스크래핑 vs 크롤링
scraping(스크래핑)
스크래핑을 한국어로 번역하면 ‘긁다’라는 뜻이 되는데, 이 의미처럼 ‘특정 사이트를 스크래핑을 한다’ 라고 하면 특정 사이트의 한 페이지를 쭉 긁어와 1번 가져오는 것을 뜻한다.
crawling(크롤링)
크롤링이란 ‘헤엄치다’ 라는 뜻을 가지고 있으며, ‘크롤링을 한다’ 라고 하면 특정 사이트에서 돌아다니며 버튼을 클릭해 여러 페이지를가지고 오는 것을 뜻한다. 즉, 여러 번 스크래핑을 한 것이 크롤링이라고 볼 수 있다.
크롤링 시 주의점
1) 크롤링한 데이터를 상업 목적으로 사용시 소송 대상이 될 수 있다.
2) 너무 많은 접속으로 해당 회사 서버에 부하를 주게 될 경우 공격으로 판단되어 주의해야 한다.
HTTP 응답 결과
페이지를 그려주는 순서
첫번째로 HTML 문서를 받아오고,
이후 HTML문서를 읽으며 링크 태그 같은데에 바인딩 된 CSS 파일과 JS파일을 가지고 온다
HTML 문서를 Network를 통해 확인해보면, response와 Header가 있음을 확인 가능
주소창에 주소를 입력하고 문서들을 받아오는 과정이 Http통신이라는 뜻
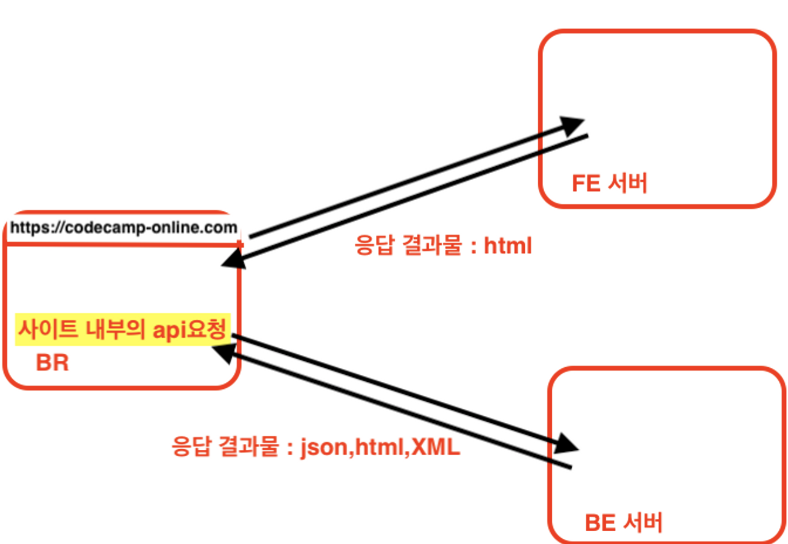
주소창에 입력된 페이지에 대한 요청은 프론트엔드 서버에서 처리하게 된다.
그럼 프론트서버에서는 요청에 대한 응답 결과물로 html을 반환하게 되고, 해당 결과물이 Network에서 보는 html이다.
주소창에 입력된 페이지에서 다른 api요청을 보낼때는 백엔드 서버에서 처리하게 된다.
백엔드 서버에서는 다양한 응답 결과물을 반환할 수 있는데, 응답 결과물로 html,json,xml을 반환할 수 있다.
브라우저의 주소창 또한 http요청의 도구였다!
백엔드에서 받아온 결과값들을 브라우저가 해석해 화면에 그려주는 것이다.
메타 태그와 Open Graph

코드캠프 아래의 미리보기 부분을 보자.
이는 해당 링크에 대한 정보를 meta태그에 담아 미리볼 수 있도록 해준 것 이다.
//제공자일 경우(provider 파일) _ 우리 페이지 / 네이버같은 사이트 페이지
import Head from 'next/head'
export default OpengraphHeadPage(){
return (
<>
<Head>
<meta property="og:title" content="중고마켓" />
<meta
property="og:description"
content="나의 중고마켓에 오신 것을 환영합니다!"
/>
<meta property="og:image" content="http://~~~~" />
</Head>
<div>
중고마켓에 오신 것을 환영합니다!(여기는 body이므로, 미리보기 상관없음!!)
</div>
</>
);
}사이트 주소를 카카오, 슬랙, 디스코드 같은 곳에 보내게 되면 위에서 만들어 뒀던 OG태그가 보이는 것 이다.
구현해둔 OG태그가 보이는 이유는 카카오,슬랙,디스코드 개발자들이 미리보기 기능을 모두 구현을 해두었기 때문에 보이는 것이다. 구현한 OG태그를 미리보기로 구현해주는 과정을 아래에서 구현해 볼 것 인데 실제로는 백엔드에서 많이 이루어 진다.
// 개발자 일 경우 _ 카카오,디스코드 개발자(우리페이지를 OG태그로 보여줄)
import axios from "axios";
export default OpengraphPreviewPage(){
const onClickEnter = async () => {
// 1. 채팅데이터에 주소가 있는지 찾기(ex, https://~~ 로 시작하는 것)
// 2. 해당 주소로 스크래핑하기
const result = await axios.get("https://www.gmarket.co.kr"); // CORS에러가 날 경우: https://www.naver.com
console.log(result.data);
// 3. 메타태그에서 오픈그래프(og:) 찾기
console.log(
result.data.split("<meta").filter((el: string) => el.includes("og:"))
);
};
return(
<div>
<button onClick={onClickEnter}>채팅입력 후 엔터치기!!</button>
</div>
)
}이렇게 해주면 원하는 html코드를 받아오는 것을 볼 수 있다.(axios의 결과물로 JSON이 아닌 html 소스코드를 받아오는 것)
html코드를 모두 받아 왔으면 여기서 og관련된 내용을 뽑아올 수 있다.
사실 이를 쉽게 뽑아올 수 있도록 도와주는 도구가 당연히 있다.
npm에 들어가 cheerio 또는 puppeteer 라고 검색해보면 사용방법과 함께 자세히 나와있다.
cheerio는 scraping 도구이며 puppeteer는 크롤링 도구 이다.
보통 실무에서는 위와같은 라이브러리를 사용하지만 ! 직접 긁어와 보면
이렇게 filter하고 자르며 열심히 긁어온 결과 콘솔에 링크가 뜨고 있습니다.
이제 OG태그에 긁어온 주소값을 넣어주면 됩니다
백엔드의 응답 결과
백엔드의 응답 결과물로 무조건 JSON이 날아오는 것은 아니다. JSON 이외에도 소스코드가 날아올 수 있다.
서버사이드 렌더링이 필요한 이유
1) OG태그에서의 서버사이드 렌더링
head태그를 하드코딩으로 만들어주면 어디서든 OG태그를 볼 수 있다.
하지만 OG태그를 언제나 하드코딩을 할 수 있는것은 아니다.
예를 들어 상품 상세 페이지같은 경우에는 여러 페이지를 만드는 것이 아닌 다이나믹 라우팅 처리를 하는 것이다.
따라서 각 상품에 대해 head태그를 삽입할 수 없는 상황이다.
그렇다면 useQuery를 이용해 data를 불러오고 그 data를 meta태그에 넣어주는 방식은?
import Head from 'next/head'
const FETCH_DATA = gql`
//상품 상세를 가지고 오는 쿼리문
`
export default OpengraphHeadPage(){
const {data} = useQuery(FETCH_DATA)
return(
<div>
<Head>
<meta property="og:title" content=`${data.fetchBoard.contents}`/>
<meta property="og:description" content="환영합니다."/>
</Head>
<h1> 오픈 그래프 연습입니다~ </h1>
</div>
)
}
이런식으로 data를 가지고 오고 가지고 온 data를 og 태그에 넣어 주었다고 가정해보면
초기 렌더링을 했을때는 백엔드 요청을 하지 않기 때문에 메타 태그가 비어있다.
이후에 useQuery가 실행되고 난 이후에야 meta 태그에 들어간 data.fetchBoard~ 이부분이 채워지게 되며 그제서야 데이터가 들어오게 된다.
즉, 브라우저에서 요청한 결과와 서버에서 보여지는 결과(postman요청결과)가 다르다는 뜻이다.
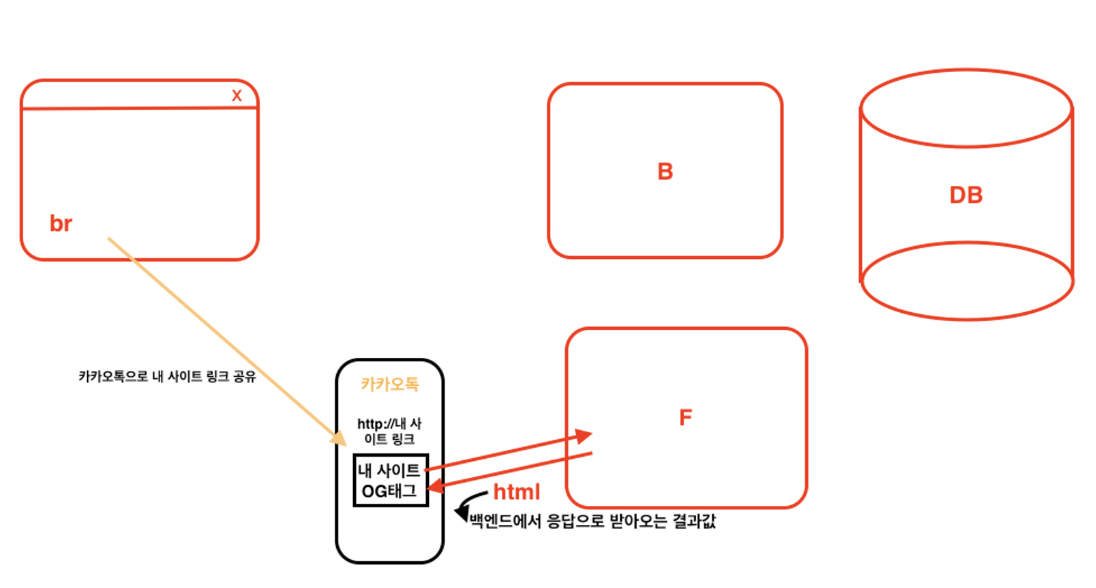
위의 그림과 같이 카카오톡 유저가 있다고 가정해보자.
그리고 카카오톡에서 내 사이트의 링크를 공유했다고 가정해보자.
그럼 프론트 서버로부터 백엔드에서 axios 응답결과로 준 html를 받아올 것이다.
그리고 해당 소스에서 meta 태그를 찾는 것 이다.
하지만 초기 렌더링에서는 useQuery까지 하지 않기때문에 meta 태그에 넣어두었던 data는 비어있는 상태가 되어있는 것이다.
이런 경우를 대비해서 서버사이드 렌더링이 필요한 것이다.
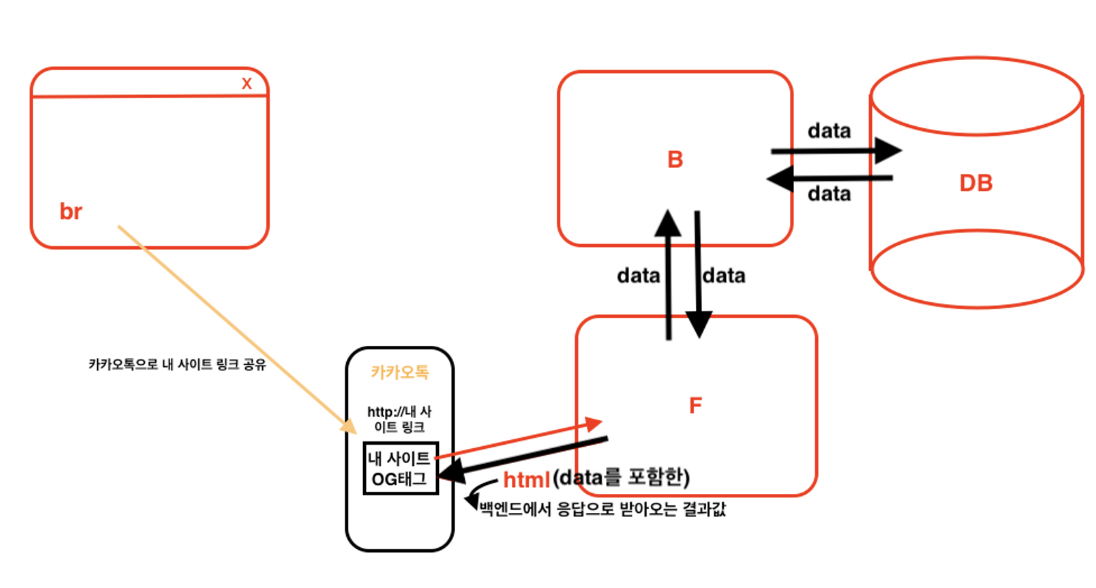
이런 경우 특정 주소에 서버사이드 렌더링 주소로 설정할 수 있다.
따라서 만일 서버사이드 렌더링 주소일 경우 프론트 서버에 요청을 하면 바로 응답을 보내는 것이 아닌 백엔드로 요청을 보내 데이터를 모두 꺼내와 합친 후 최종결과를 응답으로 전달해준다.
따라서 상품 상세 페이지같은 동적 페이지에 OG를 적용해주시고 싶다면 서버사이드 렌더링을 적용해주어야 한다.
서버사이드 렌더링 OG태그 만들어보기
서버사이드 렌더링을 적용한 OG태그를 만들기 위해 서는 useQuery를 사용하는 것이 아닌 getServerSideProps를 사용할 것
export default function OpengraphProviderPage(props: any) {
console.log("========");
console.log(props);
console.log("========");
return (
<>
<Head>
<meta property="og:title" content={props?.qqq.name} />
<meta property="og:description" content={props?.qqq.remarks} />
<meta property="og:image" content={props?.qqq.images?.[0]} />
</Head>
<div>
중고마켓에 오신 것을 환영합니다!(여기는 body이므로, 미리보기 상관없음!!)
</div>
</>
);
}
// 1. getServerSideProps는 존재하는 단어이므로 변경이 불가능합니다.
// 2. getServerSideProps는 프론트엔드 서버에서만 실행됩니다.(Webpack 프론트엔드 서버프로그램)
export const getServerSideProps = async () => {
console.log("여기는 서버입니다!");
// 1. 여기서 API 요청 - 아폴로 세딩이 되어있지 않아 grqphql-request를 이용해야 합니다.
const graphQLClient = new GraphQLClient(
"https://backend10.codebootcamp.co.kr/graphql"
);
const result = await graphQLClient.request(FETCH_USEDITEM, {
useditemId: "634f50f06cf469002995d5c9",
});
console.log(result);
// 2. 받은 결과를 return
return {
props: {
qqq: {
name: result.fetchUseditem.name,
remarks: result.fetchUseditem.remarks,
images: result.fetchUseditem.images,
},
},
};
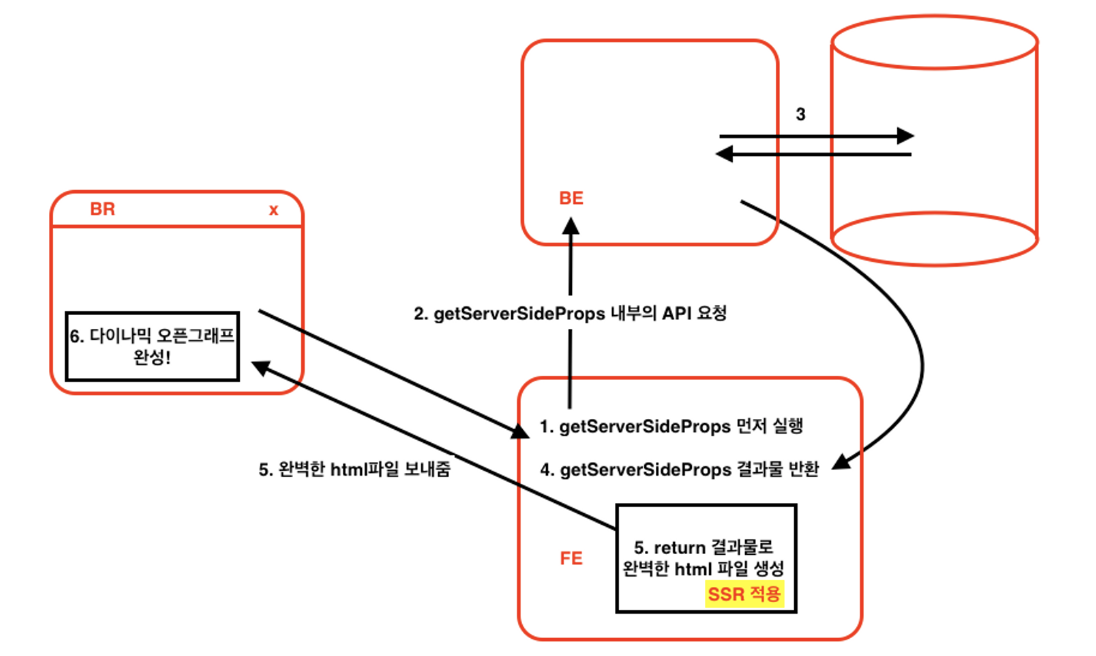
};이런식으로 getServerSideProps를 사용하게 되면 실행하게 되면 서버에서 실행된다.
그럼 서버에서 실행 후 결과물을 리턴해주고 리턴된 props는 페이지 안으로 쏙 들어가게 된다.
그럼 해당페이지는 결과값을 이미 다 받았기 때문에 데이터가 모두 있는 상태에서 화면에 그려지게 된다.
즉, 이미 데이터를 모두 채운채 브라우저로 보내주게 되는 것이다.
getServerSideProps는 처음 접속되었을 때 실행되는 부분이기 때문에 apolloSetting이 되어있지 않다.
따라서 우리가 refreshToken에서 했던 방식과 동일하게 graphql-request 를 사용해 api를 요청해주어야 한다
pageProps?
getServerSideProps를 실행 후 반환받는 값이 props였다. 해당 props는 페이지의 props로 쏙 들어가게 되는데, 이런 props를 pageProps라고 한다.
즉, 서버사이드렌더링 완료 후 리턴되어 페이지의 props로 들어가는 props를 pageProps라고 한다.
이전에는 데이터가 비어있는 상태에서 브라우저에서 useQuery를 실행해서 데이터를 채워넣었는데, getServerSideProps를 사용하면서 데이터를 채운 완벽한 상태에서 브라우저로 보내줄 수 있게 되었다.
해당과정을 그림으로 보면 아래와 같다.
2) SEO(Search Engine Optimization)
사실 **서버사이드 렌더링이 필요한 이유**를 검색하면 **검색 엔진 최적화(SEO)**가 가장 많이 언급된다.검색엔진 이라고 함은 네이버, 구글, 다음등을 말하며 해당 사이트들은 자체적인 검색봇이 있다.
각각의 검색봇은 24간동안 여러 사이트를 돌아다니며 해당 사이트가 어떤 사이트인지 파악하는데, 서버사이드 렌더링 처리가 되지 않은 사이트는 초기 렌더링 시 데이터가 모두 비어 있게 되어 검색봇은 페이지가 무슨페이지인지 모르는 상황이 생긴다.
하지만 서버사이드 렌더링을 하게되면 html,css,js 받아올 때 이미 데이터를 모두 완벽히 받아와 보여주기 때문에 검색봇이 해당 사이트가 무슨 사이트인지 알 수 있다.
tip) 검색이 더 잘 되게 하려면 h1과 같은 의미 있는 태그를 사용하는 것이 좋다. 즉, 웹 접근성, 웹 표준을 잘 지켜 코드를 작성하는 것이 좋다.
또한 router는 검색엔진이 읽을 수 없지만, a태그나 link태그는 읽을 수 있기때문에 a태그로 페이지 이동을 해준 부분은 페이지 간의 서로의 연관성을 읽을 수 있기때문에 검색에 유리하다.
