✨Persistence: Crash Consistency
운영체제

Crash Consistency
 Crash consistency는 OS가 file system의 entire life time을 ensure해야 한다는 property이다.
Crash consistency는 OS가 file system의 entire life time을 ensure해야 한다는 property이다.
In-memory data structure들과는 다르게 file system에서 사용하는 data structure는 모두 durable해야 한다.
Durable이란 power loss같은 failure가 있어도 data는 살아남아야 한다는 뜻이다.
File, directory같은 user data를 포함한 data structure와 file system의 inode, inode bitmap, data block bitmap, superblock같은 자신의 structure를 포함한 모든 data는 persist해야한다.
A Detailed Example
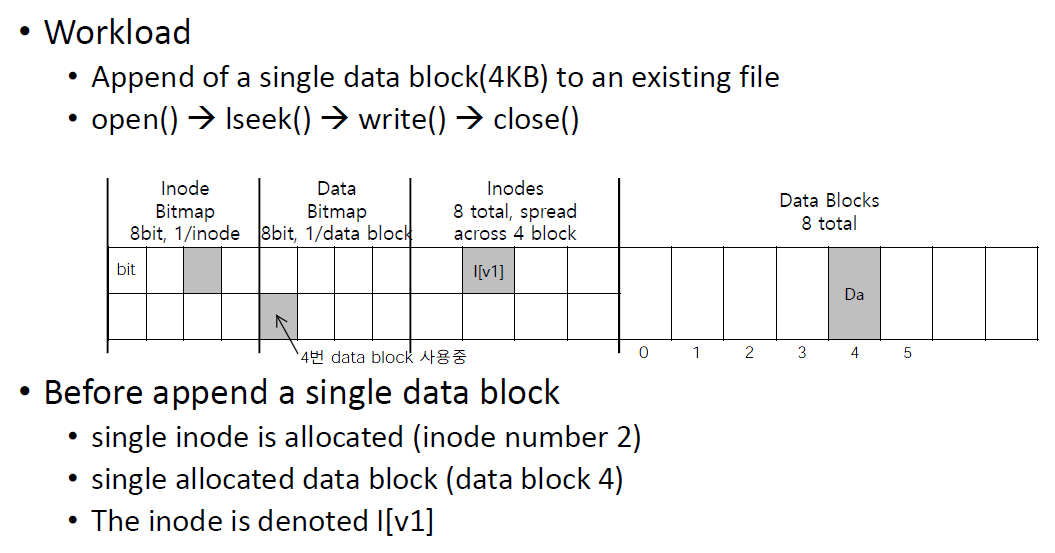 Workload를 보면 single data block을 existing file에 append한다.
Workload를 보면 single data block을 existing file에 append한다.
이것은 4개의 system call과 관련이 있다.
open()으로 file을 열어서 lseek()으로 location을 찾고 write()으로 data store한 뒤 close()한다.
이것은 간략화된 예시이다.
Inode bitmap은 8bit을 가지고 있다.
그리고 각 bit이 1 inode structure를 나타내고 있다.
Data bitmap도 8bit을 가지고 있다.
각 bit이 data block을 나타낸다.
그리고 총 8개의 inode structure를 가지고 있고 file system에는 8개의 data block이 있다.
그리고 4번째 data block이 file에 대한 data를 갖고 있다.
4번째 data block이 사용중이므로 data bitmap에 사용중이라고 mark된다.
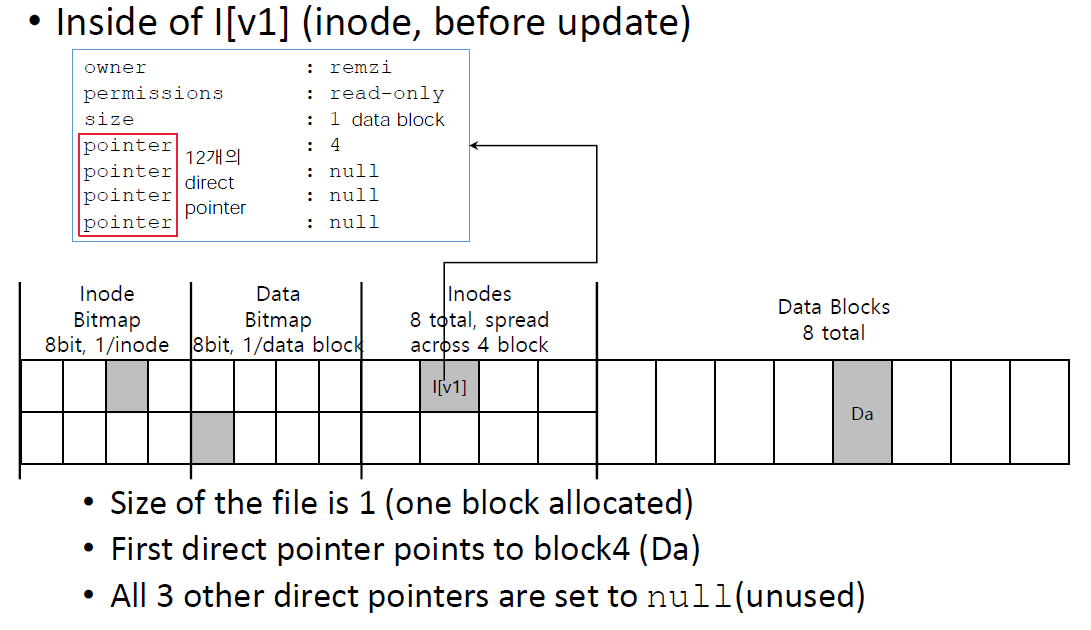 Inode structure 안에는 metadata information이 들어있다.
Inode structure 안에는 metadata information이 들어있다.
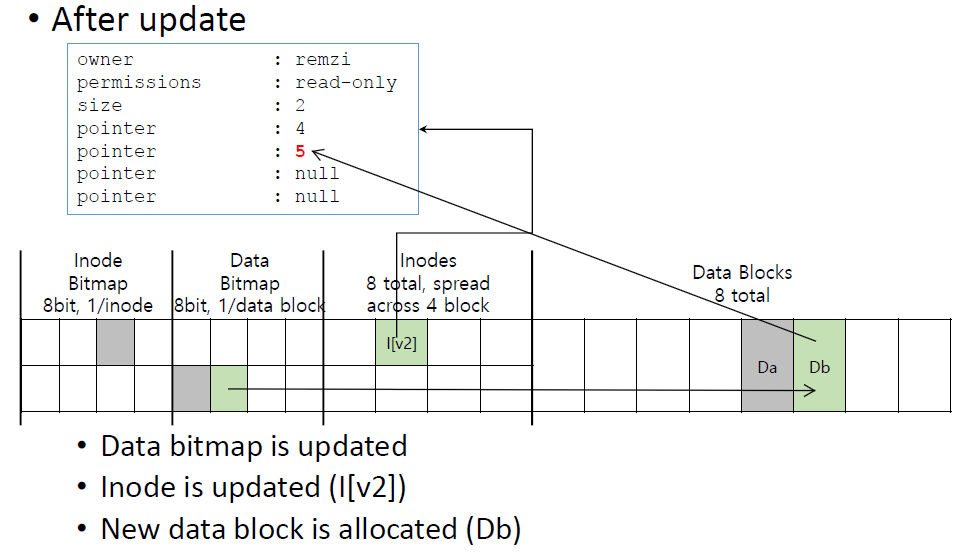 Data block에 새로운 data를 쓰려면 가장 먼저 우리가 사용할 수 있는 free data block을 찾아야 한다.
Data block에 새로운 data를 쓰려면 가장 먼저 우리가 사용할 수 있는 free data block을 찾아야 한다.
그래서 data bitmap에서 현재 사용하고 있던 block의 다음 block bit을 used로 바꾼다.
그리고 그 data block에 new data를 쓴 다음 inode를 updage한다.
즉 file system은 device에게 3 I/O command를 issue해야한다.
- Data bitmap
- Data block
- Inode structure
 문제는 different location을 update 해야하기 때문에 이 과정들을 atomic하게 만들 수 없다는 것이다.
문제는 different location을 update 해야하기 때문에 이 과정들을 atomic하게 만들 수 없다는 것이다.
즉, 3 update가 전부 실행되거나 아예 실행되지 않게 만들 수 없다는 것이다.
그래서 어떤 block은 store되고 어떤 block은 store되지 않는 inconsistency problem이 생긴다.
위의 예시에서는 file system이 performance reason으로 dirty inode, dirty bitmap, dirty data block을 memory에 저장하고 있다.
Memory는 periodically or forcefully disk로 flush된다.
File system cache는 보통 dirty inode, dirty bitmap, dirty data block을 contain한다.
어떤 block 혹은 어떤 data가 disk로 flush되냐에 따라서 disk로 writing이나 flushing 도중에 crash가 발생했을 때 inconsistency problem이 생길 수 있다.
Crash Scenario (1)

 3개 중 하나의 write만 성공하는 것이다.
3개 중 하나의 write만 성공하는 것이다.
Dirty data bitmap, dirty data block, dirty inode 3개를 써야하는데 그 중 하나만 성공한 것.
그럼 3개의 가능한 결과가 있다.
-
Data block은 disk에 쓰였지만 나머지 2개는 쓰이지 않는 경우
• 그럼 data는 disk에 있지만 inode update는 되지 않았다.
• inode는 쓸 수 있는 data가 기존에 존재하던 하나밖에 없다고 생각한다.
• 이 경우는 happy case이다. 그냥 무시하면 된다. disk에 적힌 data를 그냥 무시한다.
• inode structure과 data bitmap이 그 data block은 free이고 새로운 data가 추가되지 않았다고 생각할 것이기 때문이다. -
Inode은 disk에 쓰였지만(update) 나머지 2개는 쓰이지 않는 경우
• Inode는 new data block에 대한 address를 담고 있다.
• 하지만 new data block은 written되지 않았다.
• User가 data를 읽기 위해서 inode에 access하면 inode는 data가 있다고 할 것이다! 그런데 내가 data block을 읽으려고 하면 아무것도 담겨있지 않고 garbage data만 담겨있다.. crash로 인해 data block이 written되지 않았기 때문이다.
• File-system inconsistency가 발생한다. File system(inode)는 data가 있다고 하는데 막상 내가 data block에 가면 data block은 쓰레기만 갖고 있다. -
Data bitmap은 disk에 쓰였지만(update) 나머지 2개는 쓰이지 않는 경우
• Bitmap은 쓰려고 했던 그 block(5) 이 allocate 되었다고 나타낸다. Dirty bitmap이 disk에 쓰였기 때문이다.
• 그래서 bitmap을 check하면 block5이 이미 사용중이어서 이제 그 block을 사용할 수 없다고 함.
• 하지만 data block5를 track할 수 있는 information이 없다. inode structure의 어디에도 data block5의 location이 적혀있지 않기 때문이다.
• File-system inconsistency가 발생한다.
• 원인은 space leak되었기 때문이다. Data block bitmap은 우리한테 block5를 사용할 수 없다고 했는데 실제로 data block5는 written되지 않아서 그것을 사용할 수 있어야 한다!
Crash Scenario (2)

 3개 중 2개의 write만 성공하는 것이다.
3개 중 2개의 write만 성공하는 것이다.
Dirty data bitmap, dirty data block, dirty inode 3개를 써야하는데 그 중 2개만 성공한 것.
그럼 3개의 가능한 결과가 있다.
-
Dirty inode, dirty bitmap은 disk에 썼지만 dirty data block은 쓰지 못한 경우
• Inode와 bitmap같은 file system의 metadata는, bitmap은 block5가 사용중이라고 하고 inode를 확인했을 때도 inode도 block5를 기억하고 있는데 data는 쓰이지 않았다.
• Block5에는 garbage data가 있다.
• Inode가 data block5에 data가 있다고 했으니까 나중에 user가 data를 읽으면 쓰레기가 있다. -
Dirty inode, dirty data block은 disk에 썼지만 dirty bitmap은 쓰지 못한 경우
• Inode는 제대로 new data block을 가리키고 있다.
• Data block도 new data를 갖고 있다.
• 하지만 data block bitmap이 그 data block은 free라고 한다. 만약에 user가 bitmap으로부터 free data block을 가져가려고 할 때 bitmap이 다른 process에게 그 block을 줘버릴 수 있다. 그럼 진짜 big problem이 생긴다. 내 data를 잃어버리는 것. -
Dirty bitmap, dirty data block은 disk에 썼지만 dirty inode은 쓰지 못한 경우
• Bitmap은 block이 사용중이라고 하고 data block도 new data를 가지고 있다.
• 하지만 그 block number를 trace할 수가 없다. Inode를 update하지 않았기 때문에 trace할 방법이 없다.
• Inconsistency situation이 발생한다. 내 data도 잃고 내 data block도 잃어버린다. 아무도 그 data block을 사용할 수 없다.
The Crash Consistency Problem
 Logically하게는 user process는 1 single
Logically하게는 user process는 1 single write() system call을 호출하는건데 내부적으로 file system은 multiple I/O를 generate한다.
모든 file system이 이 문제를 overcome해야하지만 이것을 쉽게 할 수는 없다.
The File System Checker



fsck는 뭔가가 없어져야만 발동된다. 그리고 없어진 것을 찾을 수가 없다.
그리고 모든 data block, bitmap, inode를 확인해야하기 때문에 너무 느리다...
그래서 안쓴다. 제대로 고치지도 못하는 system이 느리기까지 하니까.
Copy On Write (COW)
 Copy on write에서는 그냥 update를 해버리는 것이 아니라 복사본을 만들어서 update를 안전하게 한 후에 old version을 flush하는 방법을 사용한다.
Copy on write에서는 그냥 update를 해버리는 것이 아니라 복사본을 만들어서 update를 안전하게 한 후에 old version을 flush하는 방법을 사용한다.
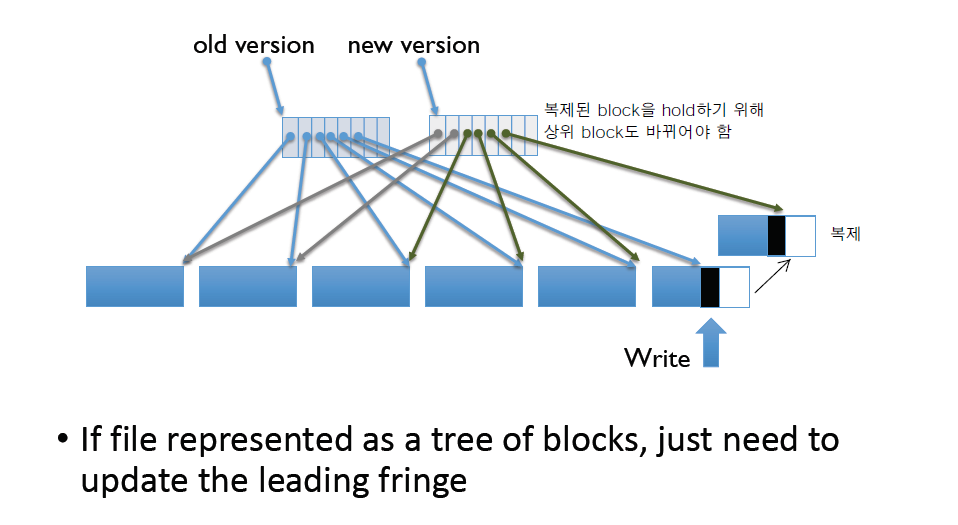 File system에 write을 그냥 하는 것이 아니라 write을 하고자 했던 block을 그대로 복사해서 new version을 만들고, 거기에 write을 한 뒤 그 new version을 가리켜야하는 다른 block들까지 복제해서 완전한 new version을 만든 뒤 old version을 버린다.
File system에 write을 그냥 하는 것이 아니라 write을 하고자 했던 block을 그대로 복사해서 new version을 만들고, 거기에 write을 한 뒤 그 new version을 가리켜야하는 다른 block들까지 복제해서 완전한 new version을 만든 뒤 old version을 버린다.
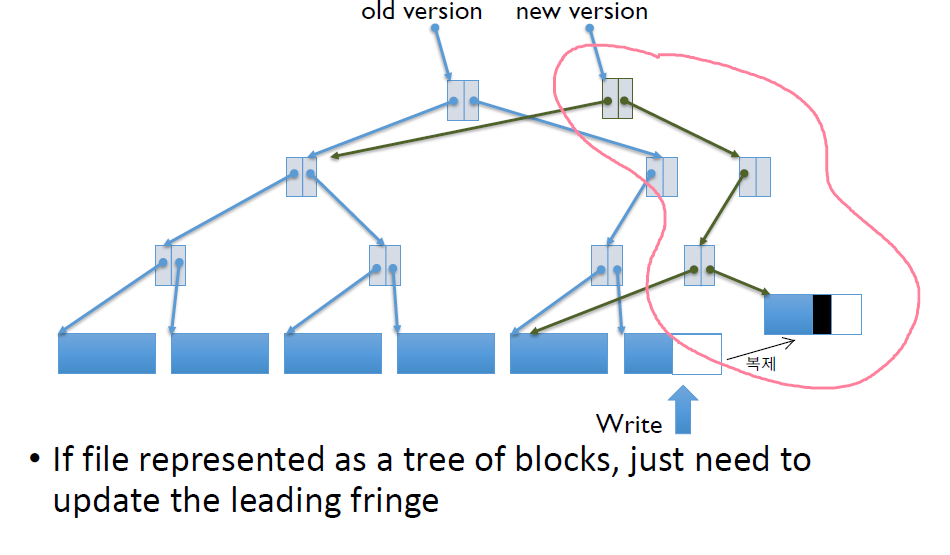 Copy on write은 무조건 update를 하기 전에 복사본을 만들어야 한다.
Copy on write은 무조건 update를 하기 전에 복사본을 만들어야 한다.
그런데 이로 인해 상당히 비효율적인 상황이 생길 수 있다.
data하나를 write하려고 했을 뿐인데 그 data를 write하기 위해 block을 copy했다.
block을 copy하게 되면서 그 block을 hold해야하는 상위 block이 바뀌어야 하므로 상위 block이 복제되었다.
그런데 그 상위 block을 hold해야하는 더 상위 block도 바뀌어야 하므로 복제되었다.
이런식으로 작은 data 하나를 쓰려고 했을 뿐인데 너무나 많은 write을 하는 문제가 발생할 수 있다.
이 문제는 file system 내부 structure의 깊이가 깊을수록 더 심해진다.
Journaling
Journaling은 DBSM community에서 빌려온 방법이다.
More General Reliability Solutions

Write를 하기 위한 multiple update가 한 번에 disk에서 atomic하게 진행되지는 않는다.
하지만 multiple write을 하나의 logical한, atomic한 unit으로 묶어서 그것을 transaction으로 사용한다.
Atomic이라는 것은 여러 update를 완전히 다 끝내거나 아예 시작도 하지 않은 상태로 유지하는 것이다.
이를 위해 log를 사용한다.
그리고 한 transaction을 recovery unit으로 사용한다.
Transactions
 Write에 대한 transaction이다.
Write에 대한 transaction이다.
여러 write를 atomic하게 수행하자는 것이다.
Log를 먼저 쓰고 flush하고 truncation하고.. 를 반복한다.
이렇게 해야만 multiple write가 atomic하지 않은 문제를 해결할 수 있다.
내가 data block을 바꾸더라도 그걸 그대로 들고와서 log를 써야하는데.. copy on write보다는 좋지만 여전히 쓰는 양이 많다.
그래서 log에 data block은 빼고 inode, inode block같은 meta-data만 적어서 light-weight journaling을 통해 logging을 하기도 한다.
Data journaling mode는 모든걸 다 적는거라 속도가 너무 느린데 잘 안깨진다.
Light weight version은 data block은 빼고 inode가 바뀐 것만 적는다.
속도가 빠른데 full-consistency를 잃어서 data를 잃어버릴 수도 있음. trade-off.
Typical Structure
 도중에 failure나 conflict가 발생하면 roll-back하고, 정상적으로 실행이 끝나면 transaction을 commit한다.
도중에 failure나 conflict가 발생하면 roll-back하고, 정상적으로 실행이 끝나면 transaction을 commit한다.
The ACID Properties of Transactions

Transactional File Systems

Logging File Systems

Redo Logging

Journaling (1)
 Disk를 update하기 전에 먼저 무엇을 하려고 하는건지 lob를 작성한다.
Disk를 update하기 전에 먼저 무엇을 하려고 하는건지 lob를 작성한다.
그러면 혹시라도 disk를 update하다가 crash가 발생해도 log를 보고 retry할 수 있다.
Example: Creating a File
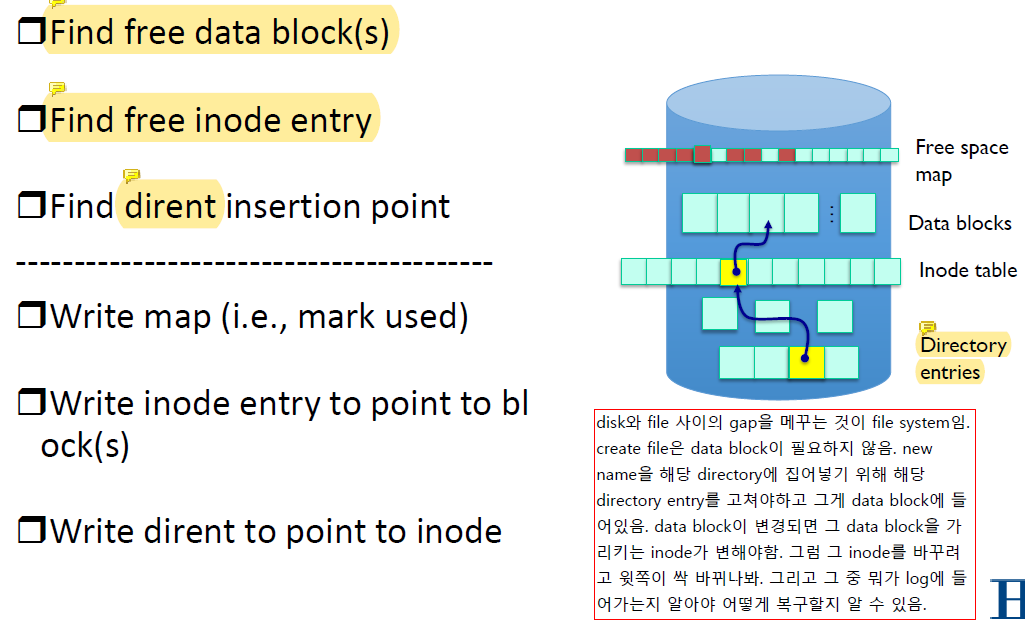 굳이 free data block을 찾을 필요는 없다.
굳이 free data block을 찾을 필요는 없다.
File write을 하는 경우에는 필요하지만 file creating에는 필요하지 않다.
Free inode entry를 찾아서 inode bitmap을 바꾼다.
Inode number에 해당하는 pointer가 inode에 저장되어 있어야 그 block을 찾을 수 있으므로 directory entry가 필요하다.
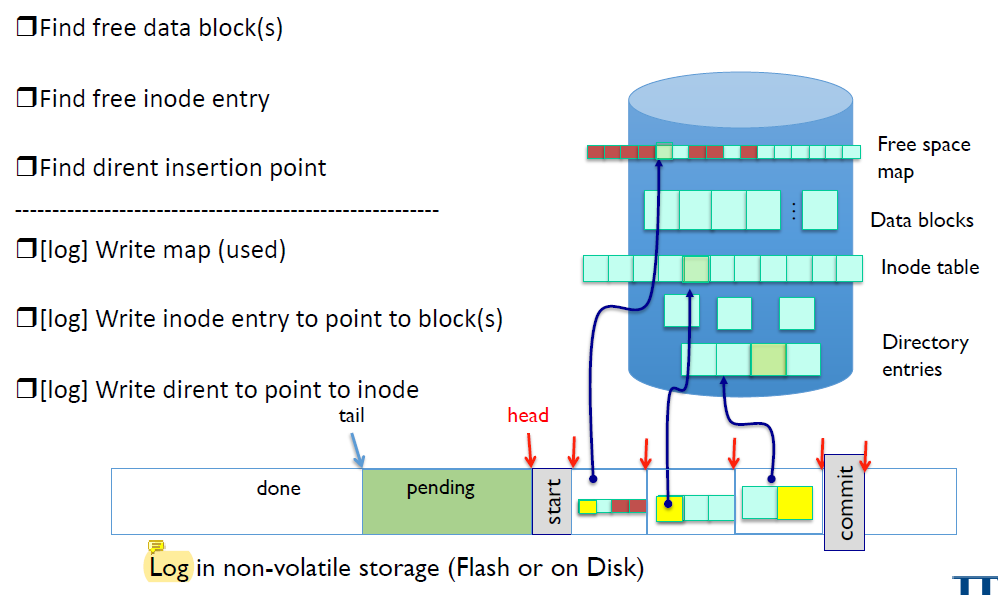 Log에는 1 creation에 사용된 모든 수정내용이 들어간다.
Log에는 1 creation에 사용된 모든 수정내용이 들어간다.
Log는 언제나 physical write에 비해 크기가 작다.
Redo Log
Crash During Logging – Recover
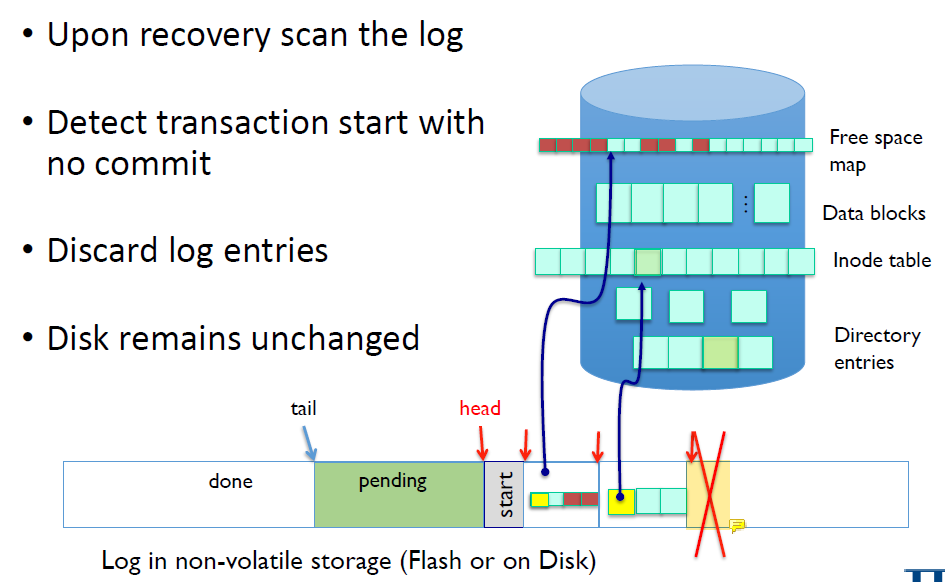 Commit block이 없다면 file system은 아무런 변경이 일어나지 않은 상태다.
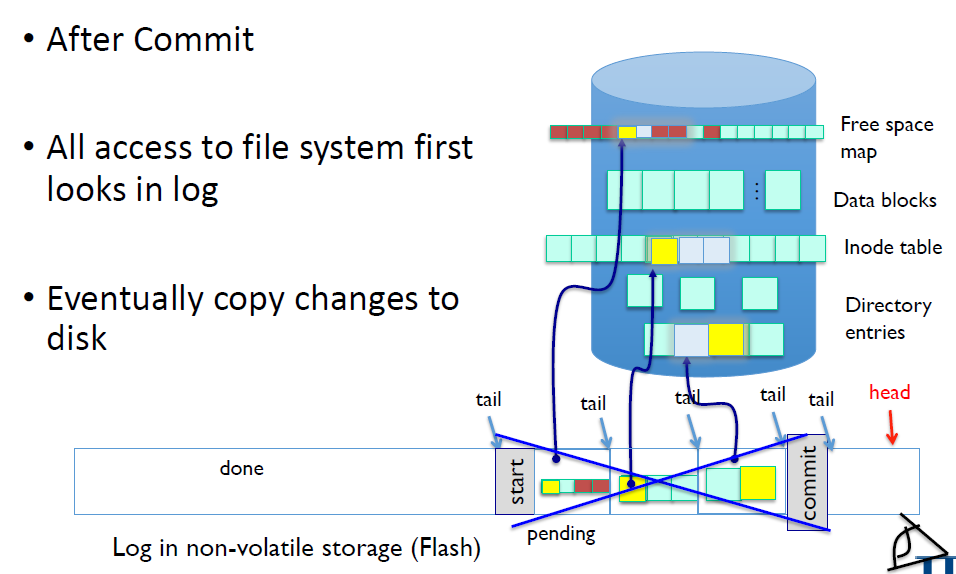
Commit block이 없다면 file system은 아무런 변경이 일어나지 않은 상태다.
그럼 나는 그냥 log를 버리면 된다. Roll-back할 필요도 없다. 이미 그 상태니까.
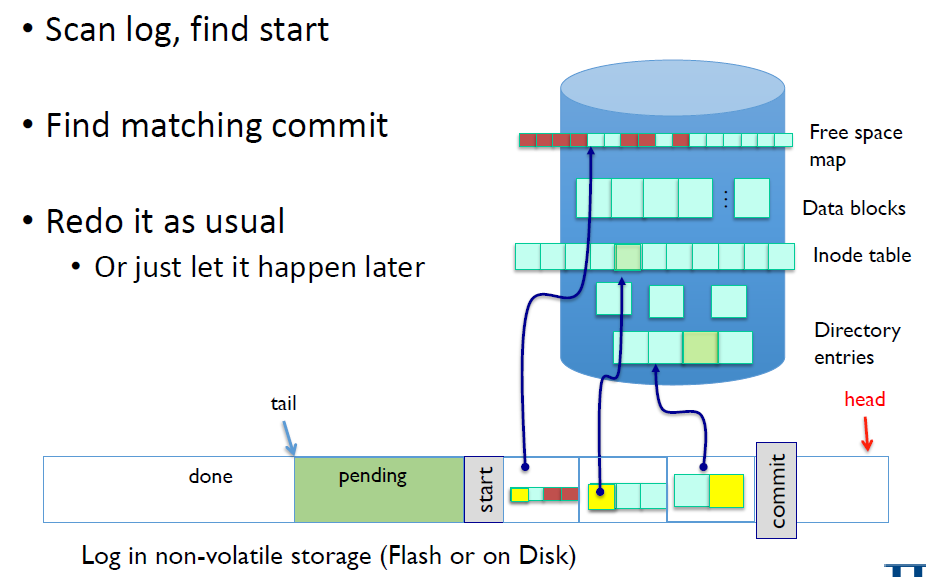
만약 commit block까지 완전히 있다면 log를 재실행하면 된다.
이렇게 하면 file system은 all or nothing 상태가 된다.
Log도 안써진 상태면 nothing으로, log를 다 가지고 있다면 all로!
Recovery After Commit
Journaling (Cont.)

