Introduction: SQL for Analysis and Reporting
행과 행간의 관계를 정의하는 SQL 표준 함수.
1. Ranking Functions
2. Reporting Functions
3. Windowing Functions
Syntax and Difference between rank() and dense_rank()
Syntax of the rank():
select rank() over(order by Criterion asc/desc) Alias(add'l)
Syntax of the dense_rank():
select dense_rank() over(order by Criterion asc/desc) Alias(add'l)
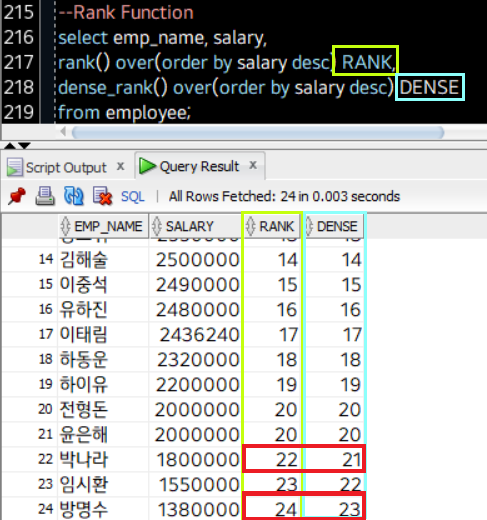
select emp_name, salary
rank() over(order by salary desc) RankAlias,
dense_rank() over(order by salary desc) DenseRankAlias
from employee;rank(), dense_rank() 두 함수 모두 후위에 붙는 over()에 Criterion, 즉 판별 조건을 인자로 받는다. 이 자리에는 order by Clause가 들어갈 수 있으며, order by절에 의해 리턴된 결과의 순서에 맞게 Rank가 정해진다. 예를 들어 rank() over(oder by salary asc) RankAlias를 선언한다고 해 보자. 리턴된 결과는 월급을 적게 받는 사람들의 순위를 나타낼 것이다. asc를 선언하여 오름차순으로 정렬하는 것을 순위매김의 기준으로 삼았기 때문에. 반대로 dense_rank() over(order by salary desc)로 작성했다고 해 보자. 이 번에는 월급을 많이 받는 사람들의 순위대로 1, 2...와 같이 매겨지게 된다.
또한 rank()와 dense_rank()에는 다음과 같은 결과상의 차이가 존재한다:
rank()는 판별시에 같은 판별값을 갖는 대상의 순위를 같은 것으로 판별하고, (즉 같은 값을 가진 대상에게 공동의 순위를 부여하고) 공동 인원 만큼의 순위를 지나쳐 다음 순위로 넘어간다. 그에 반해 dense_rank()는 같은 값을 가진 대상들에게 공동의 순위를 부여한다는 점은 같으나, 순위를 지나치지 않고 바로 그 차순을 부여한다. (주: dense는 밀집된, 빽빽한이라는 뜻이다. 참으로 직관적인 네이밍 센스가 아닌가 싶다!)
추가로 rank(), dense_rank() 자체적으로 그룹간 데이터 비교도 가능하다:
Syntax of the rank() with partition by:
rank() over(partition by Col order by Col asc/desc(add'l)) Alias(add'l)
Syntax of the dense_rank() with partition by:
dense_rank() over(partition by Col order by Col asc/desc(add'l)) Alias(add'l)
rank() over(partition by dept_code order by salary asc) R_PARTITION,
dense_rank() over(partition by dept_id order by salary desc) D_PARTITION 상기한 Criterion의 경우와 마찬가지로 rank()/dense_rank()의 후위에 위치하는 over()내에 인자로 선언해 주면 되며, partition by Col을 먼저 선언한 후 order by Col asc/desc에 해당하는 부분을 선언한다. 질리도록 많이 보았을 ORA-00979: not a GROUP BY expression, 즉 group by의 한계로 인해 발생하는 에러를 가볍게 넘길 수 있어 아주 좋은 방법이다.
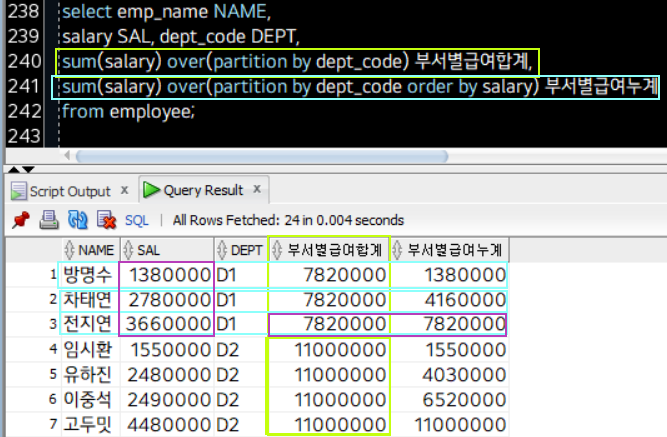
Syntax: sum/avg Function
Syntax of the sum Function:
select sum(Col) over(partition by Col) Alias(add'l)
select sum(Col) over(partition by Col order by Col asc/desc) Alias(add'l)
sum(salary) over(partition by dept_code)
sum(salary) over(partition by dept_code order by salary desc)sum()의 인자로는 합계를 낼 Column을 선언하고, over()의 인자로는 rank(), dense_rank()와 같이 partition by Col, order by Col을 받는다. 이 때, over(partition Col) 까지만 선언하게 되면 해당 Col 단위로 합산한(sum) "결과"를 행마다 리턴하며 이는 중복될 수 있고(Col단위 합계), over(partition Col1 order by Col2)까지 선언하면 Col1의 합계를 Col2를 기준으로 정렬하여 리턴하므로 Col1단위 Col2순 누계를 출력하게 된다.
Syntax of the avg Function:
select avg(Col) over(partition by Col) Alias(add'l)
select avg(Col1) over(partition by Col1 order by Col2) Alias(add'l)
trunc(avg(salary)) over(partition by dept_code)
trunc(avg(salary)) over(partition by dept_code order by salary)sum() over()와 동일한 방식으로 작동한다. avg() over(partition by Col)을 선언하면 Col단위의 "평균값 산출 결과"를 중복하여 매 행마다 리턴하고, avg() over(partition by Col1 order by Col2)까지 선언하면 Col1단위의 "평균값 산출 내역"을 Col2 기준으로 asc(오름차순)/desc(내림차순)하여 정렬한 값을 리턴한다.
