
CS스터디에서 자료구조를 공부했고, HashSet은 정렬되지 않는 것으로 배웠다. 근데 데이터에 따라 종종 정렬되어 저장되는 것처럼 보이는 경우를 보게 되었다. HashSet에 데이터가 어떻게 저장되는지 궁금하여 이 글을 작성한다
public static void main(String[] args) {
//##############################################
HashSet<Integer> set = new HashSet<>();
set.add(4);
set.add(3);
set.add(1);
set.add(5);
System.out.println(set); // [1, 3, 4, 5] ?! why?
//##############################################
set = new HashSet<>();
set.add(4);
set.add(3);
set.add(1);
set.add(2);
System.out.println(set); // [1, 2, 3, 4] ?! why?
//##############################################
set = new HashSet<>();
set.add(124);
set.add(33);
set.add(50);
set.add(1);
System.out.println(set); // [33, 1, 50, 124] // 정렬되지 않는 건 맞는데..
//##############################################
}HashSet을 뜯어보자
내부 구조

- 우선 HashSet은 내부에서 HashMap을 사용하여 데이터를 저장한다.
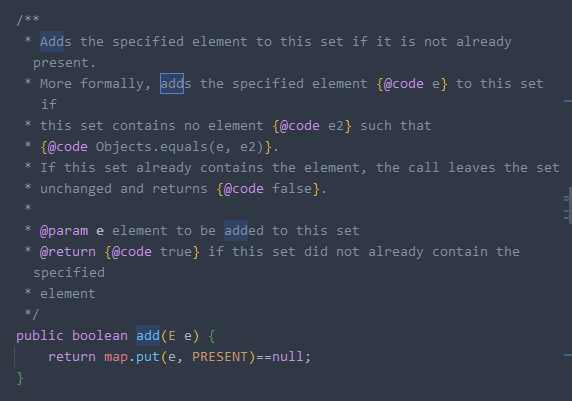
- add 함수를 사용할 때, HashMap의 put을 사용하고 중복이 되지 않도록 저장하려는 값을 map의 키로 저장한다.

- 값으로 PRESENT라는 비어있는 더미 Object를 저장한다
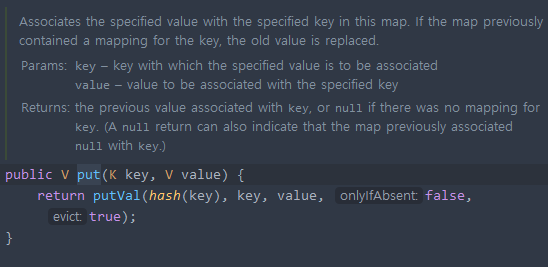

- map의 put함수를 살펴보면,
- key 값에 대해 hash 메서드를 통해 해싱한다.
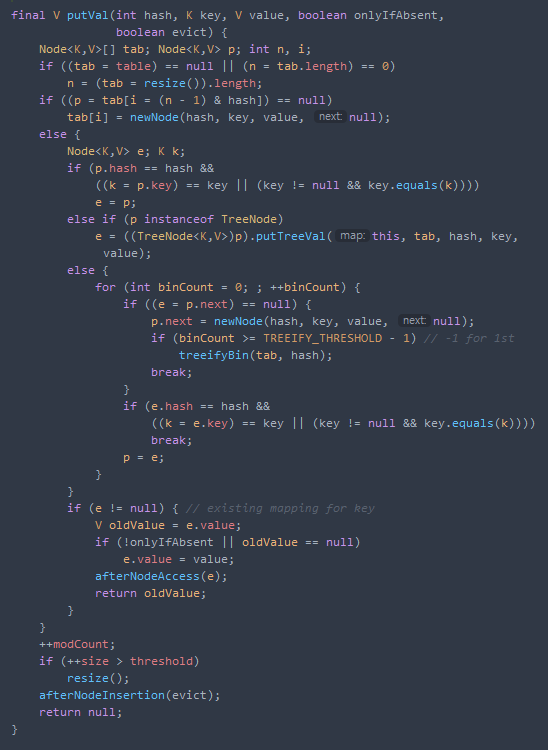
- putVal 함수를 통해 table에 저장한다.
- (n - 1) & hash를 통해 얻어진 i에 저장되어있는 노드가 null이라면,
- tab[i]에 새로운 노드를 만들어 저장하고,
- 이미 해당 i가 존재한다면
- 존재하는 노드 뒤에 이어 붙이는 방식이다.
- (n - 1) & hash를 통해 얻어진 i에 저장되어있는 노드가 null이라면,
디버깅을 해보자
HashSet<Integer> set = new HashSet<>();
set.add(124);
set.add(33);
set.add(50);
set.add(1);
System.out.println(set); // [33, 1, 50, 124]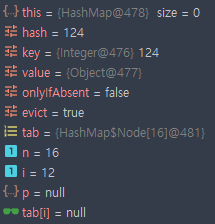
-
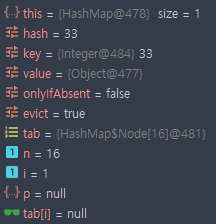
124가 추가 되었을 때,
- key = 124
- hash = 124
- i = 12
12번 인덱스가 비어있으므로 새로운 노드를 만들어 저장한다.
-
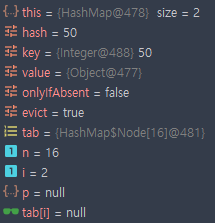
33이 추가 되었을 때,
- key = 33
- hash = 33
- i = 1
1번 인덱스가 비어있으므로 새로운 노드를 만들어 저장한다.
-
50이 추가 되었을 때,
- key = 50
- hash = 50
- i = 2
2번 인덱스가 비어있으므로 새로운 노드를 만들어 저장한다.
-
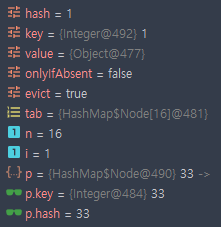
1이 추가 되었을 때,
- key = 1
- hash = 1
- i = 1
1번 인덱스에 이미 존재하는 노드가 있기 때문에 그 뒤에 연결한다.
p 노드가 이전 노드를 나타내는데, 해당 노드의 key값이 33인 것을 볼 수 있다.
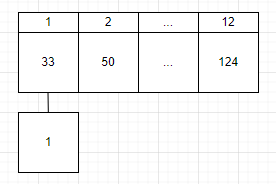
그림으로 요약하자면 이렇게 정리할 수 있겠다.
출력할 때 각 index의 노드들을 next를 통해 순차적으로 출력하게 되며,
이로써[33, 1, 50, 124] 이라는 값이 출력되는 것으로 볼 수 있다.
요약
- HashSet은 HashMap으로 구현이 되어있고,
- 저장하는 과정에서 해시테이블을 통해 저장한다.
- 해시테이블은 체이닝을 통해 중복되는 값의 경우 해당 노드 뒤에 연결하는 식으로 구현되어 있다.

hello dev!!