SVM 이란?
-
초평면(Hyper Plane)으로 나누는 모델 이라고 생각하면 됨
-
확률모델이 아니라 판별모델
-
이거아니면 저거로 결과가 나온다
-
SVM은 선형, 판별
-
SVM의 전략은 "마진을 최대화" 하는 것
SVM은 미래에 들어올 데이터의 결과를 예측하는것인대
여유롭게 분류를 해놔야 나중에 들어올 데이터를 제대로 분류할 수 있다
머신러닝의 궁극적인 목표는 '가지고 잇는 데이터' 로부터
'미래에 들어올 데이터'의 결과를 예측하는것!
모든 튜닝과 모델과 수식은 미래의 데이터를 위한것.
- 데이터 과학은 일반적으로 같은 종류의 데이터, 유사한 데이터는 가까이 있을 것으로 가정한다.
-> 그렇지 않다면 그렇게 되도록 변형하는 모델을 만든다.
그 여백을 어떻게 정의해야할까?
-
Dicision Boundary(결정경계)를 선형으로 그리되,
데이터와 경계면 사이의 폭, 거리를 크게하자! -
이 경계면과 가장 가까운 양쪽 카테고리의 데이터 사이의 거리를 Margin이라 하고
-
이 선분과 가장 가까운 데이터
즉 Margin을 결정하는 기준이 되는 데이터를 Support Vector라고 한다.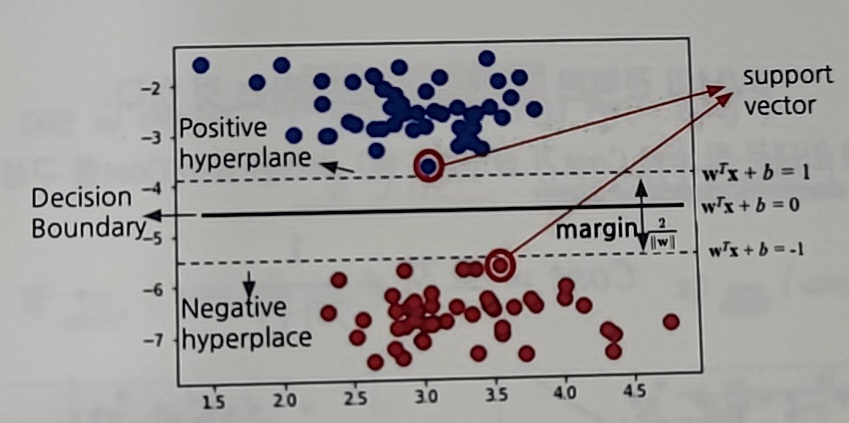
Cost Function
-
오차가 적게 설계(성능에 영향을주는..)
(Train data) -
margin을 최대로 -> 1/마진 을 해줘서 마진이 커질수록 작아지게 해줌
-
margin을 추가해주는이유
(미래에 들어오는 데이터 즉 일반 성능을 올려주기 위해 사용)
(Test data)커널트릭(kernel)
-
선형적으로 불가능할때 저차원의 데이터를
고차원으로 확장시켜서 선형적인 특징을 찾는것 -
저차원에 비선형적 함수를 사용해 고차원에서 선형 특성을 만들어 내는 것
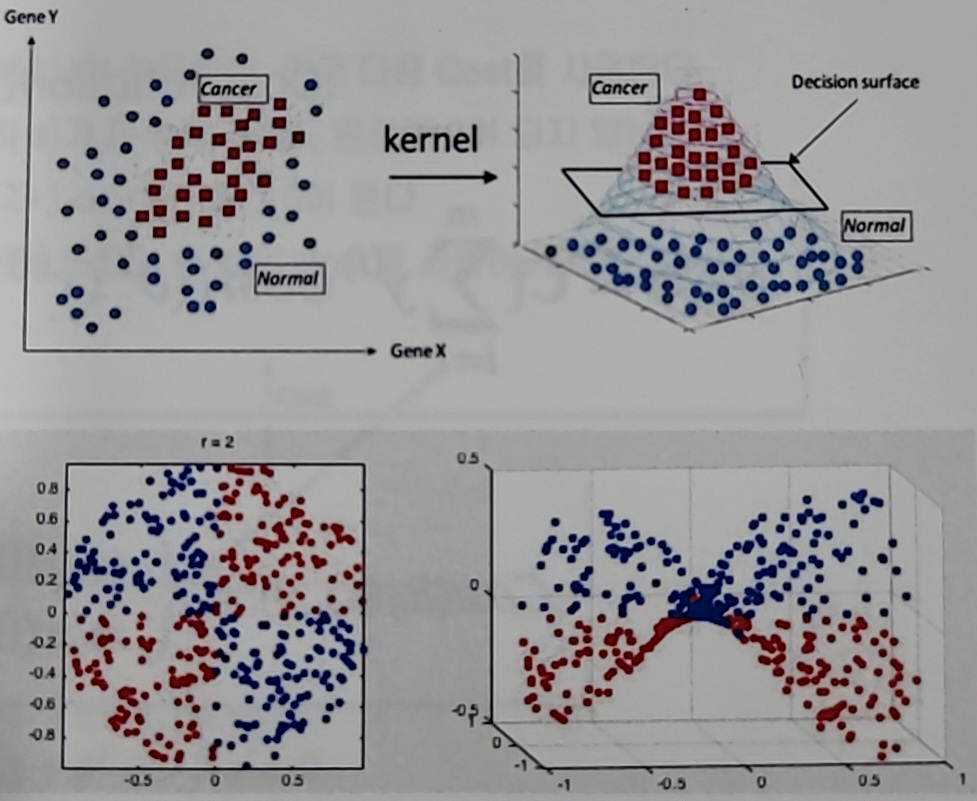
(파란 점들로 둘러 쌓인 데이터 안에 빨간점들이 가운데에 있으면..
가운대를 접어서 선 하나로 잘라서 구분을 시킨다..)

Backend Delveloper