Disclaimer: 공부한 내용을 캐주얼하게 정리하는 노트입니다. 정리하는 노트이기에 다듬어지지 않은 부분이 많고, 아직 배워가는 중이기에 틀린 내용이 있을 수 있습니다. 잘못된 내용은 댓글로 피드백 주세요 :)
Embeddings
- 딥러닝에 하기 위해 이미지,텍스트 등의 객체를 학습을 통해 벡터 (Vector) 로 맵핑하는 과정
- CNN 을 통해 이미지 데이터를 벡터 데이터로 변환
- RNN 등을 통해 텍스트를 벡트로 변환 (간단하게는 word2vec 과 같은 모델 사용)
- 임베딩 과정을 거치면 각 데이터 간의 거리를 계산할 수 있게 되는데, 이를 통해 서로 다른 객체 간 유사성과 같은 관계를 수치화 할 수 있게 된다.
1) Word Embeddings
단어의 의미 (representation) 은 문맥에 의해 결정된다.
- 단어의 의미는 근처에 자주 등장하는 단어들에 의해 의미가 결정된다 - Distributional semandics
- "You sall know a word by the company it keeps" (J.R.Firth 1957:11)
- 문맥 (context) 는 특정 단어 (w) 근처의 고정된 윈도우 내에 나타나는 단어들의 집합으로 구성되며, 문맥의 단어들이 특정 단어 (w) 의 의미를 결정한다.
[Collobert & Weston vectors]
- 모델 학습 시 단어 (w) 와 그 문맥은 positive training sample 로 사용되고, 임의의 단어는 negative training sample 로 활용하는 아이디어 - 임의의 단어에 대한 점수는 페널티를 부여해서 학습하는 방법
Word2vec - Skip-gram model
- 주어진 단어를 통해 관련 문맥 단어를 예측하는 방법 (문맥의 단어로부터 특정 단어를 예측하는 CBOW - Continuous Bag of Words - 와는 반대의 방법)
- 문맥은 fixed size window 로 지정
- I want to [go] home
go=> (center word - 주어진 단어)to=> (context)home=> (context)
Skip-gram 의 목표 함수
- center word 가 주어졌을 때, 고정된 윈도우 사이즈 m 내 문맥의 단어를 예측 시 목적 함수 (단어의 위치 t=1,...T)
- 하지만 를 계산하기에는 벡터 사이즈가 커지므로 비용이 비쌈. 따라서, Hierarchical Softmax 와 Negative Sampling 기법을 활용
Negative Sampling 을 활용
- (word, context) 에 대해 negative pair (word, context') 를 샘플링하는 방법
- 중심 단어 (center word) 근처 문맥 위치에 랜덤 단어가 오는 확률을 최소화하여 실제 문맥 단어의 확률을 최대화하는 방법
Word2Vec 외도 대표적인 word embeddings 기법들로는 GloVe (Global Vectors), fastText 등이 있다.
Word embeddings 를 평가하는 방법
- Intrinsic
- 특정 subtask 에 대해 평가하는 방법으로, 계산이 빠르다.
- 학습하는 동안 word embedding 의 퀄리티를 평가할 수 있으므로 모델을 잘 이해할 수 있다.
- 실제 태스크에 적용하기 전까지는 잘 동작하는 모델인지 확인하기가 쉽지 않다.
- Extrinsic
- 실제 태스크 (예,텍스트 분류, 단어 유추 등) 에 적용하여 평가하는 방법으로, 시간이 오래 소요될 수 있다.
- 이 때, 성능을 평가할 때 word embedding 자체가 문제인지, 다른 요인이 영향을 미친 것인지 확인하기가 어렵다.
- 다른 부분은 고정하고 word embedding 만 바꾸어서 메트릭이 향상되는지 확인하는 방법을 사용한다. 이 방법은 다른 graph embedding 등에서도 활용되는 방법이다.
2) Graph Embeddings
그래프는 엔티티의 네트워크 및 엔티티간 연결을 의미한다. 사람들 간의 상호 작용이나 지도 데이터 간 관계 등을 표현하는 데에 사용하며, 상호 엔티티 간의 관계를 표현하기에 적합한 방법이다. Knowledge graph, 추천 시스템, word embeddings 등도 그래프로 표현될 수 있다.
- 그래프 내에서 관계성을 가지는 엔티티(노드)를 숫자로 구성된 벡터로 변환하는 것을 그래프 임베딩 (Graph Embedding) 이라고 한다. (연결된 노드들은 비슷한 임베딩을 가짐)
- 그래프 임베딩은 비지도학습의 형태
- Task-agnostic 엔티티로 표현되며, feature 는 적은 데이터로 다운스트림 태스크에 활용될 수 있음
- 엔티티 (노드) 의 이웃은 의미론적으로 중요성을 가짐
- 대표적으로 PyTorch BigGraph 로 구현
multi-relation graph
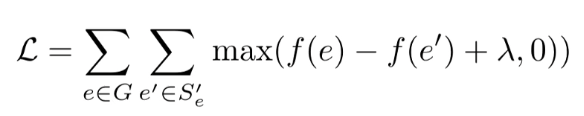
- edge 와 negative sampled edge 간 Margin Loss 최소화하는 것이 목표 (word embedding 에서 Collobert & Weston vectors 와 유사함)
- edge score : source embedding과 destination embeddig 간의 유사도 (유사도는 두 벡터 간 dot product 또는 cos)
- negative sample () : 실제 edge 의 source 또는 destination 노드를 랜덤 노드로 대체하여 실제로는 연결 (edge) 가 없지만 fake edge 를 만드는 방법 (워드 임베딩에서 하는 방법과 유사함)
- fake edge 점수를 계산하는 데에 학습 시간이 많이 걸리므로 최적화가 필요하다.
- 배치 트레이닝을 할 때 샘플링을 다시 하지 않고, 동일한 세트의 엣지를 재사용 => 메모리 액세스를 줄여서 효율을 높임.
- similarity 를 dot product 로 계산하면, negative score 의 배치는 matrix multiply 로 계산될 수 있어 효율적임
- fake edge 점수를 계산하는 데에 학습 시간이 많이 걸리므로 최적화가 필요하다.
관련 논문
PyTorch-BigGraph: A Large-scale Graph Embedding System , Adam Lerer et al.
3) 적용하기
임베딩은 다양한 영역에 적용할 수 있는데, 그 중 소셜 미디어에서 활용되는 TagSpace 와 PageSpace 를 살펴본다.
StarSpace : https://github.com/facebookresearch/StarSpace
- TagSpace
- 소셜 미디어 포스팅에서 주어진 텍스트(문장) 기반으로 해시태그를 인퍼런스 (해시태그에 대한 별도 명시 없이 텍스트에서 해시태그를 추론)
- word2vec 임베딩과 유사
- [word] --> [hashtag] 단어와 해시태그 간을 엣지로 연결
- 임베딩을 통해 소셜 미디어 포스팅을 라벨링하거나 해시태크 별 클러스터링 하는 데에 사용
- PageSpace
- [user] --> [page]
- 소셜미디어 (예, 페이스북)에서 사용자와 페이지 (예, 맛집, 조직, 그룹 등) 간의 관계를 임베딩으로 표현
- 페이지 클러스터링 또는 사용자에게 페이지를 추천할 때 활용
- 예를 들어, 뉴욕타임즈 페이지의 nearest neighbor 를 찾는다?
- 근접 노드의 similarity score 계산
- Faiss : A Library for efficient similarity search and clustering of dense vectors
- VideoSpace
- 소셜 미디어 페이지에 포스팅 된 동영상에 대한 representation
- Lookup table 과 Word embedding 을 통해 동영상의 제목, 설명에 있는 단어들을 text representation 으로 변환
- 비디오의 이미지를 CNN - video embedding 을 통해 변환
- 이 모든 embedding feature 들이 MLP 레이어에 피딩됨
=> 비디오 분류에 활용
4) Embed everything into vector space : world2vec
앞서 VideoSpace 에서 봤던 것 처럼, 서로 다른 행동 데이터, 컨텐츠 데이터가 복합적으로 태스크에 활용될 수 있음을 살펴보았다. 그렇다면 모든 데이터를 vector space 에 임베딩 하면 어떨까? 이것이 world2vec 의 아이디어이다.
- 페이스북 - 사용자, 그룹, 페이지, 포스트, 토픽 등 서로 다른 엔티티를 하나의 vector space 에 임베딩함으로써 다양한 문제를 풀 수 있다. (예, 사용자의 behaviroal feature 를 기반으로 엔티티를 임베딩)
- 사용자가 어떤 토픽에 관심이 있는지? 컨텐츠 추천? 사용자 계정이 가짜 계정인지, 스팸 페이지 분류 등
- Behavioral graph 를 기반으로 그래프 임베딩을 통해 벡터로 변환한 후 모델을 추가하거나 다른 feature 들을 추가하여 다운스트림 태스크에 적용 (e.g. ranking, classfiication, visualization, clustering, nearest neighbor)
- 거대 임베딩 모델을 트레이닝 하는 방법
- Preprocessing => Pytorch-BigGraph workflow => Downstream 적용
그래프 임베딩 알고리즘이 큰 규모의 그래프를 핸들링하는 방법
- matrix blocking 을 사용해 그래프를 파티셔닝
- 노드를 N 개 샤딩으로 균일하게 나눔
- 노드 간의 엣지는 개의 버킷에 나뉘어 담김 (source, destination 노드에 따라)
- 한 번에 한 개의 chunk 를 핸들링
- 단일 머신 : 두개 파티션만 메모리에 저장되며 나머지는 디스크에 스왑핑
- 분산 트레이닝 : 모델 파라미터를 sync 할 필요 없이 disjoint partition 이 있는 버킷이 동시에 학습되므로, 모델을 여러 대의 머신에서 병렬적으로 학습하여 효율을 높일 수 있다. 학습 과정에서 여러 오퍼레이션이 일어나는데, 대표적으로는 버킷 접근을 synchroinize하거나, 버킷 트레이닝한 이후 예측값을 교환하거나, 머신 간 파라미터 공유 (관계 종류에 대한 파라미터 - 공유 파일 시스템에 저장) 하는 작업들이 있다. 이 때, 학습하는 거대 임베딩 테이블에 비해 공유하는 파라미터 수는 매우 작기 때문에, 성능은 머신의 수에 비례한다고 볼 수 있다.
5) Hyperbolic embeddings
Poincaré Embeddings for Learning Hierarchical Representations
- 엔티티를 하이퍼볼릭 스페이스에 임베딩함으로써 Hierarchical representation 을 학습
- 아래 이미지에서, 일반적인 카테고리의 엔티티 (e.g. Entity) 는 중앙에 위치하고, 구체적인 엔티티일 수록 바깥 쪽에 위치
- similarity measurement 를 통해 계층 관계를 확인할 수 있으며, 계층구조를 2차원의 hyperbolic space 에 임베딩함으로써 차원 감소
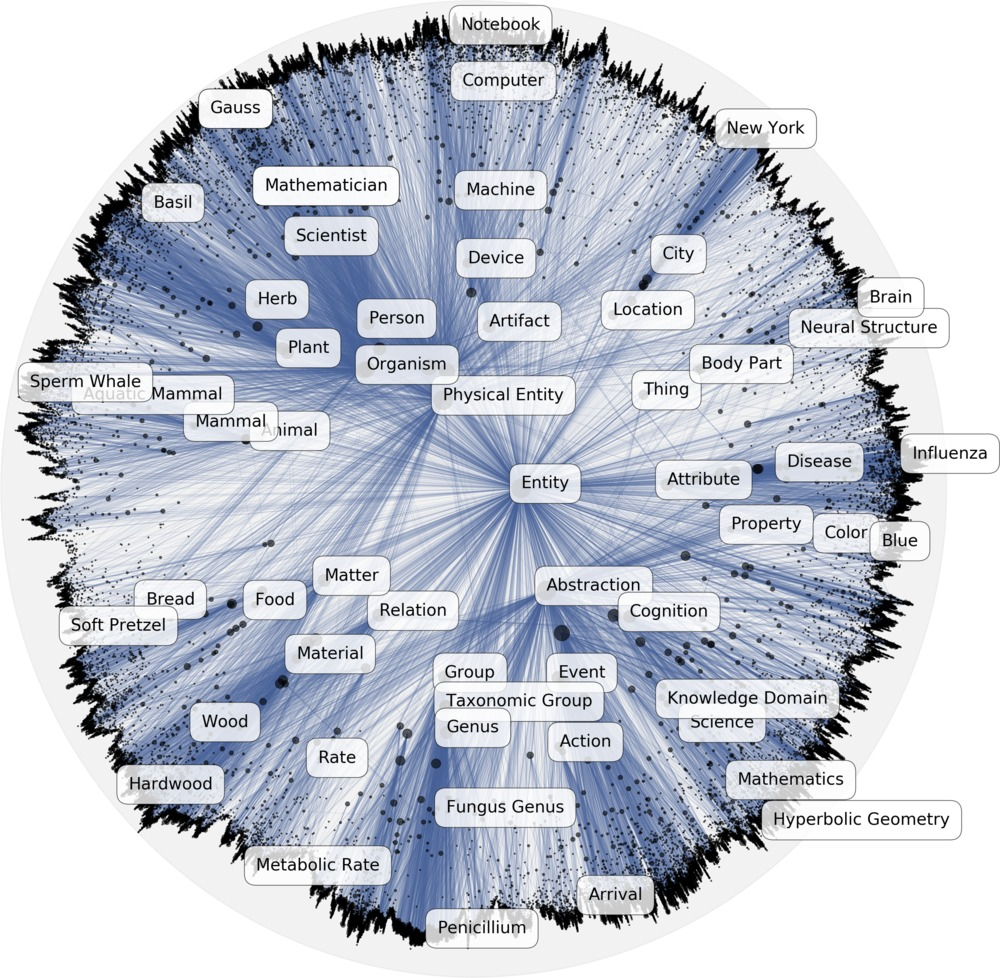
이미지 출처 : https://github.com/facebookresearch/poincare-embeddings
6) Bias
Word Embeddings 에서 추가로 생각해보야 할 영역은 Bias 이다. Bias 는 1. 학습하는 Dataset 자체로부터 발생할 수도 있으며, 2. 머신러닝의 과정을 통해 기존의 bias 가 증폭될 수도 있다.
Bias 를 제거하기 위해 (Debiasing), bias 가 있는 subspace 에 대해 projection, subtraction 등의 가공을 할 수 있으나 bias 가 특정 단어에만 국한된 것은 아니므로 실제로 bias 를 지우는 작업을 하기는 쉽지 않다. NLP 모델에서의 bias 를 해결하고 fairness 를 지켜가는 영역은 반드시 고려되어야 할 대상이며, 추후 알아볼 예정이다.
