
로깅 시스템을 개발하며 Kinesis를 이용하고 있는 기존의 레거시 시스템을 어떻게 더 개선할 수 있을까 고민하다가 aws summit 2022에서 발표한 데이터 분석 실시간으로 처리하기: Kinesis Data Streams vs MSK 영상을 발견해 영상에서 설명한 Kinesis Data Streams에 관한 부분만 정리하고, 그동안 내가 잘못 알고 있던 내용을 스스로 바로 잡는 시간을 가져 보았다.
Kinesis의 특징
분산 Queue
Shard
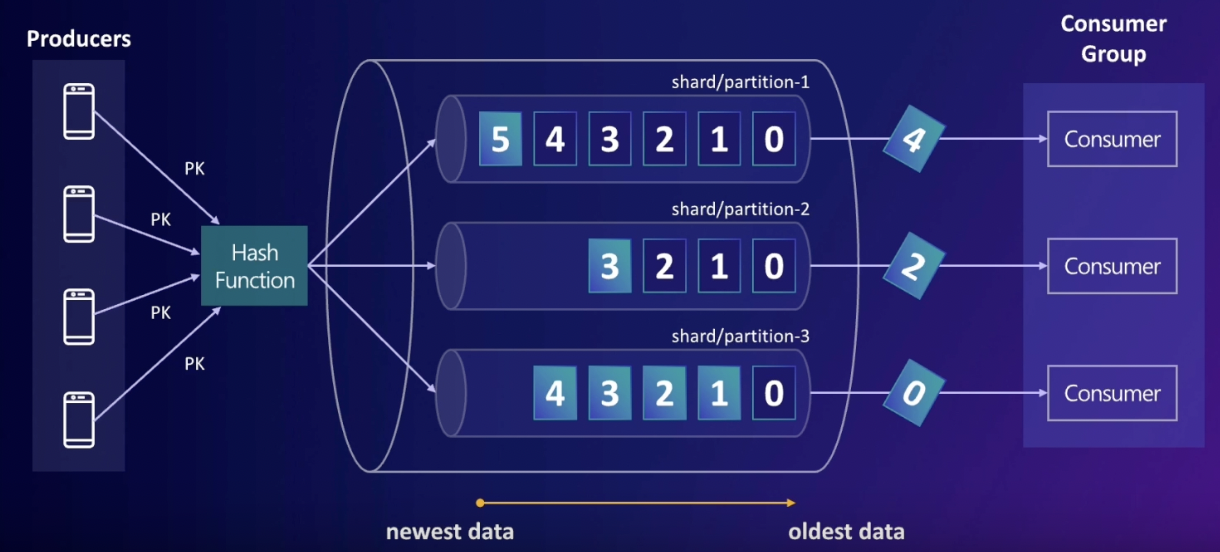
Kinesis Data Streams는 분산 Queue라는 특징을 가지고 있다. 그런데, 인메모리 자료 구조인 큐와 다른 점은 Producer가 많아지고 이에 따라 많은 데이터가 큐에 들어오면 큐가 많은 트래픽을 처리 할 수 있도록 해야 하는데 이 때 Kinesis Data Streams에서 택한 방식은 "Scale-out"을 하는 것이다. 이렇게 scale-out을 통해 만들어진 여러 개의 큐를 kinesis에서는 "Shard"라고 부른다.
Hash function
그런데, 여러 개의 큐를 사용하다 보니 Producer에서 들어오는 데이터를 각각의 샤드로 분배하기 위한 전략이 필요하게 되었다. 즉, 큐 하나에만 데이터가 몰리는 것을 방지하기 위한 방법이 필요하게 된 것이다. 따라서, Kinesis에서는 Hash function을 이용해 들어오는 데이터를 각 샤드에 분배해 준다. 이 때, Producer에서 데이터를 보낼 때 "partition key"를 함께 보내 주면 이 key를 기준으로 여러 개의 샤드로 데이터를 분산할 수 있다.
읽기 & 쓰기 성능 향상
이를 통해, producer의 관점에서는 여러 개의 데이터를 보내더라도 각 데이터가 분산 되어 여러 큐에 들어가고 반면 consumer의 관점에서는 consumer가 더 추가 되어도 consumer들은 각 샤드에서 데이터를 읽을 수 있게 된다. 이러한 방법으로, 동일한 큐를 scale-out 하여 쓰기 & 읽기 성능을 올릴 수 있다. 논리적으로, 여러 consumer들을 하나의 consumer group으로 볼 수 있고 내부적으로는 여러 개의 큐로 이루어져 있지만 외부에서 볼 때는 하나의 커다란 큐가 있는 것으로 생각할 수 있다.
스트림 스토리지
스토리지
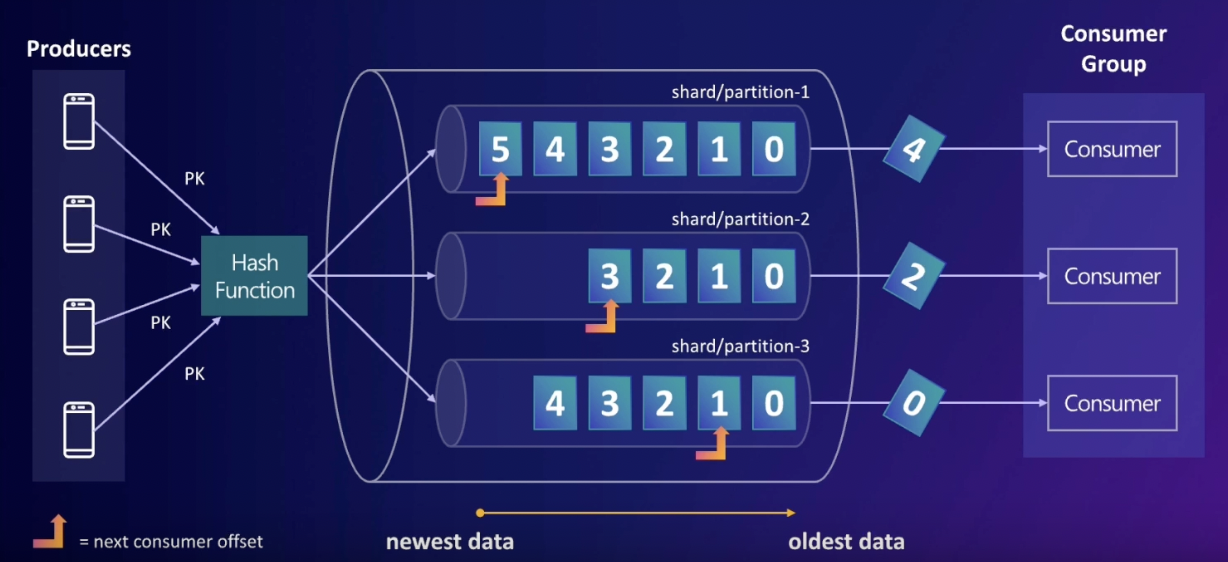
인메모리 큐 데이터 관점에서 생각해 보면, 데이터를 한 번 읽어 가면 그 데이터는 삭제 된다. 이러한 방식을 kinesis data streams에도 도입하게 되면 2번 consumer가 2번 인덱스 앞에 있는 데이터(2번 샤드)를 읽을 경우 다른 consumer는 2번 인덱스 앞에 있는 데이터를 더 이상 읽을 수 없다. 그러나, kinesis data streams에서는 특정 consumer가 데이터를 읽었다고 해서 그 데이터를 삭제하는 것이 아니라 그대로 남겨 둔다. 또한, 남겨둔 뒤 그 다음에 읽어들어야 하는 위치만 표시를 해준다(next consumer offset). 이렇게 할 경우 2번 consumer가 2번 인덱스의 데이터를 소비했더라도 다른 consumer가 데이터를 읽어 들이는 데 문제가 발생하지 않는다. 이런 의미에서 kinesis를 일종의 스토리지라고 생각할 수 있다.
리텐션
그러나, 일반적인 스토리지와는 달리 "리텐션"을 설정할 수 있다. 즉, 데이터를 얼마나 오랫동안 보관할 것인 지를 가령 24시간/1주일 등으로 설정할 경우 리텐션 기간이 지난 데이터는 오래된 순서부터 자동으로 삭제 된다. 이러한 특징 때문에 Kinesis를 스트림 스토리지 라고 한다.
Throughput 프로비저닝 모델
Kinesis는 throughput 기반으로 성능을 올리는 방식을 사용한다. 즉, kinesis data streams에 데이터를 초당 몇 번 쓰고 몇 번 읽을 지에 대한 throughtput 설정을 변경해 성능을 올릴 수 있다.
Shards 수의 증가와 감소가 가능
이러한 특징 덕분에 트래픽이 많은 시간대에 샤드 수를 크게 늘렸다가 야간에 트래픽이 줄어들면 샤드 수도 함께 줄이는 방식으로 kinesis를 운영할 수 있다.
스트림 스토리지 도입의 효과
생산자와 소비자 분리(decoupling) 통한 영구적인 버퍼 역할
이를 통해, producer가 빠르게 데이터를 생산하고 consumer가 조금 느리게 소비 하더라도 둘은 서로 분리 되어 있기 때문에 서로 영향을 주지 않고 producer가 생성한 데이터를 일정한 기간 동안 버퍼링 해서 저장하는 것이 가능하다. 이 때문에 kinesis data streams는 영구적인 버퍼 역할을 할 수 있다.
다수의 스트림을 수집하는 것이 가능함
Kinesis data streams를 일종의 큐처럼 사용 함으로써 producer가 하나의 큐에 데이터를 넣어 주면 consumer들이 이를 소비하는 방식으로 전체 구조를 단순화 시킴으로써 다수의 스트림을 수집할 수 있다.
메시지의 순서 유지가 가능함
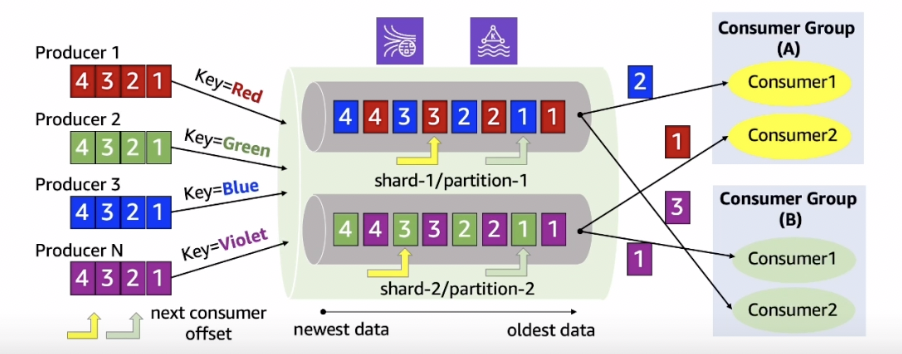
Producer가 데이터를 입력한 순서대로 consumer가 데이터를 소비할 수 있도록 데이터의 입력 순서가 보장 된다. 하지만, 큐가 하나가 아니라 내부적으로 여러개이기 때문에 내부적인 단일 큐, 즉 샤드 안에서는 데이터의 입력 순서가 보장 되지만 샤드와 샤드 간의 데이터 순서는 보장 되지 않는다. 즉, 전체 순서를 보장하는 것이 아니라 샤드 안에서만 순서가 보장 된다. 이 부분을 주의 해야 할 것 같다. 그렇다면 이 말은 사실 kinesis data streams를 프로비저닝 하여 샤드를 2개 이상으로 구성할 경우 순서를 관리할 수 있는 다른 방법을 찾아야 할 수도 있다는 말과 같기 때문이다.
병렬적인 소비
Consumer들이 서로 다른 샤드에서 개별적으로 동시에 데이터를 읽을 수 있다.
스트리밍 MapReduce
파티션 키를 기준으로 입력 데이터들이 그룹화 되어 서로 다른 샤드나 파티션에 저장 되기 때문에 여러 consumer들이 그룹화 된 데이터를 동시에 소비할 수 있다. 이러한 데이터 처리 방식을 스트리밍 맵 리듀스라고 한다.
참고
참고로, MSK(Amazon Managed Streaming for Apache Kafka)와 Kinesis Data Streams를 비교해 보면 kafka의 브로커는 kinesis의 stream에 대응 되며 kafka의 partition은 kinesis의 샤드에 대응 된다. 이러한 점에서 구조적으로는 둘이 매우 비슷하지만 kinesis data streams가 MSK에 비해서 추상화 레벨이 높은 편이라 할 수 있다.
