이전 글에서 언급했듯 배운 내용을 토대로 내가 진행했던 한 프로젝트의 성능 개선을 했는데, 해당 내용을 커밋하지 않았던 것과 정리하지 않았던 것이 떠올라서 구체적으로 어떤 내용들을 어떻게 개선했는지 정리해보고자 한다.
참고로 성능의 개선은 심하면 100배까지 났는데, 애초에 로직을 작성했던 분도 웹개발을 처음하던 분이라 그랬다.
사실 프로젝트를 완성하고 나서도 데이터를 서칭하던 파트가 유난히 오래 걸려서 '데이터가 많으니까 어쩔 수 없지 뭐..' 하고 넘겼던 기억이 있는데, 이번 성능 개선을 하고 난 다음 보니 그냥 웹에서 상호작용하듯 최소한의 시간만 필요해졌다.
거두절미하고 이제 설명을 시작해보겠다.
Lazy loading...
Django ORM은 기본적으로 lazy loading 방식을 선택한다. 다시 한 번 정리해보자면 아래와 같다.
Lazy Loading
- 참조해야할 데이터를 필요한 순간에 가져옴
- 초기 로딩 시간을 줄일 수 있음 (데이터를 필요할 때 호출하기 때문)
- 자원 소비를 좀 줄일 수 있음.
- Eager Loading에 비해서 query는 더 많이 발생한다.
많은 데이터를 다루는 실제 웹 서비스에서는 대부분 lazy loading 방식을 선택하는게 맞긴 한 것 같다. 그때그때 필요한 데이터만 가져와서 쓰는 것이 맞으니까..
하지만 이전 글에서도 말했듯 lazy loading 방식에는 고질적인 문제들이 있어서 다룰 수 있는 문제는 ORM선에서 다루고 사실 가장 좋은 것은 직접 쿼리를 작성하는 것이다.
이제 정리된 내용을 바탕으로 어떤 성능 개선을 이뤄 냈는지 보자.
About Project
진행했던 프로젝트를 먼저 알아보자.
아티스트 웹데이터 자동 크롤링 및 데이터 분석 플랫폼
- SNS와 소셜 미디어에서의 아티스트 활동이 점점 중요해지는 만큼 그것을 관리할 필요성이 요구됨.
- YG엔터테인먼트에서는 아티스트의 웹데이터를 크롤링해 그것을 관리함으로써 팬들의 동향을 살피고자 했음.
- 많은 데이터의 참조가 발생하는 부분은 예상할 수 있듯 크롤링된 데이터를 조회해서 그 중 필요한 데이터를 뽑아내는 파트이다.
Caching
주로 Caching 방식이 성능 개선의 주를 이뤘다.
아래의 코드는 기존에 작성되 있던 아티스트 목록을 가져오는 코드이다.
artist_objects = Artist.objects.filter(active=1)
artist_objects_values = artist_objects.values()
artist_list = []
for a in artist_objects_values:
artist_list.append(a['name'])위와 같이 코드를 작성하게 되면 artist_object에 담긴 query set을 for문을 돌 때마다 한 번씩 조회해서 가져오게 된다.
artist_objects = list(Artist.objects.filter(active=1))
artist_list = [query.name for query in artist_objects]아래와 같이 고치게 된다면 한 번에 데이터를 가져와서 caching한 뒤 가져온 데이터를 참조하기 때문에 query가 실행되는 것을 막을 수 있다. (깨알같은 pythonic)
비록 크롤링 대상에 있는 아티스트가 많지 않았기 때문에 해당 조회는 몇회 일어나지 않았고, 때문에 드라마틱한 개선은 없었다.
아래의 코드가 대망의 크롤링 데이터 참조 코드이다.
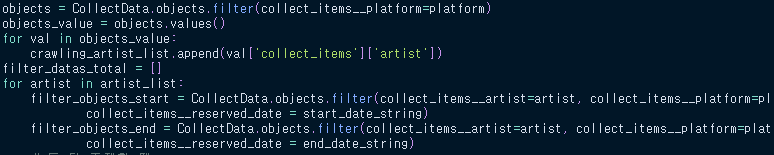
해당 코드를 설명하자면, 지정한 시작 날짜와 끝 날짜 사이의 모든 column에 대한 변화량을 뽑기 위해서, 해당 record들을 가져오는 과정을 나타내는 코드이다.
- object에 지정한 platform에 해당하는 크롤링 데이터를 담아오고, 이것을 한 번씩 돌면서 list에 append한다.
- 이후 지정된 아티스트 목록에 있는 모든 아티스트를 한 번씩 참조하면서, 모든 크롤링 데이터를 가져와 읽는다.
- 그 중 필요한 하나를 뽑는다.
즉, 한 번의 아티스트를 확인하기 위해 방대한 양의 크롤링 데이터를 두 번씩(!)이나 쿼리를 날려 가져오고, 그 과정을 전체 아티스트 수만큼 반복한다.
이를 개선하기 위해서는 먼저 전체 크롤링 데이터 중 필요한 것들을 한 번만 가져와서 caching해두는 것이 중요했다.
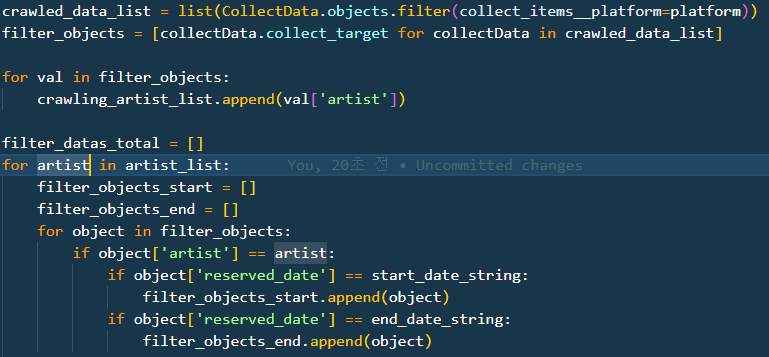
이를 개선한 코드는 위와 같다.
변화한 것을 설명해보자.
- 가장 먼저 한 번의 쿼리를 사용해 필요한 데이터만 가져와 이를 list로 바로 저장한다.(caching한다)
- filter_object list를 아래 코드에서 계속해서 사용한다.
가장 문제라고 생각했던 처음 한 번, 시작날 데이터와 끝나는 날 데이터 각각 2 * num(artist)번씩 DB를 참조하던 것에서 최종적으로 단 한 번의 참조로 변경됐다.
그 결과 성능은 무려 10.102s 걸리던 데이터 참조가 0.088s로 개선되었다...!
select_related
select_related는 1+N문제를 해결하기 위해서 DjangoORM에서 제공하는 interface이다. 이를 활용해서 해결한 문제에 대해서 설명해보고자 한다.
아래 코드를 먼저 확인해보자.
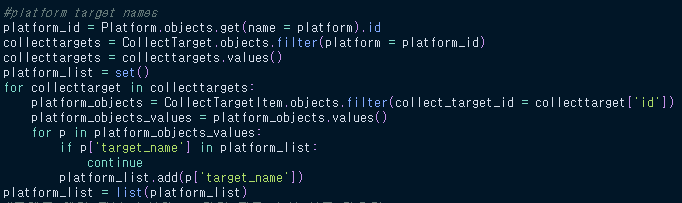
위 코드는 아래 사진처럼 플랫폼별로 가져오는 데이터가 다르기 때문에 사용자가 누른 플랫폼에서 보여줄 column name을 결정하는 코드이다.
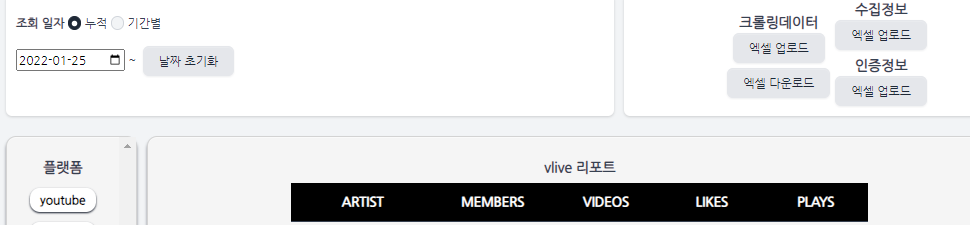
위 예시 화면에서 ARTIST, MEMBERS, VIDEOS, LIKES, PLAYS가 가져올 column name에 해당되는 항목들이다.
이제 코드를 설명해보자.
- 사용자가 지정한 platform과 같은 platform 객체의 id를 가져온다.
- 해당 아이디를 갖는 collect_target(크롤링 대상) 객체들을 가져온다.
- 각 객체별로, 실제 해당 객체를 대상으로 크롤링된 데이터를 하나씩 가져온 후, 그것의 column들을 뽑아낸다.
이처럼 모든 크롤링 대상들에 대해서, 실제 크롤링된 데이터를 가져오는 for loop를 돌리는 경우, 매 대상마다 한 번씩 크롤링된 데이터를 가져오는 쿼리를 날리게 된다...
이를 방지하기 위해서 나는 collect_target_item과 관련된 collect_target를 한 번에 가져오도록 select_related interface를 사용했고, 아래와 같이 코드가 단순해질 수 있었다.

주석에 써진대로, 0.0442초 걸리던 column 탐색 작업이 0.0109초로 감소했다.
맺으며
- 이번에는 DjangoORM에 적용한 내용을 정리해봤다.
- 대부분의 ORM들은 lazy loading 방식을 사용하고 있기 때문에, ORM을 사용하기에 발생할 수 있는 문제들을 생각하면서 코드를 작성해야겠다는 생각이 들었다.
- 또한 이렇게 늘 ORM에 의존하는 것은 좋지 않으며, 스스로 SQL문을 짜서 날리는 것에 익숙해져야겠다고 느꼈다.
