LLM 동향에 대한 강의 및 정리
How Transformer LLMs Work 를 읽고 정리한 글입니다.
NLP(LM) 발전과정
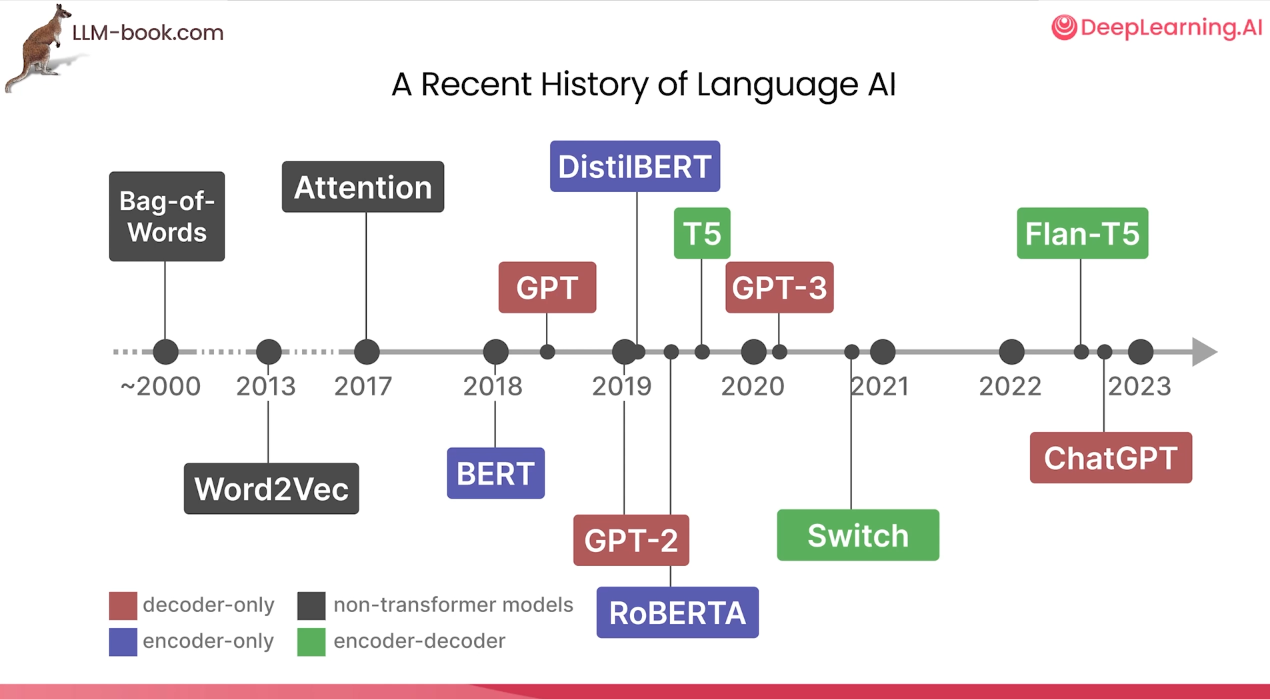
- Word2Vec은 여전히 중요한 개념
- encoder only 모델
- decoder only 모델
- ...
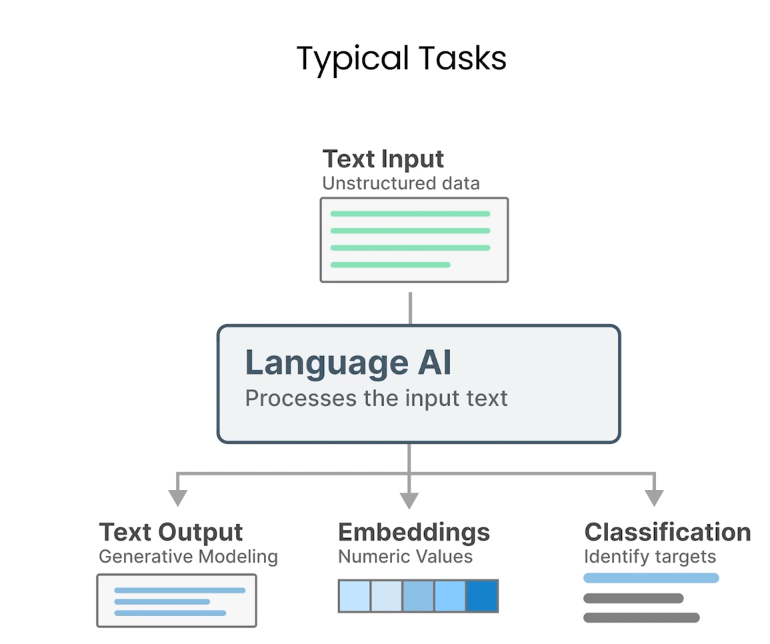
- 크게 세 갈래 태스크를 수행할 수 있음
우선 가장 기본적인 텍스트 데이터 처리법에 대해 알아보자
1. Bag of words(2000)
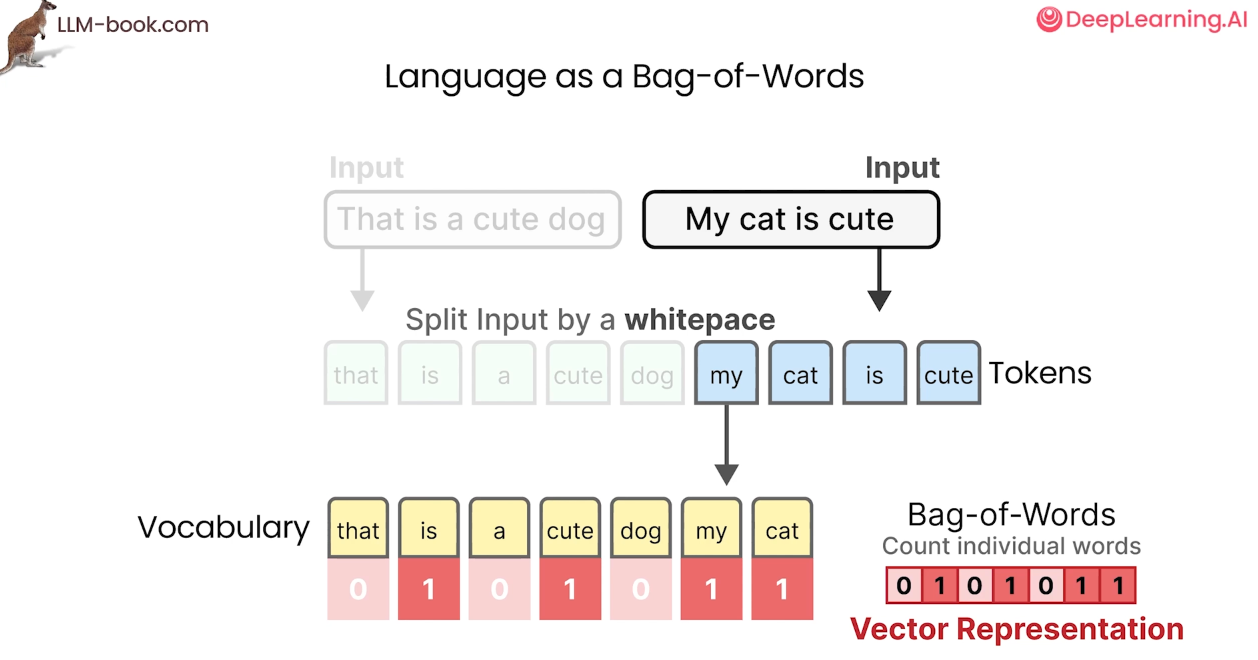
My cat is cute -> 0101011 vector representation
단어 의미적인 성질이나 순서를 고려하지 않는 단점
2. Word2Vec(2013)
- 의미적인 부분 capture
과정
- 특정 차원(ex.512)을 가진 임베딩 벡터로 변환(처음엔 Random 초기화됨)
- CBow (cotext input -> word output) 와 Skip-gram (word input -> context output) 이 있음
- 모델이 학습하면서 업데이트함
- 벡터의 각 차원은 feature(사람에 가까운지, 음식에 가까운지,) 로 대응될수 있음
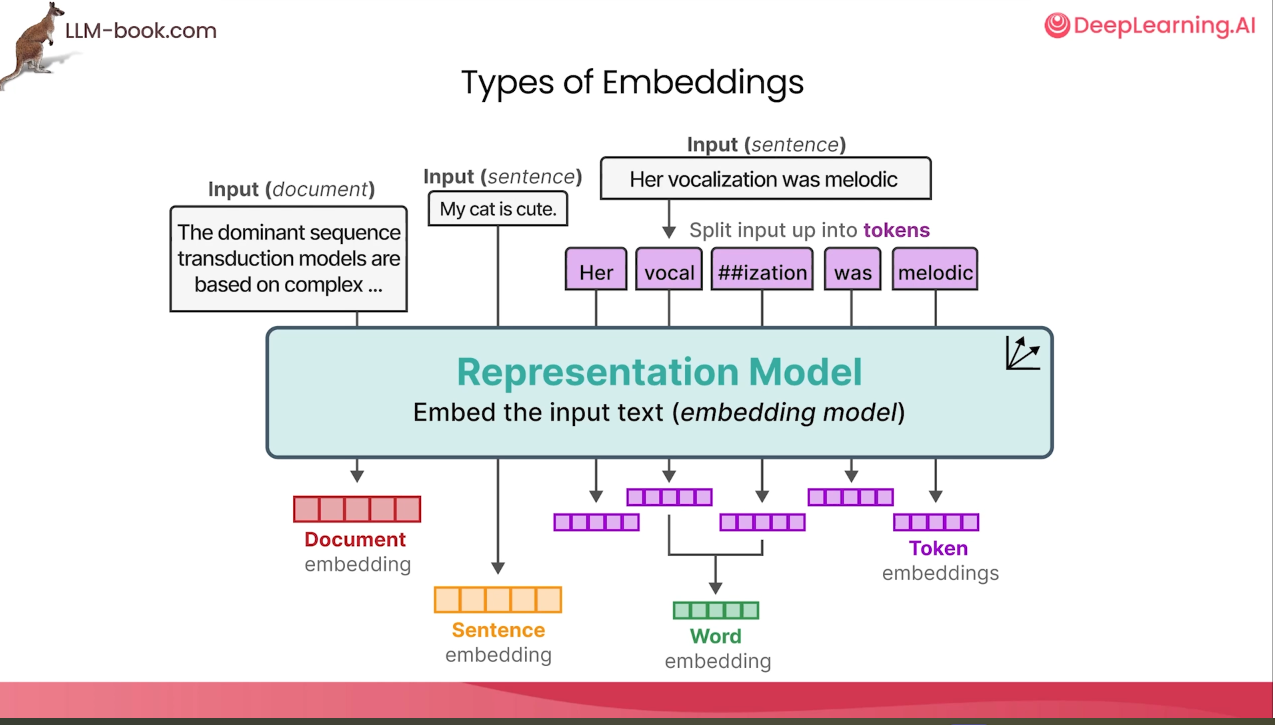
- 임베딩은 단어(토큰 합쳐서), 문장, 문서 등 다양하게 존재 가능
하지만 word2vec 은 static Embedding
ex) bank라는 단어의 중의적 의미들은 모두 하나의 의미로 치환되는 문제점
3. Attention(2014)
- 문장에서 "문맥적 의미"를 파악하는것은 매우 중요함
- 문맥적 파악을 위하여 RNN이 사용됨
RNN 등장 의의는 -> sequence를 모델링할수 있다는 것!
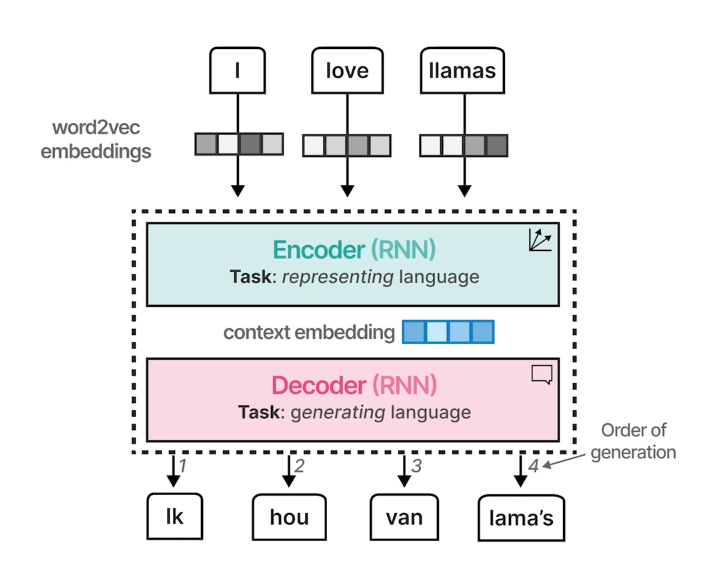
Seq2Seq
- Word Embedding -> Encoder -> Context vector -> Decoder(Autoregressive)
하지만 context embedding긴 문장에서 문장 전체 문맥 파악에 한계가 있어..
Attention
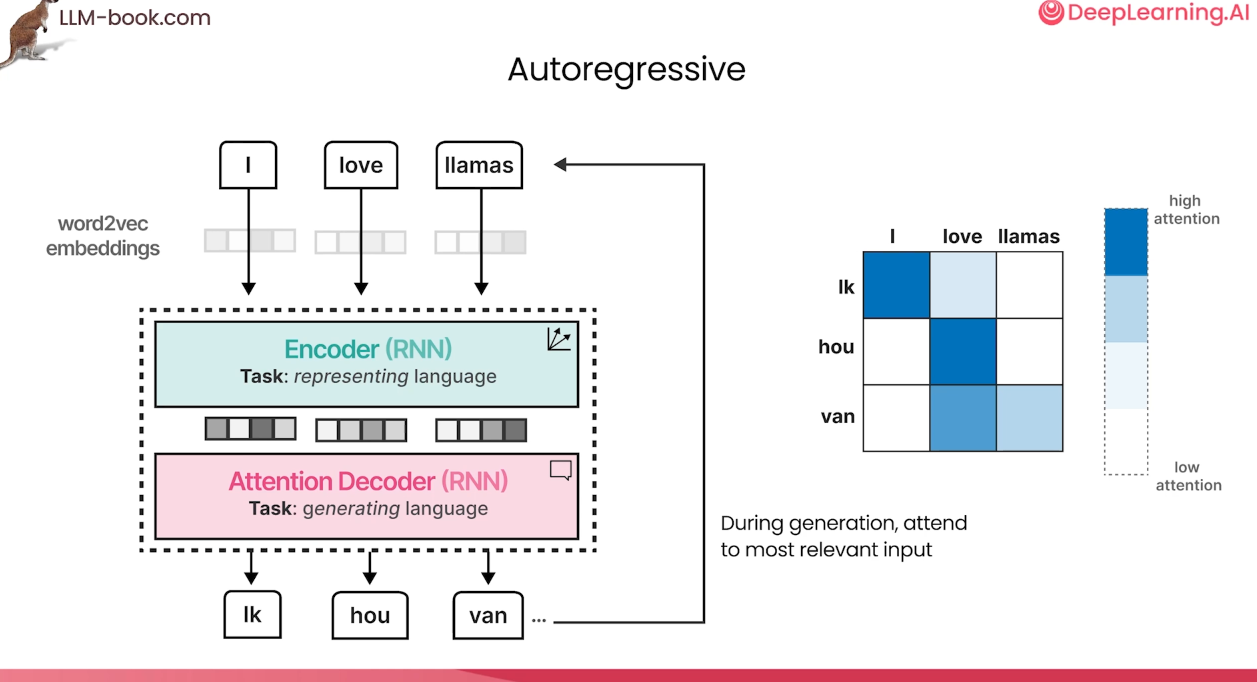
- 모든 input word의 hidden state가 decoder 로 전달됨
- RNN hidden layer의 vector 는 "Stateful word" 로서 이전 단어들의 정보를 포함하는 hidden state인것임
Attention is all you need (2017)
- RNN 없음
- parallel computing으로 인한 속도 개선
- encoder6 -decoder6 구조
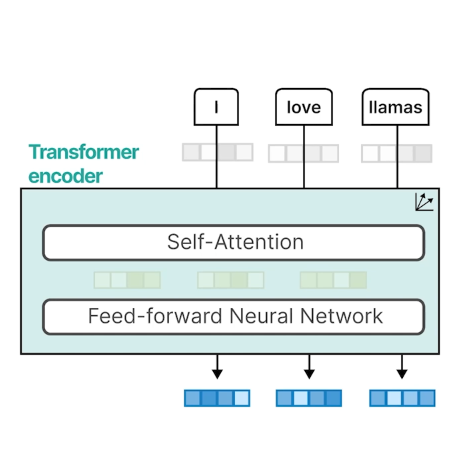
Encoder
- self-attention : input 문장 간 단어 관계 학습
- feed-forward network (LayerNorm , Resnet) 도 추가로 쌓음
Decoder
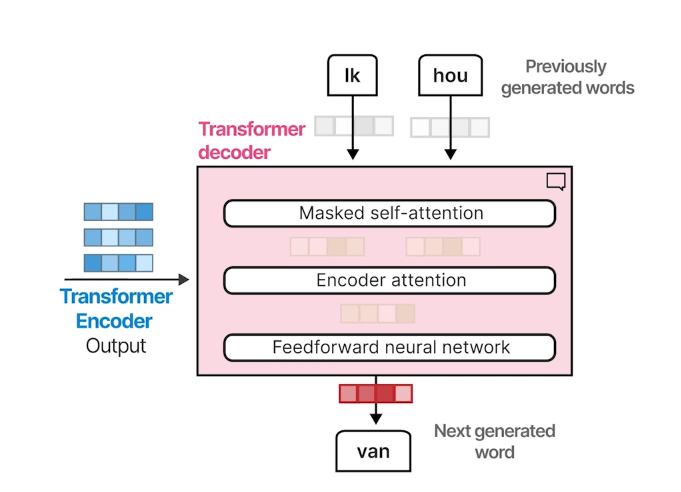
- masked self-attention: 생성되기 전의 token은 attend하지 않음
- decoder에서 생성할때, 미래의 sequence정보를 활용하는걸 막음
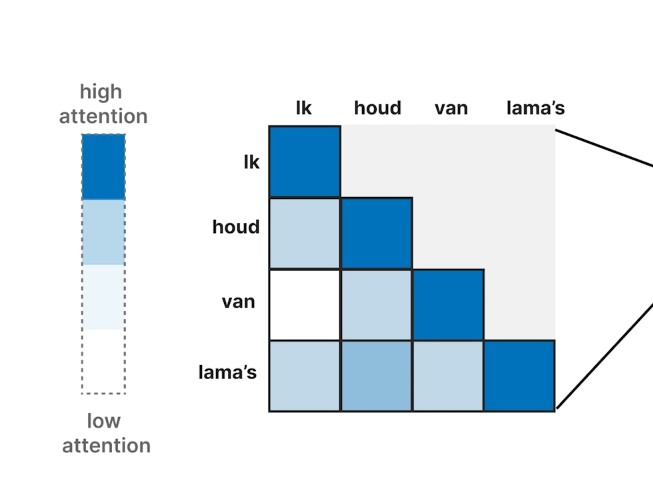
- Encoder -decoder attention: Encoder output과의 attention
- feed-forward network (LayerNorm , Resnet) 도 추가로 쌓음
LLM 동향

romantic ai developer