0️⃣ 서론
이전에 검색 기능을 QueryDSL로 변경하면서, 검색 기능이 무한 스크롤을 적용하고 있어서 반환값을 Slice로 반환해줘야 했습니다!
위의 블로그 글에서는 QueryDSL에서 Slice의 로직을 사용해서 잘 적용하고 있습니다.
그러나, QueryDSL을 사용하는 초기에는 Slice의 값으로 반환하지만, Page를 사용해서 하는 로직으로 하고 있었습니다.
즉, Slice와 Page 사용방법을 혼동하여 로직은 Page이지만 반환값은 Slice인 혼합된 코드가 되어버렸습니다.
@Override
public Slice<Scrap> searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword,
Pageable pageable) {
List<Scrap> contents = queryFactory
.selectFrom(scrap)
.where(
scrap.user.eq(user)
.and(scrap.deletedDate.isNull())
.and(scrap.title.containsIgnoreCase(keyword)
.or(scrap.description.containsIgnoreCase(keyword)))
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(scrap.createdDate.desc())
.fetch();
JPAQuery<Long> count = queryFactory.query()
.from(scrap)
.select(scrap.count())
.where(scrap.user.eq(user));
return PageableExecutionUtils.getPage(contents, pageable, count::fetchOne);
}그 이유는 QueryDSL을 사용하면서, Slice에 대한 작동 원리 등을 정확하게 고려하지 않았기 때문이었습니다.
Slice<Scrap> scrapSlice = scrapRepository.findAllByUserAndDeletedDateIsNullAndTitleContainingIgnoreCaseOrDescriptionContainingIgnoreCase(user, keyword, keyword, pageRequest)따라서 이번 기회에 Slice와 Page의 차이점을 명확하게 파악하여 무한 스크롤 기능을 구현해보겠습니다!!
1️⃣ 본론
1. Pagination vs 무한 스크롤
1-1. Pagination
페이지네이션은 페이지 단위로 분할하는 방법입니다.
즉, 아래의 사진과 같이 웹 사이트 내에서 보려는 목록이 많은 경우 페이지 단위로 분할하여 사용자가 필요한 부분만 볼 수 있도록 도와줍니다.

이미지 출처 : 네이버 검색 페이지 결과 일부
1-2. Infinite Scroll
무한 스크롤은 스크롤을 내릴때마다, 새로운 컨텐츠가 계속해서 로드되는 방식입니다.
흔히 인스타그램에서 피드를 보기 위해서 계속해서 내리면 새로운 컨텐츠가 나오는 형식입니다.
2. Page vs Slice
Spring Data JPA에서는 Pagination을 위한 두 가지의 객체인 Page와 Slice를 제공합니다.
Page와 Slice에 공통적으로 필요한 정보가 있습니다.
- page : 페이지 번호
- size : 한 페이지에 불러올 데이터 건수
- sort : 정렬 조건
Pageable의 구현체인 PageRequest를 통해서 page, size, sort를 입력받음을 알 수 있습니다.
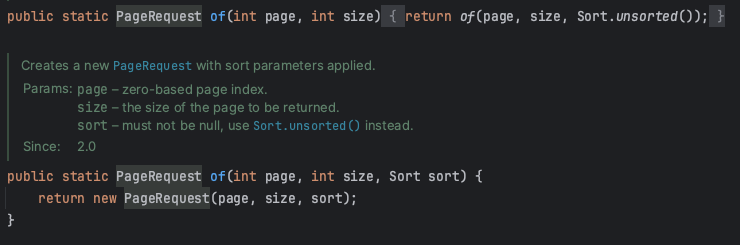
아래의 저희 프로젝트의 스크랩 Controller 중 스크랩 조회 메소드에서 Pageable은 Pagination을 위한 정보를 저장하는 객체입니다.
@GetMapping("/v1/scraps")
public ApiResponse<Slice<GetScrapResponse>> getScraps(Pageable pageable,
Authentication authentication) {
String email = authentication.getName();
return ApiResponse.success(scrapService.getScraps(email, pageable));
}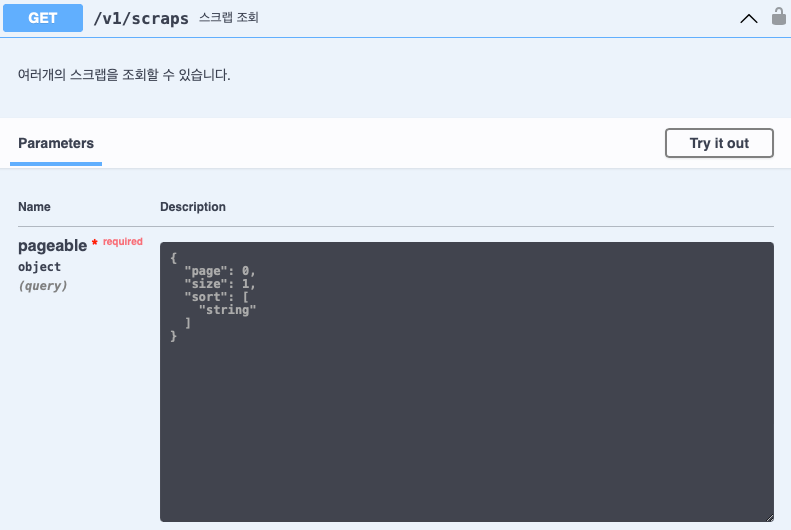
위의 그림처럼 Swagger에서 Pageable이라는 객체의 page, size, sort를 입력받습니다.
2-1. Slice

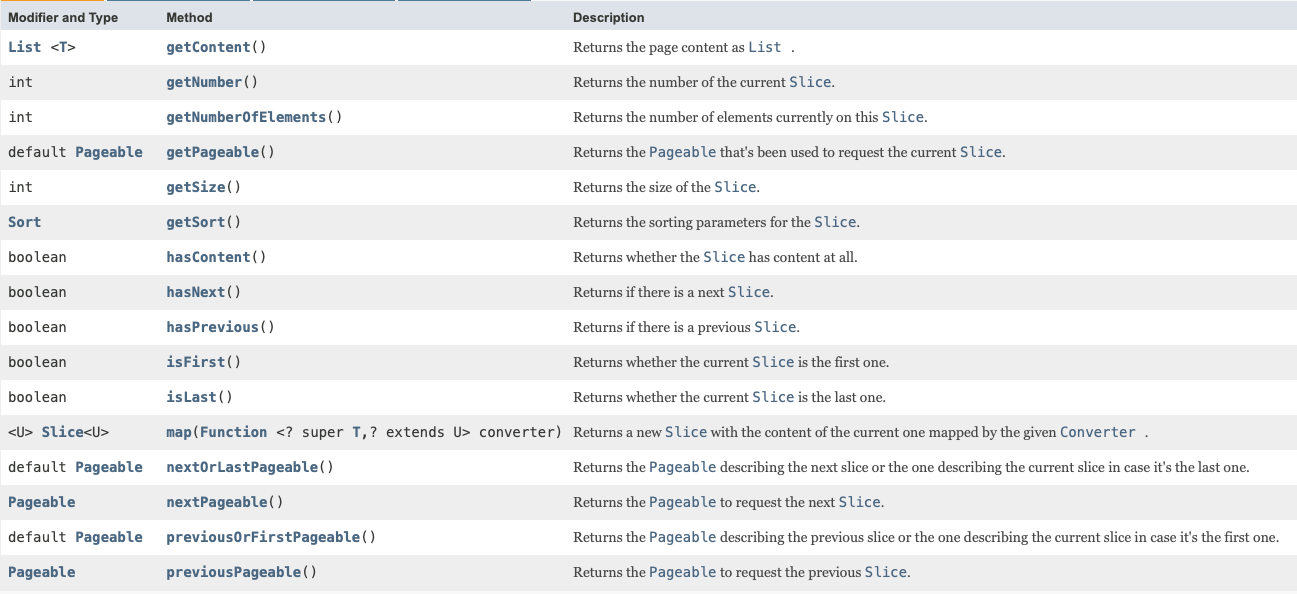
2-2. Page
Page는 Slice를 상속하고 있기 때문에 Slice의 모든 메소드를 사용할 수 있습니다.
그러나, 아래의 사진과 같이 Page는 Slice에는 없는 getTotalElements, getTotalPages를 가지고 있습니다.
따라서 이러한 getTotalElements를 위해서 조회 쿼리 이후 전체 데이터 개수를 조회하는 count 쿼리가 한번 더 실행하게 됩니다.
이러한 점이 가장 큰 차이점이라고 할 수 있습니다!!


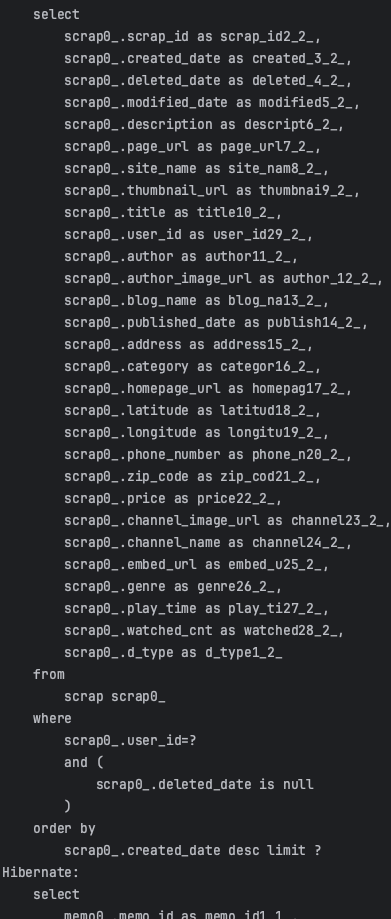
저희 프로젝트에서 스크랩을 조회하는 부분을 Slice와 Page 모두 적용해보면서 실제 실행되는 query비교해보겠습니다.
@Transactional
public Slice<GetScrapResponse> getScraps(String email, Pageable pageable) {
User user = userService.validateUser(email);
Sort sort = Sort.by(Sort.Direction.DESC, "createdDate");
PageRequest pageRequest = PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(),
sort);
Slice<Scrap> scrapSlice = scrapRepository.findAllByUserAndDeletedDateIsNull(user,
pageRequest).orElseThrow(() -> new NotFoundException(ErrorCode.NOT_EXISTS_SCRAP));
return scrapSlice.map(scrap -> GetScrapResponse.of(scrap,
memoRepository.findMemosByScrapAndDeletedDateIsNull(scrap))
);
}
@Transactional
public Slice<GetScrapResponse> getScraps(String email, Pageable pageable) {
User user = userService.validateUser(email);
Sort sort = Sort.by(Sort.Direction.DESC, "createdDate");
PageRequest pageRequest = PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(),
sort);
Page<Scrap> scrapSlice = scrapRepository.findAllByUserAndDeletedDateIsNull(user,
pageRequest).orElseThrow(() -> new NotFoundException(ErrorCode.NOT_EXISTS_SCRAP));
return scrapSlice.map(scrap -> GetScrapResponse.of(scrap,
memoRepository.findMemosByScrapAndDeletedDateIsNull(scrap))
);
}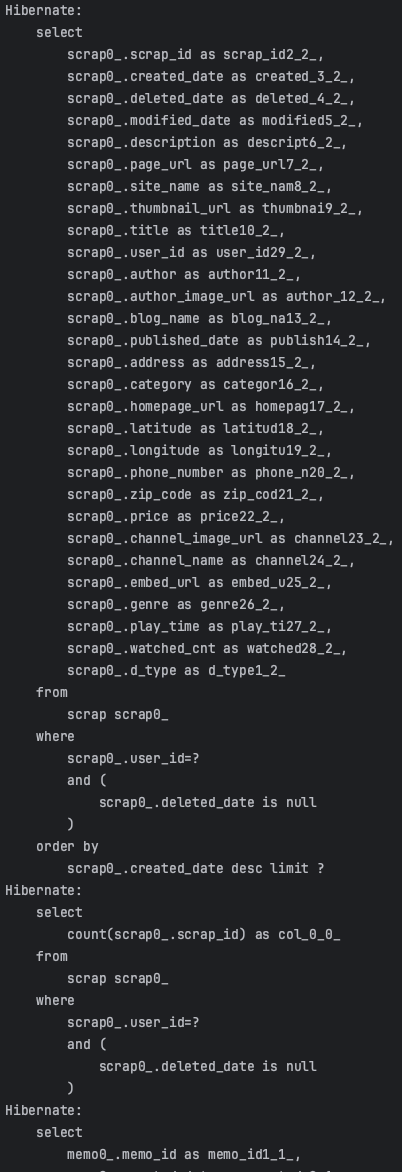
위의 사진에서도 볼 수 있듯이, Page를 사용하면 count 쿼리가 실행되지만, Slice는 count 쿼리가 실행되지 않는 모습을 볼 수 있습니다.
3. Slice VS Page 중 프로젝트에 적합한 것 찾기
- Slice는 전체 데이터 개수를 조회하지 않고 이전이나 다음의 데이터가 존재하는지만을 확인할 수 있습니다.
- 따라서 Slice는 데이터의 개수가 많은 경우 Page보다 성능상으로 유리합니다.
- Page는 전체 데이터 개수를 조회하기 때문에, 전체 페이지 개수가 필요한 경우인 상황에서 사용됩니다.
- Page는 pagination과 같이 아래의 검색 결과 페이지 수를 보여줘야 하는 경우에도 사용됩니다.

이미지 출처 : 네이버 검색 페이지 결과 일부
저희 프로젝트에서는 스크랩의 개수를 조회하고 있지만, 무한 스크롤하고 있는 중에는 전체 스크롤의 개수를 계속해서 구하지 않아도 되고, 스크랩을 추가한 순간에만 해당 전체 스크랩 전체 개수를 부르기 때문에 count를 호출하는 API를 따로 만들어놓았습니다. 따라서 Slice를 사용하여 프로젝트에 도입하기로 하였습니다!
참고 자료
- https://colour-my-memories-blue.tistory.com/10
- https://rachel0115.tistory.com/entry/QueryDsl-Page-Slice-페이지네이션-무한-스크롤
- https://junior-datalist.tistory.com/342
4. 프로젝트에 적용하기
4-1. Page 사용하기
- 아래의 코드는 맨 위의 서론에서 언급한 코드입니다.
- 즉, JPAQuery count = queryFactory.query().from(scrap).select(scrap.count()).where(scrap.user.eq(user)) 코드가 포함되어 있다는 의미는 Page를 사용했다는 것을 의미합니다.
@Override
public Slice<Scrap> searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword,
Pageable pageable) {
List<Scrap> contents = queryFactory
.selectFrom(scrap)
.where(
scrap.user.eq(user)
.and(scrap.deletedDate.isNull())
.and(scrap.title.containsIgnoreCase(keyword)
.or(scrap.description.containsIgnoreCase(keyword)))
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(scrap.createdDate.desc())
.fetch();
JPAQuery<Long> count = queryFactory.query()
.from(scrap)
.select(scrap.count())
.where(scrap.user.eq(user));
return PageableExecutionUtils.getPage(contents, pageable, count::fetchOne);
}하지만 저희 프로젝트에서는 count 쿼리가 필요없기 때문에 Slice 방식으로 변경해주겠습니다!
4-2. Slice 사용하기
- Page와 다르게 count하는 부분이 사라졌고, 다음의 데이터가 존재하는 지만을 확인할 수 있도록 hasNextPage만 추가되었습니다.
- 그리고, 요청한 pagesize보다 1을 크게 조회하여 만약에 1개가 더 조회되었다면 다음 데이터가 존재하는 것이므로 다음 페이지의 존재 여부는 true가 되고 아니라면 false가 됩니다.
@Override
public Slice<Scrap> searchKeywordInScrapOrderByCreatedDateDesc(User user, String keyword,
Pageable pageable) {
List<Scrap> contents = queryFactory
.selectFrom(scrap)
.where(
scrap.user.eq(user)
.and(scrap.deletedDate.isNull())
.and(scrap.title.containsIgnoreCase(keyword)
.or(scrap.description.containsIgnoreCase(keyword)))
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize()+1)
.orderBy(scrap.createdDate.desc())
.fetch();
return new SliceImpl<>(contents, pageable, hasNextPage(contents, pageable.getPageSize()));
}
private boolean hasNextPage(List<Scrap> contents, int pageSize) {
if (contents.size() > pageSize) {
contents.remove(pageSize);
return true;
}
return false;
}2️⃣ 결론
- 무한 스크롤에 대해서 학습하다가, no-offset 방식을 사용하여 성능을 개선하는 블로그를 보게 되었습니다. 따라서 출시 이후에 사용자 수가 많아져서 스크랩의 개수가 많아진다면 조회가 매우 느려질 것으로 예상되어 성능 개선하기 위해서 no-offset 방식을 적용해야겠다는 생각을 했습니다. 이처럼 조회의 Slice와 Page 객체들의 원리와 동작을 정확하게 이해하면서, 제공되는 기본 로직뿐만 아니라 성능 개선을 위해서 어떤 부분을 수정해야 할지를 볼 수 있는 시야를 가지게 된 것 같습니다.
- 더 나아가서, Slice와 Page의 공식 문서를 확인하고 구현된 코드를 확인해보면서 어떠한 점이 다르고 왜 다르게 설계되었는지를 파악할 수 있게 되어서 신기하기도 했고, 공식 문서를 어떻게 봐야할지를 조금이나마 알게 되었습니다!!
