프로젝트 하면 뭐가 어렵나요? 저는 무조건 설계요...😒
프로젝트의 모든 과정이 힘들겠지만 유독 설계가 어렵다.
이론을 제대로 이해해야 최적화가 되고 경험이 부족하면 잘못된 길로 빠지고... 흑흑 너무 어려워....

어렵다고 안하면 취업에 실패해 은행을 털다 감옥에 들어가기 때문에 확실히 정리해보자.
1. 과정
정보처리기사를 취득한 사람이라면 모두가 알고있을 개논물(개념 - 논리 - 물리)이 DB 설계의 과정이다.
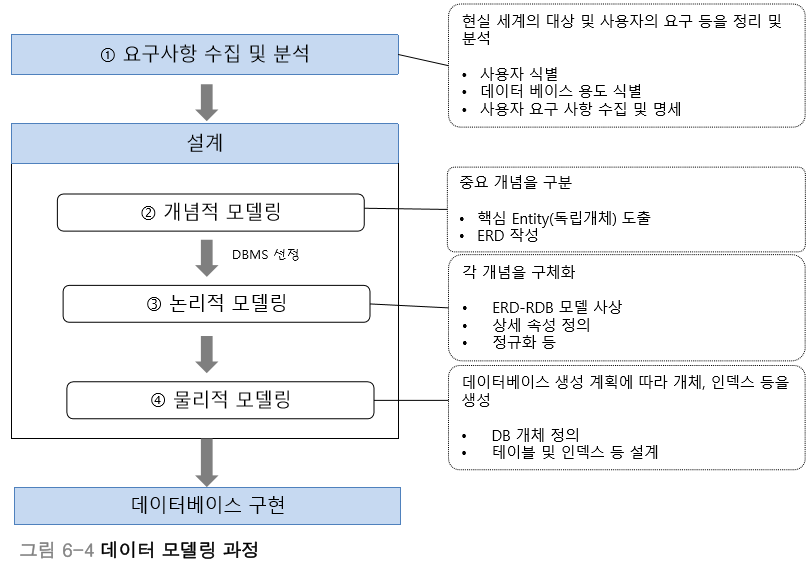
-
요구사항 분석
- 프로젝트에서 필요로 하는 데이터와 작업 이해
- 사용자 요구 사항을 수집 및 분석 후 DB가 지원해야 하는 기능 파악
-
개념적 설계
- 요구사항을 통해 데이터 모델을 만든다
- 엔티티 간의 관계를 식별하고 이를 ER 다이어그램(ERD)을 사용해 표현
- 💡정규화💡 기법을 적용할 수 있다
-
논리적 설계
- 개념적 설계를 구체화하고, 실제 DB의 구조를 정의하는 단계
- 데이터 모델 선택 후 테이블과 컬럼 정의
- 각 테이블의 속성과 제약조건 설정
- 정규화를 수행해 데이터 중복 최소화 및 일관성 유지
-
물리적 설계
- 최종적으로 데이터를 관리할 데이터 베이스를 선택
- 실제로 테이블을 만드는 작업 (SQL을 사용해 완성하는 단계)
딱딱한 이론을 게시판 예제로 물렁하게 만들어보자
-
요구사항 분석 ➡️ 게시판에 뭐가 필요하지? (회원정보, 게시글, 게시판, 댓글, 로그인 정보 등등)
-
개념적 설계 ➡️ 요구사항 분석을 통해 게시판에 필요한 데이터들을 파악한 후 관계 설정 (ER 다이어그램으로 표현)
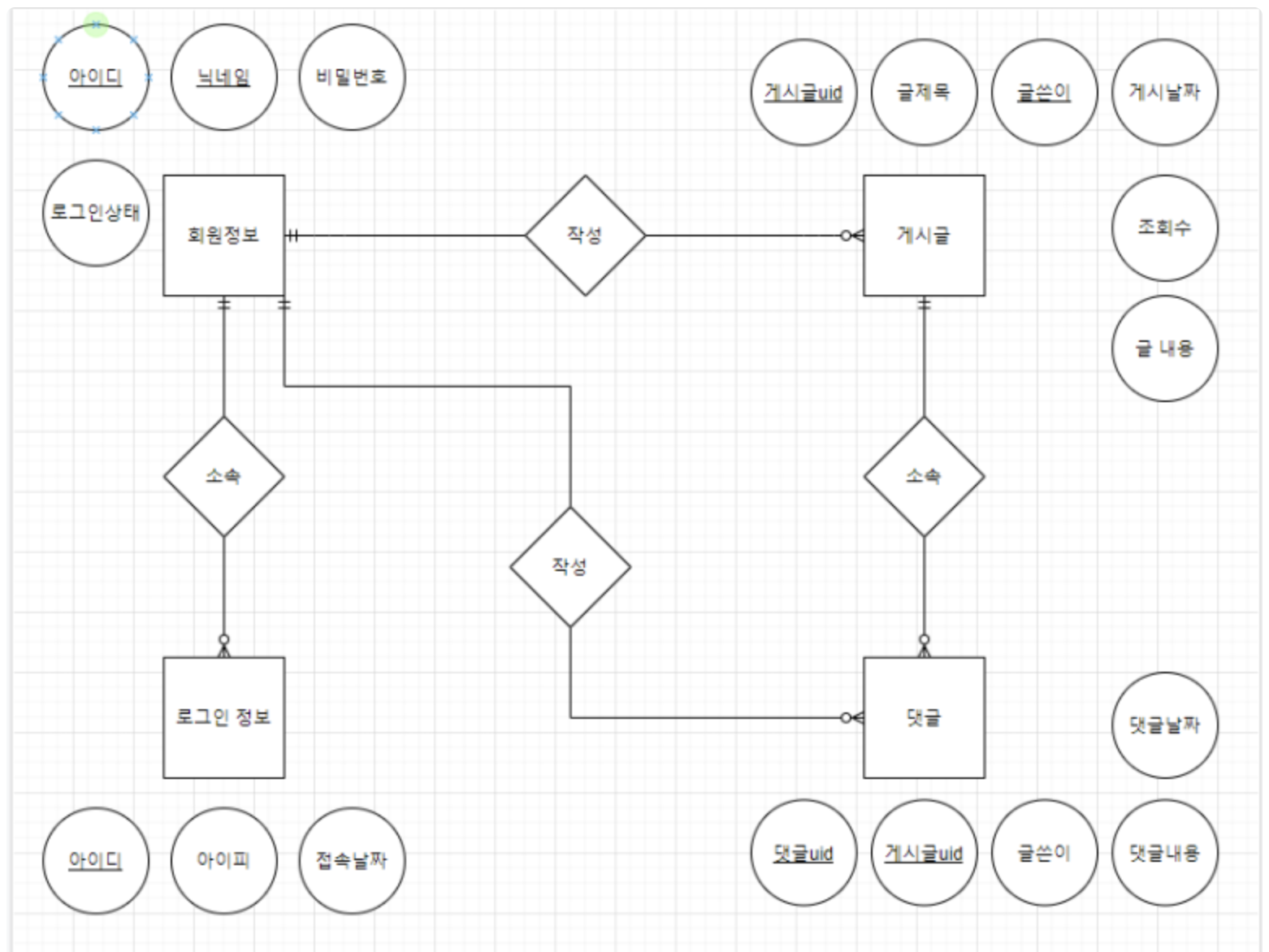
-
논리적 설계 ➡️ 개념적 설계에서 한 관계 설정과 데이터들을 표로 만들자
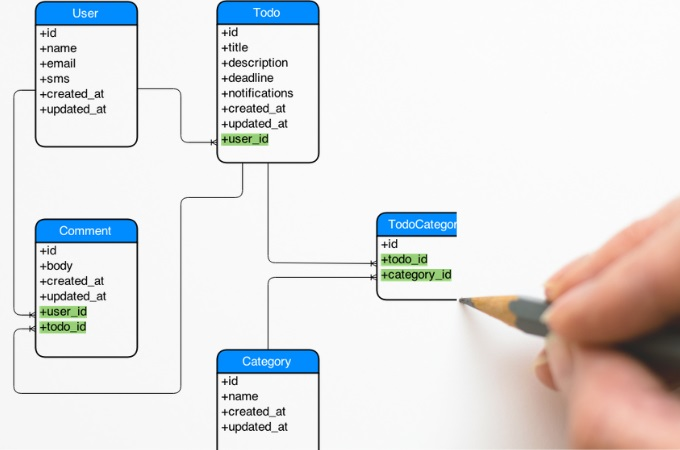 테이블과 컬럼 정의 + 속성 및 제약조건 설정
테이블과 컬럼 정의 + 속성 및 제약조건 설정
- 물리적 설계 ➡️ 이제 실제로 DB를 만들자
뭔가_엄청_멋있는 SQL 근데 게시판을 만들어주는 혼공SQL에서 배우는 내용의 대부분이 물리적 설계!
2. 각 단계 상세 분석
요구사항 분석
"게시판"을 낱낱히 모든 것을 해부한다는 마음가짐..
DB 설계를 하면 가장 먼저 하게되는 단계이면서 가장 쉬워보이는 단계이다. 하지만 제일 중요하고 가장 어려운 단계라 생각한다.
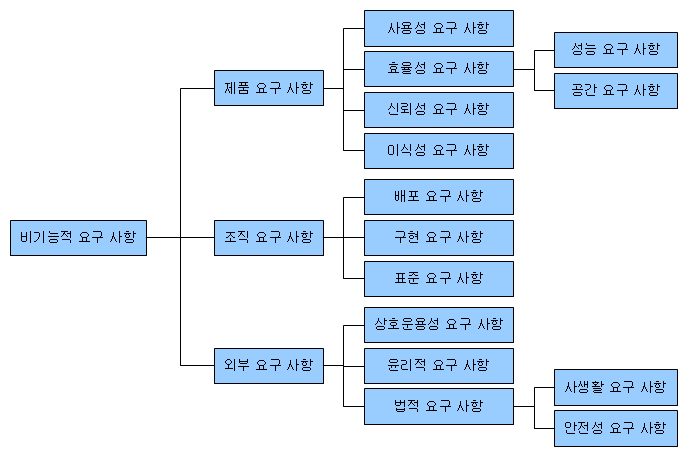
요구사항 분석은 기능적/비기능적 요구사항으로 구분하는데 DB 설계 시 항상 고민해야하는 부분이다.
- 기능적 요구사항 (Functional Requirements)
- 시스템이 무엇을 하는지?
- 입출력으로 무엇이 포함되어야 하는지?
- 어떤 상황에서 어떻게 작동하는지?
- 사용자가 제공받기 원하는 기능
- 비기능적 요구사항 (Non-Functional Requirements)
그럼 게시판을 예시로 요구사항을 도출해보자!
- 회원가입
- 아이디, 패스워드, 이름, 전화번호
- 아이디 중복 X
- 로그인
- 아이디, 패스워드
- 로그인 성공 시 게시글 리스트
- 로그인 실패 시 다시 로그인 페이지
- 게시판
- N개의 게시글 페이징
- 각 게시글의 글쓴이, 날짜, 제목, 조회수, 댓글수
- 검색 기능
- 비로그인 시 조회 가능
- 로그인 시 조회, 생성 가능
- 게시글
- 비로그인 시 작성 X
- 로그인 시 생성 가능
- 본인 게시글 수정, 삭제 가능
최대한 간단히 도출했는데도 DB에 적용하려면 생각할 부분이 엄청 많은 것을 볼 수 있다.
혼공SQL에서 배운 제약조건, 기본키-외래키 관계 설정 등 다양하게 생각을 하며 최적화를 해야한다
개념적 설계
요구사항 분석을 통해 개체와 속성, 관계를 도출하고 ERD로 작성하는 과정이 개념적 설계이다.
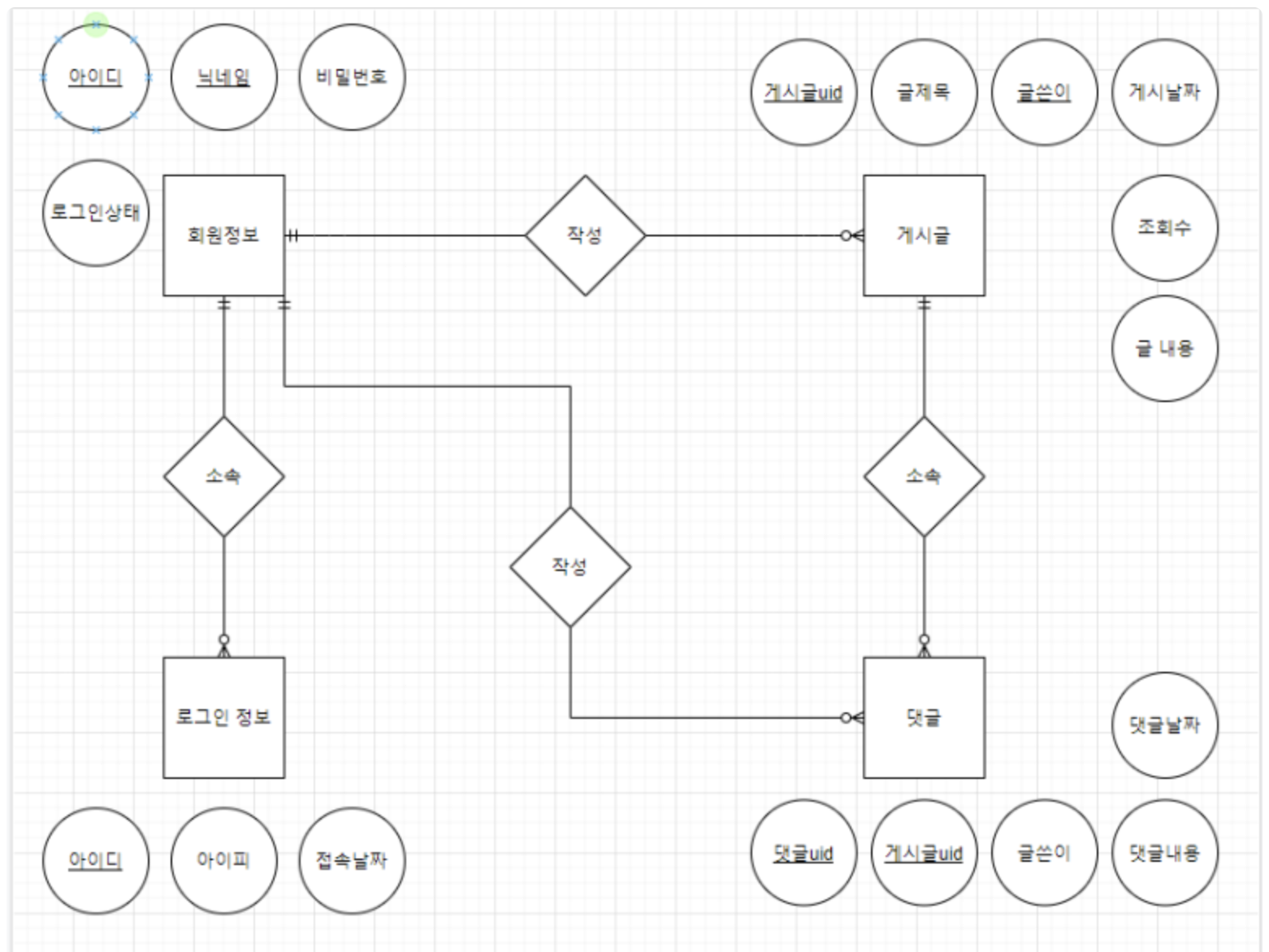
1. ERD (Entity - Relationship Diagram)
Entity = 개체, Relationship = 관계
즉, 개체와 관계를 중점으로 만든 다이어그램을 의미한다
-
개체(Entity)
- 단독으로 존재하는 객체, 동일한 객체 X
- 사각형으로 표현
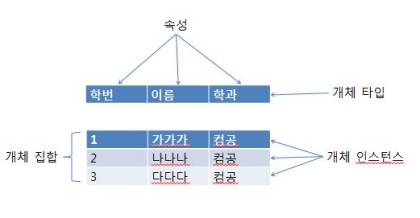
- DB에서 "테이블"이 ERD에서는 개체라 볼 수 있다 (파일의 레코드와도 대응됨)
- 개체 타입 (정의), 개체 인스턴스(실체화된 개체), 개체 집합(개체 인스턴스를 모아둔 것)
-
속성(Attribute)
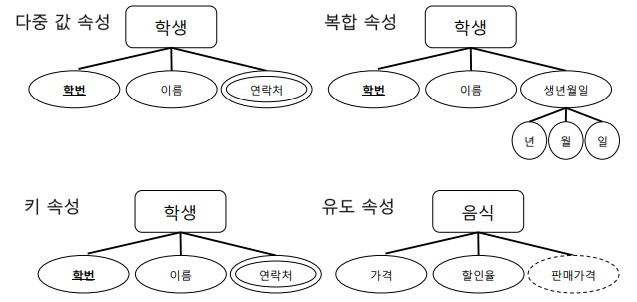
- 개체가 가지고 있는 고유의 특성
- 의미 있는 데이터의 가장 작은 논리적 단위
- 원으로 표현
- 종류
- 키 속성 : 기본키는 밑줄을 그어 표기 - ex) 회원정보의 아이디
- 단일 값 속성 vs 다중 값 속성 ➡️ 고객의 적립금 = 단일값만 가능, 책의 저자 = 다중 값 가능(여러 개 가능)
- 단순 속성 vs 복합 속성 ➡️ 의미 분해 X = 단순(학생의 성별 등), 의미 분해 O = 복합 (생년월일 분해, 연락처 분해 등)
- 유도 속성 = 나머지 속성을 통해 유도 가능 (가격 - 할인율 = 판매가격)
-
관계(Relationship)
- 개체 간의 관계를 의미 (매핑)
- 개채를 서로 이으며 마름모로 표현
- 종류
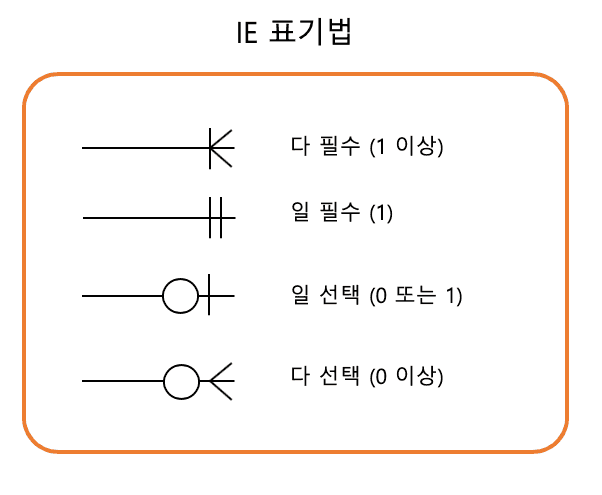
- 이전에 배운 일대일(1:1), 일대다(1:N), 다대다(N:N)
- 선택적 or 필수적
- 예제
- [학과:교수] ➡️ 1:N + 학과(필수) + 교수(필수)
학과 : 한 학과에는 여러 교수가 소속
교수 : 한 교수는 한 학과에만 소속 - [회원:주문] ➡️ 1:N + 회원(선택) + 주문(필수)
회원 : 한 회원은 여러 주문 가능
주문 : 한 주문은 한 회원만 가능 - [교수:과목] ➡️ N:1 + 교수(선택) + 과목(필수)
교수 : 한 교수는 여러 강의 가능
강의 : 한 강의는 한 교수만 가능
- [학과:교수] ➡️ 1:N + 학과(필수) + 교수(필수)
논리적 설계
E-R 다이어그램에서 릴레이션 스키마를 만들려면 규칙이 필요하다.
-
모든 개체는 릴레이션으로 변환
- 각 개체는 하나의 테이블이 되고 속성은 테이블의 속성이 됨
-
다대다(N:M)관계는 관계를 릴레이션으로 변환
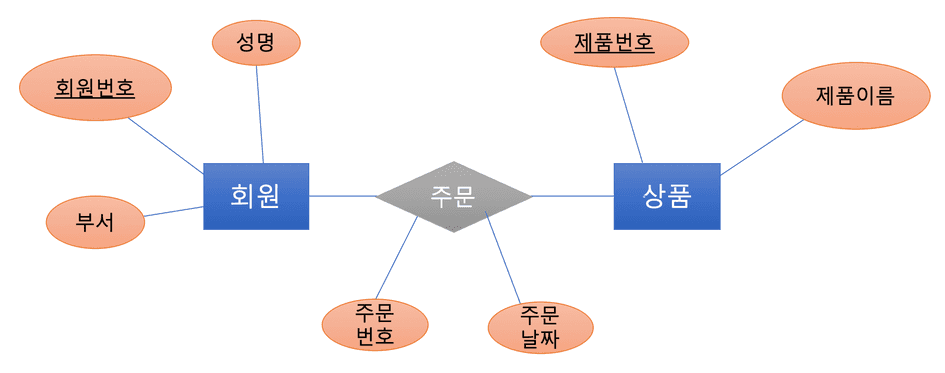
- 기존 예제에는 없는 다대다 관계 새로운 걸로 싹 살펴보기
- 회원 + 상품 = 이미 1번을 통해 릴레이션 된 상태
- 주문이란 관계를 새로운 릴레이션으로 변환
- 관계의 속성도 릴레이션에 포함함
- 관계의 릴레이션에서 별도의 기본키 사용
- 기본키 : 주문번호
- 외래키 : 회원번호, 제품번호
- 양쪽 객체의 기본키를 합쳐 기본키로 사용
- 기본키 : 회원번호 + 제품번호
- 외래키 : 회원번호, 제품번호
- 관계의 릴레이션에서 별도의 기본키 사용
-
1:N 관계는 외래키로 표현
- 1:N 관계에서 1 개체의 기본키를 N 릴레이션에 포함 후 외래키 지정 (가장 일반적)
- 지금까지 배운 모든 기본키 - 외래키는 이 표현에 해당함
-
약한 개체가 참여하는 1:N 관계는 외래키를 포함해 기본키로 지정
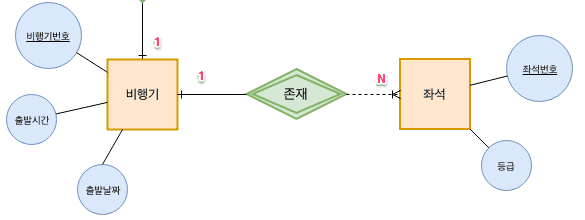
- 약한 개체 : 다른 개체에 종속되어 있어 그 개체가 없으면 존재할 수 없음 ➡️ 개별 개체 식별 속성 : 식별자, 부분키
- 따라서 종속하는 개체의 기본키와 본인을 식별하는 부분키를 합쳐 기본키를 구성 (비행기 번호 + 좌석번호)
-
1:1 관계는 외래키로 표현
- 일반적으로 양쪽에 각 릴레이션의 기본 키를 주고받음 (관계가 필수인 경우)
- 관계가 선택인지 필수인지에 따른 선택
- 필수 참여 개체의 릴레이션만 외래키를 받음
- 모든 개체가 필수라면 릴레이션 하나로 합침
-
다중 값 속성은 독립 릴레이션으로 변환
- 다중 값 속성을 가질 수 없으므로 별도의 릴레이션 생성
- 기존 개체의 기본 키를 가져와 다중 값 속성과 함께 기본키 구성
물리적 설계
지금까지 배워온 모든 SQL 작성법을 통해 논리적 설계 내용을 토대로 실제 데이터베이스를 구현하는 과정
3. 정규화
레시피(설계 과정)대로 했는데 맛없다. ➡️ 디테일(정규화)의 부족
정규화는 ERD 내에서 중복요소를 찾아 제거하는 과정
그럼 정규화는 어떻게 하는걸까?
➡️ 암스트롱의 공리(Armstrong's Axioms)와 함수 종속성 (Functional Dependency)을 알아야한다.
정규화를 위해 함수 종속성을 파악해야하고 함수 종속성을 파악하기 위해 암스트롱의 공리를 이용한다고 이해하면 된다....! 정확하지 않음
암스트롱의 공리 Amstrong's Axioms
관계형 데이터베이스는 이산수학의 relation 및 function의 개념을 이용해 정의되었기 때문에 그 성질 또한 이산수학의 개념과 유사하다.
순수한 이론이고 이를 이용해 함수 종속성을 파악할 수 있다.
| 구분 | 추론 규칙 | 설명 |
|---|---|---|
| 기본 | 재귀적 규칙(reflexivity rule) | Y가 X의 부분 집합이면 X→Y, X⊇Y이면 X→Y이다. |
| 기본 | 확대의 공리(augmentation rule) | X→Y이면, XZ→YZ |
| 기본 | 이행의 공리(transitivity rule) | X→Y이고 Y→Z이면 X→Z |
| 부수 | 합집합의 성질(union rule) | 만약 X→Y이고 X→Z이면 X→YZ |
| 부수 | 분해 규칙(decomposition rule) | X→YZ이면 X→Y이고 X→Z |
| 부수 | 유사 이행 (pseudo transitivity) | 만약 X→Y이고 YZ→W이면 XZ→W |
함수 종속성
-
함수 종속성?
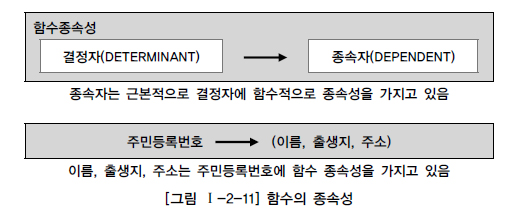
- 어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 관계 ➡️ 말이 어렵지만, 학생 ID가 101이면 이름이 뉴진스가 되는 관계를 말함
- 속성 A(학생 ID) : 결정하는 친구 = 결정자 = Determinant
- 속성 B(뉴진스) : 결정되는 친구 = B가 A에 종속
-
함수 종속성의 종류
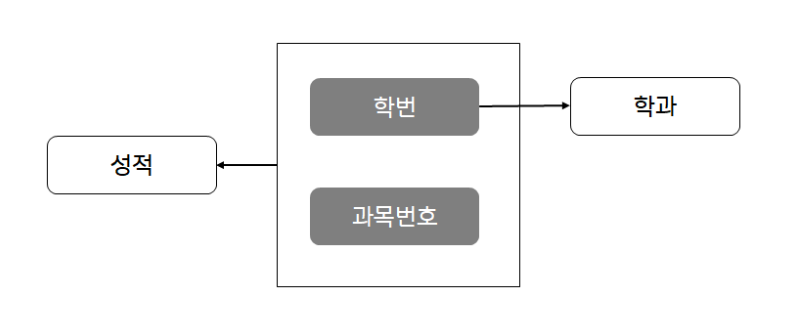
- 완전 함수 종속성 (Fully Functional Dependency, FFD)
➡️ XY→Z일 때, X→Z 와 Y→Z 가 모두 성립하지 않는 경우
➡️ {학번, 과목번호} → 성적
➡️ 이미 정규화 되어 있어 정규화 대상이 아님 - 부분 함수 종속성 (Partial Dependency)
➡️ XY→Z일때, X→Z와, Y→Z중 하나만 성립하는 경우
➡️ 학번 → 학과
➡️ 2차 정규화 대상
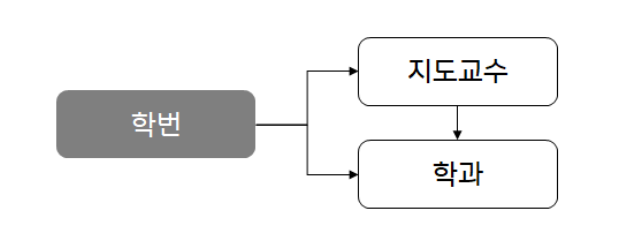
- 이행 함수 종속성 (Transitive Dependency)
➡️ X→Y이고, Y→Z일 때 X→Z가 성립하는 경우
➡️ 학번→지도교수, 지도교수→학과, 학번→학과
➡️ 3차 정규화 대상
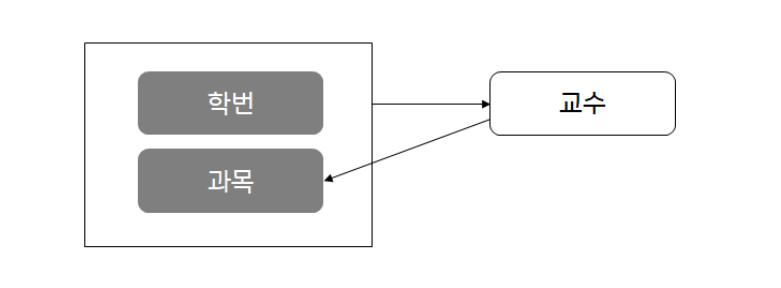
-
결정자 함수 종속성 (Boyce-Codd Normal Form, BCNF)
➡️ 함수적 종속성이 되는 결정자가 후보키가 아닌 경우
➡️ X→Y 에서 X가 후보키가 아님
➡️ 교수→과목
➡️ Boyce/Codd 정규화 대상 -
다중값 종속성 (Multivalued Dependency, MVD)
➡️ 한 관계에서 둘 이상의 독립적인 다중값 속성 존재하는 경우
➡️ 4차 정규화 대상 -
조인 종속성 (Join Dependency)
➡️ 관계 중 둘로 나눌 때에 원래의 관계를 회복할 수 없지만 셋 또는 그 이상으로 분리하면 복원 가능한 경우
➡️ 5차 정규화 대상
- 완전 함수 종속성 (Fully Functional Dependency, FFD)
-
함수적 종속의 문제
함수적 종속성이 어떤 문제를 일으키는가?
앞에서 정규화는 ERD 내의 중복요소를 찾아 제거하는 과정이라 설명했다. 실제로 데이터베이스의 중복은 여러 문제를 일으키는데 이것을 이상(Anomly)이라 한다.
- 이상 현상의 종류
- 삭제 이상 : 튜플 삭제 시 같이 저장된 다른 정보도 삭제되는 현상
- 삽입 이상 : 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 수정(갱신) 이상 : 수정 시 중복된 데이터의 일부만 수정되어 일어나는 데이터 불일치 현상
정규화
제 4,5 정규화를 사용해야하는 함수적 종속성이 있지만 대부분 제 1,2,3 + Boyce/Codd 정규화를 시도한다.
그 이유는 어느 정도의 중복을 인정하는 것이 더 효율적이기 때문이다. 즉, 제 4,5 정규화는 고도 정규화로 오히려 쿼리 성능 및 유지 관리 작업에 영향을 미친다는 뜻이다.
제 1 정규화
테이블의 컬럼이 원자값(Atomic Value)을 갖도록 테이블을 분해
말이 어려우니 바로 예제로 알아보자
예시)
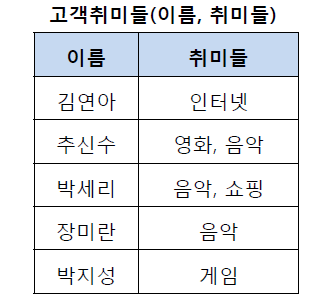
추신수와 박세리 선수는 취미가 두 개씩 있다. 이는 원자값이 아니므로 제 1 정규형을 만족하지 않는다.
수학에서 배운 함수와 비슷하게 받아들이면 된다. 하나의 x값에 y값이 두 개 있는 느낌
적용)
제 1 정규화를 적용하면 아래와 같은 결과가 나온다. (컬럼이 원자값으로만 구성된 모습 확인)
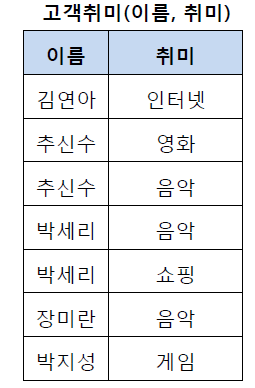
제 2 정규화
제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족 하도록 테이블을 분해
예시)
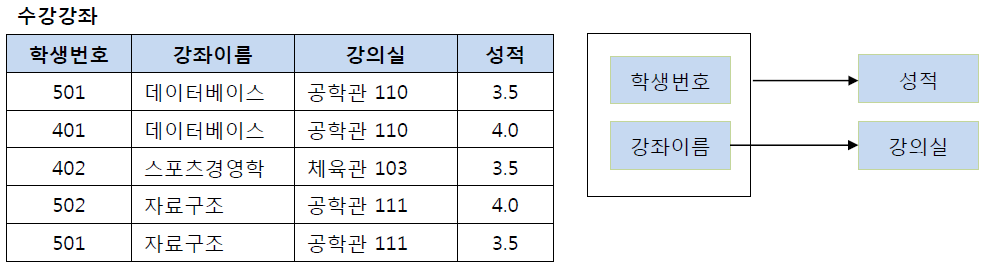
- 기본키 = 학생번호 + 강좌이름, 복합키를 가지고 있다.
- 학생번호 + 강좌이름인 기본키는 성적을 결정하고 있음
- 근데 강좌이름→강의실 : 기본키의 부분키인 강좌이름이 결정자임..
- 어? 이거 부분 함수 종속에서 본거네 ➡️ 제 2 정규화 적용
적용)
강좌이름→강의실의 새로운 테이블을 생성해서 정규화를 진행
모든 데이터가 완전 함수 종속을 만족
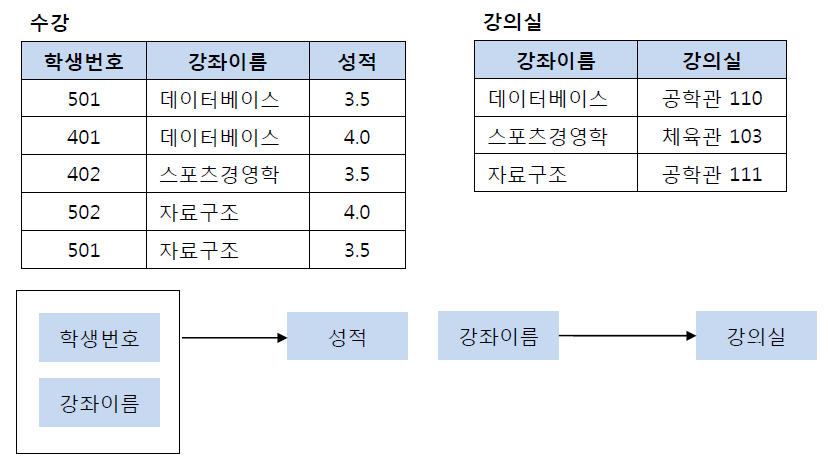
제 3 정규화
제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것
이행적 종속이란 단어가 익숙하지 않으니 비슷한 삼단논법이라 생각하자.
예시)
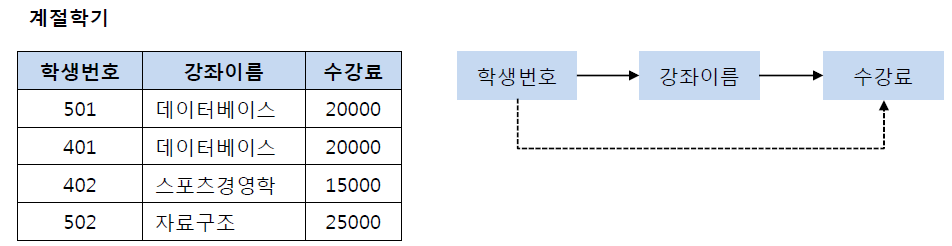
- 학생 번호→강좌이름, 강좌이름→수강료, 학생번호→수강료?
- (학생 번호, 강좌 이름), (강좌 이름, 수강료) 두 테이블로 나눔
적용)
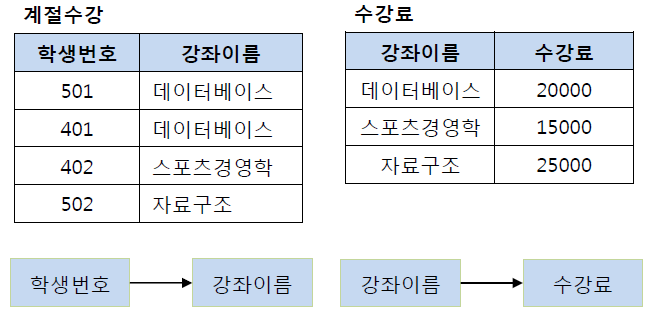
BCNF 정규화
제 3 정규화를 진행한 테이블에 대해 모든 결정자가 후보키가 되도록테이블을 분해하는 것
예시)
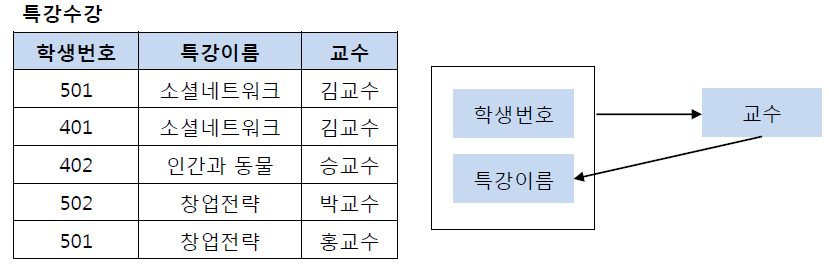
- 기본키 = 학생번호 + 특강이름 (복합키)
- 교수...가 특강이름을 결정?!
- 교수는 결정자인데 후보키가 아니다 = BCNF 적용 대상
적용)
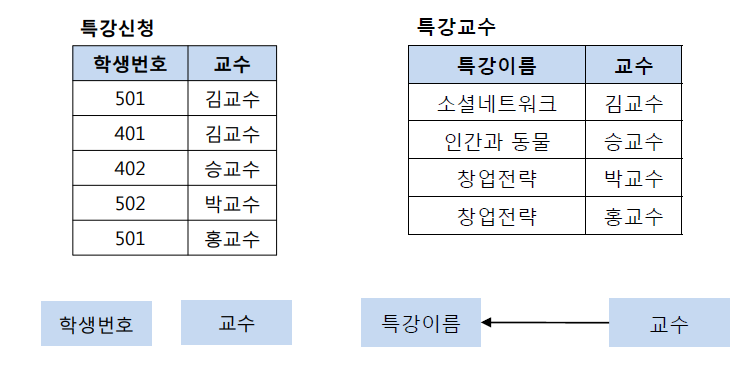
- 특강 수강 테이블을 특강 신청 + 특강 교수 테이블로 분해
- 모든 결정자가 후보키가 된 것을 확인할 수 있다.
4. 결론

DB 설계의 과정, 정규화 과정의 정확한 개념
데이터베이스 설계와 정규화 모두 데이터 중복성을 줄여 효율적이고 확장 가능한 데이터베이스를 생성할 수 있게 도와준다.
기능 종속성을 이해하고 데이터베이스 설계 과정에 활용함으로써 비즈니스 요구 사항을 충족할 수 있다
출처
<ERD, 데이터베이스 모델링>
https://mangkyu.tistory.com/27
https://nirsa.tistory.com/99
rawfish님 velog
https://siyoon210.tistory.com/26
https://behappyaftercoding.tistory.com/30
https://victorydntmd.tistory.com/126
frank님 블로그
<정규화>
https://needjarvis.tistory.com/610
https://mangkyu.tistory.com/28
Inpa님 블로그 - 역정규화와 정규화에 대한 방법에 대한 부연 설명
https://ybdeveloper.tistory.com/86
