
이번포스트에서는 파이썬의 병렬실행과 함께 병렬테스트 시에 어떤 방법이 있을지 정리해봅니다.
프로세스와 쓰레드
먼저 본론으로 들어가기 전에 프로세스와 쓰레드에 대해 간략하게 정리를 하자면..
프로세스
프로그램은 일반적으로 하드 디스크 등에 저장되어 있는 실행코드를 뜻하고, 프로세스는 프로그램을 구동하여 프로그램 자체와 프로그램의 상태가 메모리 상에서 실행되는 작업 단위를 지칭한다. 예를 들어, 하나의 프로그램을 여러 번 구동하면 여러 개의 프로세스가 메모리 상에서 실행된다.
https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
프로세스는 프로그램이 실행되는 하나의 단위라고 할 수 있습니다. 프로그램은 보조기억장치에 저장되어있다가, OS(사용자)에 의해 프로그램이 실행되기 시작하면, 주기억장치로 올라와 CPU에 의해 처리되기 시작합니다. 이 때 처리되는 단위를 프로세스 라고 합니다.
쓰레드
스레드(thread)는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다. 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이러한 실행 방식을 멀티스레드(multithread)라고 한다.
https://ko.wikipedia.org/wiki/%EC%8A%A4%EB%A0%88%EB%93%9C_(%EC%BB%B4%ED%93%A8%ED%8C%85)
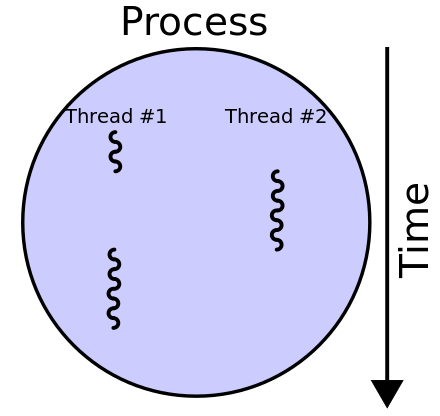
쓰레드는 프로세스 내부에서 실행되는 하나의 작업 단위를 말합니다. 보통 프로세스는 싱글 쓰레드(하나의 작업단위)이나, 하나 이상의 쓰레드로 실행되는 쓰레드끼리 프로세스의 자원을 공유합니다.
이 쓰레드끼리 프로세스의 자원을 공유하는 내용이, 본 포스팅의 핵심 내용입니다.
파이썬에서의 병렬 실행
많은 책이나 블로그, 유튜브에서 파이썬의 병렬실행에 대해서는 멀티프로세싱으로 처리하면 된다고만 하지 사실 왜 그렇게해야하는지까지 말해주는 부분은 잘 없습니다. 많은 프로그래밍 언어 입문 서적에서, Java라면 네트워크 처리나 병렬 프로그래밍에 대해서 기재해주기도 하는데 유독 파이썬만큼은 병렬프로그래밍에 대해서 기재해주는 책이 잘 없더라구요.
파이썬에서는 threading 모듈을 이용해서 쓰레드를 구현할 수는 있지만, 실제 처리속도에 있어서는 외부 인터페이스나 네트워크 처리 등의 I/O 처리가 많이 발생하지 않는 한 쓰레드를 이용해서 병렬실행을 구현하던 안하던 차이는 없다고 합니다. (I/O등으로 CPU가 idle 상태가 발생하는 경우라면 의미있지만 그렇지 않으면 쓰레드처리가 제대로 되지 않는다는 의미)
https://monkey3199.github.io/develop/python/2018/12/04/python-pararrel.html
그래서 제대로 된 병렬 실행을 하려면multiprocessing 모듈을 사용해서 구현을 해야한다고 하네요. 근데 그러면 쓰레드처리는 모듈로 지원하면서 제대로 동작하지않고, 굳이 멀티프로세싱처리를 해줘야하는 것일까요?
Python Global Interpreter Lock과 Garbage collector
그것은 파이썬이 만들어질 초창기부터 있었던 구조인, Global Interpreter Lock과 관련되어있습니다.
우선 이것을 설명하기 전에, 파이썬에서의 가비지컬렉터에 대해 알아야합니다.
Garbage Collector
쓰레기 수집 (garbage collection 가비지 컬렉션, GC)은 메모리 관리 기법 중의 하나로, 프로그램이 동적으로 할당했던 메모리 영역 중에서 필요없게 된 영역을 해제하는 기능이다. 영어를 그대로 읽어 가비지 컬렉션이라 부르기도 한다. 1959년 무렵 리스프의 문제를 해결하기 위해 존 매카시가 개발하였다.
쓰레기 수집은 동적 할당된 메모리 영역 가운데 더 이상 사용할 수 없게 된 영역을 탐지하여 자동으로 해제하는 기법이다. 더 이상 사용할 수 없게 된 영역이란, 어떤 변수도 가리키지 않게 된 영역을 의미한다.
자바, C#, 그리고 일부 스크립트 언어들은 처음부터 쓰레기 수집 기법을 염두에 두고 설계되어, 언어 정의에 쓰레기 수집이 포함되어 있다. C, C++ 등의 프로그래밍 언어는 수동 메모리 관리를 가정하고 설계되었으나, 쓰레기 수집을 지원하는 구현도 존재한다. D와 같은 어떤 언어들은 쓰레기 수집을 지원하지만, 필요에 따라 쓰레기 수집을 하지 않고 수동으로 메모리를 관리할 수 있다.
가비지컬렉터는 더이상 사용되지 않는 변수에 대해, 메모리를 해제하는 기능을 합니다. 파이썬의 인터프리터인 CPython은, 동적변수에 대해 참조되는 횟수를 계산하는 방식으로 GC가 구현되어있다고 합니다.
참조 횟수 계산 방식
일부 쓰레기 수집 기법은 참조 횟수 계산 방식을 사용한다. 참조 횟수 계산 방식은 각 객체에서 참조 횟수를 기억하여, 참조 횟수가 0이 되면 해당 객체를 해제하는 방식을 가리킨다. 파이썬 표준 구현인 CPython에서 이 방식을 사용한다. C++에서는 스마트 포인터라는 특수한 객체를 이용해 이 기법을 구현할 수 있다.참조 횟수 계산 방식은 다음과 같은 장점을 가지고 있다.
객체가 접근 불가능해지는 즉시 메모리가 해제되므로, 프로그래머가 객체의 해제 시점을 어느 정도 예측할 수 있다.
객체가 사용된 직후에 메모리를 해제하므로, 메모리 해제 시점에 해당 객체는 캐시에 저장되어 있을 확률이 높다. 따라서 메모리 해제가 빠르게 이루어진다.
위와 같은 장점 때문에, 참조 횟수 계산 방식은 메모리 관리 뿐 아니라 다른 자원 할당 기법에도 종종 사용된다. 예를 들어 하드 디스크 블록의 할당과 해제를 담당하는 파일시스템의 경우, 포인터 추적 방식의 쓰레기 수집은 디스크라는 매체의 특성 상 오랜 시간을 소모하게 된다. 그러나 참조 횟수 계산 방식은 할당된 블록을 해제하는 시점에 해당 블록을 가리키는 포인터가 운영체제의 버퍼에 로딩되어 있으므로, 빠르게 블록을 해제할 수 있다.반면 참조 횟수 계산 방식에는 다음과 같은 단점이 있다.
두개 이상의 객체가 서로를 가리키고 있을 경우, 참조 횟수가 0이 되지 않게 된다. 이를 순환 참조라고 하며, 메모리 누수의 원인이 된다. CPython은 이 문제를 해결하기 위해 순환 참조를 감지하는 알고리즘을 사용한다. 또한 자료구조에서 약한 참조(참조 횟수를 증가시키지 않는 포인터)를 사용하여 이 문제를 해결할 수도 있다.
멀티스레드 환경에서는, 스레드간에 공유하는 객체의 참조 횟수 계산을 위해 원자적 명령을 사용하거나 락을 걸어야 한다. 이 문제를 회피하기 위해 스레드 단위 지역 변수로 참조 횟수를 따로 관리하면서, 스레드의 참조 횟수가 0이 될때만 전역 참조 횟수를 확인하는 방식을 사용할 수 있다. 리눅스 커널에서 이 방식을 사용한다.
참조 횟수가 0이 될때, 해당 객체가 가리키는 다른 객체들 또한 동시에 0으로 만드는 작업이 일어난다. 이 과정은 경우에 따라 많은 시간이 걸릴 수도 있기 때문에 실시간 시스템에는 적합하지 않을 수 있다.
여기서, 멀티스레드 환경에서는 스레드 간에 공유하는 객체의 참조횟수 계산을 위해, 원자적 명령을 사용하거나 락을 걸어야한다고 기술되어있는데요, 이 기술이 바로 Global Interpreter Lock 입니다.
Global Interpreter Lock
A global interpreter lock (GIL) is a mechanism used in computer-language interpreters to synchronize the execution of threads so that only one native thread (per process) can execute at a time. An interpreter that uses GIL always allows exactly one thread to execute at a time, even if run on a multi-core processor. Some popular interpreters that have GIL are CPython and Ruby MRI.
GIL은 한 프로세스 당 무조건 하나의 스레드만 실행하도록 제한하여서, 어떠한 공유자원에 대한 Race condition이 발생하는 것을 막고, GC실행에 문제가 없도록 합니다.
이 GIL때문에 파이썬에서 threading 모듈을 사용해도 실행 속도에서 큰 차이가 없는 것이고, 이 GIL때문에 multiprocessing 모듈을 이용하여 멀티프로세싱 처리를 염두를 한 구현을 해야하고 & 실행해야합니다.
Pytest를 이용한 테스트코드 실행 시의 병렬 실행
이제 본론인, pytest를 통해 테스트를 수행할 때의 병렬실행에 대해서 알아봅니다. 테스트 코드를 병렬실행해서 여러개의 코드를 한 번에 실행하는 방법입니다.
하나의 테스트에 대해 한 번에 여러번을 실행할 수 있고, 모든 실행대상 테스트에 대해서 병렬실행기의 갯수 n개로 나누어서 전체 실행속도를 빠르게 단축시킬 수도 있습니다.
일단, 이번 포스트에서는 pytest를 이용한 테스트 코드도 프로세스로 처리되는 것을 확인해보고자합니다.
Pytest-xdist
pytest에서 병렬실행을 하기위해서는 pytest-xdist 라는, pytest의 플러그인 성격의 라이브러리를 설치해줍니다.
pip3 install pytest-xdist
https://pytest-xdist.readthedocs.io/en/stable/#
실행은 아래와 같습니다.
pytest -n auto
auto 를 입력하면, 실행가능한 CPU의 최대 코어수로 테스트를 실행하고, 숫자를 입력하면 그만큼의 프로세스를 띄워 실행합니다.
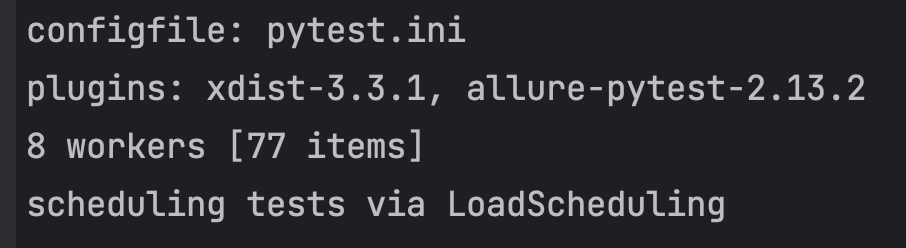
저의 경우에는 8코어 CPU라, 8개의 worker가 실행되었고 전체 테스트케이스 갯수에 대해 워커 갯수로 나누어서 병렬실행되었습니다.

이렇게 하나의 프로세스에 대해, 동일한 부모프로세스아이디를 가진 프로세스들이 추가로 생성되는 것을 ps 커맨드를 통해 확인할 수 있었습니다.
끝!
ref
