R의 기초 사용법
1. 기초 사용법
- R Studio 프로그램에서는 스크립트를 이용해 명령어를 실행, 저장하도록 한다.
- R Studio에서 제공하는 스크립트를 기준으로 설명한다.
기본 사용 기능
-
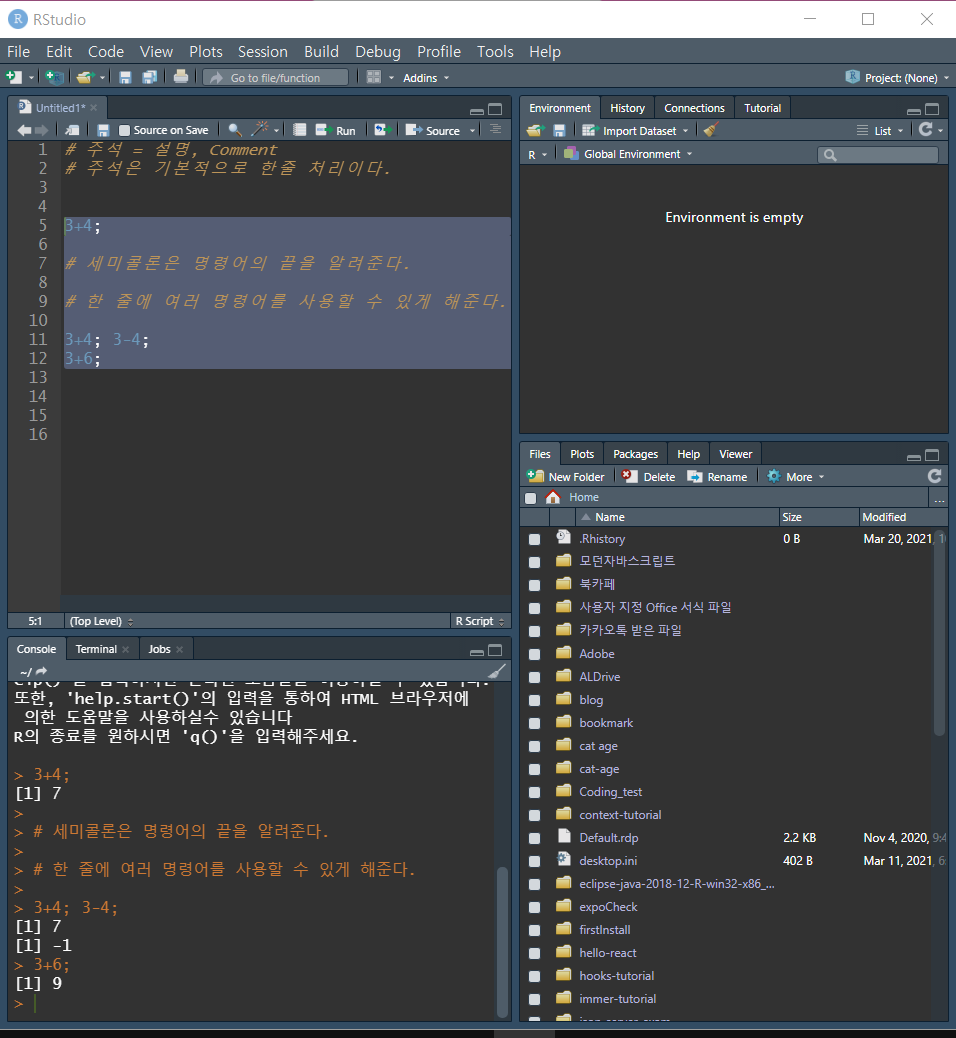
# (해시 기호)
-
주석 (Comment)의 기능
-
프로그램 전반적인 내용, 명령어의 내용 등이 무엇을 의미하는지 알 수 있도록 사용자가 설명을 달아주는 기능
-
# 뒤에 있는 한 줄이 주석으로 처리되면, R에서 지정된 문법을 검사하지 않는다.
- 다른 줄도 주석처리를 하고 싶으면 해당 줄 앞에 #을 입력해야한다.
-
-
; (세미콜론)
-
하나의 명령어가 끝났음을 알려주는 기능
-
한 줄에 하나의 명령 밖에 없으면 세미콜론을 해 주지 않아도 명령어가 끝났음을 인식한다.
-
-
Enter (엔터)
- 다음 줄로 이동할 때 사용
-
Ctrl + Enter (컨트롤 + 엔터)
-
R의 명령어를 실행하는 기능
-
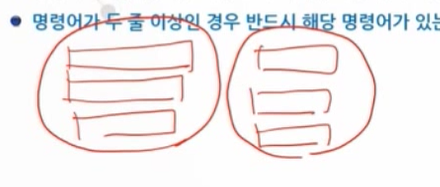
명령어가 한 줄인 경우 마우스의 위치는 해당 줄의 아무 곳에 있어도 상관이 없다.
-
명령어가 두 줄 이상인 경우 반드시 해당 명령어가 있는 곳을 블록을 잡고 실행한다.
-
R GUI에서는 Ctrl + R
-
-
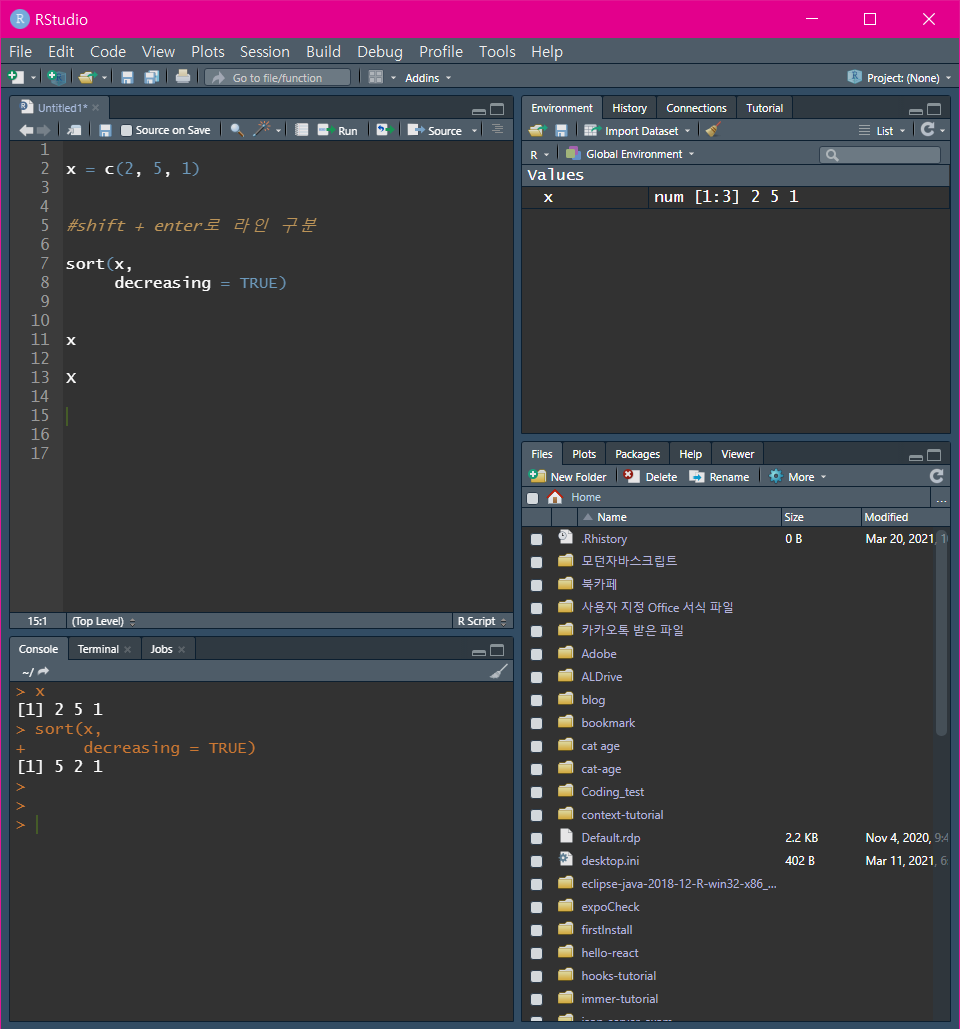
Shift + Enter (시프트 + 엔터)
-
동일한 위치에 다른 전달인자 (Argument)를 올 수 있도록 해준다.
-
Shift + Enter를 이용해서 명령어가 길게 표현되는 것을 방지한다.

-
-
대소문자
- R은 대소문자를 구분한다 (Case Sensitive)
- 소문자 'x'와 대문자 'X'는 전혀 다른 것을 의미하기 때문에 주의가 필요하다.
2. R Script 실행하기
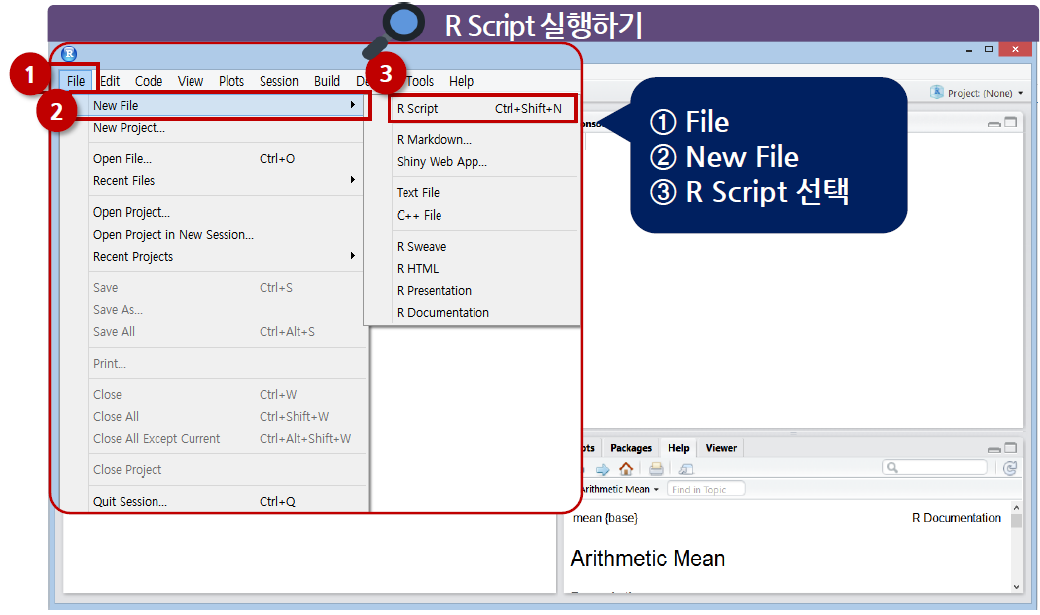
- Tools -> Global options -> apperance 에서 글자 크기 등 조정 가능하다.
-
Ctrl + Enter로 실행할 수 있다.
-
enter를 기준으로 실행되는 것을 볼 수 있음
3. R의 연산자
산술 연산자(Arithmetic Operator)
-
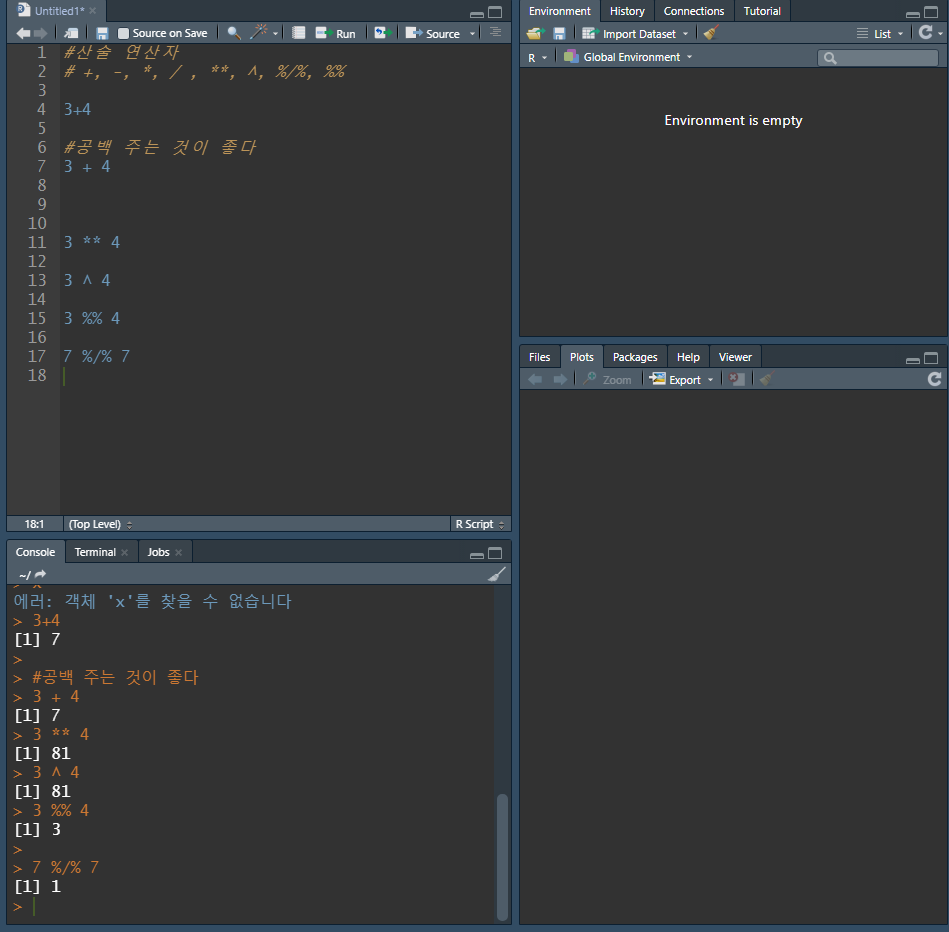
1개 이상의 수치에 대한 연산
-
더하기, 빼기, 곱하기, 나누기, 거듭제곱, 몫, 나머지를 구할 수 있다.
-
산술 연산자의 우선순위 (높은 순)
-
괄호 (( ))
-
거듭제곱(^(Caret), **)
-
곱하기(*), 나누기(/)
-
더하기(+), 빼기(-)
-
-
⭐ 동일한 우선순위의 산술 연산자가 나열된 경우 왼쪽이 오른쪽보다 우선순위를 갖게 된다.

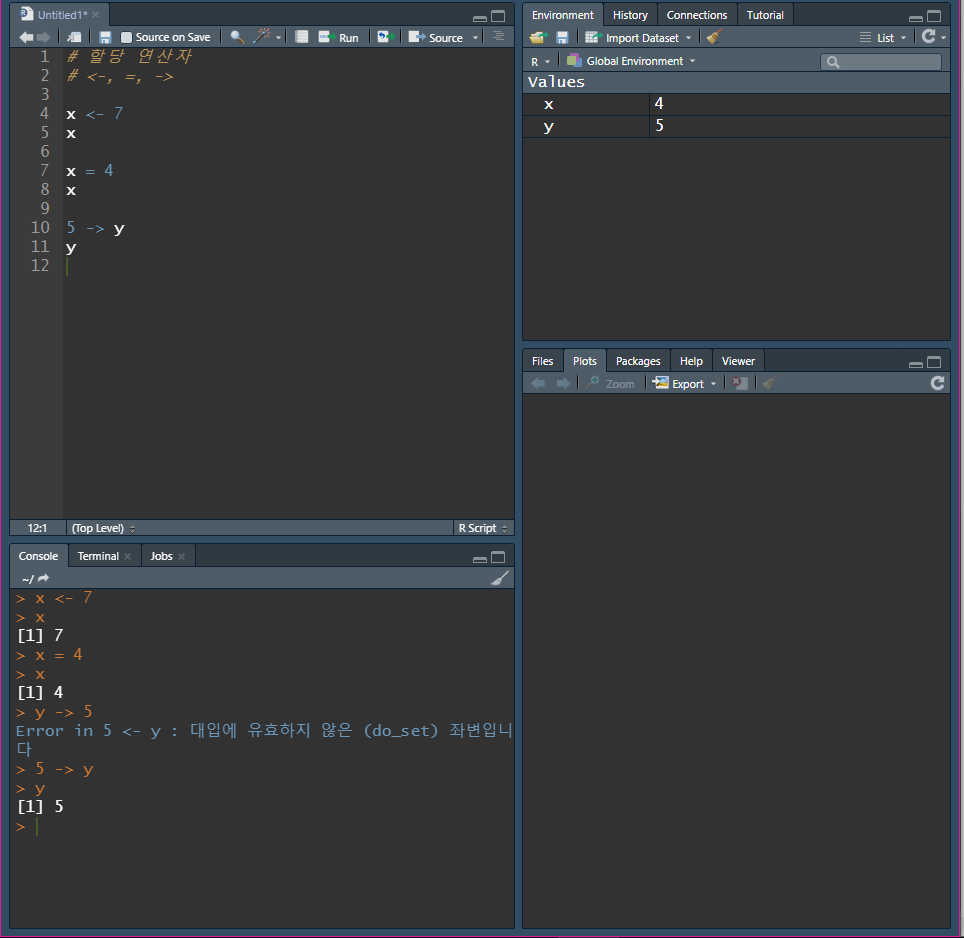
할당 연산자 (Allocation Operator)
-
어떤 객체의 이름(변수 이름, 데이터 이름)에 특정한 값을 저장할 때 사용하는 연산자
-
객체에 무엇이 있는지를 일부러 새로운 명령어를 실행하지 않아도 알 수 있는 기능
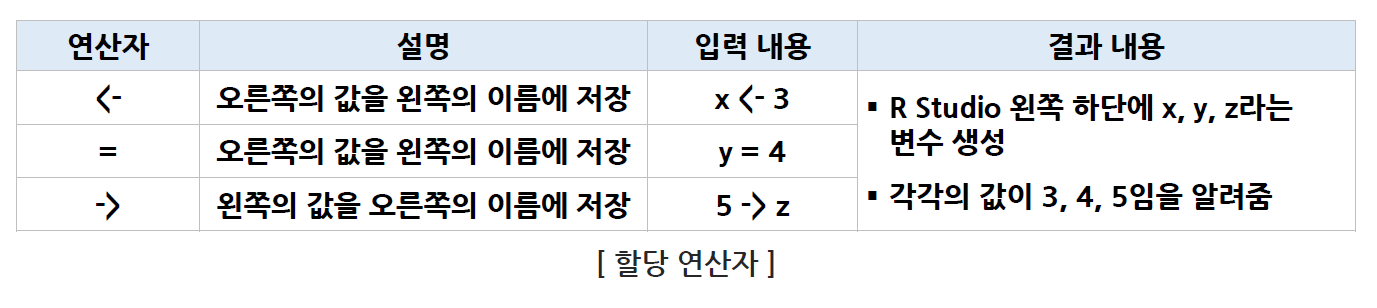
-
왼쪽 화살표와 =을 병행해서 사용한다.
->는 잘 사용되지 않는다.
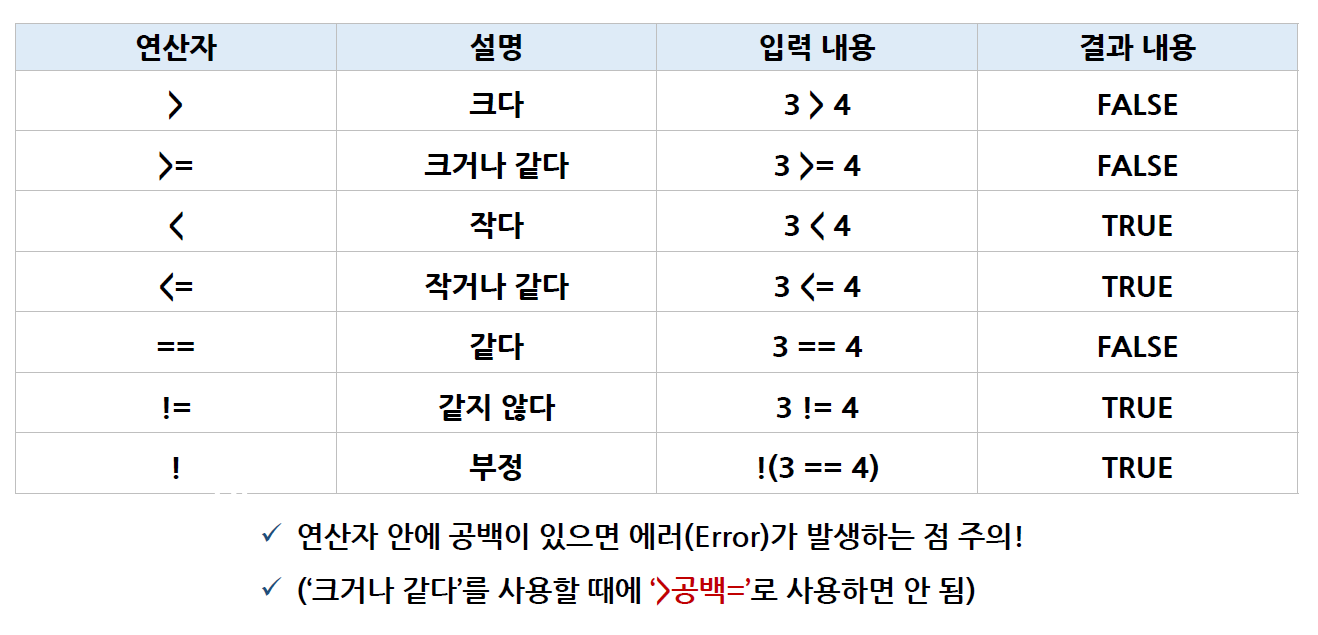
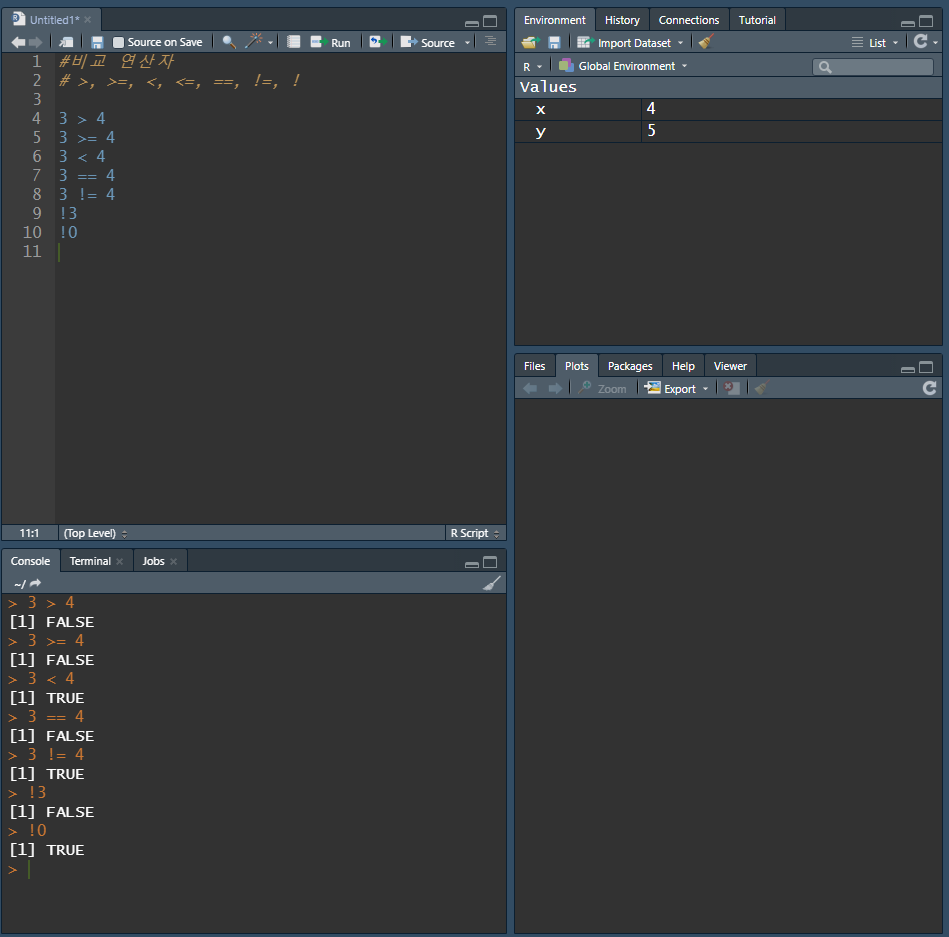
비교 연산자 (Relational Operator)
- 두 개 값에 대한 비교로써 맞으면 TRUE, 맞지 않으면 FALSE를 반환하여비교 연산의 최종적인 결과가 갖는 값
-
비교 연산자의 종류
-
크다
A > B -
크거나 같다
-
작다
-
작거나 같다
-
같다
== -
같지 않다
!= -
아니다
!
-
논리 연산자
-
두 개 이상의 조건을 비교하여 결과를 낸다.
-
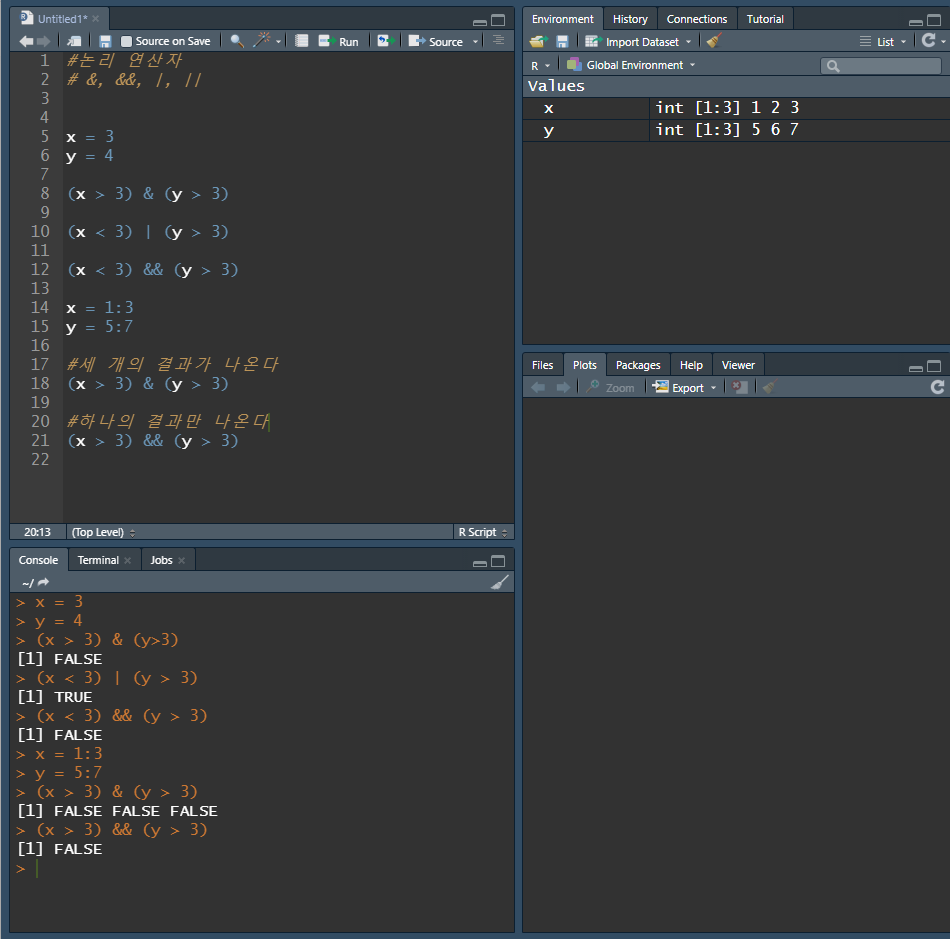
&, &&는 모든 조건이 참일 때에만 최종적인 결과가 TRUE가 된다.
-
|, ||는 조건 중에서 하나라도 참이면 최종적인 결과가 TRUE가 된다.
-
벡터(Vector)가 오면 &와 &&의 결과 또는 |와 ||의 결과에는 차이가 발생한다.

-
&
-
AND의 개념
-
두 개(또는 그 이상)의 조건을 동시에 만족할 때만 TRUE가 되는 논리 연산
-
&는 데이터가 하나인 경우나 데이터가 두 개 이상인 경우
-
X = 1 : 3 (== X = (1,2,3)), Y = 5 : 7 -> (X > 3) && (Y > 3) -> (X: 1, y: 5) -> FALSE
-
-
&&
-
AND의 개념으로 두개(또는 그 이상)의 조건을 동시에 만족할 때만 TRUE가 되는 논리 연산
-
데이터가 하나인 경우에만 가능
-
벡터(Vector)인 경우 벡터(Vector)의 첫 번째만 작동하고 나머지는 작동하지 않음
-
X = 3, Y = 4 -> (X > 3) && (Y > 3) -> FALSE
-
-
|
-
OR의 개념
-
두 개(또는 그 이상)의 조건 중에서 하나만 만족하여도 TRUE가 되는 논리 연산
-
데이터가 하나인 경우나 두 개 이상인 경우
-
-
||
-
OR의 개념으로 두 개(또는 그 이상)의 조건 중에서 하나만 만족하여도 TRUE가 되는 논리 연산
-
데이터가 하나인 경우에만 가능
-
벡터(Vector)인 경우에는 벡터(Vector)의 첫 번째만 작동하고 나머지는 작동하지 않음
-
4. R의 데이터 유형
기본 데이터 유형
- R 에서 데이터의 기본적인 속성으로 데이터의 유형이 있음
- 데이터가 어떤 값(숫자, 문자)으로 이루어져 있는가를 의미
- 데이터 유형에는 기본적인 것과 특수한 형태로 구성
-
기본 데이터 유형
-
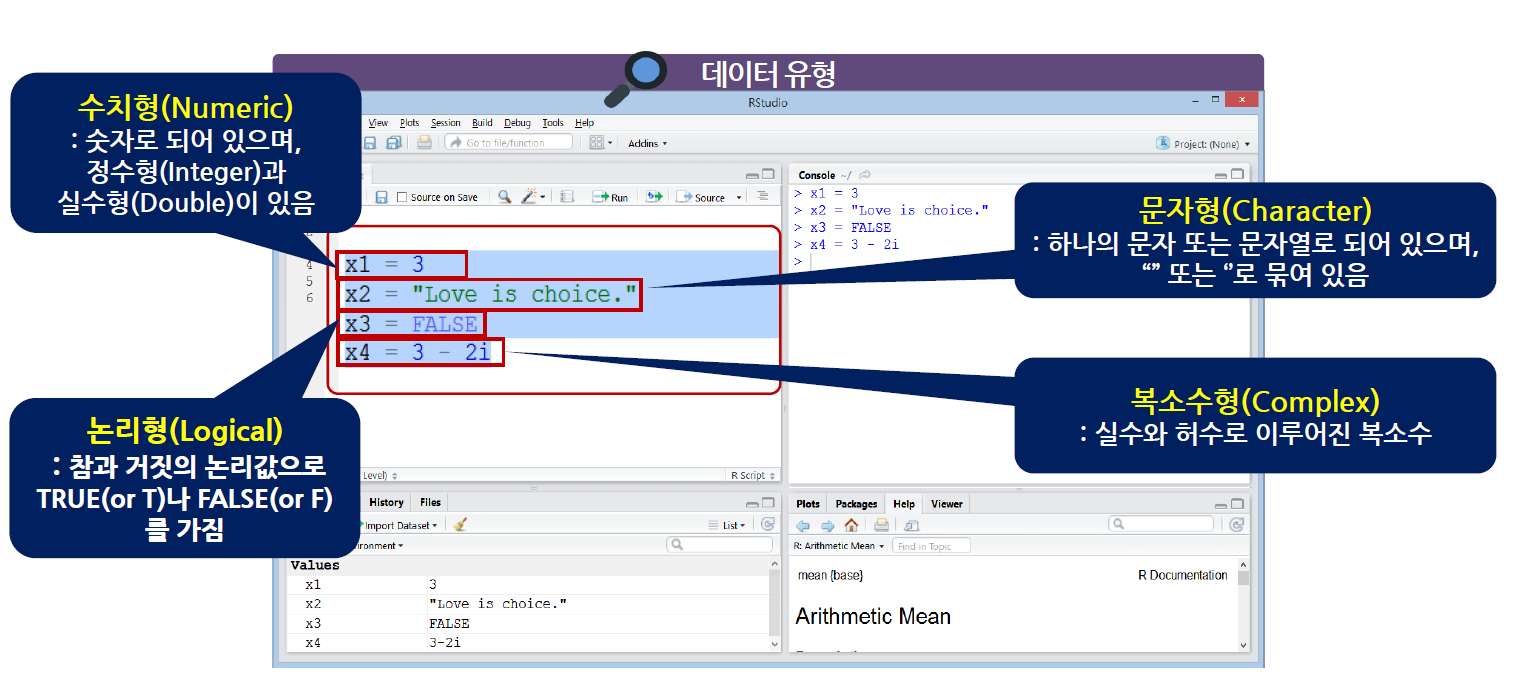
기본적인 데이터 유형에는 수치형, 문자형, 논리형, 복소수형이 있다.
-
수치형, 문자형, 논리형이 자주 사용
-
복소수형은 수학분야를 다룰 때에 사용
-
특수 형태의 데이터 유형
-
NULL
-
존재하지 않는 객체로 지정할 때 사용
- 객체: 데이터, 그래프, 분석 결과를 담고 있는 것을 가리킨다.
-
-
NA
- Not Available의 약자로 결측치(Missing value)를 의미

- Not Available의 약자로 결측치(Missing value)를 의미
-
NaN
-
Not available Number 의 약자로 수학적으로 계산이 불가능한 수를 의미
-
예 : sqrt 3) 로 음수에 대한 제곱근은 구할 수 없다.
-
-
Inf
- Infinite의 약자로 양의 무한대
-
-Inf
- 음의 무한대
5. 데이터 유형 알아내기
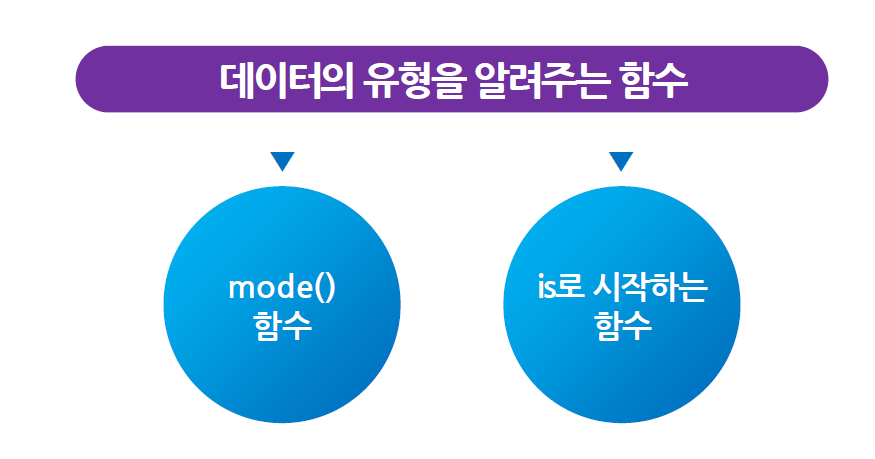
mode() 함수
-
mode() 함수
-
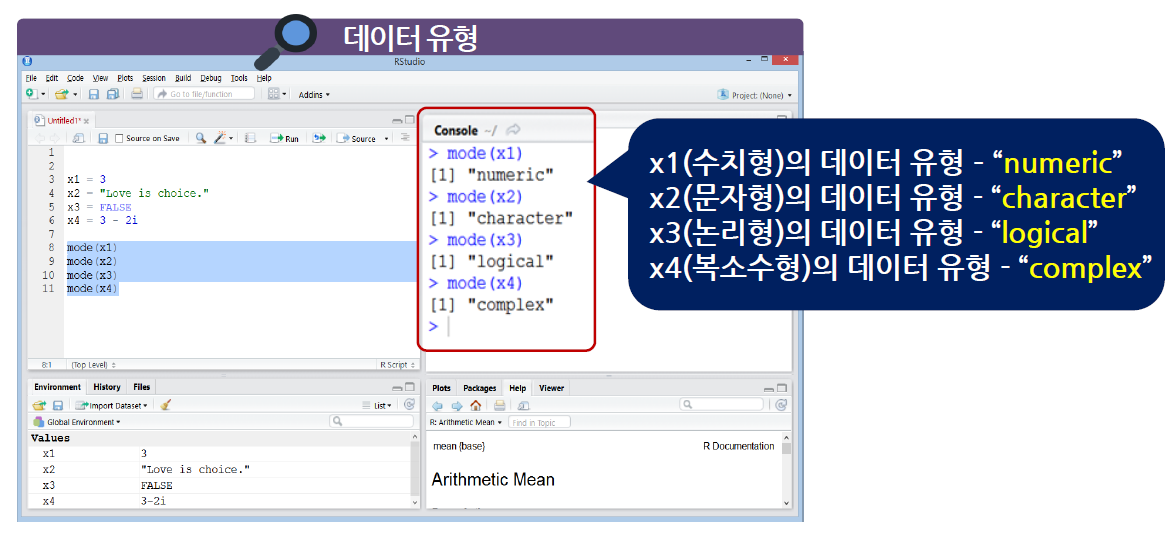
mode(데이터명) -
문자형 형태로 최종적인 결과를 알려준다.
- (“numeric”, “character”, “logical”, “complex”) 중에 하나로 표현
-
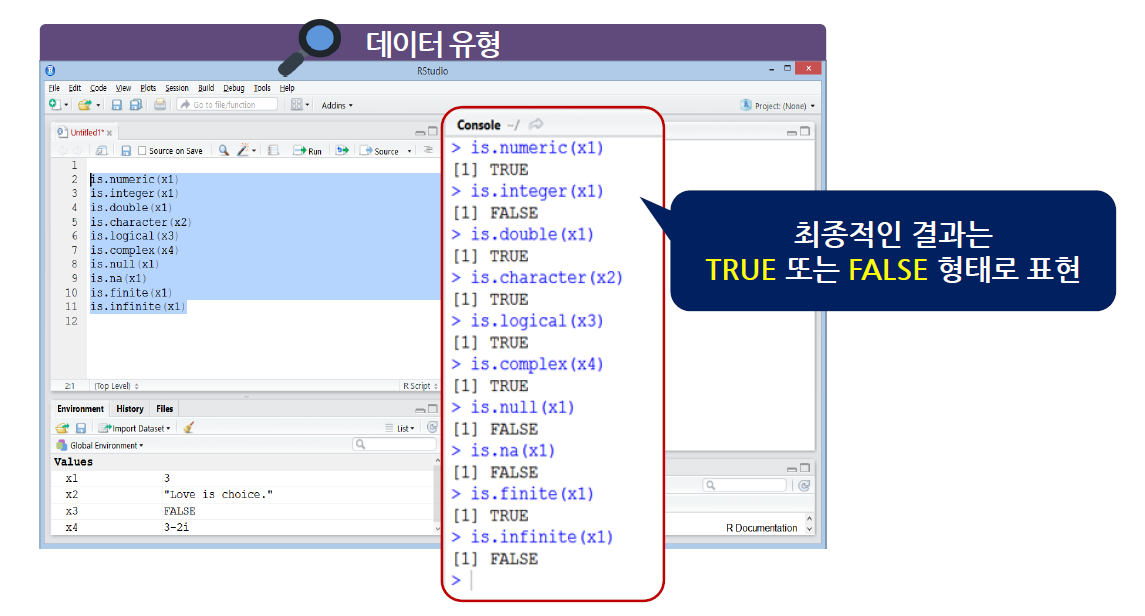
is로 시작하는 함수
- is로 시작하는 함수들의 최종적인 결과는 TRUE 또는 FALSE 형태로 나타남

6. 데이터 유형의 우선순위
-
대표적인 데이터 유형(수치형, 문자형, 논리형, 복소수형)에는 우선순위가 있다.
-
벡터와 같은 데이터에서 발생한다.
-
벡터는 하나의 유형만 가질 수 있다.
-
벡터를 만들 때, 여러가지의 유형을 넣어도 최종적인 결과에는 하나의 유형으로 변경된다.
-
-
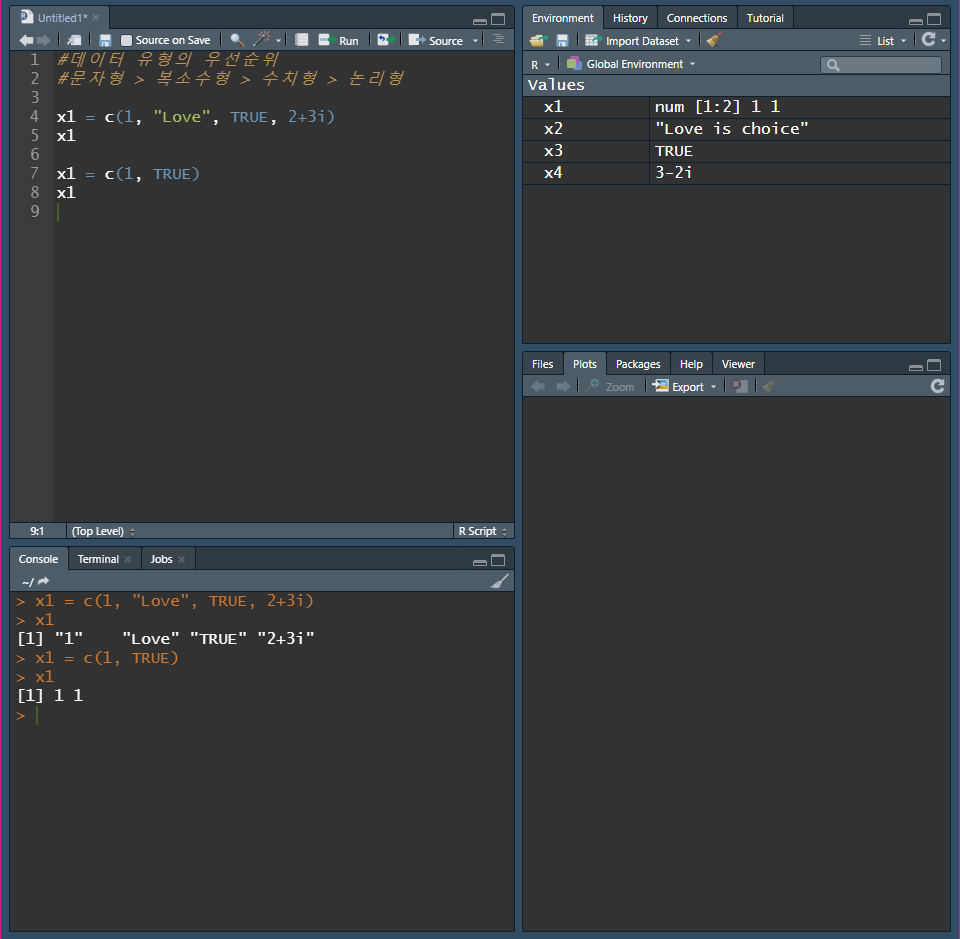
4가지 데이터 유형의 우선순위 (문자형 > 복소수형 > 수치형 > 논리형)
-
문자형(Character)
-
복소수형(Complex)
-
수치형(Numeric)
-
논리형(Logical)
-
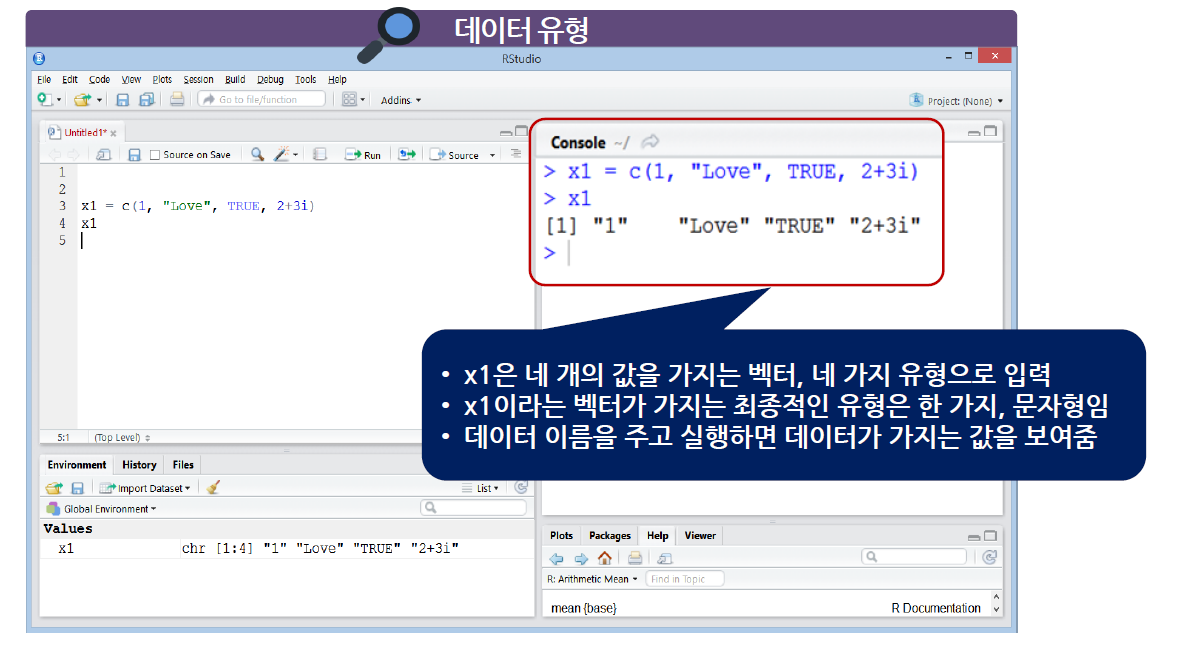
- 전부 우선순위가 가장 높은 문자형으로 변경된다.
7. 데이터 유형의 강제 변환
데이터 유형을 강제 변경하는 함수
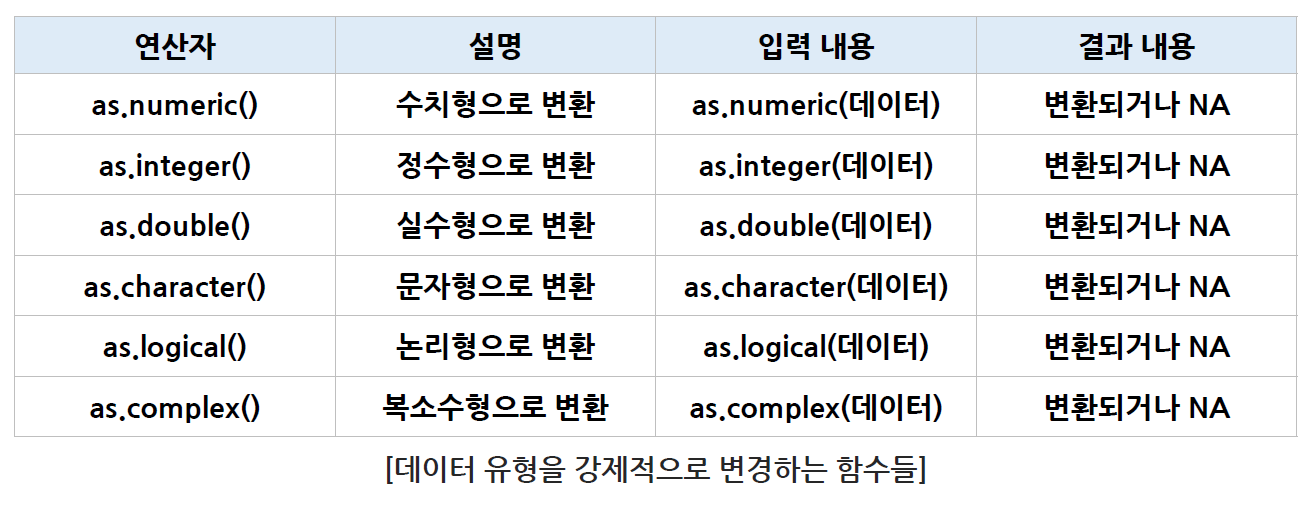

-
데이터 유형 중 우선순위가 낮은 형태에서 우선순위가 높은 형태로는 강제적으로 유형 변환이 가능하다.
-
우선순위가 높은 형태에서 우선순위가 낮은 형태로의 변환은 일부만 가능하기 때문에 경우에 따라서 강제적으로 유형이 변경되지 않을 수 있다.

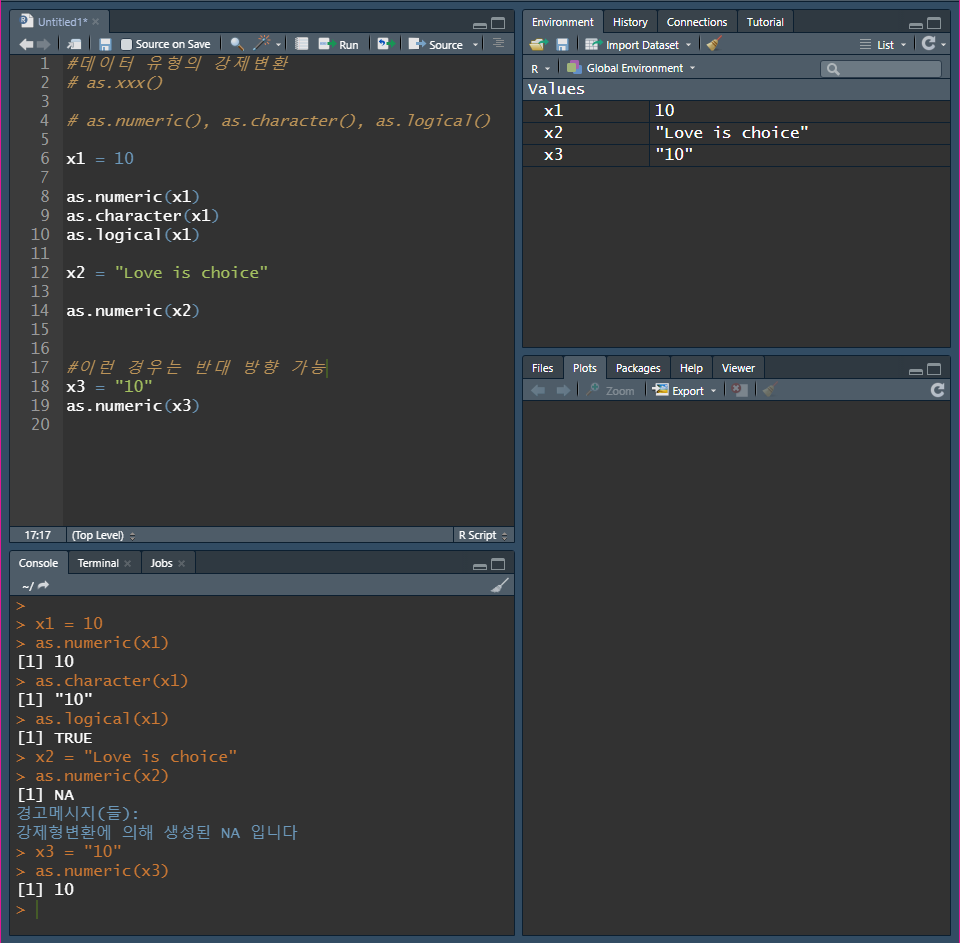
8. 벡터란?
벡터의 개념
- R은 데이터가 어떤 구조(Structure) 또는 형태로 되어 있느냐에따라 벡터(Vector), 행렬(Matrix), 배열(Array), 데이터프레임(Data frame), 요인(Factor), 리스트(List) 등으로 구분됨
- 가장 대표적인 데이터 형태는 벡터(Vector)이다.
-
백터의 개념
-
백터는 동일한 데이터 유형으로 이루어진 한 개 이상의 값들로 구성
-
하나의 열(Column)로 되어 있다.
-
벡터는 데이터 분석의 가장 기본 단위이다.
-
9. 벡터 생성하기
하나의 값으로 이루어진 벡터

두개 이상의 값으로 이루어진 백터
- 두 개 이상의 값으로 이루어진 벡터를 생성할 때와 하나의 값으로 이루어진 벡터를 생성하는 방법이 다름
- 두 개 이상의 값으로 이루어진 벡터를 생성하는 것이 대표적인 방법
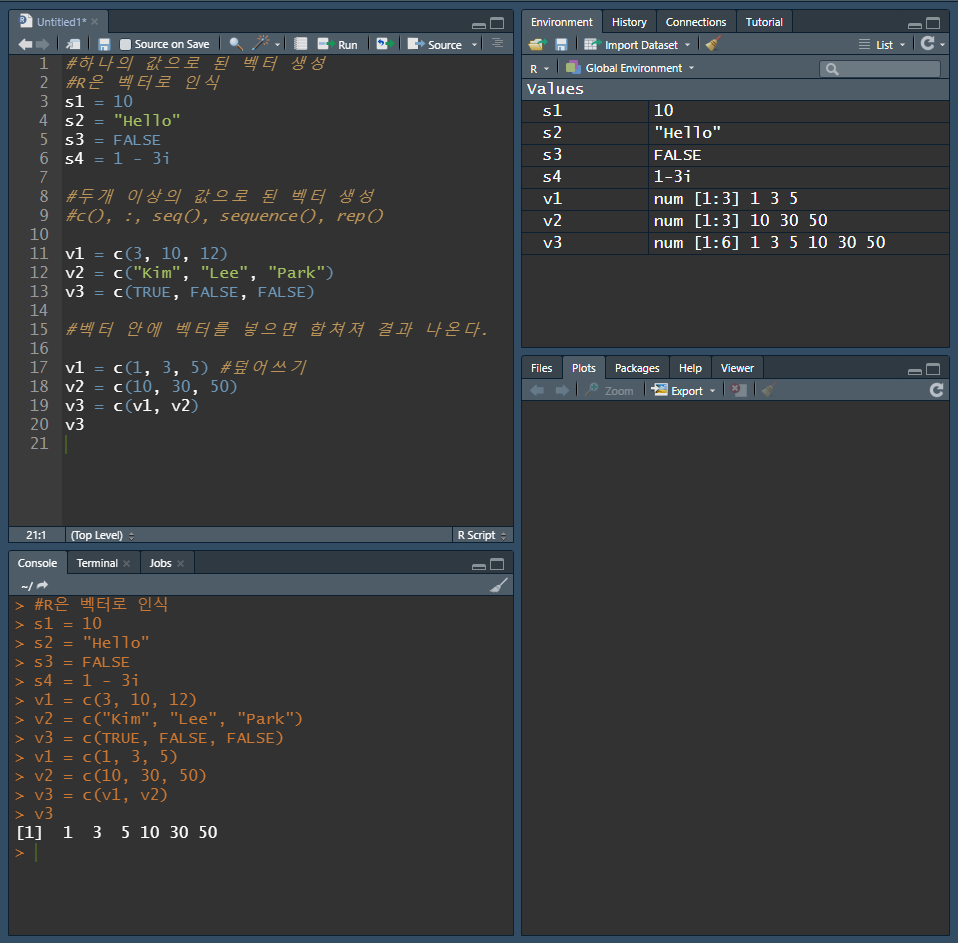
- c(), :, seq(), sequence(), rep()
-
c()
-
c() 함수는 combine 또는 concatenate의 약자
-
벡터를 생성하는 가장 대표적인 방법
-
네 가지 유형(수치형, 문자형, 논리형, 복소수형)에 적용 가능
- 수치형 벡터, 문자형 벡터, 논리형 벡터, 복소수형 벡터 생성 가능
-
규칙이 없는 데이터로 이루어진 벡터를 생성할 때 사용
- 규칙이 있을 때에는 다른 기능을 이용
-
수치형 벡터인 v1, 문자형 벡터인 v2, 논리형 벡터인 v3을 생성하면 다음과 같다.
-
c() 함수는 벡터들을 하나로 합쳐서 하나의 새로운 벡터를 생성할 수도 있음
-
새로운 v1 벡터와 v2를 생성, c() 함수를 이용하고, v1, v2 벡터를 연결하여 v3이라는 새로운 벡터를 생성할 수 있음
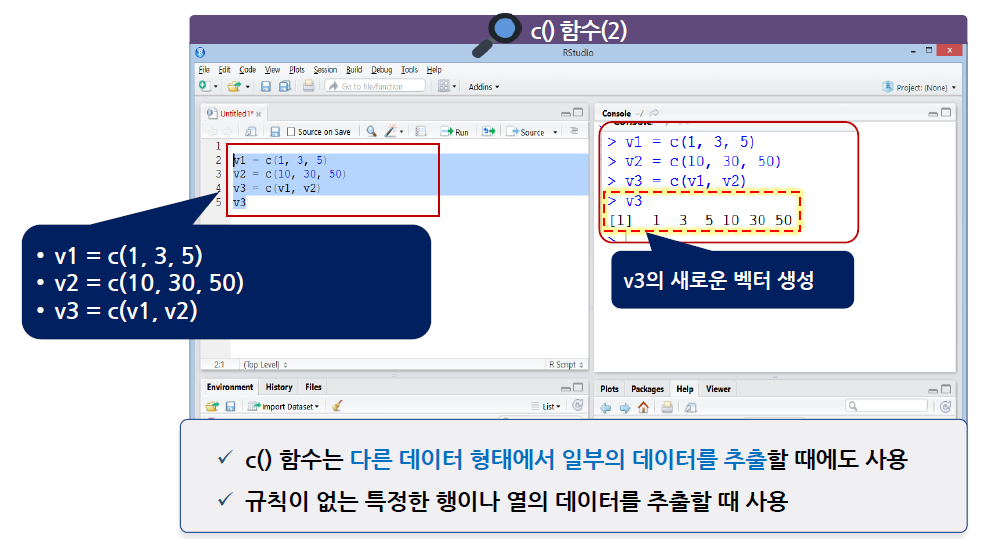
-
-
:
-
콜론(:)은 수치형에만 적용
-
1씩 증가되거나 1씩 감소되는 규칙이 있는 값으로 이루어진 벡터를 생성할 때 사용
-
start:end 구조로 사용
-
start, end는 숫자
-
start > end이면 1씩 감소
-
start < end이면 1씩 증가
-
start=end이면 start 또는 end가 된다.
- 둘 중 하나의 값
-
-
시작은 무조건 start에서 시작, end를 넘지 않음
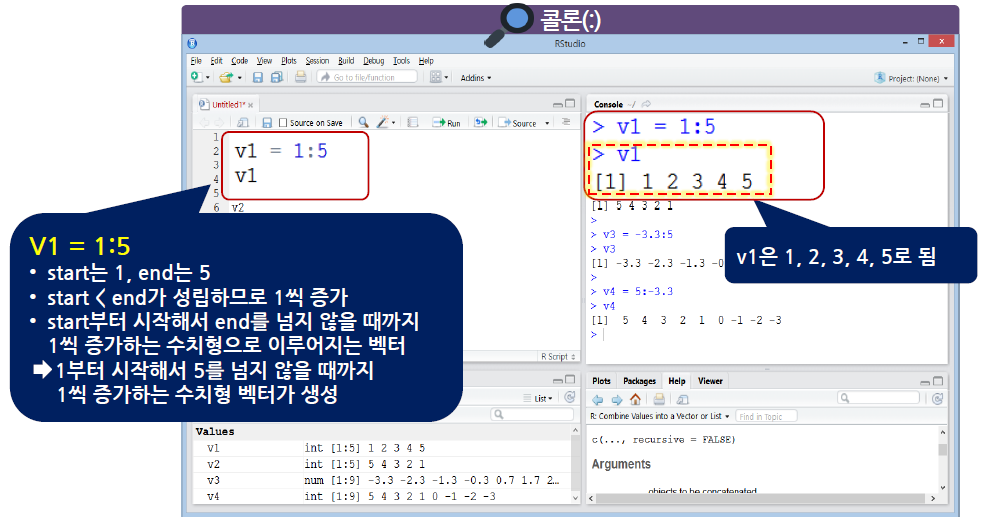
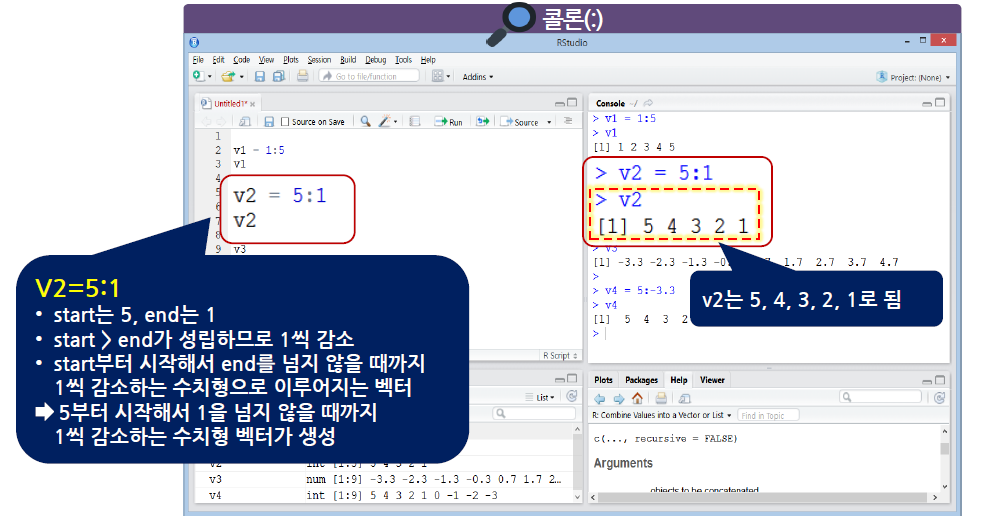
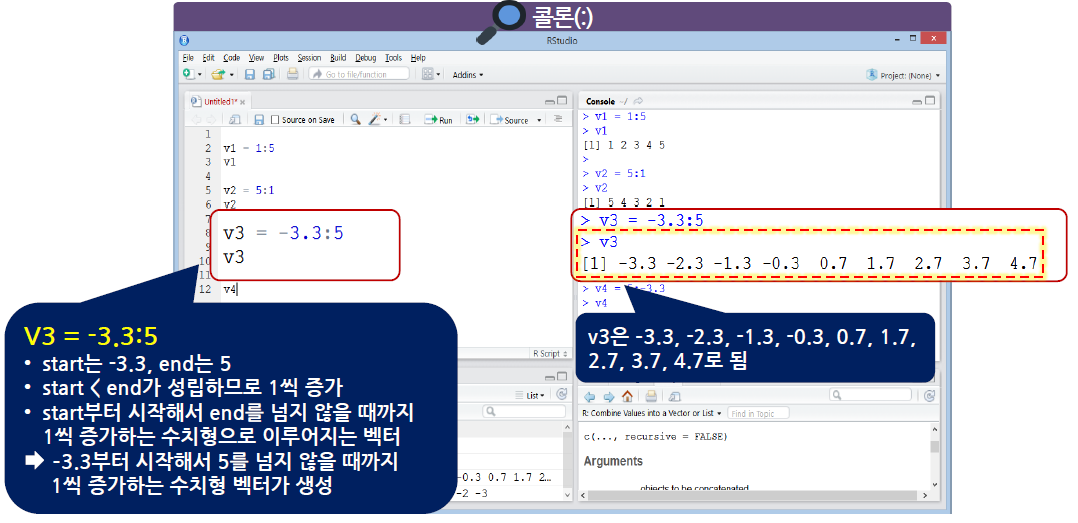
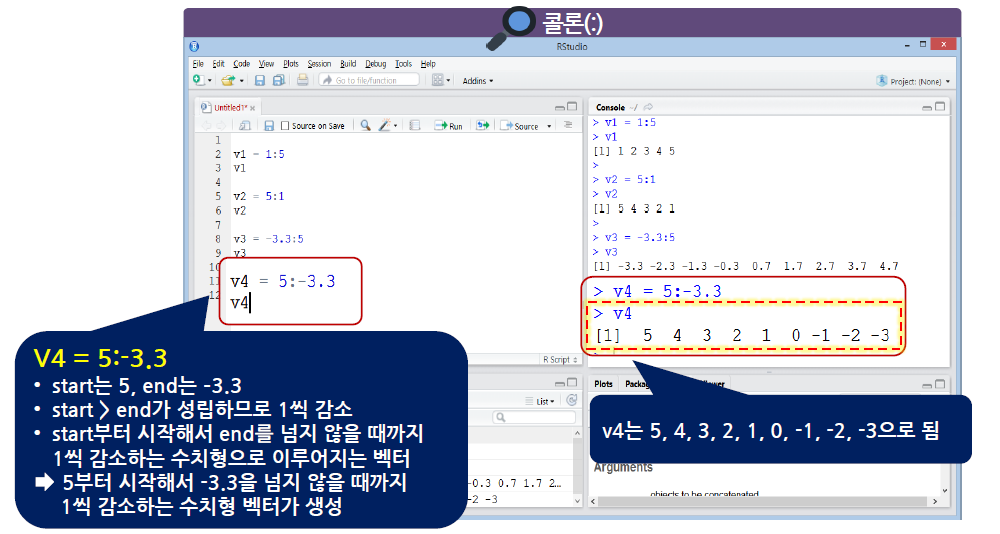
- 콜론(:)도 벡터를 생성할 때 사용하지만, 다른 데이터 형태에서 연달아 있는 특정한 행이나 열의 데이터를 추출할 때 사용할 수 있음
-
-
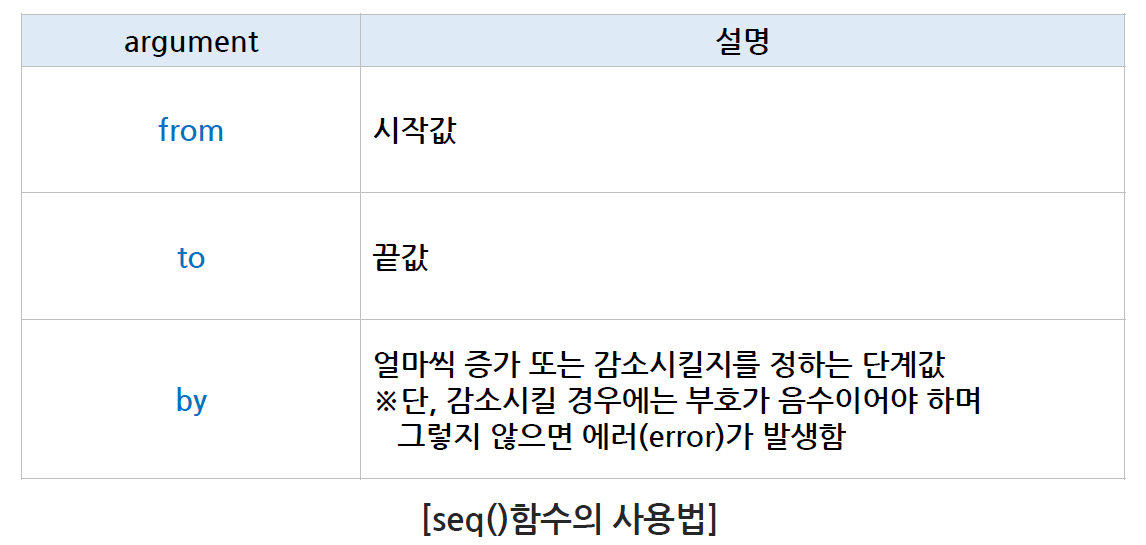
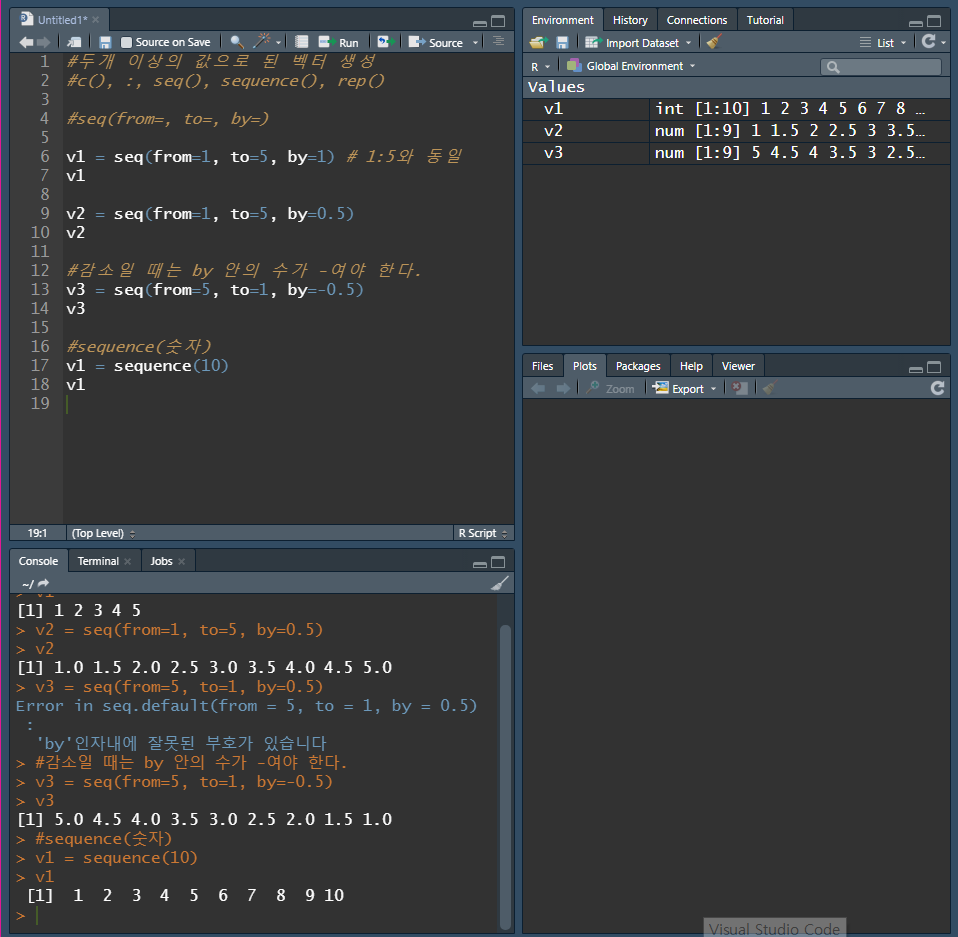
seq()
-
seq() 함수는 sequence의 약자
-
콜론(:)의 확장 또는 일반화
-
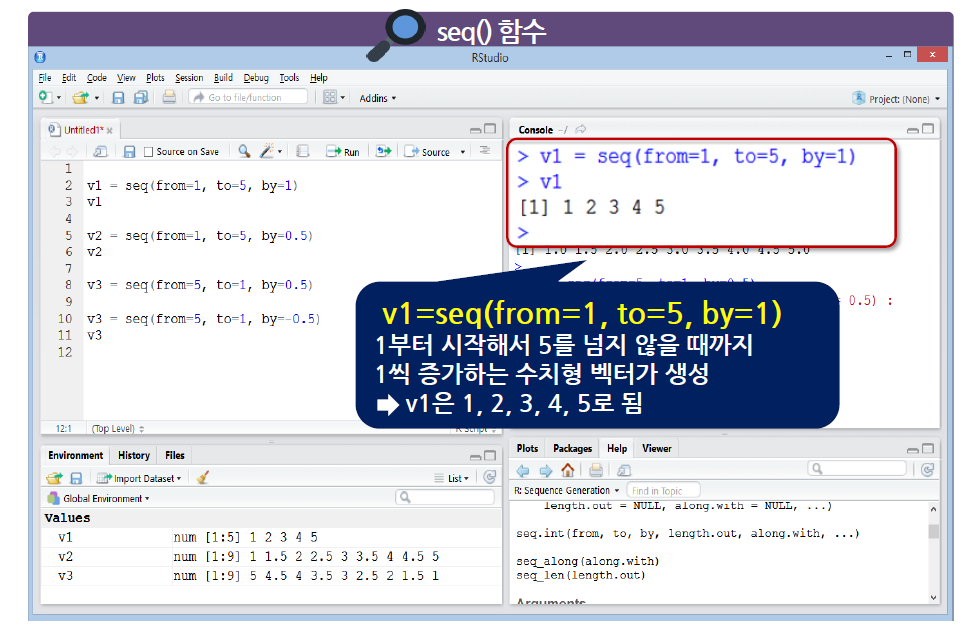
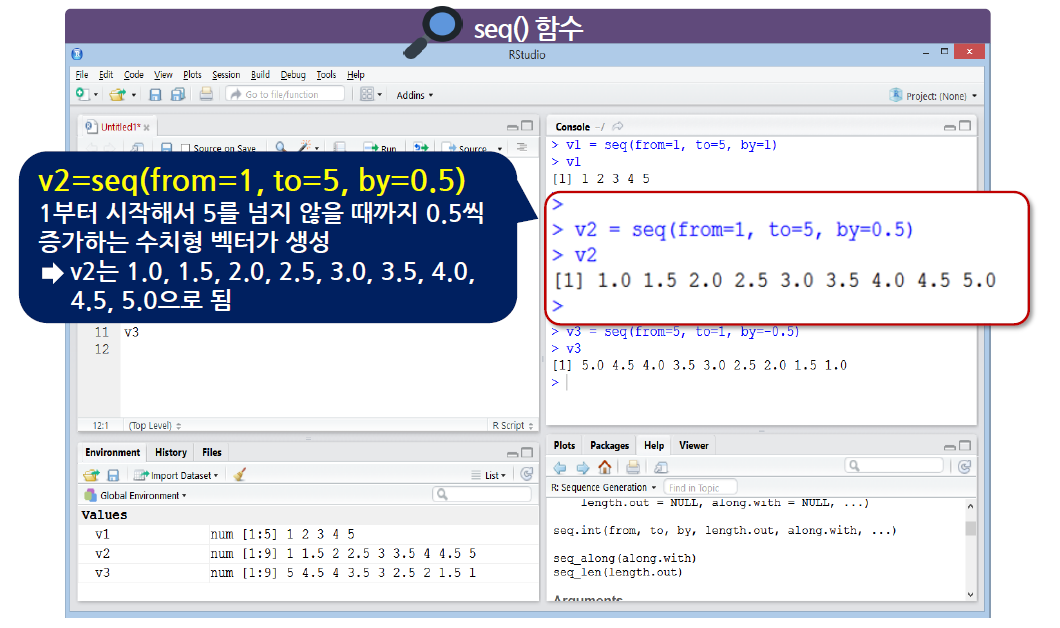
콜론(:)은 1씩 증가하거나 1씩 감소하는 수치형으로 이루어진 벡터를 생성하지만, seq() 함수는 1 이외의 증가 또는 감소가 되는 규칙 있는 수치형 벡터를 생성함
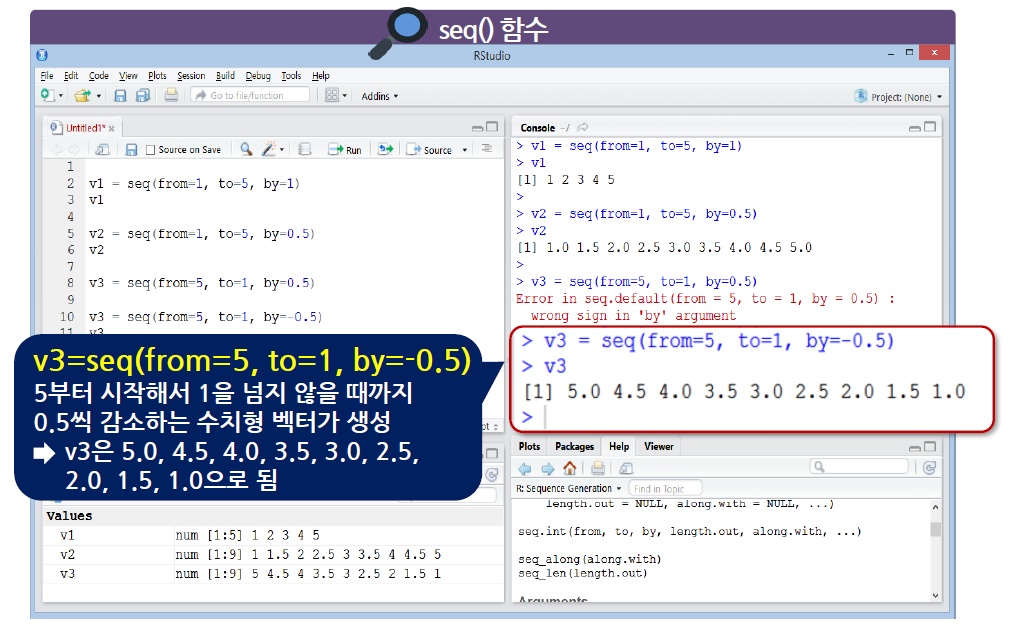
-
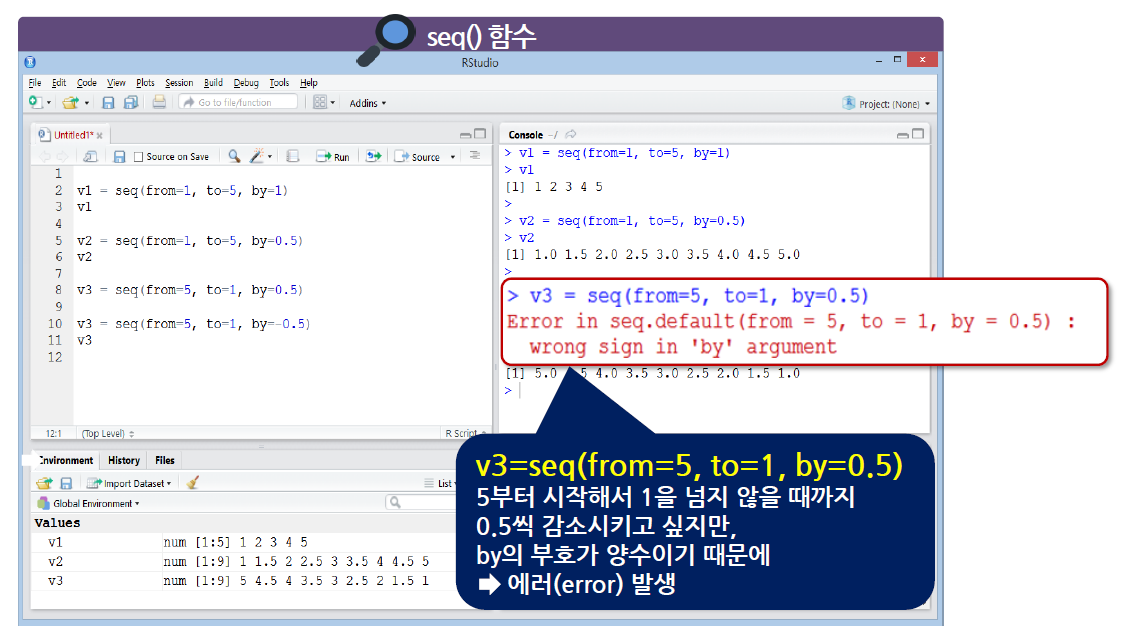
seq() 함수에는 from, to, by라는 argument가 있다.
-
R을 사용하면서 함수에 있는 argument는 가능하면 생략하지 않고 쓰도록 한다.
(함수 안에 있는 값들이 무엇인지 본인과 코드를 보는 다른 사람에게도 도움이 됨) -
argument의 순서는 문법에 영향을 주지 않지만 최대한 순서를 중요하게 생각해서 작성하는 것을 추천
-
-
sequence()
-
sequence() 함수는 sequence(숫자) 형태로 사용
-
1과 지정한 ‘숫자’ 사이의 정수로 이루어진 수치형 벡터를 생성
- 음수가 들어오면 에러가 발생한다.

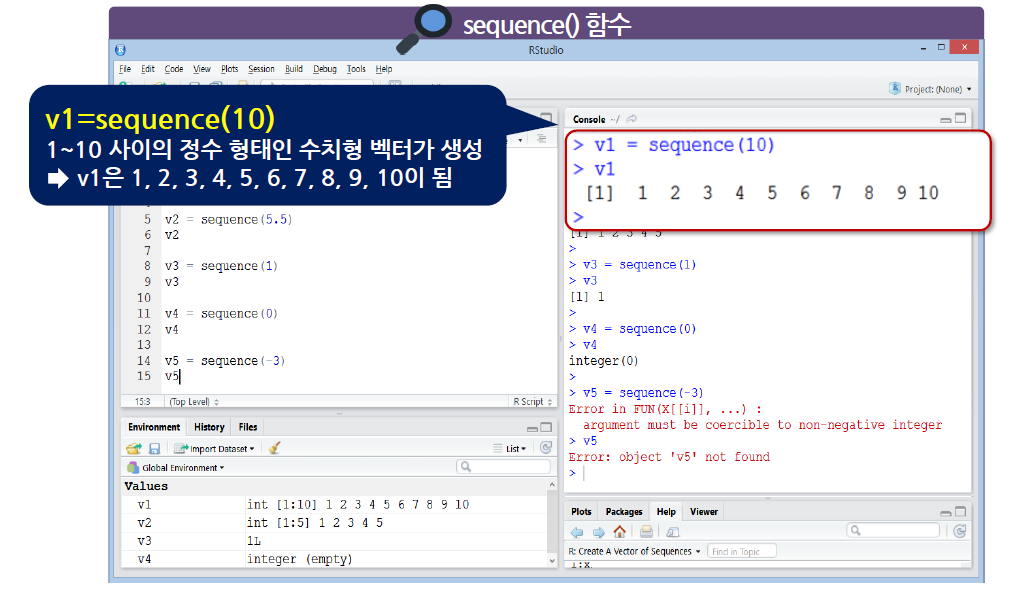
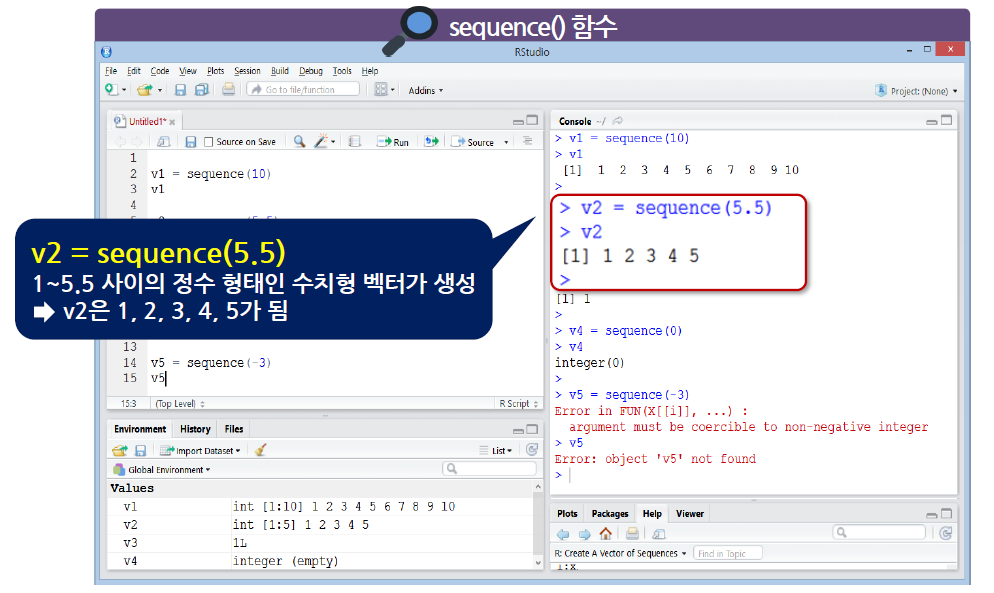
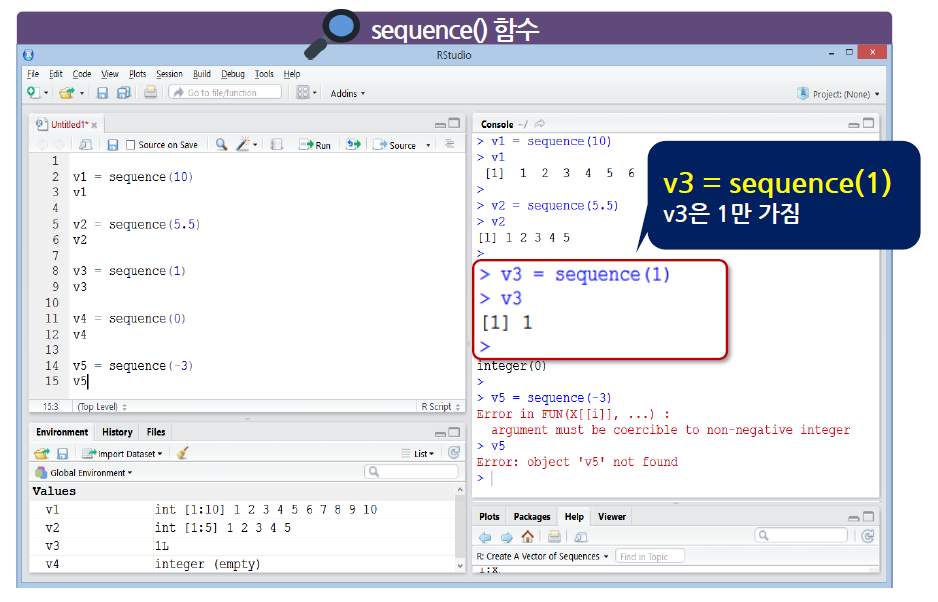
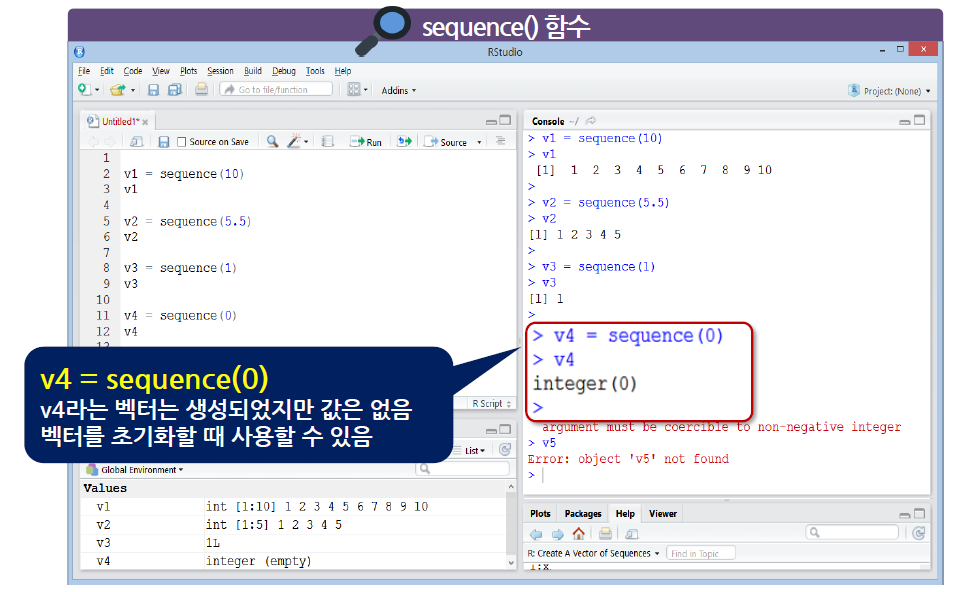

-
-
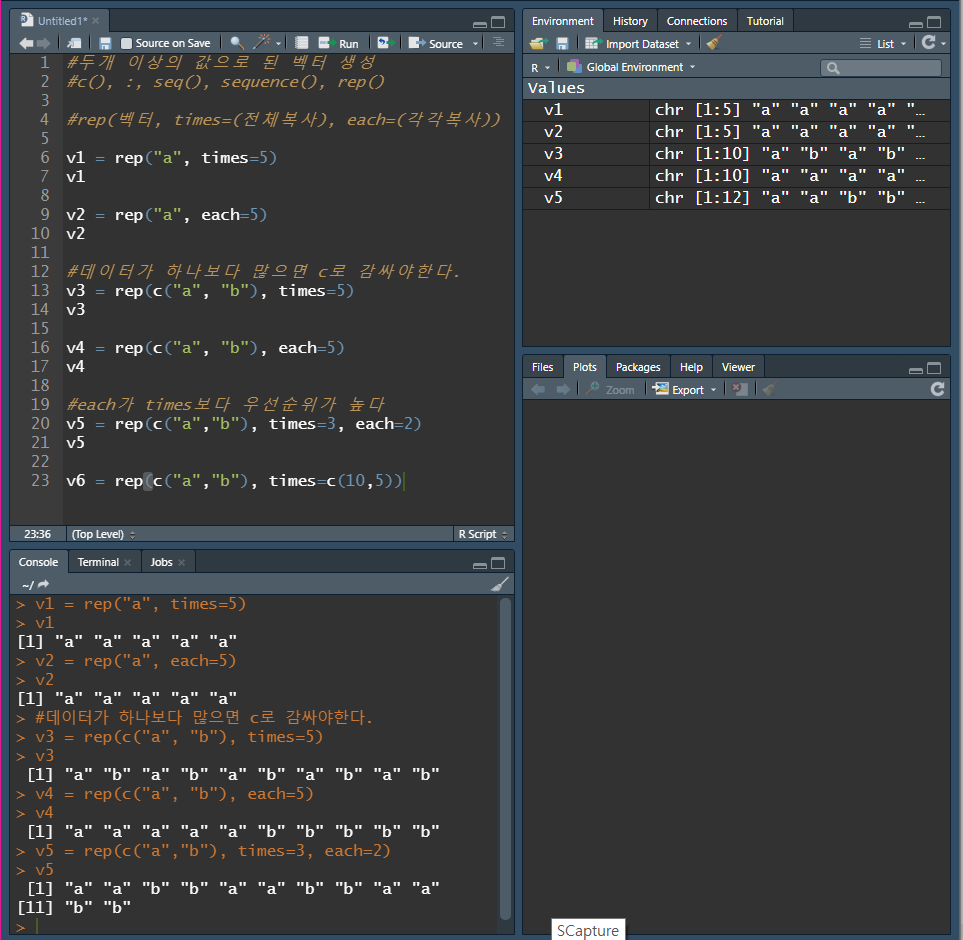
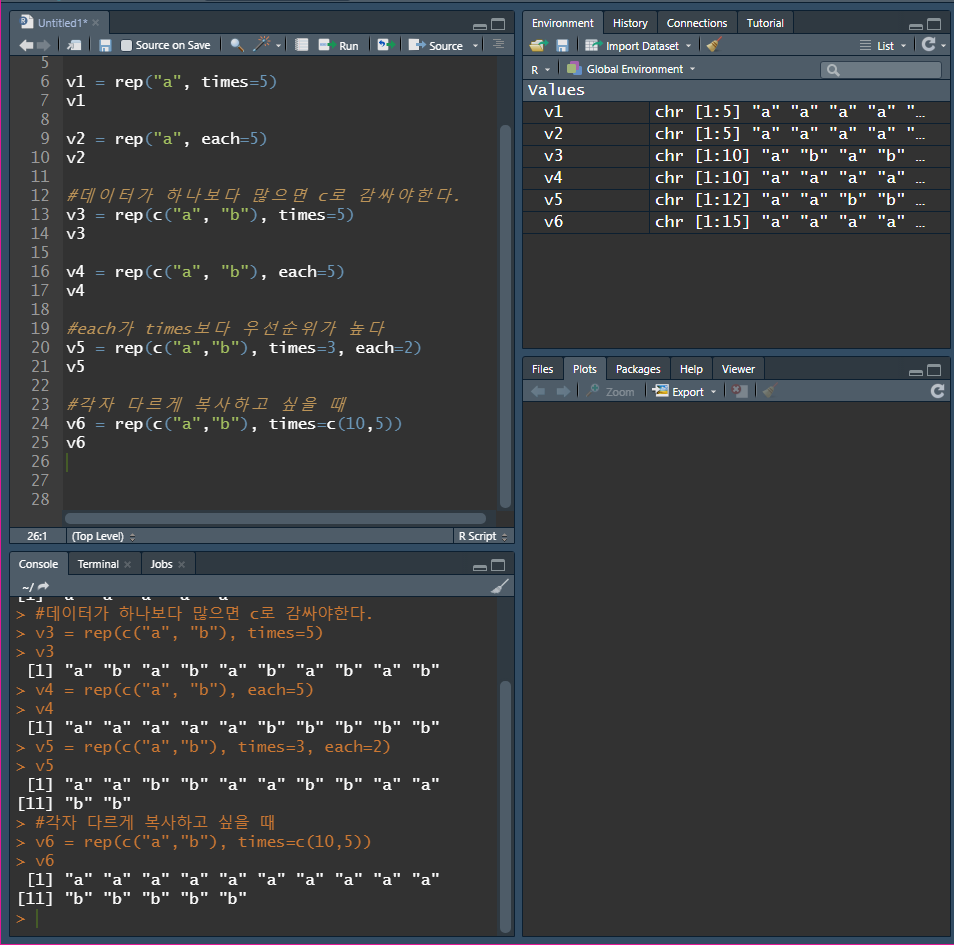
rep()
-
rep() 함수는 replicate의 약자(복사하다, 반복하다의 뜻)
-
rep() 함수는 수치형, 문자형, 논리형, 복수형으로 된 벡터를 생성할 수 있음
-
rep() 함수에 지정된 데이터를 복사해 주는 기능

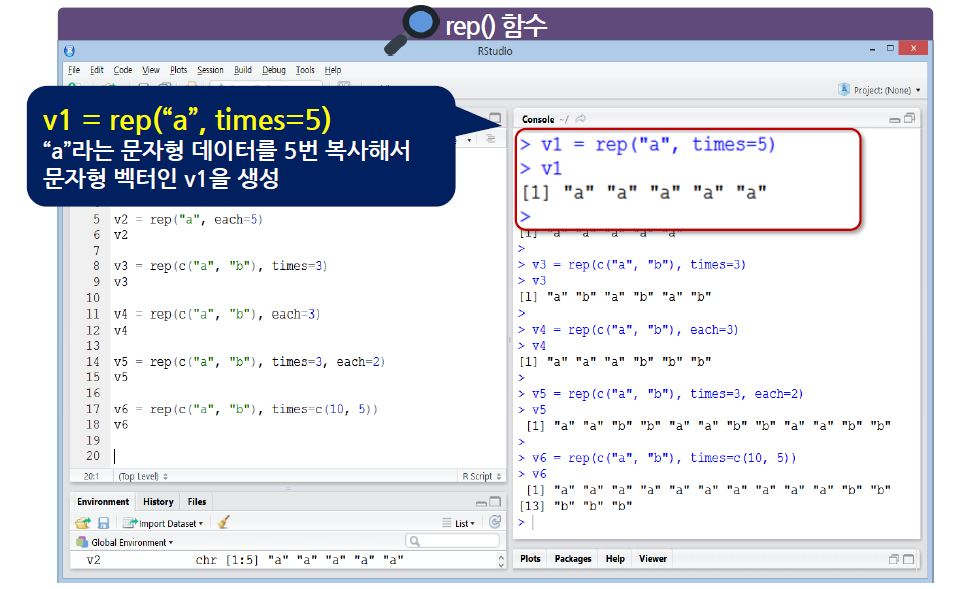
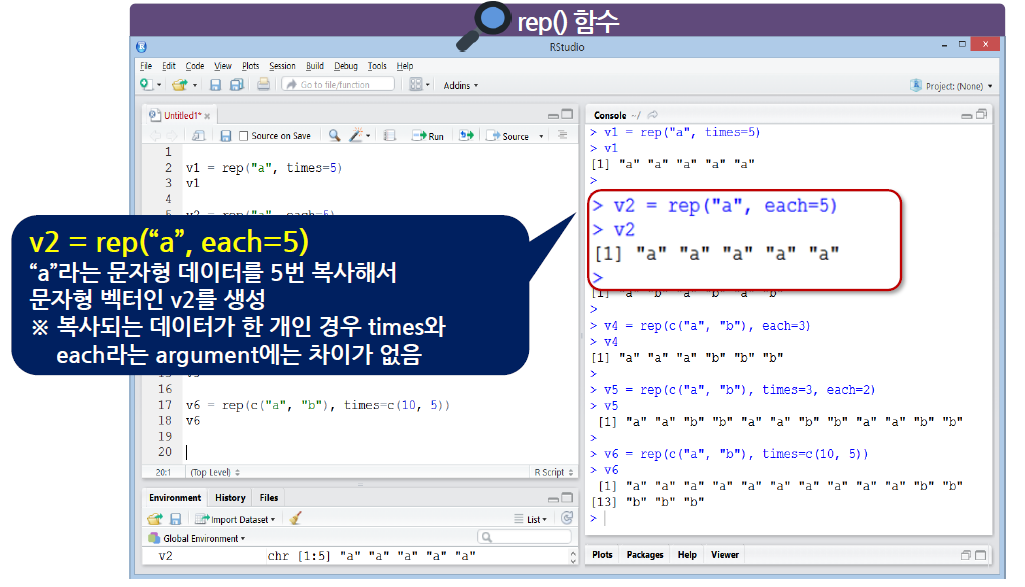
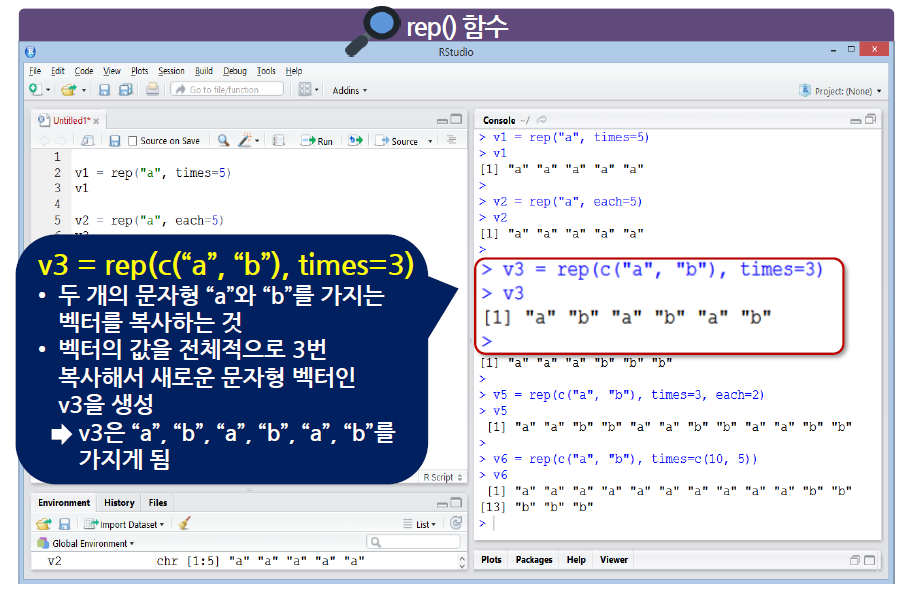
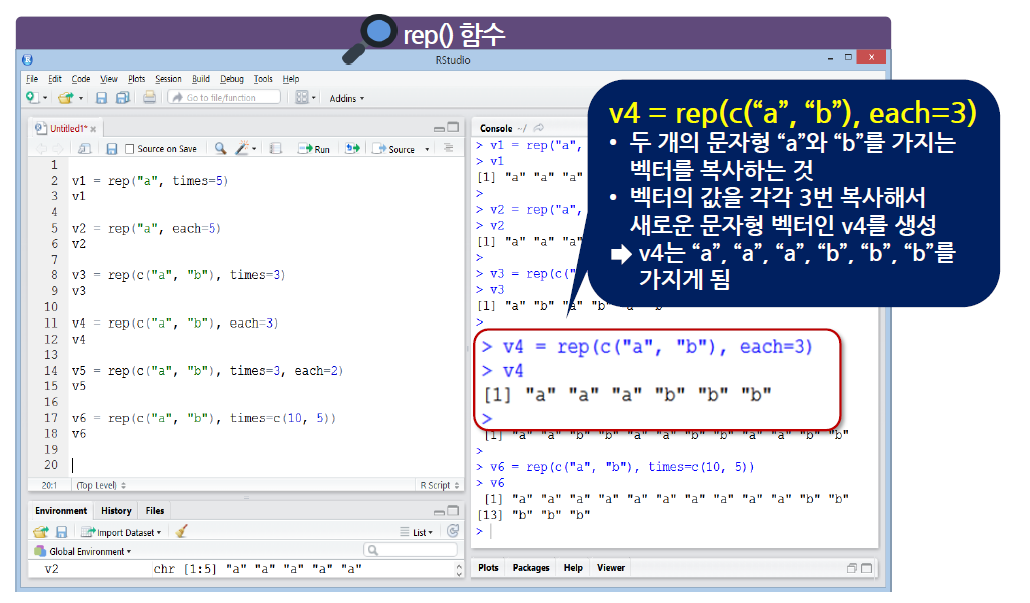
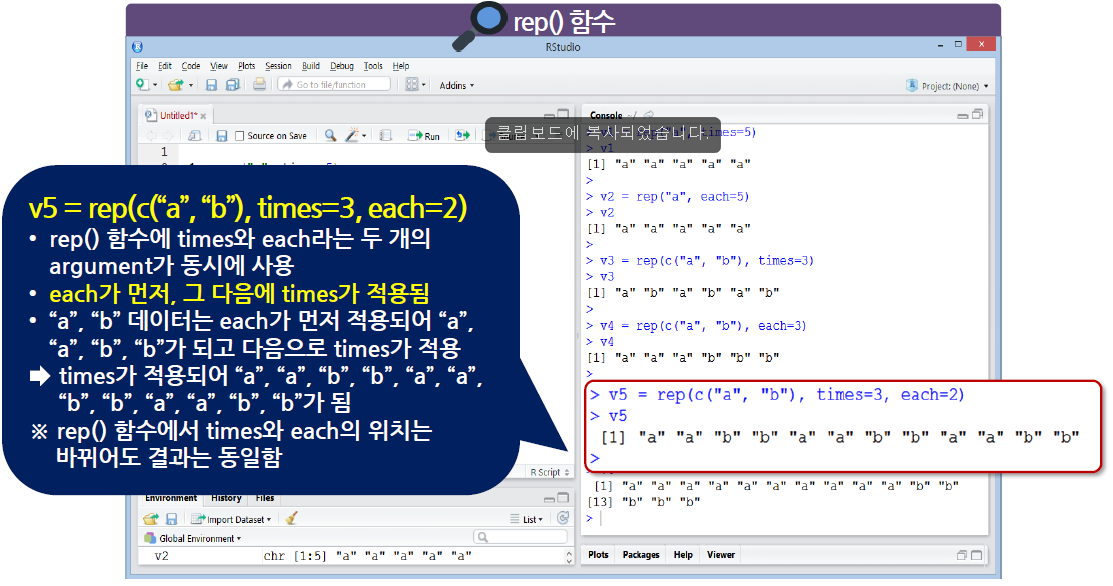
- 우선순위로 인하여, each가 먼저 적용된 다음 times가 적용된다.

times = c(10,5)는 앞의"a"를 10번,"b"를 5번 복사하라는 의미이다.
-

10. 벡터의 속성
- 벡터가 가지는 값 = 원소(Element)
- 원소들이 어떤 데이터 유형으로 이루어졌는지,
원소의 개수는 몇 개 인지, 원소의 이름은 어떻게 되어 있는지를 나타내는 것을 벡터의 속성이라고 함
데이터의 유형
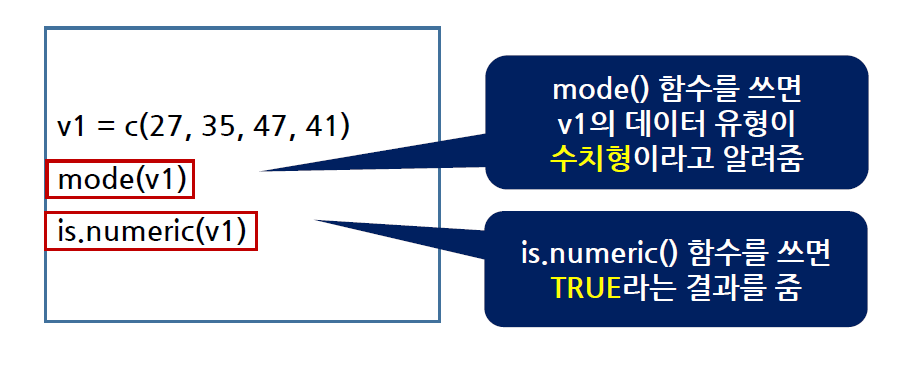
- 벡터가 가지는 값의 데이터 유형을 알아보기 위해
mode(), is.numeric(), is.character(), is.logical(), is.complex()함수를 사용
-
함수의 사용방법
-
mode(벡터)
-
is.numeric(벡터)
-
is.character(벡터)
-
is.logical(벡터)
-
is.complex(벡터)
-
-
데이터 유형을 알아보는 방법
- 27, 35, 47, 41의 4개의 수치형 값으로 이루어진 v1 벡터를 생성, v1의 데이터 유형 확인하기
원소의 개수
-
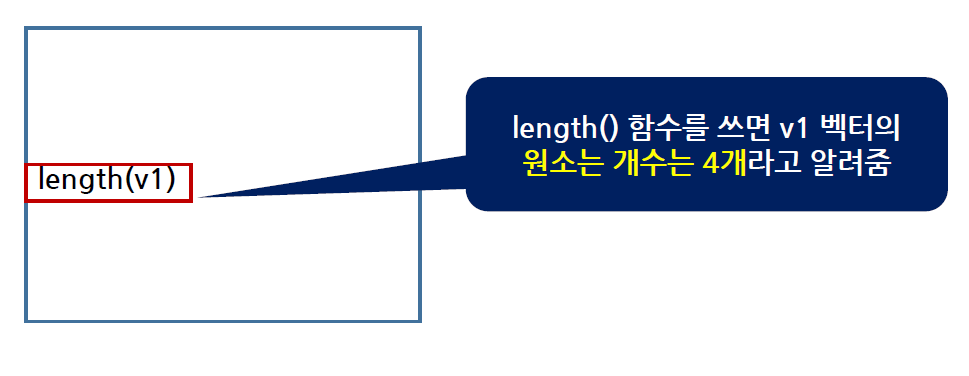
벡터가 몇 개의 원소(element)를 가지고 있는지를 원소의 개수(또는 데이터의 개수)라고 한다.
-
length() 함수를 사용하여 확인 가능하다.
원소의 이름
-
기본적으로는 벡터의 원소에 대한 이름은 없으나 이름을 부여할 수 있다.
-
names() 함수를 사용
-
원소의 이름이 무엇인지 알 수 있다.
-
원소의 이름을 새롭게 부여할 수 있다.
-
-
names() 함수 사용방법(이름 확인하기)
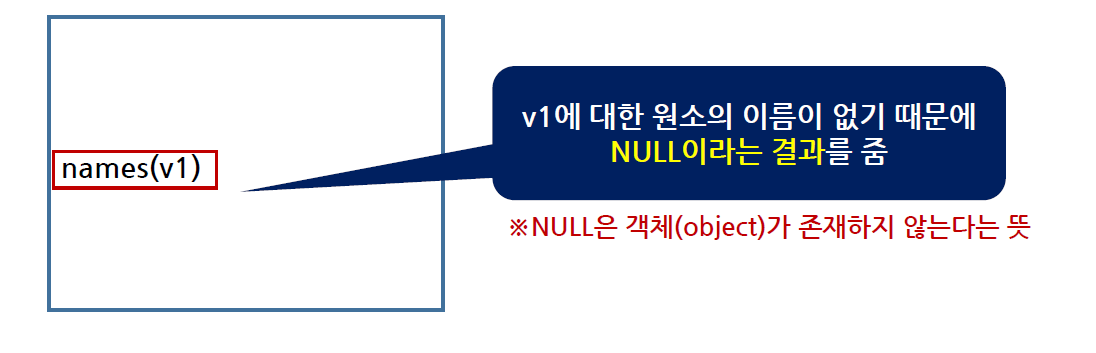
-
names() 함수 사용방법(이름 부여하기)


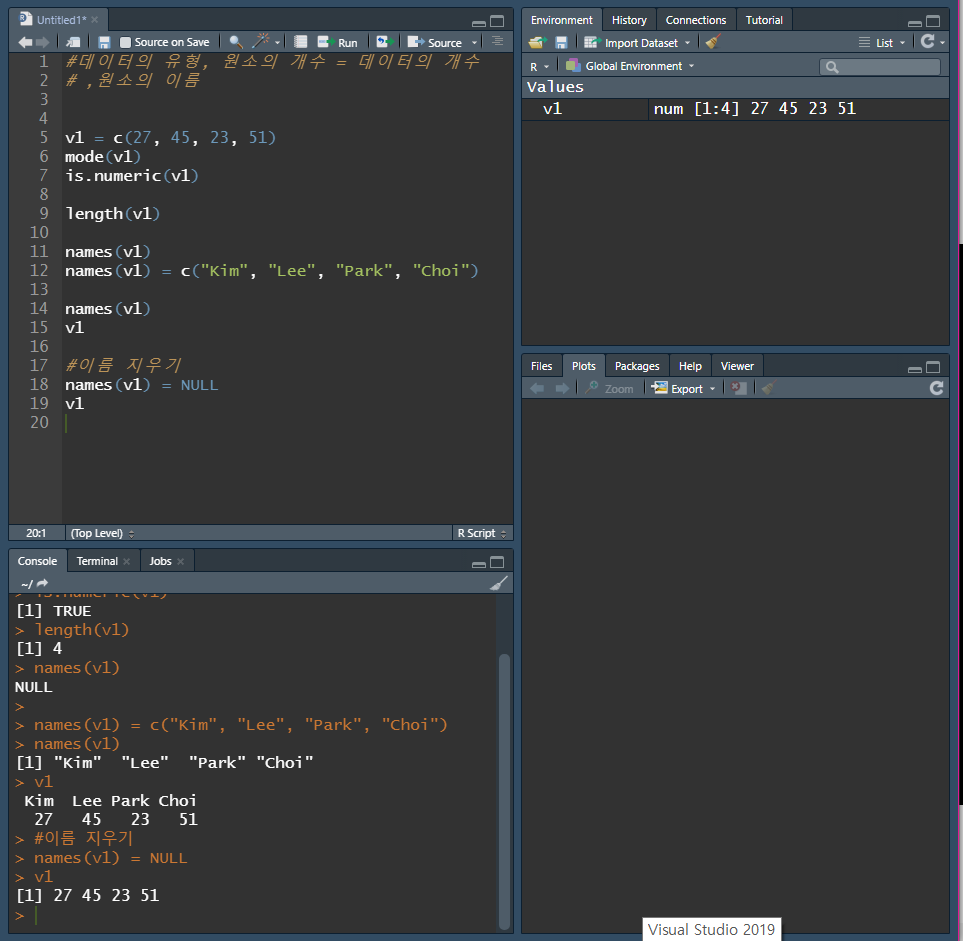
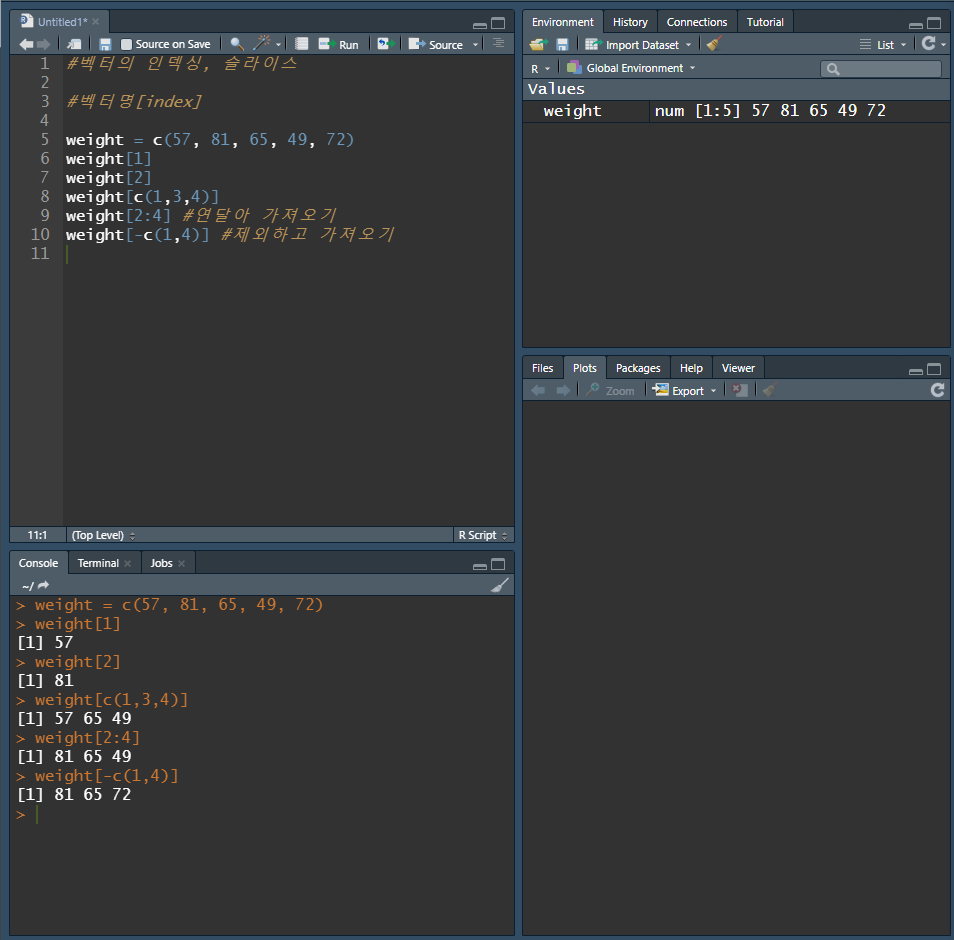
11. 벡터의 인덱싱
-
벡터의 인덱싱
-
벡터가 가지는 원소들 중에서 일부의 원소를 추출할 때는 대괄호([]) 를 사용
-
대괄호 안에 추출하기 원하는 원소의 위치(index)를 수치로 입력
-
R에서는 벡터의 첫 번째 원소에 대한 위치는 1부터 시작
-
두 개 이상의 원소를 추출할 때에는
c(), :, seq(), sequence()등을 사용
- 다른 컴퓨터 프로그램 언어는 첫 번째 원소에 대한 위치를 0으로 인식하는 경우가있기 때문에 차이점을 잘 인지해야 함
-
-
벡터에서 일부의 원소를 추출하는 방법
-
벡터[index]
-
5명의 몸무게 (57, 81, 65, 49, 72)를 저장하는 weight라는 변수를 생성

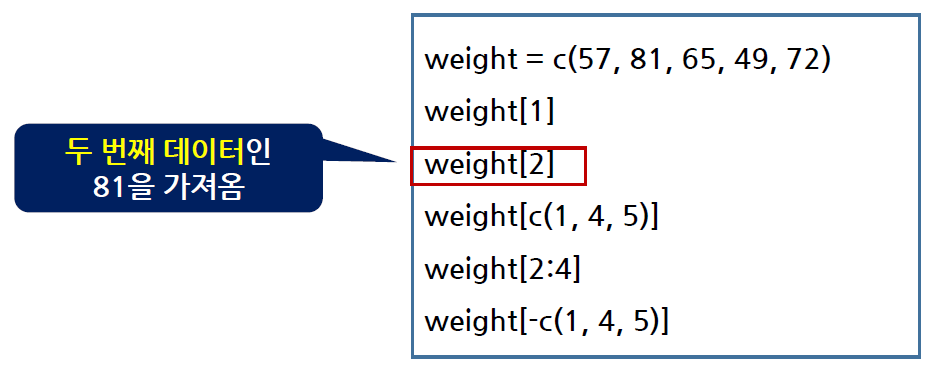
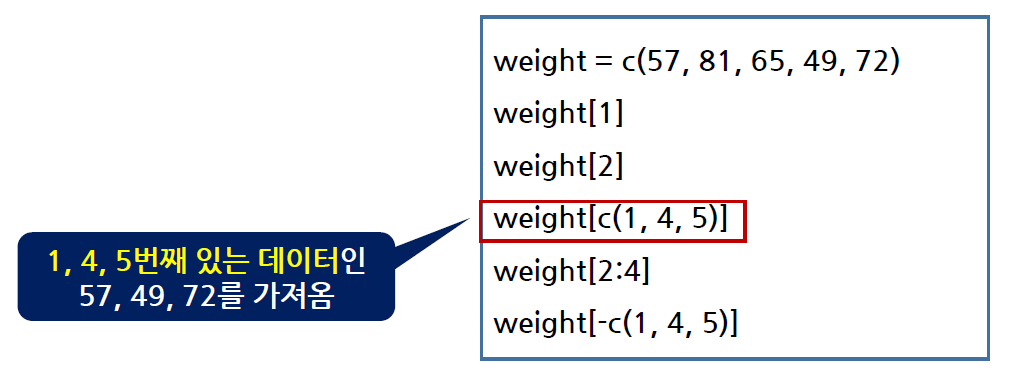


-
12. 벡터의 연산
- 수치형 벡터로 된 두 개 이상의 벡터 간에 사칙연산 가능
- R의 강점은 벡터의 연산이 편리하고 빠르다는 점이다.
(for()등은 속도가 늦어질 수 있다)
벡터의 길이가 동일한 경우
-
연산에 사용되는 벡터들의 원소의 개수가 동일한 경우
- 벡터들 간의 사칙연산이 가능하며 최종적인 결과는 벡터가 된다.
-
벡터들 간의 연산이 될 때에는 각 벡터에 있는 동일한 위치의 값들 간의 연산이 된다.
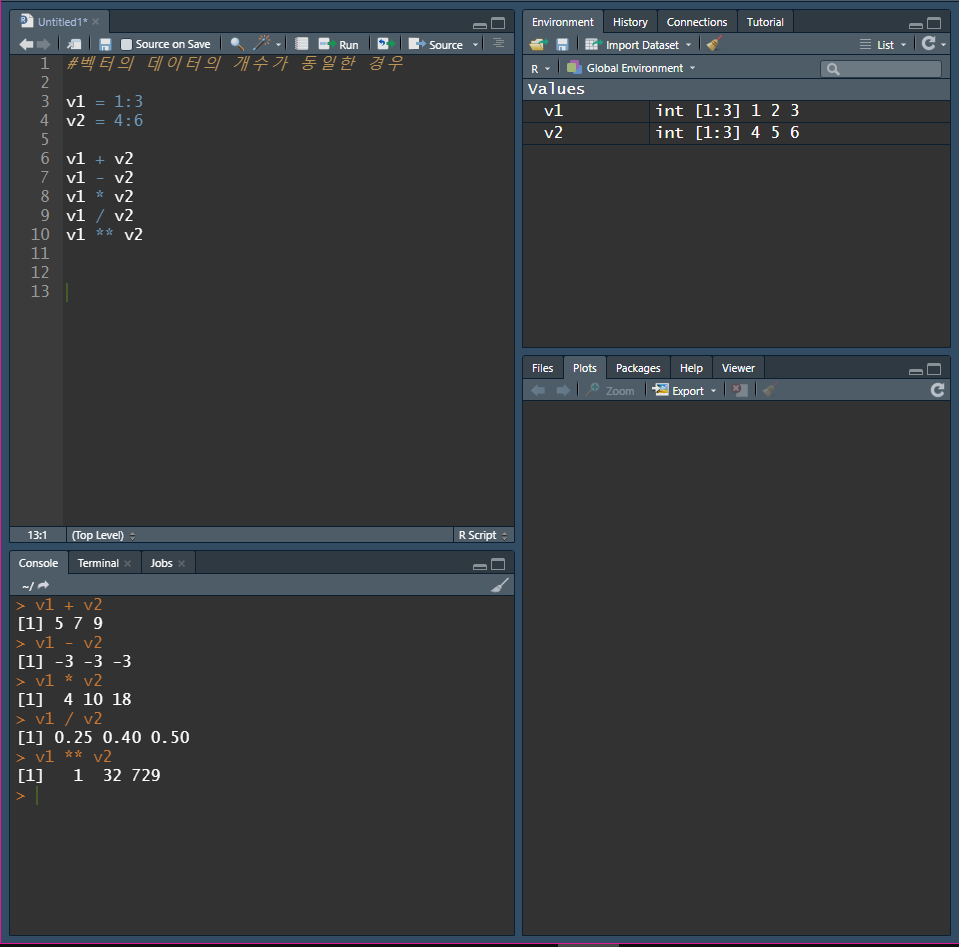
- 예 : 수치형 벡터 v1, v2가 있을 때, v1+v2의 연산을 하면 v1[1]+v2[1]의 연산이 된다.

-
v1에는 1, 2, 3을 가지고, v2는 4, 5, 6을 갖도록 생성한 후에 연산
-
v1 = 1:3
-
v2 = 4:6
-
v1 + v2
-
v1 – v2
-
v1 * v2
-
v1 / v2
-
v1 ** v2

-
-
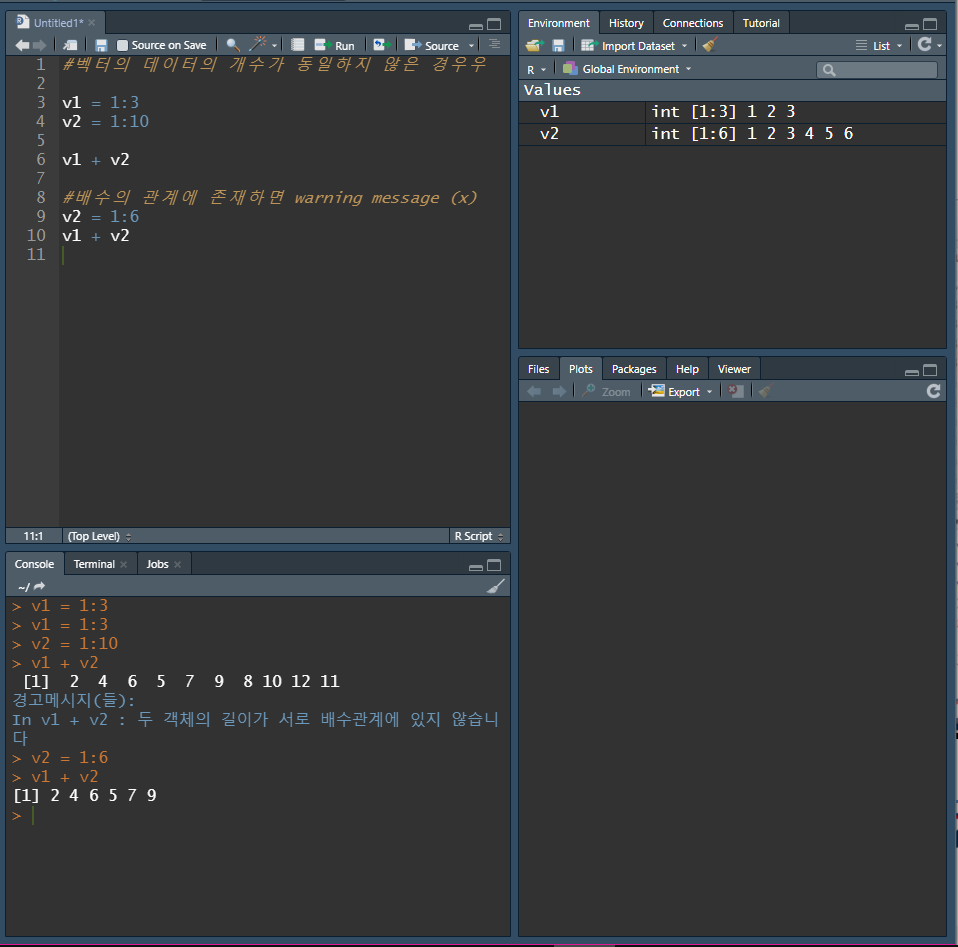
두 벡터가 가지는 원소의 개수가 다르더라도 결과적으로 연산이 된다.
-
벡터 자체는 변하지 않지만 연산과정에서 원소의 개수가 적은 쪽의 벡터는원소 개수가 많은 쪽의 벡터와 동일하게 원소의 개수를 맞춘다.
- 원소 개수가 차이가 나는 만큼 임시적으로 데이터가 생성된다.
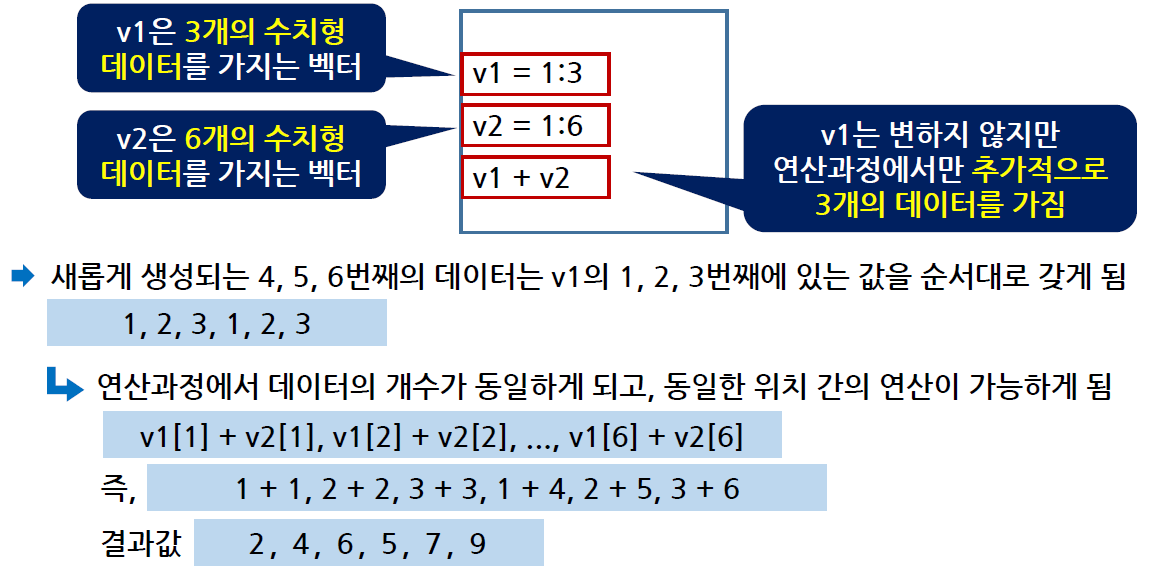
벡터의 길이가 동일하지 않은 경우
-
재사용 규칙(recycling rule)
-
v1은 3개의 데이터, v2는 6개의 데이터가 있다면 v1과 v2 벡터 간의 연산을 했을 경우 (두 벡터의 개수가 다를 경우)
-
v1의 데이터는 추가적으로 3개가 더 생성되어 6개가 된다.
-
새롭게 생성되는 3개의 데이터는 v1이 가지고 있는 값을 순차적으로 새롭게 생성되는 데이터에 지정
-
-
재사용 규칙은 R이 가지는 중요한 특징이다.
-
-
v1에 1, 2, 3을, v2에는 1, 2, 3, 4, 5, 6을 저장하고 있을 때, 두 벡터 간의 연산
-
v1은 1, 2, 3을 가지는 벡터이고, v2는 1, 2, 3, 4, 5, 6, 7, 8, 9, 10을 가지는 벡터일 때