
📌 사용자 레벨 관리 기능 추가
구현해야 할 레벨 시스템
- 사용자의 레벨은 BASIC, SILVER, GOLD 세 가지 중 하나.
- 처음 가입한 사용자는 BASIC 레벨
- 가입 후 50회 이상 로그인시 SILVER 레벨
- SILVER에서 30번 이상 추천을 받으면 GOLD 레벨
- 레벨의 변경 작업은 일정 주기마다 일괄적으로 진행 (그때그때 ❌)
Level 클래스 추가
각 레벨을 어떻게 저장할 지 생각해보자.
- 정수형(
int)으로 저장하는 방법.
⛔️ 범위를 벗어나는 값이 들어갈 수도 있음 Enum이용🗣 열거형(Enum)
✔️ Java5 이상부터 제공
✔️ 열거형으로 선언된 순서에 따라 0부터 인덱스 값을 가짐 (순차적으로 증가)
✔️ 열거형으로 지정된 상수들은 모두 대문자로 선언
✔️ 대표적인 메소드 3개 →values(),ordinal(),valueOf()
✔️ 열거체를 비교하는 과정에서 실제 값뿐만 아니라 타입까지 체크
✔️ 열거체의 상수값이 재정의되더라도 다시 컴파일할 필요 ❌
// Level.java
public enum Level {
BASIC(1), SILVER(2), GOLD(3); // 세개의 enum 객체를 정의한다.
private final int value;
Level(int value) { // DB에 저장할 값을 넣어줄 생성자를 만들어둔다.
this.value = value;
}
public int intValue() { // 값을 가져오는 메소드
return value;
}
public static Level valueOf(int value) { // 값을 받아 Level 타임의 enum 객체를 받아오도록 만든 메소드
switch (value) {
case 1: return BASIC;
case 2: return SILVER;
case 3: return GOLD;
default: throw new AssertionError("Unknown value: " + value);
}
}
}이렇게 만들어진 Level 타입의 enum은 내부에 DB 저장용 int 값을 가지고 있으면서도,
겉으로는 Level 타입이 되므로 타입 에러를 신경쓰지 않고도 사용할 수 있게 된다.
User 클래스 필드 추가
- Level 타입을 추가하고
- 앞서 언급된 로그인 횟수와 추천수도 추가한다 (
int)
⚠️ JDBC의 SQL 사용 시 주의할 점
JDBC Template으로 들어가는 SQL문은 컴파일 과정에서 단순 문자열로 취급된다.
즉, 컴파일 단계에서 쿼리의 유효성을 검증할 수 없다는 의미이다.
쿼리문에 오타가 생겨도 컴파일 과정에서는 오류가 나지 않으므로 SQL 에러를 잡아낼 수가 없다.
따라서 DB 접근 기능을 추가할 때에는 SQL 문장의 유효성을 검증하는 테스트를 만들어 미리 실행해볼 필요가 있다.
사용자 수정 기능을 추가해보자
사용자 관리 비즈니스 로직에 따르면 사용자 정보는 여러 번 수정될 수 있다.
- 수정할 정보가 담긴 User 객체를 전달하면
- id를 참고해서 사용자를 찾고
- 필드 정보를 UPDATE문으로 모두 변경시켜주는
update()메소드를 만들어보자.
update()
우리가 추가해야 할, 수정을 위한 update() 메소드에게는 두 가지의 미션이 있다.
- 수정하고자 하는 User 객체를 찾아 그 객체의 값만 변경시켜야 하며,
- 변경사항이 있는 row의 값만 변경시키고 수정하지 않아야 할 row의 내용은 그대로 유지되어야 한다.
1번은 메소드 파라미터로 넣어주면 되지만, 2번은 어떻게 확인할 수 있을까?
- 첫 번째 방법은 JdbcTemplate의
update()가 돌려주는 리턴 값을 확인하는 것이다.
JdbcTemplate의 update()는 UPDATE나 DELETE 같이 테이블의 내용에 영향을 주는 SQL을 실행하면 영향을 받은 row의 개수를 돌려주므로,
UserDao의 add(), deleteAll(), update() 메소드의 리턴 타입을 int로 바꿔 이 값이 1인지를 검사하는 방법이 있다.
- 두 번째 방법은 테스트를 보강해서 원하는 사용자 외의 정보는 변경되지 않았음을 직접 확인하는 것이다.
수정할 사용자 (user1) 만 확인하던 기존의 테스트에 수정하지 않을 사용자 (user2) 를 추가해서,
수정이 이루어진 후 user2 객체의 리턴값에 변화가 생기지 않았음을 확인한다.
UserService.upgradeLevels() 메소드
매번 조건을 충족할 때마다 등급을 올려주는 것이 아닌,
주기적으로 조건 충족 여부를 검사하고 레벨을 조정하는 로직이다.
- UserDao의 getAll() 메소드로 사용자를 다 가져와서
- 사용자별로 레벨 업그레이드 작업을 진행
- UserDao의 update()를 호출해 DB에 결과를 넣어줌
이 로직을 담아줄 서비스 클래스인 UserService를 만든다.
클래스 이름이 서비스인 이유는, 비즈니스 로직 서비스를 제공한다는 의미에서다.
이제 upgradeLevels() 메소드를 위의 로직에 따라 코드로 구현해보자.
// UserService.java
public void upgradeLevels() {
List<User> users = userDao.getAll();
for (User user : users) {
Boolean changed = null;; // 레벨에 변화가 있었는지를 확인하는 플래그
if (user.getLevel() == Level.BASIC && user.getLogin() >= 50 {
user.setLevel(Level.SILVER); // BASIC -> SILVER 작업
changed = true;
}
else if (user.getLecle() == Level.SILVER && user.getRecommend() >= 30 {
user.setLevel(Level.GOLD);
changed = true;
}
else if (user.getLevel() == Level.GOLD) { changed = false; }
else { changed = false; }
if (changed) { userDao.update(user); } // 레벨의 변경이 있는 경우에만 update() 호출
}
}먼저 모든 사용자 정보를 DAO에서 가져온 후. 한 명씩 레벨 변경 작업을 수행한다.
이때 변경 플래그를 설정하고, 변경된 경우에만 update()로 DB 호출하도록 한다.
테스트 설정은
- 적어도 가능한 모든 조건을 하나씩 확인
- GOLD를 제외한 BASIC과 SILVER 레벨의 변경 시나리오를 등록해두고 결과를 확인할 것
- BASIC/SILVER 레벨의 사용자는 업그레이드 기준이 되는 조건의 경계값 전후로 두 개씩 등록
add() 메소드
하지만 아직 비즈니스 로직에서 구현되지 않은 것이 남았다.
처음 가입하는 사용자는 BASIC 레벨이 되도록 해야 한다는 것이다.
이 로직 또한 UserService 클래스에 담는 것이 좋을 것이다.
-
테스트를 먼저 만들어보자.
이미 레벨이 GOLD인 사용자와, 레벨이null인 사용자 객체 두개를 준비한다.
준비한 두 개의 사용자 객체를UserService.add()메소드를 통해 초기화한 뒤에 DB에 저장하도록 한다.
-
다음은 이 테스트를 성공하게 할 add() 메소드를 만든다.
public void add(User user) { if (user.getLevel() == null) user.setLevel(Level.BASIC); userDao.add(user); }
리팩토링
아래와 같은 질문을 토대로 코드를 리팩토링해보자.
- 코드에 중복된 부분은 없는지
- 코드의 기능을 이해하기에 불편하지는 않은지
- 코드가 자신이 있어야 할 자리에 있는지
(→ 서비스 코드가 컨트롤러에 가 있진 않는지… 그런 걸 의미하는 것 같아요) - 변경이 일어날 수 있는 사항과, 그 변화에 쉽게 대응할 수 있는지
- 먼저 업그레이드가 가능한지 확인하는 메소드를 분리한다 (
canUpgradeLevels)
주어진 user에 대해 업그레이드가 가능하면 true, 가능하지 않으면 false를 리턴하면 된다.
업그레이드 가능 유무를 확인하는 방법은 다음과 같다.
User객체에서 레벨을 가져와- switch문으로 레벨을 구분하고 업그레이드 조건을 만족하는지 확인한 후,
- 로직에서 처리할 수 없는 경우 예외를 던진다.
- 다음으로 업그레이드 조건을 만족했을 경우의 다음 액션을 담은 메소드를 분리한다 (
upgradeLevel())
- 사용자의 레벨을 변경해주고
- 변경사항을 DB에 업데이트해주는 작업이 필요하다.
- 작업이 추가될 수도 있다.
업그레이드에 대한 안내 메일을 보낸다거나, 로그를 남기거나, 관리자에게 통보를 해준다거나…
업그레이드 작업을 하는 메소드를 분리해두면 나중에 작업이 추가되더라도 수정이 용이해진다.
하지만 여기까지 하면 로직이 너무 노골적으로 드러나고, 예외 처리가 되어있지 않다.
-
레벨의 순서와 다음 단계 레벨이 무엇인지를 결정하는 일을
enum인 Level 클래스로 분리한다.public enum Level { GOLD(3, null), SILVER(2, GOLD), BASIC(1,SILVER); // enum 선언에 DB에 저장할 값과 + 다음 단계 레벨의 정보를 함께 추가한다. ... // 다음 단계를 알려주는 생성자도 추가한다. public Level nextLevel() { return this.next; } }
Level enum에 next라는 다음 단계 레벨 정보를 담을 수 있도록 필드를 추가하고,
nextLevel이라는 생성자를 추가해 다음 레벨이 뭔지 알 수 있게 해준다.
- 이번에는 사용자 정보가 바뀌는 부분을 UserService에서 User로 옮겨본다.
User 내부의 정보가 변경되는 건 UserService보다는 User가 스스로 다루는 게 적절하다.
UserService가 일일이 User 필드를 수정하는 것보다,
User에게 레벨 업그레이드를 위한 정보 변경을 요청하는 편이 낫다.
// User.java
public void upgradeLevel() {
// 일단 다음 레벨이 무엇인지 확인하고
Level nextLevel = this.level.nextLevel();
// 예외처리
if (nextLevel == null) {
throw new IllegalStateException(this.level + "은 업그레이드가 불가능합니다.");
} else this.level = nextLevel;
} // UserService.java
private void upgradeLevel(User user) {
user.upgradeLevel();
userDao.update(user);
}📌 트랜잭션 서비스 추상화
정기적으로 레벨 관리 작업을 수행하던 중 네트워크가 끊기거나 서버에 장애가 생긴다면?
그때까지 변경된 사용자의 레벨은 그대로 두어야 할까, 아니면 모두 초기 상태로 돌려놓아야 할까.
레벨 업그레이드 중 장애 발생으로 인해 시스템 예외가 던져진 상황을 가정해보자.
모 아니면 도.
업그레이드는 성공하거나, 실패할 거면 아예 실패해서 원래 상태로 돌아가야 한다.
하지만, 우리가 지금까지 만들어온 upgradeLevels() 메소드는 하나의 트랜잭션 안에서 동작하지 않는다.
따라서 장애가 발생했을 때 서비스가 완전히 중단되어 원래 상태로 돌아가지 않을 것이다.
이런 상황에 대비해 트랜잭션의 경계 설정이 필요하다.
트랜잭션 경계 설정
트랜잭션이란 더 이상 나눌 수 없는 단위 작업을 말한다.
작업을 쪼개서 작은 단위로 만들 수 없다는 것은 트랜잭션의 핵심 속성인 원자성을 의미한다.
DB는 그 자체로 완벽한 트랜잭션을 지원한다.
SQL을 이용해 다중 로우의 수정이나 삭제 요청을 했을 때,
일부 로우만 삭제되고 안 된다거나, 일부 필드는 수정했는데 나머지 필드는 수정이 안 되고 실패로 끝나는 경우는 없다.
하나의 SQL 명령을 처리하는 자체로 DB가 트랜잭션을 보장해준다고 믿을 수 있다.
하지만 여러 개의 SQL이 사용되는 작업을 하나의 트랜잭션으로 취급해야 하는 경우도 있다.
이때 여러 가지 작업이 하나의 트랜잭션이 되기 위한 조건에 대해 생각해보자.
문제가 발생하면, 두 번째 이후의 SQL이 DB에서 수행되기 전에 앞에서 처리한 SQL 작업도 취소시켜야 한다.
이런 취소 작업을 트랜잭션 롤백(transaction rollback)이라 한다.
반대로 여러 개의 SQL을 하나의 트랜잭션으로 처리하는 경우,
모든 SQL 수행이 다 성공적으로 마무리됐음을 DB에 알려주어 작업을 확정시켜야 한다.
이것을 트랜잭션 커밋(transaction commit)이라고 한다.
모든 트랜잭션은 시작하는 지점과 끝나는 지점이 있다.
시작하는 방법은 한가지이지만, 끝나는 방법은 두 가지다.
- 모든 작업을 무효화하는
롤백과, - 모든 작업을 다 확정하는
커밋
이다.
애플리케이션에서 트랜잭션이 시작되고 끝나는 위치를 트랜잭션의 경계라 부른다.
예시 - JDBC 트랜잭션의 트랜잭션 경계 설정
JDBC의 트랜잭션은 하나의 Connection을 가져와 사용하다가 닫는 사이에 일어난다.
트랜잭션의 시작과 종료는 Connection 오브젝트를 통해 이루어지기 때문이다.
💡 JDBC의 기본 설정은 DB 작업을 수행한 직후에 자동으로 커밋이 되도록 되어 있다.
트랜잭션이 한 번 시작되면commit()또는rollback()메소드가 호출될 때까지의 작업이
하나의 트랜잭션으로 묶인다.
commit() 또는 rollback()이 호출되면 그에 따라 작업 결과가 DB에 반영되거나 취소되고 트랜잭션이 종료된다.
이때
- setAutoCommit(false)로 트랜잭션의 시작을 선언하고
- commit() 또는 rollback()으로 트랜잭션을 종료하는
작업을 트랜잭션의 경계설정(transaction demarcation)이라 한다.
트랜잭션의 경계는 하나의 Connection이 만들어지고 닫히는 범위 안에 존재한다는 점을 기억하자.
이렇게 하나의 DB 커넥션 안에서 만들어지는 트랜잭션을 로컬 트랜잭션(local transaction)이라고도 한다.
⚠️ 지금까지의 트랜잭션 문제
앞서 만든 UserService의 upgradeLevels()가 장애를 겪게 되면 완전한 커밋이나 롤백이 불가능했다.
이유는 트랜잭션의 경계설정을 하지 않았기 때문이다.
JdbcTemplate을 사용하기 시작하면서 Connection 객체의 존재를 잊었던 우리.
여기서 트랜잭션 경계설정을 해본다면 어떻게 될까?
public void upgradeLevels() throws Exception {
(1) DB 커넥션 생성
(2) 트랜잭션 시작
try {
(3) DAO 메소드 호출
(4) 트랜잭션 커밋
} catch (Exception e) {
(5) 트랜잭션 롤백
throw e;
} finally {
(6) DB 커넥션 종료
}
}트랜잭션을 사용하는 전형적인 JDBC 코드의 구조다.
하지만 이 경우 UserService에서 만든 Connection 객체를 UserDao에서 사용하기 위해서는 DAO 메소드를 호출할 때마다 Connection 객체를 파라미터로 전달해줘야 한다는 문제점이 생긴다.
비즈니스 로직 내의 트랜잭션 경계설정
UserService와 UserDao를 그대로 둔 채로 트랜잭션을 적용하려면,
결국 트랜잭션의 경계설정 작업을 UserService 쪽으로 가져와야 한다.
UserDao가 가진 SQL이나 JDBC API를 이용한 데이터 엑세스 코드는 최대한 그대로 남겨두되,
UserService에는 트랜잭션 시작과 종료를 담당하는 최소한의 코드만 가져오게 만드는 것이다.
이렇게 하면 어느 정도 책임이 다른 코드를 분리해 둔 채로 트랜잭션 문제를 해결할 수 있다.
하지만 이 경우 다음과 같은 문제점이 발생한다.
JdbcTemplate을 더 이상 활용할 수 없음- DAO 메소드와 비즈니스 로직을 담고 있는 UserService 단의 메소드에 Connection 파라미터 추가
- Connection 파라미터가 UserDao 인터페이스 메소드에 추가되었으므로,
UserDao는 더 이상 데이터 액세스 기술에 독립적일 수가 없음
트랜잭션 동기화
Connection을 파라미터로 직접 전달해야 하는 문제점을 해결해보자
upgradeLevels() 메소드가 트랜잭션 경계설정을 해야 한다는 사실은 피할 수 없다.
따라서 그 안에서 Connection을 생성하고 트랜잭션 시작과 종료를 관리하게 한다.
대신 그 안에서 생성된 Connection을 계속 파라미터로 전달해야 한다거나 DAO 호출용으로 사용하는 걸 피하고 싶으므로 트랜잭션 동기화 기법을 사용한다.
트랜잭션 동기화란,
UserService에서 트랜잭션을 시작하기 위해 만든 Connection 객체를 특별한 저장소에 보관해두고,
이후에 호출되는 DAO의 메소드에서는 저장된 Coonection을 가져다가 사용하게 하는 것이다.
트랜잭션 동기화 저장소는 작업 스레드마다 독립적으로 Connection 객체를 저장하고 관리하기 때문에 다중 사용자를 처리하는 서버의 멀티스레드 환경에서도 충돌이 날 염려는 없다.
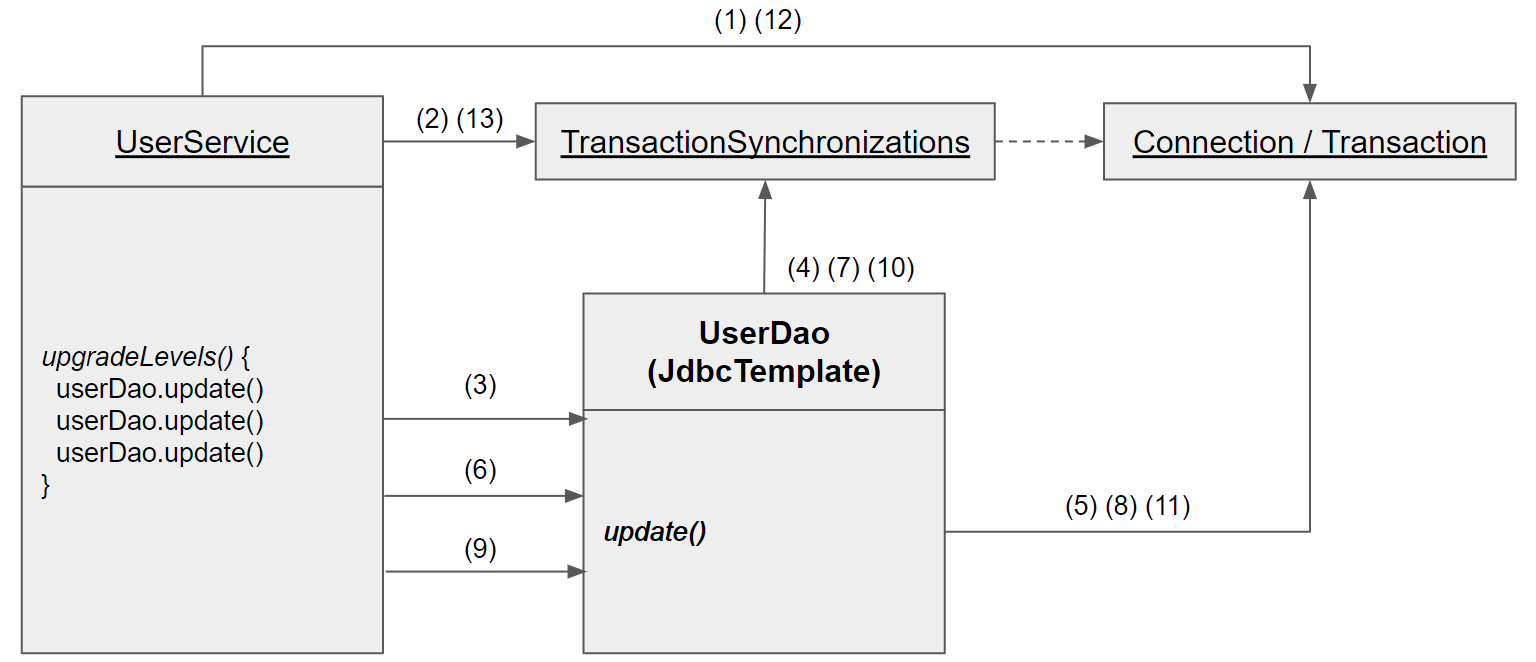
(1):UserService가Connection을 생성한다.(2): 생성한Connection을 트랜잭션 동기화 저장소에 저장한다.
이후에Connection의setAutoCommit(false)를 호출해 트랜잭션을 시작시킨다.(3): 첫 번째update()메소드를 호출한다.(4):update()메소드 내부에서 이용하는JdbcTemplate이 트랜잭션 동기화 저장소에 현재 시작된 트랜잭션을 가진Connection객체가 존재하는지 확인한다.
((2)단계에서 만든Connection객체를 발견할 것이다.)(5): 발견한Connection을 이용해PreparedStatement를 만들어 SQL을 실행한다.
트랜잭션 동기화 저장소에서 DB 커넥션을 가져왔을 때는JdbcTemplate은Connection을 닫지 않은채로 작업을 마친다.
이렇게 첫번째 DB 작업을 마쳤고, 트랜잭션은 아직 닫히지 않았다.
여전히 Connection은 트랜잭션 동기화 저장소에 저장되어 있다.
(6): 동일하게userDao.update()를 호출한다.(7): 트랜잭션 동기화 저장소를 확인하고Connection을 가져온다.(8): 발견된Connection으로 SQL을 실행한다.(9):userDao.update()를 호출한다.(10): 트랜잭션 동기화 저장소를 확인하고Connection을 가져온다.(11): 가져온Connection으로 SQL을 실행한다.(12):Connection의commit()을 호출해서 트랜잭션을 완료시킨다.(13):Connection을 제거한다.
위 과정 중 예외가 발생하면, commit()은 일어나지 않고 트랜잭션은 rollback()된다.
✨ 트랜잭션 동기화의 장점
→ 파라미터를 통해 일일이 Connection을 전달할 필요가 없어진다.
트랜잭션의 경계설정이 필요한 Service에서만 Connection을 다루게 하고,
여기에 생성된 Connection과 트랜잭션을 DAO의 JdbcTemplate이 사용할 수 있도록 별도의 저장소에 동기화하면 된다.
더 이상 메소드에 Connection 타입의 파라미터가 전달될 필요도 없고,
UserDao의 인터페이스에도 일일이 JDBC 인터페이스인 Connection을 사용한다고 노출할 필요가 없다.
스프링의 트랜잭션 서비스 추상화
💡 추상화
하위 시스템의 공통점을 뽑아내서 분리시키는 것.
그렇게 하면 하위 시스템이 어떤 것인지는 알지 못해도,
또는 하위 시스템이 바뀌더라도 일관된 방법으로 접할 수 있다.
💡 자바의 JTA(Java Transaction API)
→ JDBC 외에도 글로벌 트랜잭션을 지원하는 트랜잭션 매니저를 다루는 API
트랜잭션 매니저는 DB와 메시징 서버를 제어하고 관리하는 각각의 리소스 매니저와 XA 프로토콜을 통해 연결된다.
이를 통해 트랜잭션 매니저가 실제 DB와 메시징 서버의 트랜잭션을 종합적으로 제어할 수 있게 된다.
이렇게 JTA를 이용해 트랜잭션 매니저를 활용하면 여러 개의 DB나 메시징 서버에 대한 작업을 하나의 트랜잭션으로 통합하는 분산 트랜잭션 또는 글로벌 트랜잭션이 가능해진다.
스프링은 트랜잭션 기술의 공통점을 담은 트랜잭션 추상화 기술을 제공한다.
이를 이용하면 애플리케이션에서 직접 각 기술의 트랜잭션 API를 이용하지 않고도,
일관된 방식으로 트랜잭션을 제어하는 트랜잭션 경계설정 작업이 가능해진다.
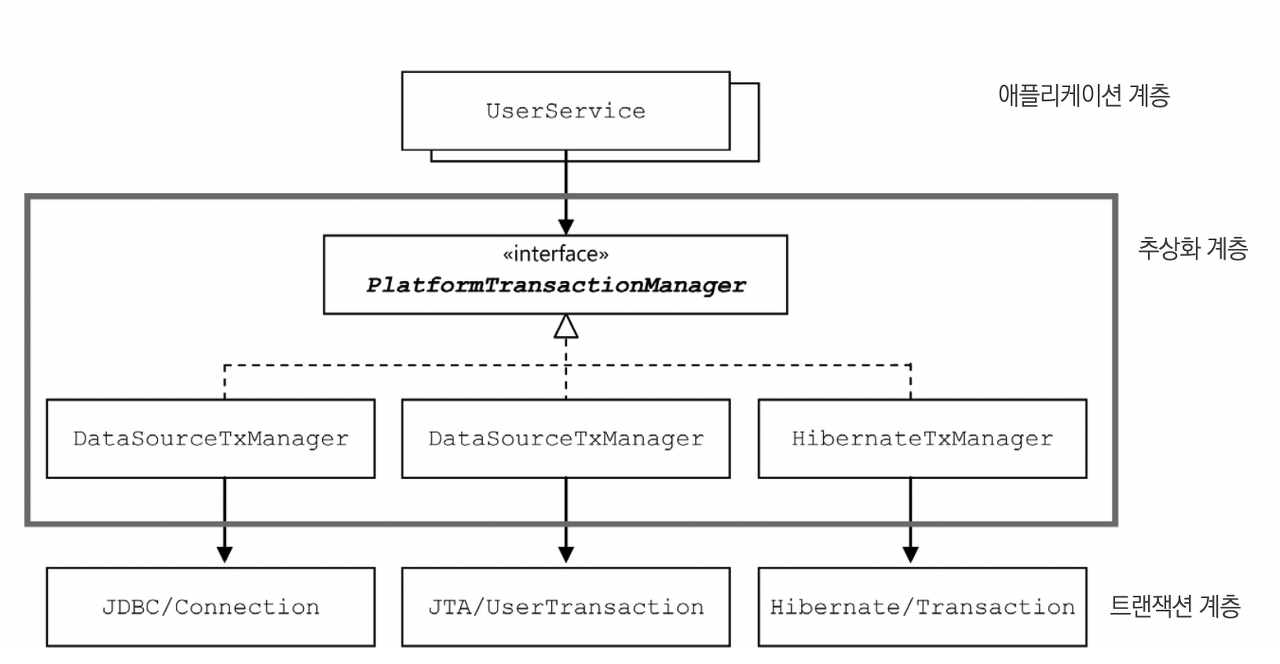
스프링의 트랜잭션 추상화 계층을 나타내면 위 그림과 같다.
이를 UserService에 적용해보면 다음과 같다.
// UserService.java
public void upgradeLevels() {
// DataSourceTransactionManager 객체 만들기
PlatformTransactionManager transactionManager = new DataSourceTransactionManager(dataSource);
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
List<User> users = userDao.getAll();
for (User user : users) {
if (canUpgradeLevel(user)) {
upgradeLevel(user);
}
}
transactionManager.commit(status);
} catch (RuntimeException e) {
transactionManager.rollback(status);
throw e;
}
}- 스프링이 제공하는 트랜잭션 경계설정을 위한 추상 인터페이스는
PlatformTransactionManager다. JDBC의 로컬 트랜잭션을 이용한다면 PlatformTransactionManager를 구현한DataSourceTransactionManager를 사용하면 된다. 사용할 DB의 DataSource를 생성자 파라미터로 넣으면서 DataSourceTransactionManager의 객체를 만든다.
- JDBC를 이용하는 경우에는 먼저 Connection을 생성하고 나서 트랜잭션을 시작했다. 하지만 PlatformTransactionManager에서는 트랜잭션을 가져오는 요청인
getTransation()메소드를 호출하기만 하면 된다. 필요에 따라 트랜잭션 매니저가 DB 커넥션을 가져오는 작업도 같이 수행해주기 때문이다. (여기서 트랜잭션을 가져온다는 것은 일단 트랜잭션을 시작한다는 의미라고 생각) 파라미터로 넘기는DefaultTransactionDefinition객체는 트랜잭션에 대한 속성을 담고 있다.
- 이렇게 시작된 트랜잭션은 TransactionStatus 타입의 변수에 저장된다. TransactionStatus는 트랜잭션에 대한 조작이 필요할 때 PlatformTransactionManager 메소드의 파라미터로 전달해주면 된다.
- 트랜잭션이 시작됐으니 이제 JdbcTemplate을 사용하는 DAO를 이용하는 작업을 진행한다. 스프링의 트랜잭션 추상화 기술은 앞에서 적용해봤던 트랜잭션 동기화를 사용한다. PlatformTransactionManager로 시작한 트랜잭션 동기화 저장소에 저장된다.
- PlatformTransactionManager를 구현한 DataSourceTransactionManager 객체는 JdbcTemplate에서 사용될 수 있는 방식으로 트랜잭션을 관리해준다. 따라서 PlatformTransactionManager를 통해 시작한 트랜잭션은 UserDao의 JdbcTemplate 안에서 사용된다.
트랜잭션 기술 설정의 분리
JTATransactionManager는 주요 자바 서버에서 제공하는 JTA 정보를 JNDI를 통해 자동으로 인식하는 기능을 갖고 있다.
따라서 별다른 설정 없이 JTATransactionManager를 사용하는 것만으로도 서버의 트랜잭션 매니저/서비스와 연동하여 동작한다.
💡 JtaTransactionManager은 애플리케이션 서버의 트랜잭션 서비스를 이용하므로 직접 DataSource와 연동할 필요는 없다.
대신 JTA를 사용하는 경우는 DataSource도 서버가 제공해주는 것으로 사용해야 한다.
💡 DAO를 Hibernate나 JPA, JDO 등을 사용하도록 수정했다면,
그에 맞게 transactionManager의 클래스만 변경해주면 된다.
UserService의 코드는 수정할 필요가 없다.
하지만, 어떤 트랜잭션 매니저 구현 클래스를 사용할지 UserService 코드가 알고 있는 것은 DI 원칙에 위배된다.
자신이 사용할 구체적인 클래스를 스스로 결정하고 생성하지 말고,
컨테이너를 통해 외부에서 제공받게 하는 스프링 DI의 방식으로 바꾸자.
📌 서비스 추상화와 단일 책임 원칙
수직, 수평 계층구조와 의존관계
애플리케이션 로직의 종류에 따른 수평적인 구분이든, 로직과 기술이라는 수직적인 구분이든 모두 결합도가 낮다.
서로 영향을 주지 않고 자유롭게 확장될 수 있는 구조를 만들 수 있는 데는 스프링의 DI가 중요한 역할을 하고 있다.
DI의 가치는 이렇게 관심, 책임, 성격이 다른 코드를 깔끔하게 분리하는 데 있다.
단일 책임 원칙
객체지향 설계의 원칙 중의 하나인 단일 책임 원칙(Single Responsibility Principle)에 대해 알아보자.
단일 책임 원칙은 하나의 모듈은 한 가지 책임을 가져야 한다는 의미다.
하나의 모듈이 바뀌는 이유는 한 가지여야 한다고 설명할 수도 있다.
단일 책임 원칙을 잘 지키고 있다면, 어떤 변경이 필요할 때 수정대상이 명확해진다.
기술이 바뀌면 기술 계층과의 연동을 담당하는 기술 추상화 계층의 설정만 바꿔주면 된다.
데이터를 가져오는 테이블의 이름이 바뀌었다면, 데이터 액세스 로직을 담고 있는 UserDao를 변경하면 된다.
비즈니스 로직도 마찬가지다.
적절하게 책임과 관심이 다른 코드를 분리하고,
서로 영향을 주지 않도록 다양한 추상화 기법을 도입하고,
애플리케이션 로직과 기술/환경을 분리하는 등의 작업을 위한 핵심적인 도구가 바로 스프링 DI다.
🌱 의존관계 주입 (DI)
DI는 모든 스프링 기술의 기반이 되는 핵심엔진이자 원리이며, 스프링의 가장 중요한 도구다.
스프링을 DI 프레임워크라고 부르는 이유는 외부 설정을 주입하는 단순한 기능 때문이 아니다.
자바 엔터프라이즈 기술의 많은 문제를 해결하기 위해 DI의 원칙을 적극적으로 활용하고 있기 때문이다아무리 추상화 기법을 통해 책임과 관심이 다른 코드를 분리하더라도,
적절하게 DI가 이루어지지 않으면 여전히 코드 사이의 결합이 남게 된다.⚠️ 단, 어떤 클래스든 스프링의 빈으로 등록할 때 먼저 검토해야 할 것은
싱글톤으로 만들어져 여러 스레드에서 동시에 사용해도 괜찮은가 하는 점이다.
상태를 갖고 있고, 멀티스레드 환경에서 안전하지 않은 클래스를 빈으로 무작정 등록하면
심각한 문제가 발생한다.
📌 메일 서비스 추상화
→ 등급이 변경되면, 메일을 보내주는 서비스를 추가해줘.
TO-DO
- User에 Email 필드를 추가해야 함.
- UserService의 upgradeLevel()에 메일 발송 기능 추가해야 함.
자바에서 메일을 발송할 때에는, Java 표준인 JavaMail을 사용하면 된다.
// UserService.java
// 한글 encoding 설정은 생략
private void sendUpgradeEmail(User user) {
Properties props = new Properties();
props.put("mail.smtp.host", "mail.ksug.org");
Session s = Session.getInstance(props, null);
MimeMessage message = new MimeMessage(s);
try {
message.setFrom(new InternetAddress("useradmin@ksug.org"));
message.addRecipient(Message.RecipientType.TO, new InternetAddress(user.getEmail()));
message.setSubject("Upgrade 안내");
message.setText("사용자님의 등급이" + user.getLevel().name() + "로 업그레이드 되었습니다.");
} catch (AddressException e) {
throw new RuntimeException(e);
} catch (MessagingException e) {
throw new RuntimeException(e);
}
}SMTP 프로토콜을 지원하는 메일 서버가 있다면, 안내 메일은 잘 작동될 것이다.
테스트와 서비스 추상화
일반적으로 추상화는 ‘수행하는 기능은 같지만, 로우레벨에서의 구현이 다른 트랜잭션이나 다양한 기술에 대해 일관적인 사용법을 제공하기 위한 접근 방법’을 의미하지만,
확장이 불가능하게 설계된 JavaMail과 같이 테스트가 어려운 API의 테스트에도 추상화 개념을 유용하게 사용할 수 있다.
스프링은 이러한 경우에 대비해
MailSender라는 인터페이스를 제공한다.
package org.springframework.mail;
//https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/mail/MailSender.html
public interface MailSender{
void send(SimpleMailMessage simpleMessage) throws MailException;
void send(SimpleMailMessage[] simpleMessage) throws MailException;
// MailException은 RuntimeException이므로 try/catch 블록 처리를 하지 않아도 된다.
}// UserService.java
private MailSender mailSender;
public void setMailSender(MailSender mailSender) {
this.mailSender = mailSender;
}
private void sendUpgradeEMail(User user) {
SimpleMailMessage mailMessage = new SimpleMailMessage();
mailMessage.setTo(user.getEmail());
mailMessage.setFrom("useradmin@ksug.org");
mailMessage.setSubject("Upgrade 안내");
mailMessage.setText("사용자님의 등급이 " + user.getLevel().name());
this.mailSender.send(mailMessage);
}
protected void upgradeLevel(User user) {
user.upgradeLevel();
userDao.update(user);
sendUpgradeEMail(user); // 여기를 추가
}/*
JavaMail API를 대체하는 테스트용 오브젝트를 만들기 위해
JavaMailSenderImpl 대신 아무 일도 하지 않는 MailSender를 구현하도록 한다.
*/
public interface DummyMailSender implements MailSender{
void send(SimpleMailMessage simpleMessage) throws MailException{
//Do Nothing
}
void send(SimpleMailMessage[] simpleMessage) throws MailException{
}
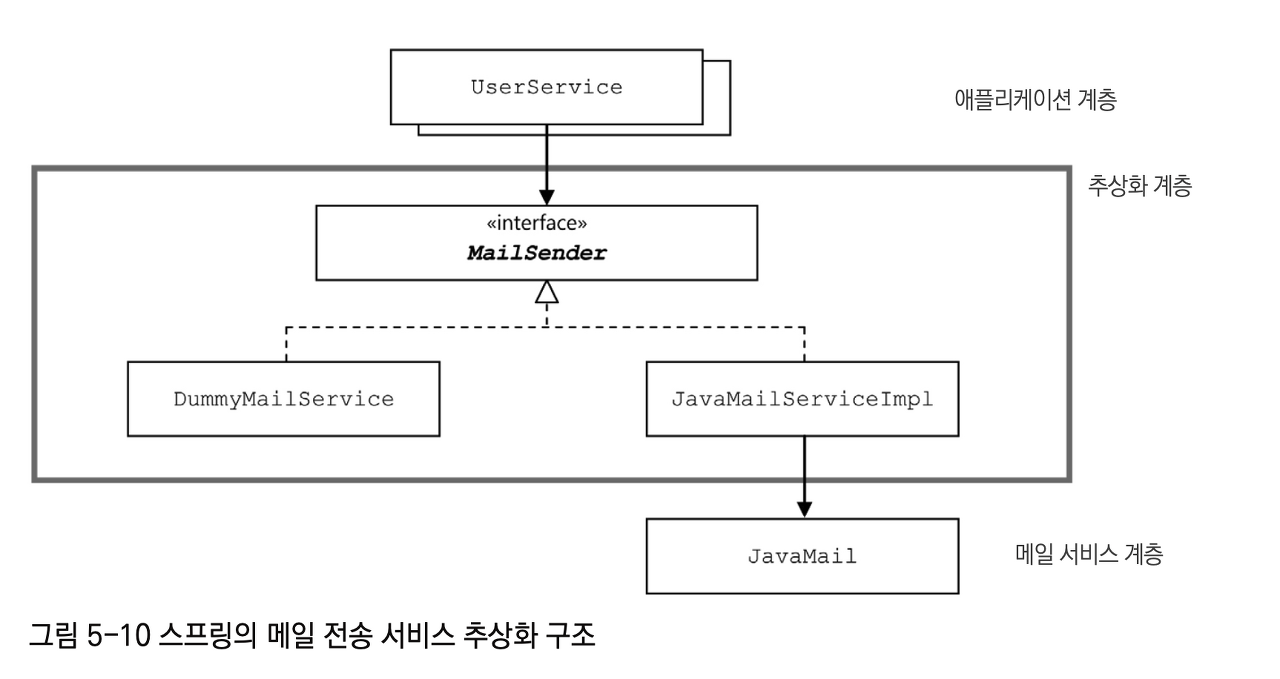
}
-
스프링이 제공하는 MailSender를 구현한 추상화 클래스를 이용하면,
JavaMail이 아닌 다른 메세징 서버 API를 이용하더라도, MailSender를 구현한 클래스를 만들어 DI 해주는 것으로 적용이 가능해진다. -
UserService에서는 그냥 MailSender 인터페이스를 통해 메일을 보낸다는 사실만 알면 된다.
MailSender을 구현한 클래스가 바뀌더라도 새로 주입만 해주면 되므로 편리하다.
그리고 만약 DB의 트랜잭션 개념을 메일에 적용한다면,
-
메일을 업그레이드할 유저 목록을 별도로 저장하고,
업그레이드 작업이 성공적으로 끝났을 때 한번에 전송하도록 한다. -
유사 트랜잭션을 구현한다.
send() 메소드를 호출하더라도 실제 메일은 발송하지 않고 있다가 작업이 끝나면 메일을 모두 발송하고,
예외가 발생한다면 메일 발송을 취소하는 방법으로 구현한다.
이렇게 MailSender 인터페이스를 이용하면 변경이 자유로워진다는 장점이 있다.
이처럼 외부 리소스를 연동하는 모든 작업은 추상화의 대상이 될 수 있다.
테스트 대역의 종류와 특징
테스트 환경에서 테스트 대상이 되는 객체의 기능을 충실하게 수행하면서,
테스트를 자주 실행할 수 있도록 하는 객체를 테스트 대역(Test Double)이라고 한다.
테스트가 관심을 가지는 대상 객체의 의존 객체로 존재하면서 테스트가 정상적으로 수행될 수 있도록 돕는 것을 테스트 스텁(Test Stub)이라 한다.
앞에서 본 DummyMailSender이 이에 해당한다.
메일 서버가 구비되지 않은 상황에서 실제 메일을 발송할 주소가 존재하지 않아 생기는 예외들 때문에 테스트를 진행할 수 없었을 것이다.⚠️ 만약 테스트 스텁의 메소드들이 리턴값을 가질 경우 특정 값을 리턴해줘야 한다.
MailSender처럼 호출만 하면 그만인 것도 있지만,
리턴값이 있는 메소드를 이용하는 경우 테스트 스텁에 필요한 정보를 리턴하도록 구현해야 한다.
Mock 객체
스텁처럼 테스트 객체가 정상적으로 실행되도록 도와주면서,
테스트 객체와 자신 사이에서 일어나는 커뮤니케이션 내용을 저장해줬다가 테스트 결과를 검증하는 데 활용할 수 있게 해주는 역할.
테스트는 테스트의 대상이 되는 객체에 직접 입력 값을 제공하고, 테스트 객체의 리턴값으로 결과를 확인하기도 한다.
테스트 대상이 받게 될 입력 값을 제어하면서 그 결과가 어떻게 달라지는지 확인하기도 한다.
문제는 테스트 대상 객체는 테스트로부터만 입력을 받는 것이 아니라는 점이다.
테스트가 수행되는 동안 실행되는 코드는 테스트 대상이 의존하고 있는 다른 의존 객체와 커뮤니케이션하기도 한다.
때론 테스트 대상 객체가 의존 객체에게 출력한 값에 관심이 있을 경우가 있다.
또는 의존 객체를 얼마나 사용했는가 하는 커뮤니케이션 행위 자체에 관심이 있을 수가 있다.
문제는 이 정보는 테스트에서는 직접 알 수가 없다는 것이다.
이때는 테스트 대상과 의존 객체 사이에 주고받는 정보를 보존해두는 기능을 가진,
테스트용 의존 객체인 Mock 객체 (이하 목 객체) 를 만들어서 사용해야 한다.
테스트 대상 객체의 메소드 호출이 끝나고 나면 테스트는 목 객체에게 테스트 대상과 목 객체 사이에서 일어났던 일에 대해 확인을 요청해서, 그것을 테스트 검증 자료로 삼을 수 있다.
목 오브젝트를 이용한 테스트는 작성하기는 간단하면서도 기능은 막강하다.
보통의 테스트 방법으로는 검증하기가 매우 까다로운 테스트 객체 내부에서 일어나는 일이나,
다른 오브젝트 사이에서 주고받은 정보까지 검증하기 쉽기 때문이다.
📌 정리
- 비즈니스 로직을 담은 코드는 데이터 엑세스 로직을 담은 코드와 깔끔하게 분리되는 것이 바람직하다.
비즈니스 로직 코드 또한 내부적으로 책임과 역할에 따라서 깔끔하게 메소드로 정리돼야 한다. - 이를 위해서는 DAO의 기술 변화에 서비스 계층의 코드가 영향을 받지 않도록 인터페이스와 DI를 잘 활용하여 결합도를 낮춰줘야 한다.
- DAO를 사용하는 비즈니스 로직에는 단위 작업을 보장해주는 트랜잭션이 필요하다.
- 트랜잭션의 시작과 종료를 지정하는 일을 트랜잭션 경계설정이라고 한다.
트랜잭션 경계설정은 주로 비즈니스 로직 안에서 일어나는 경우가 많다. - 시작된 트랜잭션 정보를 담은 객체를 파라미터로 DAO에 전달하는 방법은 매우 비효율적이므로,
스프링이 제공하는트랜잭션 동기화기법을 활용하는 것이 편리하다. - 자바에서 사용되는 트랜잭션 API의 종류와 방법은 다양하다.
환경과 서버에 따라서 트랜잭션 방법이 변경되면 경계설정 코드도 함께 변경돼야 한다. - 트랜잭션 방법에 따라 비즈니스 로직을 담은 코드가 함께 변경되면
단일 책임 원칙에 위배되며,
DAO가 사용하는 특정 기술에 대해 강한 결합을 만들어낸다. - 트랜잭션 경계설정 코드가 비즈니스 로직 코드에 영향을 주지 않게 하려면 스프링이 제공하는
트랜잭션 서비스 추상화를 이용하면 된다. - 서비스 추상화는 로우레벨의 트랜잭션 기술과 API의 변화에 상관없이 일괄된 API를 가진 추상화 계층을 도입한다.
- 서비스 추상화는 테스트하기 어려운
JavaMail같은 기술에도 적용할 수 있다.
테스트를 편리하게 작성하도록 도와주는 것만으로도 서비스 추상화는 가치가 있다. - 테스트 대상이 사용하는 의존 객체를 대체할 수 있도록 만든 객체를
테스트 대역이라고 한다. - 테스트 대역은 테스트 대상 객체가 원활하게 동작할 수 있도록 도우면서 테스트를 위해 간접적인 정보를 제공해주기도 한다.
- 테스트 대역 중에서 테스트 대상으로부터 전달받은 정보를 검증할 수 있도록 설계된 것을
목 객체라고 한다.
