🍀 JPQL 개요
DataBase 하나의 Table에는 수 많은 데이터들이 있을 수 있다.
그런데 이런 데이터들을 엔티티의 Collection Type 의 필드로 다 끌고 오면
큰 메모리 낭비가 발생한다.
그렇기 때문에 DB에서 데이터를 필터링하여 JPA가 사용할 수 있도록 해야 한다.
JPA 는 SQL에 의존을 하면 안되기 때문에 SQL 대신 JPQL을 사용한다.
JPQL의 특징은 아래와 같다.
- 테이블을 대상으로 쿼리 X, 엔티티 객체를 대상으로 쿼리 O
- JPQL은 SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않는다.
- 최종적으로 JPQL은 SQL로 변환된다.
🍀 JPQL 예제 작성
지금부터 JPA 에 대해서 알아 볼 것이다.
시작 하기 전에 예제 테이블 및 엔티티 코드를 미리 작성하고 가겠다.
데이터베이스 테이블 구성
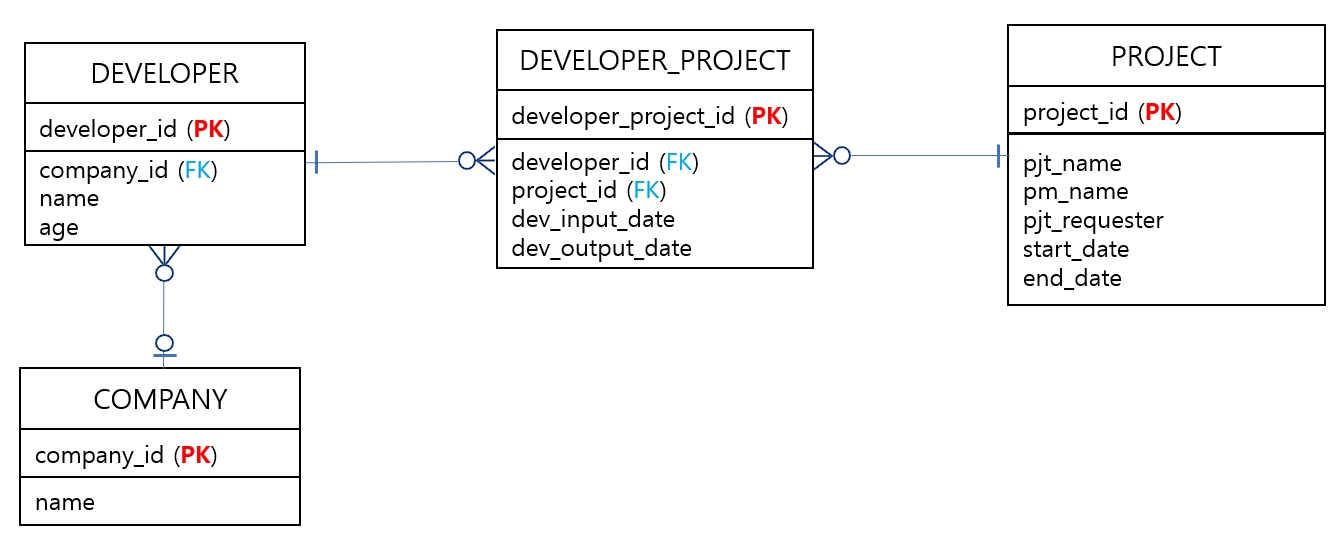
엔티티 코드
// 개발자 엔티티
@Entity
@Getter @Setter
@ToString
public class Developer {
@Id @GeneratedValue
@Column(name = "developer_id")
private Long id;
private String name;
private int age;
@ToString.Exclude
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "company_id")
private Company company;
}// 개발자들이 소속된 회사 정보 엔티티
@Entity
@Getter @Setter
@ToString
public class Company {
@Id @GeneratedValue
@Column(name = "company_id")
private Long id;
private String name;
@ToString.Exclude
@OneToMany(mappedBy = "company")
private List<Developer> developers = new ArrayList<>();
}// 개발자_투입된 프로젝트_중간 테이블 (N:N 해소)
@Entity
@Getter @Setter
@ToString
public class DeveloperProject {
@Id @GeneratedValue
@Column(name = "developer_project_id")
private Long id;
@ToString.Exclude
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "developer_id")
private Developer developer;
@ToString.Exclude
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "project_id")
private Project project;
private LocalDate devInputDate; // 개발자 투입 일자
private LocalDate devOutputDate; // 개발자 투입 제외 일자
}// 개발자들이 투입되는 프로젝트에 대한 정보를 담는 엔티티
@Entity
@Getter @Setter
@ToString
public class Project {
@Id @GeneratedValue
@Column(name = "project_id")
private Long id;
private String pjtName; // 프로젝트 이름
private String pmName; // 프로젝트 매니저의 이름
private String pjtRequester; // 프로젝트 요청자
private LocalDate startDate; // 프로젝트 시작일자
private LocalDate endDate; // 프로젝트 종료일자
}일단 편의 메소드는 딱히 작성하지 않았다. 지금은 JPQL에만 집중하자.
그리고 여러가지 테스트를 해보기 위해서 아래처럼 데이터를 넣어놓는다.
(귀찮다면 맨 마지막 목차인 "참고"에서 예제 데이터 insert 코드를 한번만 실행시킨다)

데이터 삽입이 모두 끝나면 persistence.xml 에서 hibernate.hbm2ddl.auto의 value 값을 create에서 validate로 변경해준다.
🍀 JPQL 기본
1. 기본 문법과 쿼리 API
JPQL에는 SELECT, UPDATE, DELETE 가 있고 차례대로 사용법을 알아보자.
참고로 엔티티를 저장할 때는 persist를 사용하므로 INSERT 문은 없다.
SELECT 문
ex) select d from Developer d
- JPQL은 엔티티 이름 및 필드에 대해서는 대소문자를 구분한다.
- JPQL은 엔티티 클래스 명이 아니라, 엔티티 이름을 사용한다.
ex) `@Entity(name ="entity_name")// 기본값이 클래스 명임. - JPQL에서는 별칭이 필수다. 하지만 Hibernate의 HQL을 쓰면 특정상황에서는 생략 가능
TypeQuery, Query
em.createQuery 사용시 2번째 인자로 Class 값을 주서 TypeQuery, 아니면 Query이다.
둘간의 차이를 아래 코드로 보면서 이해하자.
TypeQuery 사용 코드
// Class 지정하면 TypeQuery
TypedQuery<Developer> typedQuery = em.createQuery("select d from Developer d", Developer.class);
// API의 반환값이 제네릭이 적용된 것을 확인할 수 있다.
List<Developer> devList = typedQuery.getResultList();
for (Developer developer : devList) {
System.out.println("developer = " + developer);
}Query 사용 코드
// Class 지정 안하면 Query
Query query = em.createQuery("select d.name, d.age from Developer d");
List devList = query.getResultList();
for (Object o : devList) {
Object[] result = (Object[]) o;
System.out.println(result[0] + ", " + result[1]);
}
// 엔티티 전체가 아니라, 부분적으로 select를 해서 데이터를 읽어 올 때 유용하다.결과 조회
- query.getResultList(): 결과가 있다면 컬렉션으로 주고, 없으면 빈 컬렉션 반환
- query.getSingleResult() : 결과가 정확히 하나일 때 사용
- 결과가 없으면 NoResultException, 결과가 2개 이상이면 NonUniqueResultException
2. 파라미터 바인딩
이름 기준 파라미터
// :parameter 를 하고 setParameter로 값 매핑
TypedQuery<Developer> query
= em.createQuery("select d from Developer d where d.name = :devName", Developer.class);
query.setParameter("devName", "naverDev1");
query.getResultList().forEach(System.out::println);
위치 기준 파라미터
TypedQuery<Developer> query
= em.createQuery("select d from Developer d where d.name = ?1", Developer.class);
query.setParameter(1, "naverDev1");
query.getResultList().forEach(System.out::println);3. 프로젝션
select 절에 조회할 대상을 지정하는 것이다.
대상은 엔티티, 임베디드 타입, 스칼라 타입이 있다.
엔티티 프로젝션
조회한 엔티티는 영속성 컨텍스트에서 관리된다.
임베디드 타입 프로젝션
- 조회의 시작점, 즉
From 엔티티를 사용하지 못한다. - 엔티티가 시작점으로 하고, 그리고 그 엔티티의 별칭에서 임베디디 타입을 빼오면 된다.
- 임베디드 타입은 영속서 컨텍스트에서 관리 X
스칼라 타입 프로젝션
딱히 특징은 없다.
부분적인 데이터를 읽어오는 방법
엔티티를 통으로 읽는 것도 좋지만, 가끔은 엔티티의 몇가지 필드만 읽고 싶을 때가 있다.
이럴 때는 2가지 방법이 있다.
하나는 이전에 배운 Query 를 사용하는 것이고,
다른 하나는 지금 알아볼 New 명령어 사용하는 방법이다.
아래 코드를 보면서 이해하자.
// 필요한 필드만 정의하고, 필드를 세팅할 수 있는 생성자 작성
@ToString
public class DeveloperDTO {
private String name;
private int age;
public DeveloperDTO(String name, int age) {
this.name = name;
this.age = age;
}
}TypedQuery<DeveloperDTO> query
= em.createQuery("select new hello.dto.DeveloperDTO(d.name, d.age) from Developer d",
DeveloperDTO.class);
query.getResultList().forEach(System.out::println);콘솔 출력 결과:
DeveloperDTO(name=naverDev1, age=26)
DeveloperDTO(name=naverDev2, age=22)
DeveloperDTO(name=kakaoDev1, age=27)
DeveloperDTO(name=kakaoDev2, age=30)4. 페이징 API
코드
TypedQuery<Developer> query
= em.createQuery("select d from Developer d order by d.age desc", Developer.class);
query.setFirstResult(0);
query.setMaxResults(2);
query.getResultList().forEach(System.out::println);콘솔 출력
Hibernate:
select
developer0_.developer_id as develope1_1_,
developer0_.age as age2_1_,
developer0_.company_id as company_4_1_,
developer0_.name as name3_1_
from
developer developer0_
order by
developer0_.age desc limit ? // 페이징 쿼리가 적용된 것을 확인!
Developer(id=6, name=kakaoDev2, age=30)
Developer(id=5, name=kakaoDev1, age=27)5. 집합과 정렬
집합은 집합함수를 통해서 통계정보를 구할 때 주로 사용된다.
JPQL을 통해서는 어떻게 사용하는지 코드를 통해서 알아보자.
- 테스트 코드
Query query = em.createQuery(
"select c.name, count (d), sum (d.age), avg (d.age), max (d.age) " +
"from Developer d inner join d.company c " +
"group by c.name " +
"having count(d) > 0" // 회사원이 없는 1인 기업은 제외!
);
for (Object o : query.getResultList()) {
System.out.println("result = " + Arrays.toString((Object[]) o));
}- 출력 결과
Hibernate:
select
company1_.name as col_0_0_,
count(developer0_.developer_id) as col_1_0_,
sum(developer0_.age) as col_2_0_,
avg(cast(developer0_.age as double)) as col_3_0_,
max(developer0_.age) as col_4_0_
from
developer developer0_
inner join
company company1_
on developer0_.company_id=company1_.company_id
group by
company1_.name
having
count(developer0_.developer_id)>0
[kakao, 2, 57, 28.5, 30]
[naver, 2, 48, 24.0, 26]6. 조인
내부 조인
- 테스트 코드
TypedQuery<Developer> query
= em.createQuery(
"select d from Developer d inner join d.company c " +
"where c.name = :companyName", Developer.class)
.setParameter("companyName", "kakao");
query.getResultList().forEach(System.out::println);- 출력 결과
Hibernate:
select
developer0_.developer_id as develope1_1_,
developer0_.age as age2_1_,
developer0_.company_id as company_4_1_,
developer0_.name as name3_1_
from
developer developer0_
inner join
company company1_
on developer0_.company_id=company1_.company_id
where
company1_.name=?
Developer(id=5, name=kakaoDev1, age=27)
Developer(id=6, name=kakaoDev2, age=30)
Process finished with exit code 0
외부 조인
- 테스트 코드
TypedQuery<Developer> query
= em.createQuery(
"select d from Developer d left join d.company c " +
"where c.name = :companyName", Developer.class)
.setParameter("companyName", "kakao");
query.getResultList().forEach(System.out::println);- 출력 결과
Hibernate:
select
developer0_.developer_id as develope1_1_,
developer0_.age as age2_1_,
developer0_.company_id as company_4_1_,
developer0_.name as name3_1_
from
developer developer0_
left outer join
company company1_
on developer0_.company_id=company1_.company_id
where
company1_.name=?
Developer(id=5, name=kakaoDev1, age=27)
Developer(id=6, name=kakaoDev2, age=30)세타 조인
- 주의 사항
- where 절을 사용해서 세타 조인 사용 가능
- 세타 조인은 inner join만 지원
- 연관관계가 없는 필드를 사용해서 조인할 수 있다, 다만 CROSS JOIN이 사용된다
- 테스트 코드
Query query = em.createQuery("select d, c from Developer d, Company c " +
"where d.name like concat('%',c.name,'%')");
query.getResultList().forEach(s -> {
Object[] result = (Object[]) s;
System.out.println("result = " + Arrays.toString(result));
});- 출력 결과
Hibernate:
select
developer0_.developer_id as develope1_1_0_,
company1_.company_id as company_1_0_1_,
developer0_.age as age2_1_0_,
developer0_.company_id as company_4_1_0_,
developer0_.name as name3_1_0_,
company1_.name as name2_0_1_
from
developer developer0_ cross // cross join을 사용한다.
join
company company1_
where
developer0_.name like ('%'||company1_.name||'%')
result = [Developer(id=3, name=naverDev1, age=26), Company(id=1, name=naver)]
result = [Developer(id=4, name=naverDev2, age=22), Company(id=1, name=naver)]
result = [Developer(id=5, name=kakaoDev1, age=27), Company(id=2, name=kakao)]
result = [Developer(id=6, name=kakaoDev2, age=30), Company(id=2, name=kakao)]컬렉션 조인
- 테스트 코드
Query query = em.createQuery("select c, d from Company c left join c.developers d");
for (Object o : query.getResultList()) {
Object[] result = (Object[]) o;
System.out.println("result = " + Arrays.toString(result));
}출력 결과
Hibernate:
select
company0_.company_id as company_1_0_0_,
developers1_.developer_id as develope1_1_1_,
company0_.name as name2_0_0_,
developers1_.age as age2_1_1_,
developers1_.company_id as company_4_1_1_,
developers1_.name as name3_1_1_
from
company company0_
left outer join
developer developers1_
on company0_.company_id=developers1_.company_id
result = [Company(id=1, name=naver), Developer(id=3, name=naverDev1, age=26)]
result = [Company(id=1, name=naver), Developer(id=4, name=naverDev2, age=22)]
result = [Company(id=2, name=kakao), Developer(id=5, name=kakaoDev1, age=27)]
result = [Company(id=2, name=kakao), Developer(id=6, name=kakaoDev2, age=30)]JOIN ON 절
- Join 에서 필터링을 하고 싶을 사용
- 연관관계가 없어도(또는 연관관계 필드를 사용하지 않아도) 외부/내부 조인 가능
- 옛날에는 내부 조인만 가능했다고 함. JPA 2.1 부터 외부 조인도 가능
테스트 코드
// 자세히 보면 이전에는 left join d.company 를 했던 방식과 다르게 작성했다.
// 이는 연관관계 필드를 사용하지 않고도 join을 걸 수 있다는 의미이기도 하다.
List resultList = em.createQuery(
"select d, c from Developer d left join Company c " +
"on d.name like concat('%', c.name, '%') "
).getResultList();
for (Object o : resultList) {
Object[] result = (Object[]) o;
System.out.println("result = " + Arrays.toString(result));
}출력 결과
Hibernate:
select
developer0_.developer_id as develope1_1_0_,
company1_.company_id as company_1_0_1_,
developer0_.age as age2_1_0_,
developer0_.company_id as company_4_1_0_,
developer0_.name as name3_1_0_,
company1_.name as name2_0_1_
from
developer developer0_
left outer join
company company1_
on (
developer0_.name like ('%'||company1_.name||'%')
)
result = [Developer(id=3, name=naverDev1, age=26), Company(id=1, name=naver)]
result = [Developer(id=4, name=naverDev2, age=22), Company(id=1, name=naver)]
result = [Developer(id=5, name=kakaoDev1, age=27), Company(id=2, name=kakao)]
result = [Developer(id=6, name=kakaoDev2, age=30), Company(id=2, name=kakao)]7. 서브 쿼리
테스트 코드 (1)
TypedQuery<Developer> query = em.createQuery(
"select d from Developer d " +
"where d.age > (select avg(d2.age) from Developer d2)",
Developer.class);
query.getResultList().forEach(System.out::println);콘솔 출력 (1)
Hibernate:
select
developer0_.developer_id as develope1_1_,
developer0_.age as age2_1_,
developer0_.company_id as company_4_1_,
developer0_.name as name3_1_
from
developer developer0_
where
developer0_.age>(
select
avg(cast(developer1_.age as double))
from
developer developer1_
)
Developer(id=5, name=kakaoDev1, age=27)
Developer(id=6, name=kakaoDev2, age=30)테스트 코드 (2)
TypedQuery<Company> query = em.createQuery(
"select c from Company c " +
"where (select count(d) from Company c2 inner join c2.developers d) > 0",
Company.class);
query.getResultList().forEach(System.out::println);콘솔 출력 (2)
Hibernate:
select
company0_.company_id as company_1_0_,
company0_.name as name2_0_
from
company company0_
where
(
select
count(developers2_.developer_id)
from
company company1_
inner join
developer developers2_
on company1_.company_id=developers2_.company_id
)>0
Company(id=1, name=naver)
Company(id=2, name=kakao)그외에도...
ALL, EXISTS, ANY 등의 문법에도 이런 JPQL 서브쿼리 기능을 적용할 수 있다.
코드는 생략.
JPA 서브 쿼리 한계
- SELECT(하이버네이트 쓰면), WHERE, HAVING 절에서만 서브쿼리 사용 가능
- FROM 절의 서브 쿼리는 현재 JPQL에서 불가능! 대체할 방법은 많다.
8. JPQL 타입 표현과 기타식
타입 표현
- 문자:
''로 감싸기, 만약''중간에'가 있다면''로 표기하면 escape 됨 - 숫자: 10L(Long), 10D(Double), 10F(Float)
- 불린: TRUE, FALSE
- ENUM: hello.goodjob.Type , 패키지명을 다 포함시켜야 함
- Entity:
TYPE(d) = Developer, 상속 관계에서 쓰인다.
기타식
EXISTS,INAND,OR,NOT=,>,>=,<,<=,<>BETWEEN,LIKE,IS NULL
8. 조건식
CASE
코드
Query query = em.createQuery("select " +
"case when d.age < 25 then '어린 개발자' " +
" else '개발자' " +
"end " +
"from Developer d");
query.getResultList();콘솔 출력
Hibernate:
select
case
when developer0_.age<25 then '어린 개발자'
else '개발자'
end as col_0_0_
from
developer developer0_CAOLESCE, NULLIF
생략
9. JPQL 기본 함수
기본 제공
- concat
- substring
- trim
- lower, upper
- length
- locate
- abs, sqrt, mod
- size
사용자 정의 함수 호출
방언에 추가해야함. 이미 제공하는 방언을 확장하여 새로운 방언 클래스를 만들면 된다.
org.hibernate.dialect.H2Dialect java 파일을 열어서 어떻게 하는지 가볍게 보자.
그리고 확장해서 Dialect를 생성하고 적용했다면
function('생성한 함수 이름', ...) 처럼 사용할 수 있다.
🍀 참고
자바 ORM 표준 JPA 프로그래밍
인프런 JPA 관련 로드맵
예제 데이터 insert 코드
// company table insert
Company naver = new Company();
naver.setName("naver");
em.persist(naver);
Company kakao = new Company();
kakao.setName("kakao");
em.persist(kakao);
// developer table insert
Developer naverDev1 = new Developer();
naverDev1.setName("naverDev1");
naverDev1.setCompany(naver);
naverDev1.setAge(26);
em.persist(naverDev1);
Developer naverDev2 = new Developer();
naverDev2.setName("naverDev2");
naverDev2.setCompany(naver);
naverDev2.setAge(22);
em.persist(naverDev2);
Developer kakaoDev1 = new Developer();
kakaoDev1.setName("kakaoDev1");
kakaoDev1.setCompany(kakao);
kakaoDev1.setAge(27);
em.persist(kakaoDev1);
Developer kakaoDev2 = new Developer();
kakaoDev2.setName("kakaoDev2");
kakaoDev2.setCompany(kakao);
kakaoDev2.setAge(30);
em.persist(kakaoDev2);
// project table insert
Project naverProject = new Project();
naverProject.setPjtName("naver-api-building-ver1");
naverProject.setPjtRequester("requester1");
naverProject.setPmName("naver-pm");
naverProject.setStartDate(LocalDate.of(2022,2,15));
naverProject.setEndDate(LocalDate.of(2023, 12, 30));
em.persist(naverProject);
Project kakaoProject = new Project();
kakaoProject.setPjtName("kakao-care-project-ver1");
kakaoProject.setPjtRequester("requester2");
kakaoProject.setPmName("kakao-pm");
kakaoProject.setStartDate(LocalDate.of(2022, 1, 20));
kakaoProject.setEndDate(LocalDate.of(2023, 11, 10));
em.persist(kakaoProject);
// dev-project table insert
DeveloperProject naverDevPjt1 = new DeveloperProject();
naverDevPjt1.setDeveloper(naverDev1);
naverDevPjt1.setProject(naverProject);
naverDevPjt1.setDevInputDate(LocalDate.of(2022,2,15));
naverDevPjt1.setDevOutputDate(LocalDate.of(2023,12,30));
em.persist(naverDevPjt1);
DeveloperProject naverDevPjt2 = new DeveloperProject();
naverDevPjt2.setDeveloper(naverDev2);
naverDevPjt2.setProject(naverProject);
naverDevPjt2.setDevInputDate(LocalDate.of(2022,2,15));
naverDevPjt2.setDevOutputDate(LocalDate.of(2023,12,30));
em.persist(naverDevPjt2);
DeveloperProject kakaoDevPjt1 = new DeveloperProject();
kakaoDevPjt1.setDeveloper(kakaoDev1);
kakaoDevPjt1.setProject(kakaoProject);
kakaoDevPjt1.setDevInputDate(LocalDate.of(2022, 1, 20));
kakaoDevPjt1.setDevOutputDate(LocalDate.of(2023, 11, 10));
em.persist(kakaoDevPjt1);
DeveloperProject kakaoDevPjt2 = new DeveloperProject();
kakaoDevPjt2.setDeveloper(kakaoDev2);
kakaoDevPjt2.setProject(kakaoProject);
kakaoDevPjt2.setDevInputDate(LocalDate.of(2022, 1, 20));
kakaoDevPjt2.setDevOutputDate(LocalDate.of(2023, 11, 10));
em.persist(kakaoDevPjt2);