
aws 공식문서를 읽어봐도 잘 이해가 되지 않아, 유튜브에 올려진 강의를 찾아 보았다.
아래 강의 내용을 참고해 이번 글을 정리했다.
AWS 기반의 대용량 실시간 스트리밍 데이터 분석 아키텍처 패턴 - 김필중 솔루션즈 아키텍트(AWS)
Kinesis란?
대용량 스트리밍 데이터를 수집하고, 처리 및 분석할 수 있다. 이를 통해, 데이터를 실시간 처리해 S3와 같은 스토리지에 저장한 후, 다양한 일괄 처리를 할 수 있다.
Kinesis는 한 샤드당 초당 1000개 레코드 또는 1MB 까지 수집할 수 있다.
스트리밍 데이터 처리 패턴
데이터 생산자 → 스트리밍 서비스 → 데이터 소비자 의 순으로 데이터 처리가 이루어짐
- 데이터 생산자
- 지속적 데이터 생성
- 스트림으로 지속적인 데이터 쓰기
- 무엇이든 대상이 될 수 있다!
- 스트리밍 서비스
- 내구성 있게 데이터 저장해야 한다.
- 데이터 준비를 위한 임시 버퍼 공간을 제공한다.
- 매우 높은 through-put 제공해야 한다 → 처리 속도를 높이기 위함
- 데이터 소비자
- 지속적으로 데이터를 처리함
- 정리, 준비 및 집계 등의 일을 함
- 데이터를 정보로 변환함
Kinesis 특징
비디오와 데이터 스트림을 실시간으로 손 쉽게 수집 및 처리, 분석하는 서비스로 총 4가지로 나눌 수 있다.
- Kinesis Data Streams: 데이터 스트림을 분석하는 사용자 정의 애플리케이션 개발에 사용된다.
- 데이터를 받으면 일정 기간 동안 내구성 있게 데이터를 저장하기 위한 서비스
- Kinesis Data Firehose: 데이터 스트림을 AWS 데이터 저장소에 적재한다.
- 데이터를 입력 받고 S3나 redshift, elasticsearch로 전송
- 뒷 단의 목적지로 데이터를 전송하기 위한 목적을 가짐
- Kinesis Data Analytics: SQL을 사용해 데이터 스트림 분석
- Kinesis Data Stream 또는 Firehose에 쉽게 연결하고 SQL 검색을 할 수 있다.
- 수행 결과를 다시 Data Stream 또는 Fireshose로 보냄
- 스트리밍 소스에 연결 → SQL 코드를 쉽게 작성 → 지속적으로 SQL 결과를 전달함
- 데이터를 처리하기 위한 2가지 컨셉을 사용하고 있다.
- 스트림(인-메모리 테이블) → 가상의 테이블 or view라고 봐야 함
- 펌프(연속 쿼리) → 실제 데이터를 앞서 만든 view에 넣어주는 역할
- 스트림(인-메모리 테이블) → 가상의 테이블 or view라고 봐야 함
- Kinesis Video Streams: 분석을 위한 비디오 스트림 캡쳐 및 처리, 저장
스트리밍 애플리케이션의 패턴
현재 개발자들은 다양한 방식으로 스트리밍 애플리케이션을 사용하고 있는데 그 형태는 아래의 세 가지로 크게 나누어 생각해 볼 수 있다.
1. 스트리밍 수집-변환-적재
- 신속하고 저렴하게 분석 도구에 데이터를 전달함
- 50% 이상의 use-case가 이 패턴을 따름
적용 예시
- S3로 로그 데이터를 수집 및 적재하기 위해 해당 패턴을 사용할 수 있음
- 모든 클릭 기록(clickstream) 데이터 수집 및 정리 & 데이터 웨어하우스에 넣는 작업
- aws 네트워크 로그 분석
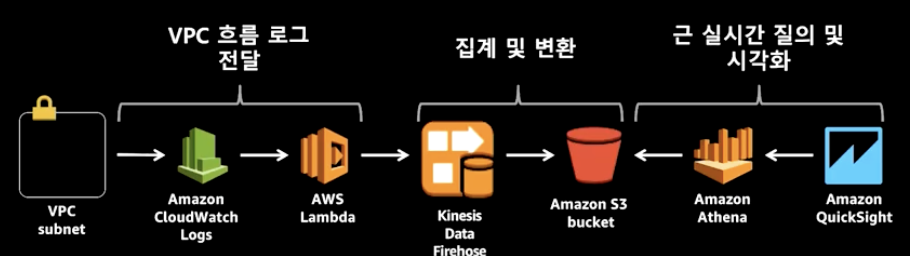
- 순서: aws logs에 데이터 적재 → aws lambda가 읽어 옴 → data fire hose로 보냄 → S3에 데이터 밀어 넣음 → S3에 있는 데이터에 Athena로 쿼리문을 날림 → QuickSight라는 BI 툴로 결과를 확인할 수 있음 - 여러 단계로 데이터를 버퍼링 하는 것이 중요함(latency를 줄이기 위함) - 작업 유형에 알맞는 데이터 형식을 선택해야 함(Athena는 parquet 형식을 이용해야 효율적으로 쿼리를 할 수 있음) - 높은 요구 사항과 latency 사이의 절충점을 찾아야 함
핵심 요구사항
- 대용량의 소규모 이벤트를 내구성 있는 곳에 수집 및 버퍼링 해야 함
- 간단한 변환을 수행해야 함
- 효율적으로 데이터를 보존 및 저장해야 함
2. 지속적인 지표 생성
- 데이터가 생성 될 때 분석 수행
- 배치로 처리하던 것과는 달리 실시간으로 데이터를 보여줄 수 있음
- 데이터가 늦어지거나 순서가 바뀔 수 있으므로 이러한 데이터가 있을 수 있다는 점을 고려해 정확한 결과를 생성해야 함
- 과거의 데이터와 결합해서 인사이트를 도출해야 함
적용 예시
- 리더 보드 구현: group rank를 돌리는데 사용자별 score 합을 더해서 사용자들에게 리더 보드 랭킹을 보여주는 데 사용
- 애플리케이션 로그를 사용해 지표를 생성해야 할 때
- 광고 노출 및 페이지 뷰와 같은 clickstream 분석
- 시계열 데이터 분석
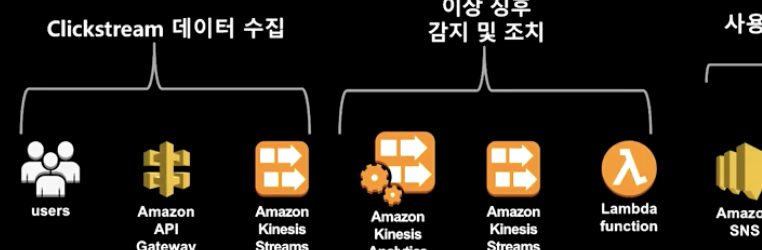
- 데이터 생성자가 항상 온라인이 아닐 수 있기 때문에 늦거나 혹은 순서가 바뀔 수 있는 데이터라는 사실을 인지해야 한다. → 따라서, 수집할 때의
이벤트 시간을 기준으로 사용해야 한다. → Data stream으로 넘어오는 시간 또는 별도의 timestamp를 기준으로 분석해야 함
- 과거 또는 정적 데이터와의 결합을 통해 insight를 얻어야 하기 때문에 S3 또는 Reshift와 결합할 필요가 있음
- 데이터 생성자가 항상 온라인이 아닐 수 있기 때문에 늦거나 혹은 순서가 바뀔 수 있는 데이터라는 사실을 인지해야 한다. → 따라서, 수집할 때의
핵심 요구사항
- 늦거나 순서가 바뀔 수 있는 데이터로 정확한 결과를 생성해야 함 → IoT의 경우 인터넷이 언제든지 끊길 수 있다. 그러나 kinesis는 작동을 하기 때문에 online이 되었을 때 나중에 한 번에 몰아서 데이터를 보내게 된다. → 따라서, 이런 경우가 생길 수 있다는 전제를 하고 있어야 함
- 과거의 데이터와 결합해서 과거에 비해 어떻게 달라졌는 지에 대한 insight를 도출해야 함
3. 반응형 분석
- 통찰력을 기반으로 분석결과에 반응할 수 있음
- 적용 예시
- 리테일 웹사이트의 추천 엔진
- 지능적 장치 운영 및 경보
- 사용자 이상 행동 감지(어뷰징)
- 실시간 이상 징후 감지 및 조치
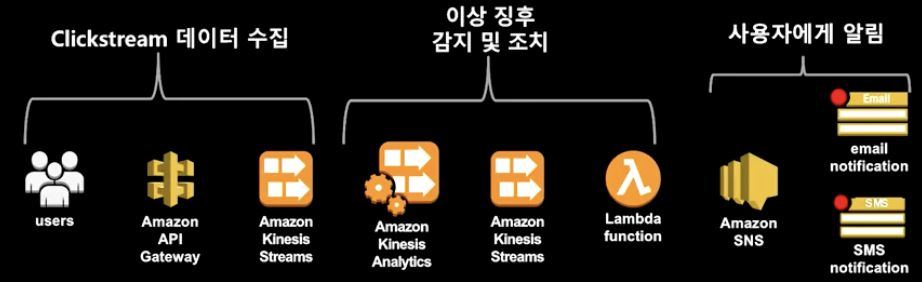
- 수집 및 처리시 확장성을 가지고 있어야 함 → 생성된 데이터를 한 번에 받아낼 수 있어야 하기 때문에 들어오는 데이터 사이즈에 따라서 가변적으로 확장이 가능해야 함
- 앱 또는 사람이 ‘이유’를 파악하기 위해 데이터와 관련된 충분한 문맥 정보가 제공되어야 함
- 수집 및 처리시 확장성을 가지고 있어야 함 → 생성된 데이터를 한 번에 받아낼 수 있어야 하기 때문에 들어오는 데이터 사이즈에 따라서 가변적으로 확장이 가능해야 함
- 핵심 요구사항
- 지연 없이 사용자와 단말에 즉각 통지할 수 있어야 함 → 사용자 어뷰징 제지를 즉각 할 수 있어야 함
- 스트림을 통한 지속적 실행, 상태가 있는 작업이어야 함
- 지연 없이 사용자와 단말에 즉각 통지할 수 있어야 함 → 사용자 어뷰징 제지를 즉각 할 수 있어야 함
실시간 데이터 분석 예시: 게임
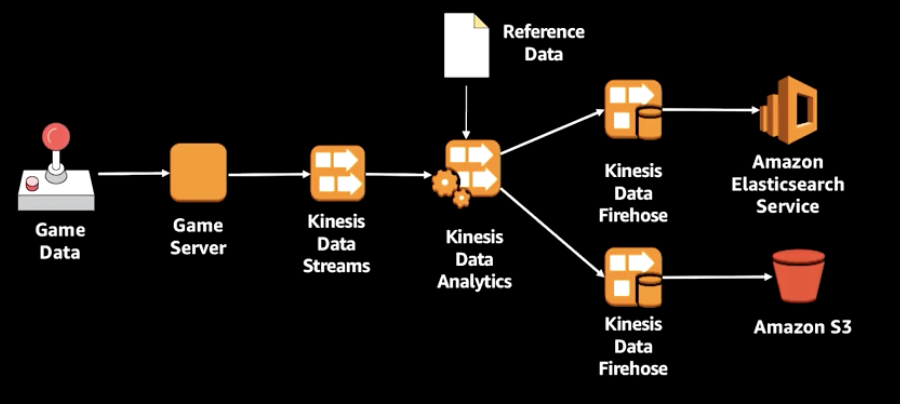
위와 같은 방식의 데이터 전송 과정을 거치게 될 수 있다.
- 데이터를 수집해서 Kinesis Data Analytics를 통해 데이터를 분석하고 Data Firehose로 데이터를 전달한다. → 이 때, Data Analytics는 스트림 & 펌프가 가능하며 이를 통해 인-메모리에 테이블에 데이터를 적재한다.
- 잠재적으로 끊임없는 스트림이 일어나기 때문에 이 경우
윈도우 함수(아래 윈도우란? 참고)로 부분 집합을 지정해 처리해야 한다. - 그 다음, Firehose를 통해 elasticsearch와 S3에 적재하고
- kibana로 결과를 시각화할 수 있다.
윈도우란?
- 시간 또는 행을 기반으로 정의하는 고정된 길이의 창
- 두 종류의 윈도우
텀블링,슬라이딩이 있다.
- 가상의 창(window)을 지정해서 데이터의 range를 정해 데이터에 연산을 적용하고 집계할 수 있음
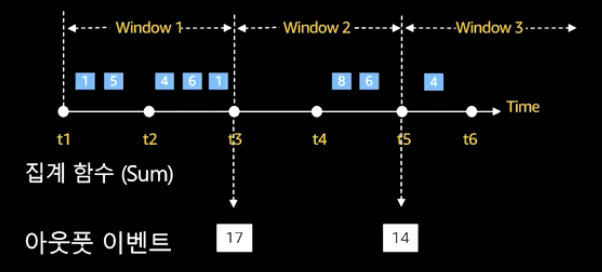
- 텀블링 윈도우(시간 간격 별 집계)와 슬라이딩 윈도우(지속적으로 재평가 되는 윈도우)로 구성된다.
- 텀블링 윈도우: 계산된 데이터가 다시 계산되지 않음 → 데이터가 들어오든 말든 시간이 되면 일단 결과를 보내준다.
- 슬라이딩 윈도우: 가령, 10초 간격으로 지정해 놓아도 레코드가 들어올 때마다 다시 그 시점 기준으로 지난 10초 간의 이벤트를 다시 집계함 → 데이터 인풋이 없으면 결과를 보내주지 않음
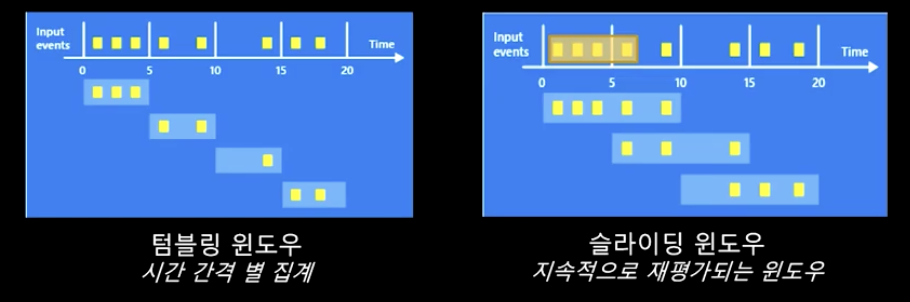
- 텀블링 윈도우: 계산된 데이터가 다시 계산되지 않음 → 데이터가 들어오든 말든 시간이 되면 일단 결과를 보내준다.
추가적으로 더 알아본 설명을 덧붙인다.
Kinesis Data Stream
Producer인 웹 페이지, 어플리케이션 등에서 스트리밍 데이터를 Data Stream으로 실시간으로 계속해서 보내면, 여러 Consumer(EC2 인스턴스가 될 수 있다.)에서 실시간으로 데이터를 처리하는 아키텍쳐이다.
이후 Kinesis Firehose를 통해 S3와 같은 저장소에 저장할 수도 있다.
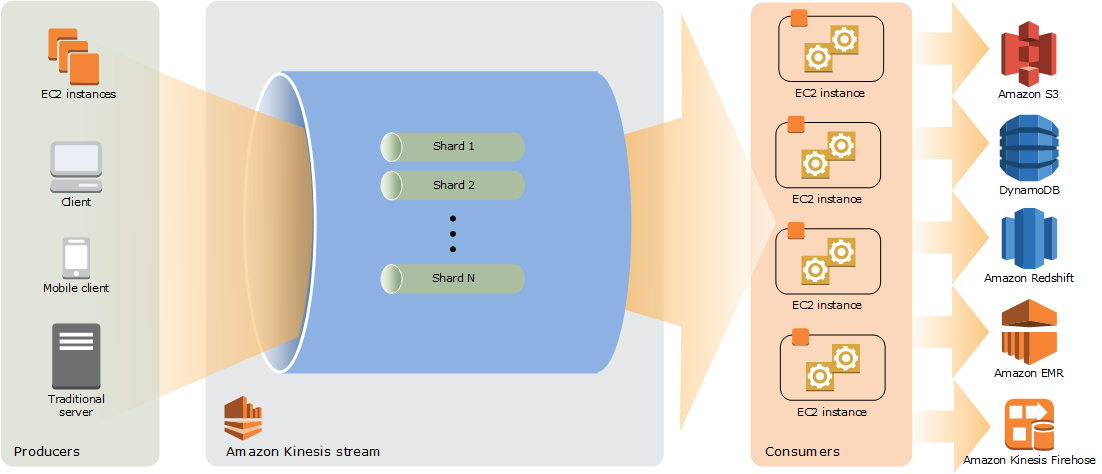
from aws
아래의 4가지로 구성된다.
- Data record: kinesis stream에 저장되는 단위(시퀀스 번호 + 파티션 키 + 데이터 BLOB(변경 불가한 바이트 시퀀스)로 구성됨
- Shard: Data stream에서 고유하게 식별되는 레코드 시퀀스 → 스트림은 하나 이상의 샤드로 구성되며 샤드는 고정된 용량을 제공함
- Partition key: 스트림 내의 샤드 별로 데이터를 그룹화 하는 데 사용함 → 이를 통해 레코드가 보내질 샤드를 구분한다.
- Sequence Number: 각 데이터 레코드에는 샤드 내에 파티션-키 마다 고유한 sequence number가 있다.
Kinesis Firehose Delivery Stream
- Firehose를 통해 스트리밍 데이터를 S3 버킷과 같은 저장소, 분석 도구, Data Lake 등으로 안정적인 전달이 가능하다.
- 스트리밍 데이터를 캡쳐해 로드할 수도 있고 압축, 처리, 변환 기능도 제공해서 편리한 사용이 가능하다. → 이 때, 버퍼 크기와 간격을 설정해서 데이터를 특정 크기로 특정 기간 동안 버퍼링 후 대상으로 전달한다.
Kinesis Data Stream VS Kinesis Data Firehose
- 둘 다 클라우드 내 실시간 데이터를 처리한다는 점은 동일하다.
- 그러나, Data Stream은 ‘수집과 저장’ 기능을 하며 Data Firehose는 ‘처리 및 전송’ 기능을 한다는 점이 다르다!
Kinesis Data Stream
- 데이터 ‘수집 및 저장’ → 초당 기가바이트의 데이터를 수집해 실시간으로 처리 및 분석 하는 데 사용함
- 로그 및 이벤트 데이터 ‘수집’
- Producer, Source, Writing
- Kinesis Agent
- Kinesis Data Streams API
- Kinesis Producer Library(KPL)
- Destination
- Amazon Kinesis Data Analytics
- Spark on EMR
- EC2
- Lambda
Kinesis Data Firehose
- 데이터 ‘처리 및 전송’ → 데이터 저장소, 분석 툴에 실시간 데이터 스트림을 준비하고 로드함
- 로그 및 이벤트 ‘분석’
- Producer, Source, Writing
- Kinesis Data Streams
- Kinesis Agent
- Kinesis Data Firehose API
- CloudWatch Logs & Events
- Destination
- S3
- Redshift
- Elasticsearch
- Splunk
- HTTP 엔드포인트
참고

정리가 깔끔해서 보기도 좋았고 이해도 잘 되었습니다. 잘봤습니다 감사합니다