
Platypus는 오리너구리라는 뜻이라고 한다.
들어가며
Platypus는 Open LLM Leaderboard에서 1위를 했었던 LLaMA 기반의 Instruction Tuning 모델로 8월 14일에 ArXiv에 공개된 연구이다. 글을 쓰는 현 시점에서는 2위에 랭크되어있다.
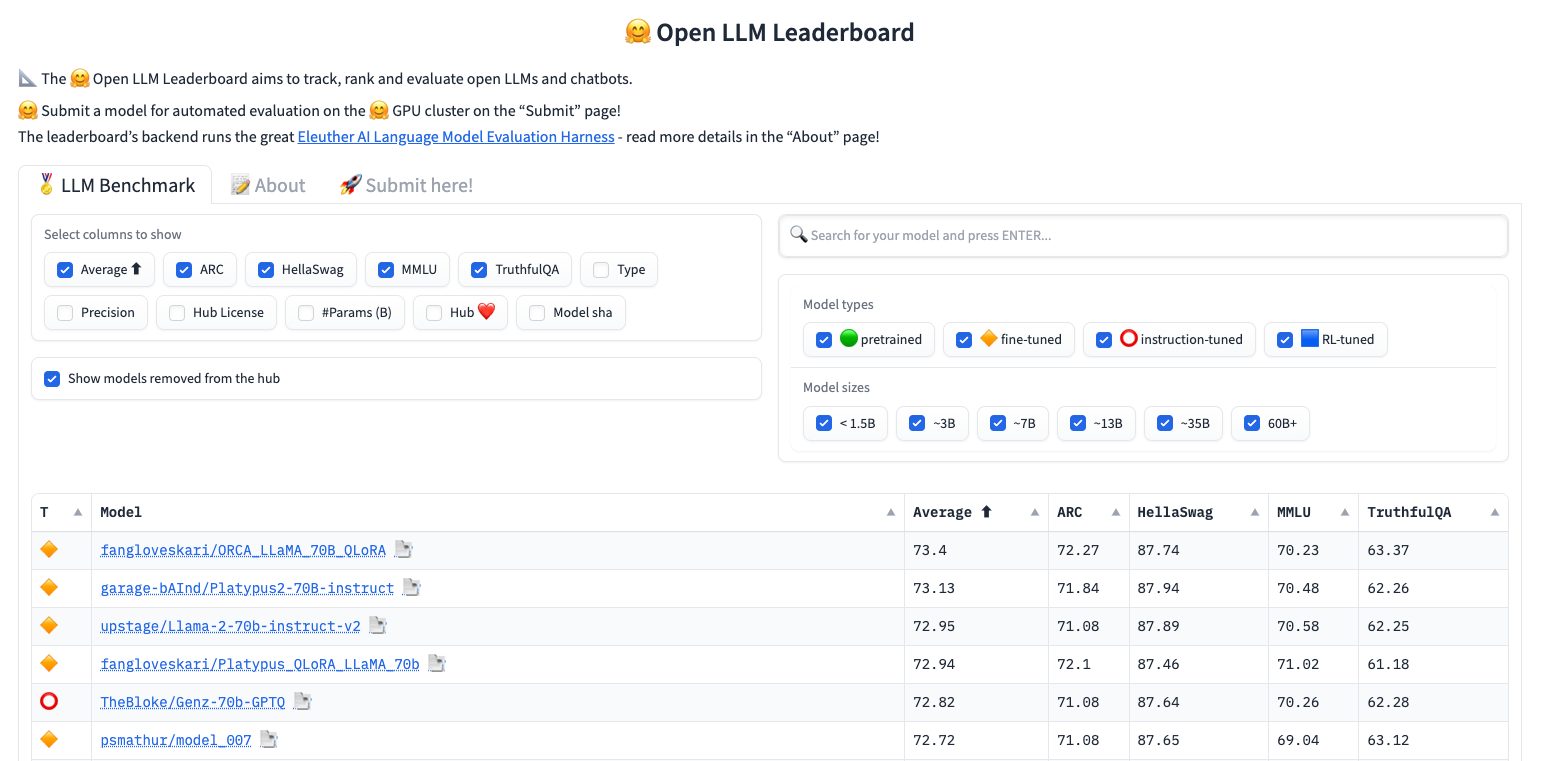
이 페이퍼를 보면서 놀랐던 것은 25k의 데이터셋만을 사용했다는 점이다. Platypus가 공개되기 전에 Leaderboard에서 1위를 했던 Orca는 Instruction Tuning을 위해 GPT를 통해 생성한 대량의 데이터를 사용하였다. 이와 비교할때, Platypus는 자원 대비 성능이 매우 높다는 것을 확인할 수 있었다.
Platypus가 접근한 방법은 크게 두 가지로 좁혀볼 수 있다.
- Curated small dataset
- Full fine-tuning (X), LoRA (O)
Curated Small Dataset
데이터셋 선택
Platypus는 대부분 오픈소스 데이터셋에서 데이터를 선별하였다. Alpaca 이후 많은 Instruction Tuning 접근법들이 LLM에서 생성된 데이터셋을 학습에 사용하는 것과 비교할때 주목할만하다. 다만, 여기서도 10% 정도의 데이터셋은 LLM으로 생성된 데이터셋을 사용하였다고 밝히고 있다.
데이터 크기는 앞서 밝혔듯이 25K로 매우 작은 편이다. 이는 Meta에서 발표한 LIMA 에서 제시한 메시지(Superficial Alignment Hypothsis)와 일치한다. LIMA에서는 성능의 대부분은 이미 pre-training 에서 결정되며 최소한의 훈련 데이터(1K)만으로도 충분히 Alignment를 할 수 있음을 보여줬다(완벽하게 결론이 난 것은 아니지만).
데이터를 정련한 방식이 재미있는데, 먼저 11개의 오픈소스 데이터셋을 최대한 활용하였으며 약 10% 정도만 LLM으로 생성하였다. 벤치마크 성능을 올리기 위해서 선택한 것 같은데, STEM과 logic 과 관련된 데이터를 집중적으로 선택한 듯 하다.
데이터셋 정련
많은 벤치마크 데이터셋이 중복된 데이터를 포함하고 있다. Platypus에서는 중복된 데이터셋으로 인해 모델이 정답을 외워버리는 Memorization 문제가 발생할 수 있다고 가정하고 있다.
따라서 중복된 단어들이 있는 데이터를 삭제하였는데, 그 기준은 Cosine similarity 이다. 구체적으로는 Training 데이터셋과 Test 데이터셋 간의 Cosine similarity가 80%를 넘어가는 경우에는 해당 데이터셋을 삭제하였다.
다음으로 Contamination Check를 하는데, 벤치마크 데이터에 있는 질문들이 training set에 녹아들어있는지 확인하고 제거하는 과정을 의미한다. 여기서도 마찬가지로 Cosine similarity가 80%를 넘어가면 삭제하였다. 다만, duplicate, gray-area, similar but differnt 처럼 삭제된 것에도 사람의 판단을 요하는 부분이 있긴하다. 연구에서는 모두 삭제한 것으로 보이지만 여전히 탐구되어야 할 영역이라 생각된다.
Model and Training Method
Back-bone Model은 MATH의 수정된 버전을 사용했다고 한다.
Instruction data의 형태는 Alpaca 에서 사용한 방식을 사용하였다.
Platypus는 학습에 LoRA를 사용하였다. 자원의 효율성때문에 LoRA만 사용한 것 같다고 생각이된다. 성능에 있어서는 LoRA와 Full fine-tuning 한 결과와 비교해봐야 알 수 있을 듯 하다. 물론 LLaMA-2 70B를 FFT로 학습시키기는 쉽지 않을 것이다. 여러 연구에서 밝히고 있듯이 alignment를 위해서는 LoRA 정도면 충분하다는 생각도 든다.
Platypus에서 재미있는 점은 처음에는 v_proj, q_proj, k_proj, o_proj에 LoRA를 적용했지만, 이후에는 gate_proj, down_proj, up_proj 모듈에 LoRA를 적용한 것이다. 이는 Toward a Unified View of Parameter-Efficient Transfer Learning 에서 제시된 방법이라고 한다 (아래 레퍼런스 참고). 성능이 실제로도 잘 나온 것으로 보이니 LLaMA-2에 LoRA를 사용할때 참고할 수 있겠고 생각된다.
Result
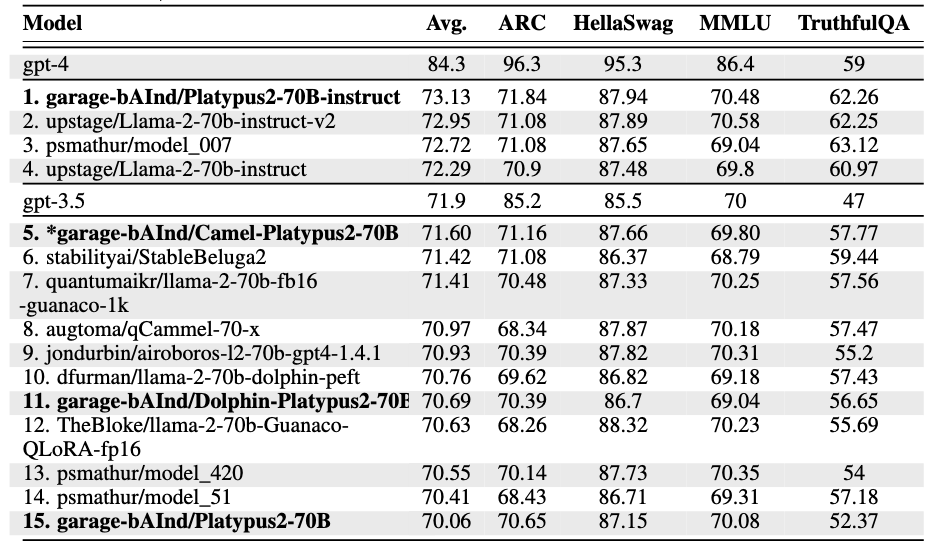
지금은 순위가 다시 바뀌긴했지만, 연구가 발표된 시점에는 1위를 하였다.
의견
LIMA의 컨셉을 적용해서 실제 벤치마크에서 1위를 한 의의가 있다고 생각된다. 그리고 데이터를 정련하는 방법들이 자원이 많이 소모되는 일이 아니기에, 실제 프로덕트를 개발할때도 적용해볼만하다고 생각된다.
다만, 다시 벤치마크 순위가 바뀐다는 점. 그리고 벤치마크에 최적화되어서 일반화 성능이 잘나올지 의문이라는 점은 여전히 숙제라고 생각된다.
Reference
- Playtus arXiv
https://arxiv.org/abs/2308.07317 - Playtus github repo
https://platypus-llm.github.io/ - LIMA
https://arxiv.org/abs/2305.11206 - Toward a Unified View of Parameter-Efficient Transfer Learning
https://arxiv.org/abs/2110.04366
