
Topic : 카트라이더 Open API를 이용하여 v1엔진의 레전드 카트가 출시되기 전후의 메타를 분석하고 정보에 따른 승률을 예측하는 프로젝트
PPT와 발표스크립트, 코드파일을 포함한 추가적인 내용은 깃허브 링크를 참조하시길 바랍니다.
깃허브 링크 : https://github.com/colacan100/Kartrider_Meta_Analysis_Project
1. API를 이용한 데이터셋 생성

카트라이더 공식 Open API를 이용하여 데이터셋을 만든다. 데이터셋을 만드는 과정은 아래의 그림과 같다.
v1엔진의 레전드 카트가 출시되기 전과 후로 데이터셋을 각각 추출한다. 출시되기전을 프로젝트1, 출시된 후를 프로젝트2로 언급하고 가겠다.

데이터셋을 추출하는데 가장 신경 쓴 부분은 API의 호출허용량이다. 10초당 호출허용량을 넘기면 key error 가 발생한다. 이러한 문제 해결을 위해 sleep 함수를 이용하여 호출에 자체적으로 제한을 주었다. 위의 이미지를 참고바란다.
1-1) 매치리스트 조회를 통해 매치고유식별자를 가져온다.
import warnings
import requests
import pandas as pd
import json
from datetime import datetime
from datetime import timedelta
import time
warnings.filterwarnings(action='ignore')
def make_data(start,end,total_end):
start_date = start #'시작시간'
end_date = end #'종료시간'
offset = 0 # 시작위치
limit = 200
match_types = ''
match_list = []
hour_count = 0
error_code = []
# while 문을 != 기간으로 설정하면 이를 초과하는 문제발생, ex) 기간설정 12일 24시를 13시 00시로 설정할것
# 아니면 end time을 datetime으로 바꿔 < 비교 연산자 사용
count = 0
while start_date != total_end :
api = '개인 API키 이용'
headers = {'Authorization': api}
_API_URL = f'https://api.nexon.co.kr/kart/v1.0/matches/all?start_date={start_date}&end_date={end_date}&offset={offset}&limit={limit}&match_types={match_types}'
res = requests.get(_API_URL, headers = headers)
data=res.json()
try:
for i in range(len(data['matches'])):
match_list.extend(data['matches'][i]['matches'])
except TypeError as e: # TypeError: object of type 'NoneType' has no len()
error_code.append([start_date, end_date, e, res])
print(res)
pass
count += 1
if count % 30 == 0: # 중간 진행과정 확인, 출력되는 날짜가 +30분 상태로 출력 확인시 주의
hour_count += 1
print(res, hour_count, " start:",start_date," end : ", end_date)
time.sleep(2)
start_date = end_date
d = datetime.strptime(end_date, '%Y-%m-%d %H:%M:%S')
new_end_date = d + timedelta(minutes=2)
end_date = new_end_date.strftime('%Y-%m-%d %H:%M:%S')
print(match_list)
print(len(match_list))
print(start_date)
df_match = pd.DataFrame(match_list)
df_error = pd.DataFrame(error_code)
df_error.to_csv('pre_error.csv',encoding='utf-8-sig')
return df_match
df_match_1 = make_data('2021-12-04 00:00:00','2021-12-04 00:30:00','2021-12-12 00:00:00')1-2) 매치상세정보 조회를 통해서 매치정보와 플레이어정보를 가져온다.
df_res = pd.DataFrame()
df_res2 = pd.DataFrame()
df_user = pd.DataFrame()
def match_lookup(match_id):
global df_res,df_user,df_res2
api = 'eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJhY2NvdW50X2lkIjoiMTA5MTM3MTU4NCIsImF1dGhfaWQiOiI0IiwidG9rZW5fdHlwZSI6IkFjY2Vzc1Rva2VuIiwic2VydmljZV9pZCI6IjQzMDAxMTM5MyIsIlgtQXBwLVJhdGUtTGltaXQiOiIyMDAwMDoxMCIsIm5iZiI6MTY0NzUyNjM2MiwiZXhwIjoxNzEwNTk4MzYyLCJpYXQiOjE2NDc1MjYzNjJ9.c1JR3S8Y7-I95PU2gHdGJfRry1_zV6oaGXgpQ6hOCuY'
headers = {'Authorization': api}
_API_URL = f'https://api.nexon.co.kr/kart/v1.0/matches/{match_id}'
res = requests.get(_API_URL, headers = headers)
data=res.json()
df_res = pd.DataFrame()
df_res = df_res.append(data,ignore_index=True)
for i in range(len(data['players'])):
df_user = pd.DataFrame()
df_user = df_user.append(data['players'][i],ignore_index=True)
df_res2 = df_res2.append(pd.concat((df_res,df_user),axis=1))
return df_res2count = 0
for i in df_match_after[0]:
try:
if count % 1000 == 0:
time.sleep(10)
print('1000 count')
match_lookup(i)
count += 1
except KeyError: # TypeError: object of type 'NoneType' has no len()
print('Error:',count)
pass이후 csv 파일로 변환하였다.
df.to_csv('kartrider_data_1.csv',encoding='utf-8-sig')2. 데이터 전처리
2-1) 요소들의 Drop
- 중복값 제거
- 관련없는 요소 제거
1) matchId : 매치 고유 식별자
2) character : 캐릭터는 플레이에 영향을 주지 않음
3) license : 이전 라이센스는 ''값을 가짐
4) matchRetired : 순위로 리타이어 여부를 나타냈음
5) characterName : 유저 닉네임
6) channelName : battle 유형의 게임은 협력전 (일부 행 제거)
7) matchRank : 0은 강제종료를 의미 (일부 행 제거) - Data Leakage 방지
1) matchResult, matchWin : target에 직접적 영향을 줌
2) startTime, endTime ,playTime, matchTime : target에 직접적 영향을 줌
import pandas as pd
df = pd.read_csv('C:\\Users\\colacan\\Documents\\GitHub\\Kartrider_Meta_Analysis_Project\kartrider_data_1.csv')
df = df.drop('Unnamed: 0', axis = 1)
df.duplicated().sum()
# 필요없는 columns 드롭
df = df.drop(['character','characterName','accountNo','players','matchId','startTime','endTime','matchResult','license','matchRetired','matchWin','playTime','matchTime'],axis=1)
# 결측치 비율 확인
import seaborn as sns
sns.heatmap(df.isnull().T,cbar=False)
# battle 데이터는 협력전이므로 제외
df= df[df['channelName'] != 'battle']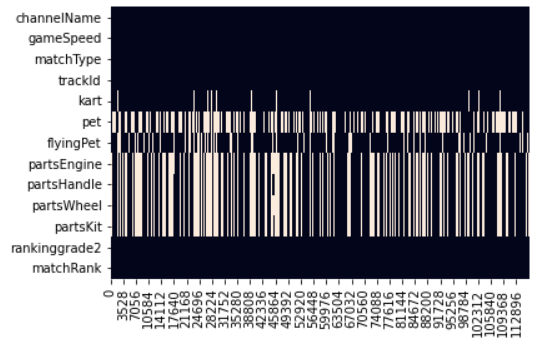
위의 그래프는 결측치를 시각화한 것이다.
2-2) 결측치 처리
- kart : api 자체 공백값 (drop)
- pet : 펫 미장착 (non_pet 대체)
- flyingPet : 플라잉 펫 미장착 (non_flyingPet 대체)
- partsEngine : X엔진 이상 버전 미등록 (over_ver_engine 대체)
- partsHandle : X엔진 이상 버전 미등록 (over_ver_handle 대체)
- partsWheel : X엔진 이상 버전 미등록 (over_ver_wheel 대체)
- partsKit : X엔진 이상 버전 미등록 (over_ver_kit 대체)
- matchRank : 강제종료로 인한 공백값 (drop)
# 결측치 제거
df = df.dropna(subset= ['kart', 'matchRank'])
# 결측치 대체
values = {'pet':'non_pet', 'flyingPet':'non_flyingPet', 'partsEngine':'over_ver_engine', 'partsHandle':'over_ver_handle','partsWheel':'over_ver_wheel','partsKit':'over_ver_kit'}
df = df.fillna(value=values)
df = df[df['matchRank'] != 0]
# 인덱스 재정렬
df = df.reset_index()
df = df.drop('index',axis=1)이후 csv 파일로 변환하였다.
df.to_csv('kartrider_eda_1.csv',encoding='utf-8-sig')3. 머신러닝 모델적용
3-1) 베이스라인 모델설정
import pandas as pd
df = pd.read_csv('C:\\Users\\colacan\\Documents\\GitHub\\Kartrider_Meta_Analysis_Project\\kartrider_eda_1.csv')
df = df.drop('Unnamed: 0', axis = 1)
# 등수 예측이 목적이므로 타겟은 matchRank
target = 'matchRank'
# 타겟이 범주형데이터이므로 분류문제로 해결
import seaborn as sns
import matplotlib.pyplot as plt
fig = sns.displot(df[target])
fig.fig.set_size_inches(10,6)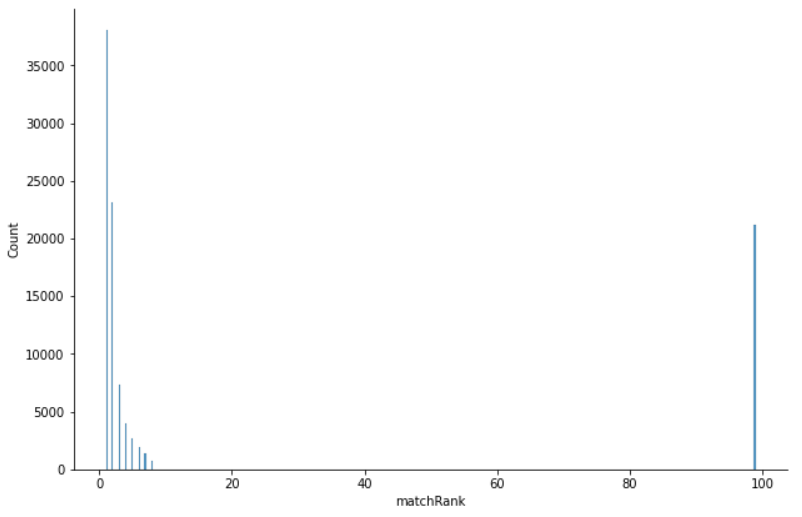
위의 그래프는 타겟인 matchRank의 데이터 불균형을 보여준다.
f[target].value_counts(normalize=True)
major = df[target].mode()[0]
pred = [major] * len(df[target])
from sklearn.metrics import f1_score
import sklearn.metrics as metrics
# 기준모델의 평가지표
print("training accuracy: ", metrics.f1_score(df[target], pred,average ='weighted'))베이스라인 모델 : 최빈값인 1위를 기준으로 한 모델
프로젝트 1 - 최빈값 비율 : 38.13%, f1-score : 0.2105
프로젝트 2 - 최빈값 비율 : 37.85%, f1-score : 0.2078
3-2) 훈련,테스트 데이터셋 분류
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
def divide_data(df):
X = df.drop('matchRank', axis = 1)
y = df['matchRank']
return X, y
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
print(X_train.shape,y_train.shape)
print(X_test.shape,y_test.shape)3-3) 평가지표 설정
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred,average='weighted')
recall = recall_score(y_test, pred,average='weighted')
print('Confusion Matrix')
print(confusion)
print('정확도:{}, 정밀도:{}, 재현율:{}'.format(accuracy, precision, recall))3-4) 사용할 모델 선택
- RandomForestClassifier
과적합 문제를 회피하기 좋음 - CatBoostClassifier
boosting의 장점을 가져가며 과적합 방지 - XGBClassifier
강력한 병렬처리, 과적합방지, 자체 교차검증 가능
3개의 모델 모두 불균형 데이터 조정 option을 지원한다.
3-5) RandomForestClassfier 모델적용
import warnings
warnings.filterwarnings(action='ignore')
from sklearn.model_selection import RandomizedSearchCV
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from category_encoders import OrdinalEncoder
from sklearn.impute import SimpleImputer
from scipy.stats import randint, uniformtrain, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
def fit_rf(X_train, y_train):
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
RandomForestClassifier(class_weight = "balanced", random_state=42)
)
dists = {
'randomforestclassifier__max_depth' : randint(1, 30),
'randomforestclassifier__max_features' : randint(1, 10),
'randomforestclassifier__n_estimators' : randint(1, 300)
}
clf = RandomizedSearchCV(
pipe,
param_distributions=dists,
n_iter=10,
cv=5,
scoring='f1',
verbose=1,
n_jobs=-1,
random_state = 42
)
clf.fit(X_train, y_train)
print("Optimal Hyperparameter:", clf.best_params_)
return clf
clf_rf = fit_rf(X_train, y_train)
pred_rf = clf_rf.predict(X_test)
get_clf_eval(y_test, pred_rf)
f1 = f1_score(y_test, pred_rf,average='weighted')
print('f1 score :', f1)
모델의 결과는 위의 이미지를 참고바란다.
3-6) CatBoostClassifier 모델적용
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
!pip install catboost
from catboost import CatBoostClassifier
def fit_cb(X_train, y_train):
# YOUR CODE HERE
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
CatBoostClassifier(loss_function = 'MultiClass',class_weights=[0.622,0.77,0.928,0.928,0.974,0.982,0.987,0.993,0.789],early_stopping_rounds=35,verbose=100)
)
# YOUR CODE ENDS HERE
pipe.fit(X_train, y_train)
return pipe
clf_cb = fit_cb(X_train, y_train)
pred_cb = clf_cb.predict(X_test)
get_clf_eval(y_test, pred_cb)
f1 = f1_score(y_test, pred_cb,average='weighted')
print('f1 score :', f1)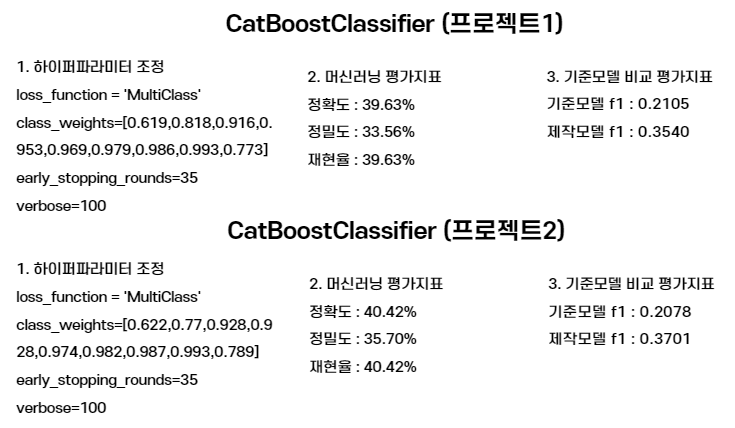
모델의 결과는 위의 이미지를 참고바란다.
3-7) XGBClassifier 모델적용
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
!pip install xgboost
# XGBClassifier
from sklearn.utils import class_weight
from xgboost import XGBClassifier
def fit_xg(X_train, y_train):
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_train_processed = processor.fit_transform(X_train)
classes_weights = class_weight.compute_sample_weight(
class_weight='balanced',
y=y_train
)
clf = XGBClassifier(eval_metric='mlogloss',max_depth = 21,n_estimators = 190)
clf.fit(X_train_processed, y_train, sample_weight=classes_weights)
return clf
clf_xg = fit_xg(X_train, y_train)
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_test_processed = processor.fit_transform(X_test)
pred_xg = clf_xg.predict(X_test_processed)
get_clf_eval(y_test, pred_xg)
f1 = f1_score(y_test, pred_xg,average='weighted')
print('f1 score :', f1)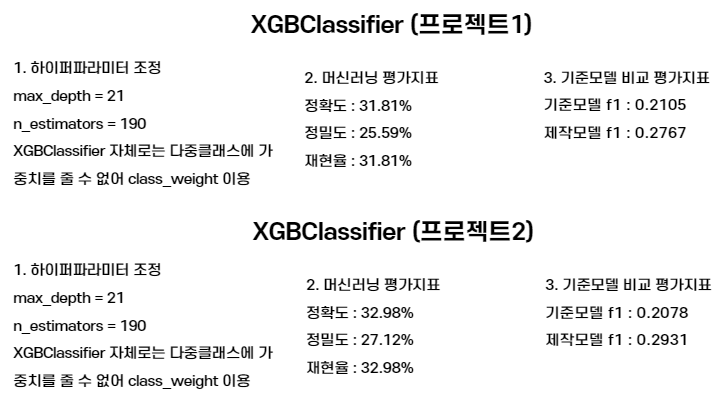
모델의 결과는 위의 이미지를 참고바란다.
3-8) 모델성능 비교
import seaborn as sns
import matplotlib.pyplot as plt
df_by_group = pd.DataFrame(columns = {'model 2','f1'})
data_to_insert = {'model 2': 'baseline','f1': 0.2105}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 2': 'RandomForestClassifier','f1': 0.2838}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 2': 'CatBoostClassifier','f1': 0.3701}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
data_to_insert = {'model 2': 'XGBClassifier','f1': 0.2931}
df_by_group = df_by_group.append(data_to_insert, ignore_index=True)
df_by_group.plot.bar(x='model 2',y='f1',rot=0)
plt.xticks(rotation=45)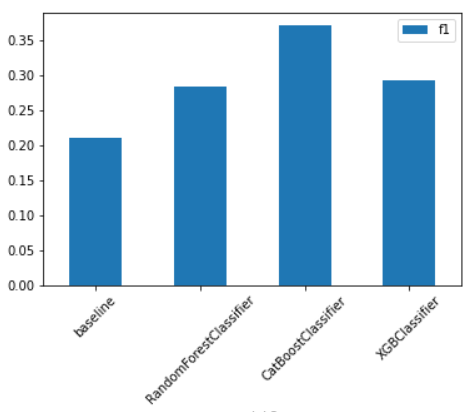
위의 그래프는 모델성능을 시각화한 것이다. 프로젝트 1,2에서 비슷한 추세를 보였다.
성능이 가장 괜찮은 CatBoostClassifier를 채용했다.
3-9) 교차검증 진행
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
# (참고) warning 제거를 위한 코드
np.seterr(divide='ignore', invalid='ignore')
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='mean'),
CatBoostClassifier(loss_function = 'MultiClass',class_weights=[0.619,0.818,0.916,0.953,0.969,0.979,0.986,0.993,0.773],early_stopping_rounds=35,verbose=100)
)
# 5-fold 교차검증을 수행합니다.
k = 5
scores = cross_val_score(pipe, X_train, y_train, cv=k, scoring=make_scorer(f1_score,average ='weighted'))
print(f'f1 ({k} folds):', scores)
print(scores.mean())
print(scores.std())
import seaborn as sns
import matplotlib.pyplot as plt
data = {'fold2': ['fold1', 'fold2', 'fold3', 'fold4', 'fold5'], 'f1': [0.37507727, 0.37053896, 0.36973846, 0.37202236, 0.3717662]}
df_by_fold = pd.DataFrame(data=data)
df_by_fold.plot.bar(x='fold2',y='f1',rot=0)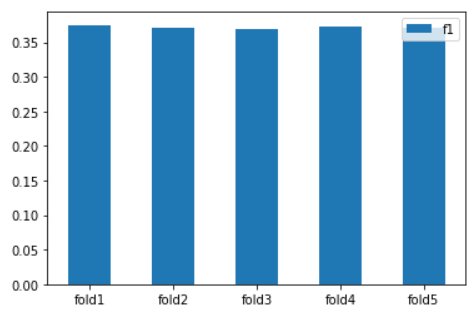
위의 그래프는 교차검증을 시각화한 것이다. 프로젝트 1,2에서 비슷한 추세를 보였다.
Variance가 작다는 것은 모델 complexity에 비해 sample수가 많다는 것을 의미한다.
3-10) 특성중요도 확인
train, test = train_test_split(df, train_size=0.7, stratify=df[target], random_state=2)
X_train, y_train = divide_data(train)
X_test, y_test = divide_data(test)
from catboost import CatBoostClassifier
def fit_cb(X_train, y_train):
# YOUR CODE HERE
pipe = make_pipeline(
OrdinalEncoder(),
SimpleImputer(),
CatBoostClassifier(loss_function = 'MultiClass',class_weights=[0.622,0.77,0.928,0.928,0.974,0.982,0.987,0.993,0.789],early_stopping_rounds=35,verbose=100)
)
# YOUR CODE ENDS HERE
pipe.fit(X_train, y_train)
return pipe
processor = make_pipeline(
OrdinalEncoder(),
SimpleImputer(strategy='median')
)
X_train_processed = processor.fit_transform(X_train)
res_clf = CatBoostClassifier(loss_function = 'MultiClass',class_weights=[0.622,0.77,0.928,0.928,0.974,0.982,0.987,0.993,0.789],early_stopping_rounds=35,verbose=100)
res_clf.fit(X_train_processed,y_train)
res_clf.get_feature_importance()
def plot_feature_importance(importance,names,model_type):
#Create arrays from feature importance and feature names
feature_importance = np.array(importance)
feature_names = np.array(names)
#Create a DataFrame using a Dictionary
data={'feature_names':feature_names,'feature_importance':feature_importance}
fi_df = pd.DataFrame(data)
#Sort the DataFrame in order decreasing feature importance
fi_df.sort_values(by=['feature_importance'], ascending=False,inplace=True)
#Define size of bar plot
plt.figure(figsize=(10,8))
#Plot Searborn bar chart
sns.barplot(x=fi_df['feature_importance'], y=fi_df['feature_names'])
#Add chart labels
plt.title(model_type + 'FEATURE IMPORTANCE')
plt.xlabel('FEATURE IMPORTANCE')
plt.ylabel('FEATURE NAMES')
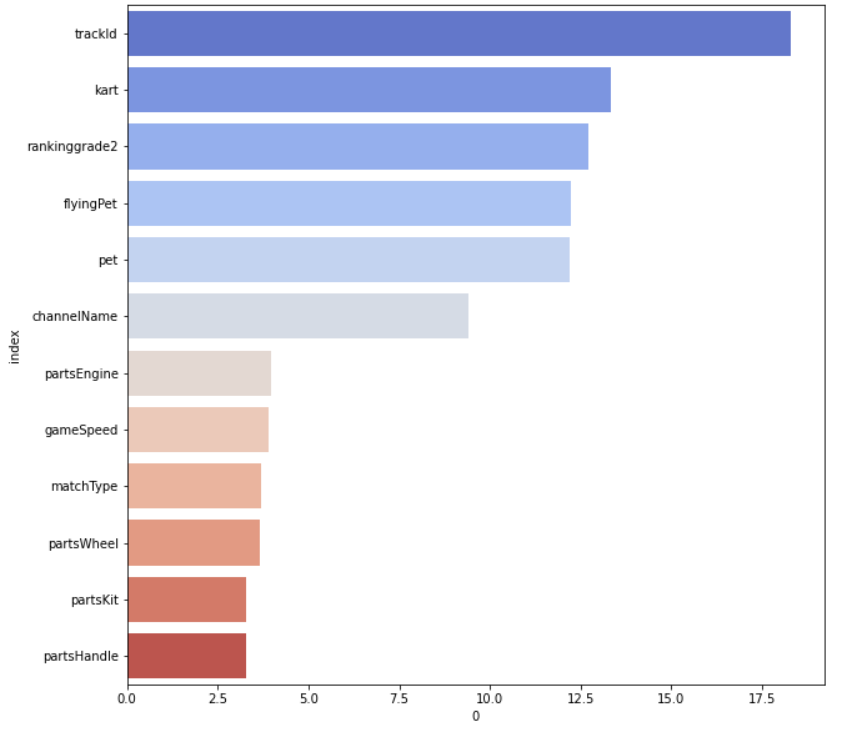
plot_feature_importance(res_clf.get_feature_importance(),X_train.columns,'CATBOOST')프로젝트 1의 특성중요도 시각화이다.
프로젝트2의 특성중요도 시각화이다.
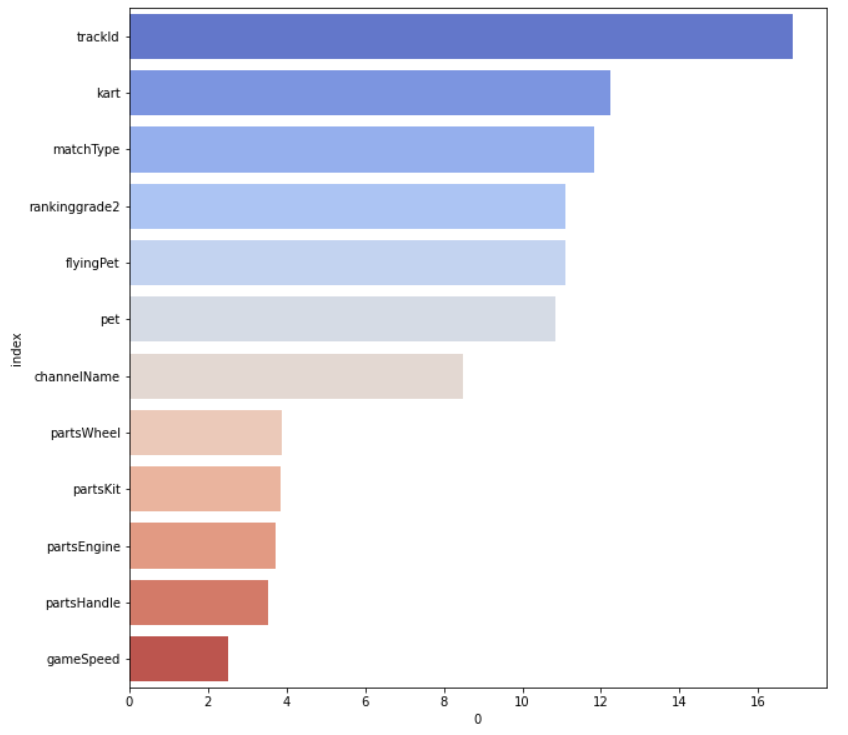
4. 머신러닝 모델해석
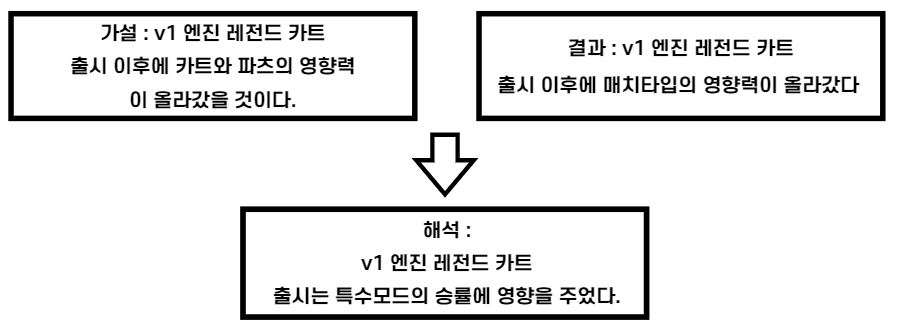
가설과 결과를 통해서 위의 이미지와 같은 결과를 도출해냈다. 세운 가설과는 차이가 있다. 카트와 파츠의 영향력이 올라가긴했지만, 그 차이가 크지않아 해석에 포함시키지 않았다.
5. 머신러닝 모델피드백
- 특정 ver 이후의 파츠들이 Nan 값
파츠의 다양성을 제대로 보여주지 못했다. 좋지 못한 데이터라고 할 수 있다. 버전에 대한 업데이트가 이루어졌다면 더 나은 결과를 가져왔을 것 같다. 많이 아쉬운 부분이다. - 낮은 f1-score
MatchTime을 제거하기 전 f1-score : 0.65
MatchTime을 제거한 후 f1-score : 0.37
하지만 데이터 누수를 예상해 제거했다. 이는 낮은 성능을 가져왔지만, 잘한 행동이라고 생각한다. - 그 외 아쉬운 점
데이터 추출에 6시간, 모델의 적용과정에 몇십분이 들었다. 이는 기간이 정해진 프로젝트에 치명적인 영향을 끼쳤다. 그에 더해 처음해보는 api 사용으로 인한 시간지연 +α 이 있었고 이로 인해 더 많은 내용을 다루지 못했다
6. 후기
최종적인 결과는 만족스럽지 못했지만, 연구자의 부분에서는 최선을 다한 부분이었다. 또한 개인적으로 많은 것을 배우고 시도한 프로젝트라고 생각하기에 만족한다. 많은 시간과 노력을 투자한 보람이 있었다. 이후 피드백 리뷰로 찾아뵙도록 하겠다.
