
컴퓨터가 이해하는 정보 단위 - 명령어
컴퓨터는 0과 1로 모든 정보를 표현하고, 0과 1로 표현된 정보만을 이해할 수 있다.
그리고 이렇게 0과 1로 표현되는 정보에는 크게 데이터(data)와 명령어(instruction)가 있다.
명령어(instruction)
- 명령어는 데이터를 움직이고 컴퓨터를 작동시키는 정보
- 데이터는 명령어를 위해 존재하는 일종의 재료
저급 언어 vs 고급 언어
저급 언어
저급 언어 (low-level programming language) : 컴퓨터가 직접 이해하고 실행할 수 있는 언어
저급 언어의 종류
① 기계어(machine code) : 0과 1의 명령어 비트로 이루어진 저급 언어
② 어셈블리어(assembly language) : 0과 1로 이루어진 기계어를 읽기 편한 형태로 번역한 저급 언어
고급 언어
고급 언어 (high-level programming language) : 개발자가 이해하기 쉽게 만든 언어
고급 언어의 종류
① 컴파일 언어 : 컴파일어에 의해 소스 코드 전체가 저급 언어로 변환되어 실행되는 고급 언어
컴파일(compile) : 컴파일 언어로 작성된 소스코드 전체가 저급 언어로 변환되는 과정
컴파일러(compiler) : 컴파일을 수행해 주는 도구
목적 코드(object code) : 컴파일러를 통해 저급 언어로 변환된 코드- 소스 코드 전체가 저급 언어로 변환
- 소스 코드 내에 오류가 하나라도 있으면 컴파일이 불가능
② 인터프리터 언어 : 인터프리터에 의해 소스 코드가 한 줄씩 실행되는 고급 언어
인터프리터(interpreter) : 인터프리터 언어로 작성된 소스 코드를 한 줄씩 저급 언어로 변환하여 실행해 주는 도구- 소스 코드를 한 줄씩 차례로 실행
- 소스 코드 N번째 줄에 문법 오류가 있더라도 N-1번째 줄까지는 올바르게 수행
❗ 하나의 프로그래밍 언어가 반드시 둘 중 하나의 방식만으로 작동한다고 생각하는 것은 오개념이다.
❗ 예시로 대표적인 인터프리터 언어로 알려진 파이썬도 컴파일을 하지 않는 것은 아니며,
자바의 경우 저급 언어가 되는 과정에서 컴파일과 일터프리트를 동시에 수행한다.
❗ 고급 언어와 저급 언어를 이해할 때는 고급 언어가 저급 언어로 변환되는 대표적인 방법에는
컴파일 방식과 인터프리트 방식이 있다고 이해해야 한다.명령어의 구조
명령어 : 연산 코드 + 오퍼랜드
연산 코드와 오퍼랜드
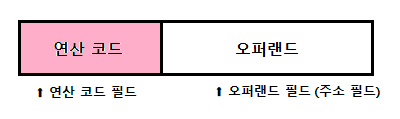
오퍼랜드
오퍼랜드 (operand) : 연산에 사용할 데이터 또는 연산에 사용할 데이터가 저장된 위치 (피연산자)
- 오퍼랜드 필드에는 숫자와 문자등을 나타내는 데이터 또는 메모리나 레지스터 주소가 올 수 있다.
- 오퍼랜드는 명령어 안에 하나도 없을 수도 있고, 여러 개가 있을 수도 있다.
0-주소 명령어 : 오퍼랜드 0개
1-주소 명령어 : 오퍼랜드 1개
2-주소 명령어 : 오퍼랜드 2개
3-주소 명렁어 : 오퍼랜드 3개
연산 코드
연산 코드 (operation) : 명령어가 수행할 연산 (연산자)
- 기본적인 연산 코드 유형 : 데이터 전송/ 산술, 논리 연산/ 제어 흐름 변경/ 입출력 제어
- 명령어의 종류와 생김새는 CPU마다 다르기 때문에 연산 코드의 종류와 생김새 또한 CPU마다 다르다.
주소 지정 방식
유효 주소(effective address) : 연산의 대상이 되는 데이터가 저장된 위치
주소 지정 방식(addressing mode) : 유효 주소를 찾는 방법
즉시 주소 지정 방식
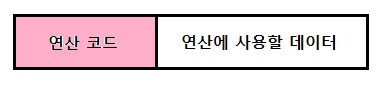
즉시 주소 지정 방식(immediate addressing mode) : 연산에 사용할 데이터를 오퍼랜드 필드에 직접 명시하는 방식
- 가장 간단한 형태의 주소 지정 방식
- 장점 : 연산에 사용할 데이터를 메모리나 레지스터로부터 찾는 과정이 없기 때문에 빠름
- 단점 : 표현할 수 있는 데이터의 크기가 작아짐
직접 주소 지정 방식
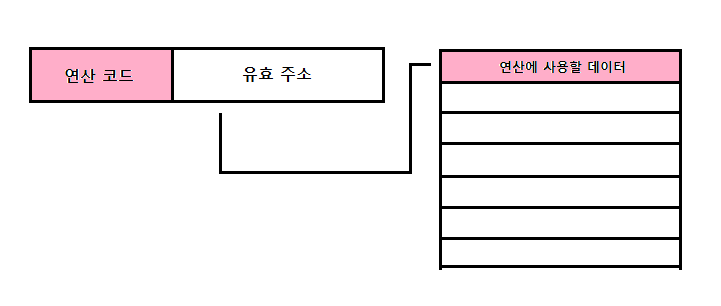
직접 주소 지정 방식(direct addressing mode) : 오퍼랜드 필드에 유효 주소를 직접적으로 명시하는 방식
- 데이터 크기는 즉시 주소 지정 방식보다 커짐
- 여전히 유효 주소를 표현할 수 있는 범위가 연산 코드의 비트 수만큼 줄어듦
간접 주소 지정 방식
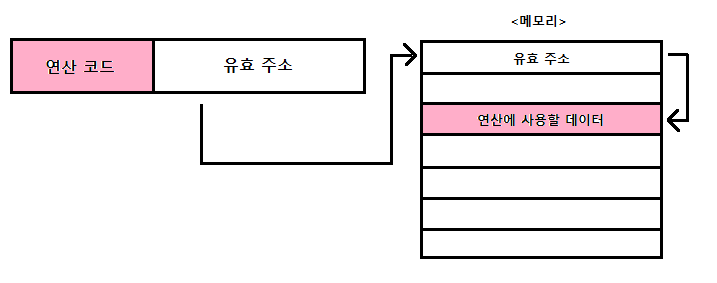
간접 주소 지정 방식(indirect addressing mode) : 유효 주소의 주소를 오퍼랜드 필드에 명시하는 방식
- 직접 주소 지정 방식보다 표현할 수 있는 유효 주소의 범위가 더 넓어짐
- 두 번의 메모리 접근이 필요하기 때문에 일반적으로 느린 방식
레지스터 주소 지정 방식
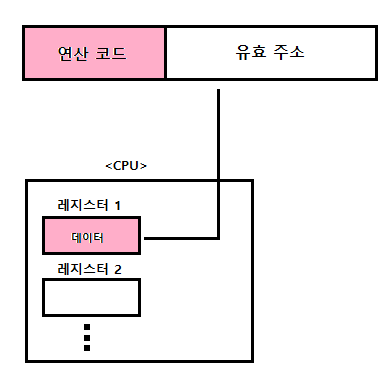
레지스터 주소 지정 방식(register addressing mode) : 연산에 사용할 데이터를 저장한 레지스터를 오퍼랜드 필드에 직접 명시하는 방식
- CPU 외부에 있는 메모리에 접근하는 것보다 CPU 내부에 있는 레지스터에 접근하는 것이 더 빠르기에 레지스터 주소 지정방식은 직접 주소 지정 방식보다 빠르게 데이터에 접근 가능
- 직접 주소 지정 방식과 비슷하게 표현할 수 있는 레지스터 크기에 제한이 생길 수 있음
레지스터 간접 주소 지정 방식
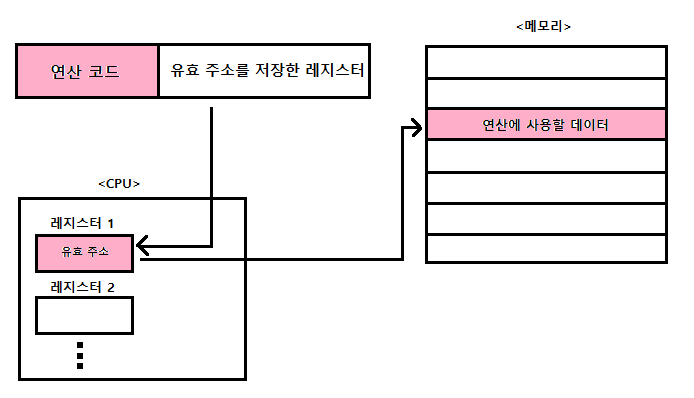
레지스터 간접 주소 지정 방식(register indirect addressing mode) : 연산에 사용할 데이터를 메모리에 저장하고 그 유효 주소를 저장한 레지스터를 오퍼랜드 필드에 명시하는 방법
- 유효 주소를 찾는 과정이 간접 주소 지정 방식과 비슷하지만, 메모리에 접근하는 횟수가 한 번으로 줄어듦
- 레지스터 간접 주소 지정 방식은 간접 주소 지정 방식보다 빠름
스택과 큐
스택
스택(stack) : 한쪽 끝이 막혀 있는 통과 같은 저장 공간
- 나중에 저장한 데이터를 가장 먼저 빼내는 데이터 관리 방식(후입선출) ➡
LIFO(Last In First Out)
큐
큐(queue) : 스택과는 달리 양쪽이 뚫려 있는 통과 같은 저장 공간
- 가장 먼저 저장된 데이터부터 빼내는 데이터 관리 방식(선입선출) ➡
FIFO(First In First Out)
참고
- 혼자 공부하는 컴퓨터 구조 + 운영체제 (강민철 지음)
