
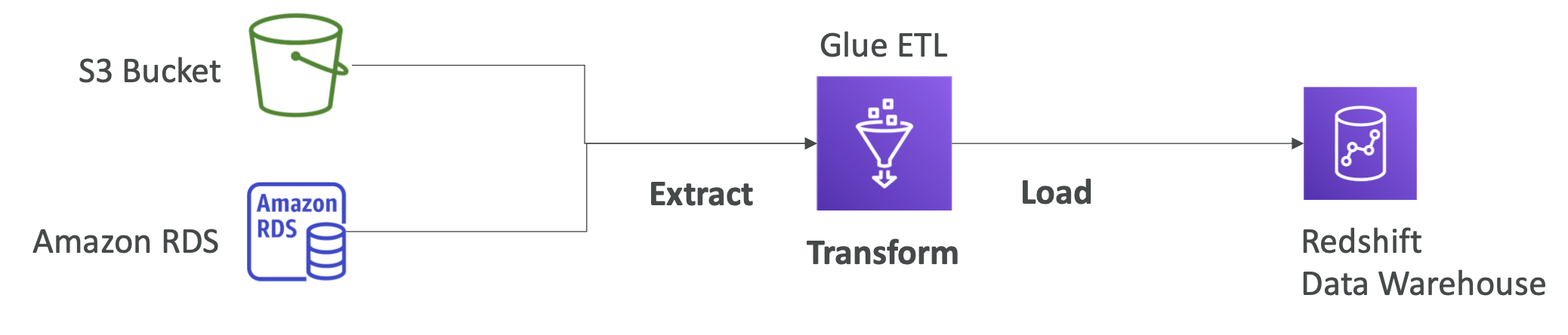
Glue
- 관리형 ETL(Extract + Transform + Load) 서비스이다.
- 분석을 위해 데이터를 추출하고 변형하는 데 사용된다.
- 서버리스 서비스이다.
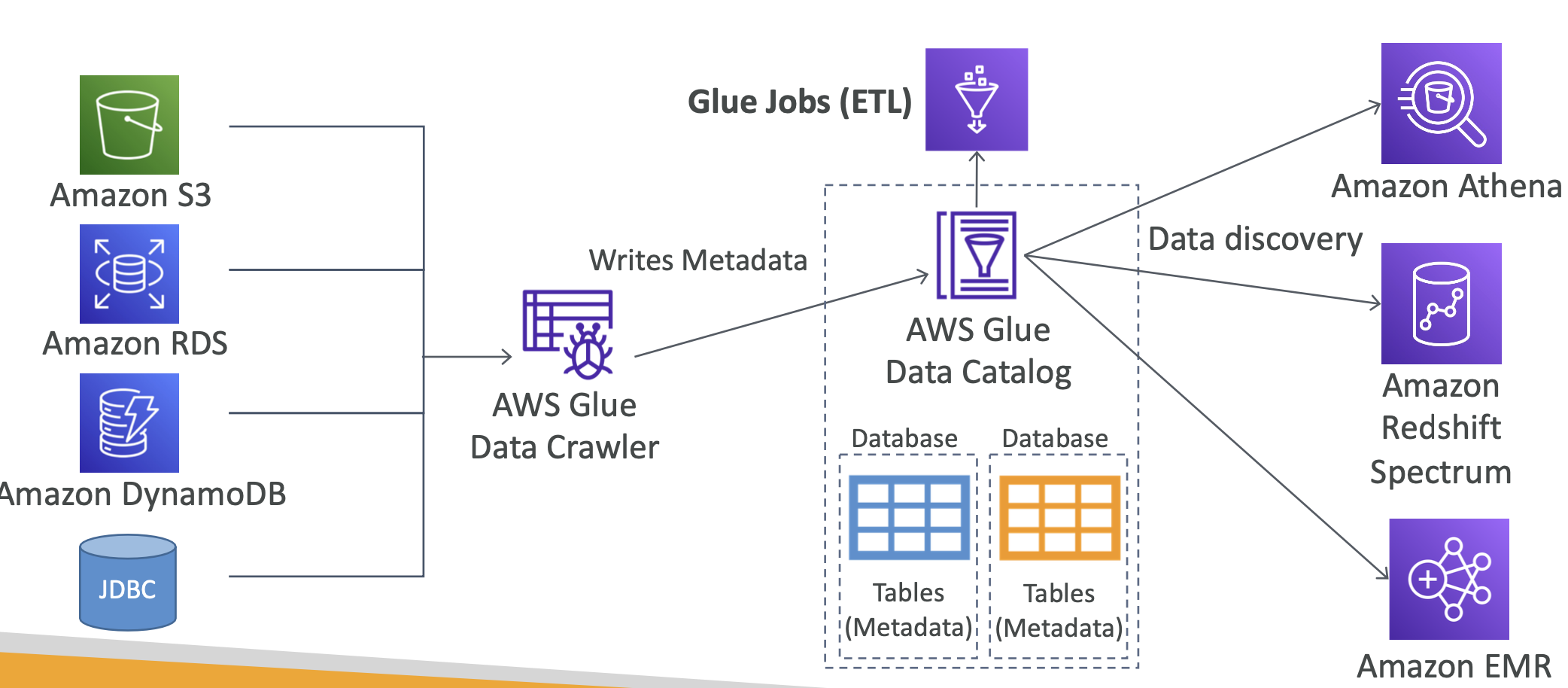
Glue Data Catalog
- 데이터의 카탈로그로, 메타데이터이다.
- 메타데이터는 데이터에 대한 정보를 가지고 있다. - Glue 크롤러가 데이터베이스에서 데이터를 찾아 크롤링 하고, 그 다음 찾은 데이터에 대한 정보(Metadata)를 Glue Data Catalog에 쓰게 된다.
- 테이블명, 테이블 유형, 컬럼명 등등 - Glue Data Catalog는 ETL을 하는 Glue Jobs에 의해 사용될 수 있다.
- 크롤링이 올바르게 완료 되었는지 확인하기 위해 사용된다. - 이는 Athena에 의한 데이터 복원, Redshift 또는 EMR에 의한 데이터 분석에 사용될 수도 있다.
Neptune
- 완전 관리형의 그래프 데이터베이스이다.
- 사용 예시
- 서로 많이 연관된 데이터들에서 사용 된다.
- 소셜 네트워킹: 특정 유저와 친구 관계인 유저가 포스트에 댓글을 달거나 좋아요를 하는 경우 이용할 수 있다. -> "에이미의 친구들이 올린 게시물에 대한 좋아요 수는 몇 개일까요?"와 같은 복잡한 쿼리를 수행할 때 사용할 수 있다.
- 위키피디아 같은 지식 그래프: 여러 종류가 서로 얽혀 있다. - 3개의 AZ에서 사용되는 고가용성이며 최대 15개의 읽기 복제본을 갖는다.
- 특정 시점을 기준으로 복원이 가능하며 S3로 지속적으로 백업을 생성한다.
- KMS 암호화와 HTTPS를 지원한다.
Solutions architect 관점의 Neptune
- 운영
- RDS와 유사하다. - 보안
- RDS와 같은 보안을 가지며, 이에 더해 Neptune으로의 IAM 인증을 받는다. - 신뢰성
- Multi-AZ, 클러스터링 - 성능
- 그래프에 최적화 되어 있으며 성능을 높이기 위해 클러스터링을 사용한다. - 비용
- 프로비저닝 된 노드 당 비용을 지불한다.
ElasticSearch
- 오픈 소스이며 AWS에서는 서비스로 판매 된다.
- DynamoDB와 비교해 보면 DynamoDB의 경우 원하는 값을 찾기 위해서는 정확히 일치하는 primary key 또는 indexes를 제공해야 한다.
- ElasticSearch의 경우 어떤 필드도 찾을 수 있으며 필드 값 전체가 아닌 부분만을 제공해도 찾는 것이 가능하다.
- 예를 들어, John을 검색하고 싶을 경우 Jo만 검색해도 John을 찾을 수 있다. - 검색에 최적화 되어 있으며 데이터베이스의 보조 역할로 사용할 수 있다.
- 데이터 흡수를 위한 내장된 통합 기능을 제공한다.
- 통합 기능에 사용되는 서비스들: AWS Kinesis Data Firehose, AWS IoT, Amazon CloudWatch logs - Cognito, IAM, KMS, SSL과 VPC를 통해 보안을 높일 수 있다.
- ELK 스택도 제공 된다.
- Kibana(Visualization) + Logstash(Log ingestion)
- Elasticsearch와 위 두 가지가 함께 사용되면 ELK 스택이 된다.
Solutions Architect 관점에서 본 ElasticSearch
- 운영
- RDS와 유사 - 보안
- Cognito, IAM, VPC, KMS, SSL - 신뢰성
- Multi-AZ, Clustering - 성능
- ElasticSearch 오픈 소스를 기반으로 하며 petabyte 규모까지 확장이 가능하다. - 비용
- 프로비저닝 된 노드 당 비용을 지불한다.
오답노트
Q1. 여러분은 OLTP(온라인 트랜잭션 처리)를 수행하려고 합니다. 자동 크기 조정 기능이 내장되어 있고 기본 스토리지에 대한 최대 복제본 수를 제공하는 데이터베이스를 사용하려고 합니다. 어떤 AWS 서비스를 추천할까요?
A1. Amazon Aurora
Amazon Aurora는 MySQL 및 PostgreSQL 호환 관계형 데이터베이스입니다. 데이터베이스 인스턴스당 최대 128TB까지 자동 스케일링되는 분산형 내결함성 자가 복구 스토리지 시스템이 특징입니다. 최대 15개의 짧은 지연 시간 읽기 전용 복제본, 특정 시점 복구, Amazon S3로의 지속적인 백업, 3개의 AZ에 걸친 복제를 통해 고성능과 가용성을 제공합니다.
Q2. 여러분은 로그를 필터링하고 무단 작업을 시도한 사용자를 찾기 위해 가능한 경우 서버를 사용하지 않는 빠른 분석을 수행하려는 S3 버킷에 많은 로그 파일이 저장되어 있습니다. 어떤 AWS 서비스가 그렇게 할 수 있을까요?
A2. Amazon Athena
Amazon Athena는 표준 SQL을 사용하여 S3 버킷의 데이터를 쉽게 분석할 수 있는 대화형 서버리스 쿼리 서비스입니다.
Q3. Redshift의 어떤 기능이 VPC를 통해 클러스터와 데이터 리포지토리 간에 이동하는 모든 COPY 및 UNLOAD 트래픽을 강제할까요?
A3. 향상된 VPC 라우팅

- 이 문제에서는 DynamoDB를 생각했는데 DynamoDB는 아이템의 크기가 최대 400KB이기 때문에 사용이 불가능하다. 따라서 크기가 큰 데이터를 저장하기 위해 적합한 서비스는 S3이다.
