시스템-네트워크-OSI(open systems interconnection) 참조 모델
순 기능
Open System :
Interconnection : 연결된
OSI(개방형 시스템 상호 연결) 모델의 목적은 네트워크 프로토콜과 시스템을 이해, 설계 및 구현하기 위한 표준화된 프레임워크를 제공. 1970년대 말과 1980년대 초에 국제 표준화 기구(ISO)에서 개발한 OSI 모델은 네트워크 통신의 복잡한 프로세스를 각각 특정 기능 집합을 가진 7개의 계층으로 나눔.
OSI 모델의 주요 목표
상호 운용성 촉진:
OSI 모델은 공통 참조 모델을 제공해 제조업체나 사용되는 특정 기술에 관계없이 다양한 네트워크 하드웨어 및 소프트웨어 구성 요소가 함께 작동하고 효과적으로 통신할 수 있도록 지원
모듈식 설계:
separation of concern. 계층화된 아키텍처를 통해 separation of concern으로 네트워크 설계자와 개발자가 통신 프로세스의 특정 측면에 더 쉽게 집중할 수 있습니다. 이런 모듈성을 통해 전체 시스템을 수정할 필요 없이 개별 레이어를 독립적으로 개발하고 업그레이드할 수 있음.
문제 해결 간소화:
레이어 식별. OSI 모델은 문제가 발생할 수 있는 특정 레이어를 식별할 수 있는 구조화된 프레임워크를 제공하여 네트워크 관리자와 엔지니어가 네트워크 문제를 진단하고 해결하는 데 도움을 준다.
표준화 촉진:
국제 표준 개발. OSI 모델은 네트워크 통신에 대한 국제 표준 개발의 기반이 되어 업계 전반에서 일관된 프로토콜과 기술을 사용할 수 있도록 한다.
OSI 모델 응용
네트워크 관리자인데 조직의 사용자가 특정 웹사이트에 액세스할 수 없다고 보고한다고 가정.
문제의 근본 원인을 체계적으로 해결하고 파악하기 위해 OSI 모델을 프레임워크로 사용하기로 결정. 다음은 계층별로 문제에 접근하는 방법:
물리적 계층(계층 1):
먼저 네트워크 장치(예: 스위치, 라우터, 케이블)가 제대로 연결되어 있고 전원이 켜져 있으며 제대로 작동하는지 확인합니다. 케이블이 손상되었거나 연결이 느슨하지 않은지 살펴보세요. 이 계층에서 모든 것이 정상으로 보이면 다음 계층으로 이동합니다.
데이터 링크 레이어(레이어 2):
스위치가 MAC 주소를 기반으로 데이터 패킷을 올바르게 전달하고 있는지 확인합니다. 잘못 구성된 VLAN, NIC(네트워크 인터페이스 카드) 문제 또는 기타 데이터 링크 관련 문제가 있는지 확인합니다. 문제가 발견되지 않으면 다음 계층으로 계속 진행합니다.
네트워크 계층(계층 3):
라우터가 IP 주소를 기반으로 데이터 패킷을 올바르게 라우팅하고 있는지 확인합니다. 라우팅 테이블 항목이 잘못되었거나 해당 웹사이트로의 트래픽을 차단할 수 있는 액세스 제어 목록(ACL)이 있는지 확인하세요. 또한 장치에 IP 주소와 서브넷 마스크가 올바르게 구성되어 있는지 확인하세요. 이 계층에서 모든 것이 정상으로 보이면 다음 계층으로 진행합니다.
전송 레이어(레이어 4):
웹사이트와의 통신에 영향을 줄 수 있는 TCP 또는 UDP와 같은 전송 프로토콜에 문제가 있는지 확인합니다. 예를 들어, 적절한 포트가 열려 있는지, 방화벽이 필요한 트래픽을 차단하고 있지 않은지 확인합니다. 이 계층에서 문제가 발견되지 않으면 다음 계층으로 이동합니다.
세션 레이어(레이어 5):
사용자 디바이스와 웹사이트 서버 간에 세션을 설정, 유지 또는 종료하는 데 문제가 있는지 조사합니다. 이 계층이 문제의 원인이 될 가능성은 낮지만 모든 가능성을 염두에 두고 확인하는 것이 좋습니다.
프레젠테이션 레이어(레이어 6):
전송되는 데이터가 적절한 형식과 인코딩 또는 암호화되어 있는지 검사합니다. 이 계층에서 문제가 발생하는 경우는 비교적 드물지만 모든 잠재적 원인을 고려하는 것이 중요합니다.
애플리케이션 레이어(레이어 7):
마지막으로 문제가 웹 브라우저 또는 프록시 설정과 같이 사용 중인 특정 애플리케이션이나 소프트웨어와 관련이 있는지 확인합니다. 브라우저 캐시를 지우거나 브라우저를 업데이트하거나 다른 브라우저에서 웹사이트에 접속하여 문제가 지속되는지 확인합니다.
OSI 모델의 각 계층을 체계적으로 살펴보고 잠재적인 문제를 확인하면 문제의 근본 원인을 파악하고 적절한 해결책을 구현할 수 있습니다. 이 예제에서는 레이어 3의 라우터에서 웹사이트에 대한 액세스를 차단하는 잘못된 ACL을 발견했다고 가정해 보겠습니다. ACL을 수정하면 문제를 해결하고 웹사이트에 대한 사용자의 액세스를 복원할 수 있습니다.
- 네트워크 기능을 구분해서 (ISO에서 정함) 네트워크 관련 이슈 발생시 문제 범위를 좁힐 수 있음
Mnemonics
PD Newton's Tv Series Prison Architect
호스트 영역
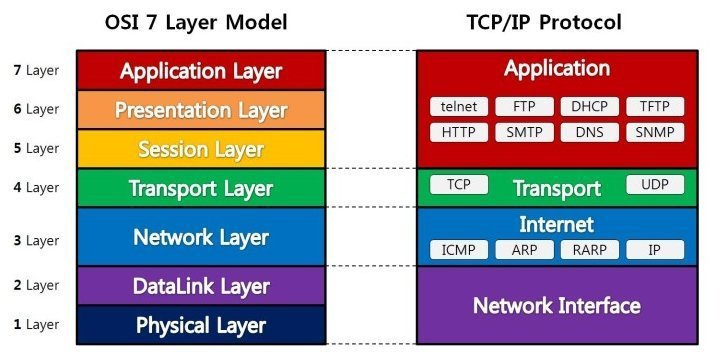
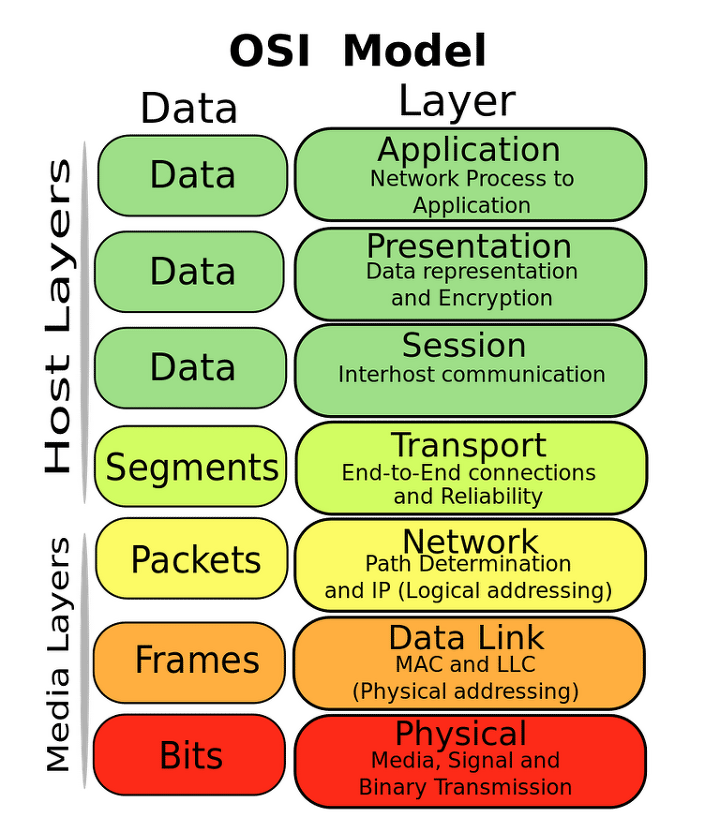
브라우저-프로그램 UI-응용 계층 Application
기본 정의 :
- 사용 중인 브라우저, 메일 프로그램 등에 UI(사용자 인터페이스)를 만들어 사용자가 서비스를 쉽게 쓸 수 있게 해주는 응용 프로그램.
- 응용 서비스 역할을 해주는 영역.
추가 정의
- 통신 패킷 처리는 SMTP(이메일 프로토콜), FTP(파일 전송 프로토콜), HTTP(하이퍼텍스트 전송 프로토콜), Telnet 등의 프로토콜에 의해서 모두 처리된다.
- 사용자가 OSI 환경에 접근할 수 있는 서비스 제공. - Interacts with sw application
정보 인코딩-표현 계층 Presentation
기본 정의 :
- 통신에 적합한 형태로 바꾸는(인코딩, 암호화) 영역.
- 이후 데이터를 세션 계층에 보냄.
추가 정의
- MIME 인코딩, 암호화 등의 작업을 함.
- EBDIC로 인코딩된 문서 파일을 ASCII 인코딩으로 변경
- 데이터가 TEXT, GIF, JPG인지 타입인지 구분
- Translate data for application layer based on syntax/semantics application accepts.
통신 유지-세션 계층 Session
기본 정의 :
- 데이터 통신/대화 제어 담당.
- 응용 프로세스가 통신을 관리하기 위한 방법을 제공.
추가 정의
- 동시 송수신 방식 duplex, half-duplex, full duplex 통신 등이 있으며, 체크 포인팅, 종료, 다시 시작 등의 과정을 수행한다.
- TCP/IP 세션을 만들고 없엔다.
- 송수신 측 간의 관련성을 유지하고 대화 제어를 당담.
- Controls conversations between different computers.
통신 형식,목적지 검증-전송 계층 Transport
기본 정의 :
- 네트워크에서 전송된 데이터의 유효성을 점검하고 (실패시 패킷을 다시 전송하고) 목적지가 어떤 애플리케이션인지 식별.
- (예) TCP를 사용해 포트를 열어 응용프로그램들이 전송할 수 있게 해줌.
추가 정의
- 대표적인 프로토콜로는 TCP(Transmission Control Protocol)
- TCP는 신뢰성있는 연결지향적인 프로토콜이고 UDP는 낮은 신뢰성이고 비연결성이지만 멀티캐스팅이 가능하고 실시간 응용 및 단순한 해더를 제공한다.
- 논리적 안정과 균일한 데이터 전송 서비스 제공.
- Manage delivery and error checking of data packets. TCP
https://www.notion.so/9f4aa2eb023546f9b837f3e8f7b0c1f9
미디어 영역
통신 장비-논리적 소통-네트워크 계층 Network
기본 정의 :
- 네트워크끼리의 데이터 전송/통신을 담당.
- 네트워크는 장비 사이의 신호를 주고 받을 때 형성됨.
추가 정의
-
데이터를 목적지까지 가장 안전하고 빠르게 전달하는 라우팅이라는 기능을 사용.
-
안전한 데이터 전송을 위해 라우팅, 흐름제어, 세그멘테이션, 인터네트워킹 역할을 수행.
-
라우터로 연결된 네트워크 집합을 인터네트워크(Internetwork)라 하며 이 중 가장 유명한 것이 인터넷(Internet).
-
대표적인 장비로는 라우터가 있으며, 프로토콜은 IP(Internet Protocol)을 사용함.
-
개방 시스템들 간의 네트워크 연결을 관리하는 기능과 데이터의 교환 및 중계.
-
Receive frame from data-link layer and deliver them to intended destination based on address inside the frame.
-
Finds destination by using logical addreses such as IP
https://www.notion.so/a3c1bf345880405d93471d5bd3c5b15f
통신 장비-물리적 소통-데이터 링크 계층 Data-link
기본 정의 :
- 물리적인 영역에서 장비 사이의 연결과 신호를 전송했을 때 전송된 신호를 어떻게 해석해서 전달할지 결정.
- 각 컴퓨터가 갖고 있는 고유 주소(MAC)을 확인하고 오류를 감지.
추가 정의
- 정보의 전달을 수행할 수 있도록 도와주는 역할.
- 각 컴퓨터의 물리적 주소(MAC 주소)를 확인하고 오류를 감지.
- 대표적인 장비로는 브릿지와 스위치가 (MAC주소 사용) 있으며 프로토콜로는 이더넷(Ethernet).
- 두 개의 인접한 개방 시스템 간에 신뢰성 있고 효율적인 정보 전송.
- 송신측과 수신 측의 속도 차이를 해결하기 위한 흐름 제어.
- 프레임 동기화
- Transfer data from node-to-node packaged into frames. (corrects errors)
https://www.notion.so/efd3b20719a44fbaaa60984534dd2dde
통신 장비-연결-물리 계층 Physical
기본 정의 :
- 컴퓨터가 서로 연결하는 물리적인 장비와 주소가 있는 영역.
- 프로토콜은 없음
- 각 장비가 디지털 신호를 어떻게 전송할지 포함.
추가 정의
- 컴퓨터를 서로 연결하는 물리 장비
- 무엇을 통해 어떻게 신호를 전송하는지 정의만 하며 데이터가 뭔지 어떤 에러가 있는지는 신경 안쓴다.
- 물리적 전송 매체와 전송 신호 방식 정의.
- 통신 케이블, 리피터, 허브 등의 장비가 있다.
https://www.notion.so/23d54dc247114061a543aa1a9aa6f5ce
OS Interview 질문
프로세스(Process)
기본 정의
- CPU에서 할당 받아서 시스템 메모리에 적재되어 실행 중인 프로그램.
- 운영체제로가 주소 공간, 파일, 메모리 등을 할당해 주고 이것들을 총칭한 명칭
추가 정의
- 함수의 매개변수, 복귀 주소와 로컬 변수와 같은 임시 자료를 갖는 프로세스 스택과 전역 변수들을 수록하는 데이터 섹션.
- 프로세스는 프로세스 실행 중에 동적으로 할당되는 메모리인 힙을 포함.
프로세스 제어 블록(Process Control Block, PCB)
기본 정의
- 특정 프로세스에 대한 중요한 정보를 저장 하고 있는 운영체제의 자료구조.
- 운영체제는 프로세스를 관리하기 위해 프로세스의 생성과 동시에 고유한 PCB 를 생성.
추가 정의
- 프로세스는 CPU를 할당받아 작업을 처리하다가도 프로세스 전환이 발생하면 진행하던 작업을 저장하고 CPU 를 반환해야 하는데, 이때 작업의 진행 상황을 모두 PCB 에 저장.
- 다시 CPU 를 할당받게 되면 PCB에 저장되어있던 내용을 불러와 이전에 종료됐던 시점부터 다시 작업을 수행.
PCB 에 저장되는 정보
기본 정의
- 프로세스 식별자, 상태, 카운터, 레지스터
추가 정의
- 프로세스 식별자(Process ID, PID) : 프로세스 식별번호
- 프로세스 상태 : new, ready, running, waiting, terminated 등의 상태를 저장
- 프로그램 카운터 : 프로세스가 다음에 실행할 명령어의 주소
CPU 레지스터
- CPU 스케쥴링 정보 : 프로세스의 우선순위, 스케줄 큐에 대한 포인터 등
- 메모리 관리 정보 : 페이지 테이블 또는 세그먼트 테이블 등과 같은 정보를 포함
- 입출력 상태 정보 : 프로세스에 할당된 입출력 장치들과 열린 파일 목록
- 어카운팅 정보 : 사용된 CPU 시간, 시간제한, 계정번호 등
프로세스-단위-스레드(Thread)
기본 정의
- 프로세스의 실행 단위.
- 한 프로세스 내에서 동작되는 여러 실행 흐름, 프로세스 내의 주소 공간이나 자원 공유가 가능.
- 스레드 ID, 프로그램 카운터, 레지스터 집합, 그리고 스택으로 구성.
추가 정의
- 같은 프로세스에 속한 다른 스레드와 코드, 데이터 섹션, 그리고 열린 파일이나 신호와 같은 운영체제 자원들을 공유.
멀티 스레딩
멀티 : 자원을 공유하는 다수
스레딩 : 실행 단위
- 하나의 프로세스를 다수의 실행 단위로 구분하여 자원을 공유하고 자원의 생성과 관리의 중복성을 최소화하여 수행 능력을 향상시키는 것.
- 이 경우 각각의 스레드는 독립적인 작업을 수행해야 하기 때문에 각자의 스택과 PC 레지스터 값을 갖고 있다.
스택을 스레드마다 독립적으로 할당하는 이유
스택 : 함수, 변수 임시 저장 공간
- 스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하는 메모리 공간이므로 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것이고 이는 독립적인 실행 흐름이 추가되는 것이다.
- 따라서 스레드의 정의에 따라 독립적인 실행 흐름을 추가하기 위한 최소 조건으로 독립된 스택을 할당한다.
PC Register 를 스레드마다 독립적으로 할당하는 이유
- PC 값은 스레드가 명령어의 어디까지 수행하였는지를 나타나게 된다.
- 스레드는 CPU 를 할당받았다가 스케줄러에 의해 다시 선점당한다.
- 그렇기 때문에 명령어가 연속적으로 수행되지 못하고 어느 부분까지 수행했는지 기억할 필요가 있다.
- 따라서 PC 레지스터를 독립적으로 할당한다.
멀티 스레드
멀티 스레딩의 장점
- 프로세스를 이용하여 동시에 처리하던 일을 스레드로 구현할 경우 메모리 공간과 시스템 자원 소모가 줄어든다.
- 스레드 간의 통신이 필요한 경우에도 별도의 자원을 이용하는 것이 아니라 전역 변수의 공간 또는 동적으로 할당된 공간인 Heap 영역을 이용하여 데이터를 주고받을 수 있다.
- 그렇기 때문에 프로세스 간 통신 방법에 비해 스레드 간의 통신 방법이 훨씬 간단하다. 심지어 스레드의 context switch 는 프로세스 context switch 와는 달리 캐시 메모리를 비울 필요가 없기 때문에 더 빠르다.
- 따라서 시스템의 throughtput 이 향상되고 자원 소모가 줄어들며 자연스럽게 프로그램의 응답 시간이 단축된다.
- 이러한 장점 때문에 여러 프로세스로 할 수 있는 작업들을 하나의 프로세스에서 스레드로 나눠 수행하는 것이다.
멀티 스레딩의 문제점
-
멀티 프로세스 기반으로 프로그래밍할 때는 프로세스 간 공유하는 자원이 없기 때문에 동일한 자원에 동시에 접근하는 일이 없었지만 멀티 스레딩을 기반으로 프로그래밍할 때는 이 부분을 신경써줘야 한다.
서로 다른 스레드가 데이터와 힙 영역을 공유하기 때문에 어떤 스레드가 다른 스레드에서 사용중인 변수나 자료구조에 접근하여 엉뚱한 값을 읽어오거나 수정할 수 있다. -
그렇기 때문에 멀티스레딩 환경에서는 동기화 작업이 필요하다.
-
동기화를 통해 작업 처리 순서를 컨트롤 하고 공유 자원에 대한 접근을 컨트롤 하는 것이다.
-
하지만 이로 인해 병목현상이 발생하여 성능이 저하될 가능성이 높다.
-
그러므로 과도한 락으로 인한 병목현상을 줄여야 한다.
멀티 스레드 vs 멀티 프로세스
- 멀티 스레드는 멀티 프로세스보다 적은 메모리 공간을 차지하고 문맥 전환이 빠르다는 장점이 있지만,
- 오류로 인해 하나의 스레드가 종료되면 전체 스레드가 종료될 수 있다는 점과 동기화 문제를 안고 있다.
- 반면 멀티 프로세스 방식은 하나의 프로세스가 죽더라도 다른 프로세스에는 영향을 끼치지 않고 정상적으로 수행된다는 장점이 있지만, 멀티 스레드보다 많은 메모리 공간과 CPU 시간을 차지한다는 단점이 존재한다.
- 이 두 가지는 동시에 여러 작업을 수행한다는 점에서 같지만 적용해야 하는 시스템에 따라 적합/부적합이 구분된다.
- 따라서 대상 시스템의 특징에 따라 적합한 동작 방식을 선택하고 적용해야 한다.
프로세스-스케줄러
- 프로세스를 스케줄링하기 위한 Queue 에는 세 가지 종류가 존재한다.
Job Queue :
현재 시스템 내에 있는 모든 프로세스의 집합
Ready Queue :
현재 메모리 내에 있으면서 CPU 를 잡아서 실행되기를 기다리는 프로세스의 집합
Device Queue :
Device I/O 작업을 대기하고 있는 프로세스의 집합
각각의 Queue 에 프로세스들을 넣고 빼주는 스케줄러에도 크게 세 가지 종류가 존재한다.
장기스케줄러(Long-term scheduler or job scheduler)
- 메모리는 한정되어 있는데 많은 프로세스들이 한꺼번에 메모리에 올라올 경우, 대용량 메모리(일반적으로 디스크)에 임시로 저장된다.
- 이 pool 에 저장되어 있는 프로세스 중 어떤 프로세스에 메모리를 할당하여 ready queue 로 보낼지 결정하는 역할을 한다.
메모리와 디스크 사이의 스케줄링을 담당.
프로세스에 memory(및 각종 리소스)를 할당(admit)
degree of Multiprogramming 제어
(실행중인 프로세스의 수 제어)
프로세스의 상태
new -> ready(in memory)
cf) 메모리에 프로그램이 너무 많이 올라가도, 너무 적게 올라가도 성능이 좋지 않은 것이다. 참고로 time sharing system 에서는 장기 스케줄러가 없다. 그냥 곧바로 메모리에 올라가 ready 상태가 된다.
단기스케줄러(Short-term scheduler or CPU scheduler)
CPU 와 메모리 사이의 스케줄링을 담당.
Ready Queue 에 존재하는 프로세스 중 어떤 프로세스를 running 시킬지 결정.
프로세스에 CPU 를 할당(scheduler dispatch)
프로세스의 상태
ready -> running -> waiting -> ready
중기스케줄러(Medium-term scheduler or Swapper)
여유 공간 마련을 위해 프로세스를 통째로 메모리에서 디스크로 쫓아냄 (swapping)
프로세스에게서 memory 를 deallocate
degree of Multiprogramming 제어
현 시스템에서 메모리에 너무 많은 프로그램이 동시에 올라가는 것을 조절하는 스케줄러.
프로세스의 상태
ready -> suspended
Process state - suspended
Suspended(stopped) : 외부적인 이유로 프로세스의 수행이 정지된 상태로 메모리에서 내려간 상태를 의미한다. 프로세스 전부 디스크로 swap out 된다. blocked 상태는 다른 I/O 작업을 기다리는 상태이기 때문에 스스로 ready state 로 돌아갈 수 있지만 이 상태는 외부적인 이유로 suspending 되었기 때문에 스스로 돌아갈 수 없다.
뒤로/위로
CPU 스케줄러
스케줄링 대상은 Ready Queue 에 있는 프로세스들이다.
FCFS(First Come First Served)
특징
먼저 온 고객을 먼저 서비스해주는 방식, 즉 먼저 온 순서대로 처리.
비선점형(Non-Preemptive) 스케줄링
일단 CPU 를 잡으면 CPU burst 가 완료될 때까지 CPU 를 반환하지 않는다. 할당되었던 CPU 가 반환될 때만 스케줄링이 이루어진다.
문제점
convoy effect
소요시간이 긴 프로세스가 먼저 도달하여 효율성을 낮추는 현상이 발생한다.
SJF(Shortest - Job - First)
특징
다른 프로세스가 먼저 도착했어도 CPU burst time 이 짧은 프로세스에게 선 할당
비선점형(Non-Preemptive) 스케줄링
문제점
starvation
효율성을 추구하는게 가장 중요하지만 특정 프로세스가 지나치게 차별받으면 안되는 것이다. 이 스케줄링은 극단적으로 CPU 사용이 짧은 job 을 선호한다. 그래서 사용 시간이 긴 프로세스는 거의 영원히 CPU 를 할당받을 수 없다.
SRTF(Shortest Remaining Time First)
특징
새로운 프로세스가 도착할 때마다 새로운 스케줄링이 이루어진다.
선점형 (Preemptive) 스케줄링
현재 수행중인 프로세스의 남은 burst time 보다 더 짧은 CPU burst time 을 가지는 새로운 프로세스가 도착하면 CPU 를 뺏긴다.
문제점
starvation
새로운 프로세스가 도달할 때마다 스케줄링을 다시하기 때문에 CPU burst time(CPU 사용시간)을 측정할 수가 없다.
Priority Scheduling
특징
우선순위가 가장 높은 프로세스에게 CPU 를 할당하는 스케줄링이다. 우선순위란 정수로 표현하게 되고 작은 숫자가 우선순위가 높다.
선점형 스케줄링(Preemptive) 방식
더 높은 우선순위의 프로세스가 도착하면 실행중인 프로세스를 멈추고 CPU 를 선점한다.
비선점형 스케줄링(Non-Preemptive) 방식
더 높은 우선순위의 프로세스가 도착하면 Ready Queue 의 Head 에 넣는다.
문제점
starvation
무기한 봉쇄(Indefinite blocking)
실행 준비는 되어있으나 CPU 를 사용못하는 프로세스를 CPU 가 무기한 대기하는 상태
해결책
aging
아무리 우선순위가 낮은 프로세스라도 오래 기다리면 우선순위를 높여주자.
Round Robin
특징
현대적인 CPU 스케줄링
각 프로세스는 동일한 크기의 할당 시간(time quantum)을 갖게 된다.
할당 시간이 지나면 프로세스는 선점당하고 ready queue 의 제일 뒤에 가서 다시 줄을 선다.
RR은 CPU 사용시간이 랜덤한 프로세스들이 섞여있을 경우에 효율적
RR이 가능한 이유는 프로세스의 context 를 save 할 수 있기 때문이다.
장점
Response time이 빨라진다.
n 개의 프로세스가 ready queue 에 있고 할당시간이 q(time quantum)인 경우 각 프로세스는 q 단위로 CPU 시간의 1/n 을 얻는다. 즉, 어떤 프로세스도 (n-1)q time unit 이상 기다리지 않는다.
프로세스가 기다리는 시간이 CPU 를 사용할 만큼 증가한다.
공정한 스케줄링이라고 할 수 있다.
주의할 점
설정한 time quantum이 너무 커지면 FCFS와 같아진다. 또 너무 작아지면 스케줄링 알고리즘의 목적에는 이상적이지만 잦은 context switch 로 overhead 가 발생한다. 그렇기 때문에 적당한 time quantum을 설정하는 것이 중요하다.
동기와 비동기의 차이
비유를 통한 쉬운 설명
- 해야할 일(task)가 빨래, 설거지, 청소 세 가지가 있다고 가정한다. 이 일들을 동기적으로 처리한다면 빨래를 하고 설거지를 하고 청소를 한다. 비동기적으로 일을 처리한다면 빨래하는 업체에게 빨래를 시킨다. 설거지 대행 업체에 설거지를 시킨다. 청소 대행 업체에 청소를 시킨다. 셋 중 어떤 것이 먼저 완료될지는 알 수 없다. 일을 모두 마친 업체는 나에게 알려주기로 했으니 나는 다른 작업을 할 수 있다. 이 때는 백그라운드 스레드에서 해당 작업을 처리하는 경우의 비동기를 의미한다.
Sync vs Async
일반적으로 동기와 비동기의 차이는 메소드를 실행시킴과 동시에 반환 값이 기대되는 경우를 동기 라고 표현하고 그렇지 않은 경우에 대해서 비동기 라고 표현한다. 동시에라는 말은 실행되었을 때 값이 반환되기 전까지는 blocking되어 있다는 것을 의미한다. 비동기의 경우, blocking되지 않고 이벤트 큐에 넣거나 백그라운드 스레드에게 해당 task 를 위임하고 바로 다음 코드를 실행하기 때문에 기대되는 값이 바로 반환되지 않는다.
글로만 설명하기가 어려운 것 같아 그림과 함께 설명된 링크를 첨부합니다.
Reference
http://asfirstalways.tistory.com/348
프로세스 동기화
-
Critical Section(임계영역)
멀티 스레딩에 문제점에서 나오듯, 동일한 자원을 동시에 접근하는 작업(e.g. 공유하는 변수 사용, 동일 파일을 사용하는 등)을 실행하는 코드 영역을 Critical Section 이라 칭한다. -
Critical Section Problem(임계영역 문제)
프로세스들이 Critical Section 을 함께 사용할 수 있는 프로토콜을 설계하는 것이다.
Requirements(해결을 위한 기본조건)
-
Mutual Exclusion(상호 배제)
프로세스 P1 이 Critical Section 에서 실행중이라면, 다른 프로세스들은 그들이 가진 Critical Section 에서 실행될 수 없다. -
Progress(진행)
Critical Section 에서 실행중인 프로세스가 없고, 별도의 동작이 없는 프로세스들만 Critical Section 진입 후보로서 참여될 수 있다. -
Bounded Waiting(한정된 대기)
P1 가 Critical Section 에 진입 신청 후 부터 받아들여질 때가지, 다른 프로세스들이 Critical Section 에 진입하는 횟수는 제한이 있어야 한다.
해결책
Lock
하드웨어 기반 해결책으로써, 동시에 공유 자원에 접근하는 것을 막기 위해 Critical Section 에 진입하는 프로세스는 Lock 을 획득하고 Critical Section 을 빠져나올 때, Lock 을 방출함으로써 동시에 접근이 되지 않도록 한다.
한계
다중처리기 환경에서는 시간적인 효율성 측면에서 적용할 수 없다.
Semaphores(세마포)
소프트웨어상에서 Critical Section 문제를 해결하기 위한 동기화 도구
종류
OS 는 Counting/Binary 세마포를 구분한다
카운팅 세마포
가용한 개수를 가진 자원 에 대한 접근 제어용으로 사용되며, 세마포는 그 가용한 자원의 개수 로 초기화 된다. 자원을 사용하면 세마포가 감소, 방출하면 세마포가 증가 한다.
이진 세마포
MUTEX 라고도 부르며, 상호배제의 (Mutual Exclusion)의 머릿글자를 따서 만들어졌다. 이름 그대로 0 과 1 사이의 값만 가능하며, 다중 프로세스들 사이의 Critical Section 문제를 해결하기 위해 사용한다.
단점
Busy Waiting(바쁜 대기)
Spin lock이라고 불리는 Semaphore 초기 버전에서 Critical Section 에 진입해야하는 프로세스는 진입 코드를 계속 반복 실행해야 하며, CPU 시간을 낭비했었다. 이를 Busy Waiting이라고 부르며 특수한 상황이 아니면 비효율적이다. 일반적으로는 Semaphore에서 Critical Section에 진입을 시도했지만 실패한 프로세스에 대해 Block시킨 뒤, Critical Section에 자리가 날 때 다시 깨우는 방식을 사용한다. 이 경우 Busy waiting으로 인한 시간낭비 문제가 해결된다.
Deadlock(교착상태)
세마포가 Ready Queue 를 가지고 있고, 둘 이상의 프로세스가 Critical Section 진입을 무한정 기다리고 있고, Critical Section 에서 실행되는 프로세스는 진입 대기 중인 프로세스가 실행되야만 빠져나올 수 있는 상황을 지칭한다.
모니터
고급 언어의 설계 구조물로서, 개발자의 코드를 상호배제 하게끔 만든 추상화된 데이터 형태이다.
공유자원에 접근하기 위한 키 획득과 자원 사용 후 해제를 모두 처리한다. (세마포어는 직접 키 해제와 공유자원 접근 처리가 필요하다. )
뒤로/위로
메모리 관리 전략
메모리 관리 배경
각각의 프로세스 는 독립된 메모리 공간을 갖고, 운영체제 혹은 다른 프로세스의 메모리 공간에 접근할 수 없는 제한이 걸려있다. 단지, 운영체제 만이 운영체제 메모리 영역과 사용자 메모리 영역의 접근에 제약을 받지 않는다.
Swapping : 메모리의 관리를 위해 사용되는 기법. 표준 Swapping 방식으로는 round-robin 과 같은 스케줄링의 다중 프로그래밍 환경에서 CPU 할당 시간이 끝난 프로세스의 메모리를 보조 기억장치(e.g. 하드디스크)로 내보내고 다른 프로세스의 메모리를 불러 들일 수 있다.
이 과정을 swap (스왑시킨다) 이라 한다. 주 기억장치(RAM)으로 불러오는 과정을 swap-in, 보조 기억장치로 내보내는 과정을 swap-out 이라 한다. swap 에는 큰 디스크 전송시간이 필요하기 때문에 현재에는 메모리 공간이 부족할때 Swapping 이 시작된다.
단편화 (Fragmentation) : 프로세스들이 메모리에 적재되고 제거되는 일이 반복되다보면, 프로세스들이 차지하는 메모리 틈 사이에 사용 하지 못할 만큼의 작은 자유공간들이 늘어나게 되는데, 이것이 단편화 이다. 단편화는 2 가지 종류로 나뉜다.
Process A free Process B free Process C free Process D
외부 단편화: 메모리 공간 중 사용하지 못하게 되는 일부분. 물리 메모리(RAM)에서 사이사이 남는 공간들을 모두 합치면 충분한 공간이 되는 부분들이 분산되어 있을때 발생한다고 볼 수 있다.
내부 단편화: 프로세스가 사용하는 메모리 공간 에 포함된 남는 부분. 예를들어 메모리 분할 자유 공간이 10,000B 있고 Process A 가 9,998B 사용하게되면 2B 라는 차이 가 존재하고, 이 현상을 내부 단편화라 칭한다.
압축 : 외부 단편화를 해소하기 위해 프로세스가 사용하는 공간들을 한쪽으로 몰아, 자유공간을 확보하는 방법론 이지만, 작업효율이 좋지 않다. (위의 메모리 현황이 압축을 통해 아래의 그림 처럼 바뀌는 효과를 가질 수 있다)
Process A Process B Process C Process D free
Paging(페이징)
하나의 프로세스가 사용하는 메모리 공간이 연속적이어야 한다는 제약을 없애는 메모리 관리 방법이다. 외부 단편화와 압축 작업을 해소 하기 위해 생긴 방법론으로, 물리 메모리는 Frame 이라는 고정 크기로 분리되어 있고, 논리 메모리(프로세스가 점유하는)는 페이지라 불리는 고정 크기의 블록으로 분리된다.(페이지 교체 알고리즘에 들어가는 페이지)
페이징 기법을 사용함으로써 논리 메모리는 물리 메모리에 저장될 때, 연속되어 저장될 필요가 없고 물리 메모리의 남는 프레임에 적절히 배치됨으로 외부 단편화를 해결할 수 있는 큰 장점이 있다.
하나의 프로세스가 사용하는 공간은 여러개의 페이지로 나뉘어서 관리되고(논리 메모리에서), 개별 페이지는 순서에 상관없이 물리 메모리에 있는 프레임에 mapping 되어 저장된다고 볼 수 있다.
단점 :
내부 단편화 문제의 비중이 늘어나게 된다. 예를들어 페이지 크기가 1,024B 이고 프로세스 A 가 3,172B 의 메모리를 요구한다면 3 개의 페이지 프레임(1,024 * 3 = 3,072) 하고도 100B 가 남기때문에 총 4 개의 페이지 프레임이 필요한 것이다. 결론적으로 4 번째 페이지 프레임에는 924B(1,024 - 100)의 여유 공간이 남게 되는 내부 단편화 문제가 발생하는 것이다.
Segmentation(세그멘테이션)
페이징에서처럼 논리 메모리와 물리 메모리를 같은 크기의 블록이 아닌, 서로 다른 크기의 논리적 단위인 세그먼트(Segment)로 분할 사용자가 두 개의 주소로 지정(세그먼트 번호 + 변위) 세그먼트 테이블에는 각 세그먼트의 기준(세그먼트의 시작 물리 주소)과 한계(세그먼트의 길이)를 저장
단점 :
서로 다른 크기의 세그먼트들이 메모리에 적재되고 제거되는 일이 반복되다 보면, 자유 공간들이 많은 수의 작은 조각들로 나누어져 못 쓰게 될 수도 있다.(외부 단편화)
뒤로/위로
가상 메모리
다중 프로그래밍을 실현하기 위해서는 많은 프로세스들을 동시에 메모리에 올려두어야 한다. 가상메모리는 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 기법 이며, 프로그램이 물리 메모리보다 커도 된다는 주요 장점이 있다.
가상 메모리 개발 배경
실행되는 코드의 전부를 물리 메모리에 존재시켜야 했고, 메모리 용량보다 큰 프로그램은 실행시킬 수 없었다. 또한, 여러 프로그램을 동시에 메모리에 올리기에는 용량의 한계와, 페이지 교체등의 성능 이슈가 발생하게 된다. 또한, 가끔만 사용되는 코드가 차지하는 메모리들을 확인할 수 있다는 점에서, 불필요하게 전체의 프로그램이 메모리에 올라와 있어야 하는게 아니라는 것을 알 수 있다.
프로그램의 일부분만 메모리에 올릴 수 있다면...
물리 메모리 크기에 제약받지 않게 된다.
더 많은 프로그램을 동시에 실행할 수 있게 된다. 이에 따라 응답시간은 유지되고, CPU 이용률과 처리율은 높아진다.
swap에 필요한 입출력이 줄어들기 때문에 프로그램들이 빠르게 실행된다.
가상 메모리가 하는 일
가상 메모리는 실제의 물리 메모리 개념과 사용자의 논리 메모리 개념을 분리한 것으로 정리할 수 있다. 이로써 작은 메모리를 가지고도 얼마든지 큰 가상 주소 공간을 프로그래머에게 제공할 수 있다.
가상 주소 공간
한 프로세스가 메모리에 저장되는 논리적인 모습을 가상메모리에 구현한 공간이다. 프로세스가 요구하는 메모리 공간을 가상메모리에서 제공함으로서 현재 직접적으로 필요치 않은 메모리 공간은 실제 물리 메모리에 올리지 않는 것으로 물리 메모리를 절약할 수 있다.
예를 들어, 한 프로그램이 실행되며 논리 메모리로 100KB 가 요구되었다고 하자. 하지만 실행까지에 필요한 메모리 공간(Heap영역, Stack 영역, 코드, 데이터)의 합이 40KB 라면, 실제 물리 메모리에는 40KB 만 올라가 있고, 나머지 60KB 만큼은 필요시에 물리메모리에 요구한다고 이해할 수 있겠다.
Stack free (60KB) Heap Data Code
프로세스간의 페이지 공유
가상 메모리는...
시스템 라이브러리가 여러 프로세스들 사이에 공유될 수 있도록 한다. 각 프로세스들은 공유 라이브러리를 자신의 가상 주소 공간에 두고 사용하는 것처럼 인식하지만, 라이브러리가 올라가있는 물리 메모리 페이지들은 모든 프로세스에 공유되고 있다.
프로세스들이 메모리를 공유하는 것을 가능하게 하고, 프로세스들은 공유 메모리를 통해 통신할 수 있다. 이 또한, 각 프로세스들은 각자 자신의 주소 공간처럼 인식하지만, 실제 물리 메모리는 공유되고 있다.
fork()를 통한 프로세스 생성 과정에서 페이지들이 공유되는 것을 가능하게 한다.
Demand Paging(요구 페이징)
프로그램 실행 시작 시에 프로그램 전체를 디스크에서 물리 메모리에 적재하는 대신, 초기에 필요한 것들만 적재하는 전략을 요구 페이징이라 하며, 가상 메모리 시스템에서 많이 사용된다. 그리고 가상 메모리는 대개 페이지로 관리된다. 요구 페이징을 사용하는 가상 메모리에서는 실행과정에서 필요해질 때 페이지들이 적재된다. 한 번도 접근되지 않은 페이지는 물리 메모리에 적재되지 않는다.
프로세스 내의 개별 페이지들은 페이저(pager)에 의해 관리된다. 페이저는 프로세스 실행에 실제 필요한 페이지들만 메모리로 읽어 옮으로서, 사용되지 않을 페이지를 가져오는 시간낭비와 메모리 낭비를 줄일 수 있다.
Page fault trap(페이지 부재 트랩)
페이지 교체
요구 페이징 에서 언급된대로 프로그램 실행시에 모든 항목이 물리 메모리에 올라오지 않기 때문에, 프로세스의 동작에 필요한 페이지를 요청하는 과정에서 page fault(페이지 부재)가 발생하게 되면, 원하는 페이지를 보조저장장치에서 가져오게 된다. 하지만, 만약 물리 메모리가 모두 사용중인 상황이라면, 페이지 교체가 이뤄져야 한다.(또는, 운영체제가 프로세스를 강제 종료하는 방법이 있다.)
기본적인 방법
물리 메모리가 모두 사용중인 상황에서의 메모리 교체 흐름이다.
디스크에서 필요한 페이지의 위치를 찾는다
빈 페이지 프레임을 찾는다.
페이지 교체 알고리즘을 통해 희생될(victim) 페이지를 고른다.
희생될 페이지를 디스크에 기록하고, 관련 페이지 테이블을 수정한다.
새롭게 비워진 페이지 테이블 내 프레임에 새 페이지를 읽어오고, 프레임 테이블을 수정한다.
사용자 프로세스 재시작
페이지 교체 알고리즘
FIFO 페이지 교체
가장 간단한 페이지 교체 알고리즘으로 FIFO(first-in first-out)의 흐름을 가진다. 즉, 먼저 물리 메모리에 들어온 페이지 순서대로 페이지 교체 시점에 먼저 나가게 된다는 것이다.
장점
이해하기도 쉽고, 프로그램하기도 쉽다.
단점
오래된 페이지가 항상 불필요하지 않은 정보를 포함하지 않을 수 있다(초기 변수 등)
처음부터 활발하게 사용되는 페이지를 교체해서 페이지 부재율을 높이는 부작용을 초래할 수 있다.
Belady의 모순: 페이지를 저장할 수 있는 페이지 프레임의 갯수를 늘려도 되려 페이지 부재가 더 많이 발생하는 모순이 존재한다.
최적 페이지 교체(Optimal Page Replacement)
Belady의 모순을 확인한 이후 최적 교체 알고리즘에 대한 탐구가 진행되었고, 모든 알고리즘보다 낮은 페이지 부재율을 보이며 Belady의 모순이 발생하지 않는다. 이 알고리즘의 핵심은 앞으로 가장 오랫동안 사용되지 않을 페이지를 찾아 교체하는 것이다. 주로 비교 연구 목적을 위해 사용한다.
장점
알고리즘 중 가장 낮은 페이지 부재율을 보장한다.
단점
구현의 어려움이 있다. 모든 프로세스의 메모리 참조의 계획을 미리 파악할 방법이 없기 때문이다.
LRU 페이지 교체(LRU Page Replacement)
LRU: Least-Recently-Used
최적 알고리즘의 근사 알고리즘으로, 가장 오랫동안 사용되지 않은 페이지를 선택하여 교체한다.
특징
대체적으로 FIFO 알고리즘보다 우수하고, OPT알고리즘보다는 그렇지 못한 모습을 보인다.
LFU 페이지 교체(LFU Page Replacement)
LFU: Least Frequently Used
참조 횟수가 가장 적은 페이지를 교체하는 방법이다. 활발하게 사용되는 페이지는 참조 횟수가 많아질 거라는 가정에서 만들어진 알고리즘이다.
특징
어떤 프로세스가 특정 페이지를 집중적으로 사용하다, 다른 기능을 사용하게되면 더 이상 사용하지 않아도 계속 메모리에 머물게 되어 초기 가정에 어긋나는 시점이 발생할 수 있다
최적(OPT) 페이지 교체를 제대로 근사하지 못하기 때문에, 잘 쓰이지 않는다.
MFU 페이지 교체(MFU Page Replacement)
MFU: Most Frequently Used
참조 회수가 가장 작은 페이지가 최근에 메모리에 올라왔고, 앞으로 계속 사용될 것이라는 가정에 기반한다.
특징
최적(OPT) 페이지 교체를 제대로 근사하지 못하기 때문에, 잘 쓰이지 않는다.
뒤로/위로
캐시
캐시의 지역성 원리
캐시 메모리는 속도가 빠른 장치와 느린 장치간의 속도차에 따른 병목 현상을 줄이기 위한 범용 메모리이다. 이러한 역할을 수행하기 위해서는 CPU 가 어떤 데이터를 원할 것인가를 어느 정도 예측할 수 있어야 한다. 캐시의 성능은 작은 용량의 캐시 메모리에 CPU 가 이후에 참조할, 쓸모 있는 정보가 어느 정도 들어있느냐에 따라 좌우되기 때문이다.
이 때 적중율(Hit rate)을 극대화 시키기 위해 데이터 지역성(Locality)의 원리를 사용한다. 지역성의 전제조건으로 프로그램은 모든 코드나 데이터를 균등하게 Access 하지 않는다는 특성을 기본으로 한다. 즉, Locality란 기억 장치 내의 정보를 균일하게 Access 하는 것이 아닌 어느 한 순간에 특정 부분을 집중적으로 참조하는 특성인 것이다.
이 데이터 지역성은 대표적으로 시간 지역성(Temporal Locality)과 공간 지역성(Spatial Locality)으로 나뉜다.
시간 지역성 : 최근에 참조된 주소의 내용은 곧 다음에 다시 참조되는 특성.
공간 지역성 : 대부분의 실제 프로그램이 참조된 주소와 인접한 주소의 내용이 다시 참조되는 특성
Caching line
언급했듯이 캐시(cache)는 프로세서 가까이에 위치하면서 빈번하게 사용되는 데이터를 놔두는 장소이다. 하지만 캐시가 아무리 가까이 있더라도 찾고자 하는 데이터가 어느 곳에 저장되어 있는지 몰라 모든 데이터를 순회해야 한다면 시간이 오래 걸리게 된다. 즉, 캐시에 목적 데이터가 저장되어 있다면 바로 접근하여 출력할 수 있어야 캐시가 의미 있어진다는 것이다.
그렇기 때문에 캐시에 데이터를 저장할 때 특정 자료구조를 사용하여 묶음으로 저장하게 되는데 이를 캐싱 라인 이라고 한다. 프로세스는 다양한 주소에 있는 데이터를 사용하므로 빈번하게 사용하는 데이터의 주소 또한 흩어져 있다. 따라서 캐시에 저장하는 데이터에는 데이터의 메모리 주소 등을 기록해 둔 태그를 달아놓을 필요가 있다. 이러한 태그들의 묶음을 캐싱 라인이라고 하고 메모리로부터 가져올 때도 캐싱 라인을 기준으로 가져온다. 종류로는 대표적으로 세 가지 방식이 존재한다.
Full Associative
Set Associative
Direct Map
참고
https://www.forcepoint.com/ko/cyber-edu/osi-model
https://yuda.dev/261?category=846255
https://github.com/JaeYeopHan/Interview_Question_for_Beginner/tree/master/OS
https://shlee0882.tistory.com/110
