
배열이란?
배열은 여러 개의 값을 순차적으로 나열한 자료구조이다.
배열이 가지고 있는 값을 요소(element) 라고 부른다. 자바스크립트의 모든 값은 배열의 요소가 될 수 있다. 즉, 원시값은 물론 객체, 함수, 배열 등 자바스크립트에서 값으로 인정하는 모든 것은 배열의 요소가 될 수 있다.
배열의 요소는 배열에서 자신의 위치를 나타내는 0 이상의 정수인 인덱스(index) 를 갖는다. 인덱스는 배열의 요소에 접근할 때 사용하며 대부분의 프로그래밍 언어에서 인덱스는 0부터 시작한다.
요소에 접근할 때는 대괄호 표기법을 사용하며 대괄호 내에 접근하고 싶은 요소의 인덱스를 지정한다.
배열은 요소의 개수, 즉 배열의 길이를 나타내는 length 프로퍼티 를 갖는다. 그렇기에 인덱스와 함께 for 문을 통해 순차적으로 요소에 접근할 수 있다.
자바스크립트에 배열이라는 타입은 존재하지 않는다. 배열은 객체 타입이다.
배열은 배열 리터럴, Array 생성자 함수, Array.of, Array.from 메서드로 생성할 수 있다.
배열의 생성자 함수는 Array 이며, 배열의 프로토타입 객체는 Array.prototype 으로 배열을 위한 빌트인 메서드를 제공한다.
const arr = [1, 2, 3];
console.log(arr.constructor === Array); // true
console.log(Object.getPrototypeOf(arr) === Array.prototype);배열은 객체지만 일반 객체와는 구별되는 독특한 특징이 있다.

일반 객체와 배열을 구분하는 가장 명확한 차이는 값의 순서와 length 프로퍼티다. 이를 통해 배열은 반복문을 통해 순차적으로 값에 접근하기 적합한 자료구조이다.
배열의 장점은 처음부터 순차적으로 요소에 접근, 마지막부터 역순으로 요소에 접근, 특정 위치부터 순차적으로 요소에 접근이 가능하다는 장점이 있는데 이는 배열이 인덱스, 즉 값의 순서와 length 프로퍼티를 갖기 때문에 가능한 것이다.
자바스크립트 배열은 배열이 아니다.
자료구조에서 말하는 배열은 동일한 크기의 메모리 공간이 빈틈없이 연속적으로 나열된 자료구조를 말한다.
즉, 배열의 요소는 하나의 데이터 타입으로 통일되어 있으며 서로 연속적으로 인접해 있다. 이러한 배열을 밀집 배열(dense array) 이라 한다.

위와 같은 구조로 인해 인덱스를 통해 단 한 번의 연산으로 임의의 요소에 접근(O(1))할 수 있다.
하지만 정렬되지 않은 배열에서 특정한 요소를 검색하는 경우 모든 요소를 처음부터 검색하는 선형 검색(O(N))을 진행해야 한다.
또한 배열에 요소를 삽입하거나 삭제하는 경우 배열의 요소를 연속적으로 유지하기 위해 요소를 이동시켜야 하는 번거로움도 있다.
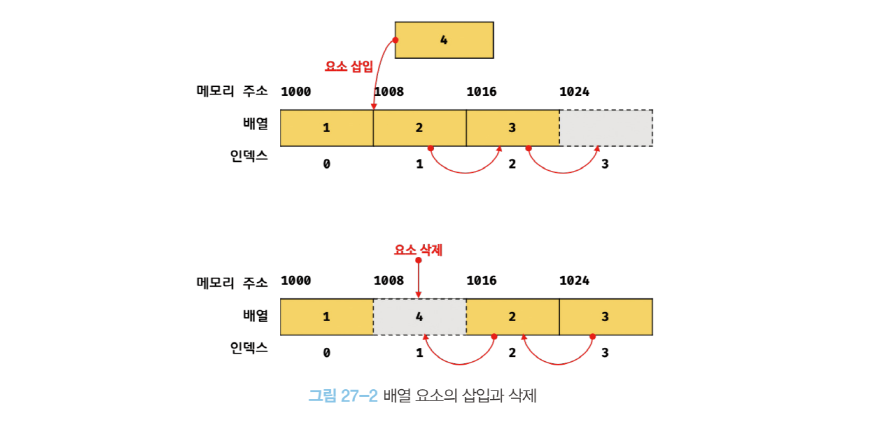
자바스크립트의 배열은 지금까지 살펴본 자료구조에서 말하는 일반적인 의미의 배열과 다르다.
배열의 요소를 위한 각각의 메모리 공간은 동일한 크기를 갖지 않아도 되며, 연속적으로 이어져 있지 않을 수도 있다.
배열의 요소가 연속적으로 이어져 있지 않는 배열을 희소 배열(sparse array) 이라 한다.
이처럼 자바스크립트의 배열은 엄밀히 말해 일반적 의미의 배열이 아니다. 자바스크립트의 배열은 일반적인 배열의 동작을 흉내 낸 특수한 객체다.
console.log(Object.getOwnPropertyDescriptors([1, 2, 3]));
/**
{
'0': { value: 1, writable: true, enumerable: true, configurable: true },
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'2': { value: 3, writable: true, enumerable: true, configurable: true },
length: { value: 3, writable: true, enumerable: false, configurable: false }
}
*/이처럼 자바스크립트 배열은 인덱스를 나타내는 문자열을 키로 가지며, length 프로퍼티를 갖는 특수한 객체다.
자바스크립트 배열의 요소는 사실 프로퍼티 값이다.
자바스크립트에서 사용할 수 있는 모든 값은 객체의 프로퍼티 값이 될 수 있으므로 어떤 타입의 값이라도 배열의 요소가 될 수 있는 것이다.
일반적인 배열은 인덱스로 요소에 빠르게 접근할 수 있지만, 특정 요소를 검색하거나 요소를 삽입 또는 삭제하는 경우에는 효율적이지 않다.
자바스크립트 배열은 해시 테이블로 구현된 객체이므로 인덱스로 요소에 접근하는 경우 일반적인 배열보다 성능적인 면에서 느릴 수밖에 없는 구조적인 단점이 있다.
하지만 특정 요소를 검색하거나 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠른 성능을 기대할 수 있다.
즉, 자바스크립트 배열은 인덱스로 배열 요소에 접근하는 경우에는 일반적인 배열보다 느리지만 특정 요소를 검색하거나 요소를 삽입 또는 삭제하는 경우에는 일반적인 배열보다 빠르다.
인덱스로 배열 요소에 접근할 때 일반적은 배열보다 느릴 수밖에 없는 구조적인 단점을 보완하기 위해 대부분의 모던 자바스크립트 엔진은 배열을 일반 객체와 구별하여 좀 더 배열처럼 동작하도록 최적화하여 구현했다.
일반 객체({})와 배열([])의 성능을 테스트해 보면 배열이 일반 객체보다 빠르게 동작한다.
length 프로퍼티와 희소 배열
length 프로퍼티는 요소의 개수, 즉 배열의 길이를 나타내는 0 이상의 정수를 값으로 갖는다. 값으로 빈 배열일 경우 0이며, 빈 배열이 아닐 경우 가장 큰 인덱스에 1을 더한 값과 같다.
length 프로퍼티의 값은 배열에 요소를 추가하거나 삭제하면 자동 갱신된다. 임의의 숫자 값을 명시적으로 할당할 경우 배열의 길이가 줄어들게 된다.
주의할 점은 length 프로퍼티 값보다 큰 숫자 값을 프로퍼티에 할당하는 경우이다.
const arr = [1];
arr.length = 3;
console.log(arr.length); // 3
console.log(arr); // [ 1, <2 empty items> ]length 프로퍼티 값이 변경되었지만 실제로 배열의 길이가 늘어나지는 않는다. empty items 는 실제로 추가된 배열의 요소가 아니다.
length 프로퍼티 값은 성공적으로 변경되었지만 실제로 배열에는 아무런 변함이 없다.
값 없이 비어 있는 요소를 위해 메모리 공간을 확보하지 않으며 빈 요소를 값으로 생성하지도 않는다.
이렇게 요소의 앞, 뒤 어느곳이든 요소가 연속적으로 위치하지 않고 일부가 비어 있는 배열인 희소 배열을 자바스크립트는 문법적으로 허용한다.
const sparse = [, 2, , 4];
// 희소 배열의 length 프로퍼티 값은 요소의 개수와 일치하지 않는다.
console.log(sparse.length); // 4
console.log(sparse); // [ <1 empty item>, 2, <1 empty item>, 4 ]
// 배열 sparse에는 인덱스가 0, 2인 요소가 존재하지 않는다.
console.log(Object.getOwnPropertyDescriptors(sparse));
/**
{
'1': { value: 2, writable: true, enumerable: true, configurable: true },
'3': { value: 4, writable: true, enumerable: true, configurable: true },
length: { value: 4, writable: true, enumerable: false, configurable: false }
}
*/일반적인 배열의 length는 배열 요소의 개수가 배열의 길이와 언제나 일치한다.
하지만 희소 배열은 length와 배열 요소의 개수가 일치하지 않는다. 희소 배열의 length는 희소 배열의 실제 요소 개수보다 언제나 크다.
이렇게 자바스크립트는 문법적으로 희소 배열을 허용하지만 희소 배열은 사용하지 않는 것이 좋다.
희소 배열은 연속적인 값의 집합이라는 배열의 기본적인 개념과 맞지 않으며, 성능에도 좋지 않은 영향을 준다.
배열에는 같은 타입의 요소를 연속적으로 위치시키는 것이 최선이다.
배열 생성
객체와 마찬가지로 배열도 다양한 생성 방식이 있다.
배열 리터럴
배열 리터럴은 0개 이상의 요소를 쉼표로 구분하여 대괄호([])로 묶는다. 배열 리터럴은 객체 리터럴과 달리 프로퍼티 키가 없고 값만 존재한다.
배열 리터럴에 요소를 하나도 추가하지 않으면 배열의 길이, length 프로퍼티 값이 0인 빈 배열이 된다.
배열 리터럴에 요소를 생략하면 희소 배열이 생성된다.
const arr = [1, 2, 3];
console.log(arr.length); // 3
const arr2 = [];
console.log(arr2.length); // 0
const arr3 = [1, , 3];
console.log(arr3.length); // 3
console.log(arr3); // [ 1, <1 empty item>, 3 ]
console.log(arr3[1]); // undefined, 빈 공간에 요소를 생성하지 않기 때문Array 생성자 함수
Array 생성자 함수는 전달된 인수의 개수에 따라 다르게 동작한다.
전달된 이수가 1개이고 숫자인 경우 length 프로퍼티 값이 인수인 배열을 생성한다.
이때 생성된 배열은 희소 배열로 length 프로퍼티 값은 0이 아니지만 실제로 배열의 요소는 존재하지 않는다.
const arr = new Array(10);
console.log(arr); // [empty × 10]
console.log(arr.length); // 10전달된 인수가 없는 경우 빈 배열을 생성하는데 배열 리터럴 []과 결과가 같다.
new Array(); // -> []전달된 인수가 2개 이상이거나 숫자가 아닌 경우 인수를 요소로 갖는 배열을 생성한다.
// 전달된 인수가 2개 이상이면 인수를 요소로 갖는 배열을 생성한다.
new Array(1, 2, 3); // -> [1, 2, 3]
// 전달된 인수가 1개지만 숫자가 아니면 인수를 요소로 갖는 배열을 생성한다.
new Array({}); // -> [{}]Array 생성자 함수는 new 연산자와 함께 호출하지 않더라도 new.target 을 확인하기 때문에 배열을 생성하는 생성자 함수로 동작한다.
Array(1, 2, 3); // -> [1, 2, 3]Array.of
ES6에서 도입된 Array.of 메서드는 전달된 인수를 요소로 갖는 배열을 생성한다.
Array 생성자 함수와 다르게 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
// 전달된 인수가 1개이고 숫자이더라도 인수를 요소로 갖는 배열을 생성한다.
Array.of(1); // -> [1]
Array.of(1, 2, 3); // -> [1, 2, 3]
Array.of("string"); // -> ['string']Array.from
ES6에서 도입된 Array.from 메서드는 유사 배열 객체 또는 이터러블 객체를 인수로 전달받아 배열로 변환하여 반환한다.
// 유사 배열 객체를 변환하여 배열을 생성한다.
Array.from({ length: 2, 0: "a", 1: "b" }); // ➔ ['a', 'b']
// 이터러블을 변환하여 배열을 생성한다. 문자열은 이터러블이다.
Array.from("Hello"); // ➔ ['H', 'e', 'l', 'l', 'o']유사 배열 객체는 마치 배열처럼 인덱스로 프로퍼티 값에 접근할 수 있고 length 프로퍼티를 갖는 객체를 말한다. 배열과 같이 for문으로 순회할 수도 있다.
const arrayLike = {
0: "apple",
1: "banana",
length: 2,
};
for (let i = 0; i < arrayLike.length; i++) {
console.log(arrayLike[i]);
}이터러블 객체는 Symbol.iterator 메서드를 구현하여 for...of 문으로 순회할 수 있으며, 스프레드 문법과 배열 디스트럭처링 할당의 대상으로 사용할 수 있는 객체를 말한다.
배열 요소의 참조
배열의 요소를 참조할 때에는 대괄호[]표기법 안에 참조할 인덱스를 가리킨다. 대괄호 안에는 인덱스가 와야 하는데 정수로 평가되는 표현식이라면 인덱스 대신 사용할 수 있다.
인덱스는 값을 참조할 수 있다는 의미에서 객체의 프로퍼티 키와 같은 역할을 한다.
존재하지 않는 요소에 접근하면 undefined 가 반환된다.
배열은 인덱스를 나타내는 문자열을 프로퍼티 키로 갖는 객체다. 존재하지 않는 프로퍼티 키로 객체의 프로퍼티에 접근하면 undefined 반환되는 것과 같은 원리로 배열 역시 undefined 가 반환되는 것이다.
const arr = [1, 2];
// 인덱스가 0인 요소를 참조
console.log(arr[0]); // 1
// 인덱스가 1인 요소를 참조
console.log(arr[1]); // 2
// 인덱스가 2인 요소를 참조
console.log(arr[2]); // undefined배열 요소의 추가와 갱신
객체에 프로퍼티를 동적으로 추가할 수 있는 것처럼 배열에도 요소를 동적으로 추가할 수 있다.
존재하지 않는 인덱스를 사용해 값을 할당하면 새로운 요소가 추가되며 이때 length 프로퍼티 값은 자동 갱신된다.
const arr = [0];
// 배열 요소의 추가
arr[1] = 1;
console.log(arr); // [0, 1]
console.log(arr.length); // 2
// length 프로퍼티 값보다 큰 인덱스로 새로운 요소 추가
arr[100] = 100;
console.log(arr); // [ 0, 1, <98 empty items>, 100 ]
console.log(arr.length); // 101
// 요소값의 갱신
arr[1] = 10;
console.log(arr); // [0, 10, empty × 98, 100]length 프로퍼티 값보다 큰 인덱스로 새로운 요소를 추가하면 희소 배열이 되며 이때 인덱스로 요소에 접근하여 명시적으로 값을 할당하지 않은 요소는 빈 값을 가지는 요소 자체가 생성되지 않는다는 것을 명심하자.
인덱스는 요소의 위치를 나타내므로 반드시 0 이상의 정수(또는 정수 형태의 문자열)를 사용해야 한다.
만약 정수 이외의 값을 인덱스처럼 사용하면 요소가 생성되는 것이 아니라 프로퍼티가 생성되는데 이때 추가된 프로퍼티는 length 프로퍼티 값에 영향을 주지 않는다.
const arr = [];
// 배열 요소의 추가
arr[0] = 1;
arr["1"] = 2;
// 프로퍼티 추가
arr["foo"] = 3;
arr.bar = 4;
arr[1.1] = 5;
arr[-1] = 6;
console.log(arr); // [1, 2, foo: 3, bar: 4, '1.1': 5, '-1': 6]
// 프로퍼티는 length에 영향을 주지 않는다.
console.log(arr.length); // 2배열 요소의 삭제
배열은 사실 객체이기 때문에 배열의 특정 요소를 삭제하기 위해 delete 연산자를 사용할 수 있다.
const arr = [1, 2, 3];
// 배열 요소의 삭제
delete arr[1];
console.log(arr); // [1, empty, 3]
// length 프로퍼티에 영향을 주지 않는다. 즉, 희소 배열이 된다.
console.log(arr.length); // 3delete 연산자는 객체의 프로퍼티를 삭제하는데 이때 배열은 희소 배열이 되며 length 프로퍼티 값은 변하지 않는다.
그렇기에 배열의 요소를 삭제하려고 희소 배열을 만드는 delete 연산자는 사용하지 않는 것이 좋다.
대신 Array.prototype.splice 메서드를 사용하면 희소 배열을 만들지않고 요소를 삭제할 수 있다.
const arr = [1, 2, 3];
// Array.prototype.splice(삭제를 시작할 인덱스, 삭제할 요소 수)
// arr[1]부터 1개의 요소를 제거
arr.splice(1, 1);
console.log(arr); // [1, 3]
// length 프로퍼티가 자동으로 갱신된다.
console.log(arr.length); // 2배열 메서드
자바스크립트는 배열을 다룰 때 유용한 다양한 빌트인 메서드를 제공한다.
Array 생성자 함수는 정적 메서드를 제공하며, 배열 객체의 프로토타입은 Array.prototype은 프로토타입 메서드를 제공한다.
배열 메서드는 결과물을 반환하는 패턴이 아래와 같이 두 가지이므로 보다 깊은 이해도가 필요하다.
- 원본 배열을 직접 변경하는 메서드
- 원본 배열을 직접 변경하지 않고 새로운 배열을 생성하여 반환하는 메서드
여기서 원본 배열은 배열 메서드를 호출한 배열이다. 즉, 배열 메서드의 구현체 내부에서 this가 가리키는 객체를 말한다.
ES5부터 도입된 배열 메서드는 대부분 원본 배열을 직접 변경하지 않지만 초창기 배열 메서드는 원본 배열을 직접 변경하는 경우가 많다.
원본 배열을 직접 변경하는 메서드는 외부 상태를 직접 변경하는 부수 효과가 있으므로 사용할 때 주의해야 한다.
따라서 가급적 원본 배열을 직접 변경하지 않는 메서드 사용을 지향하자
Array.isArray
Array.isArray 메서드는 Array.of 와 Array.from 과 같이 Array 생성자 함수의 정적 메서드다.
Array.isArray 메서드는 전달된 인수가 배열이면 true, 배열이 아니면 false를 반환한다.
// true
Array.isArray([]);
Array.isArray([1, 2]);
Array.isArray(new Array());
// false
Array.isArray();
Array.isArray({});
Array.isArray(null);
Array.isArray(undefined);
Array.isArray(1);
Array.isArray("Array");
Array.isArray(true);
Array.isArray(false);
Array.isArray({ 0: 1, length: 1 }); // 유사 배열 객체Array.prototype.indexOf
indexOf 메서드는 원본 배열에서 인수로 전달된 요소를 검색하여 요소의 인덱스를 반환한다.
원본 배열에 인수로 전달한 요소와 중복되는 요소가 여러 개 있다면 첫 번째로 검색된 요소의 인덱스를 반환한다.
원본 배열에 인수로 전달한 요소가 존재하지 않으면 -1을 반환한다.
const arr = [1, 2, 2, 3];
// 배열 arr에서 요소 2를 검색하여 첫 번째로 검색된 요소의 인덱스를 반환한다.
arr.indexOf(2); // 1
// 배열 arr에 요소 4가 없으므로 -1을 반환한다.
arr.indexOf(4); // -1
// 두 번째 인수는 검색을 시작할 인덱스다. 두 번째 인수를 생략하면 처음부터 검색한다.
arr.indexOf(2, 2); // 2배열에 특정 요소가 존재하는지 확인할 때 유용하다. 하지만 ES7에서 도입된 Array.prototype.includes 메서드를 사용하면 가독성이 더 좋다.
const foods = ["apple", "banana", "orange"];
// indexOf메서드 사용시
// foods 배열에 'orange' 요소가 존재하는지 확인한다.
if (foods.indexOf("orange") === -1) {
// foods 배열에 'orange' 요소가 존재하지 않으면 'orange' 요소를 추가한다.
foods.push("orange");
}
// includes메서드 사용시
if (!foods.includes("orange")) {
foods.push("orange");
}
console.log(foods); // ["apple", "banana", "orange"]Array.prototype.push
push 메서드는 인수로 전달받은 모든 값을 원본 배열의 마지막 요소로 추가하고 변경된 length 프로퍼티 값을 반환한다.
push 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열 arr의 마지막 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.push(3, 4);
console.log(result); // 4
// push 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 2, 3, 4]push 메서드는 원본 배열을 직접 변경하는 부수 효과가 있고 성능 면에서도 좋지 않다. 따라서 push 메서드보다는 ES6의 스프레드 문법을 사용하는 편이 좋다.
const arr = [1, 2];
// ES6의 스프레드 문법
const newArr = [...arr, 3];
console.log(newArr); // [1, 2, 3]Array.prototype.pop
pop 메서드는 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다. 원본 배열이 빈 배열이면 undefined를 반환한다.
pop 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 원본 배열에서 마지막 요소를 제거하고 제거한 요소를 반환한다.
const result = arr.pop();
console.log(result); // 2
// pop 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1]pop 메서드와 push 메서드를 사용하면 스택 자료구조를 쉽게 구현할 수 있다.
스택은 데이터를 마지막에 밀어 넣고, 마지막에 밀어 넣은 데이터를 먼저 꺼내는 후입 선출(LIFO - Last In First Out) 방식의 자료 구조다.
스택에 데이터를 밀어 넣는 것을 push 라하고 스택에서 데이터를 꺼내는 것을 pop이라고 한다.
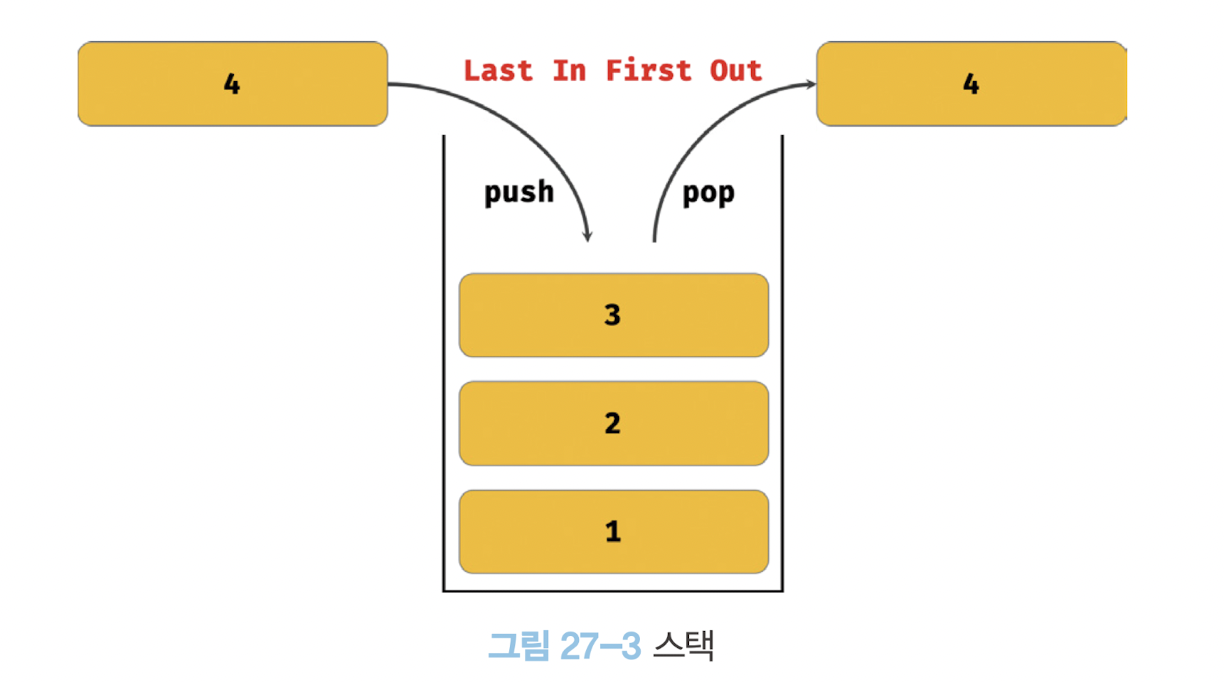
Array.prototype.unshift
unshift 메서드는 인수로 전달받은 모든 값을 원본 배열의 선두에 요소로 추가하고 변경된 length 프로퍼티 값을 반환단다.
unshift 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 인수로 전달받은 모든 값을 원본 배열의 선두에 요소로 추가하고 변경된 length 값을 반환한다.
let result = arr.unshift(3, 4);
console.log(result); // 4
// unshift 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [3, 4, 1, 2]unshift 메서드는 원본 배열을 직접 변경하는 부수 효과가 있다. 따라서 unshift 메서드보다는 ES6의 스프레드 문법을 사용하는 편이 좋다.
const arr = [1, 2];
// ES6의 스프레드 문법
const newArr = [3, ...arr];
console.log(arr); // [3, 1, 2]Array.prototype.shift
shift 메서드는 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환한다. 원본 배열이 빈 배열이면 undefiend 를 반환한다.
shift 메서드는 원본 배열을 직접 변경한다.
const arr = [1, 2];
// 원본 배열에서 첫 번째 요소를 제거하고 제거한 요소를 반환한다.
let result = arr.shift();
console.log(result); // 1
// shift 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [2]shift 메서드와 push 메서드를 사용하면 큐를 쉽게 구현할 수 있다.
큐는 데이터를 마지막에 밀어 넣고, 처음 데이터, 즉 가장 먼저 밀어 넣은 데이터를 먼저 꺼내는 선입 선출(FIFO - First In First Out)방식의 자료구조다.
스택은 언제나 마지막에 밀어 넣은 데이터를 최신 데이터로 취득한다.
큐는 언제나 밀어 넣은 순서대로 최신 데이터를 취득한다.
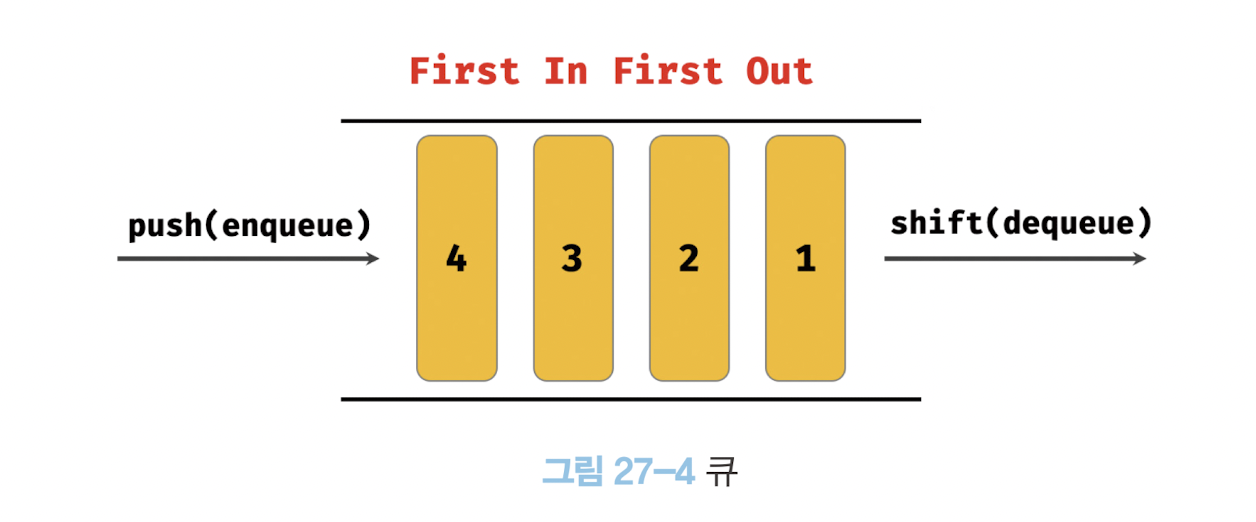
Array.prototype.concat
concat 메서드는 인수로 전달된 값들(배열 또는 원시값)을 원본 배열의 마지막 요소로 추가한 새로운 배열을 반환한다.
인수로 전달한 값이 배열(1차원 배열)인 경우 배열을 해체하여 새로운 배열의 요소로 추가한다.
원본 배열은 변경되지 않는다.
const arr1 = [1, 2];
const arr2 = [3, 4];
// 배열 arr2를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
// 인수로 전달한 값이 배열인 경우 배열을 해체하여 새로운 배열의 요소로 추가한다.
let result = arr1.concat(arr2);
console.log(result); // [1, 2, 3, 4]
// 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
result = arr1.concat(3);
console.log(result); // [1, 2, 3]
// 배열 arr2와 숫자를 원본 배열 arr1의 마지막 요소로 추가한 새로운 배열을 반환한다.
result = arr1.concat(arr2, 5);
console.log(result); // [1, 2, 3, 4, 5]
// 원본 배열은 변경되지 않는다.
console.log(arr1); // [1, 2]concat 메서드는 ES6의 스프레드 문법으로 대체할 수 있다.
let result = [1, 2].concat([3, 4]);
console.log(result); // [1, 2, 3, 4]
//concat 메서드는 ES6의 스프레드 문법으로 대체할 수 있다.
result = [...[1, 2], ...[3, 4]];
console.log(result); // [1, 2, 3, 4]원본 배열을 직접 변경하지 않고 새로운 배열은 반환하는 concat 메서드는 부수효과가 없다.
결론적으로 push/unshift 메서드와 concat 메서드를 사용하는대신 ES6 의 스프레드 문법을 일관성 있게 사용하는 것을 권장한다.
Array.prototype.splice
push, pop, unshift, shift 메서드는 모두 원본 배열을 직접 변경하는 메서드이며 원본 배열의 처음이나 마지막 요소를 추가하거나 제거한다.

원본 배열의 중간에 요소를 추가하거나 중간에 있는 요소를 제거하는 경우 splice 메서드를 사용한다.
splice 메서드는 3개의 매개변수가 있으며 원본 배열을 직접 변경한다.
-
start
원본 배열의 요소를 제거하기 시작할 인덱스이다.
start만 지정하면 원본 배열의 모든 요소를 제거한다.
start가 음수일 경우 배열의 끝에서의 인덱스를 나타낸다. -
deleteCount(옵션)
원본 배열의 요소를 제거하기 시작할 인덱스인 start부터 제거할 요소의 개수이다.
deleteCount가 0인 경우 아무런 요소도 제거되지 않는다. -
items(옵션)
제거한 위치에 삽입할 요소들의 목록이다.
생략할 경우 원본 배열에서 요소를 제거하기만 한다.
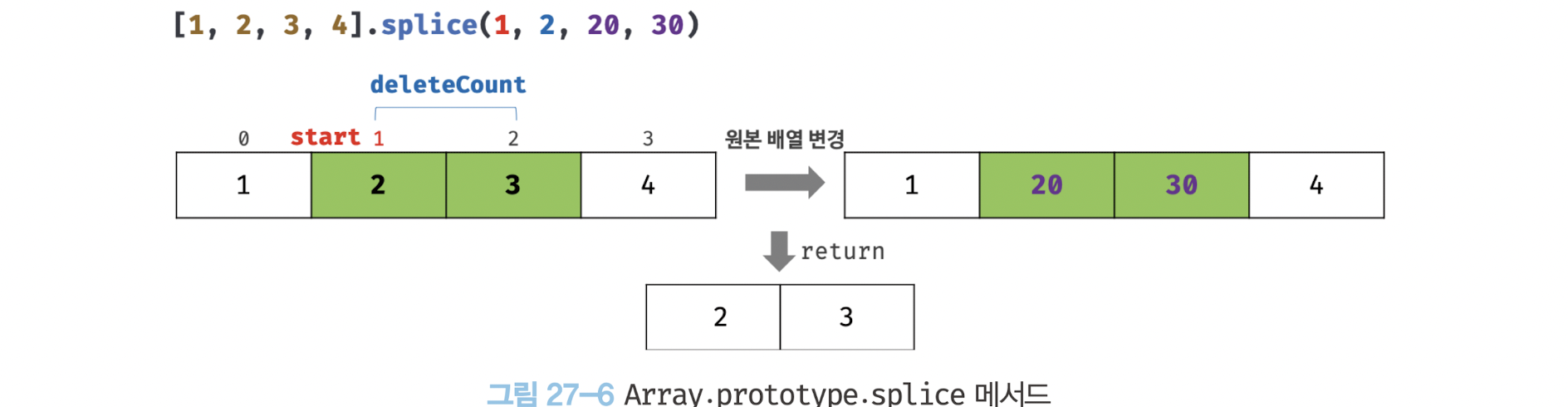
const arr = [1, 2, 3, 4];
// 원본 배열의 인덱스 1부터 2개의 요소를 제거하고 그 자리에 새로운 요소 20, 30을 삽입한다.
const result = arr.splice(1, 2, 20, 30);
// 제거한 요소가 배열로 반환된다.
console.log(result); // [2, 3]
// splice 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 20, 30, 4]두번째 인수, 즉 제거할 요소의 개수를 0으로 지정하면 아무런 요소도 제거하지 않고 새로운 요소들을 삽입한다.
const arr = [1, 2, 3, 4];
// 원본 배열의 인덱스 1부터 0개의 요소를 제거하고 그 자리에 새로운 요소 100을 삽입한다.
const result = arr.splice(1, 0, 100);
// splice 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 100, 2, 3, 4]
// 제거한 요소가 배열로 반환된다.
console.log(result); // []세번째 인수 즉, 제거한 위치에 추가할 요소들의 목록을 전달하지 않으면 원본 배열에서 지정된 요소를 제거하기만 한다.
const arr = [1, 2, 3, 4];
// 원본 배열의 인덱스 1부터 2개의 요소를 제거한다.
const result = arr.splice(1, 2);
// splice 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 4]
// 제거한 요소가 배열로 반환된다.
console.log(result); // [2, 3]splice 메서드의 두번째 인수, 즉 제거할 요소의 개수를 생략하면 첫 번째 인수로 전달된 시작 인덱스부터 모든 요소를 제거한다.
const arr = [1, 2, 3, 4];
// 원본 배열의 인덱스 1부터 모든 요소를 제거한다.
const result = arr.splice(1);
// splice 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1]
// 제거한 요소가 배열로 반환된다.
console.log(result); // [2, 3, 4]배열에서 특정 요소를 제거하려면 indexOf 메서드를 통해 특정 요소의 인덱스를 취득한 다음 splice 메서드를 사용한다.
const arr = [1, 2, 3, 1, 2];
// 배열 array에서 item 요소를 제거한다. item 요소가 여러 개 존재하면 첫 번째 요소만 제거한다.
function remove(array, item) {
// 제거할 item 요소의 인덱스를 취득한다.
const index = array.indexOf(item);
// 제거할 item 요소가 있다면 제거한다.
if (index !== -1) array.splice(index, 1);
return array;
}
console.log(remove(arr, 2)); // [1, 3, 1, 2]
console.log(remove(arr, 10)); // [1, 3, 1, 2]filter 메서드를 사용하여 특정 요소를 제거할 수도 있다. 하지만 특정 요소가 중복된 경우 모두 제거된다.
const arr = [1, 2, 3, 1, 2];
function removeAll(array, item) {
return array.filter((v) => v !== item);
}
console.log(removeAll(arr, 2)); // [1, 3, 1]Array.prototype.slice
slice 메서드는 인수로 전달된 범위의 요소들을 복사하여 배열로 반환한다.
원본 배열은 변경되지 않는다.
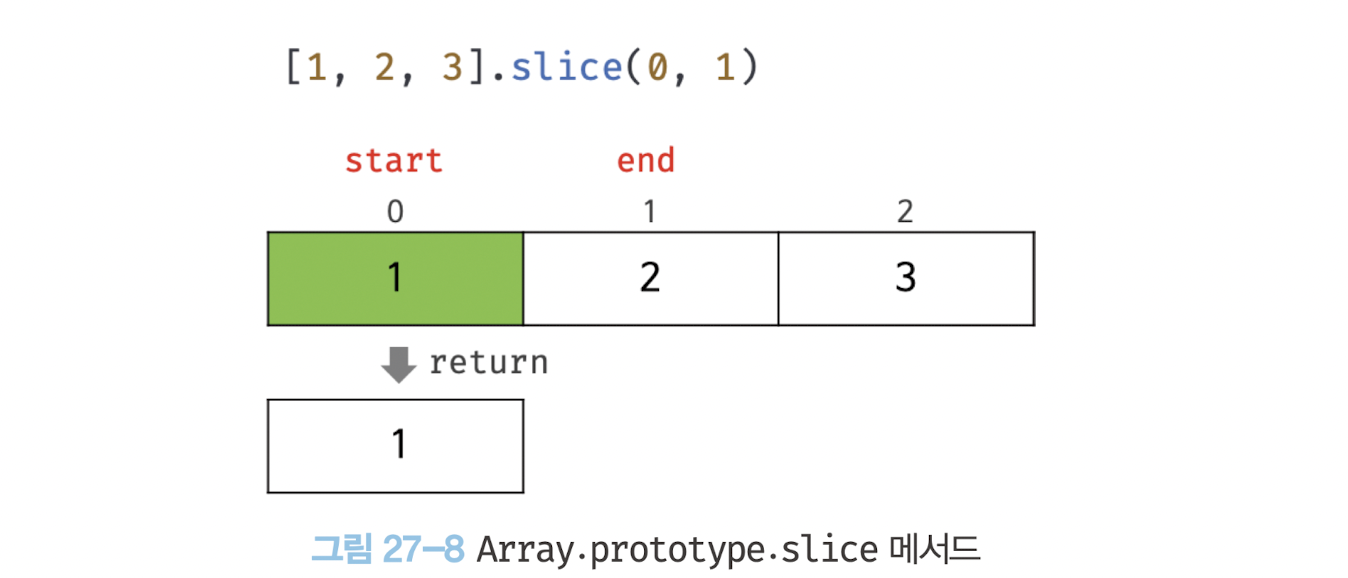
const arr = [1, 2, 3];
// arr[0]부터 arr[1] 이전(arr[1] 미포함)까지 복사하여 반환한다.
arr.slice(0, 1); // -> [1]
// arr[1]부터 arr[2] 이전(arr[2] 미포함)까지 복사하여 반환한다.
arr.slice(1, 2); // -> [2]
// 원본은 변경되지 않는다.
console.log(arr); // [1, 2, 3]두번째 인수를 생략하면 첫 번째 인수로 전달 받은 인덱스부터 모든 요소를 복사하여 배열로 반환한다.
const arr = [1, 2, 3];
// arr[1] 부터 이후의 모든 요소를 복사하여 반환한다.
arr.slice(1); // -> [2, 3]첫번째 인수가 음수인 경우 배열의 끝에서부터 요소를 복사하여 배열로 반환한다.
const arr = [1, 2, 3];
// 배열의 끝에서부터 요소를 한 개 복사하여 반환한다.
arr.slice(-1); // -> [3]
// 배열의 끝에서부터 요소를 두 개 복사하여 반환한다.
arr.slice(-2); // -> [2, 3]인수를 모두 생략하면 원본 배열의 복사본을 생성하여 반환한다. 이때 생성된 복사본은 얕은 복사를 통해 생성된다.
const arr = [1, 2, 3];
const copy = arr.slice();
console.log(copy); // [1, 2, 3]
console.log(copy === arr); // false얕은복사와 깊은복사 ?
객체를 프로퍼티 값으로 갖는 객체의 경우
- 얕은 복사는 한 단계까지만 복사하는 것을 말하고
- 깊은 복사는 객체에 중첩되어 있는 객체까지 모두 복사하는 것을 말한다. ㅤ
slice 메서드, 스프레드 문법, Object.assign 메서드는 모두 얕은 복사를 수행한다.
Array.prototype.join
join 메서드는 원본 배열의 모든 요소를 문자열로 변환한 후, 인수를 전달받은 문자열인 구분자로 연결한 문자열을 반환한다.
구분자는 생략 가능하며 기본 구분자는 콤마(,)다.
const arr = [1, 2, 3, 4];
// 기본 구분자는 ','이다.
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 기본 구분자 ','로 연결한 문자열을 반환한다.
arr.join(); // '1,2,3,4';
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 빈문자열로 연결한 문자열을 반환한다.
arr.join(""); // '1234'
// 원본 배열 arr의 모든 요소를 문자열로 변환한 후, 구분자 ':'로 연결한 문자열을 반환한다.
arr.join(":"); // '1:2:3:4'Array.prototype.reverse
reverse 메서드는 원본 배열의 순서를 반대로 뒤집는다. 이때 원본 배열이 변경된다.
반환 값은 변경된 배열이다.
const arr = [1, 2, 3];
const result = arr.reverse();
// reverse 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [3, 2, 1]
// 반환값은 변경된 배열이다.
console.log(result); // [3, 2, 1]Array.prototype.fill
ES6 에서 도입된 fill 메서드는 인수로 전달받은 값을 배열의 처음부터 끝까지 요소로 채운다.
이때 원본 배열이 변경된다.
const arr = [1, 2, 3];
// 인수로 전달 받은 값 0을 배열의 처음부터 끝까지 요소로 채운다.
arr.fill(0);
// fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [0, 0, 0]두번째 인수로 요소 채우기를 시작할 인덱스를 전달 할 수 있다.
const arr = [1, 2, 3];
// 인수로 전달받은 값 0을 배열의 인덱스 1부터 끝까지 요소로 채운다.
arr.fill(0, 1);
// fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 0, 0]세 번째 인수로 요소 채우기를 멈출 인덱스를 전달 할 수 있다.
const arr = [1, 2, 3, 4, 5];
// 인수로 전달받은 값 0을 배열의 인덱스 1부터 3 이전(인덱스 3 미포함)까지 요소로 채운다.
arr.fill(0, 1, 3);
// fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 0, 0, 4, 5]fill 메서드를 사용하면 배열을 생성하면서 특정 값으로 요소를 채울 수 있다.
const arr = new Array(3);
console.log(arr); // [empty × 3]
// 인수로 전달받은 값 1을 배열의 처음부터 끝까지 요소로 채운다.
const result = arr.fill(1);
// fill 메서드는 원본 배열을 직접 변경한다.
console.log(arr); // [1, 1, 1]
// fill 메서드는 변경된 원본 배열을 반환한다.
console.log(result); // [1, 1, 1]Array.prototype.includes
ES7에서 도입된 includes 메서드는 배열 내에 특정 요소가 포함되어 있는지 확인하여 true또는 false를 반환한다.
첫 번째 인수로 검색할 대상을 지정한다.
const arr = [1, 2, 3];
// 배열에 요소 2가 포함되어 있는지 확인한다.
arr.includes(2); // -> true
// 배열에 요소 100이 포함되어 있는지 확인한다.
arr.includes(100); // -> false두번째 인수로 검색을 시작할 인덱스를 전달 할 수 있다.
두 번째 인수를 생략할 경우 기본 값 0이 설정된다. 만약 두 번째 인수에 음수를 전달하면 length 프로퍼티 값과 음수 인덱스를 합산하여(length + index) 검색시작 인덱스를 설정한다.
const arr = [1, 2, 3];
// 배열에 요소 1이 포함되어 있는지 인덱스 1부터 확인한다.
arr.includes(1, 1); // -> false
// 배열에 요소 3이 포함되어 있는지 인덱스 2(arr.length - 1)부터 확인한다.
arr.includes(3, -1); // -> trueArray.prototype.flat
ES10(ECMAScript 2019)에서 도입된 flat 메서드는 인수로 전달한 깊이만큼 재귀적으로 배열을 평탄화한다.
평탄화한 새 배열을 생성하여 반환하며 원본 배열의 변경이 없다.
[1, [2, 3, 4, 5]].flat(); // -> [1, 2, 3, 4, 5]중첩 배열을 평탄화할 깊이를 인수로 전달할 수 있다.
인수를 생략할 경우 기본값은 1이다. 인수로 Infinity를 전달하면 중첩 배열 모두를 평탄화한다.
// 중첩 배열을 평탄화하기 위한 깊이 값의 기본값은 1이다.
[1, [2, [3, [4]]]].flat(); // -> [1, 2, [3, [4]]]
[1, [2, [3, [4]]]].flat(1); // -> [1, 2, [3, [4]]]
// 중첩 배열을 평탄화하기 위한 깊이 값을 2로 지정하여 2단계 깊이까지 평탄화한다.
[1, [2, [3, [4]]]].flat(2); // -> [1, 2, 3, [4]]
// 2번 평탄화한 것과 동일하다.
[1, [2, [3, [4]]]].flat().flat(); // -> [1, 2, 3, [4]]
// 중첩 배열을 평탄화하기 위한 깊이 값을 Infinity로 지정하여 중첩 배열 모두를 평탄화한다.
[1, [2, [3, [4]]]].flat(Infinity); // -> [1, 2, 3, 4]배열 고차 함수
고차 함수(Higher-Order Function, HOF)는 함수를 인수로 전달받거나 함수를 반환하는 함수를 말한다.
자바스크립트의 함수는 일급 객체이므로 함수를 값처럼 인수로 전달할 수 있으며 반환할 수도 있다.
고차 함수는 외부 상태의 변경이나 가변 데이터를 피하고 불변성을 지향하는 함수형 프로그래밍에 기반을 두고 있다.
함수형 프로그래밍은 순수 함수와 보조 함수의 조합을 통해 로직 내에 존재하는 조건문과 반복문을 제거하여 복잡성을 해결하고 변수의 사용을 억제하여 상태 변경을 피하려는 프로그래밍 패러다임이다.
함수형 프로그래밍은 결국 순수 함수를 통해 부수 효과를 최대한 억제하여 오류를 피하고 프로그램의 안정성을 높이려는 노력의 일환이라고 할 수 있다.
자바스크립트는 고차 함수를 다수 지원한다. 특히 배열은 매우 유용한 다양한 고차 함수들이 존재한다.
Array.prototype.sort
sort 메서드는 배열의 요소를 정렬한다. 원본 배열을 직접 변경하며 정렬된 배열을 반환한다.
기본적으로 오름차순으로 요소를 정렬한다.
const fruits = ["Banana", "Orange", "Apple"];
// 오름차순(ascending) 정렬
fruits.sort();
// sort 메서드는 원본 배열을 직접 변경한다.
console.log(fruits); // ['Apple', 'Banana', 'Orange']한글 문자열인 요소도 오름차순으로 정렬된다.
const fruits = ["바나나", "오렌지", "사과"];
// 오름차순(ascending) 정렬
fruits.sort();
// sort 메서드는 원본 배열을 직접 변경한다.
console.log(fruits); // [ '바나나', '사과', '오렌지' ]내림차순으로 요소를 정렬하려면 sort 메서드를 사용하여 오름차순 정렬 후 reverse 메서드를 사용하여 요소의 순서를 뒤집는다.
const fruits = ["Banana", "Orange", "Apple"];
// 오름차순(ascending) 정렬
fruits.sort();
// sort 메서드는 원본 배열을 직접 변경한다.
console.log(fruits); // ['Apple', 'Banana', 'Orange']
// 내림차순(descending)
fruits.reverse();
// reverse 메서드는 원본 배열을 직접 변경한다.
console.log(fruits); // ['Orange', 'Banana', 'Apple']위와 같이 문자열 요소로 이루어진 배열의 정렬은 아무런 문제가 없지만 숫자 요소로 이루어진 배열을 정렬할 때는 주의가 필요하다.
sort 메서드의 기본 정렬 순서는 유니코드 코드 포인트의 순서를 따른다.
배열의 요소가 숫자 타입이라 할지라도 배열의 요소를 일시적으로 문자열로 변환한 후 유니코드 포인트의 순서를 기준으로 정렬한다.
따라서 숫자 요소를 정렬할 때는 sort 메서드에 정렬 순서를 정의하는 비교 함수를 인수로 전달해야 한다.
비교 함수는 양수나 음수 또는 0을 반환해야 한다.
비교 함수의 반환값이 0보다 작으면 비교 함수의 첫 번째 인수를 우선하여 정렬하고, 0이면 정렬하지 않으며, 0보다 크면 두 번째 인수를 우선하여 정렬한다.
const points = [40, 100, 1, 5, 2, 25, 10];
// 숫자 배열의 오름차순 정렬. 비교 함수의 반환값이 0보다 작으면 a를 우선하여 정렬한다.
points.sort((a, b) => a - b);
console.log(points); // [1, 2, 5, 10, 25, 40, 100]
// 숫자 배열에서 최소/최대값 취득
console.log(points[0], points[points.length - 1]); // 1 100
// 숫자 배열의 내림차순 정렬. 비교 함수의 반환값이 0보다 작으면 b를 우선하여 정렬한다.
points.sort((a, b) => b - a);
console.log(points); // [100, 40, 25, 10, 5, 2, 1]
// 숫자 배열에서 최대값 취득
console.log(points[points.length - 1], points[0]); // 1, 100Array.prototype.forEach
forEach 메서드는 for 문을 대체할 수 있는 고차 함수다.
forEach 메서드는 자신의 내부에서 반복문을 실행한다. 반복문을 추상화한 고차 함수로서 내부에서 반복문을 통해 자신을 호출한 배열을 순회하면서 수행해야 할 처리를 콜백 함수로 전달받아 반복 호출한다.
const numbers = [1, 2, 3];
let pows = [];
// forEach 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
numbers.forEach((item) => pows.push(item ** 2));
console.log(pows); // [1, 4, 9]forEach 메서드의 콜백함수는 3개의 인수를 전달 받을 수 있다.
- forEach 메서드를 호출한 배열의 요소값
- 인덱스
- forEach 메서드를 호출한 배열자체, 즉 this
// forEach 메서드는 콜백 함수를 호출하면서 3개(요소값, 인덱스, this)의 인수를 전달한다.
[1, 2, 3].forEach((item, index, arr) => {
console.log(
`요소값: ${item}, 인덱스: ${index}, this: ${JSON.stringify(arr)}`
);
});
/*
요소값: 1, 인덱스: 0, this: [1,2,3]
요소값: 2, 인덱스: 1, this: [1,2,3]
요소값: 3, 인덱스: 2, this: [1,2,3]
*/forEach 메서드는 원본배열을 변경하지 않는다. 하지만 콜백함수를 통해 원본 배열을 변경할 수는 있다.
const numbers = [1, 2, 3];
// 콜백 함수의 세번째 매개변수 arr은 원본 배열 numbers를 가리킨다.
// 따라서 콜백 함수의 세 번째 매개변수 arr을 직접 변경하면 원본 배열 numbers가 변경된다.
numbers.forEach((item, index, arr) => {
arr[index] = item ** 2;
});
console.log(numbers); // [1, 4, 9]forEach 메서드의 반환값은 언제나 undefined 다.
forEach는 for문과는 달리 break, continue문을 사용할 수 없다.(중간에 순회 중단X)
희소 배열의 경우 존재하지 않는 요소는 순회 대상에서 제외된다.
forEach 메서드는 for 문에 비해 성능이 좋지는 않지만 가독성은 더 좋다. 따라서 요소가 대단히 많은 배열을 순회하거나 시간이 많이 걸리는 복잡한 코드 또는 높은 성능이 필요한 경우가 아니라면 for 문 대신 forEach 메서드를 사용할 것을 권장한다.
Array.prototype.map
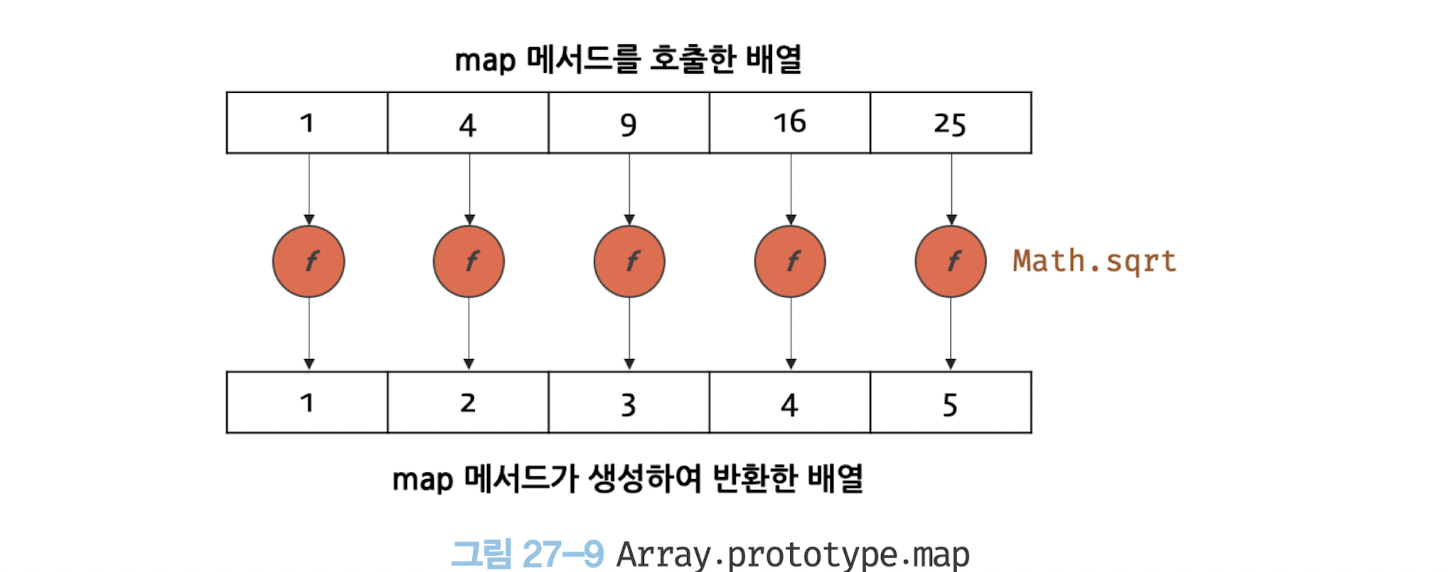
map 메서드는 자신을 호출한 배열의 모든 요소를 순회하면서 인수로 전달받은 콜백 함수를 반복 호출한다.
그리고 콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다. 이때 원본 배열은 변경되지 않는다.
const numbers = [1, 4, 9];
// map 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값들로 구성된 새로운 배열을 반환한다.
const roots = numbers.map((item) => Math.sqrt(item));
// 위 코드는 다음과 같다.
// const roots = numbers.map(Math.sqrt);
// map 메서드는 새로운 배열을 반환한다
console.log(roots); // [ 1, 2, 3 ]
// map 메서드는 원본 배열을 변경하지 않는다
console.log(numbers); // [ 1, 4, 9 ]map 메서드는 요소 값을 다른 값으로 매핑한 새로운 배열을 생성하기 위한 고차 함수다. forEach 메서드는 단순히 반복문을 대체하기 위한 고차 함수라는 차이점이 존재한다.
map 메서드가 생성하여 반환하는 새로운 배열의 length 프로퍼티 값은 map 메서드를 호출한 배열의 length 프로퍼티 값과 반드시 일치한다.
즉, map 메서드를 호출한 배열과 map 메서드가 생성하여 반환한 배열은 1:1 매핑한다.
forEach 메서드와 마찬가지로 map 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있다.
Array.prototype.filter
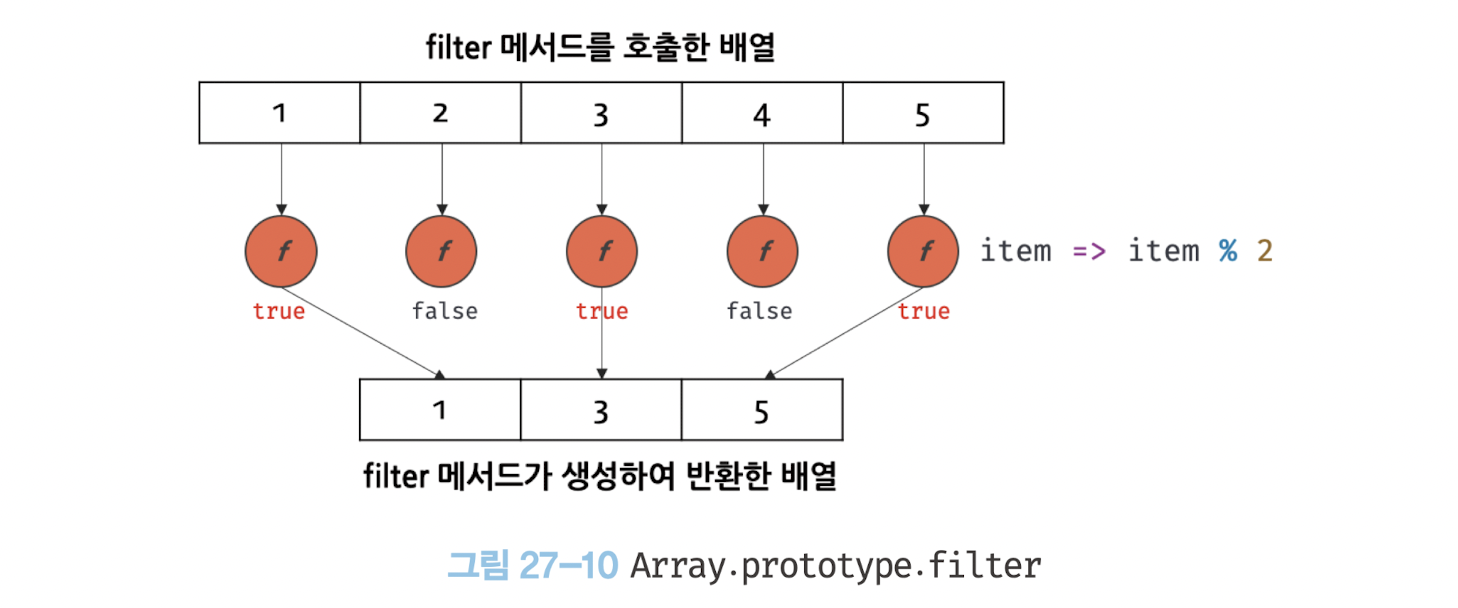
filter 메서드는 자신을 호출한 배열의 모든 요소를 순회하면서 인수로 전달받은 콜백 함수를 반복 호출한다.
그리고 콜백 함수의 반환 값이 true인 요소로만 구성된 새로운 배열을 반환한다. 이때 원본 배열은 변경되지 않는다.
const numbers = [1, 2, 3, 4, 5];
// filter 메서드는 numbers 배열의 모든 요소를 순회하면서 콜백 함수를 반복 호출한다.
// 그리고 콜백 함수의 반환값이 true인 요소로만 구성된 새로운 배열을 반환한다.
// 다음의 경우 numbers 배열에서 홀수인 요소만을 필터링한다(1은 true로 평가된다).
const odds = numbers.filter((item) => item % 2);
console.log(odds); // [1, 3, 5]filter 메서드가 생성하여 반환한 새로운 배열의 length 프로퍼티 값은 filter 메서드를 호출한 배열의 length 프로퍼티 값과 같거나 작다.
forEach, map 메서드와 마찬가지로 filter 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있다.
Array.prototype.reduce
reduce 메서드는 자신을 호출한 배열의 모든 요소를 순회하면서 인수로 전달받은 콜백 함수를 반복 호출한다.
그리고 콜백 함수의 반환값을 다음 순회 시에 콜백 함수의 첫 번째 인수로 전달하면서 콜백 함수를 호출하여 하나의 결과값을 만들어 반환한다.
이때 원본 배열은 변경되지 않는다.
reduce 메서드는 첫 번째 인수로 콜백 함수, 두 번째 인수로 초기값을 전달받는다.
reduce 메서드의 콜백 함수에는 4개의 인수가 순서대로 초기값 또는 콜백 함수 이전의 반환값, reduce 메서드를 호출한 배열의 요소값, 인덱스, reduce 메서드를 호출한 배열 자체(this)가 전달된다.
reduce 메서드를 호출할 때는 언제나 초기값을 지정하는 것이 안전하다.
// [1, 2, 3, 4]의 모든 요소의 누적을 구한다.
const sum = [1, 2, 3, 4].reduce(
(accumulator, currentValue, index, array) => accumulator + currentValue,
0
);
console.log(sum); // 10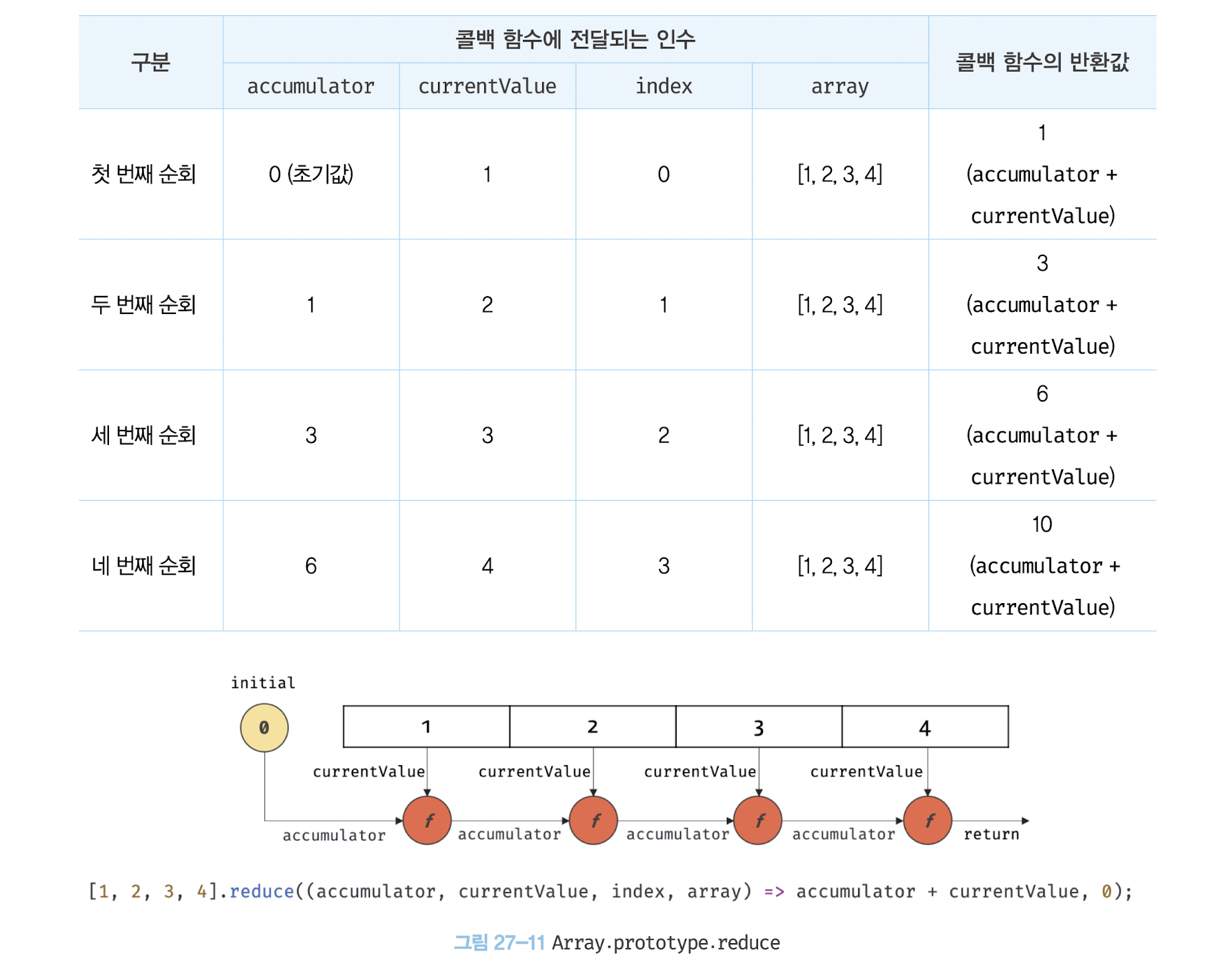
reduce 함수를 활용한 유용한 예제
요소의 중복 횟수 구하기
const fruits = ["banana", "apple", "orange", "orange", "apple"];
const fruitsCountObj = fruits.reduce((acc, cur) => {
acc[cur] = (acc[cur] || 0) + 1;
return acc;
}, {});
console.log(fruitsCountObj); // { banana: 1, apple: 2, orange: 2 }Array.prototype.some
some 메서드는 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백함수를 호출한다.
이때 some 메서드는 콜백 함수의 반환값이 단 한번이라도 참이면 true, 모두 거짓이면 false를 반환한다.
즉, 배열의 요소 중에 콜백 함수를 통해 정의한 조건을 만족하는 요소가 1개 이상 존재하는지 확인하여 그 결과를 불리언 타입으로 반환한다.
단, some 메서드를 호출한 배열이 빈 배열인 경우 언제나 false 를 반환한다.
forEach, map, filter 메서드와 마찬가지로 some 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있고, 화살표 함수를 사용해 this로 사용할 객체를 전달할 수 있다.
// 배열의 요소 중에 10보다 큰 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some((item) => item > 10); // true
// 배열의 요소 중에 0보다 작은 요소가 1개 이상 존재하는지 확인
[5, 10, 15].some((item) => item < 0); // false
// 배열의 요소 중에 'banana'가 1개 이상 존재하는지 확인
["apple", "banana", "mango"].some((item) => item === "banana"); // true
// some 메서드를 호출한 배열이 빈 배열인 경우 언제나 false를 반환한다.
[].some((item) => item > 3); // falseArray.prototype.every
every 메서드는 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백함수를 호출한다.
이때 every 메서드는 콜백 함수의 반환값이 모두 참이면 true, 단 한 번이라도 거짓이면 false 를 반환한다.
즉, 배열의 모든 요소가 콜백 함수를 통해 정의한 조건을 모두 만족하는지 확인하여
그 결과를 불리언 타입으로 반환한다.
단, every 메서드를 호출한 배열이 빈 배열인 경우 언제나 true 를 반환하므로 주의하자.
forEach,map,filter 메서드와 마찬가지로 every 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있고, 화살표 함수를 사용해 this로 사용할 객체를 전달할 수 있다.
// 배열의 모든 요소가 3보다 큰지 확인
[5, 10, 15].every((item) => item > 3); // true
// 배열의 모든 요소가 10보다 큰지 확인
[5, 10, 15].every((item) => item > 10); // false
// every 메서드를 호출한 배열이 빈 배열인 경우 언제나 true를 반환한다.
[].every((item) => item > 3); // trueArray.prototype.find
ES6에서 도입된 find 메서드는 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백함수를 호출하여 반환값이 true 인 첫 번째 요소를 반환한다.
콜백 함수의 반환값이 true 인 요소가 존재하지 않으면 undefined 를 반환한다.
forEach,map,filter 메서드와 마찬가지로 find 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있고, 화살표 함수를 사용해 this로 사용할 객체를 전달할 수 있다.
const users = [
{ id: 1, name: "Lee" },
{ id: 2, name: "Kim" },
{ id: 2, name: "Choi" },
{ id: 3, name: "Park" },
];
// id가 2인 첫 번째 요소를 반환한다. find 메서드는 배열이 아니라 요소를 반환한다.
users.find((user) => user.id === 2); // {id: 2, name: 'Kim'}
// Array#filter는 배열을 반환한다.
[1, 2, 2, 3].filter((item) => item === 2); // [2, 2]
// Array#find는 요소를 반환한다.
[1, 2, 2, 3].find((item) => item === 2); // 2Array.prototype.findIndex
ES6에서 도입된 findIndex 메서드는 자신을 호출한 배열의 요소를 순회하면서 인수로 전달된 콜백함수를 호출하여 반환값이 true인 첫 번째 요소의 인덱스를 반환한다.
콜백 함수의 반환값이 true 인 요소가 존재하지 않으면 -1을 반환한다.
forEach,map,filter 메서드와 마찬가지로 findIndex 메서드의 콜백 함수는 3개의 인수(요소값, 인덱스, this)를 순차적으로 전달받을 수 있고, 화살표 함수를 사용해 this로 사용할 객체를 전달할 수 있다.
const users = [
{ id: 1, name: "Lee" },
{ id: 2, name: "Kim" },
{ id: 2, name: "Choi" },
{ id: 3, name: "Park" },
];
// id가 2인 요소의 인덱스를 구한다.
users.findIndex((user) => user.id === 2); // 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex((user) => user.name === "Park"); // 3
// 위와 같이 프로퍼티 키와 프로퍼티 값으로 요소의 인덱스를 구하는 경우
// 다음과 같이 콜백 함수를 추상화할 수 있다.
function predicate(key, value) {
// key와 value를 기억하는 클로저를 반환
return (item) => item[key] === value;
}
// id가 2인 요소의 인덱스를 구한다.
users.findIndex(predicate("id", 2)); // 1
// name이 'Park'인 요소의 인덱스를 구한다.
users.findIndex(predicate("name", "Park")); // 3Array.prototype.flatMap
ES10(ECMAScript 2019)에서 도입된 flatMap 메서드는 map 메서드를 통해 생성된 새로운 배열을 평탄화 한다.
즉, 메서드와 flat 메서드를 순차적으로 실행하는 효과가 있다.
const arr = ["hello", "world"];
// map과 flat을 순차적으로 실행
arr.map((x) => x.split("")).flat();
// ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
// flatMap은 map을 통해 생성된 새로운 배열을 평탄화한다.
arr.flatMap((x) => x.split(""));
// ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']원본 배열을 변경하지 않으며 새로운 배열을 반환한다.
const arr = ["hello", "world"];
// flatMap은 map을 통해 생성된 새로운 배열을 평탄화한다.
const newArr = arr.flatMap((x) => x.split(""));
console.log(arr); // [ 'hello', 'world' ]
console.log(newArr); // ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']단, 인수를 전달하여 깊이를 지정할 수 없고 1단계만 평탄화한다. 평탄화 깊이를 지정해야 한다면 flatMap 대신 map, flat 메서드를 각각 호출한다.
const arr = ["hello", "world"];
// flatMap은 1단계만 평탄화한다.
arr.flatMap((str, index) => [index, [str, str.length]]);
// [[0, ['hello', 5]], [1, ['world', 5]]] => [0, ['hello', 5], 1, ['world', 5]]
// 평탄화 깊이를 지정해야 하면 flatMap 메서드를 사용하지 말고 map 메서드와 flat 메서드를 각각 호출한다.
arr.map((str, index) => [index, [str, str.length]]).flat(2);
// [[0, ['hello', 5]], [1, ['world', 5]]] => [0, 'hello', 5, 1, 'world', 5