🫡 QA데이터셋을 위한 전략적 라벨링
포화: 학습 능력 제동
논문이 해결하고자 하는 바
- QA task를 위한 라벨링은 높은 비용과 집약적 노동을 필요로하지만, 여전히 저비용고효율의 QA 데이터셋 라벨링 전략은 부족하다.
- 본 논문은 대규모 분석을 시행해 QA 데이터셋 라벨링의 권장 및 전략 사항을 도출한다.
- 훈련 샘플이 많다고 해서 일반화에 도움되지 않는 다는 사실을 실험적으로 보여준다.
이전 접근법
- 문맥 이해 없이 답변할 수 있는 질문의 수
- 유사성과 엔티티 타입에 따른 질문 난이도 비율 계산
- QA 데이터셋의 일반화 능력
문제에 대한 이 논문의 접근은 무엇인가?
- 성능이 데이터셋 사이즈에 영향을 받는가?
- 어떤 질문의 하위 집합이 라벨링 되어야 비용과 노동을 줄일 수 있는가?
- 다양한 컨텍스트에 먼저 라벨링을 하면 어떤 이득이 있는가?
핵심 Contribution
훈련 샘플 개수가 미치는 영향력 실험
1. 훈련 데이터 Dp를 학습할 때 얼마나 성능에 영향을 끼치는지,
2. 훈련 시 사용되지 않았던 Dg로 일반화에 영향을 끼치는지를 중점으로 확인한다.
Influence of the training data size on performance and generalization.
핵심 contribution을 위한 방법은 무엇인가?
실험설계
모델
BERT-based
데이터셋
- SQuAD
- NewsQA
- HotPotQA
- TriviaQA
설계
Dp의 모든 학습 데이터가 사용될 때까지 2 ~ 4 를 반복
1. 최초 데이터셋 Dp 중 1.5% 무작위 샘플만을 훈련
2. 학습 후, 보류된 데이터셋으로 성능 평가
3. 훈련에 사용되지 않은 Dg 데이터셋 성능 평가
4. 훈련 샘플 수를 b만큼 증가
Test 1. 데이터셋 사이즈가 성능과 일반화에 미치는 영향
-
Dp 에서의 성능
TriviaQA를 제외하고 훈련 샘플의 85-90% 정도로도 자체 테스트셋에서 포화에 도달할 수 있었으며, 더 많은 샘플을 추가한다고 하더라도 성능에 큰 영향을 미치지는 않았다. -
Dg 일반화
학습 시 사용되지 않았던 데이터는 대게 일찍 포화상태에 도달한다 -
TriviaQA 데이터셋
Dp 포화와 Dg 일반화 모두 다른 데이터셋에 비해 늦다.
네 개의 데이터셋 중 유일하게 자동 라벨링을 통해 라벨이 붙여졌고, 나머지 3개는 수동으로 주석이 추가되어서 이런 결과가 나타났을 수 있다. 또한 본 데이터셋은 잘 일반화되지 않는 모습을 보인다.
모델은 학습 시 사용된 데이터셋이 99.5%의 성능에 도달하기 전에 Dg에 대한 일반화를 중지하므로 데이터셋이 크다고 하여 성능에 도움이 되는 건 아니다.
또한 주석 품질이 높을 수록 더 빠르게 학습하며 더 잘 일반화되었다.
Test 2. 계층화된 라벨이 학습에 어떻게 도움이 되는가?
Active Learning에서 계층적으로 접근하며 실험을 진행한다.
계층화된 Annotators가 라벨링에 얼마나 도움이 되는지에 대한 추정치를 보여주는 게 더 빠른 속도로 높은 성능에 도달할 수 있는지를 확인한다.
Question Difficulty
적절한 의미를 학습하지 않고도 간단한 질문에 대답할 수 있다는 아이디어를 기반으로
질문에 대한 답을 두 번 예측하도록 한다.
1. 완전한 질문 문장과 처음 세 단어만을 추출한 문장을 넣고, 두 답변이 같으면 easy, 다르면 hard로 라벨링한다.
이후 hard 라벨 샘플링 /easy 라벨 샘플링을 각각 진행한다.

무작위 샘플링 방식과 비교해보면, 훈련 데이터 사용량이 더 높아졌다는 걸 확인할 수 있다.
Model Uncertainty
문서의 정보/지문 내에서 질문에 대한 답변을 예측하고, 답변에 대한 시작 및 종료 예측의 엔트로피를 평균화 한다. 이를 반복해 불확실성이 가장 높은 질문을 선택한다.

무작위 샘플링보다 더 나은 결과를 확인할 수 있다.
포화에는 16.9% 더 적은 데이터를 필요로하고, 일반화에는 19.2% 더 적은 데이터를 필요로 한다.
- model-guided 전략을 통해 더 적은 수의 질문으로 학습 데이터셋 및 일반화 모두 성능 수준 향상에 도움이 된다.
Test 3. 다양한 문맥에 먼저 라벨링 하는 이점
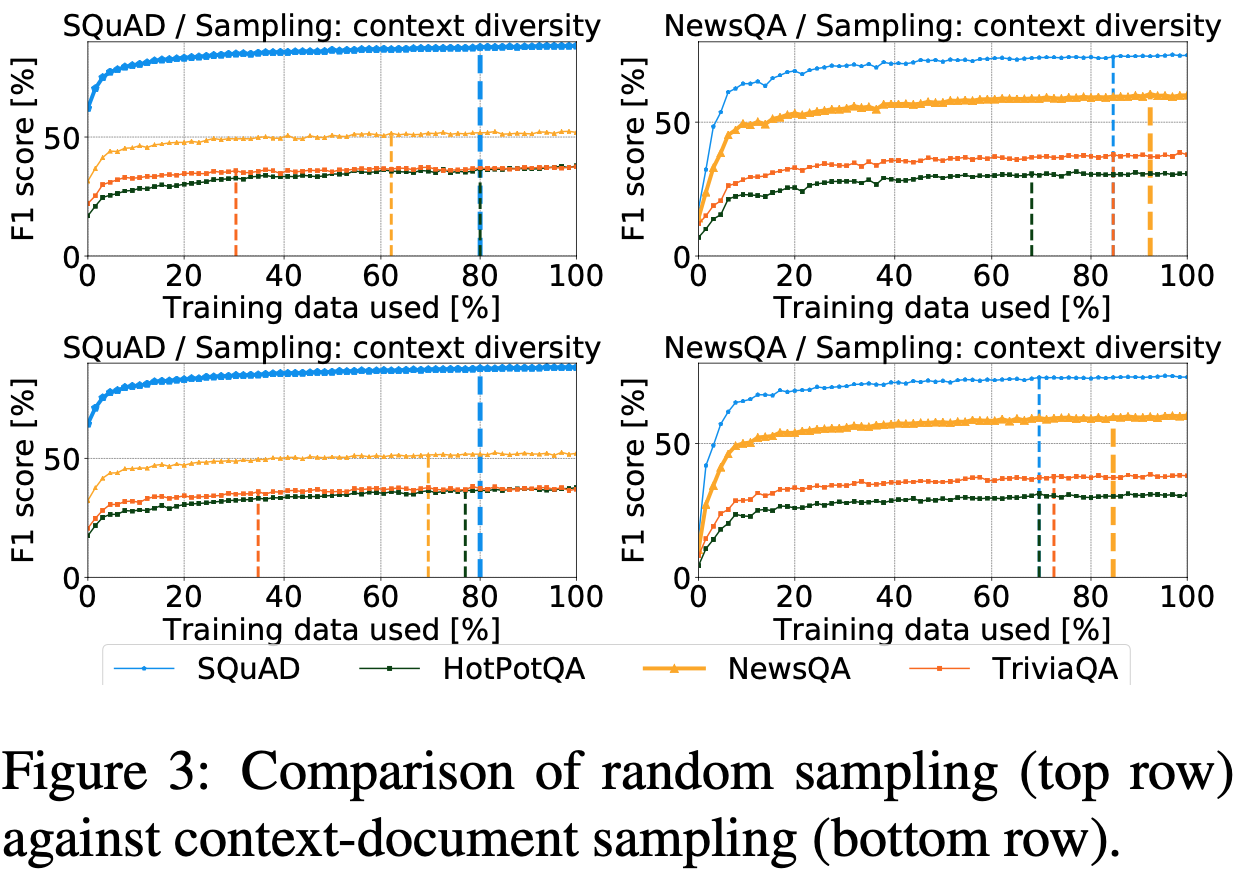
단일 문서에 대한 여러 질답 라벨이 포함되어있는 NewsQA와 SQuAD 데이터셋만을 사용한다.
랜덤 샘플링과 다양한 컨텍스트로 질문을 샘플링한 두 가지 방식을 비교하였다.
다양한 문서가 있는 NewsQA의 경우 포화 및 일반화 모두 이점을 보였고
소규모 위키피디아 기사에서 추출한 단락인 SQuAD는 개선사항이 거의 없었다.
- 다양한 문서를 함양 할 수록 다양한 질문으로 나누어져야 한다고 볼 수 있다.
- 다양한 문서의 말뭉치 라벨은 다양한 컨텍스트 문서 집합으로 나누어져야 합니다.
어떤 결과가 나왔는가?
-
주석 품질이 좋을 수록 더 적은 데이터셋 사이즈로도 충분한 학습이 가능하다.
-
model-guided 라벨링 전략을 개발한다. 라벨링 대상이 되는 질문의 subset을 제안하는 방법 개발.
-
라벨링 작업을 줄이면서 도메인 안팎의 데이터셋에서 원 성능을 유지하는 방식
- model-guided annotation 전략 실험은 학습 샘플의 65%만을 사용하면서 도메인 안팎의 데이터셋에 대해 동일한 성능을 달성했다.
