1) AI model 에 대한 설명 및 문제선정이유,
-1) AI model
Kaggle 7가지 감정 분류를 통한 긍정적/부정적 감정에 대한 classification 성능 확인
-2) 문제선정이유
인간의 감정에는 많은 feature들이 있다, 예를 들어, 화난 경우 눈썹을 찡그리거나, 눈을 반즘 감는 모션을
하고, surprise의 경우 눈을 크게 뜨거나, 입을 벌리는 경우가 있다.
우리는 epoch 수에 따른 모델성능 비교와 함께, 부정적인 감정의 class가 4개, 중립 감정의 class 1개, 긍정
적인 감정의 class가 2개로, 부정적인 감정에 대한 data가 많을때 부정적인 감정의 세부 감정들을 표현하는
것이 어렵다라고 전제로 검증하는 모델학습을 한다. 이를 검증하기 위해, 모든 class에 대한 Accuracy를 확인
하고, training set과 test set의 목적함수(loss function)의 결과값을 그래프로 확인하면서 비교해보았다.
2) 학습을 위한 영상데이터 수집방법,
표정에는 다양한 특징들을 가지고 있기에, 많은 데이터들을 학습시켜, 특징에 대한 추출이 필요하다. 따라서 kaggle에 있는 표정 이미지에 대한 data set을 다운로드 받아, 총 7개의 class를 나누어 각각 400개씩 데이터 학습을 진행하였다. 또한 이미지의 경우 컬러이미지가 아닌 흑백이미지를 통해 contrast를 비교할 것이며, 각 데이터에는 아래와 같은 happy class의 정확한 사진도 있지만,

아래 사진과 같이 사람이 인식하기에 표정에서 happy class에 포함되어야하는가 에 대한 이슈가 조금씩 있다.

kaggle data set: https://www.kaggle.com/datasets/jonathanoheix/face-expression-recognition-dataset
- data set(sample 중 85% : training data, 15% : test data)
| class | dataset num(training(85%)+ test(15%)) |
|---|---|
| happy | 400(340 + 60) |
| sad | 400(340 + 60) |
| angry | 400(340 + 60) |
| fear | 400(340 + 60) |
| disgust | 400(340 + 60) |
| surpise | 400(340 + 60) |
| neutral | 400(340 + 60) |
- test data set ( stable diffusion model AI로 만든 이미지 데이터) Show an image of a person with an “emotion” expression ex) Show an image of a person with an surprised expression
class data num happy 1 sad 1 angry 1 fear 1 disgust 1 surpise 1 neutral 1
3) 학습을 진행한 과정
학습을 하기 위한 모델의 epoch를 비교하여 2개의 모델을 생성하였다. 모델의 epoch 및 batch size는 아래와 같다.
- 1번 방법 : (default) epoch : 50, batch size : 16, 학습률 : 0.001
- 2번 방법 : epoch : 100, batch size : 16, 학습률 : 0.001
4) 생성AI로 만든 이미지에 대한 각 클래스별 예측결과
-
1번 방법 : epoch : 50, batch size : 16, 학습률 : 0.001
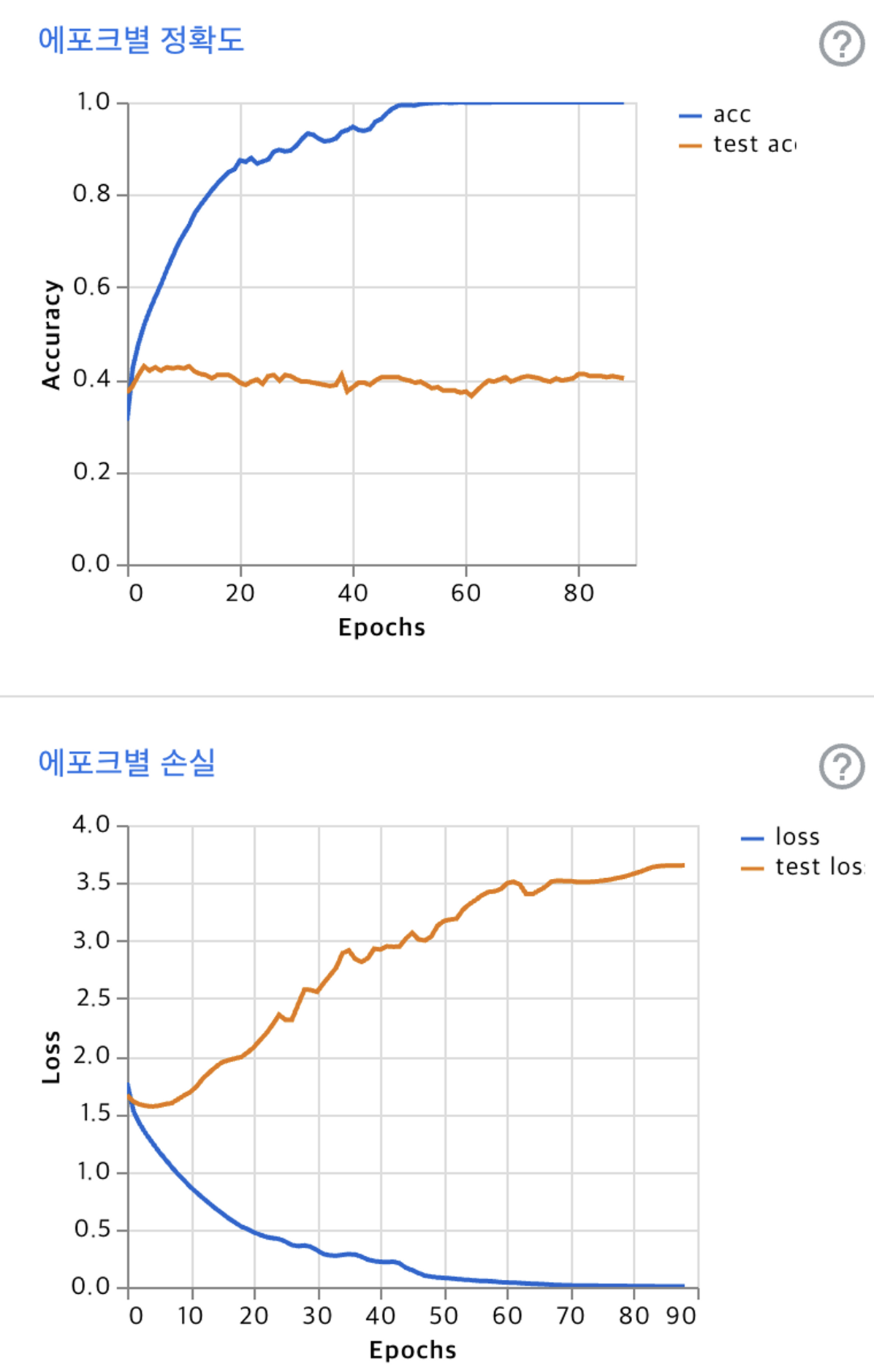
test를 거칠수록 object function의 결과값(손실)이 커지는 것을 알 수 있다 → 정확도가 낮다.
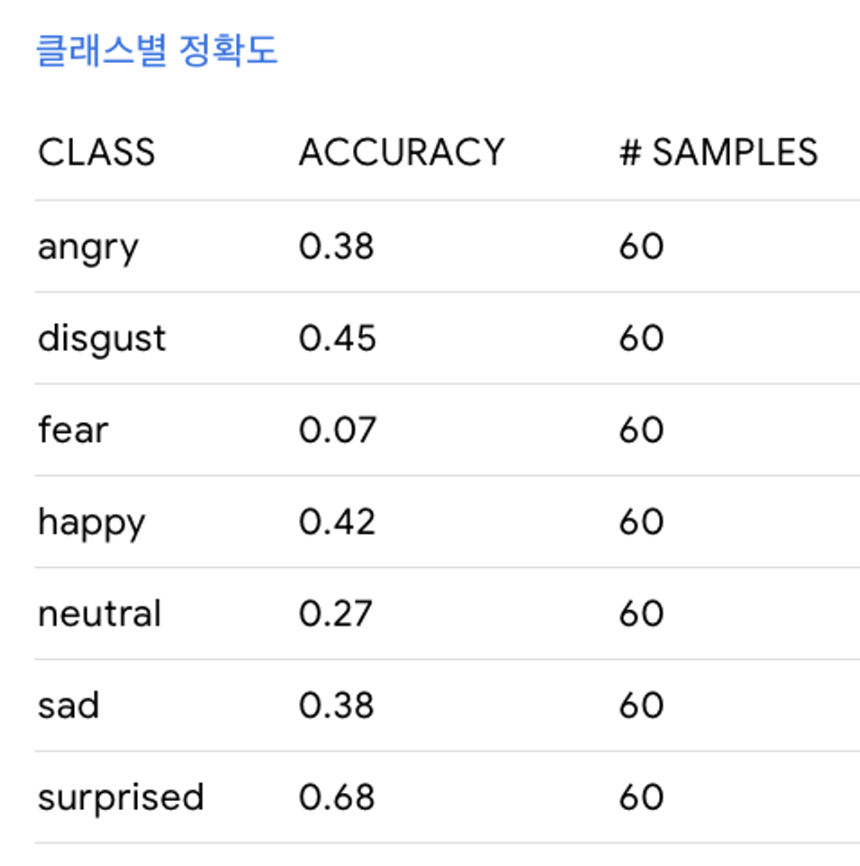
💡 정확도 : surprise → — → sad → — → fear
- 가장낮은것 (test data : fear image)
- 가장낮은것 (test data : fear image)
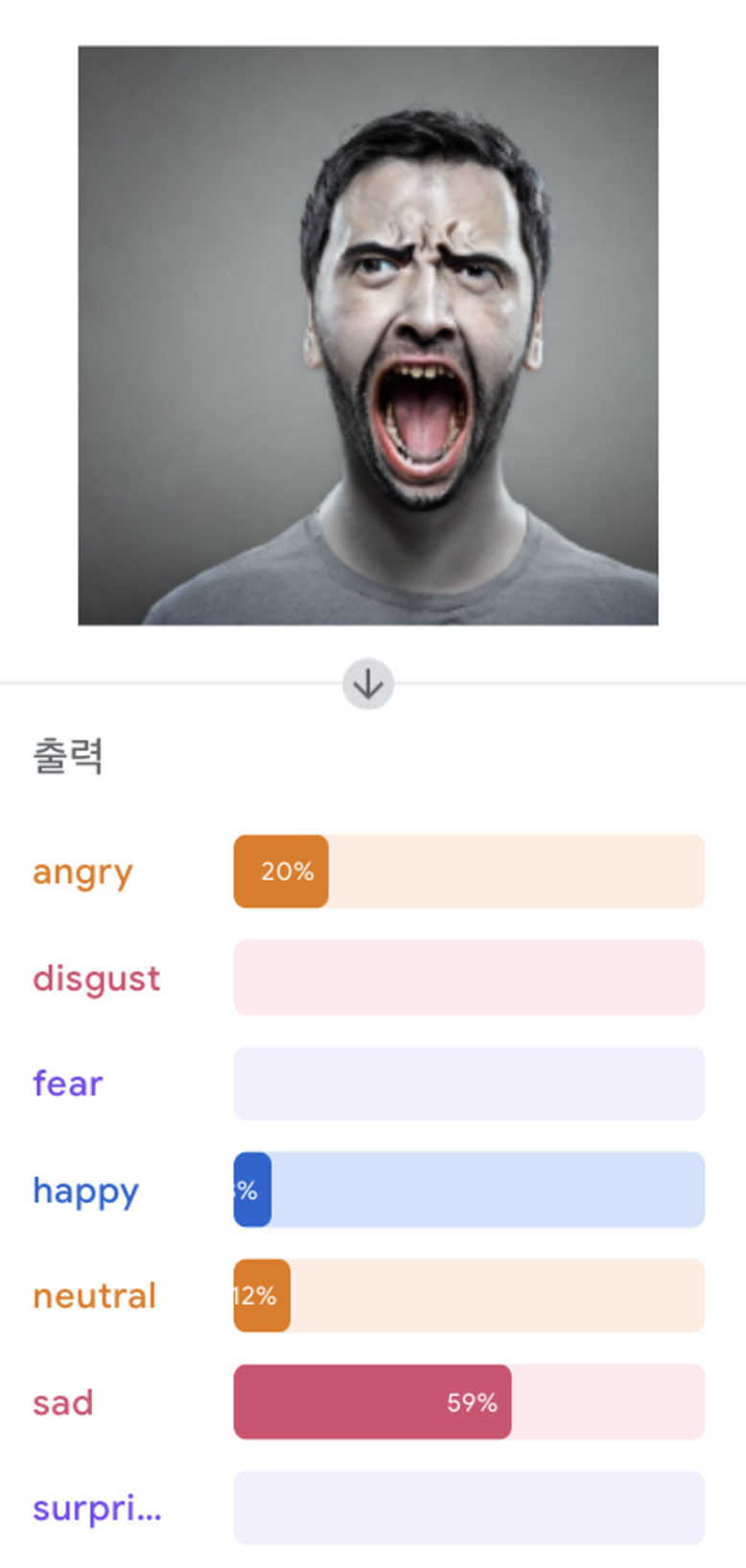
💡 fear에 대한 감정을 분류하지 못했다.
-
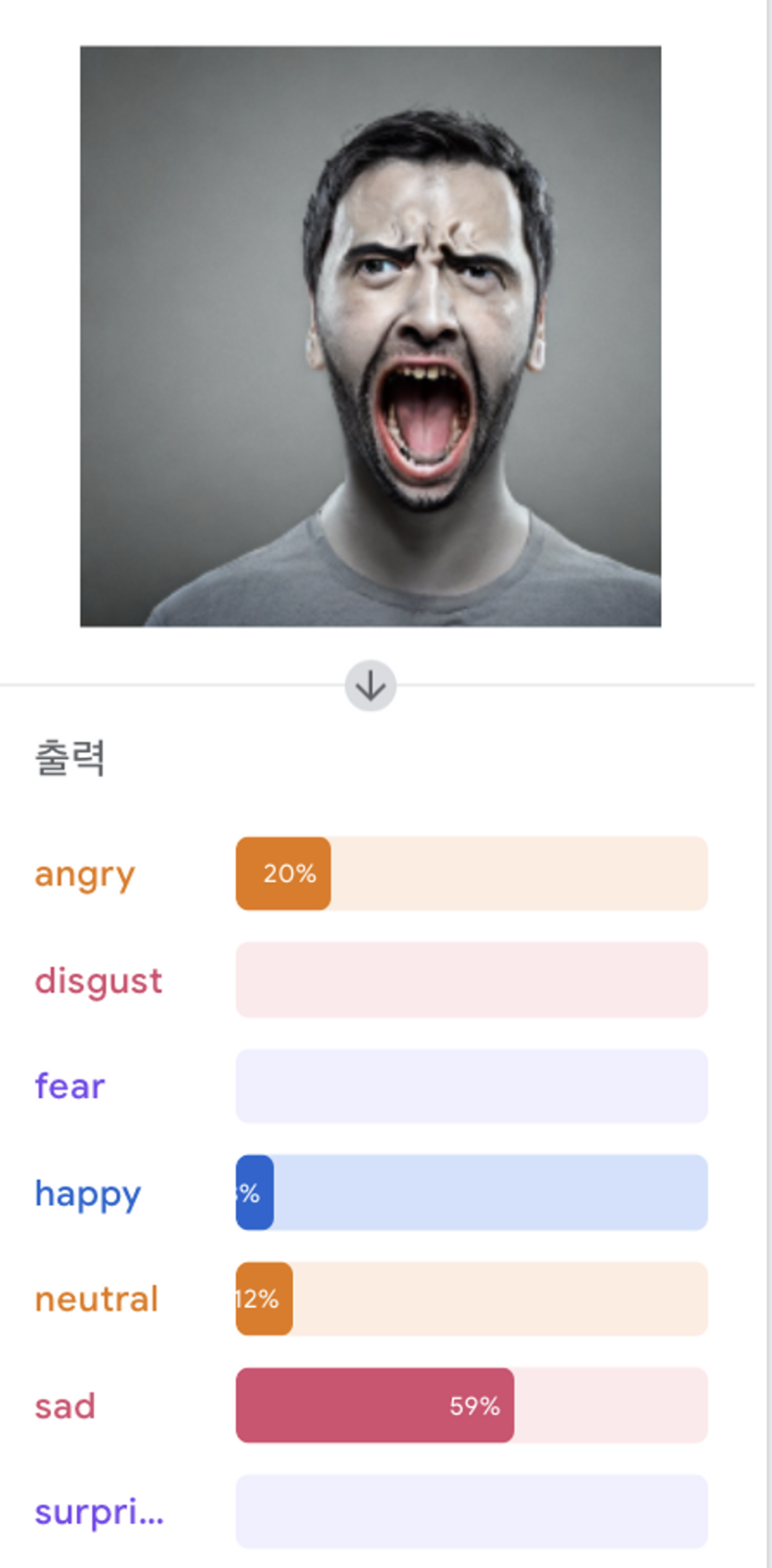
가장 높은 것 (test data : surprised image)
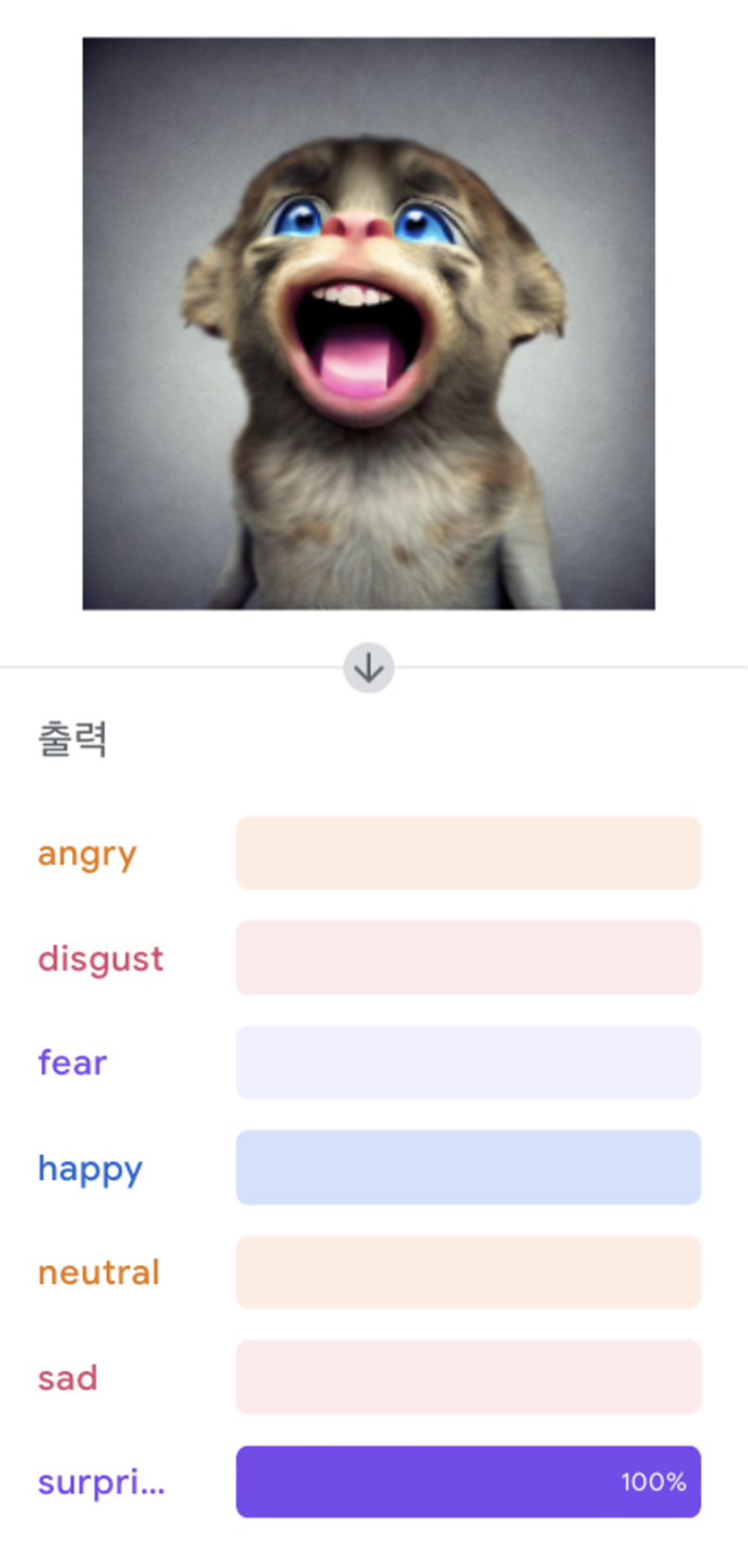
-
2번 방법 : epoch : 100, batch size : 16, 학습률 : 0.001
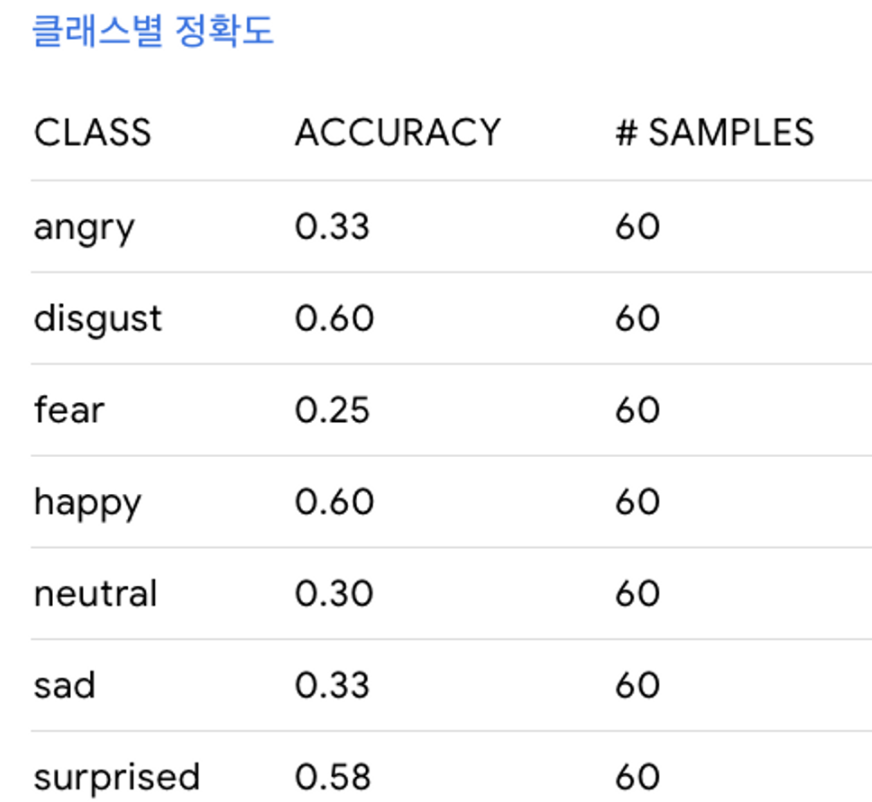
test를 거칠수록 object function의 결과값(손실)이 커지는 것을 알 수 있다 → test set에 대한 정확도가 낮다.
💡 성능 좋은 분류 : disgust = happy, surprised > sad > fear
-
가장 낮은 것(test data : fear image)
화난 것은 잘 알기 어려운 감정이라는 것을 확인할 수 있다.
- 가장 높은 것(test data : happy image)
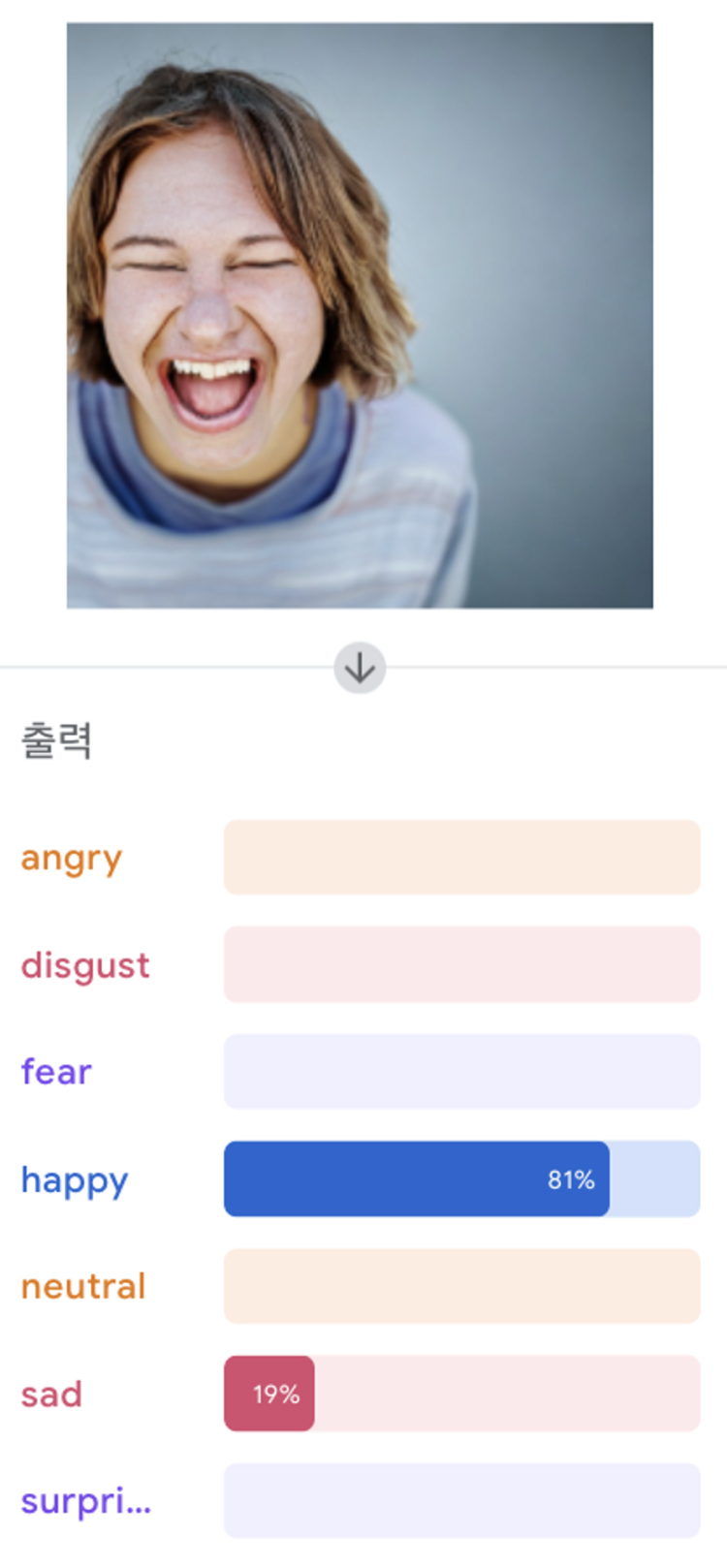
- 가장 높은 것(test data : happy image)
5) 결과에 대한 분석 - 잘못 예측한 경우 원인분석
-
epoch 개수에 따른 예측 성능 결과
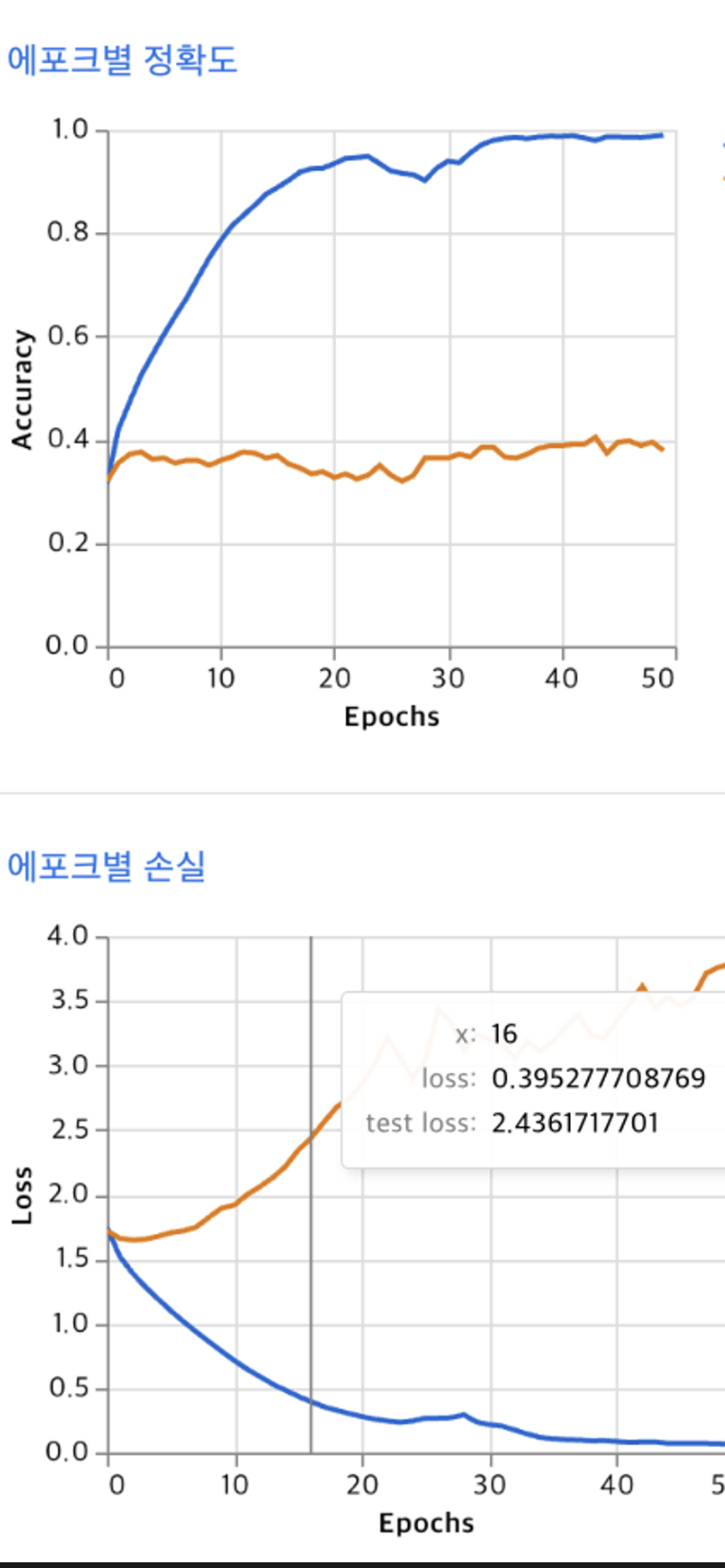
1번 방법
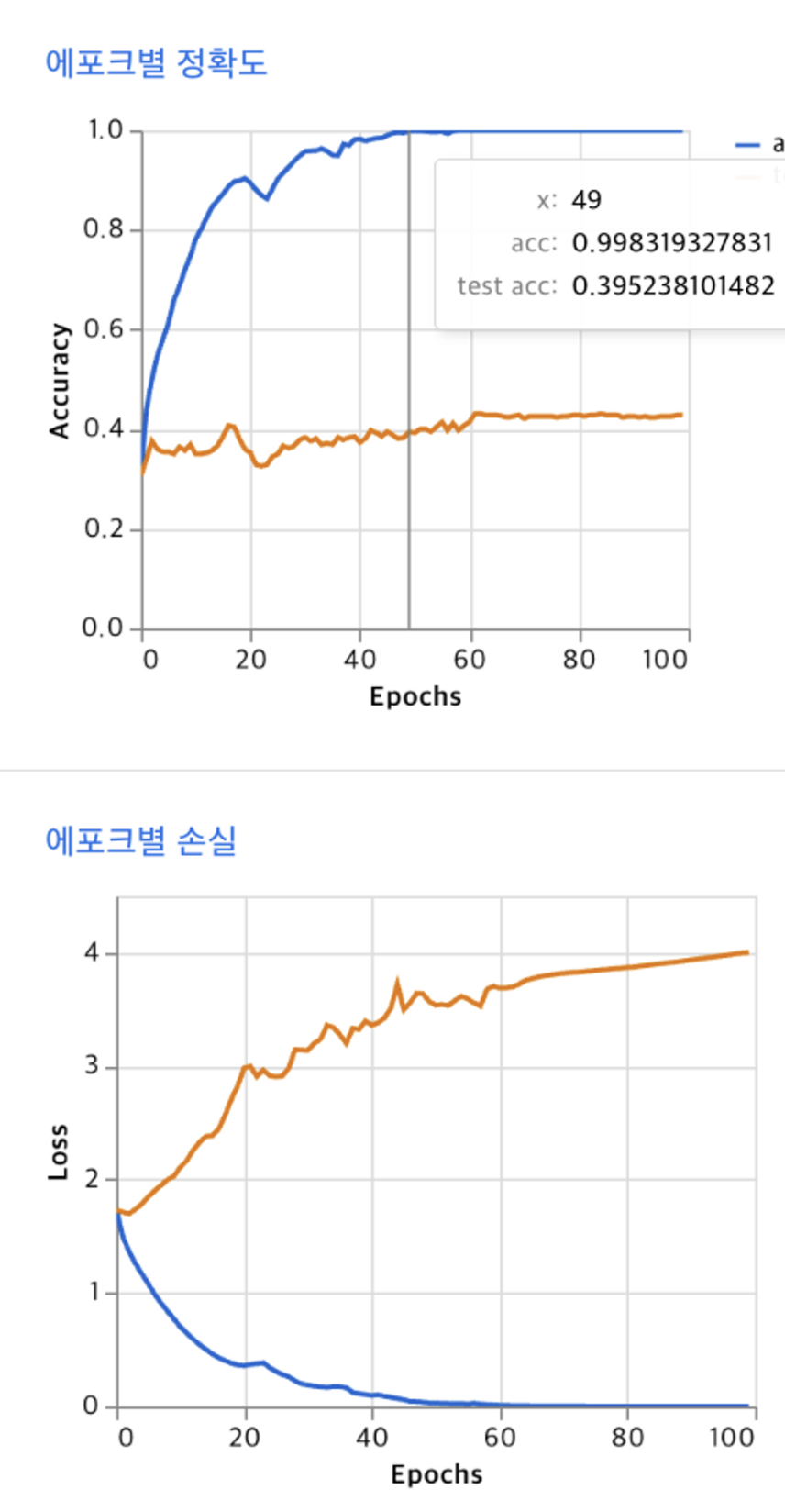
2번 방법
epoch를 2배늘렸을때 test data set에서 정확도가 조금 증가한 것을 볼 수 있음, 하지만 training set에서는 epoch 50회 정도부터 비슷한 성능이 나옴(=같은 데이터셋이기 때문에 50번까지는 비슷하거나 같은 그래프 양상을 그림)
- overfitting 문제(과적합) 모델이 지나치게 training data와 유사하게 분류해, 테스트 샘플에 대해 정확히 분류하지 못하는 경우가 있는 것 같음. 따라서 test 데이터 셋에 대한 정확도 및 loss에 대한 평가가 좋지 못함
- 부정적인 감정( sad, angry, fear, disgust)이 중립 및 긍정적인 감정(happy,surprise, neutral)보다 많은 class를 가지고 있어 부정적인 감정의 특징을 구분하기가 어려워하는 것으로 보임, → 부정적인 감정과 중립 및 긍정적인 감정에 대한 3가지 클래스로 분류하여 검증한다면, 구체적이진 못하지만, 확실한 평가가 나올 것으로 예상됨
