 Class 는 객체지향을 구현하기 위한 하나의 문법일 뿐이다.
OOP class 라는 문법이 생기기 전의Javascript에서도 적용되던 개념이다.
즉 Class 라는 문법이 없어도 충분히 OOP 를 할 수 있었다는 의미다.그러니까 (제발) OOP 에서 Class 가 없다고 객체지향이 불가능하다는 양 말하지 말자.
OOP 를 구현하기 위한 방법은 각각의 언어마다 다르다.
간단한 예
예를 들어서 회사의 부장님께서 "누가 펜 좀 빌려줄래?" 라고 말하면
같은 방에 있던 대부분의 대리, 사원들이 뒤를 돌아보면서 펜을 줄 겁니다.
부장님은 그 중 한명의 펜을 빌리게 될 겁니다.
객체로 생각해봅시다.
부장님이라는 하나의 객체가 "펜을 빌려달라!"라는 요청을 불특정 다수에게 전달한 겁니다.
그런데 이 불특정 다수 중에서도 "펜을 빌려줄 수 있는 사람"들이 이에 대한 대응을 해줬습니다.
이때 "펜을 빌려줄 수 있는 사람" 은 하나의 그룹으로 볼 수 있습니다. 아래 그림처럼 말이죠.

여기서 중요한 것은 "펜을 빌려줄 수 있는 사람들" 이라는 Group 에 소속된 모든 객체들이
"펜을 빌려줘"라는 요청 처리해줄 수 있다는 점입니다.
이처럼 어떤 요청에 대해서 이를 처리해줄 수 있는 객체들의 Group
또는 Boundary 를 우리는 타입(Type)이라고 표현합니다.
그리고 이렇게 하나의 타입에 종속되는 객체들을 "인스턴스(Instance)"라고도 표현합니다.
여기까지 해서 일단 용어적인 것들은 이해가 됐습니다.
이제는 객체지향 프로그래밍을 할 때 나오는 여러 주제들에 대해
알아보겠습니다.
객체의 책임의 크기
객체지향 프로그래밍의 맨 처음하는 일은
1. 소프트웨어 기능 요구사항들을 쭈욱 나열(= 정리)
2. 관련되어 있는 기능들을 묶어서 하나의 집합, 즉 책임을 만듦
3. 그 책임들을 적절한 객체에 분배
그런데 여기서 중요한 것은 책임을 객체에 분배할 때,
이 책임의 개수가 적을 수록 좋다는 것입니다.
왜 그럴까요?
그 이유는 하나의 객체가 너무 많은 책임(= 관련된 기능의 집합 = 기능들)을
가져버리면, 그와 관련된 객체 내에서 유지/관리할 데이터들이 늘어날테고,
당연히 그 데이터들을 서로 공유해서 쓰는 메소드가 늘어납니다.
전형적인 프로시저 프로그래밍의 단점이죠. 😨
그 결과 변경 사항이 발생했을 때 이를 반영하기 힘들며,
유지보수에도 악영향을 끼게 됩니다.
결론:
- 어떤 기능 목록이 있고,
- 이 기능들을 어떻게 묶어서 어떤 객체에 부여하는 게 객체지향 설계의 출발점
- 핵심은 기능의 묶음을 가능한 작게 하고 그것을 객체에 부여함으로써
객체의 책임을 최소화하는 게 중요합니다.
객체의 의존, 문제점 그리고 캡슐화
객체지향에서 의존은 필연적이다.
객체와 객체가 서로 협력해서 소프트웨어가 만들어지기 때문에,
필연적으로 객체는 다른 객체를 사용합니다.
그리고 이게 실제 프로그래밍 상에서는 (java 기준) 객체를 필드 변수에 세팅하든,
메소드의 파라미터로 받아서 사용하게 되는 것이죠.
그런데 여기서 중요한건 객체의 의존은 어떤 형태가 아니라,
의존을 함으로서 하나의 객체에 대한 변경이 발생했을 때,
그 객체를 의존하는 곳에도 변경이 일어날 수 있다는 것입니다.
그렇다면 이를 해소할 수 있는 방법에는 뭐가 있을까?
일단 가장 대표적이면서, 심플한 해결법은 캡슐화입니다.
캡슐화
캡슐화는 어떤 객체가 자신의 갖는 상태에 대한 처리를 위해서는
객체 자신의 인터페이스를 통해서만 처리되도록 하여 외부에 자신의 상태를
노출시키지 않는 것을 말합니다.
그런데 단순히 숨기는 것일 뿐인데 이게 의존에 의해 생기는 문제점을 어떻게 해소할까요?
예를 들어보죠.
어떤 데이터를 갖는 객체 A 가 있다고 합시다.
그리고 불특정 다수의 객체 들이 A 객체의 상태를 읽어서(= Getter 메소드 호출)
그 데이터들을 조합하여 만들어낸 공통된 프로세스가 있다고 가정해봅시다.
이때, A 객체의 데이터와 관련된 정책에 변경에 발생해서
이 데이터를 쓰던 불특정 다수의 객체들이 동시다발적으로 그 변화를 적용해야 합니다.
끔찍하죠?
이때! 캡슐화를 사용하면 어떨까요?
A 객체의 여러 데이터를 읽어서 공통된 프로세스를 불특정 다수의 객체 에 작성한다고 했죠?
이러지 말고, 여러 데이터에 대한 공통된 프로세스를 A 객체에 작성하고 이 프로세스를
수행하는 하나의 기능을 열어놓으면 됩니다!
이러면 A 객체의 데이터와 관련된 정책이 바뀌어도, 해당 프로세스가 어짜피
A 객체의 기능 내부에서 변경되기 때문에, 이 기능을 사용하는 불특정 다수의 객체 에는
영향을 주지 않는 것이죠.
다형성
제가 생각하는 이론적인 정의
하나의 Client 코드가 같은 message(요청)에 대하여 이를 처리할 수 있는
객체가 하나가 아니라 여러 개일 수 있는데, 이때 서로 다른 방식으로 해당 요청을
처리하는 것을 다형성이라고 합니다.
여기서 잠시 생각할 부분이 바로 "처리를 할 수 있는 객체"라는 것입니다.
이건 다르게 말하자면 해당 요청에 대한 "기능을 제공하는 객체"라는 것인데요.
기능을 제공하는 것은 곧 그 기능을 제공하는 "책임"을 갖는 객체이기도 합니다.
그리고 책임은 곧 역할이기도 하죠.
그리고 최종적으로 역할은 여러 인스턴스들을 묶어주는 "타입(Type)"으로 표현할 수 있습니다.
그러면 다형성을 정의해보죠.
하나의 Client 코드가 어떤 요청(message)를 전송하는데,
이때 해당 요청은 처리할 수 있는 타입에 소속되는(=역할을 할 수 있는)
모든 객체(인스턴스)들 모두 이 message 를 받아서 처리를 수행할 수 있다.결과적으로 이것은 Client 코드에서는 하나의 message 를 전송하지만,
이를 처리하는 하나의 타입에 소속된 인스턴스들이 서로 다르게 처리를
하여 결과를 반영하는데, 이런 동작 방식을 우리는 다형성이라고 한다.
코드에서 보는 다형성 (Java 기준)
참고로 여러 인스턴스를 묶어주는 Boundary 역할이 Type 인데,
해당 Type 을 표현함에 있어서 자바에서는 Class 또는 Interface 가 있다.
1. CLASS
우리가 주로 아래처럼 Class 를 작성하고, new 명령어를 통해서 인스턴스를 생성한다.
public class Animal {
public void walk() {
System.out.println("walk");
}
public static void main(String[] args) {
Animal cat = new Animal();
cat.walk();
Animal dog = new Animal();
dog.walk();
}
}- Animal 이라는 하나의 Class 는 여러 객체를 묶어주는 boundary(= type)이다.
- Animal 이라는 class 문법을 통하여 2가지 객체(cat, dog)를 생성했다.
- dog 와 cat 은 엄연히 따로 존재하는 객체이지만, Animal 이라는 Class, 즉 Animal 타입에
속하는 인스턴스이기도 하다.
2. Interface
public interface Reader {
public byte[] loadData(String url);
}
public class FileReader implements Reader {
public byte[] loadData(String url) {
// File System 에서 특정 파일을 읽어서 byte[] 형태로 메모리에 올린다.
}
}
public class SocketReader implements Reader {
public byte[] loadData(String url) {
// Socket Client 를 통해서 외부 자원을 읽고 byte[] 형태로 메모리에 올린다.
}
}
// 클라이언트 코드
public class MainClass {
public static void main(String[] args) {
Reader reader = new FileReader();
byte[] fileData = reader.loadData("file:/data/file/user_info.txt");
animal = new SocketReader();
byte[] externalData = reader.walk("http://daily.code.io/user_info");
// 분명 클라이언트 코드에서는 하나의 타입(여기서는 Reader interface)를
// 사용하지만 이 요청을 수행하는 내부적인 방법은 완전히 다르다.
}
}- Reader 라는 인터페이스는 여러 객체를 묶어주는 boundary(= type)이다.
- Reader 를 구현한 2가지 concrete class (FileReader, SocketReader) 가 있다.
- 이 2가지 concrete class 를 통해서 2가지 객체를 생성할 수 있다.
- 이 2개의 객체는 Reader 라는 인터페이스 타입에 종속되는 인스턴스다.
음... 그런데 여기까지만 작성하고 다시 다형성에 대한 저의 정의를 보면 약간 께림칙합니다.
"... 요청 처리 객체들이 하나의 타입에 속하지만, 각각의 인스턴스가 요청을 서로 다르게 처리한다"
Interface 코드는 Reader 라는 하나의 타입에 서로 다른 concrete class 를 작성하여
다형성을 구현할 수 있습니다. 외부에서 Reader r = ~~; r.loadData("??") 를 하면
실제 런타임에 변수 r 이 참조하는 인스턴스가 동작하게 되어서,
결과적으로 client 요청의 형태는 같지만, 다른 내부 동작을 하게 되죠.
다형성을 Java 라는 프로그래밍 언어로 구현한 것이죠.
하지만 순수한 Class 를 사용하면 어떨까요?
앞서 작성한 Class Animal 로 cat 객체를 만들든, dog 객체를 만들든 클라이언트
코드에서 요청한 walk 에 대한 내부 처리방식은 두 객체 모두 똑같습니다.
제가 생각하는 다형성과는 거리가 멀죠.
두 객체가 물론 Animal 이라는 하나의 타입에는 속하지만,
내부 처리방식까지도 완전히 동일하기 때문입니다.
그렇다면 Java 의 Class 라는 타입을 통해서는 다형성을 어떻게 구현할까?
그 방법은 바로 "extends"입니다.
extends 라는 표현을 봐서 알겠지만,
Class 에 정의된 데이터 혹은 메소드를 그대로 유지하면서,
거기에 추가적인 기능을 덧붙여(=확장하여) 새로운 Class 를 생성하는 문법입니다.
예제를 한번 볼까요?
public class Animal {...}
public class Dog extends Animal {
@Override
public void walk() {
System.out.println("walk like a cat 🐈");
}
}
public class Cat extends Animal {
@Override
public void walk() {
System.out.println("walk like a dog 🐕");
}
}
public class MainClass {
public static void main(String[] args) {
Animal animal = new Dog();
animal.walk(); // "walk like a dog 🐕"
animal = new Cat();
animal.walk(); // "walk like a cat 🐈"
}
}클라이언트 코드에서는 Animal 이라는 하나의 타입을 바라보고,
실제 요청도 해당 타입에 정의된 인터페이스만 사용하게 되죠.
하지만 하나의 타입을 확장한 하위 타입의 객체를 사용했기 때문에
결과적으로 같은 요청에 대해서 다르게 동작하게 됩니다.
즉 다형성의 정의에 부합하는 동작방식입니다.
추상화
추상화의 방식
추상화는 굉장히 복잡하고 세세한 부분들을 단순화하는 과정을 의미합니다.
딱 보면 알겠지만 추상화는 단순히 프로그래밍 영역을 벗어나서 더 다양한 곳에서도
쓰일 수 있는 표현입니다.
하지만 지금은 객체지향을 공부중이니,
객체지향에서 주로 어떤 추상화가 있는지만 알면 됩니다.
- 타입 추상화
- 복잡한 로직에 대한 추상화
타입 추상화는 타입의 계층화로 이해해도 됩니다.
예를 들어서 아래 그림과 같이 말이죠.
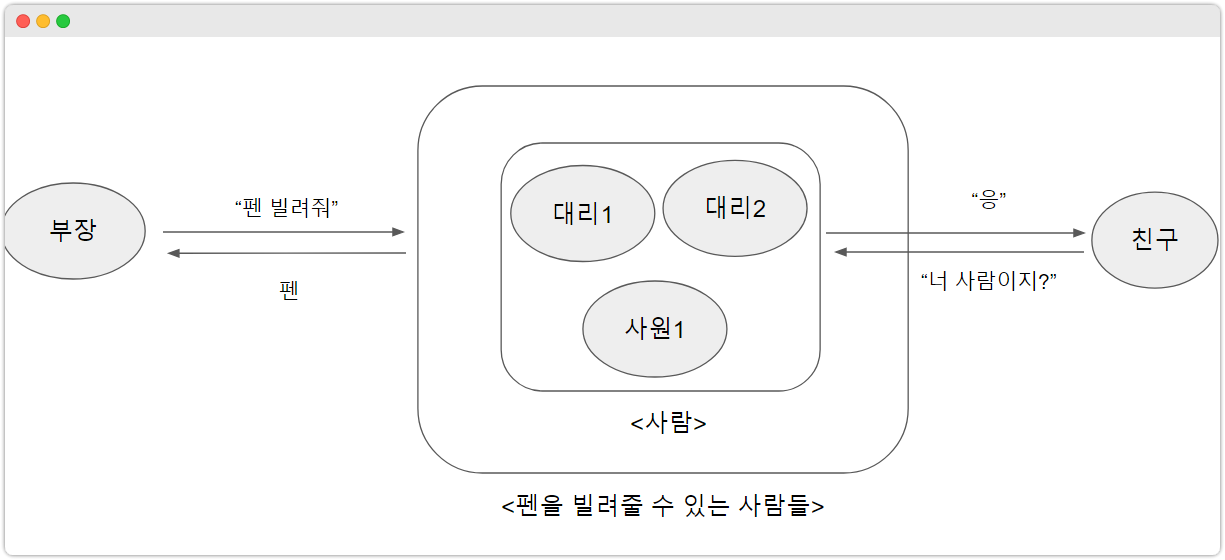
앞서 본 예제를 조금 변형시켜봤습니다.
모든 대리, 사원들은 무장님의 "펜을 빌려달라"라는 요청을 처리해줄 수 있는
객체들이고, 이런 기능을 제공할 수 있는 객체들을 묶는 Boundary 를 타입이라 했습니다.
그런데 각 객체들을 자세히 보면 모두 "서로 다른 사람"입니다.
즉 세세하게 모두 서로 다른 이름, 나이를 갖죠.
- 대리1는 박철수라는 이름을 갖고, 나이가 21 인 사람입니다.
- 대리2는 김동수라는 이름을 갖고, 나이가 23 인 사람입니다.
- 사원1은 하동훈이라는 이름을 갖고, 나이가 20 인 사람입니다.
그런데 각각 의 세부사항들을 좀 더 단순하게 하는 추상화를 거치면 어떨까요?
모두 맨 끝에 "사람"이라는 표현으로 추상화가 가능합니다.
즉 각각의 펜을 빌려줄 수 있는 사람들은 결국 "사람"이라는 것으로 추상화가 되죠.
이렇게 기존에 있는 타입의 더 안쪽의 타입이 생길 때, 즉 계층이 생기게 될 때
우리는 이를 타입의 추상화라고 합니다.
복잡한 로직에 대한 추상화는 단순화는 굳이 설명하지 않겠습니다.
간단한 예시로 그대로 복잡한 로직 자체를 하나의 객체로 추상화 시킨 것을 떠올리면 됩니다.
추상화는 변경되는 부분에 적용하면 좋다
변경이 자주 발생하는 코드(로직)에 대해서는 추상화를 하면 좋다.
위에서 말한 어떤 형태의 추상화든간에 적용하면 된다.
자주 발생하는 변경 point 를 하나의 객체 혹은 기능으로 추상화함으로써
해당 변경이 오롯이 해당 객체와 관련해서만 변경해주면 된다.
SOLID 설계 원칙
아주 간단하게만 정리하겠다.
SOLID 는 객체지향적으로 설계할 때 필요한 중요한 5가지 원칙을 의미한다.
SOLID 의 각 한 철자가, 하나의 원칙을 의미하며 아래와 같다.
Single Responsibility principle (SRP) , 단일책임 원칙Open-closed principle (OCP) , 개방-폐쇄 원칙Liskov substitution principle (LSP) , 리스코프 치환 원칙Interface segregation principle (ISP) , 인터페이스 분리 원칙Dependency inversion principle (DIP) , 의존 역전 원칙
SRP, 단일 책임 원칙
하나의 객체는 하나의 책임만 갖는다는 것이다.
어떤 객체가 책임이 너무 많으면 하나의 책임과 관련된 변경사항 때문에,
다른 책임과 관련된 기능에도 영향을 주기 때문이다.
원치 않는 연쇄적인 변경이 발생할 수 있다는 의미다.
OCP, 개방-폐쇄 원칙
"화장에는 열러 있고, 변경에는 닫혀있다" 라는 의미다.
좀 더 풀어서 얘기하자면....
- 기능을 제공하는 객체는 자신의 기능을 확장할 수 있지만,
- 그 기능을 사용하는 객체에는 변경이 일어나서는 안된다.
라는 의미다.
이는 주로 추상 타입을 정의함으로써 가능한데,
기능을 제공하는 객체들을 추상 타입으로 묶고,
기능을 사용하는 객체에서는 해당 추상 타입에 대고 기능을 요청하면 된다.
이러면 추상 타입을 실제 구현한 객체들 얼마든지 추가할 수 있고,
이를 사용하는 입장에서는 계속 똑같은 추상 타입에 대고 기능을 요청하기 때문에
OCP 가 자연스럽게 지켜진다.
LSP, 리스코프 치환 원칙
"상위 타입의 객체를 하위 타입의 객체로 치환해도 상위 타입을 사용하는 프로그램은 정상적으로 동작해야 한다" 라는 의미를 갖는다.
좀 더 쉽게 얘기하자면 리스코프 치환 원칙은 기능의 명세(계약)을 하위 타입의 객체도
똑같이 지켜야 한다는 것이다.
예를 들어서 loadData() 라는 원격에서 데이터를 읽어오는 메소드를 제공하는 상위 타입이
있다고 가정하자. 그런데 하위 타입에서 loadData 를 확장했는데 데이터를 읽어올 뿐만 아니라
화면에 해당 데이터를 랜더링하는 기능까지 포함되면 어떨까?
이는 초기 loadData 라는 명세를 만든 상위 타입의 의도를 완전히 무시한 것이다.
이로 인해서 하위 타입의 객체를 받아서 사용하는 코드에서는 전혀 엉뚱한 동작을 하게 될 수 있다.
ISP, 인터페이스 분리 원칙
"클라이언트는 자신이 사용하는 메서드에만 의존해야 한다" 라는 의미이다.
이는 클라이언트 코드가 어떤 객체의 A 기능을 사용하고
다른 클라이언트가 객체의 B 기능을 사용하는 상태에서
클라이언트의 변경에 의해서 객체의 B 기능에도 변경사항이 전파될 수도 있습니다.
그런데 문제는 이 B 기능에 의해서 A 기능을 사용하는 클라이언트에도 영향을 줄 수 있습니다.
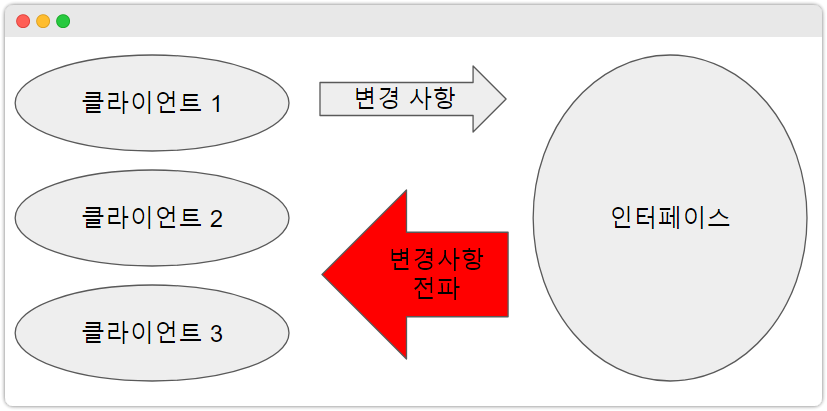
그림을 보면 알겠지만, 이는 단일책임원칙을 잘 지키지 못해서 하나의 객체가
제공하는 인터페이스의 영역이 너무 커서 그렇습니다.
이런 현상을 피하기 위하는 클라이언트 입장에서 인터페이스를 분리하라는 ISP 원칙을
지키면 됩니다. (아래 그림 참고)

각 클라이언트가 사용하는 기능을 중심으로 인터페이스를 분리하여,
클라이언트로부터 발생하는 인터페이스의 변경여파를 최소화하자는 것이죠!
DIP, 의존 역전 원칙
"고수준 모듈은 저수준 모듈의 구현에 의존해서는 안된다. 저수준 모듈이 고수준 모듈에서 정의한 추상 타입에 의존해야 한다" 라는 의미의 원칙입니다.
여기서 말하는 고수준 모듈은 단일 기능을 제공하는 모듈이고,
저수준 모듈은 고수준 모듈의 기능을 구현하기 위해 필요한 하위 기능의 구현으로 정의할 수 있습니다.
예를들어서 아래처럼 말이죠.
- 고수준 모듈: 바이트 데이터를 읽고, 암호화하고, 해당 데이터를 다시 파일에 쓰는 기능
- 저수준 모듈:
- 파일에서 데이터 읽는 기능
- 알고리즘을 통한 암호화 기능
- 파일에 바이트 데이터를 쓰는 기능
좀 쉽게 생각하자면 고수준 모듈은 상대적으로 큰 틀, 흐름을 제어하는 것이라고 생각하면 되고,
그 큰 틀 안에서 세세한 기능 구현을 하위 모듈이라 생각하면 됩니다.
그런데 이때 고수준 모듈이 상세한 저수준 모듈의 타입, 객체 등에 의존하는 코드를
작성하면 해당 저수준 모듈의 변경에 의해서 계속해서 고수준 모듈도 변경이 일어날 수 있습니다.
이를 방지하기 위해서 고수준 모듈에서 하나의 추상 타입을 제공하고,
고수준 모듈, 저수준 모듈 모두 해당 추상타입에만 의존하게 하는 것이다.
이러면 고수준 모듈에서는 해당 추상 타입에 대고 기능을 요청할 것이고,
저수준 모듈에서는 고수준 모듈에서 제공한 하나의 규칙과도 같은
추상타입에 대한 구현을 통해서 기능을 제공할 것이다.
결과적으로 저수준 모듈의 변화는 고수준 모듈에 영향을 주지 않게된다!
참고: 객체지향 vs 프로시저 프로그래밍
프로시저 프로그래밍
프로시저 프로그래밍은 어떤 데이터가 있고, 그 데이터를 처리해주는 "프로시저(= 함수)"를
사용한 프로그래밍 방식을 의미합니다.
프로시저 프로그래밍의 문제점
프로그램은 계속 커지는 게 일반적이고,
커지는 프로그램에는 당연히 관리해야될 새로운 데이터와 이를 처리하는 프로시저들이 늘어납니다.
그리고 이러면서 자연스럽게 아래 2가지 문제점이 나오기 시작합니다.
- 여러 프로시저가 하나의 데이터를 동시 다발적으로 변경
- 서로 다른 프로시저가, 하나의 데이터에 대해서 서로 다르게 해석
- ex: A 프로시저는 어떤
회사원의 퇴사일데이터를 null 값이면 현재 근무로 처리 - ex: 그런데 B 프로시저는 null 이면 퇴사로 간주해버림 😱
- 이렇게 다른 프로시저가 같은 데이터에 대한 해석이 달라짐에 따라 잘못된 프로시저가
계속해서 코드가 불어나고, 점점 나비효과가 되어서 돌아옴.
- ex: A 프로시저는 어떤
객체지향은 어떨까?
프로시저는 여러 공유 데이터와 이를 처리하는 프로시저가 여럿이 잇는데,
객체지향 프로그래밍은 관련된 데이터와 이를 처리하는 프로시저가 하나로 묶여있는
형태를 갖습니다. 덕분에 이곳저곳에서 공유 데이터를 처리하는 게 아니라,
다른 객체가 직접적으로 데이터에 접근하는 것을 막고,
어떤 데이터를 처리하기 위해서는 객체에게 요청을 하게 됩니다.
앞서 본 문제점들이 사라지겠죠?
추후 계획
음... 글을 쓰면서도 아직 애매한 부분이 많았던 거 같다.
"오브젝트"라는 조영호님의 책을 읽어보고 재작성하게 될지도 모르겠다.
참고하면 좋은 글들
