Amazon Aurora
- Amazon Aurora는 내결함성을 갖춘 자가 복구 분산 스토리지 서비스
- 데이터베이스 인스턴스 당 최대 128TB까지 자동으로 확장 됨
- 지연시간이 짧은 읽기 전용 복제본 최대 15개, 특정 시점으로 복구, Amazon S3로 지속적 백업, 3개 AZ에 걸친 복제를 통해 뛰어난 성능과 가용성 제공
기존 아키텍쳐
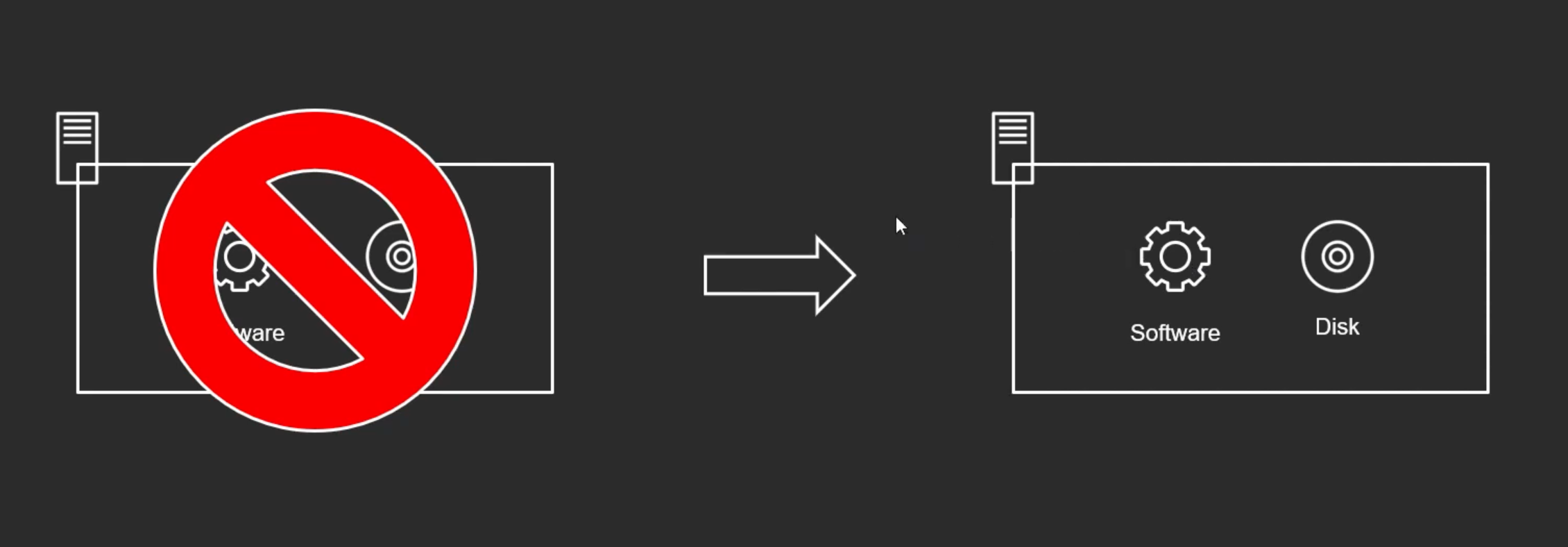
- 전통적인 아키텍쳐는 디스크와 소프트웨어가 하나의 서버 안에 있다.
- 이 서버 자체가 터지게 되면 기존과 똑같으 서버를 다시 만들어야 한다.
스토리지 / 컴퓨팅 분리
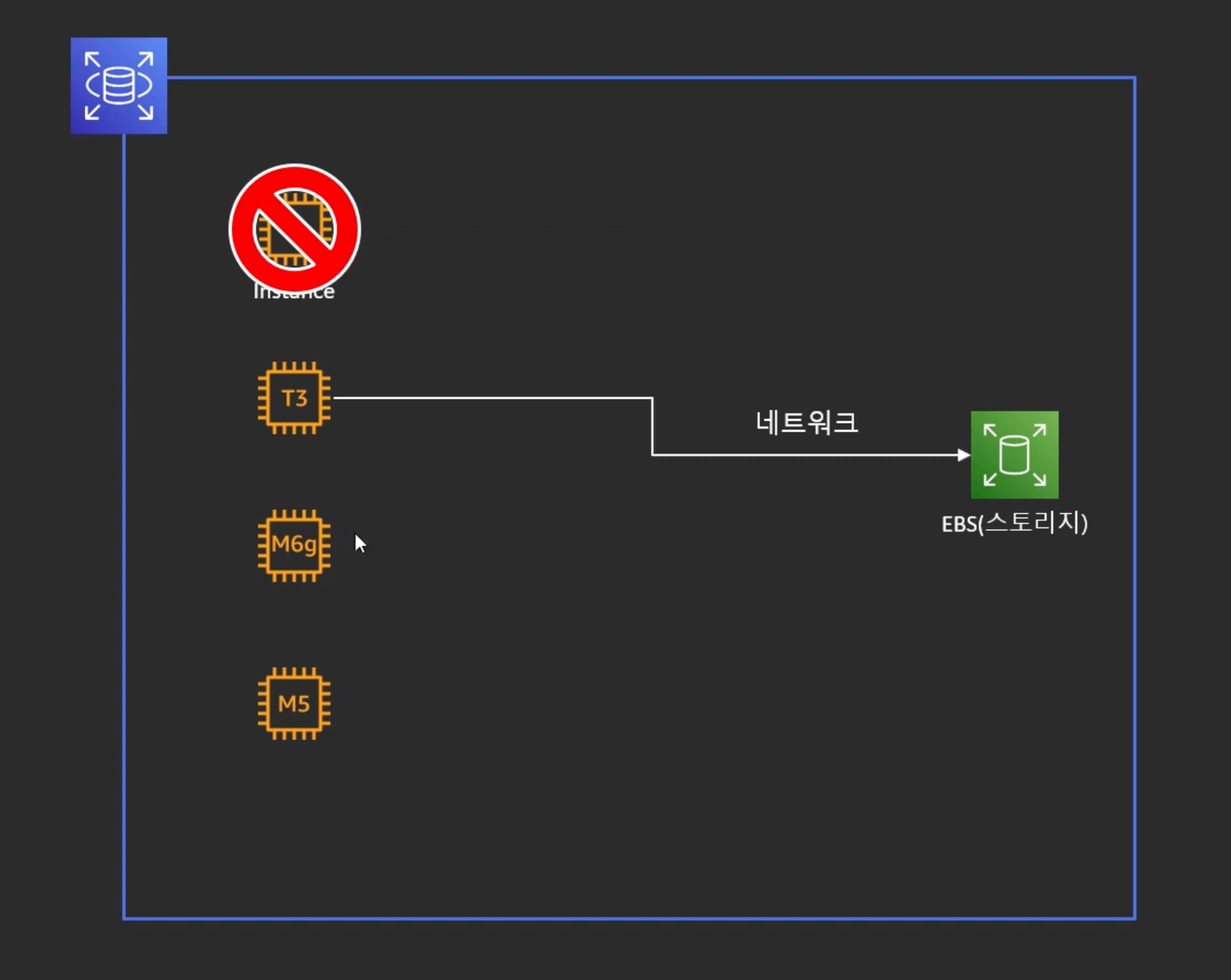
- 스토리지와 컴퓨팅을 분리
- 인스턴스와 EBS가 네트워크로 분리 되어있다.
- 인스턴스가 Fail이 나면 다른 인스턴스로 바꾸기만 하면 됨
- 인스턴스를 업그레이드 하고싶을 때도 네트워크만 바꾸기만 하면 됨
- 인스턴스가 Fail이 났을 때는 다른 인스턴스로 교체하면 되지만 스토리지가 Fail이 났을 때는 어떻게 할 것인가?
- 스토리지가 Fail이 났을 때 데이터를 어떻게 안전하게 보관하고 복구하느냐?
--> RDS에서는 스토리지에 동기 or 비동기로 복제를 함
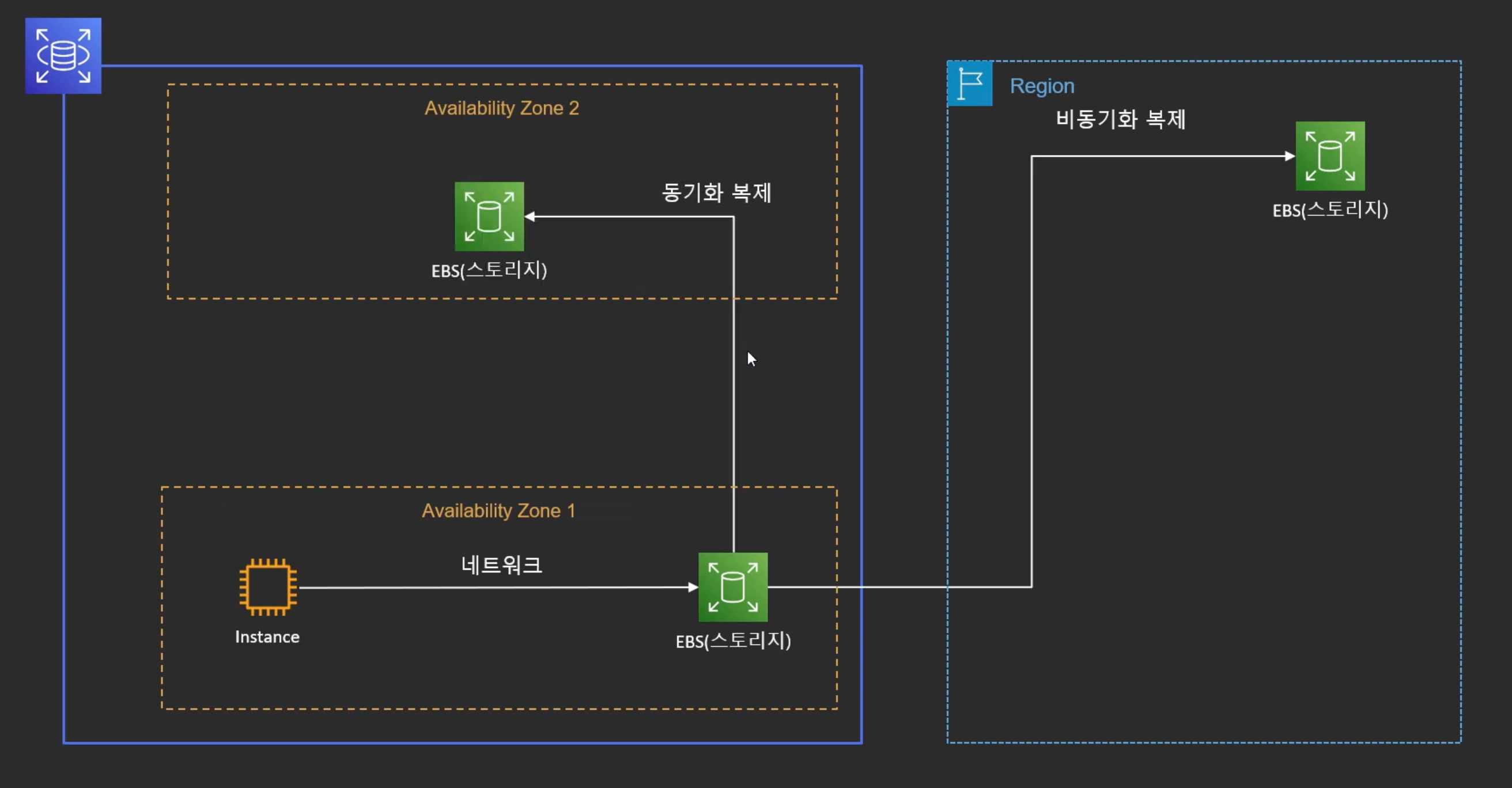
- 다른 리전으로 비동기 복제가 가능
- 같은 리전으로 동기 복제가 가능
동기 복제의 문제점
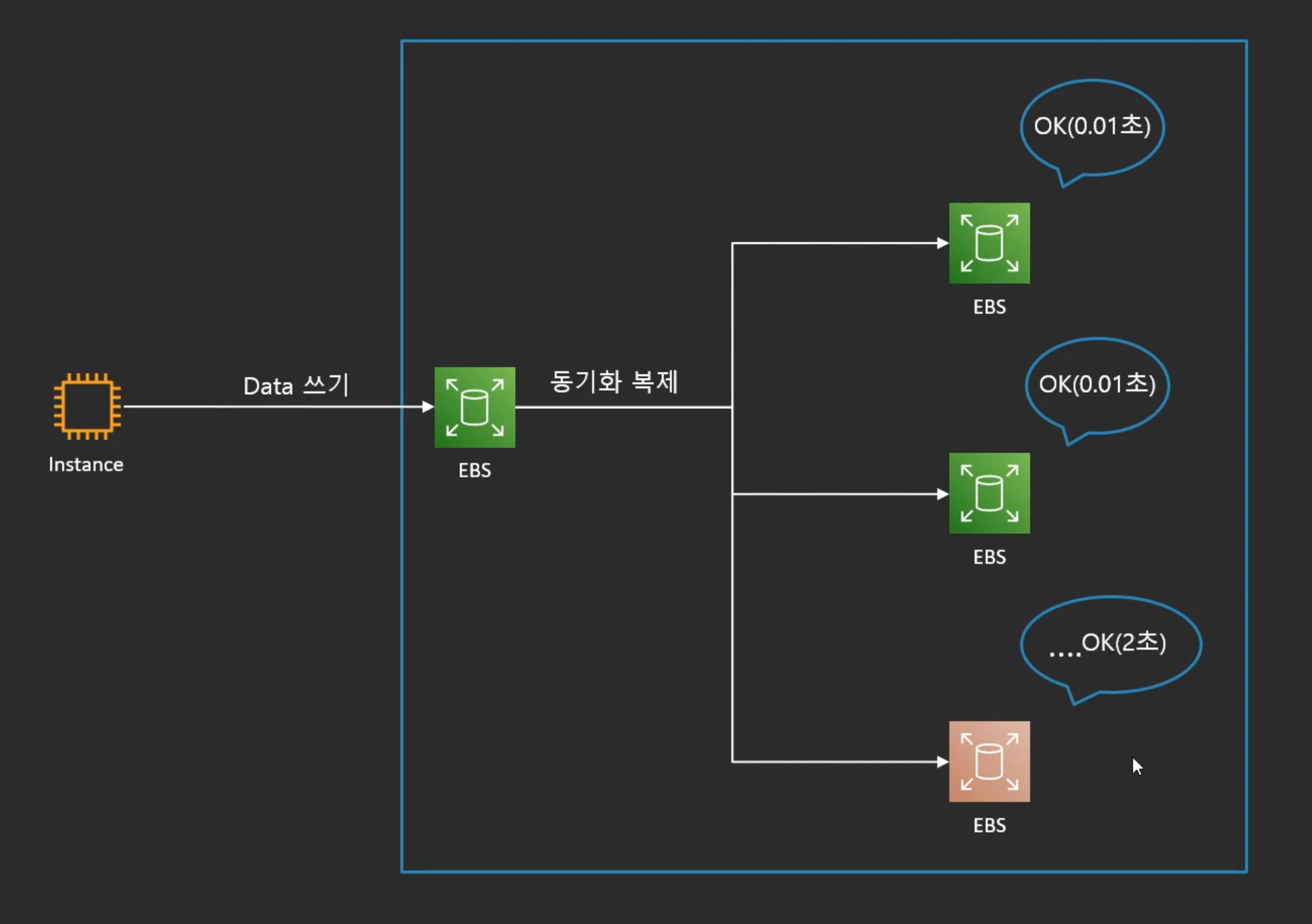
- 동기복제를 여러 스토리지에 할 때, 전체 타임은 모든 노드에서 데이터가 저장이 되고 OK가 떨어져야 데이터가 안전하게 저장되었다는 것을 선언할 수O
- 많은 노드에서 시간이 아무리 짧게 걸려도 가장 오래 걸리는 노드에 영향을 받는다.
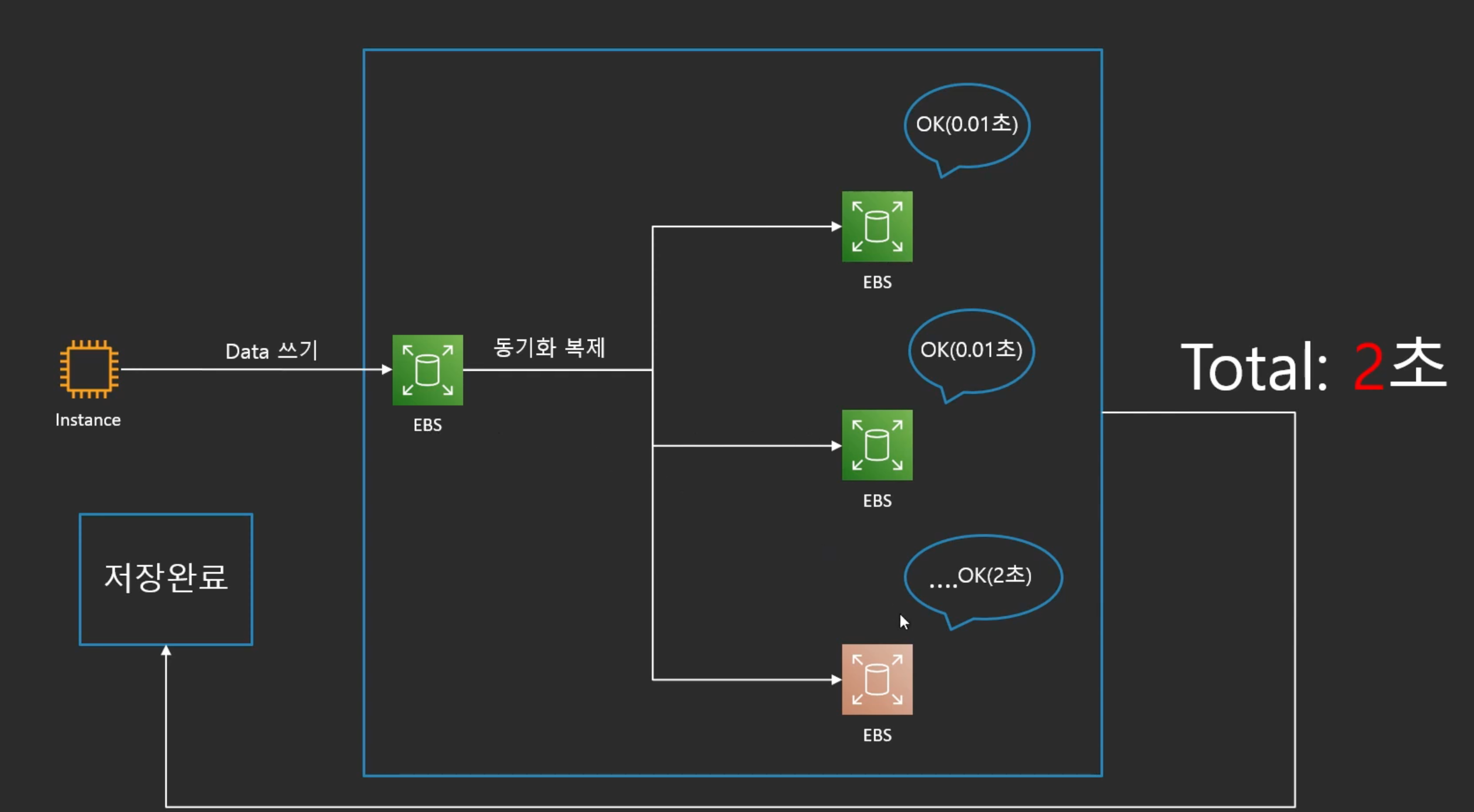
- 다른 노드들이 모두 0.1초만에 처리를 했더라도 마지막 노드가 2초가 걸렸으면 데이터가 안전하게 저장이 된 전체 시간은 2초가 된다.
비동기 복제의 문제점
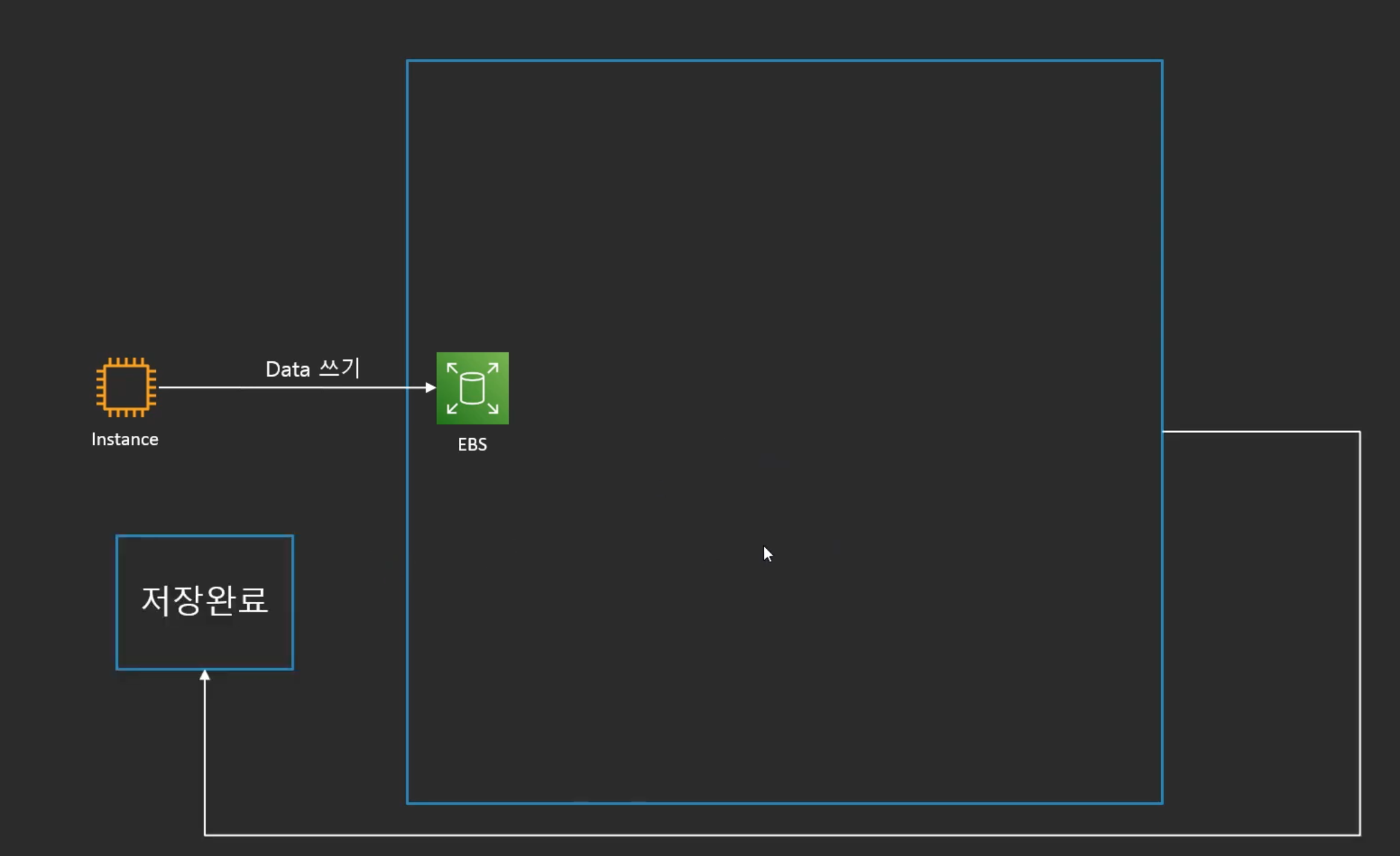
- 일단은 저장완료라고 선언을 한 후, 비동기로 복제
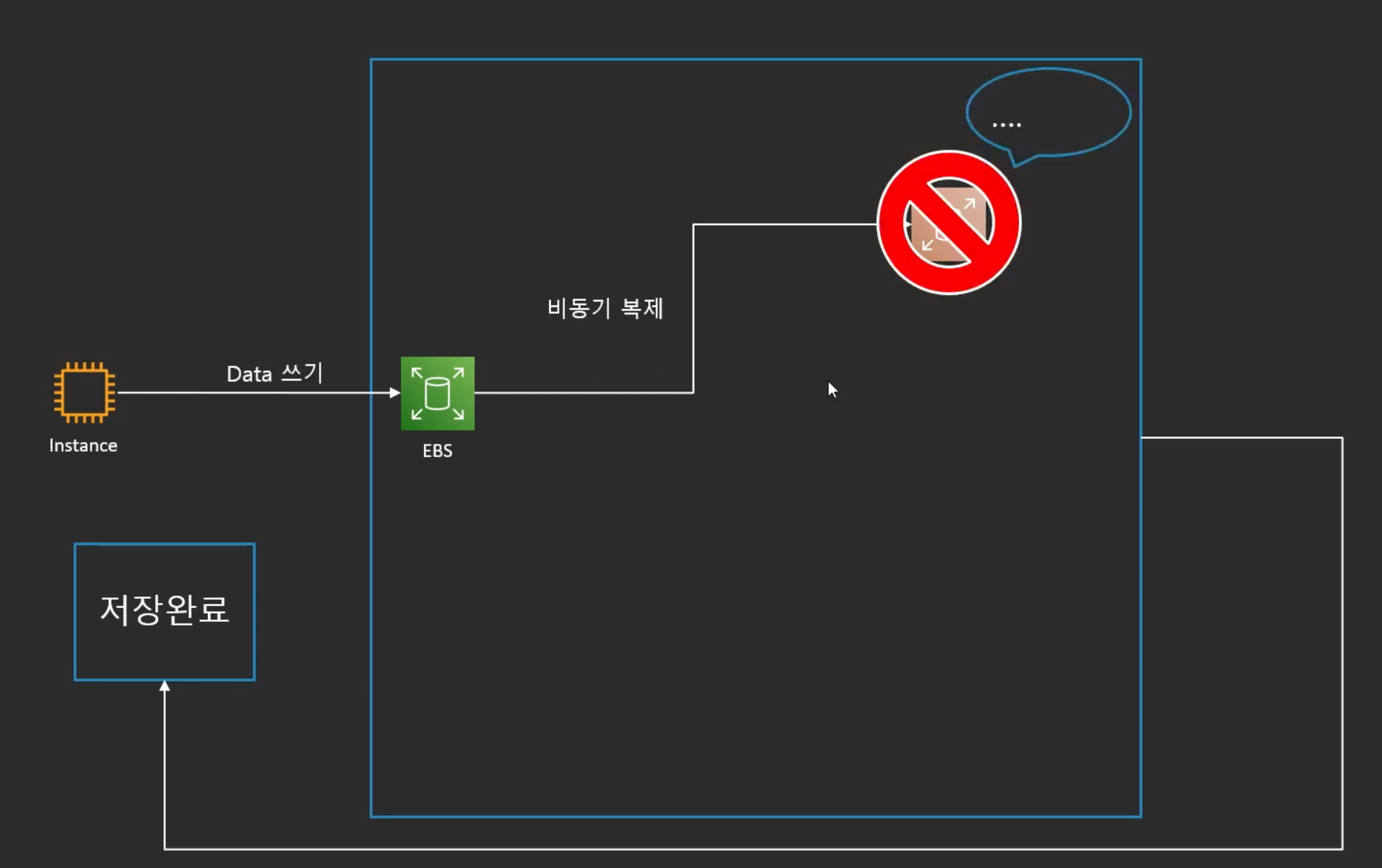
- 저장을 하다가 Fail이 나게 되면 데이터가 안전하게 저장이 안됨
복제 복구 문제
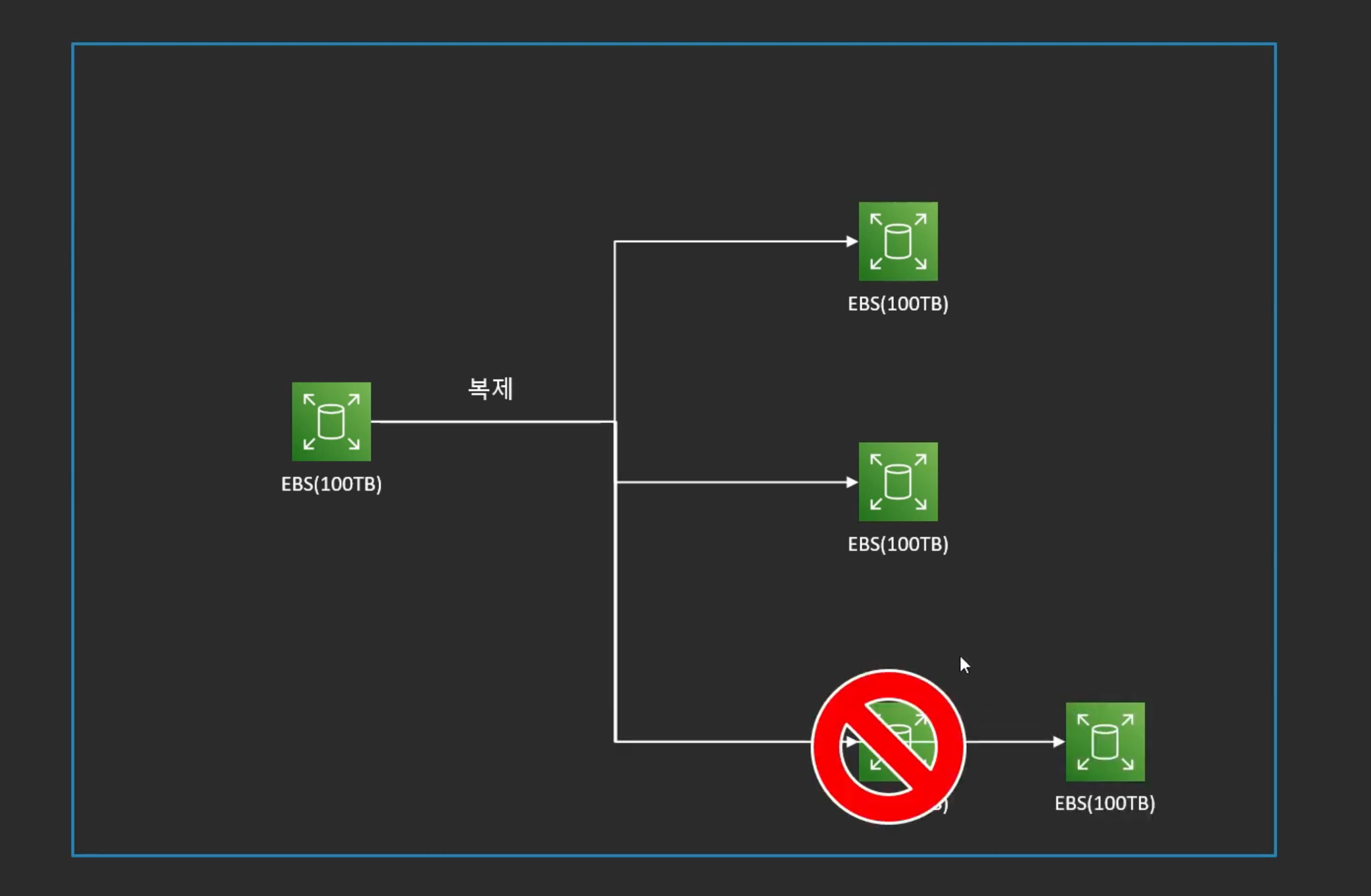
- 여러가지 복제본들 중에 하나가 Fail이 되었을 때 다른 복제본을 다시 만들어야 함
- 용량이 100TB 처럼 크다면 다시 만드는 게 오래걸려서 동기화가 지연이 됨
Quorum Model
"읽기 혹은 쓰기를 분산노드 중 일부분에서만 수행 하는 것"
--> Quorum: 분산 시스템에서 트랜잭션을 수행하기 위해서 각 분산노드로부터 확보해야하는 최소한의 투표 수
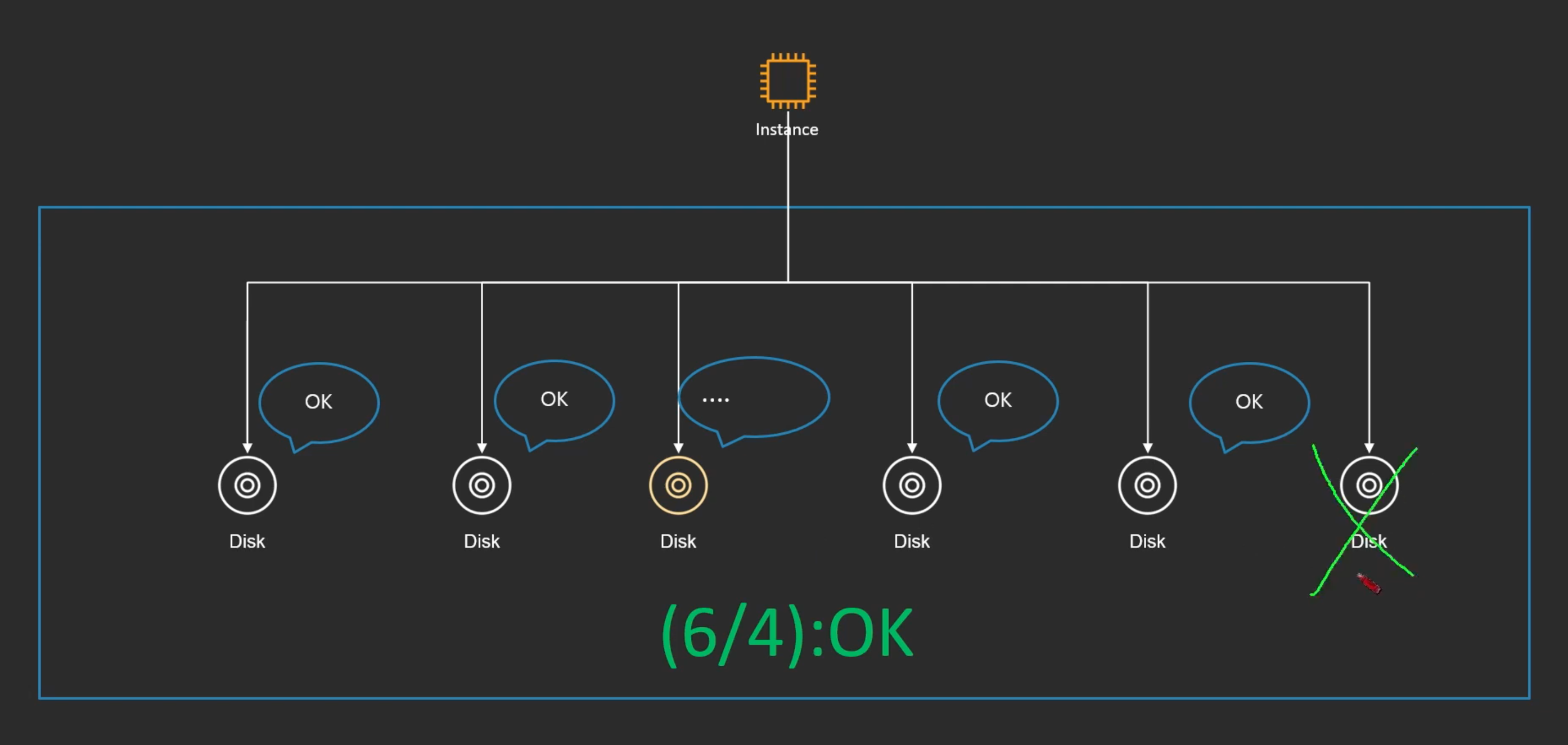
- 인스턴스와 스토리지 레이어가 있는데 스토리지는 분산되어있다.
- 이때 Write가 발생 했을 때, 이중에 지정된 숫자 이상이 OK 되었을 때 그 순간 데이터가 안전하게 저장되었음을 선언 함
- 노드가 장애가 났거나 Fail이 났어도 지정된 숫자 이상만 OK가 되면 됨
- 장애가 나거나 Fail이 난 노드는 나중에 복구를 하면 됨
(1) 읽기 쿼럼과 쓰기 쿼럼은 적어도 하나 이상의 노드가 겹쳐야 함
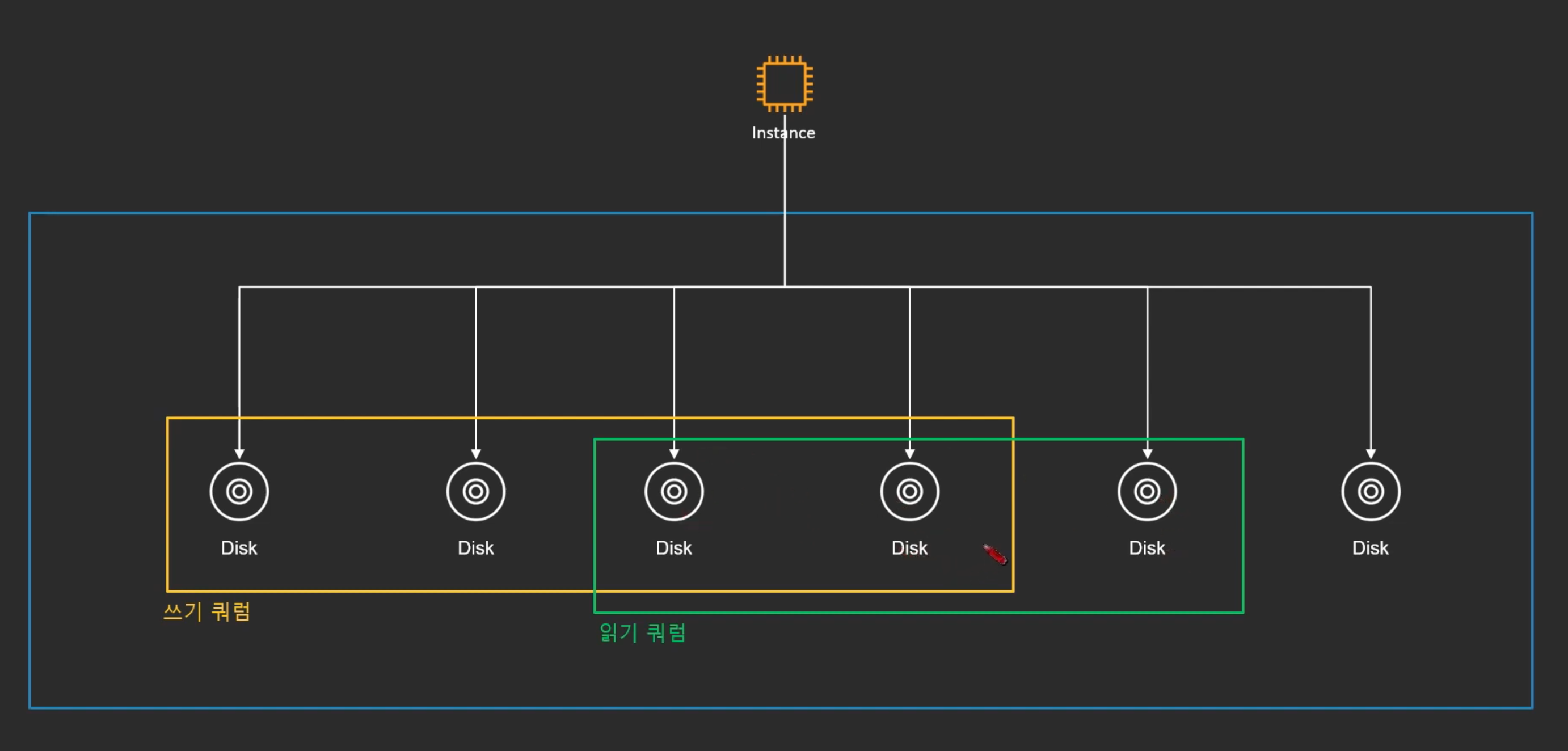
- 읽기와 쓰기가 동시에 벌어지면, 겹쳐져 있는 노드에서는 한가지는 Fail이 남
- 겹쳐지는 노드가 없다면 최신 데이터가 반영되지 않음
(2) 쓰기를 완료하려면, 이번에 사용할 쓰기 쿼럼과 이전에 쓰기를 완료한 쓰기 쿼럼이 겹쳐야 함
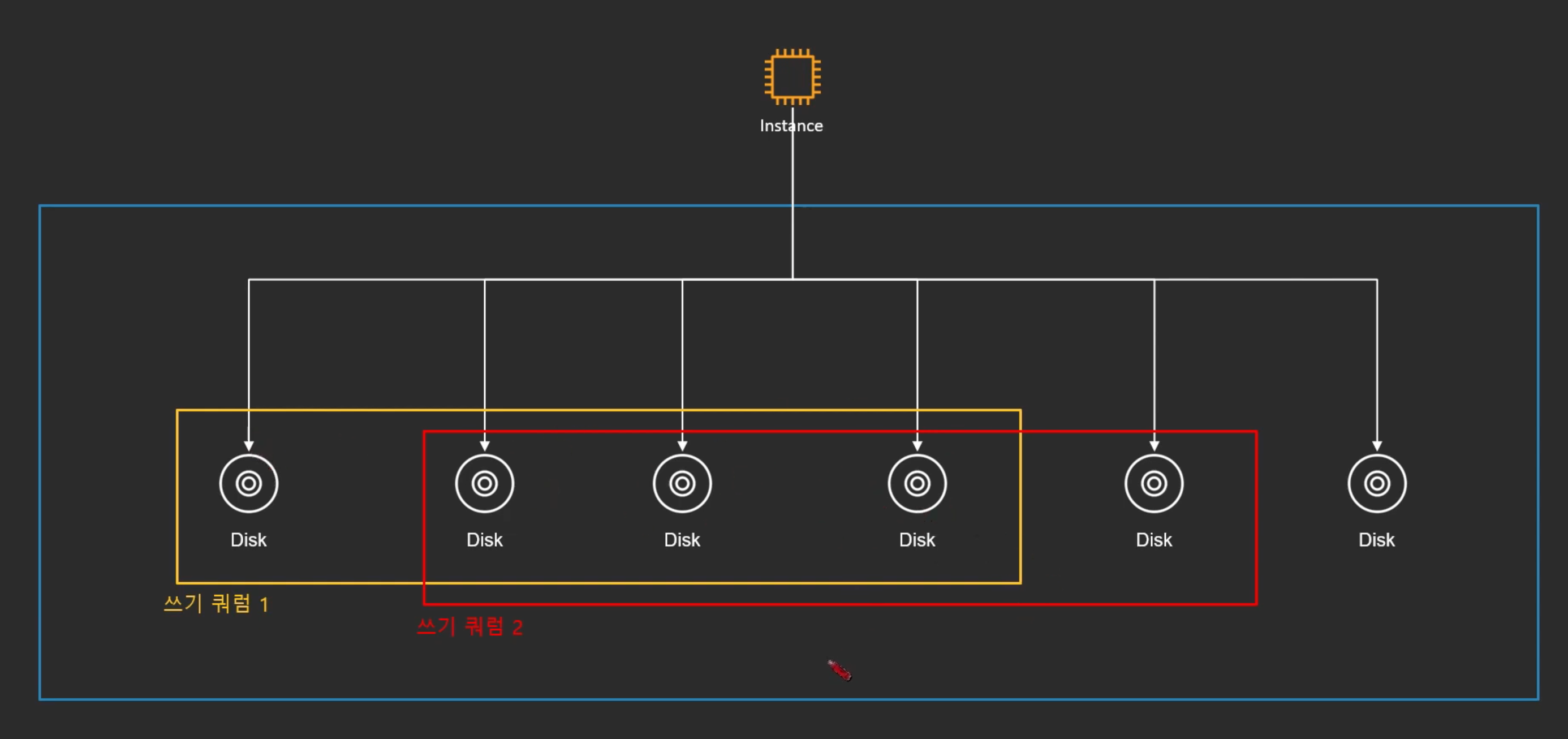
- 이전에 쓰기가 어떻게 이루어졌는지 알고있는 노드는 필요함
- 확보하기 위해서는 쓰기쿼럼의 필요 수 자체를 전체 이상의 과반수 초과로 만들면 됨
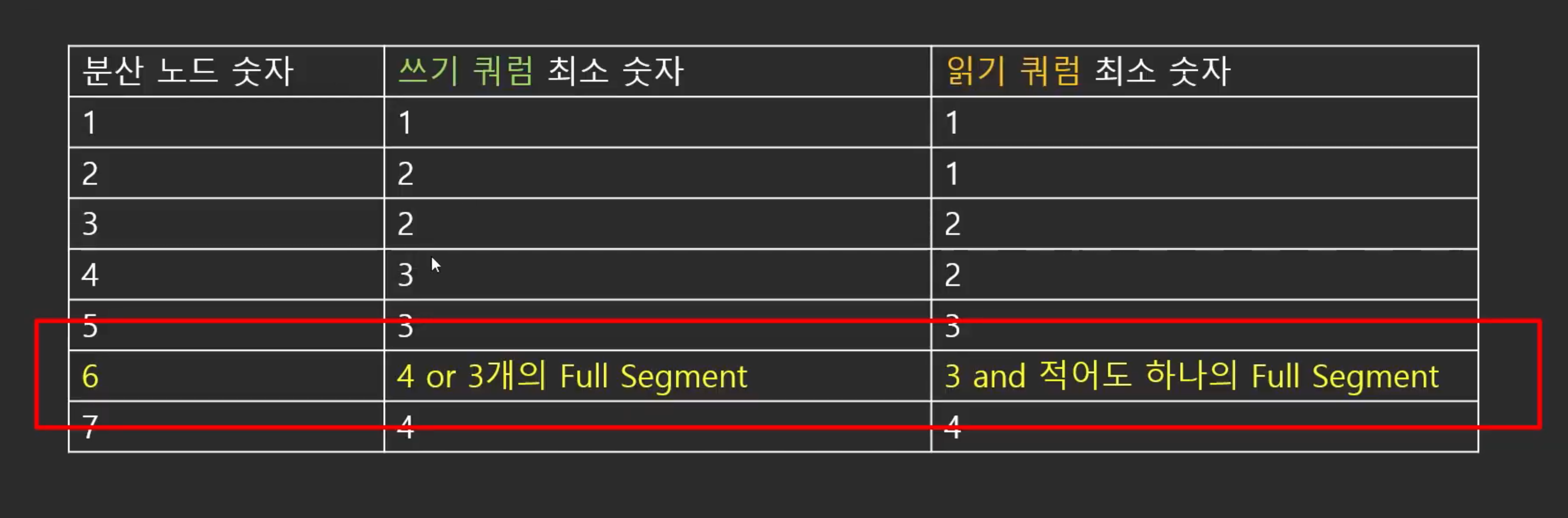
(3) 쿼럼 최소 숫자
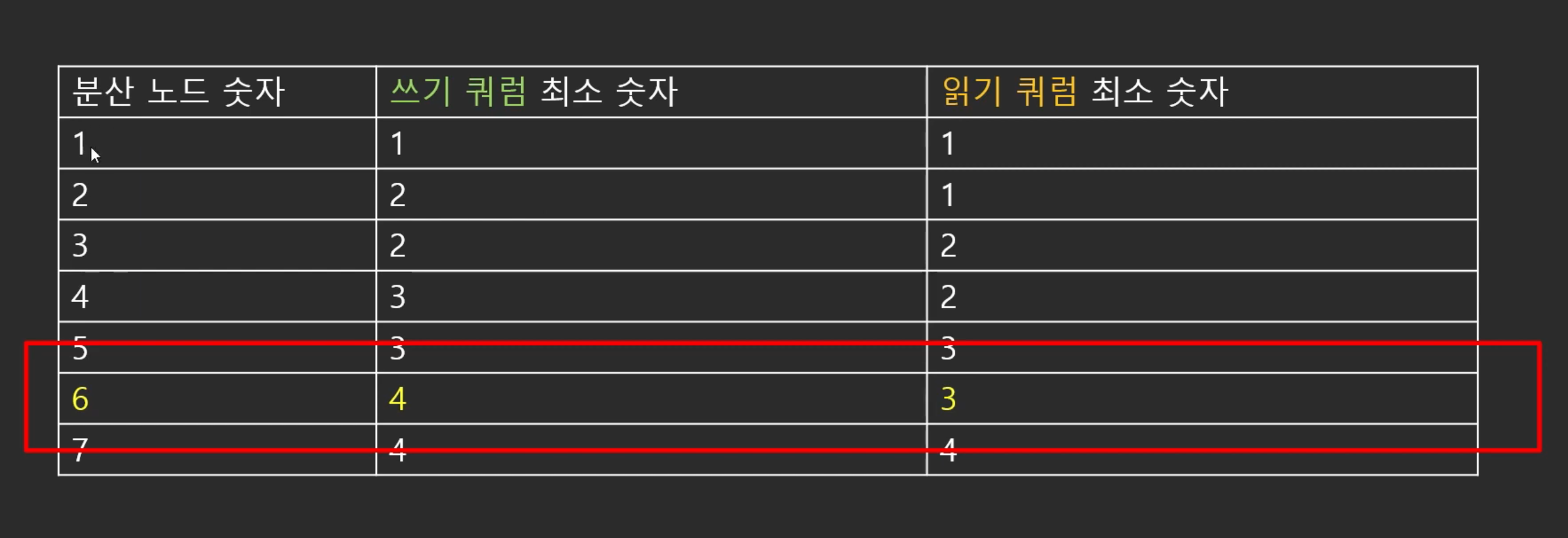
분산노드가 6개인 이유
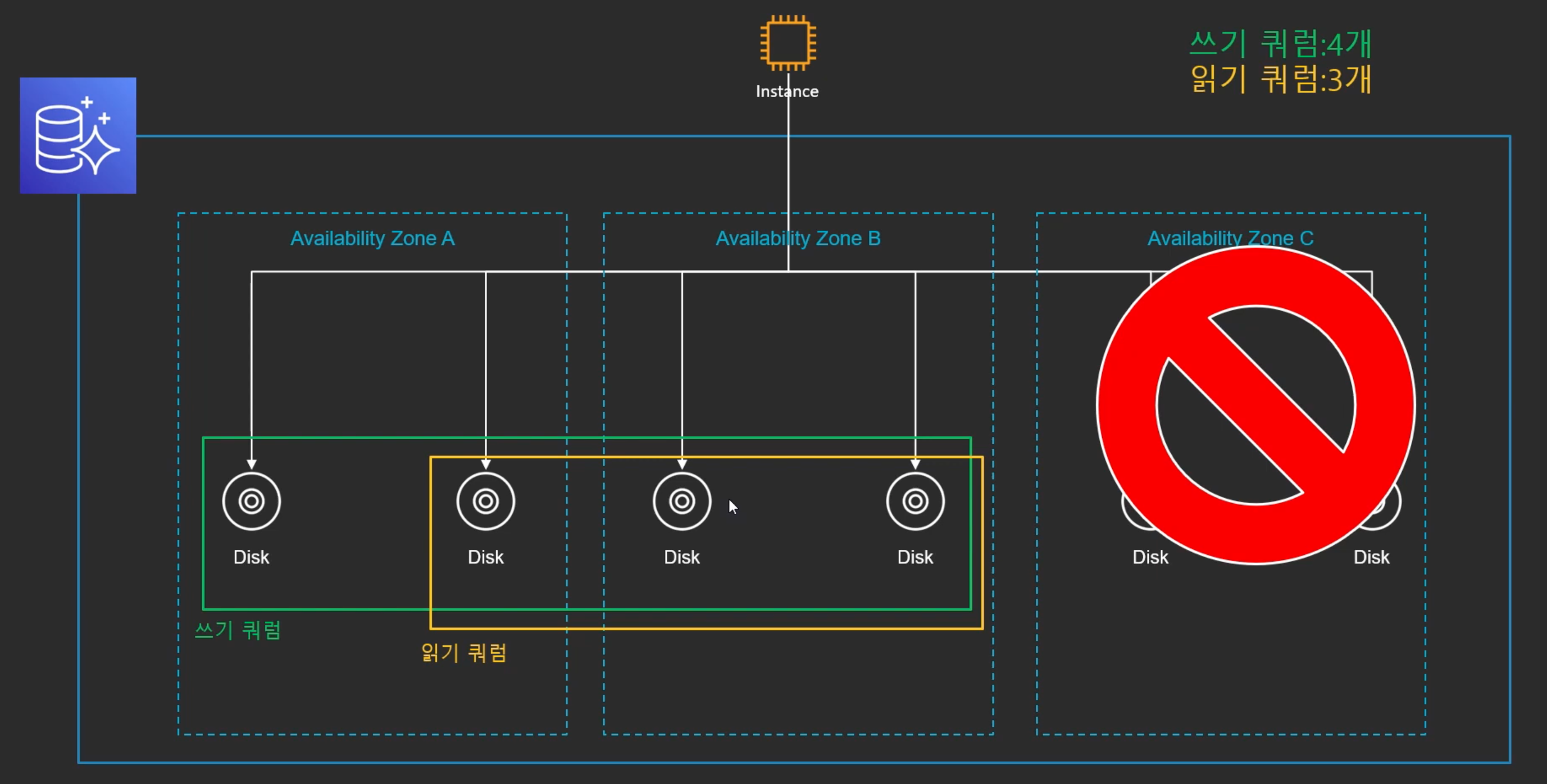
- 만약 어떤이유에서 AZ가 Fail이 되었다 해도 쓰기 쿼럼 4개가 확보 되고, 읽기 쿼럼도 3개가 확보 되기 때문에 Aurora의 데이터를 쓸 수 있다.
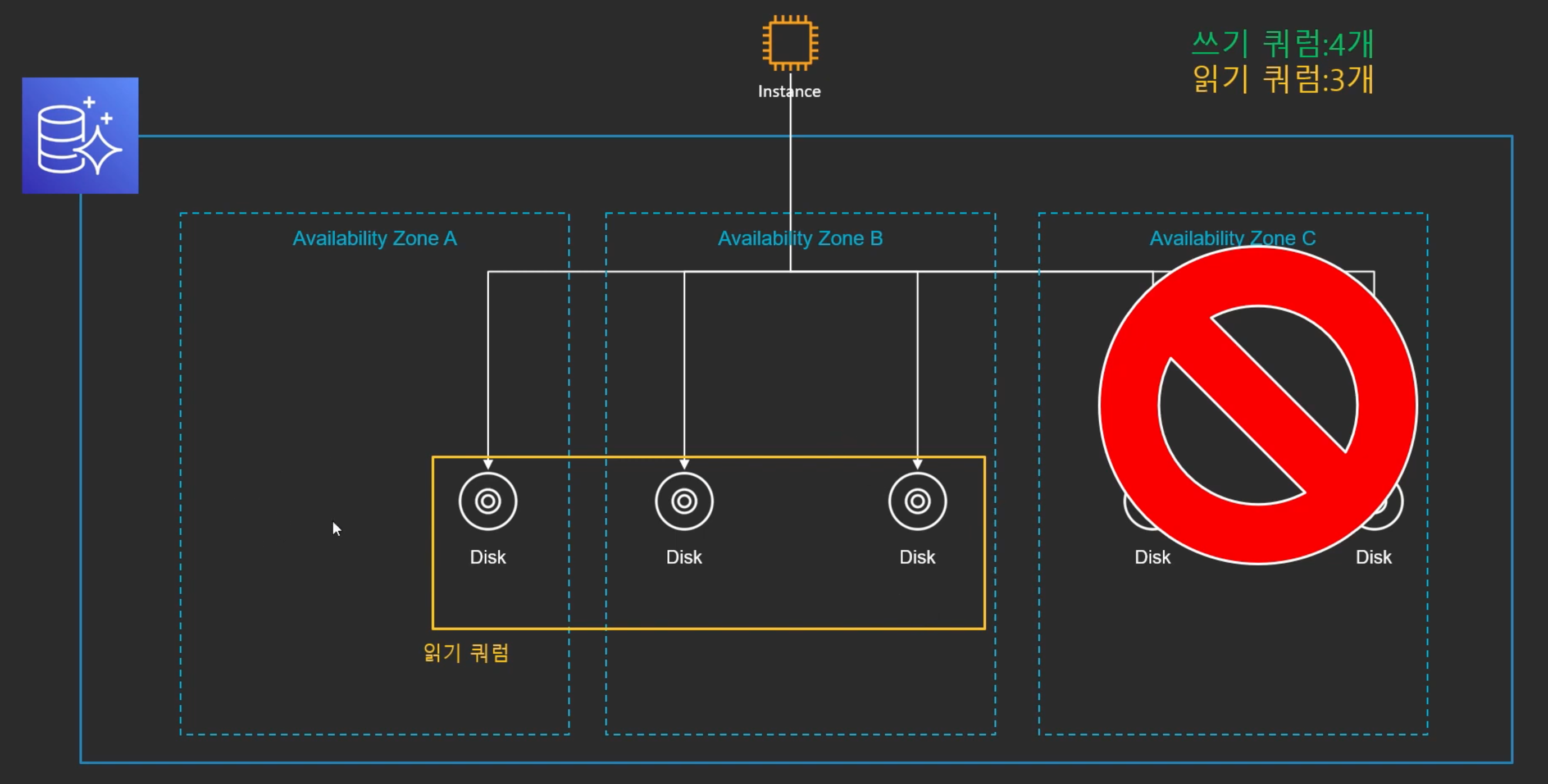
- AZ가 Fail이 된 상태에서 노드 하나가 날라을 때에도 읽기 쿼럼 3개는 확보 됨
--> 완전무결한 데이터를 가지고 있고 추후 복구과정을 통해 다른 노드들로 분산시킬 수O
결국 6개의 분산노드면 괜찮을까?
"실패하는 것보다 복구를 더 빨리하면 된다."
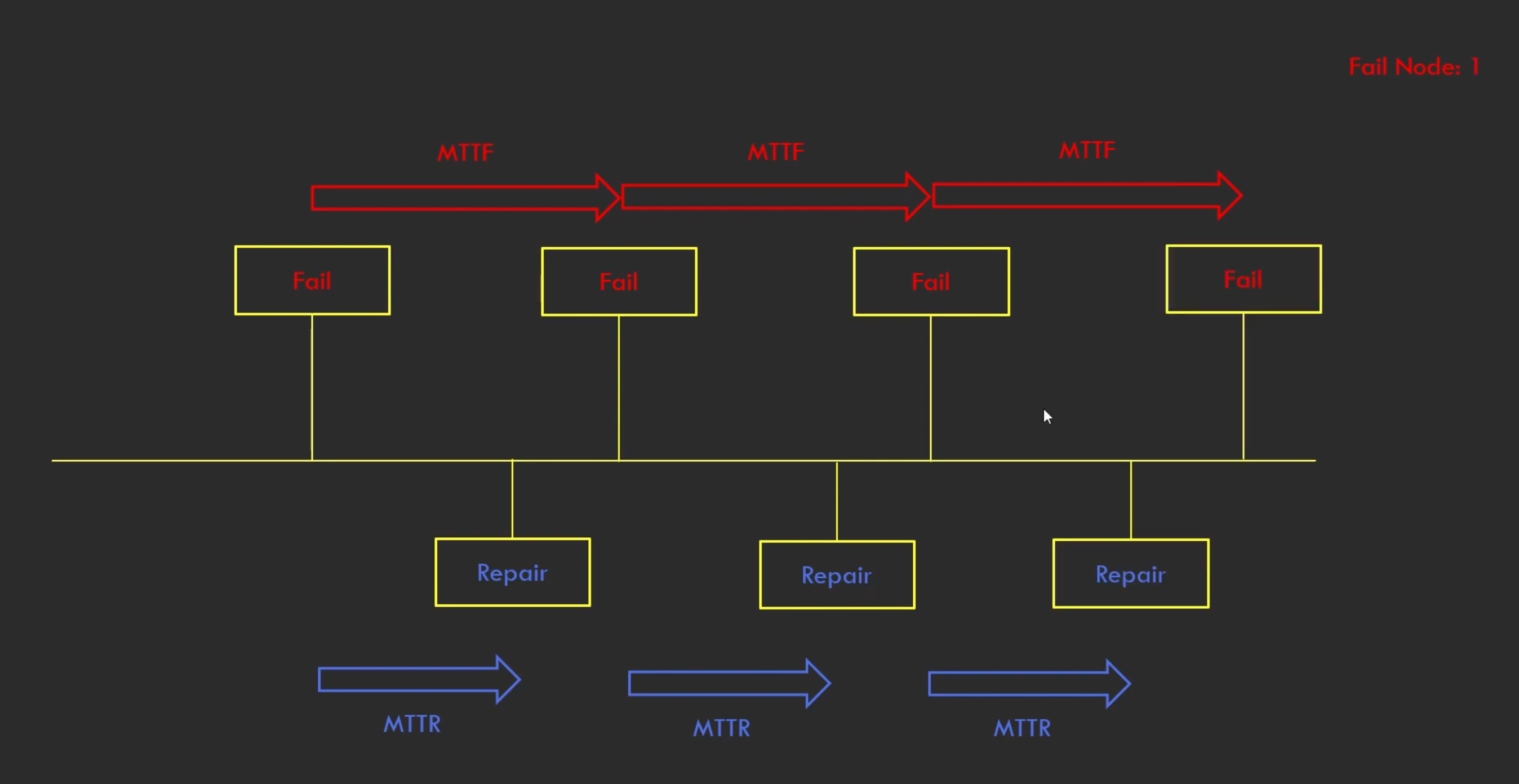
- Mean Time To Failure(MTTF): 실패까지 걸리는 시간
- Mean Time To Repair(MTTR): 복구까지 걸리는 시간
Aurora의 데이터 저장단위
복구를 빨리하기 위해서 Aurora의 데이터 저장단위를 어떻게 만들었냐면
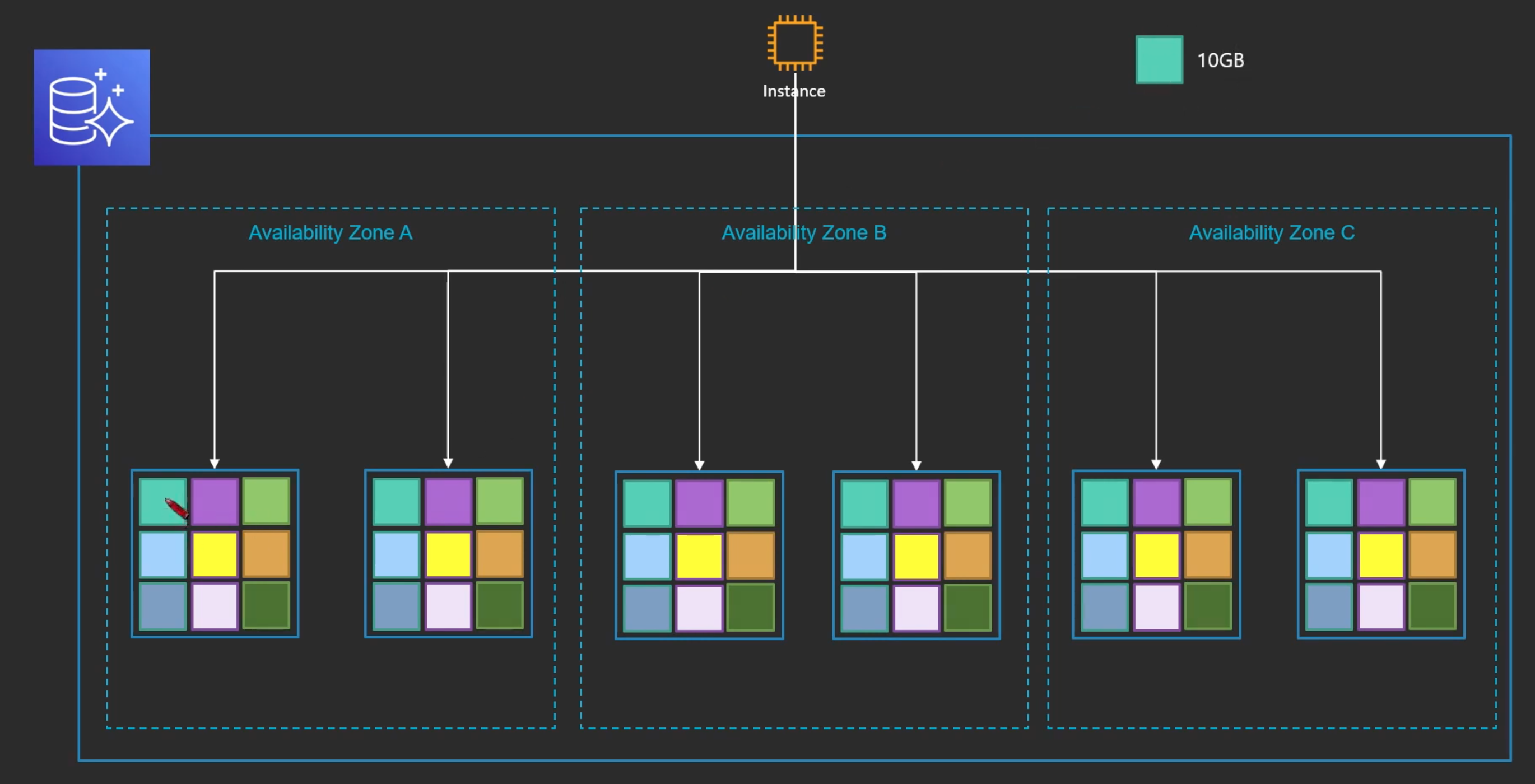
- 모든 데이터를 10GB 단위로 잘라서 보관을 함
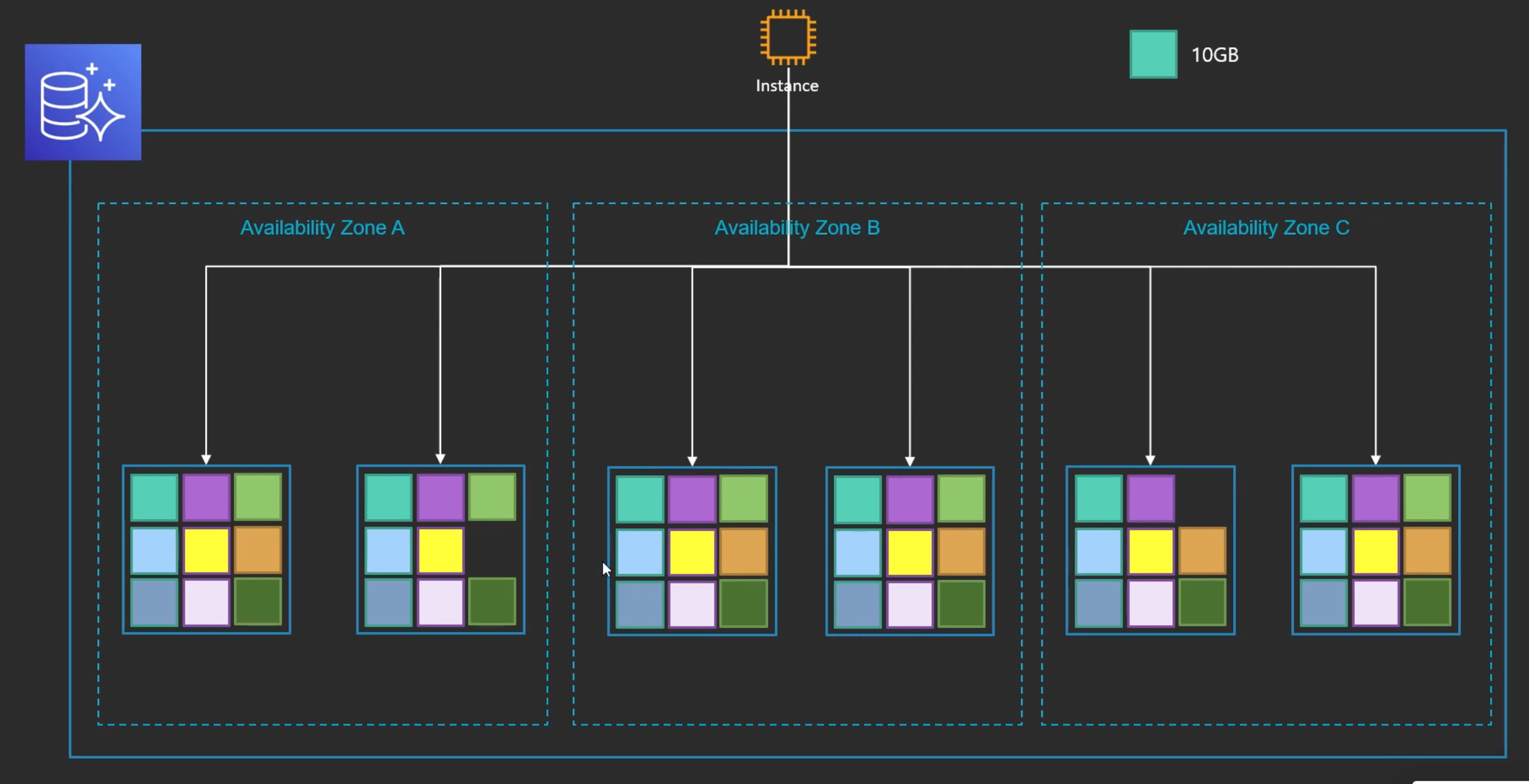
- 데이터가 하나라도 날아가면
--> 다른 곳에도 데이터를 가지고 있기 때문에 빨리 복구 할 수 있다.

- AWS에서는 복구 시간이 몇분 미만이라고 한다.
- AZ가 날아가고 노드가 날아가더라도 빨리 복구 할 수 있다.
- 그리고 빨리 복구되기 때문에 AZ가 날아가고 노드가 몇개씩 날아가는 상황은 거의 오지 않는다.
- 그리고 데이터가 무결한지, 데이터가 남아있는지 계속적으로 검사를 함
- 데이터에 오류가 생기면 자동으로 복구 진행을 함
노드를 여러개 쓰는것이, 하나 쓰는것 보다 느린것 아닐까?
알아보기 전에, 먼저 알아야 할 개념을 공부해보자
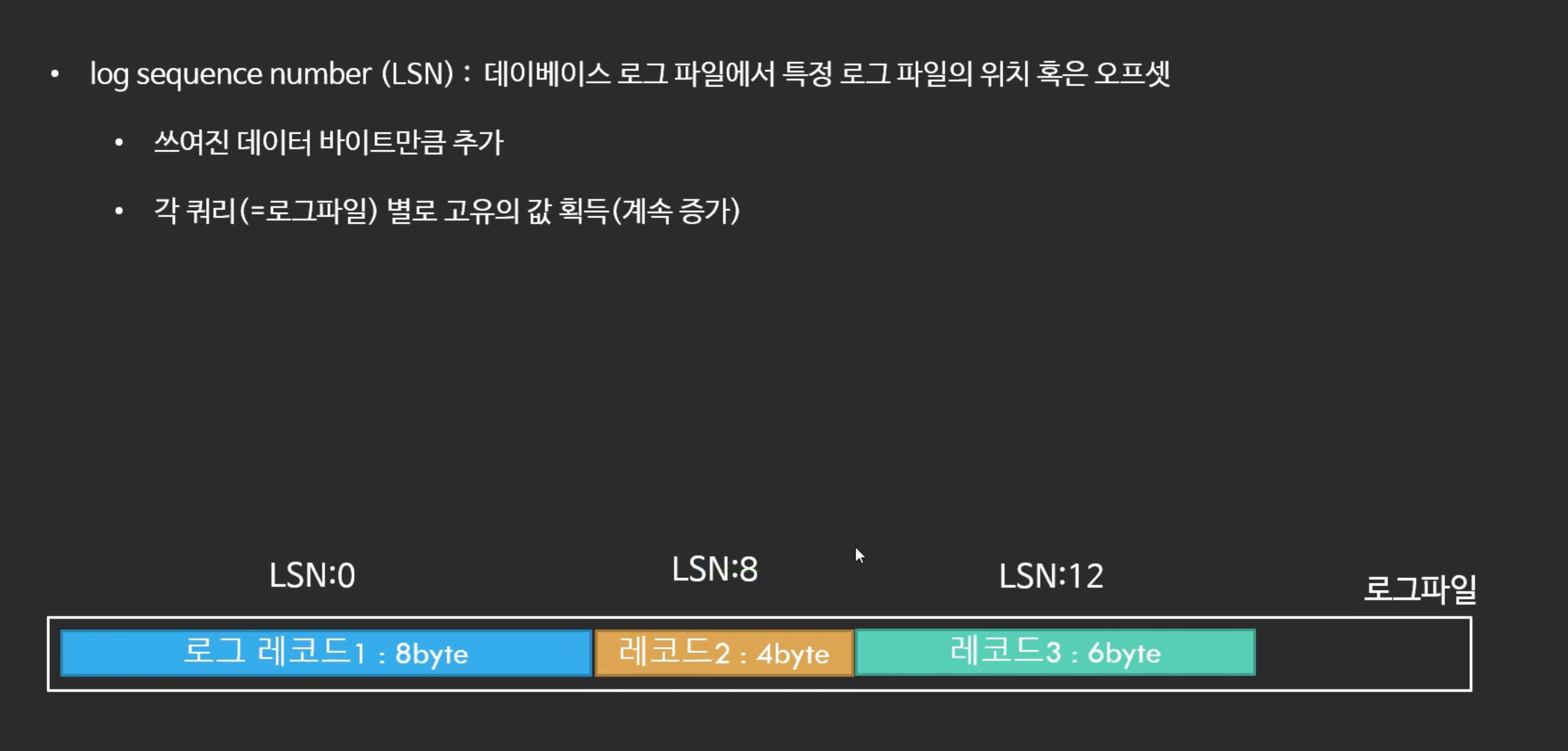
- 8byte짜리 쿼리를 Write 할 때 LSN은 0이다.
- 그 다음 쿼리는 4byte짜리 Write 쿼리고 LSN은 8이다.
- 그 다음은 6byte Read 쿼리고 LSN은 12이다.
- 이런식으로 쿼리를 수행할 때 로그파일이 생성되는데 로그파일의 위치가 LSN인데 계속 증가를 한다.
- 쿼리의 고유값 이라고 볼 수 있다.
- 해당 LSN의 쿼리가 처리 되려면 이전의 LSN에 해당하는 쿼리가 처리 되었어야 함
: 레코드 3이 실행 되려면 레코드1, 레코드2의 쿼리 모두 트랜잭션이 완료 되어야 함
페이지 업데이트
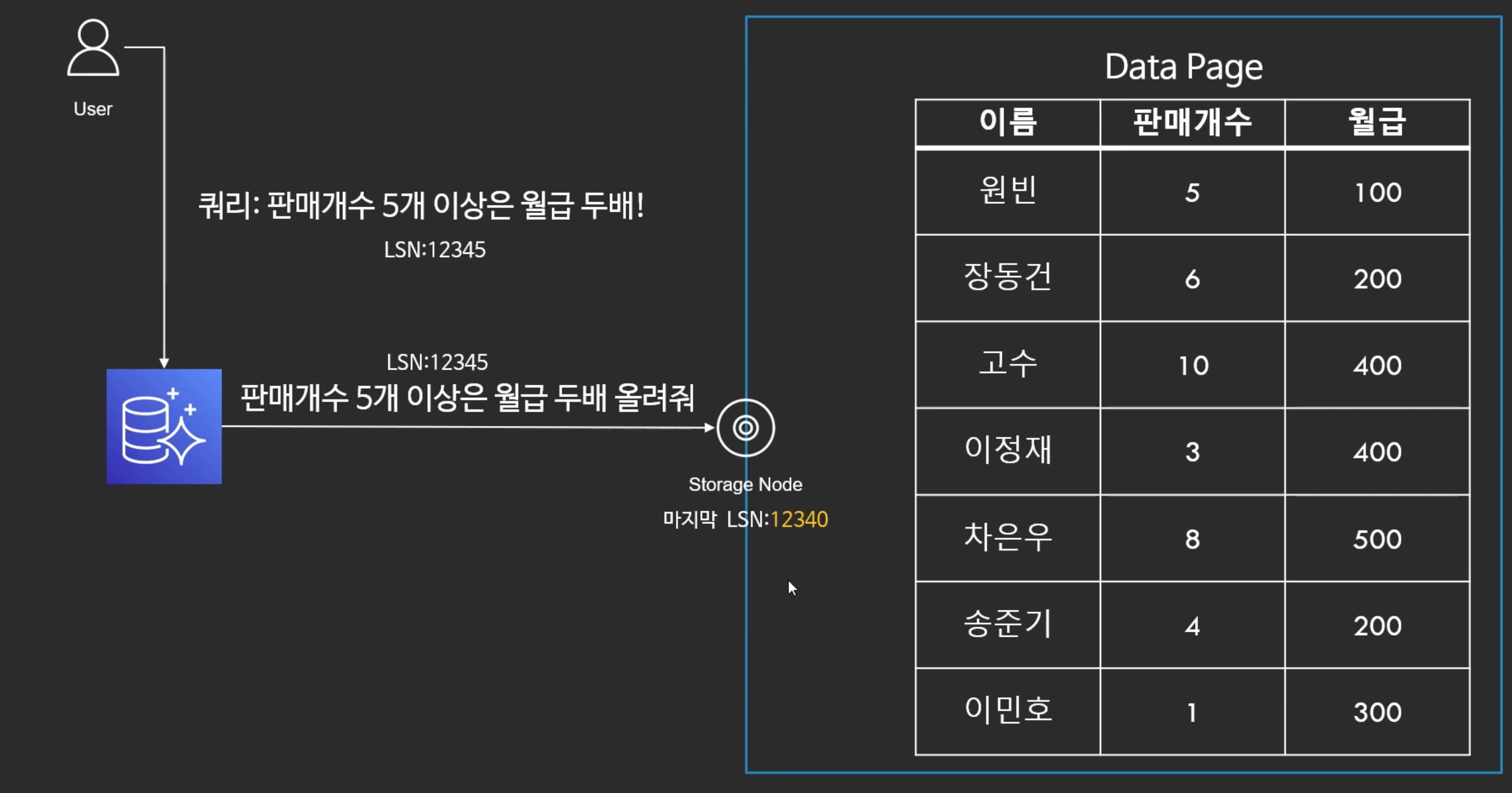
- 오로라에 판매개수 5개 이상은 월급 2배로 올리라는 쿼리를 보낸다.
- 오로라는 스토리지 노드에게 판매개수 5개 이상은 월급 2배로 올리라고 한다.
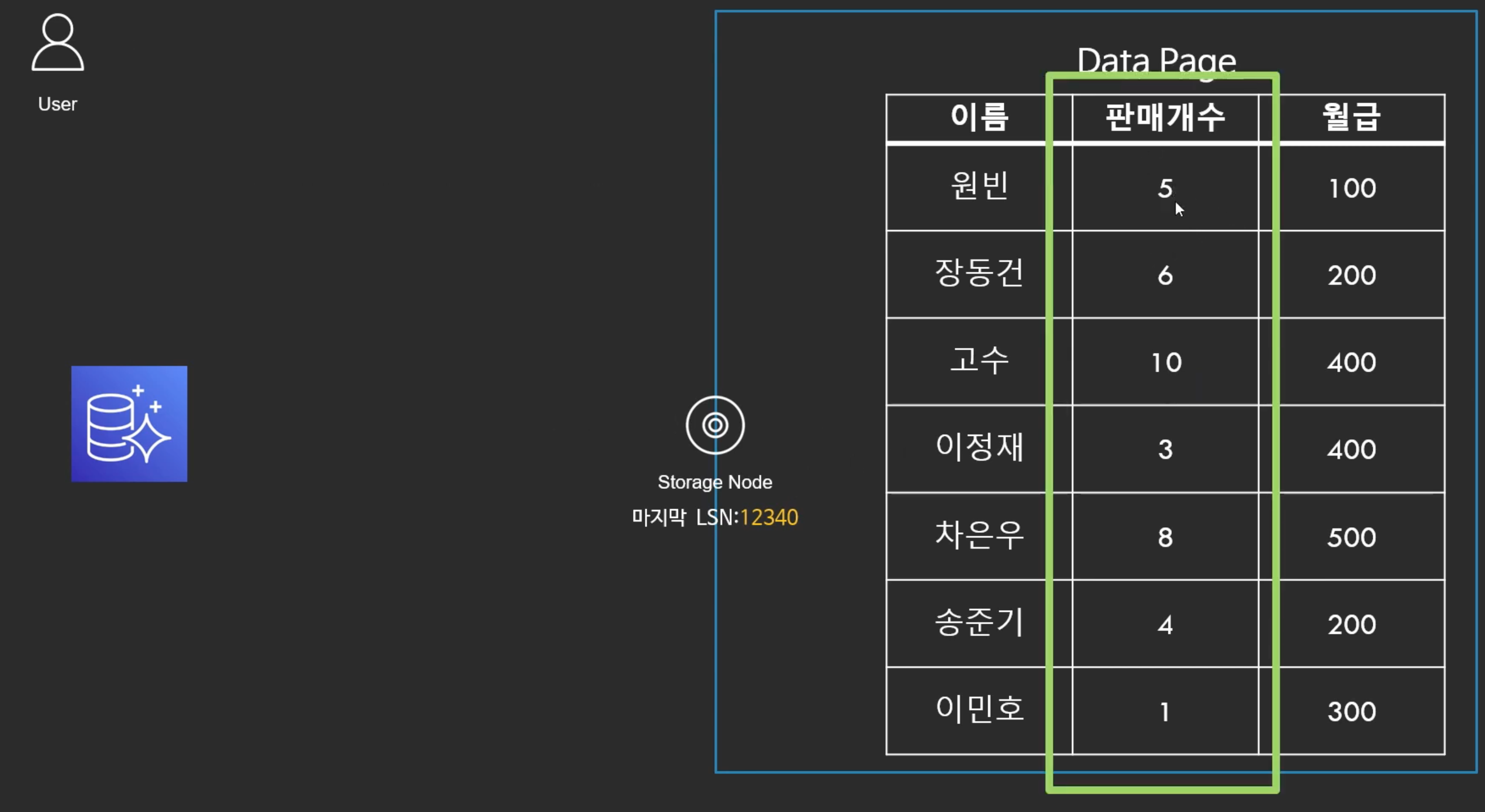
- 스토리지 노드는 받자마자 판매개수를 조회하고 월급을 2배로 올린다.
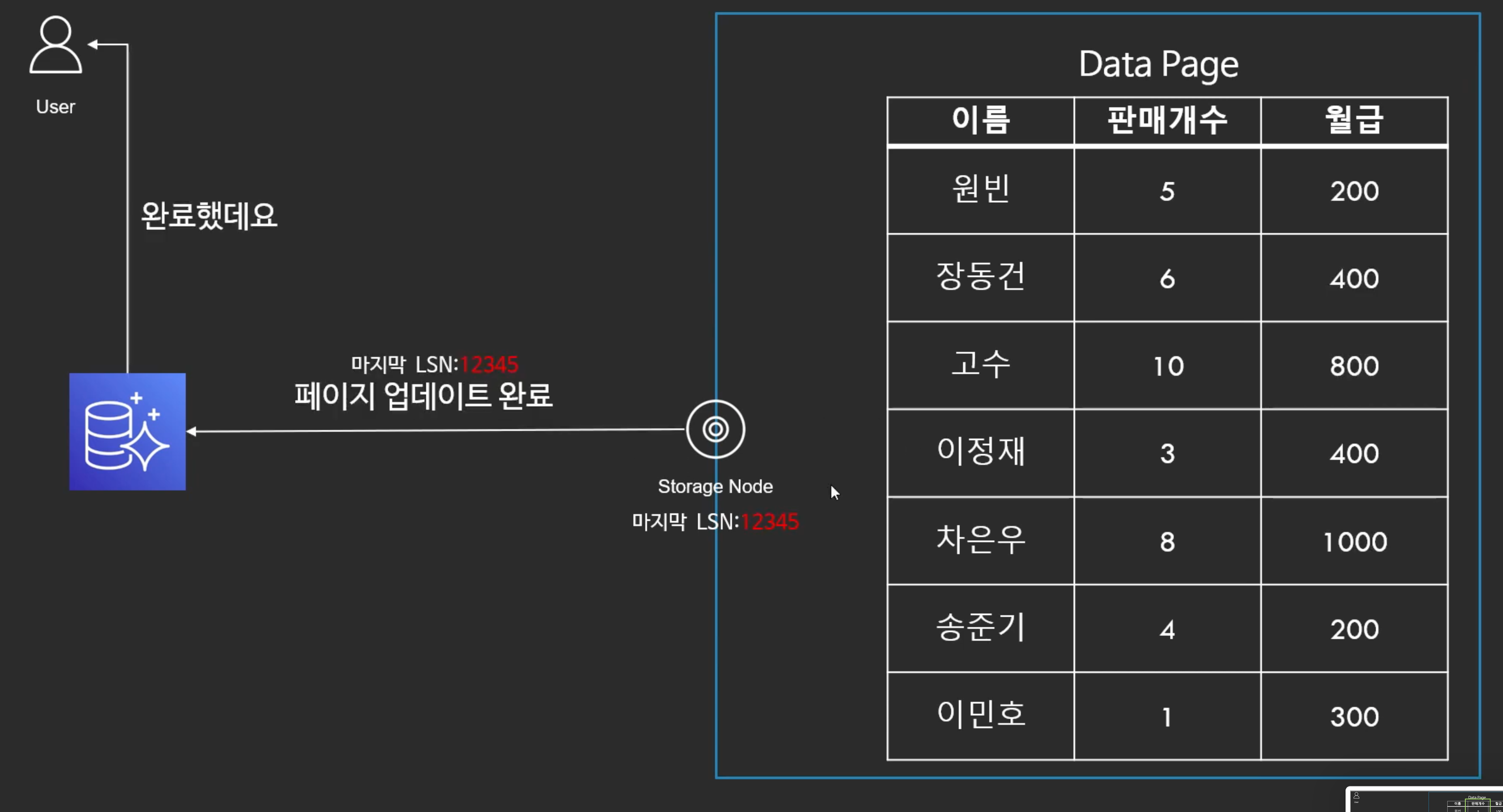
- 마지막 처리한 LSN을 12345로 업데이트 하고 오로라에게 보내줌
- 오로라는 유저에게 완료했다고 알려줌
로그파일 업데이트 (로그 레코드만 업데이트)

- 일종의 async와 비슷
- 로그 레코드를 스토리지 노드에 저장을 한ㄴ다.
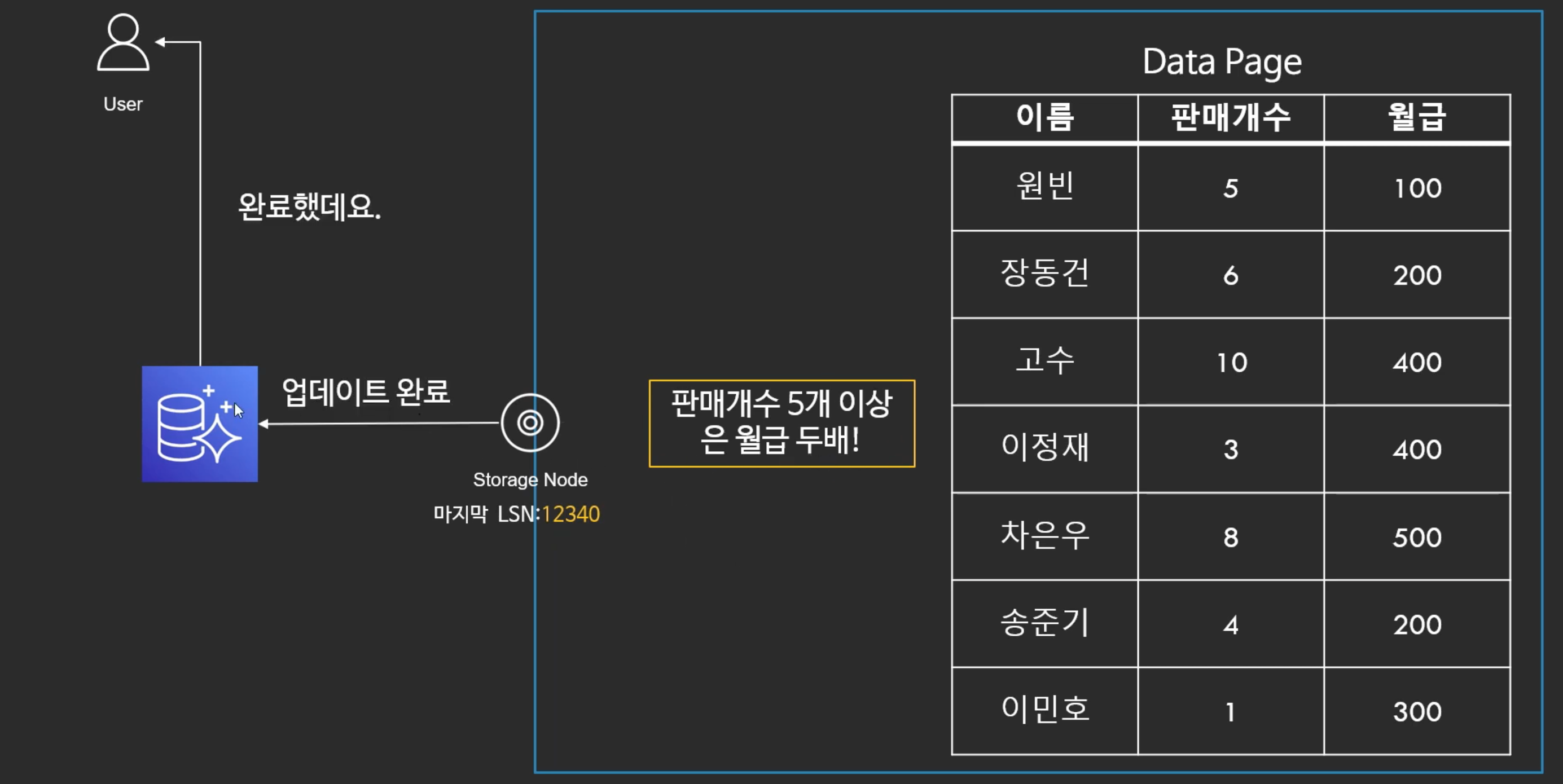
- 스토리지 노드는 로그 레코드만 받고 바로 업데이트가 되었다고 선언 한다.
- 시간 절약이 됨
- LSN은 나중에 업데이트 됨
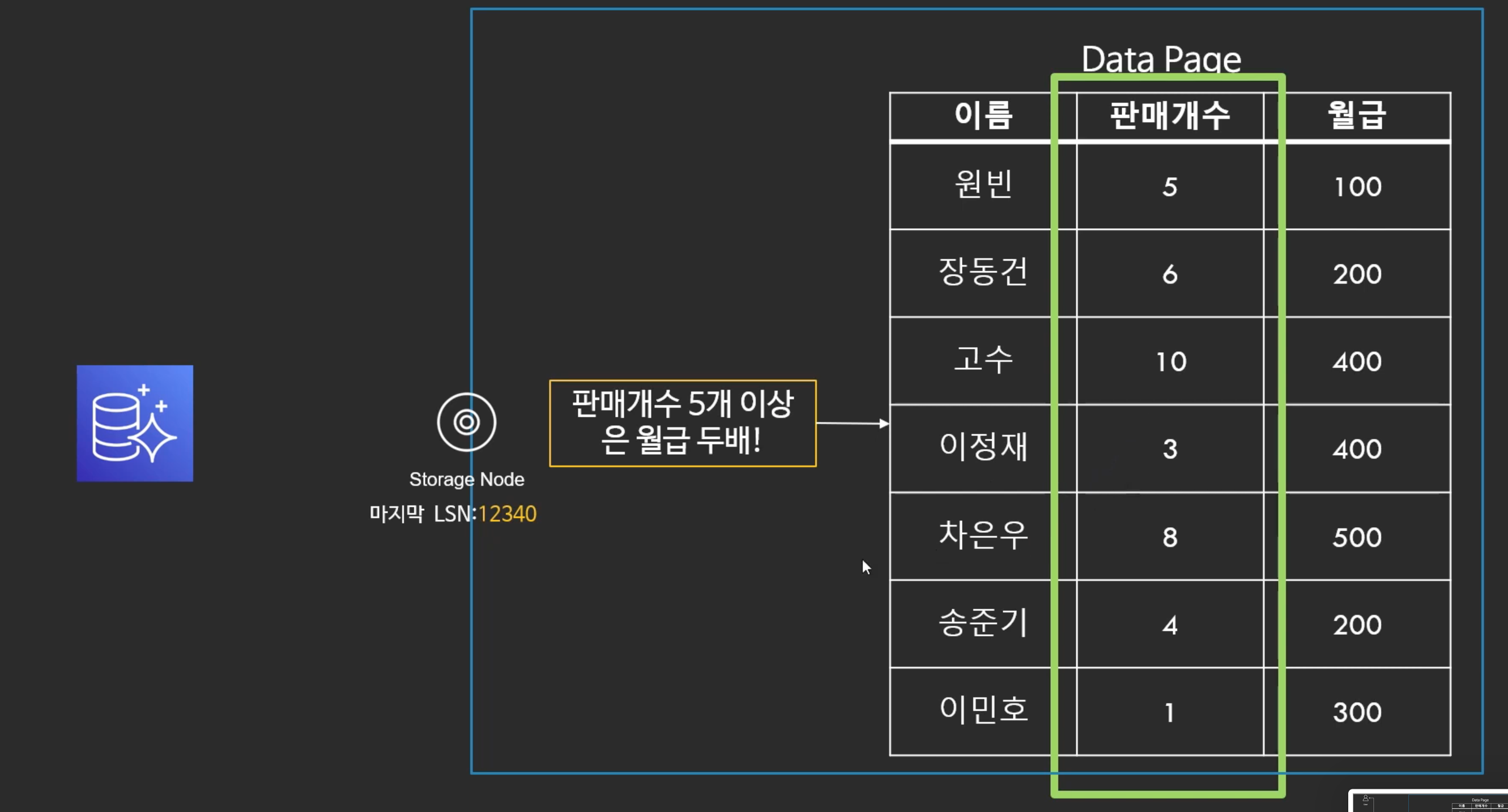
- 그리고 나서 내부적으로 로그 레코드의 내용을 Data Page에 업데이트 한다.
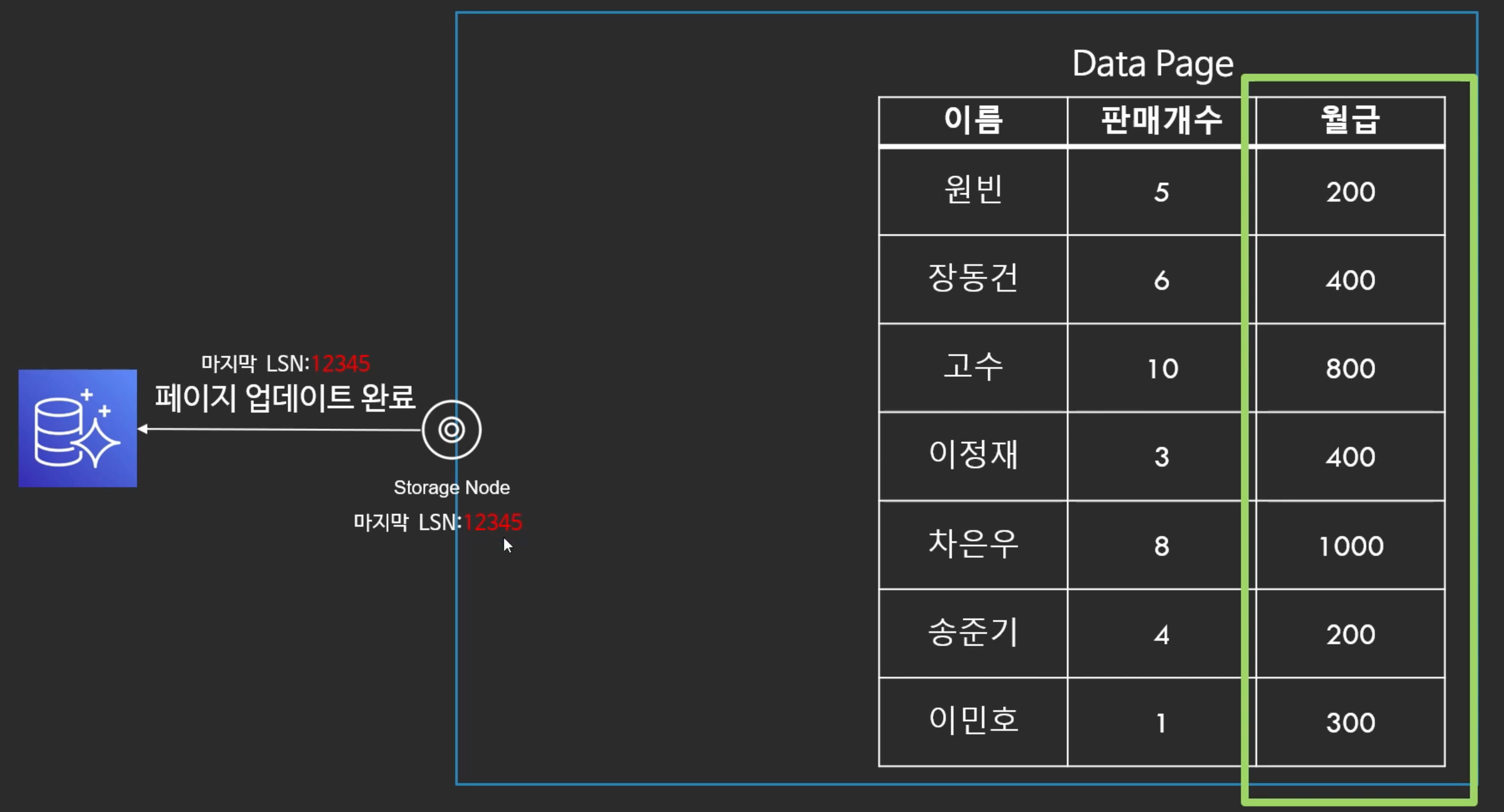
- 데이터를 업데이트 한 후, 로그 레코드에 해당하는 LSN을 업데이트 한다.
- 그리고 페이지 업데이트 완료 되었다고 알려준다.
--> 아마존 오로라에서는 Write에 관해서 로그 레코드만 업데이트 하는 방식으로 속도를 빠르게 처리한다.
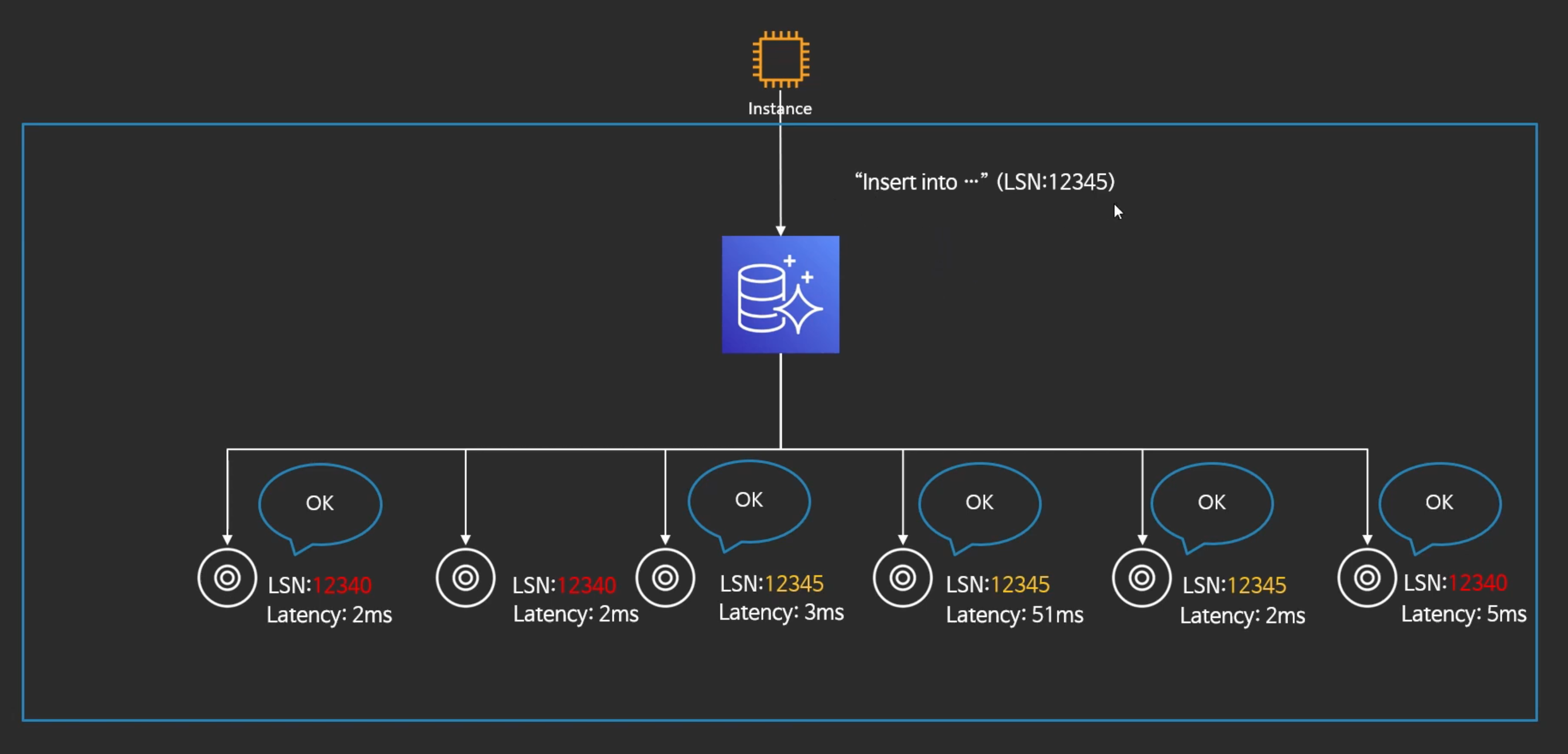
- INSERT를 할 때, 스토리지 노드들은 로그 레코드만 받고 OK를 날린다.
- 실제 페이지 업데이트는 내부적으로 async로 돌아간다.
- 페이지가 모두 업데이트 될때까지 기다리는 것이 아니라 로그 레코드만 업데이트 되면 바로 OK날리기 때문에 6개 모두 쓰지만 굉장히 빠르기 OK를 받는다.
- 단, LSN은 늦을 수 있다.
--> 아마존 오로라에서는 Read에 관해서
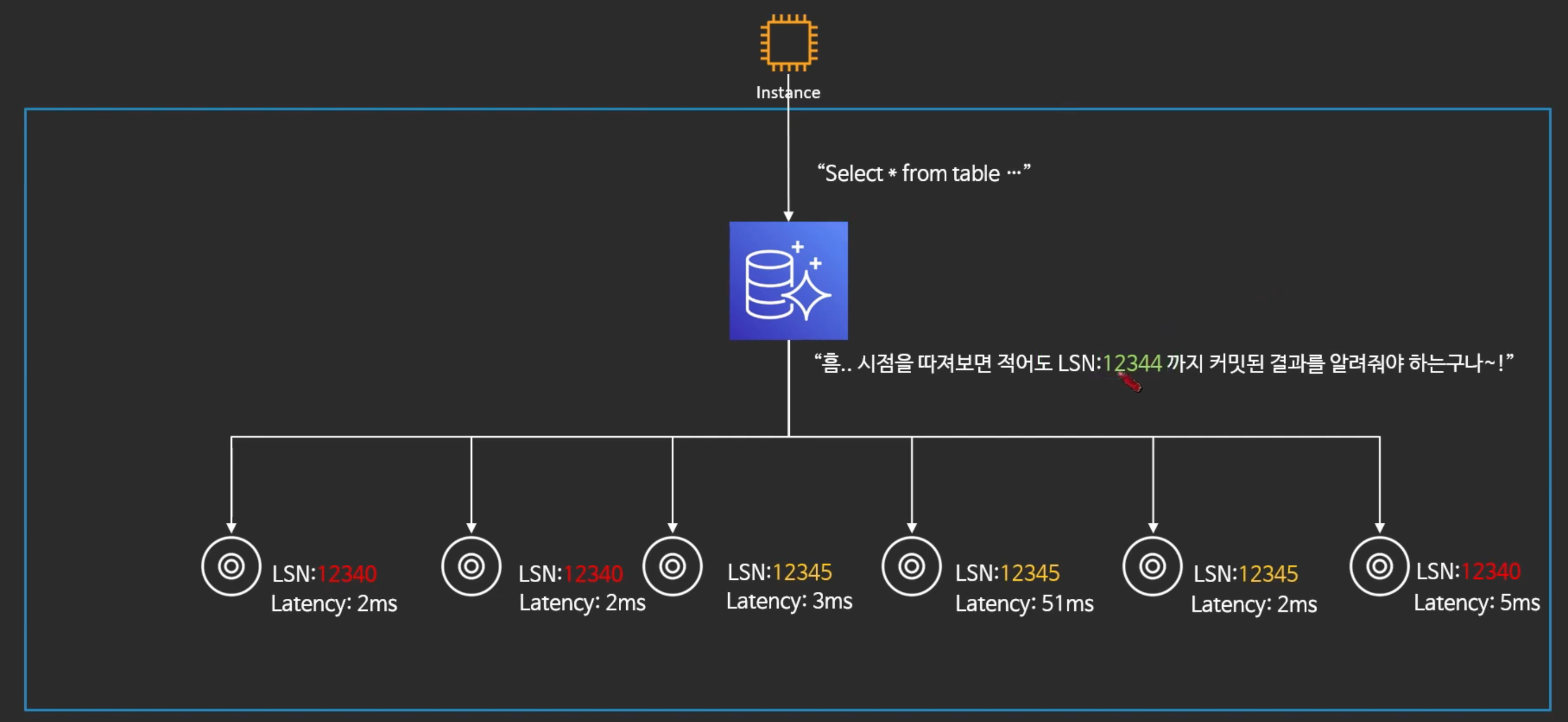
- 쿼리 시점에서 LSN을 알고있다.
- LSN보다 높은 데이터들을 보여줘야 한다.
- 오로라는 각 노드의 LSN도 파악하고 있다.
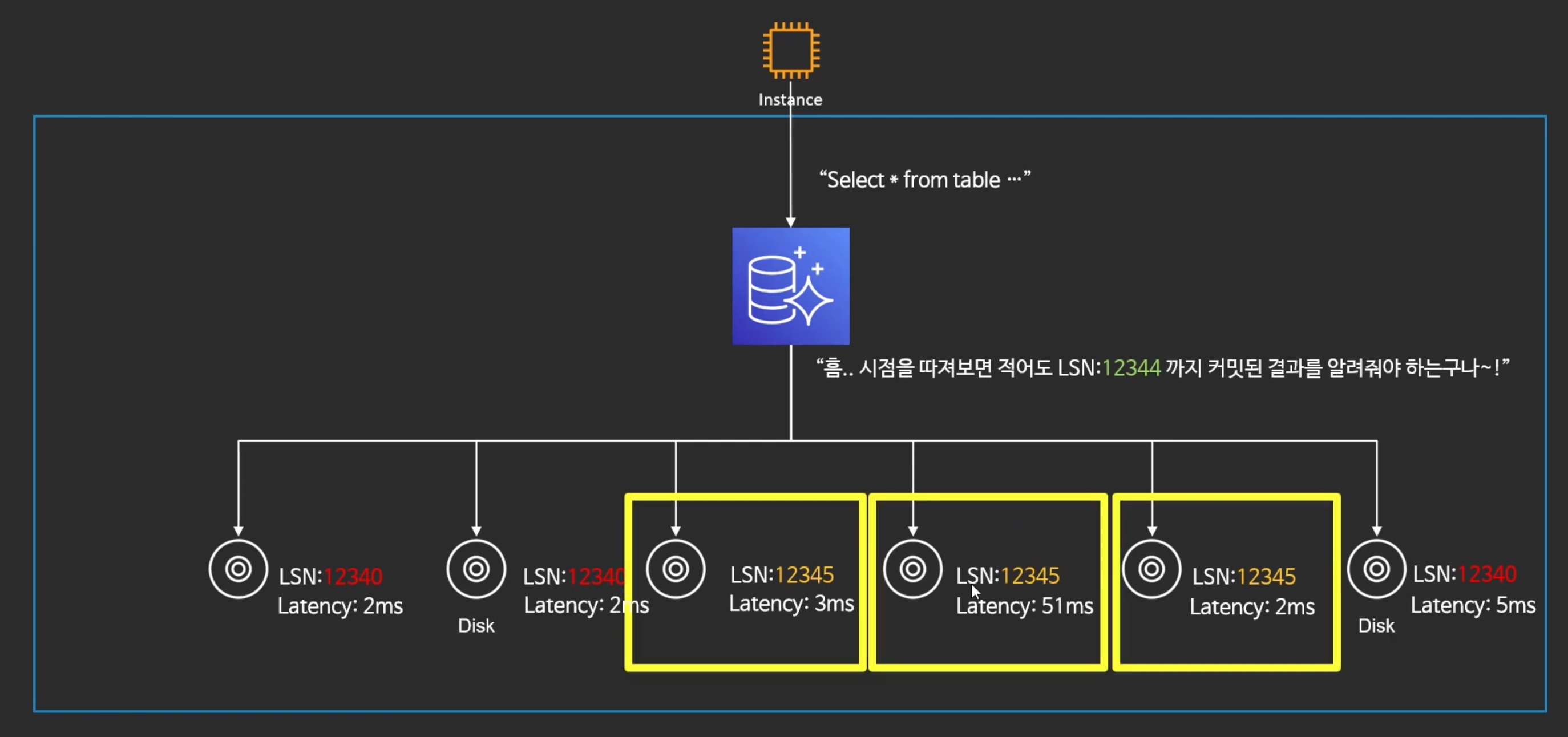
- LSS이 12344보다 큰것은 노란색 박스 3가지가 있다.
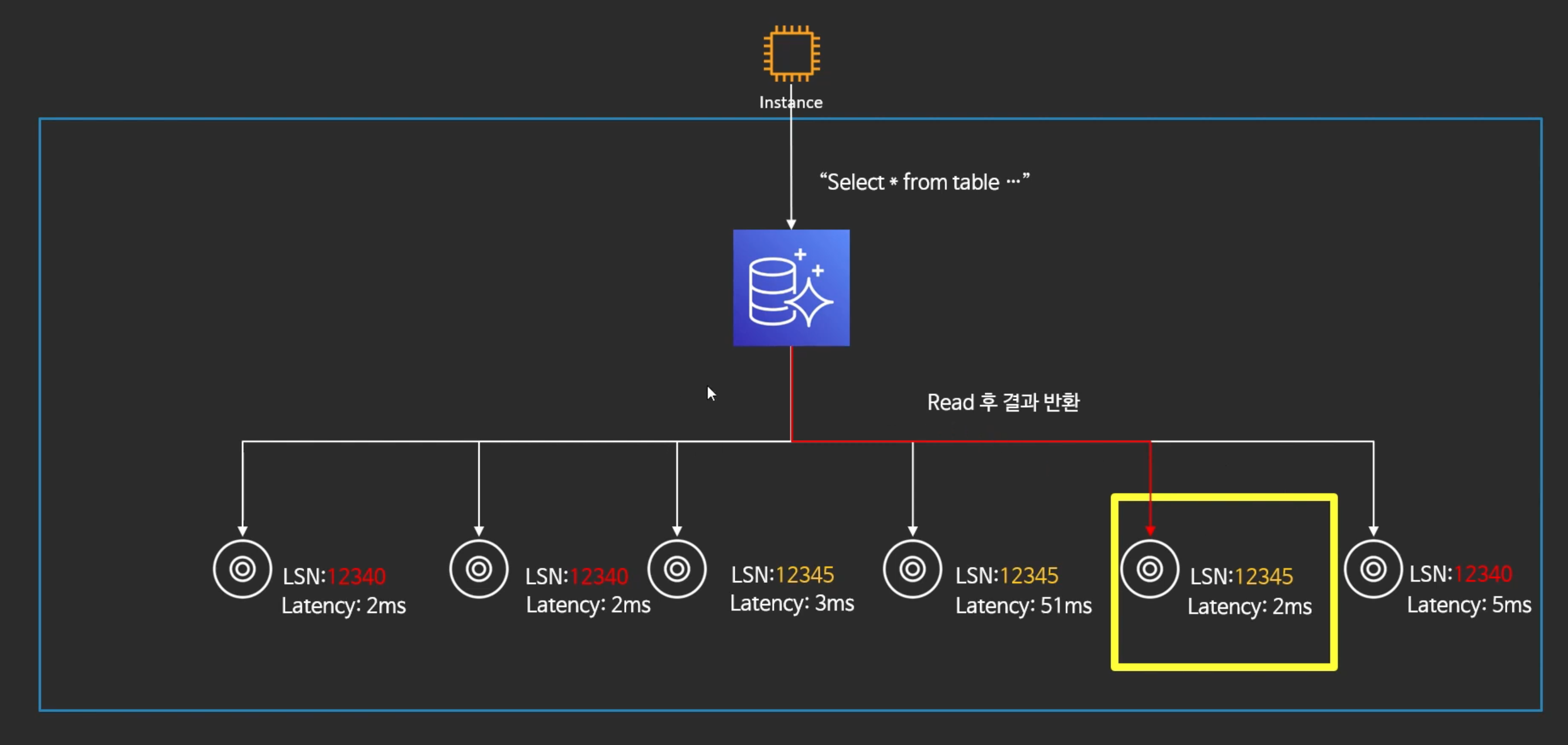
- 그리고 셋중에 Latency가 가장 적은 것을 찾아서 그 스토리지 노드한테만 쿼리를 조회 한다.
"결국 Read는 한 노드에서 한번 발생"
- 결국 Aurora의 Quorum 모델은 Read Quorum이 아닌 Repair Quorum
--> 읽기를 위한 Quorum이 아닌 복구를 위한 Quorum - 전체 노드(6개)를 읽는 것이 X
데이터를 6개나 만들면 비용은 6배인가??
--> "모두 같은 Segment가 아니다!"
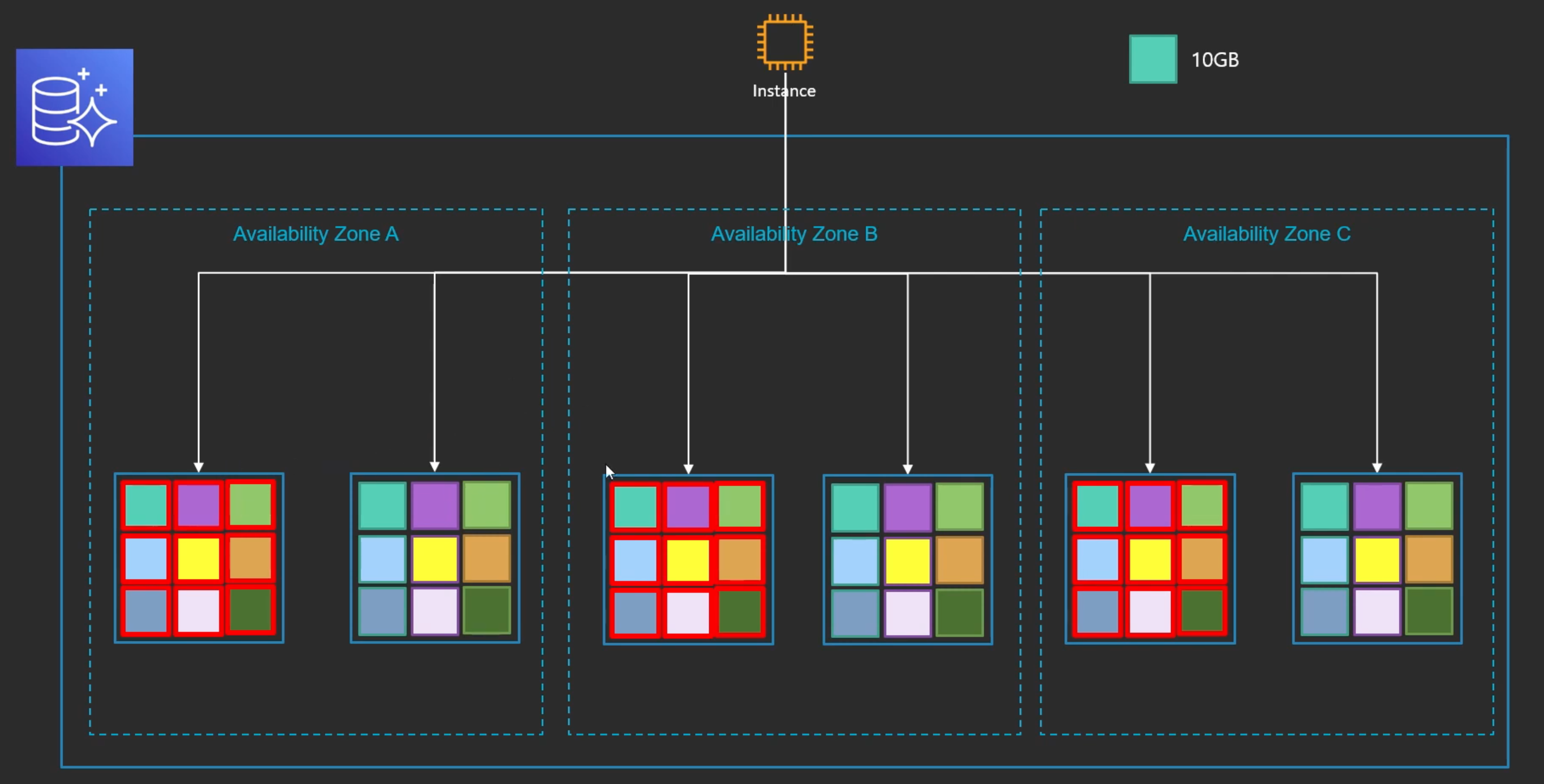
Segment의 구성
- Aurora는 10GB 단위로 데이터 저장: Segment
- 총 6개의 Segment를 유지
- 3개의 Full Segment --> 10GB의 데이터와 로그 레코드
- 3개의 Tail Segment --> 10GB의 로그 레코드

Segment의 복구 방법
참고

쿄쿄쿄