키워드
- 교차검증
- 하이퍼 파라미터 튜닝
- grid search
- randomizedSearchCV
교차검증
교차검증을 하는 이유는 과적합을 피하면서 파라미터를 튜닝하고 일반적인 모델을 만들고 더 신뢰성 있는 모델 평가를 진행하기 위해서입니다.
- 고정된 test set을 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, 결국 내가 만든 모델은 test set 에만 잘 동작하는 모델이 된다.
- 즉, test set에 과적합(overfitting)하게 되므로, 다른 실제 데이터를 가져와 예측을 수행하면 엉망인 결과가 나와버리게 된다.
- 이를 해결하고자 하는 것이 바로 교차 검증(cross validation)이다.
-
교차 검증은 train set을 train set + validation set으로 분리한 뒤, validation set을 사용해 검증하는 방식이다.
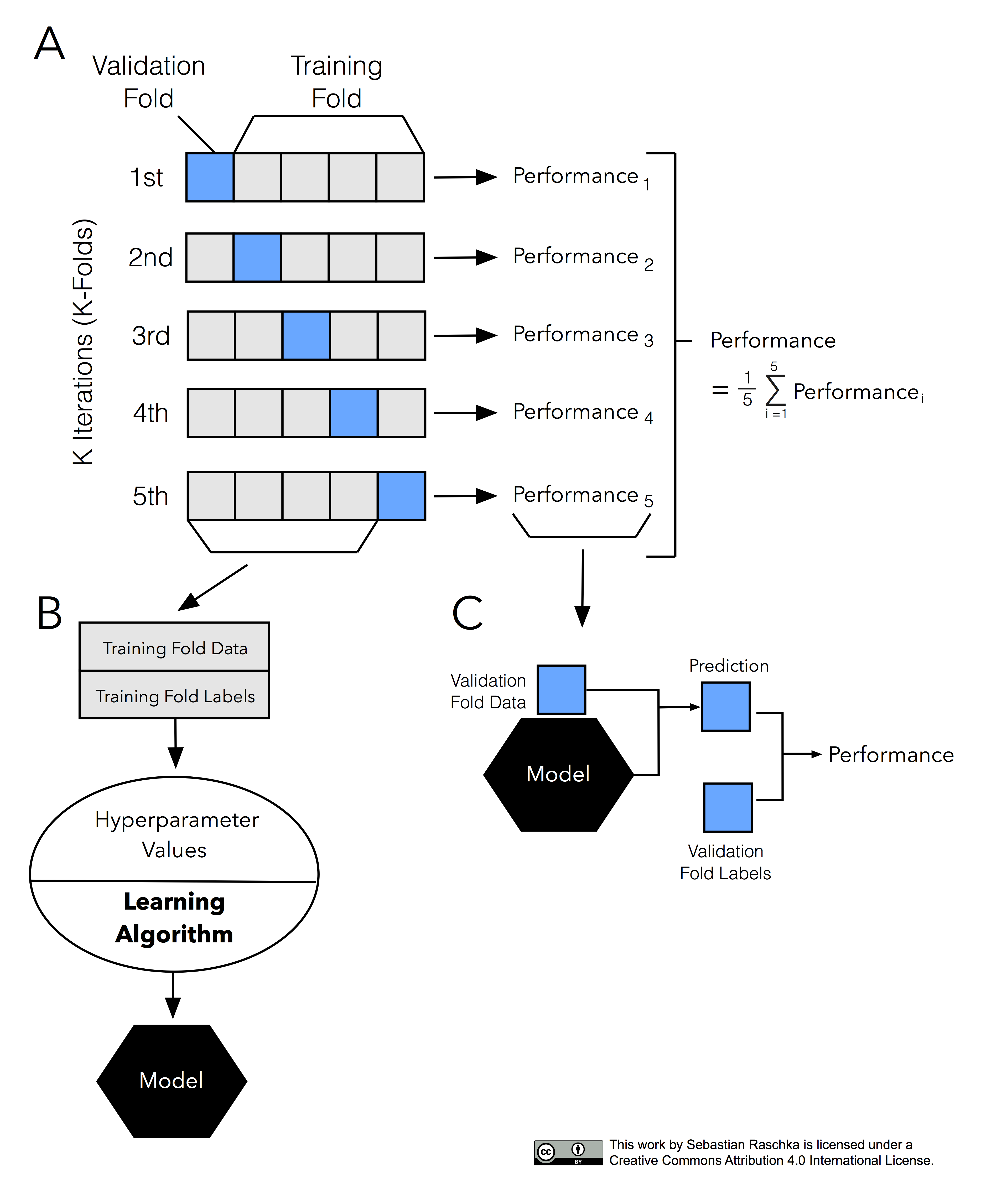
-
교차 검증의 장점과 단점
- 장점
- 모든 데이터셋을 훈련에 활용할 수 있다.
- 정확도를 향상시킬 수 있다.
- 데이터 부족으로 인한 underfitting을 방지할 수 있다.
- 모든 데이터셋을 평가에 활용할 수 있다.
- 평가에 사용되는 데이터 편중을 막을 수 있다.
- 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다.
- 모든 데이터셋을 훈련에 활용할 수 있다.
- 단점
- Iteration 횟수가 많기 때문에, 모델 훈련/평가 시간이 오래 걸린다.
하이퍼 파라미터 튜닝
머신러닝 모델을 만들때 중요한 이슈는 최적화(optimization)와 일반화(generalization) 입니다.
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정이며,
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 합니다.
TargetEncoder
- 범주형 Features에 대해서 사용할 수 있는 Encoding방법 중 하나인 TargetEncoding을 수행하는 명령어이다.
- Target Encoding의 일반적인 아이디어는 target 변수의 더 큰 값에 해당하는 범주가 더 큰 숫자로 인코딩 되게 하는 것이다.
- 하지만 이렇게 Target 변수의 확률을 이용해 더 큰 값에 해당하는 범주가 더 큰 숫자로 인코딩 되는 과정에서 다른 범주에서 동일한 값이 출력되는 등 문제가 발생할 수 있다.
- 이러한 원치 않는 효과를 줄이기 위해서
smoothing파라미터를 설정하여 줄 수 있다.
# 예시
from category_encoders import TargetEncoder
target_enc=TargetEncoder(min_samples_leaf=1, smoothing=1)
target_enc.fit_transform(X_train,y_train)RandomizedSearchCV
- 지정된 범위에서 각 하이퍼 파라미터들을 "Random"하게 조합하여 검증을 실시한다. 이를 통해서 Random으로 이루어진 검증에서 원하는 평가지표에서 최고의 값을 기록하는 모델을 뽑아낼 수 있다.
- 말그대로 범위 내에서 정해진 수만큼 랜덤하게 조합을 추출하여 사용하기 때문에 범위 안의 모든 조합을 탐색하는 GridSearchCV방식보다 Cost가 적다는 장점이 있다.
from sklearn.model_selection import RandomizedSearchCV
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True)
, SimpleImputer()
, StandardScaler()
, SelectKBest(f_regression)
, Ridge()
)
# 튜닝할 하이퍼파라미터의 범위를 지정해 주는 부분
dists = {
'simpleimputer__strategy': ['mean', 'median'],
'selectkbest__k': range(1, len(X_train.columns)+1),
'ridge__alpha': [0.1, 1, 10],
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=50,
cv=3,
scoring='neg_mean_absolute_error',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);GridSearchCV
- 지정한 하이퍼파라미터의 가능한 모든 조합을 이용하여 최적점을 찾아낸다.
from sklearn.model_selection import GridSearchCV
pipe = make_pipeline(
OrdinalEncoder(cols=cols_enc,mapping=mapping_enc,handle_unknown='return_nan'),
SimpleImputer(),
RandomForestClassifier(oob_score=True)
)
dists = {
'randomforestclassifier__n_estimators': [300,400,500,600,700,800,900,1000],
'randomforestclassifier__max_depth': [3,4,5,6],
'randomforestclassifier__criterion': ['gini','entropy']
}
clf = GridSearchCV(
pipe,
param_grid=dists,
cv=3,
scoring='roc_auc',
verbose=1,
n_jobs=-1
)
clf.fit(X_train, y_train);Bayesian Search
- 검증하고자 하는 하이퍼파라미터의 범위 내에서, 이전에 탐색한 조합들의 성능을 기반으로 성능이 잘 나오는 조합들을 중심으로 확률적으로 탐색합니다.
- 랜덤 서치보다 상대적으로 똑똑하고 효율적으로 탐색하는 방법으로, 한정된 자원 내에서 좋은 하이퍼파라미터 조합을 발견할 가능성이 더 높습니다.
sklearn에서는 이 기능을 제공하지 않으며, 일반적으로hyperopt등의 라이브러리를 추가 사용해서 탐색을 진행하게 됩니다.
선형회귀, 랜덤포레스트 하이퍼파라미터 튜닝 추천
- Random Forest
- class_weight (불균형(imbalanced) 클래스인 경우)
- max_depth (너무 깊어지면 과적합)
- n_estimators (적을경우 과소적합, 높을경우 긴 학습시간)
- min_samples_leaf (과적합일경우 높임)
- max_features (줄일 수록 다양한 트리생성)
- Logistic Regression
- C (Inverse of regularization strength)
- class_weight (불균형 클래스인 경우)
- penalty
- Ridge / Lasso Regression
- alpha

ENTJ 데이터 분석가 준비중입니다:)