정규화
기본 정의
- 관계형 데이터베이스 설계에서 중복을 최소화하기 위해 데이터를 구조화하는 프로세스.
정규화(Normalization)의 목표
데이터베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것
- 크고, 제대로 조직되지 않은 테이블들과 관계들을 작고 잘 조직된 테이블과 관계들로 나누는 것
- 하나의 테이블에서의 데이터의 삽입, 삭제, 변경이 정의된 관계들로 인하여 데이터베이스의 나머지 부분들로 전파되게 하는 것
정규화의 특징
1 데이터 중복 제거 ( 테이블 분해 )
2 무결성 형성
3 DB 저장 용량 최소화
단 현업에서는 데이터의 과도한 조인과 데이터의 세부적인 변경사항 때문에 역정규화된 구조도 종종 사용한다.
이상현상(Anomaly)
데이터 중복 저장으로 발생하는 문제
삽입 이상
신규 데이터 삽입을 위해서 불필요한 데이터를 입력
갱신 이상
중복 데이터 변경 중 일부만 변경해 데이터 불일치 발생
삭제 이상
삭제되면 안되는 데이터도 같이 삭제되는 경우
제 1(원자) 정규화
정의
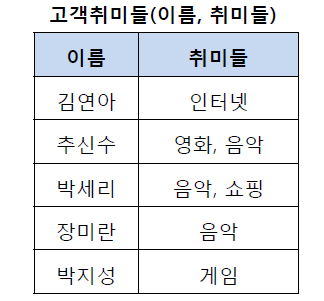
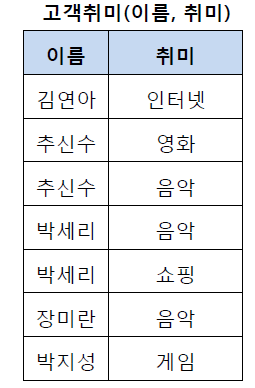
- 테이블의 컬럼이 1원자값(Atomic Value, 하나의 값)을 갖도록 테이블을 분해하는 것
필요한 경우
- 원자값이 아닌 경우 반복되는 데이터가 계속해서 등장해서 쓸데없는 공간 낭비 + 관리도 어렵다.
1N 전
1N 후
제 2(PrimaryKey:1) 정규화
기본 정의
- 데이터를 묶어주는 대표자와 각자 묶여 있어야지 대표 2명 이상이 같은 공간에서 여러 무리를 관리하면 안된다!
- 기본키 컬럼이 아닌 컬럼 후보들은 모두 연관된 기본키에 종속 되어야함
심화 정의
- 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것
완전 함수 종속이라는 것은 기본키의 부분집합이 결정자가 되어선 안된다는 것
필요한 경우
- 기본키 후보들이 다른 특성의 데이터와 함꼐 한 테이븖에 있으면 데이터 해석의 직관성도 떨어지고 관계 생성도 복잡해진다. 마치 회사/사회 조직도 다른 기능을 하는 부서끼리 같이 묶여 있으면 역할 구분이 명확하지 않고 효율성이 떨어지듯이 데이터는 조직화가 필요하다.
2N 전
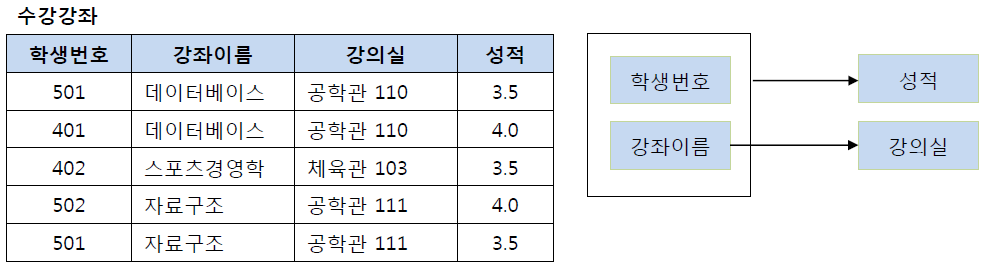
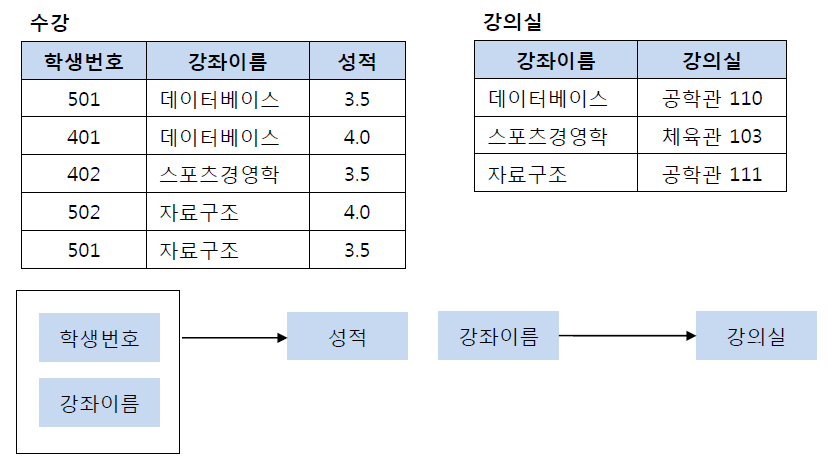
여기서 기본키는 (학생번호, 강좌이름)으로 복합키이고 강의실을 결정하고 있다. 근데 기본키의 부분집합인 강좌이름에 의해서도 강의실이 결정될 수 있다. 그래서 분해가 필요하다.
2N 후
제 3(A-B-C, A!=C) 정규화
제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것
이행적 종속이라는 것은 A -> B, B -> C가 성립할 때 A -> C가 성립되는 것
이행적 종속이 있으면
501번 학생이 자료구조로 강의를 변경하면 수강료도 바꿔야하는 번거로움이 발생한다.
3N 전
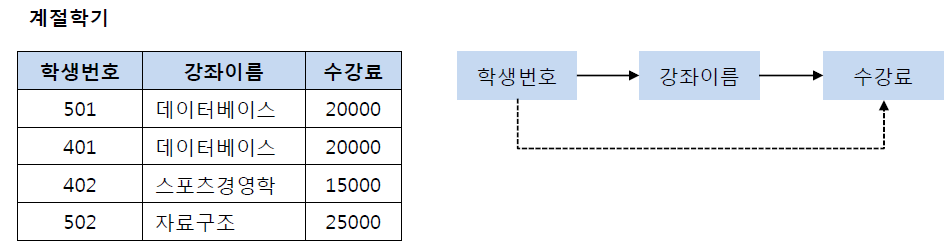
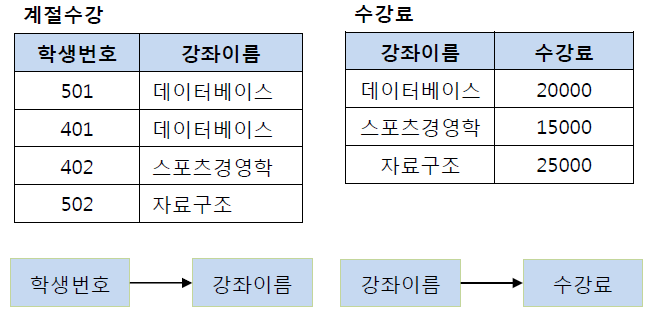
3N 후
BCNF 정규화
Boyce-Codd Normal Form
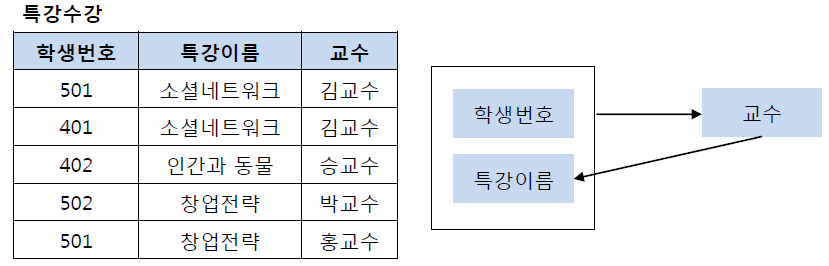
제3 정규화를 진행한 테이블에 대해 모든 결정자 (어떤 애트리뷰트의 값이 다른 애트리뷰트의 값을 고유하게 결정할 수 있음)가 후보키가 되도록 테이블을 분해하는 것
BCNF 전
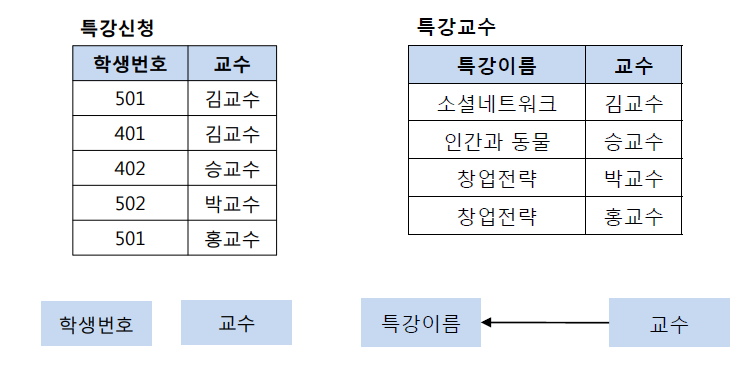
BCNF 후
출처
https://mangkyu.tistory.com/110
https://mr-dan.tistory.com/10
https://ko.wikipedia.org/wiki/%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4_%EC%A0%95%EA%B7%9C%ED%99%94
https://brownbears.tistory.com/542
