
Proportional Share Scheduler
Fair-share scheduler는 이전의 scheduler와는 다른 철학을 가지고 있다:
Fair-share scheduler는 response time이나 turnaround time을 생각하는 것이 아니라 오로지 fair share에만 관심이 있다.
우리가 충분한 share가 있다고 가정하는데 그 share는 일종의 주식 같은 의미로, share가 있다면 뭔가를 claim할 권리가 생기는 것이다. 어떤 서비스에 돈을 지불하면 좋은 서비스를 받을 권리가 생기는 것처럼.
따라서 우리는 process가 가진 share에 상응하는 만큼의 서비스를 process에게 제공하는데, 그것은 곧 CPU time을 제공하는 것을 의미한다.
즉, 각 job이 자신이 가진 share에 맞게 CPU time을 점유하는 것을 보장한다.
Basic Concept
- Tickets
process가 제공받아야 하는 resource의 share를 나타낸다.
자신이 갖고 있는 ticket의 percent가 system resource에 대한 share를 의미하게 된다. 만약 전체 ticket의 100%를 가지고 있다면 CPU를 완전히 own하게 된다.
예를 들면,
만약 두 process
A,B가 있고 전체 ticket이 100개라고 가정했을 때
A가 ticket 75개를 가지고 있으면A는 CPU의 75%를 점유한다.
B가 ticket 25개를 가지고 있으면B는 CPU의 25%를 점유한다.
Lottery Scheduling
scheduler가 랜덤으로 winning ticket을 뽑는 방식이다.
로또처럼 그냥 랜덤하게 번호를 하나 뽑아서 그 번호를 갖고 있던 process에게 resource(CPU time)을 주는 것이다. 즉, 그 process를 CPU에서 running한다.
예를 들면,
만약 두 process
A,B가 있고 전체 ticket이 100개라고 가정했을 때
A가 ticket 75개:0~74
B가 ticket 75개:75~99
를 가지고 있을 경우scheduler가
63을 뽑음 ->A실행
scheduler가85을 뽑음 ->B실행
scheduler가 ticket을 많이 뽑을 수록 fair share에 수렴하게 되는데 초기에는 확률이 가진 문제로 인해 제대로 동작하지 않는다.
확률을 생각해보면 동전의 앞면과 뒷면이 각각 50%의 확률로 나온다고 해도 동전을 적게 던지면 동전의 앞면 또는 뒷면만 연속적으로 나와 50%의 확률을 만족시키지 못하는 경우가 많다.
그러나 동전을 던지는 횟수가 점점 증가할수록 수학적 확률인 50%에 확률이 근사하게 된다 (큰 수의 법칙).
lottery scheduling 역시 위의 동전처럼 정해진 share를 초기에는 만족시키지 못할 가능성이 높다.
The longer the jobs compete, the more likely they are to achieve the desired percentage.
Ticket Mechanisms
Ticket currency
user가 그들이 원하는 currency만큼 자신의 ticket을 할당할 수 있다. 그러면 system이 그 ticket을 global value로 변환해준다.
예를 들면,
만약 두 process
A,B가 있고 전체 ticket이 200개라고 가정했을 때
A가 ticket 100개를 가지고 있으면A에게는 내부적으로 1000개의 sub-ticket을 나눠가진 두 job이 있다.
B가 ticket 100개를 가지고 있다.B는 10개의 sub-ticket을 가진 single job이 있다.User
A-> 500 (A's currency) toA1-> 50 (global currency)
UserA-> 500 (A's currency) toA2-> 50 (global currency)
UserB-> 10 (B's currency) toB1-> 100 (global currency)
Ticket transfer
process는 일시적으로 자신의 ticket을 다른 process에게 전달할 수 있다.
Ticket inflation
process는 일시적으로 자신이 가진 ticket의 수를 늘리거나 줄일 수 있다.
process가 더 많은 CPU time을 요구하면 자신의 ticket 수를 boost할 수 있다.
Unfairness metric
unfairness metric U : 첫번째 job이 완료되기까지 걸린 시간을 두 번째 job이 완료되기까지 걸린 시간으로 나눈 값
예를 들면,
두 job이 있고 각 job이
10의 runtime을 가지고 있을 때첫 번째 job은 time
10에 끝난다.
두 번째 job은 time20에 끝난다.
U = 10/20 = 0.5
U가 1에 가까울수록 각 job이 비슷한 시간에 완료된 것이다.
즉, U가 1에 가까울수록 fair하다.
Lottery Fairness Study
두 job이 있고 같은 양의 ticket을 가지고 있으면 다음과 같이 동작한다:
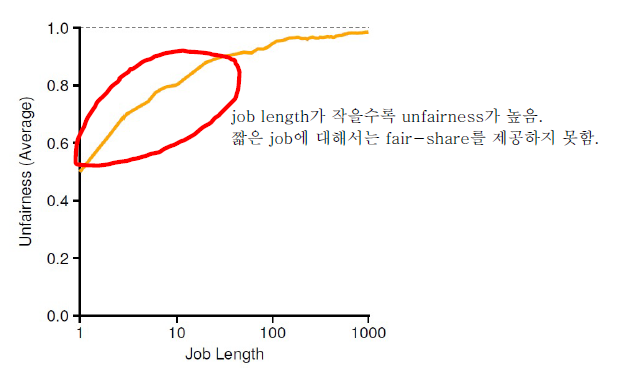
When the job length is not very long, average unfairness can be quite severe.
lottery scheduling에서는 job length가 짧을수록 unfairness가 높다.
따라서 짧은 job에 대해서는 fair-share를 제공하지 못하는 문제점이 있다.
Stride Scheduling
stride는 one step의 length를 말한다.
동일한 거리를 가기 위해서 걸음이 작은 사람이 더 많은 걸음을 걸어야 하는 것 처럼, longer stride를 가진 사람이 한 발자국을 걸었을 때 shorter stride를 가진 사람보다 더 많은 거리를 갔으므로 shorter stride를 가진 사람이 더 많은 step을 가야 한다.
각 process의 stride를 구하는 방법은 다음과 같다:
(total number of tickets) / (the number of tickets of the process)예를 들면,
만약
total number of ticket = 10000이라면
A가 ticket 100개를 가지고 있으면 ->A의 stride는100이다.
B가 ticket 50개를 가지고 있으면 ->B의 stride는200이다.
process가 running할 때 counter(=pass vaue)의 값을 stride만큼 증가시킨다.
pass value는 거리를 총 얼마나 갔는지를 나타내준다.
scheduler는 pass value의 값이 가장 작은 process를 선택해 실행한다. pass value가 적다는 것은 다른 process들과 비교했을 때 상대적으로 거리를 덜 갔다는 의미이기 때문이다.
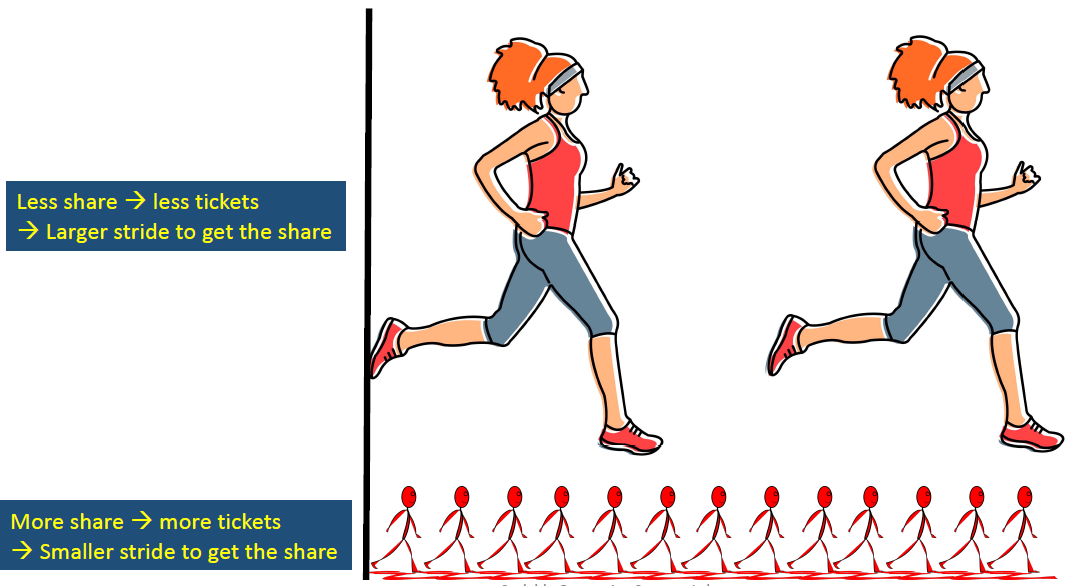 share가 적을수록 적은 ticket을 가지고 있으므로 다른 process에 비해 덜 실행되어야 한다. 큰 stride를 가지면 큰 걸음으로 조금만 가도 같은 거리에 도달할 수 있으므로 scheduler에 의해 적게 실행된다.
share가 적을수록 적은 ticket을 가지고 있으므로 다른 process에 비해 덜 실행되어야 한다. 큰 stride를 가지면 큰 걸음으로 조금만 가도 같은 거리에 도달할 수 있으므로 scheduler에 의해 적게 실행된다.
share가 클 수록 많은 ticket을 가지고 있으므로 다른 process에 비해 많이 실행되어야 한다. 작은 stride를 가지면 같은 거리를 가기 위해 더 많은 걸음을 걸어야 하므로 그만큼 scheduler가 많이 실행하게 된다.
Stride Scheduling : Basic Algorithm
stride scheduling은 다음과 같은 방법으로 실행된다:
tickets을 이용해stride를 구한다.- minimum
pass value를 가진 process를 실행한다. - 그 process의
pass value에 stride를 더해pass value를 증가시킨다.
 두 번째 단계에서
두 번째 단계에서 B의 pass value가 가장 낮으므로 B를 실행시키고 B의 stride만큼 pass value를 증가시킨 것을 확인할 수 있다.
이 과정을 반복하면 다음과 같이 실행하게 된다.
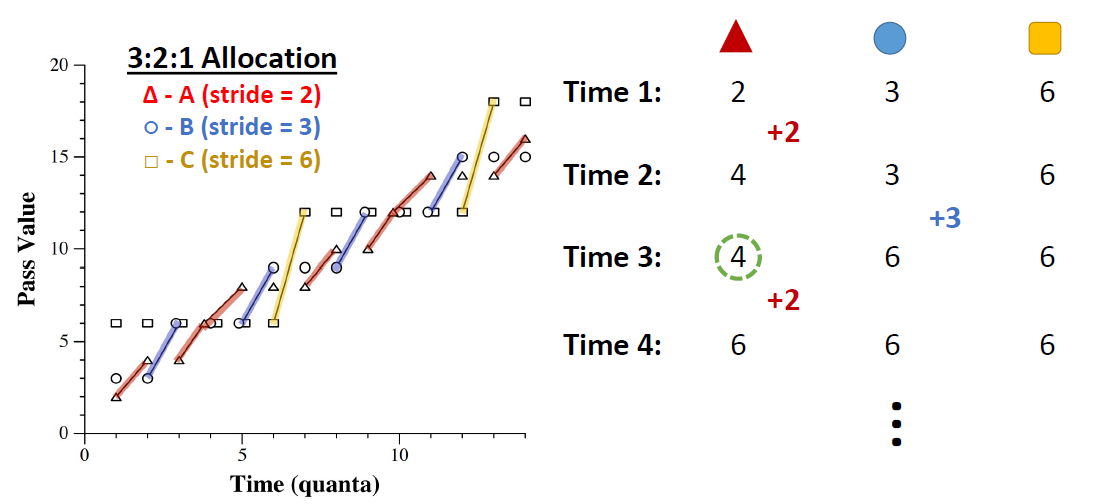 stride scheduling은
stride scheduling은 pass value가 작은 process를 pick해서 실행한다.
즉, random하게 선택해 실행하는 것이 아니라 deterministic하게 동작한다.
따라서 stride scheduling은 lottery scheduling이 random하게 process를 pick하기 때문에 발생했던 확률 상의 문제를 해결할 수 있다.
