Spark의 특징
- RDD와 Dataframe의 주 데이터 타입
- 하둡과 달리 RAM에서 I/O가 발생하도록 설정 가능: 속도에서 비약적 차이 발생
Lazy execution
- 효율적인 처리/분석 가능
- Transform/Action으로 구분하여 Action일 경우에만 실제 실행이 발생 : 속도 향상
Transfrom: filter, select, drop, join, dropDuplicates, distinct, withColumn, pivot, get_json_object, sample
Action: count, collect, show,head, take
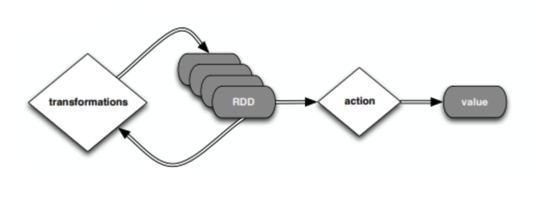
RDD
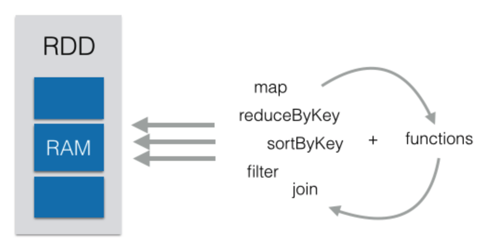
DataFrame
- SparkSQL 이용
SparkML
- 대량의 데이터 처리를 위한 머신러닝 Framework
- 텐서플로우나 사이킷런에 비해 모델 업데이트가 느리지만, 대량 데이터 처리에 적합함
- 학습에 필요한 전처리를 스파크로 진행하고 모델링은 텐서플로우와 같은 타 라이브러리로 진행하거나, 스파크 지원 모델로 충분한 프로젝트라면 모델링까지 스파크로 마무리하여 작업의 속도를 높일 수 있음
Reference
- Getting Started with Spark in Practice : https://www.duchess-france.org/starting-with-spark-in-practice/
- Spark & 주요 모듈 소개 : https://wikidocs.net/16565
- SparkML : https://moons08.github.io/programming/sparkML/

romantic ai developer