Binary Classification
classification의 결과가 0 또는 1인 것을 의미한다.
예를 들면
 사진 하나를 보여주고 이 사진이 고양이이면 1, 고양이가 아니면 0을 뱉는 classification model은 binary classification을 수행한다.
사진 하나를 보여주고 이 사진이 고양이이면 1, 고양이가 아니면 0을 뱉는 classification model은 binary classification을 수행한다.
input(x)로 사진을 주면 output(y)으로 0 또는 1이 나온다.
input은 여러 개의 채널을 가지게 된다.
예를 들면, 사진의 색을 표현하기 위해서는 R, G, B의 3개 요소가 필요하므로 vector가 된다.
만약 사진이 가로 64 pixel, 세로 64 pixel에 R, G, B의 3 channel이라면 x의 dimension nx는 64 * 64 * 3 = 12288로 12288이 된다.
Notation
training example이 1개라면
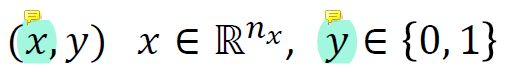
x는 입력 이미지가 벡터로 표현된 것이고 y는 입력 이미지에 따른 결과이다(고양이이면 1, 고양이가 아니면 0).
이러한 training example은 사진 하나 당 1개씩 나오게 되므로 m개의 사진을 사용하면 이 example이 m개 생성된다.
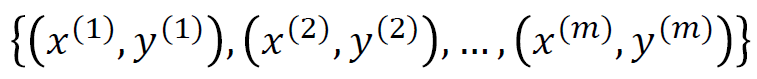 이 m개의 example을 matrix를 사용하면 더 쉽게 표현할 수 있다.
이 m개의 example을 matrix를 사용하면 더 쉽게 표현할 수 있다.
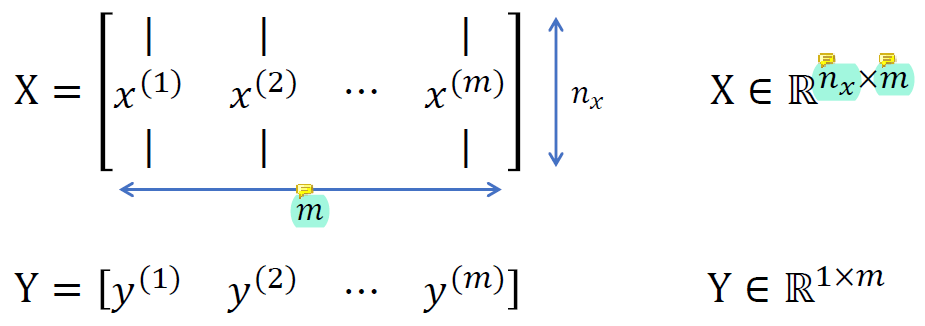
x 1개가 사진 1개를 의미하고 m개의 사진이 있다. 또한 x에는 nx개의 채널이 있으므로 X는 nx * m의 dimension을 가지게 된다.
y는 m개의 사진에 따른 m개의 결과이므로 m의 dimension을 가지게 된다.
Logistic Regression
이건 고양이 이미지를 줬을 때 고양이가 있을 확률을 예측하는 테크닉 중 하나이다.
그림 한 장이 주어졌을 때 고양이가 있을 확률이 38%다 이런 확률 값을 return하는 여러 시스템 중 logistic regression을 이용해 return할 수 있다는 것.

x를 통해 y에 매우 근접한 y hat을 estimate하고 싶어한다.
y hat을 estimate하는 데에 필요한 parameter은 W와 b이다.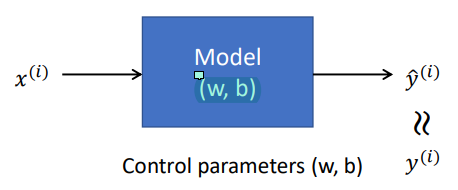
output식이 굉장히 중요하다.
x에 곱해진 W^T는 affine transformation으로, 일종의 선형변환이다.
즉, output y hat은 input인 x를 선형변환 한 번, 비선형변환 한 번을 수행하는 것이다.
x는 input으로 우리가 찾아야 하는 것이 아닌 일종의 상수이다.
우리가 찾아야 하는 것은 W와 b이다. 이것이 unknown variable이며 선형변환 부분에만 unknown이 있다.
Logistic regression의 목적은
W와b를 learning해서 주어진x에 대해y가 1이 될 확률을y hat이 잘 estimate하도록 만드는 것이다.
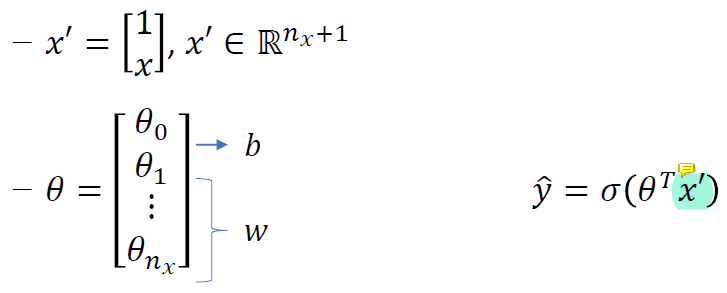
y hat을 linear form으로 표현하기 위해 x'을 사용하였다.
첫번째는 선형변환, 두번째는 비선형변환이라는 것이 중요하다.
Cost Function
learning을 해서 최적의 값을 찾아내야 하는데 최적의 값이 무엇인지 판별하려면 기준이 필요하다.
그 기준이 되는 것이 바로 loss(objective, error) function이다.
우리의 목적은 y와 y hat이 최대한 비슷해지는 것이다.
그 목적함수를 세우는 방법이 굉장히 많은데 그 중 하나가 euclidean distance를 이용하는 방법이고 이게 제일 simple한 방법의 loss function이다.
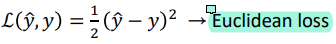 loss function은 손실이 작을 수록, 즉 값이 작을 수록 좋게 정의한다.
loss function은 손실이 작을 수록, 즉 값이 작을 수록 좋게 정의한다.
그런데 반드시 이 loss function을 사용해야하는 것은 아니다.
다른 함수를 사용했을 때 더 좋은 결과가 나온다면, 그 함수를 사용하면 된다. 보통은 여러 함수를 써보고 최적의 함수를 채택해 사용한다. 항상 제일 값이 좋게 나오는 만병통치약같은 loss function이 존재하는 것은 아니다.
보통은 cross-entropy loss function이 euclidean loss function보다 더 좋은 W와 b를 찾는다고 알려져있다.
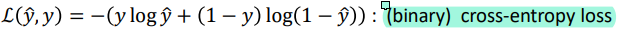
loss function은 example 하나를 다룰 때 사용하고, cost function은 example 전체에 대한 것이지만..
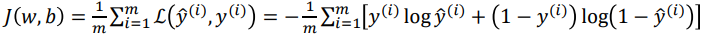 보통 loss function과 cost function의 개념을 혼용해서 거의 같은 개념으로 사용하므로 명확하게 호칭을 구분하여 사용하지 않아도 될 것 같다.
보통 loss function과 cost function의 개념을 혼용해서 거의 같은 개념으로 사용하므로 명확하게 호칭을 구분하여 사용하지 않아도 될 것 같다.
Gradient Descent
m개의 training data가 존재할 때 m이 너무 크면 전체를 다 미분해서 최솟값을 구하기가 너무 힘들기 때문에 gradient descent method를 사용한다.
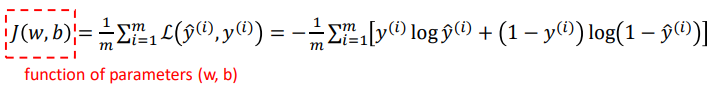 cost function을
cost function을 J(w,b)라고 할 때, J(w,b)를 최소화하는 w와 b를 찾는 방법이다.
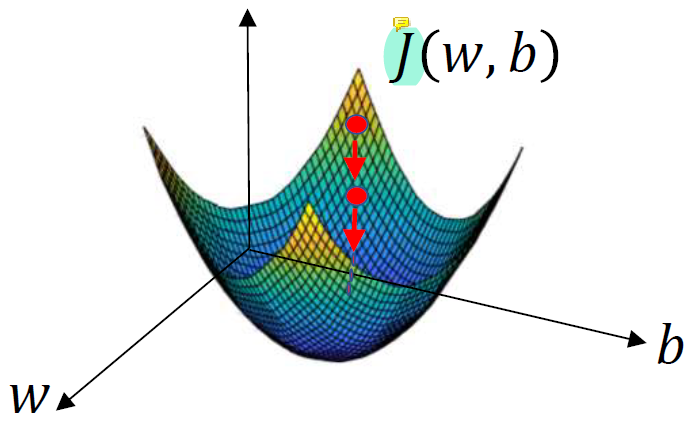 한 점에서 미분해서 기울기를 찾아서 기울기 방향으로 이동한다. 그럼 그 점에서는 이전보다 기울기가 줄어든다. 그럼 그 점에서 미분하고 기울기 찾아서 이동하고..... 를 반복.
한 점에서 미분해서 기울기를 찾아서 기울기 방향으로 이동한다. 그럼 그 점에서는 이전보다 기울기가 줄어든다. 그럼 그 점에서 미분하고 기울기 찾아서 이동하고..... 를 반복.
그럼 결론적으로는 최솟값의 점에 도달하게 된다.
사실 이건 굉장히 이상적인 얘기이긴 함. 최솟값에 가까이 도달할 수록 기울기가 update되는 양이 줄어들기 때문에 매우 비효율적이다. 그래서 어느정도 최솟값에 가까이 도달했으면 steepest descent method를 사용함.
w랑 b가 백만개쯤 되면 J의 형태가 예쁘게 안나오고 왔다갔다 요동을 치는데 그 때는 기울기에 따라 조금씩 움직이면서 update를 하기 때문에 시간이 오래 걸리는 단점이 있을 수 있음
그리고 아마 local minimum에 빠질 확률도 있어서 random restart를 여러 번 필요로 할 것임
gradiant decsent는 다음과 같은 방법으로 수행함.
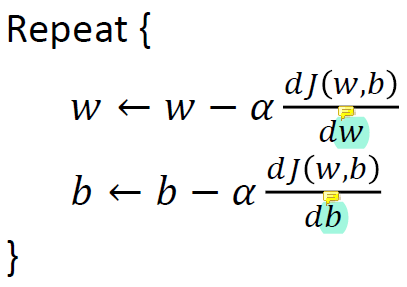
J(w,b)를 미분한 것에 α를 곱한 값을 빼서 w와 b를 각각 update시켜주면 된다.
α 는 learning rate로, w와 b를 얼마나 update할지를 결정한다. 보통 training의 초기에는 엄청 큰 값을 사용하고 나중에는 작은 값을 사용한다.
초기에 큰 값을 사용하는 것은 함수의 이곳저곳을 구경해보라는 뜻이다. 이후에는 fine tuning을 해야하기 때문에 작은 값을 사용한다.
