
[https://www.topbots.com/to-rouge-or-not-to-rouge/]
Rouge Score란?
-
Recall-Oriented Understudy for Gisting Evaluation
-
label(사람이 만든 요약문)과 summary(모델이 생성한 inference)을 비교해서 성능 계산
-
ROUGE-N, ROUGE-L, ROUGE-W, ROUGE-S 등 다양한 지표가 있음
-
각각 지표별로 recall 및 precision을 둘 다 구하는 것이 도움이 됨(기반하여 F1 score로 측정 가능)
-
Recall : label을 구성하는 단어 중 몇개가 inference와 겹치는가?
- 우선적으로 필요한 정보들이 다 담겨있는지 체크
-
precision : inference를 구성하는 단어 중 몇개가 label과 겹치는가?
- 요약된 문장에 필요한 정보만을 얼마나 담고있는지를 체크
사람이 요약한 Reference 정보를 label, 모델로부터 추론된 data를 output이라고 표현하여 아래를 설명하겠습니다.
1. ROUGE-N
-
N-gram의 개수가 기준
-
Rouge-1은 unigram, Rouge-2 는 bigram,...
-
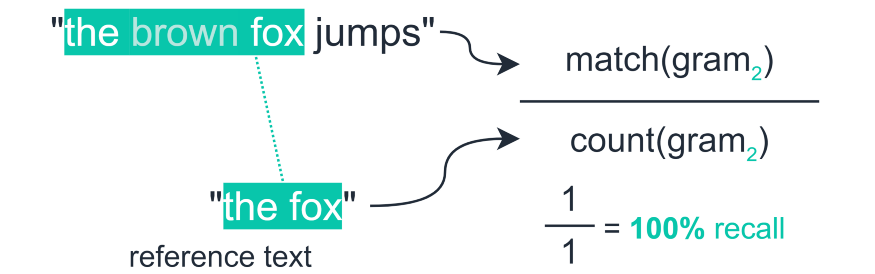
Recall : output과 겹치는 N-gram의 수 / label의 N-gram의수

[ROUGE-1 SCORE(recall) example] -
precision : label과 겹치는 N-gram의 수 / output의 N-gram의수
2. ROUGE-L
-
LCS(longest common sequence) between model output
-
말 그대로 common sequence 중에서 가장 긴 것을 매칭함
-
n-gram과 달리 순서나 위치관계를 고려한 알고리즘
-
Recall : LCS 길이 / label의 N-gram의수
-
Precision : LCS 길이 / output의 N-gram의수
3. ROUGE-S
- Skip-bigram을 활용한 metric
- 두 개의 토큰을 한 쌍으로 묶어서() ROUGE Score를 계산
- 예를 들어, 'the brown fox' 는 (the,brown), (brown,fox), (the,fox)로 매핑되어 계산됨.
- 결과적으로 위 그림의 경우 와 개의 토큰 사이에서 비교하게 됨.(precision은 1/6이 됨).
3-1. ROUGE-SU
- Unigram과 skip-bigram 모두 고려.
- 3번의 그림의 경우 output에 unigram인 the, brown, fox, jumps 를 추가
- (4+4C2)개, (2+2C2)개와 겹치는 개수를 비교하게 됨
4. Rouge score의 단점
- 동음이의어에 대해서 평가할 수 없음. 즉 같은 의미의 다른 단어가 많으면 성능을 낮게 측정함.
- Reference를 활용하여 average score를 내는 방법을 고려해 볼 수 있음
- 또는 동의어 dictionary를 구축하여 Rouge score를 계산하는 Rouge 2.0 방법도 있음논문
python에서 Rouge score 쓰는법
-
rouge library 설치
$ pip install rouge -
불러오고 객체 생성후
get.scores를 사용하면 Rouge-1, Rouge-2, Rouge-l score 확인 가능
from rouge import Rouge
model_out = ["he began by starting a five person war cabinet and included chamberlain as lord president of the council",
"the siege lasted from 250 to 241 bc, the romans laid siege to lilybaeum",
"the original ocean water was found in aquaculture"]
reference = ["he began his premiership by forming a five-man war cabinet which included chamberlain as lord president of the council",
"the siege of lilybaeum lasted from 250 to 241 bc, as the roman army laid siege to the carthaginian-held sicilian city of lilybaeum",
"the original mission was for research into the uses of deep ocean water in ocean thermal energy conversion (otec) renewable energy production and in aquaculture"]
rouge = Rouge()
rouge.get_scores(model_out, reference, avg=True)
>>>
{ 'rouge-1': { 'f': 0.6279006234427593,
'p': 0.8604497354497355,
'r': 0.5273531655225019},
'rouge-2': { 'f': 0.3883256484545606,
'p': 0.5244559362206421,
'r': 0.32954545454545453},
'rouge-l': { 'f': 0.6282785202429159,
'p': 0.8122895622895623,
'r': 0.5369305616983636}}
5. RDASS

- 문서(d), 정답 요약문장(r), 모델이 생성한 문장(p) 각각의 벡터에 대해 유사도를 구해서 평균을 내는 과정.
- 한글의 특성인 어근에 붙은 접사가( 은,는)가 단어의 역할을 결정하기에, 단어의 변형이 빈번하게 일어나므로 ROUGE 평가지표가 적절하지 않다는 판단에서 개발되었음
결론(활용 및 개발방안)
- 한글 요약 성능 평가지표는, RDASS, rouge-u, rouge-su 가 보다 합리적으로 비교할 수 있는 metric으로 판단됨.
- 영어와 비교한 한국어 문장성분의 특성 상 순서보다 조사가 중요함. 조사가 그대로 있다면, 단어의 순서는 결코 중요하지 않음.
ex) 아빠가 나에게 선물을 주셨다. == 나에게 아빠가 선물을 주셨다. Daddy bought me the gift. != I bought Daddy the gift.
- 다시말해, Semantic하게 성능을 분석하기 위해서는 영어와 달리 단어의 순서를 비교하는 것이 적절한 지표가 되지 않을 수도 있다는 이야기.
- '순서'가 아닌 '조합'으로 성능을 판단할 수 있는 ROUGE-U, ROUGE-SU가 적절해보임
- RDASS 도 추가로 고려하여 성능 확인.
- 추가로 축구 유사용어사전을 간단하게 구축하여 성능을 더 잘 비교할 수 있다면 시도(Optional).
Reference
