sagemaker 도입 이유
현재 사내에서 개발 중인 의사결정 최적화 AI 플랫폼에서
비용을 고려하려 추론 서버를 격리된 환경에 제공하는 방법을 리서치하다 발견했습니다
sagemaker의 여러 기능 중 inference 기능을 사용할 예정입니다
inference도 아래의 타입이 존재합니다
- Real-Time
- 상시 운영되는 엔드포인트를 통해 실시간 요청을 처리합니다
- Serverless
- Lambda처럼 자동으로 인스턴스를 스케일 업/다운합니다
- 사용량을 기반으로 과금됩니다
- asynchronous
- 비동기 방식으로 요청을 큐에 넣고, 결과를 나중에 받아보는 방식입니다
- 모델 예측 시간이 길거나 즉시 결과가 필요 없는 경우 적합합니다
이 중에서도 특히 Serverless Inference 방식이
예상 트래픽이 불규칙하고, 사용량 기반으로 비용을 추적할 수 있다는 점에서
적합한 인퍼런스 구조라고 판단해서 POC를 진행했습니다
sagemaker 구현
1. 인퍼런스 도커 이미지 만들기!
의사결정 최적화 AI 플랫폼은 sagemaker에서 제공해주는 모델을 사용한 게 아니라
custom한 이미지를 사용함으로 /ping /invocation API를 구현하여야 합니다
관련 docs
만약 sagemaker에서 제공해주는 모델을 사용하신다면 /ping /invocation API를 구현할 필요없이 해당 함수들을 정해진 파일에 구현해놓으시면 sagemaker가
알아서 샥 잘 호출해서 inference를 동작시켜줍니다!
- PyTorch 및 MXNet 모델 : model_fn, input_fn, predict_fn, output_fn
- inf1 인스턴스 또는 onnx, xgboost, keras 컨테이너 이미지의 경우 : neo_preprocess, neo_postprocess
- TensorFlow 모델의 경우 : input_handler(inference.py 안에), output_handler (inference.py 안에)
2. sagemaker endpoint 배포
sagemaker model, sagemaker endpoint config, sagemaker endpoint를 연결해서 생성
serverless로 배포해야 하기에 sagemaker endpoint config를
아래와 같이 생성
response = client.create_endpoint_config(
EndpointConfigName="<your-endpoint-configuration>",
ProductionVariants=[
{
"ModelName": "<your-model-name>",
"VariantName": "AllTraffic",
"ServerlessConfig": {
"MemorySizeInMB": 2048,
"MaxConcurrency": 20,
"ProvisionedConcurrency": 10,
}
}
]
)❗️트러블 슈팅
- ray init할 때 에러가 발생
- lambda는 /tmp 에서만 쓰기 권한이 있는데, ray가 병렬처리를 위해 이외의 경로에서 쓰기 작업을 시도하면서 발생하는 것 같다는 ML개발자 분의 답변을 듣고
비용을 고려 해야하는 요구사항을 만족 못할 난관에 봉착했습니다
- lambda는 /tmp 에서만 쓰기 권한이 있는데, ray가 병렬처리를 위해 이외의 경로에서 쓰기 작업을 시도하면서 발생하는 것 같다는 ML개발자 분의 답변을 듣고
scale down to zero
그러다 발견한 scale down to zero!!
3개의 sagemaker inference type 중 real-time을 auto-scaling 하는 기능을 활용해서 설정한 기간동안 트래픽이 발생하지 않으면 아예 인스턴스를 0개로 내려버리는 기능입니다
endpoint 수정
- endpoint config 수정
MinInstanceCount를 0로 설정함으로 zero instance를 허용함
sagemaker_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ExecutionRoleArn=role,
ProductionVariants=[
{
"VariantName": variant_name,
"InstanceType": instance_type,
"InitialInstanceCount": 1,
"ModelDataDownloadTimeoutInSeconds": model_data_download_timeout_in_seconds,
"ContainerStartupHealthCheckTimeoutInSeconds": container_startup_health_check_timeout_in_seconds,
"ManagedInstanceScaling": {
"Status": "ENABLED",
"MinInstanceCount": 0,
"MaxInstanceCount": max_instance_count,
},
"RoutingConfig": {"RoutingStrategy": "LEAST_OUTSTANDING_REQUESTS"},
}
],
)- endpoint 생성
sagemaker_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name,
)
- inference component 생성
sagemaker_client.create_inference_component(
InferenceComponentName=inference_component_name,
EndpointName=endpoint_name,
VariantName=variant_name,
Specification={
"ModelName": model_name,
"StartupParameters": {
"ModelDataDownloadTimeoutInSeconds": 3600,
"ContainerStartupHealthCheckTimeoutInSeconds": 3600,
},
"ComputeResourceRequirements": {
"MinMemoryRequiredInMb": 1024,
"NumberOfAcceleratorDevicesRequired": 1,
},
},
RuntimeConfig={
"CopyCount": 1,
},
)sagemaker_client.create_inference_component(
InferenceComponentName=inference_component_name,
EndpointName=endpoint_name,
VariantName=variant_name,
Specification={
"ModelName": model_name,
"StartupParameters": {
"ModelDataDownloadTimeoutInSeconds": 3600,
"ContainerStartupHealthCheckTimeoutInSeconds": 3600,
},
"ComputeResourceRequirements": {
"MinMemoryRequiredInMb": 1024,
"NumberOfAcceleratorDevicesRequired": 1,
},
},
RuntimeConfig={
"CopyCount": 1,
},
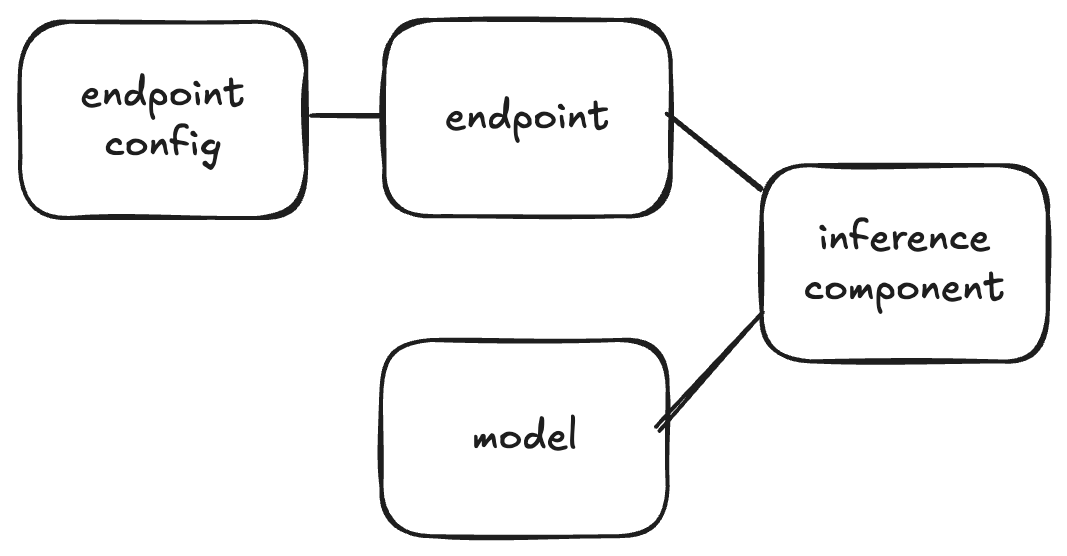
)기존 설정과 다른 점 : endpoint config 와 model 연결을 끊었습니다
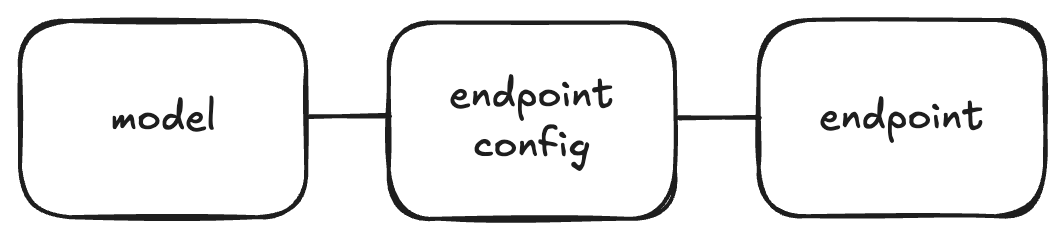
- as-is
- model - endpoint config - endpoint 로 연결
- to-be
scaling policies 추가
scale down to zero를 위해서 아래 2개의 scaling policy를 설정해야 합니다
- inference component model copy를 0개까지 scale down하는
target tracking정책 - inference component model copy를 0개에서 scale up하는
step scaling정책
target tracking정책
MinCapacity 를 0으로 설정하여 scale down to zero 가능합니다
aas_client.register_scalable_target(
ServiceNamespace=service_namespace,
ResourceId=resource_id,
ScalableDimension=scalable_dimension,
MinCapacity=0,
MaxCapacity=max_copy_count, # Replace with your desired maximum number of model copies
)TargetValue 는 동시 요청수가 해당 값 이상이면 capacity를 늘립니다
aas_client.put_scaling_policy(
PolicyName="inference-component-target-tracking-scaling-policy",
PolicyType="TargetTrackingScaling",
ServiceNamespace=service_namespace,
ResourceId=resource_id,
ScalableDimension=scalable_dimension,
TargetTrackingScalingPolicyConfiguration={
"PredefinedMetricSpecification": {
"PredefinedMetricType": "SageMakerInferenceComponentConcurrentRequestsPerCopyHighResolution",
},
# Low TPS + load TPS
"TargetValue": 5, # you need to adjust this value based on your use case
"ScaleInCooldown": 300, # default
"ScaleOutCooldown": 300, # default
},
)scaling이 되는 동작 원리
- cloudWatch 알람 기반
step scaling정책
NoCapacityInvocationFailures 트리거되는 CloudWatch alarm을 생성하고
alarm이 트리거되어step scaling정책이 실행됩니다
그래서 NoCapacityInvocationFailures이면 ScalingAdjustment을 1로 설정하여 model copy를 0에서 1로 설정하여 scale up 됩니다
aas_client.put_scaling_policy(
PolicyName="inference-component-step-scaling-policy",
PolicyType="StepScaling",
ServiceNamespace=service_namespace,
ResourceId=resource_id,
ScalableDimension=scalable_dimension,
StepScalingPolicyConfiguration={
"AdjustmentType": "ChangeInCapacity",
"MetricAggregationType": "Maximum",
"Cooldown": 60,
"StepAdjustments":
[
{
"MetricIntervalLowerBound": 0,
"ScalingAdjustment": 1 # you need to adjust this value based on your use case
}
]
},
)cw_client.put_metric_alarm(
AlarmName='ic-step-scaling-policy-alarm',
AlarmActions=<step_scaling_policy_arn>, # Replace with your actual ARN
MetricName='NoCapacityInvocationFailures',
Namespace='AWS/SageMaker',
Statistic='Maximum',
Dimensions=[
{
'Name': 'InferenceComponentName',
'Value': inference_component_name # Replace with actual InferenceComponentName
}
],
Period=30,
EvaluationPeriods=1,
DatapointsToAlarm=1,
Threshold=1,
ComparisonOperator='GreaterThanOrEqualToThreshold',
TreatMissingData='missing'
)성과 및 보안점
사용량 기반 과금과 함께 격리된 추론 서버환경을 제공하는 방법은 찾았지만
serverless의 cold start 관련된 문제가 존재합니다
실제 테스트 결과는 cold start시 3~6분입니다
다만 합리적인 요금이 우선순위가 높아서 해당 이슈는 격리된 추론 서버를 사용할
유저가 로그인하면 미리 요청을 보내 warm하게 만드는 방식으로 보안할 예정입니다
