서문
필자는 소프트웨어 개발을 2011년부터 시작했다. 임베디드(embedded system) 개발을 시작으로 WIN32 프로그램, 게임 클라이언트 개발까지 해오고 있다. 요구사항에 따라 기능과 시스템을 구현하지만, 항상 프로세스(Process)가 뻑(crash)나지 않도록, 논리 오류(Logic Error)가 발생하지 않도록 예외 처리를 많이 하는 편이다. 코드를 짜다보면 예외 처리가 필요한 상황은 정말정말 많다. 하나하나 따지면 끝이 없다. 하지만 이번 포스팅은 코드레벨의 예외처리보다 넓은 시각으로 이야기를 해보고자 한다.
왜 오류가 발생할까?
결과물을 만들다 보면 참 많은 상황을 마주하게 된다. 예측하였지만 전부 대응하지 못한 경우, 혹은 예측하지 못한 경우. 보통 후자의 경우가 많을 것이다. 그래서 우리는 변인(變因)을 통제하려고 한다. 변인이 통제된 상황은 예측가능한 결과를 생성하고, 우리는 그것에 대응할 수 있게된다. 많은 오류는 통제되지 않는 요인에 의해 발생한다.
int arr[] = {1,2,3,4,5};
int count = std::size(arr);
for(auto ii = 0; ii < count; ++ii)
{
arr[ii] = ii % 2;
} 위의 코드는 배열의 크기 만큼 반복문이 실행된다. 반복문의 반복횟수는 std::size() 를 통해 런타임(Runtime)에 계산되며 정확하게 배열의 크기만큼 반복된다. 심지어 배열 크기를 바꾸어 컴파일하여도 런타임에 문제가 발생하지 않는다. 단순하지만 아름답지 않은가? 배열의 크기에 잘 대처하는 코드다.
하지만 항상 우리는 이런 코드를 생산하지 않는다. 사람이니까.
예외처리에 대한 접근
우리 모두 실용적이고 아름다운 코드를 지향(志向)하지만, 잘 안된다. 우리가 짠 코드는 가끔 프로그램을 죽이기도 하고, 예상과 벗어난 동작을 하기도 한다. 어떻게 해야할까? 코드레벨에서는 예외(Exception)를 잡아서 안정적으로 프로그램이 구동되도록 try-catch-finally 와 같은 수단을 언어 차원에서 제공한다. 그런데...이런 생각 해본적 없는가?
- 왜? 예외처리해야되지? 확실한 트러블 슈팅(Trouble Shooting)을 위해선 그냥 죽는(crash)게 낫지 않나?
- 의도를 벗어난 동작을 한다는건, 결국 데이터도 잘못되었는데 예외처리한다고 해결되나?
자, 이제 고민이 늘어날 시간이다. 프로그래머 입장에서 그냥 프로세스(Process)를 죽이는게 더 나을수도 있다. 복잡한 루틴을 타는 경우, 예외처리로 인해 어디서 문제가 발생했는지 확인이 더 어려울 수도 있고, 많은 시간을 소비할 수도 있다.
그리고 예상된 동작을 안하는 경우는 내부 데이터도 같이 잘못되어 있는 경우가 많다. 이 경우는 아무리 예외처리를 잘했다고 하더라도 절대 올바른 결과를 도출할 수 없는데, 차라리 지구 리셋론처럼 프로세스를 다시 시작하는게 확실한 방법일지도 모른다. 여러분들은 어떻게 했으면 좋겠는가? 참고로 필자는 최근에 그럼에도 살려야한다로 바뀌었다.
어떻게 대처해야될까?
예외처리를 했건 안했건 오류는 발생했다. 일은 벌어졌고 우리는 해결해야한다. QA단계에서 발생한 오류라면 재현방법 공유받고 수정하면된다. 유저에게 배포된것이 아니니까 별문제 아니다.
문제는 유저한테 배포한 버전에서 오류가 발생할 경우다. 이 경우엔 기획, 사업, 운영과 같은 부서의 의사결정이 필요하다. 오류의 경중(輕重)을 파악하여, 당장 수정패치를 배포할 것인가? 아니면 다음 배포에 수정해서 나갈 것인가? 이런 의사결정 말이다.
게임의 경우를 예를들면
- 유료 상품을 결제하지 못하거나, 결제 정보가 갱신되지 않는 경우
- 게임의 핵심 플레이(로그인 실패, 케릭터 소실, 사냥불가 등등)가 불가능한 경우
이런 경우는 즉시 대응하는 경우가 많다. 결국은 의사결정이다. 서비스의 질을 생각하면 즉시대응이 좋지만, 이럴경우 잦은 업데이트로 인해 불편을 야기할 것이고, 묻어놓고 가면 오류가 해결되지 않아 서비스에 대한 신뢰가 바닥으로 떨어질 것이다. 프로젝트마다 다르겠지만, 이런 룰 하나도 서비스질을 결정하는 중요한 요소가 된다.
우리는 정보가 필요하다.
오류는 개발자 테스트에서, QA 단계에서, 유저 보고와 같은 단계에서 전달된다. 개발자 테스트나 QA 단계에서 수집되고 처리되는 오류는 소스코드(Source Code)에 중단점(Break Point)를 찍고, 코드 라인 하나하나 확인이 가능하다. 메모리까지 뒤집어 깔수 있으니 너무나 행복한 작업환경이다. 하지만 유저한테 보고 받는 오류는 다르다. 정보가 너무 부족하다. 실행 환경, 오류 재현 방법은 유저가 전달하는 정보에 의존할 수 밖에 없고, 프로세스 내부 데이터는 꿈도 못꾼다. 때문에 우리는 유저에게 배포하기전에 오류를 발생을 대비해 정보를 수집할 수 있는 방법을 고민해야한다. 고전부터 내려오는 여러가지 수단이 있어서 소개해보고자한다.
- 런타임에 로그파일를 남긴다.
- 프로세스 크래쉬 발생할 경우, 메모리 덤프(Memory Dump)를 만든다.
- 남긴 데이터를 FTP 서버로 전송하여 능동적으로 대응한다.
머릿속에 잘 그려지지 않는 분들은 이런 화면을 본적이 있는가?
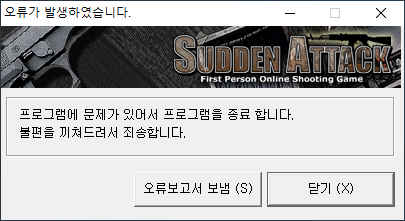
유명한 게임의 오류보고창이다. 저런 오류 보고 시스템은 유저에게 치명적인 오류가 발생하면, 런타임중에 작성한 로그와 메모리 덤프를 FTP 서버로 송신하여 개발팀이 대응할 수 있게 해준다. 이런 시스템이 없다고? 개발비가 허용하는 한도에서 도입을 고민해보자. 다만 조심해야한다. 유저의 실행환경에 대한 기록을 남기는 만큼 유저의 민감한 정보를 남기게 되면 법적문제가 발생할 수 있으니, 남겨야될 정보도 중요도를 나눠서 꼭 필요한 정보만 남기자.
마치며
오류는 다양하게 발생할 수 있고, 여러 환경에서 여러분을 괴롭힐 것이다. 특별하지만 고민해볼만한 주제도 포함시켜 글을 남겨본다. 정답은 없지만 한번쯤 고민해볼만한 주제가 아닐까?
