종종 드럼을 치러 다닌다.
좋아하는 아티스트의 새로운 곡이 나왔거나 악보가 없는 곡을 커버하려고 할 땐 귀로 청음한대로 따라 치려고 많이 노력하지만 특정 부분의 필인(fill-in)을 치려면 난해한 경우가 종종 생긴다.
그래서 문득 아래와 같은 생각을 했다.
드럼 사운드를 학습한 컴퓨터에게 mp3, wav형식의 악곡 파일 하나를 던져주고
컴퓨터가 시계열 형식의 데이터로 언제 어떤 음이 나왔는지 내어주고 그걸 악보로 변환해주면 어떨까?
구현 정확도는 그 이후의 내용일 것 같지만. 상상만 해도 꽤 멋질 것 같다.
그래서 프로젝트를 진행하면서 글을 작성하게되었다.
프로젝트 코드는 여기서 확인할 수 있다.
음성데이터를 준비한다
직접 드럼킷 사운드를 녹음해도되지만 그러기엔 너무 많은 시간이 소요된다.
다른사람이 만들어둔 데이터가 있는지 알아보자
http://www.mattprockup.com/percussion-dataset
있다.
WAV 파일의 metadata 수정
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
audio, _ = tf.audio.decode_wav(audio_binary)
waveform = tf.squeeze(audio, axis=-1)
return waveform, labelwav 파일 정보를 활용하기위해 아래와 같이 tensorflow.io.read_file 로 읽어오는데
아래와 같이 Header 관련 이슈가 있다..
tensorflow.python.framework.errors_impl.InvalidArgumentError: Header mismatch: Expected fmt but found JUNK [Op:DecodeWav]fmt가 들어있을 줄 알았는데 왠 이상한 JUNK라는 값이 들어가있으니
못찾았다 혹은 내가 알던거랑 달라 같은 느낌이라서..
실제로 데이터를 바이너리로 까보면 아래와 같은 헤더를 볼 수 있다.
(vi 에서 %!xxd 입력하여서 Hex모드로 전환했다)

RIFF4...WAVEJUNK...
생각을 좀 해보자
Header 관련 이슈가 있었는데 파일 정보를 제대로 불러올 수 없었다는 메시지는
헤더를 못알아먹었다 로 생각해볼법 하다.
특히 fmt라는 키워드를 내어주었는데 그게 어느 부분에 있는지 알아야 제대로 대응할 것 같다.
Wave 파일 헤더는 어떻게 생김?
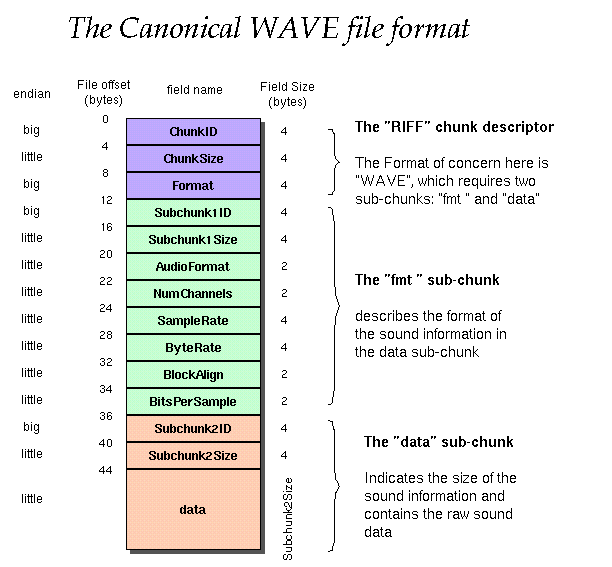
http://soundfile.sapp.org/doc/WaveFormat/
WAVE라는 포맷은 fmt 혹은 data와 같은 sub-chunk를 필요로 한다는 내용을 알 수 있다.
- WAV 파일의 Header는 44 Byte이다.
- 요구하는 fmt는 앞 12바이트의 RIFF 부분이 끝난 13바이트에 있어야한다.
- 나머지는 날리면 플레이어에서 이 파일이 스테레오 타입인지 모노타입인지 모를 수도 있고.. 어떤 파일인지 대응을 못할 가능성이 생길 수 있기 때문에 적당히 JUNK라고 되어있는 부분을 fmt로 치환하는 작업이 필요해보인다.
파일 수정
filename = 'ST_FloorTom_Rim_1111.2.wav'
header1 = bytearray()
corrupted = bytearray()
header2 = bytearray()
data = bytearray()
with open(filename, 'rb') as f:
header1 = f.read(12)
corrupted = f.read(4) # b'JUNK'
header2 = f.read(28)
data = f.read()
result = header1 + bytearray(b' fmt') + header2 + data
with open('result.wav', 'wb') as f:
f.write(result)
이 외의 사이드이펙트가 발생할 수 있지만 헤더값을 조정하여 디버깅 할 수 있다.
스테레오 타입에서 모노 타입으로 분리
데이터 학습시킬땐 스테레오 타입 데이터보다 모노 타입의 데이터가 좀 더 사용하기 편했던 것 같다. 그래서 분리해주기로 했음.
import wave
def save_wav_channel(fn, wav):
'''
한 파일에 여러 채널이 있을 경우 분리하는 함수
'''
# Read data
nch = wav.getnchannels()
if nch < 2:
return
depth = wav.getsampwidth()
wav.setpos(0)
sdata = wav.readframes(wav.getnframes())
# Extract channel data (24-bit data not supported)
typ = {1: np.uint8, 2: np.uint16, 4: np.uint32}.get(depth)
if not typ:
raise ValueError("sample width {} not supported".format(depth))
data = np.fromstring(sdata, dtype=typ)
for i in range(channel+1):
ch_data = data[i::nch]
# Save channel to a separate file
outwav = wave.open('{}_ch{}.wav'.format(fn, i+1), 'w')
outwav.setparams(wav.getparams())
outwav.setnchannels(1)
outwav.writeframes(ch_data.tostring())
outwav.close()
wav = wave.open('{}'.format(filename))
save_wav_channel(filename, wav)데이터 길이 맞추기
모든 데이터 길이를 균일하게 맞춰주기 위한 작업이다.
데이터 읽어올때 특정 길이까지만 읽어주면 된다.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform[:20000], labelspectrogram 역시 마찬가지로.. 같은 길이를 박아놓고 시작하지만 혹시모르니 빈공간에는 패딩을 채워준다. 패딩을 채우는 작업은 각각의 데이터 길이가 다를 때 매우 유용하다.
def get_spectrogram(waveform):
# Padding for files with less than 16000 samples
zero_padding = tf.zeros([20000] - tf.shape(waveform), dtype=tf.float32)
waveform = tf.cast(waveform, tf.float32)
waveform = tf.concat([waveform, zero_padding], 0)
spectrogram = tf.signal.stft(
waveform, frame_length=255, frame_step=128)
spectrogram = tf.abs(spectrogram)
return spectrogram모델 생성
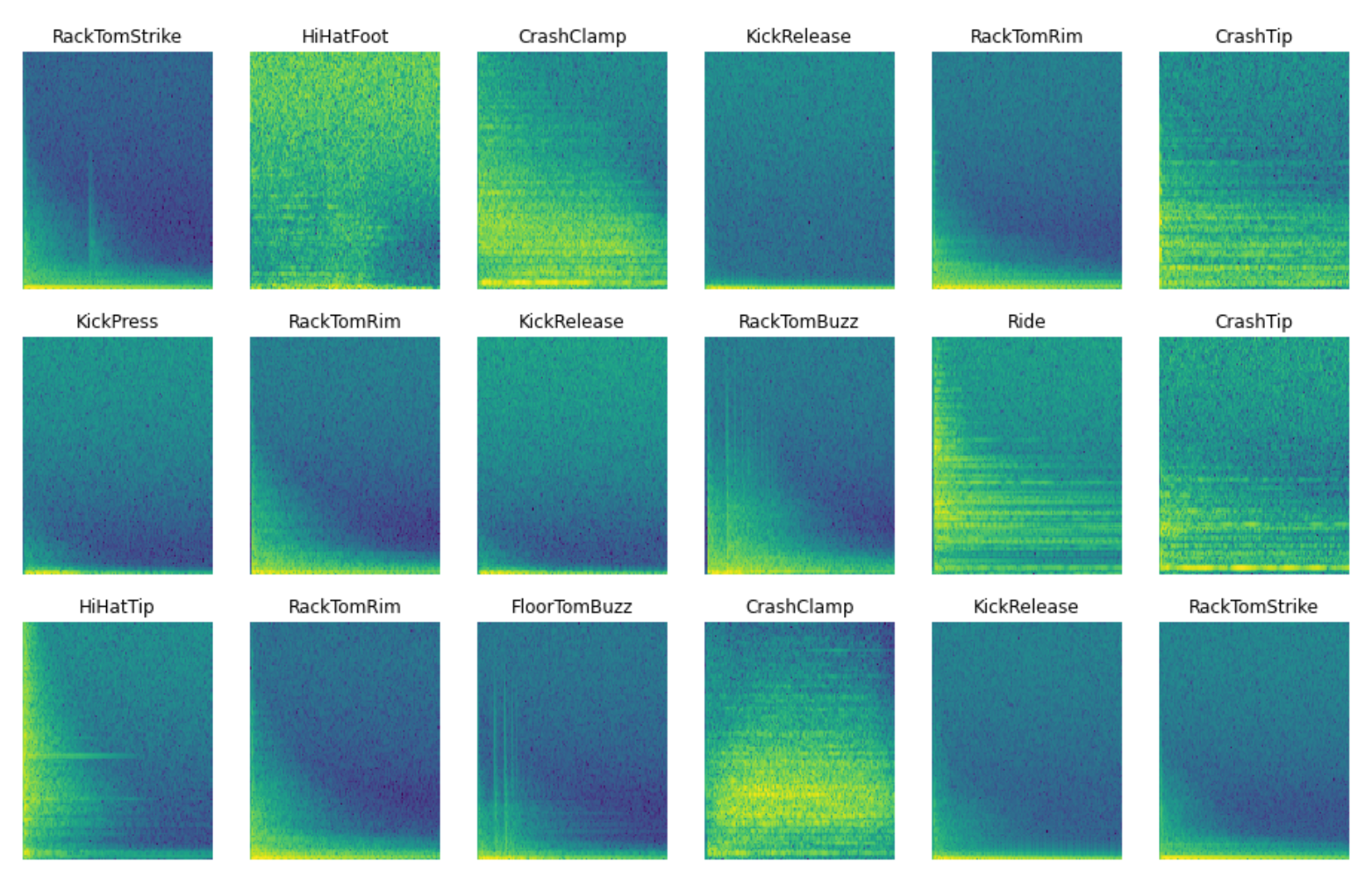
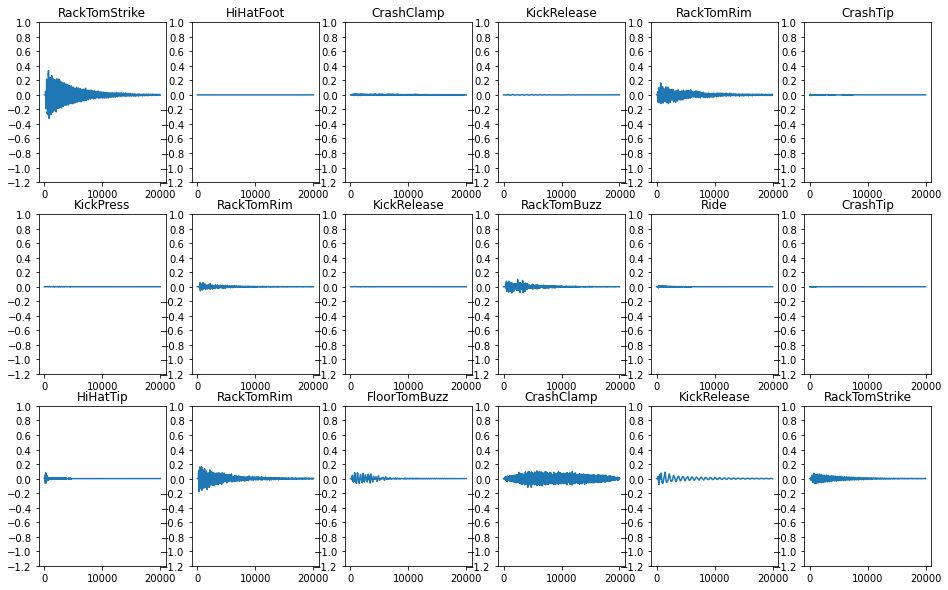
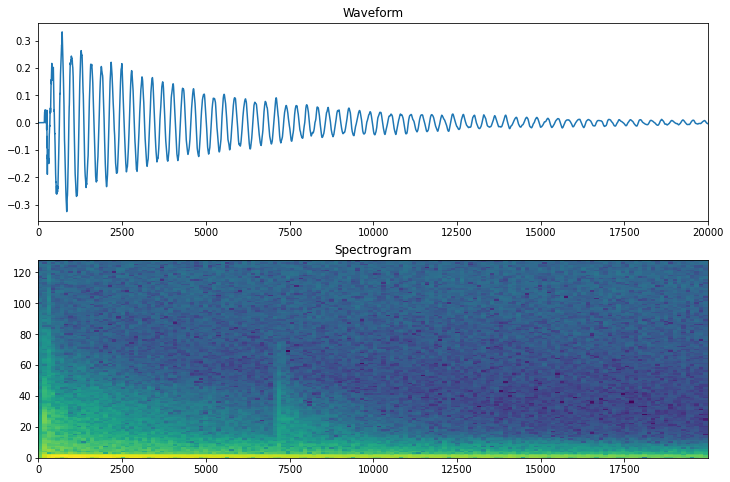
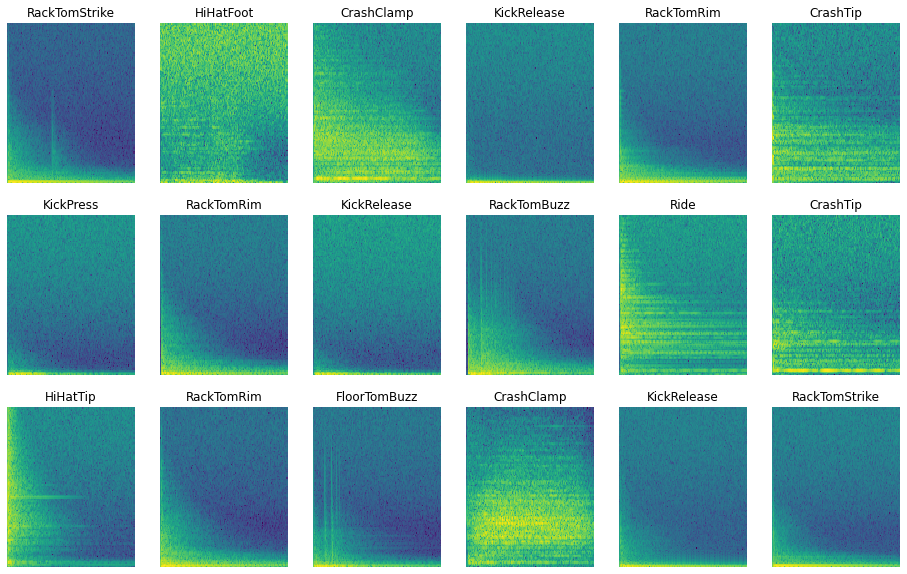
음성데이터 파형 및 스펙트럼 확인
Layer
Input shape: (155, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
_________________________________________________________________
normalization (Normalization (None, 32, 32, 1) 3
_________________________________________________________________
conv2d (Conv2D) (None, 30, 30, 32) 320
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 14, 14, 64) 0
_________________________________________________________________
dropout (Dropout) (None, 14, 14, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 12544) 0
_________________________________________________________________
dense (Dense) (None, 128) 1605760
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_1 (Dense) (None, 19) 2451
=================================================================
Total params: 1,627,030
Trainable params: 1,627,027
Non-trainable params: 3
_________________________________________________________________Epoch 1/10
22/22 [==============================] - 12s 493ms/step - loss: 2.5761 - accuracy: 0.2087 - val_loss: 2.1809 - val_accuracy: 0.3432
Epoch 2/10
22/22 [==============================] - 4s 205ms/step - loss: 2.0913 - accuracy: 0.3268 - val_loss: 1.6706 - val_accuracy: 0.5207
Epoch 3/10
22/22 [==============================] - 5s 206ms/step - loss: 1.6512 - accuracy: 0.4652 - val_loss: 1.2816 - val_accuracy: 0.5976
Epoch 4/10
22/22 [==============================] - 5s 206ms/step - loss: 1.3469 - accuracy: 0.5601 - val_loss: 1.0197 - val_accuracy: 0.6893
Epoch 5/10
22/22 [==============================] - 5s 206ms/step - loss: 1.1273 - accuracy: 0.6152 - val_loss: 0.8711 - val_accuracy: 0.7278
Epoch 6/10
22/22 [==============================] - 5s 239ms/step - loss: 0.9061 - accuracy: 0.6942 - val_loss: 0.7160 - val_accuracy: 0.8077
Epoch 7/10
22/22 [==============================] - 6s 283ms/step - loss: 0.8384 - accuracy: 0.7116 - val_loss: 0.6807 - val_accuracy: 0.8373
Epoch 8/10
22/22 [==============================] - 5s 206ms/step - loss: 0.7571 - accuracy: 0.7333 - val_loss: 0.5674 - val_accuracy: 0.8580
Epoch 9/10
22/22 [==============================] - 5s 206ms/step - loss: 0.6838 - accuracy: 0.7630 - val_loss: 0.5373 - val_accuracy: 0.8669
Epoch 10/10
22/22 [==============================] - 5s 208ms/step - loss: 0.6520 - accuracy: 0.7703 - val_loss: 0.4867 - val_accuracy: 0.8698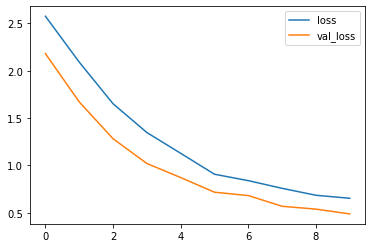
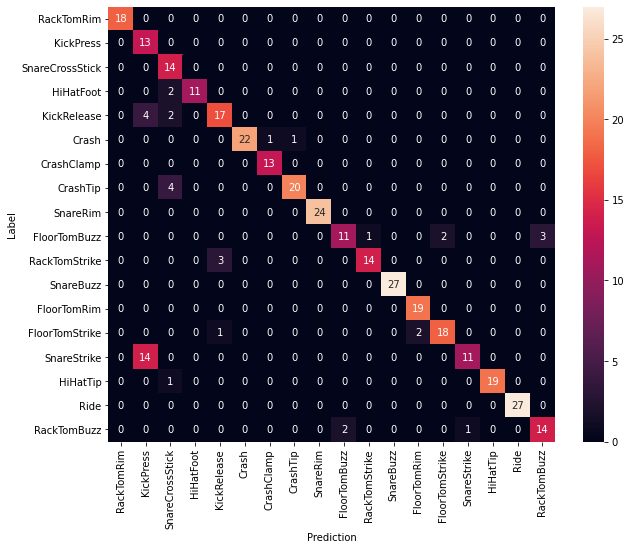
학습 완료
데이터 라벨링 후 모델도 만들어두었다.
이걸 어떻게 써먹을까 고민해봐야 할 것 같은데..
실시간으로 음성 데이터를 받고 모델이 뱉어주는 시계열 데이터로 악보를 만드는 작업을 진행한다?
이런 방식이면 괜찮지않을까 생각이 든다.
관련 내용은 다음 포스트에서 이어서 작성해보려고한다.
