3줄 요약
🎹 전문 작곡가들이 제작한 4,422개의 MIDI 샘플로 구성된 데이터셋.
📊 각 샘플은 음악 메타데이터와 CC#1(모듈레이션 휠 값) 정보를 포함.
🤖 토큰 기반 인코딩 방법론을 통해 딥러닝 모델에 적용 가능성 확인.
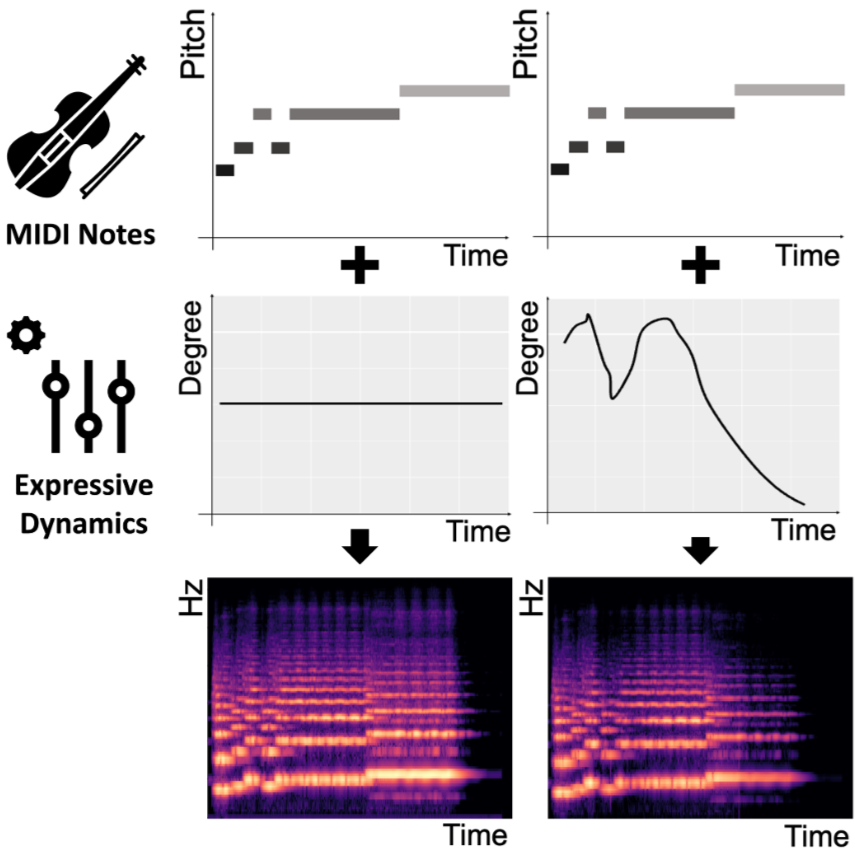
음악 샘플 별 "메타정보(악기, 트랙분류 ,분위기) + (음표, 셈여림을 의미하는 시계열 곡선(Fine Level))쌍"이 하나의 데이터를 이룬다고 생각하면 이해가 빠를 것!
-> 한 샘플에 담긴 음표와 셈여림(시계열)곡선 쌍을 표현한 것!
연구 배경
- Expressive dynamics(셈여림 표현)은 음악에서 매우 중요한 요소이다.
- 기존에는 음표 단위의 샘여림까지에 많이 집중하거나, 단순히 도메인 지식이 포함된 annotation없이 음원의 주파수 및 진폭으로부터 셈여림에 관한 특징을 추출했다
-> 이러한 기존 연구의 문제는
- 음표단위의 셈여림 표현은 더 사람과 같은 음악으로 다가가에는 부족하다 (크레센도 표현 불가)
- 실제 작곡에서 셈여림을 표현할때는 악기, 분위기, 트랙역할 등을 고려하는데, 이러한 점을 고려하지 않고 메타데이터가 없는 채로 audio signal에서만 추출하는것은 너무 단순한 접근일수 있다
-> 우리 데이터셋 미드필드는
- fine level의 dynamics: 전문 작곡가들이 그렸음
- meta information 4종류 포함
- (메타데이터 + 강약정보)를 함께 포함하는 유일한 데이터셋
Data collection
- 두 팀으로 나뉘어서 한팀이 가이드라인 만들고 나머지한팀은 샘플제작, 메타데이터 라벨링, 그리고 CC 값 그리기
메타데이터
- instrument
- track role
- mood
- min & max cc#1 value
- 5 bin size
Data Analysis
-
metadata에 따른 데이터 분포를 파악함
-
명료한 분석을 위해 추가적인 grouping
-
track role: 그대로
-
mood: Russel's 4Q model 로 매핑(19개-> 4개)
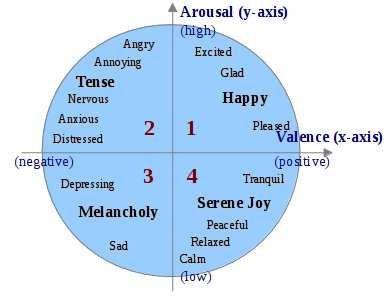
Russel's 4Q model: 여러 mood를 이차원 공간의 4 사분면에 표현.
valence : 긍정도 (양의 감정인지, 음의 감정인지)
arousal : 상승도 (상승하는 감정인지, 하강하는 감정인지) -
instrument: Western Instrument Category(18개 -> 3개)
-
Metadata별 분포
-
각 샘플의 CC#1값을 평균 내고, 메타데이터 그룹 별 CC#1값 평균의 분포를 violinplot으로 표현
-
"3개 항목의 각 메타데이터 그룹간 유의미한 분포 차이가 있다"는 가설을 검정함.
-
Welch's ANOVA and Games-Howell Test(post-hoc pairwise comparison)
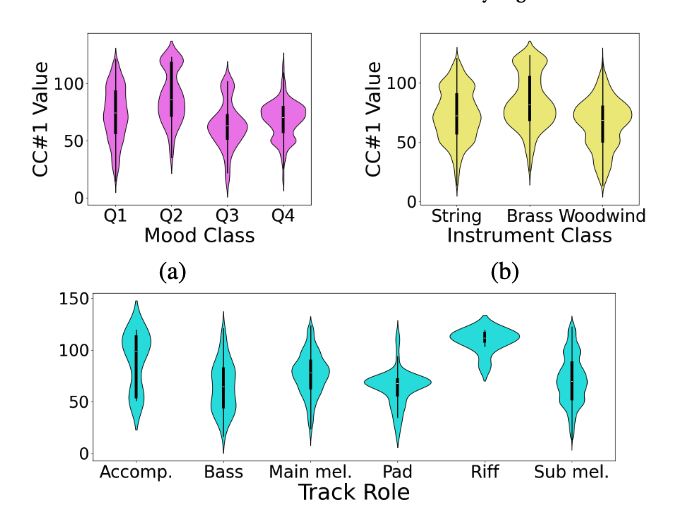
- track role 특성 반영
- mood 도 특성 반영
-
MOOD
- 유의미한 차이 보임 (p < 0.01)- Q2 가 제일 큰 평균값을 보임
-> negative arousal이 소리의 강도와 깊게 연관되어 있다는 선행 연구에 힘을 싣는 결과
- Q2 가 제일 큰 평균값을 보임
-
Instrument
- 더욱 유의미한 차이( p<0.0001)- brass가 가장 큰 평균값
-
Track Role
- 유의미한 차이 p<0.05- 사후 검정시 아래항목엗 대해서는 유의미하지 않았음
- (
main melody VS accompaniment) p > 0.1 - (
riff VS accompaniment) p > 0.1 - (
bass VS pad) p > 0.1 - bass 랑 pad는 실제로 유사한 역할
- (
- 사후 검정시 아래항목엗 대해서는 유의미하지 않았음
-
Relatasionships among metadata
-
메타데이터 간 관계분석
-
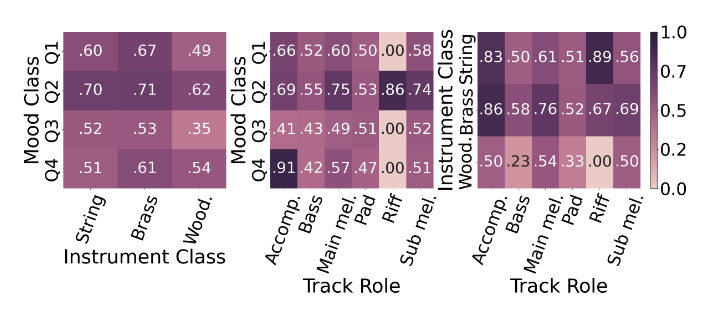
3항목의 메타데이터 간 aggregated mean 을 체크(mean은 [0,1]로 normalize)
- 예를 들어, mood class Q1 과 string 으로 분류되는 영역의 평균은 0.6이다. -
메타데이터가 음악 생성의 controllability에 영향을 줄수 있다는 걸 충분히 보여줌
-
Q2(약기와 상관없이) 와 brass 에서(mood 와 상관없이) 평균이 가장 큼
-
WoodWind 는 평균이 가장 작음(track role과 mood에 관계없이)
-
bass랑 pad는 다른 필드와 관계없이 낮음
-
accompaniment & Q4 는 제일 높고, accompaniment & Q3는 제일 낮다
-> Mood가 accompaniment보다 영향력이 크다는 것을 의미 -
각각의 메타데이터가 CC#1 value와 상호작용한다는 사실은 자명함
-
기타 경향성으로 controllability 입증
실험
Representation
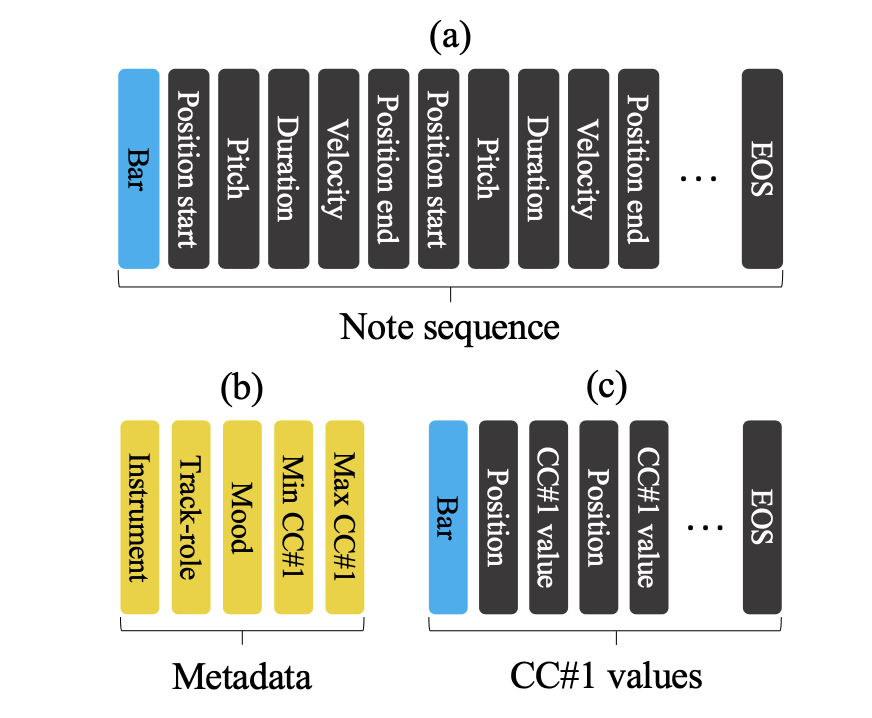
- 토큰화된 학습데이터. source(a) 와 target[(b)+(c)] 트랜스포머 모델의 input으로 들어감.
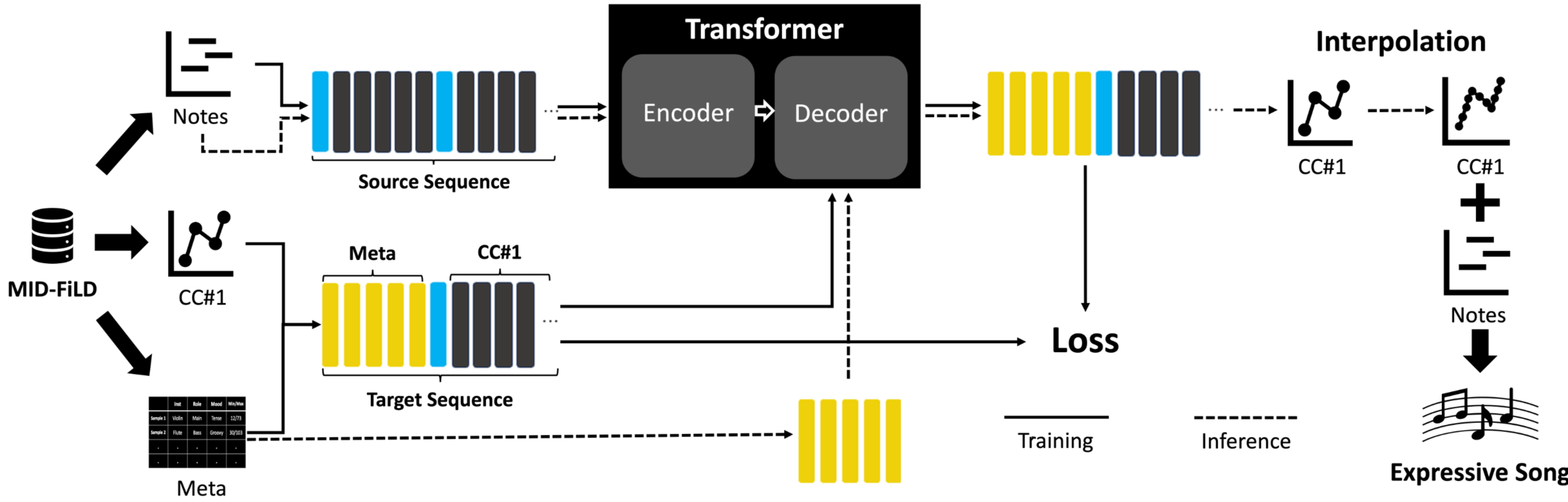
학습 전략
- note sequence와 metadata 주어졌을때 알맞은 CC#1 값을 예측하는 모델을 구현하여, 데이터셋의 우수성 증명
- 학습/생성 설계도는 아래와 같고, 기타 인코딩 방법론 및 loss function 등은 논문의 설명 및 수식 참고
GT VS Generated 평가항목
메타데이터를 하나씩 빼가면서 생성 성능이 어떻게 달라지는지 확인
Fidelity
- 정답데이터 곡선과 생성 곡선과의 RMSE score
- 완벽한 곡선의 형태가 아니므로, Linear interpolation 이용 - Top-k 가 아닌 greedy search 로 평가
Controllability
- difference of min&max: 메타정보 값고 생성완료된 곡선의 차이 비교
- Mood Classification
- SVM으로 학습시킨 분류기를 testset(ground truth) 및 generated 항목에 적용- 음표, CC#1, velocity 등으로부터 통계량(평균, 분산, 최대 최소, 미분값 등)
Result
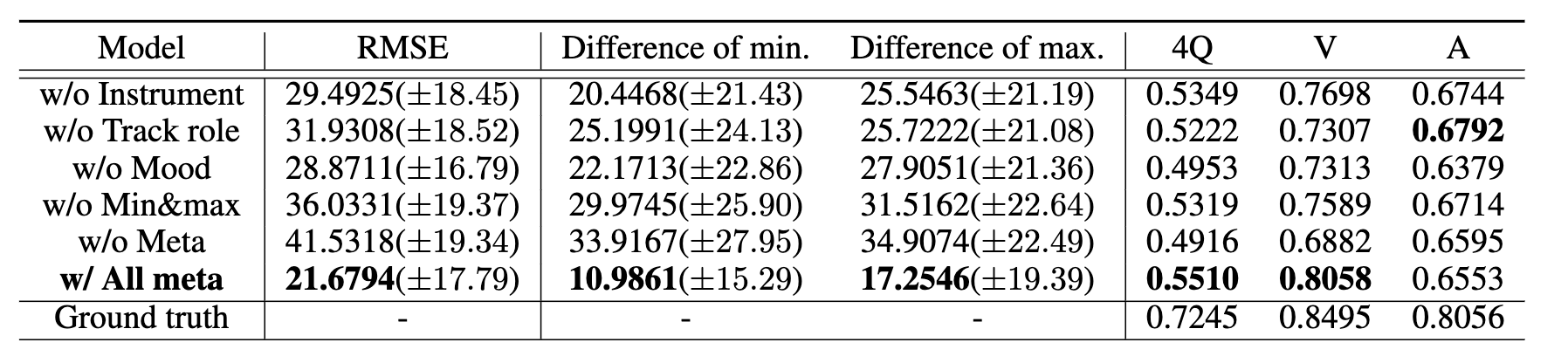
- 메타정보 풍부한 항목이 가장 평가지표상으로 Fidelity 와 Controllability가 알맞게 나왔음.
- mood classification의 Arousal 항목만 mood 영향이 가장 큰것으로 보였다
-> 메타정보의 유의성 입증 및 Encoding 방법론 공개를 통한 딥러닝 모델 적용 가능성 확인.
Appendix
- Semi- Continuous 한 CC#1 값을 integer로 encoding했으므로, 연속적인 값 간의 관계를 잘 반영했을지 의문이 들 수 있음
- 그러나 Transformer Embedding Matrix를 차원축소(UMAP)하여 시각화한 결과, 아래와 같이 연속적인 값을 잘 반영했음을 알 수 있음.
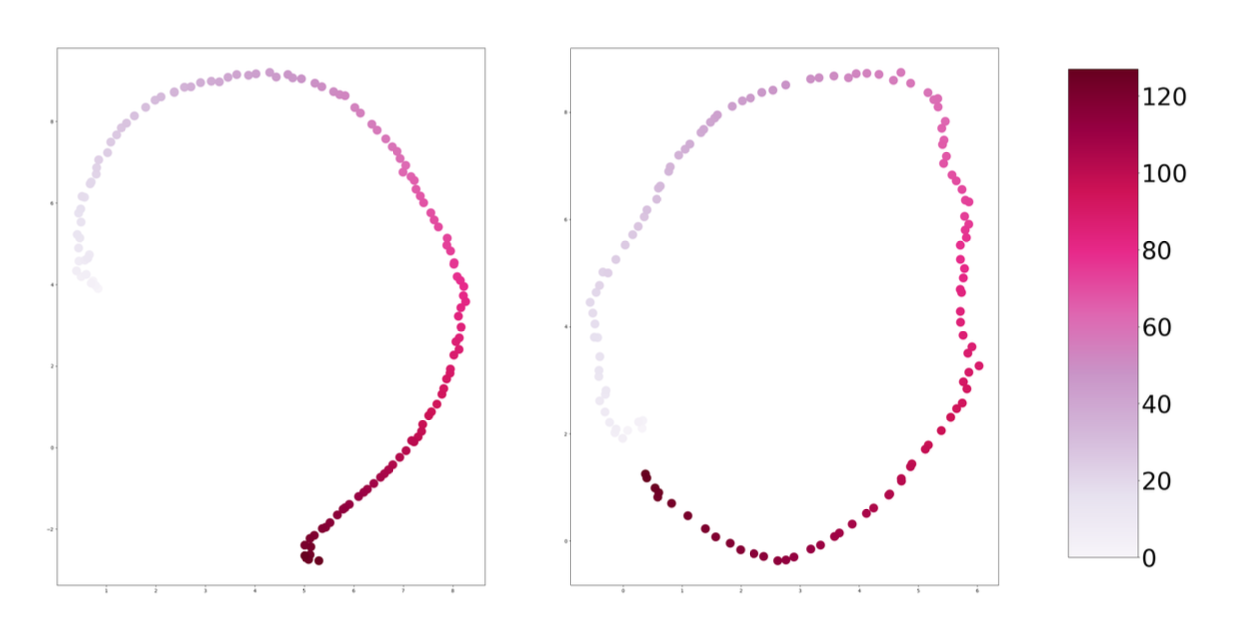
- 512-> 2차원으로 매핑한 embedding space를 나타냄.
- 왼쪽은 position token, 오른쪽은 CC#1 value 토큰.
